 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Alzheimers Dementia Detection using Acoustic & Linguistic features and Pre-Trained BERT
Sep 24, 2021
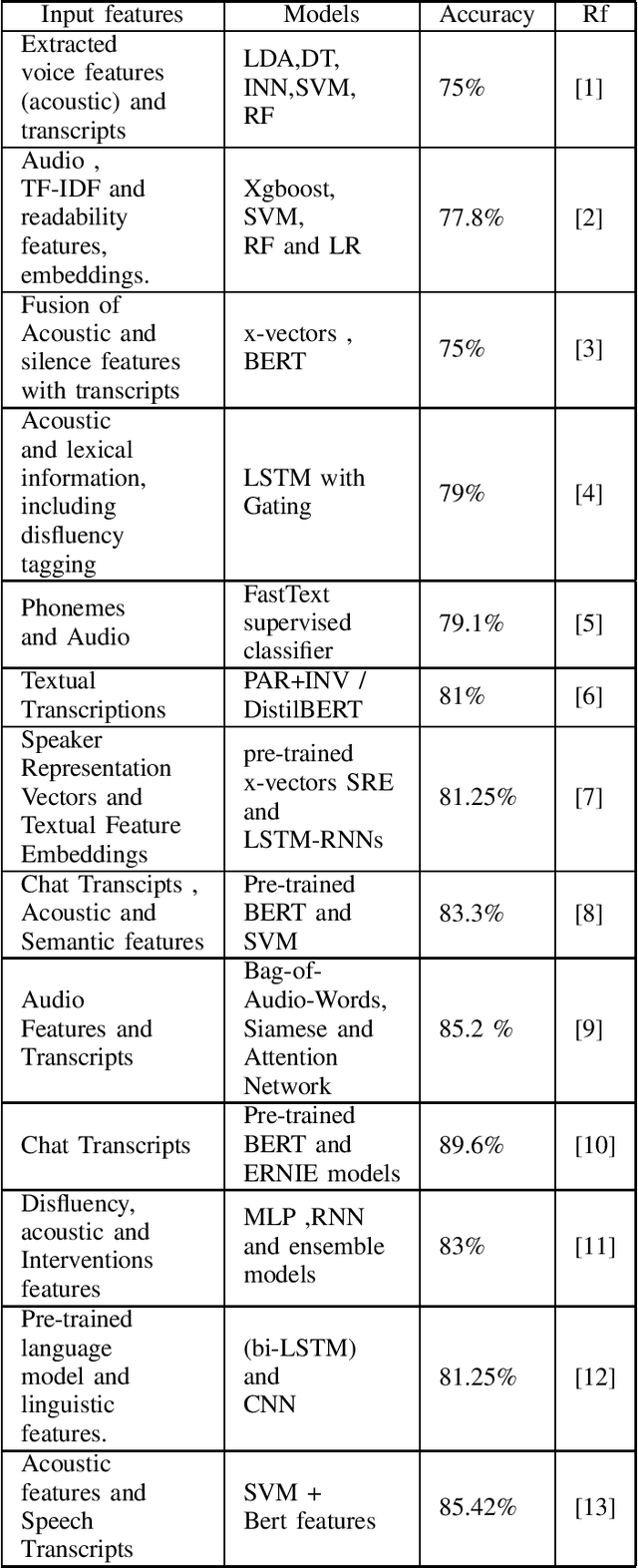
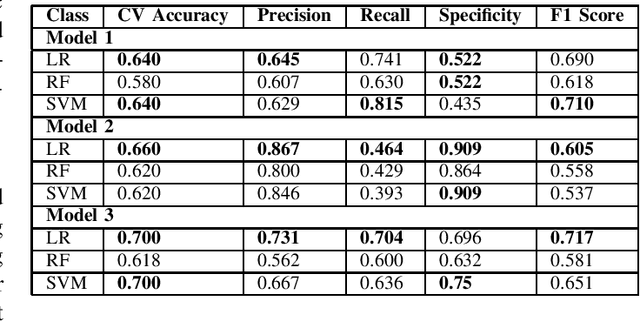
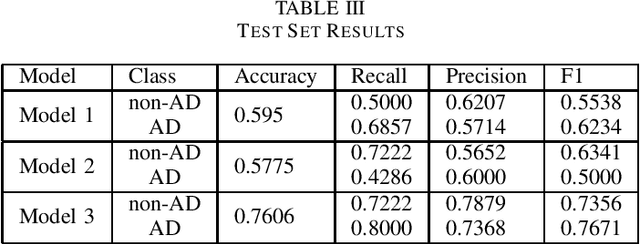
Alzheimers disease is a fatal progressive brain disorder that worsens with time. It is high time we have inexpensive and quick clinical diagnostic techniques for early detection and care. In previous studies, various Machine Learning techniques and Pre-trained Deep Learning models have been used in conjunction with the extraction of various acoustic and linguistic features. Our study focuses on three models for the classification task in the ADReSS (The Alzheimers Dementia Recognition through Spontaneous Speech) 2021 Challenge. We use the well-balanced dataset provided by the ADReSS Challenge for training and validating our models. Model 1 uses various acoustic features from the eGeMAPs feature-set, Model 2 uses various linguistic features that we generated from auto-generated transcripts and Model 3 uses the auto-generated transcripts directly to extract features using a Pre-trained BERT and TF-IDF. These models are described in detail in the models section.
AI-Based Radio Resource Management and Trajectory Design in CoMP UAV VLC Networks: Constant Velocity Vs. Constant Acceleration
Nov 06, 2021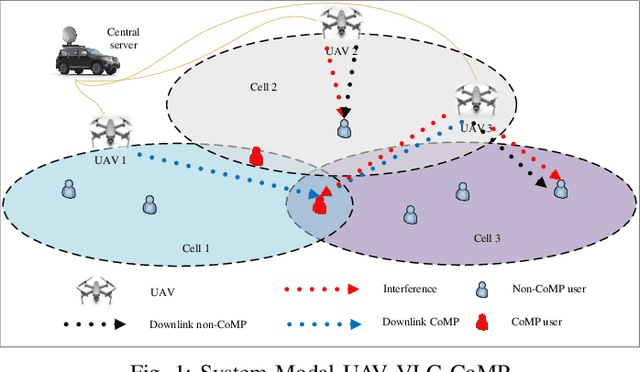
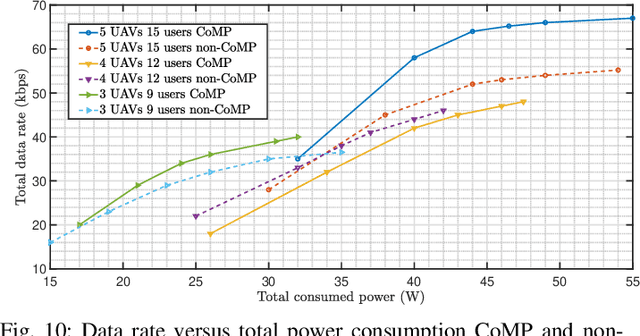
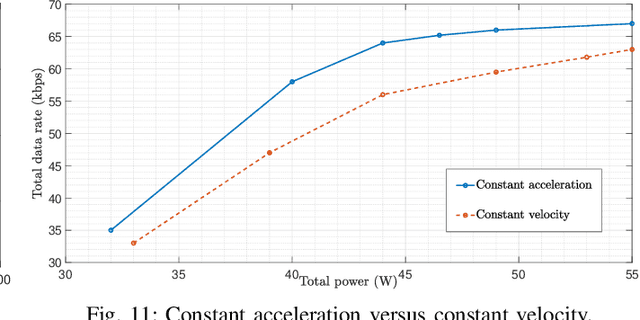
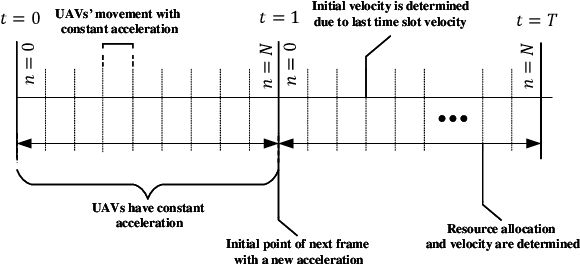
In this paper, we consider UAVs equipped with a VLC access point and coordinated multipoint (CoMP) capability that allows users to connect to more than one UAV. UAVs can move in 3-dimensional (3D) at a constant acceleration in each master timescale, where a central server is responsible for synchronization and cooperation among UAVs. We define the data rate for each user type, CoMP and non-CoMP. The constant speed in UAVs' motion is not practical, and the effect of acceleration on the movement of UAVs is necessary to be considered. Unlike most existing works, we see the effect of variable speed on kinetic and allocation formulas. For the proposed system model, we define timescales for two different slots in which resources are allocated. In the master timescale, the acceleration of each UAV is specified, and in each short timescale, radio resources are allocated. The initial velocity in each small time slot is obtained from the previous time slot's velocity. Our goal is to formulate a multiobjective optimization problem where the total data rate is maximized and the total communication power consumption is minimized simultaneously. To deal this multiobjective optimization, we first apply the weighted method and then apply multi-agent deep deterministic policy gradient (MADDPG) which is a multi-agent method based on deep deterministic policy gradient (DDPG) that ensures more stable and faster convergence. We improve this solution method by adding two critic networks as well as allocating the two step acceleration. Simulation results indicate that the constant acceleration motion of UAVs gives about 8\% better results than conventional motion systems in terms of performance. Furthermore, CoMP supports the system to achieve an average of about 12\% higher rates comparing with non-CoMP system.
LatentHuman: Shape-and-Pose Disentangled Latent Representation for Human Bodies
Nov 30, 2021
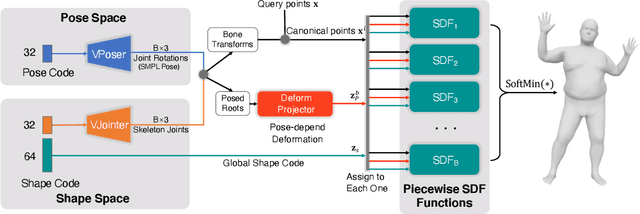
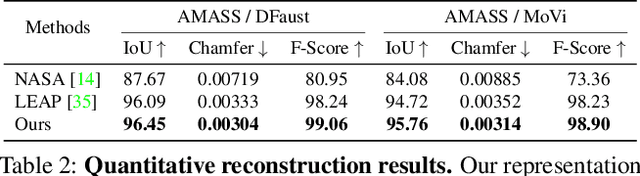

3D representation and reconstruction of human bodies have been studied for a long time in computer vision. Traditional methods rely mostly on parametric statistical linear models, limiting the space of possible bodies to linear combinations. It is only recently that some approaches try to leverage neural implicit representations for human body modeling, and while demonstrating impressive results, they are either limited by representation capability or not physically meaningful and controllable. In this work, we propose a novel neural implicit representation for the human body, which is fully differentiable and optimizable with disentangled shape and pose latent spaces. Contrary to prior work, our representation is designed based on the kinematic model, which makes the representation controllable for tasks like pose animation, while simultaneously allowing the optimization of shape and pose for tasks like 3D fitting and pose tracking. Our model can be trained and fine-tuned directly on non-watertight raw data with well-designed losses. Experiments demonstrate the improved 3D reconstruction performance over SoTA approaches and show the applicability of our method to shape interpolation, model fitting, pose tracking, and motion retargeting.
A minimalistic stochastic dynamics model of cluttered obstacle traversal
Dec 15, 2021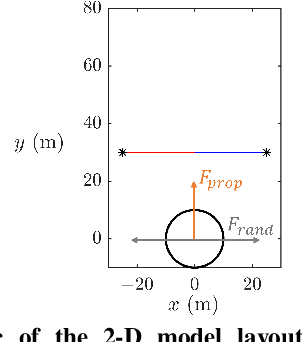
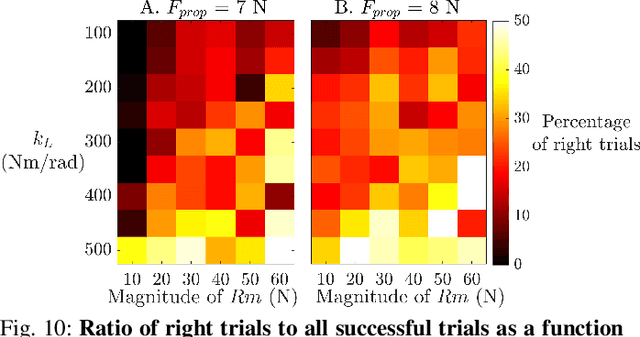
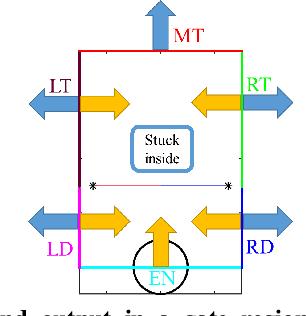
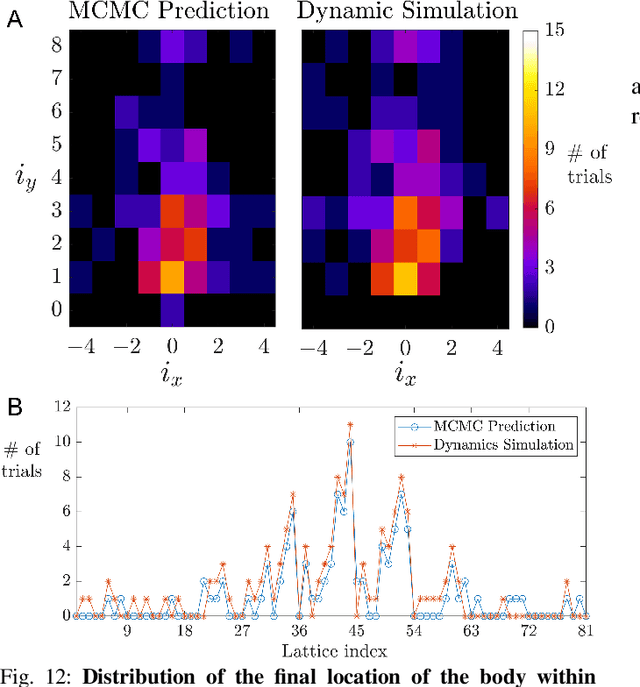
Robots are still poor at traversing cluttered large obstacles required for important applications like search and rescue. By contrast, animals are excellent at doing so, often using direct physical interaction with obstacles rather than avoiding them. Here, towards understanding the dynamics of cluttered obstacle traversal, we developed a minimalistic stochastic dynamics simulation inspired by our recent study of insects traversing grass-like beams. The 2-D model system consists of a forward self-propelled circular locomotor translating on a frictionless level plane with a lateral random force and interacting with two adjacent horizontal beams that form a gate. We found that traversal probability increases monotonically with propulsive force, but first increases then decreases with random force magnitude. For asymmetric beams with different stiffness, traversal is more likely towards the side of the less stiff beam. These observations are in accord with those expected from a potential energy landscape approach. Furthermore, we extended the single gate in a lattice configuration to form a large cluttered obstacle field. A Markov chain Monte Carlo method was applied to predict traversal in the large field, using the input-output probability map obtained from single gate simulations. This method achieved high accuracy in predicting the statistical distribution of the final location of the body within the obstacle field, while saving computation time by a factor of 10^5.
SFFDD: Deep Neural Network with Enriched Features for Failure Prediction with Its Application to Computer Disk Driver
Sep 20, 2021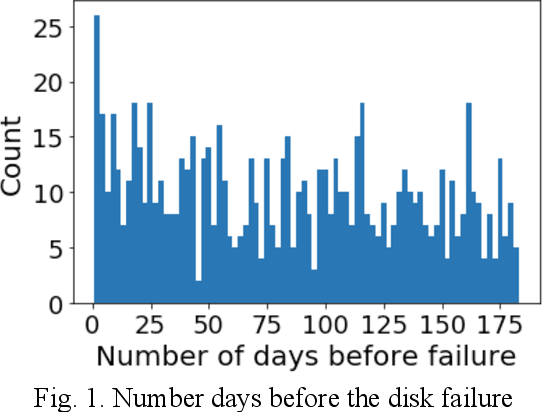
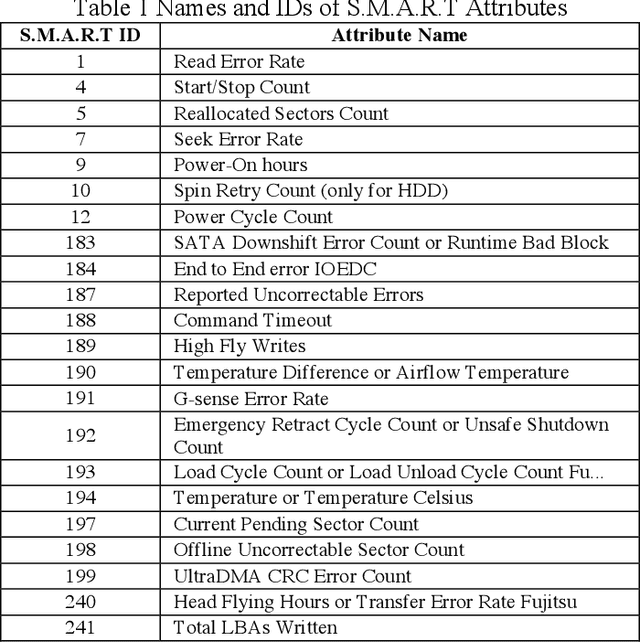
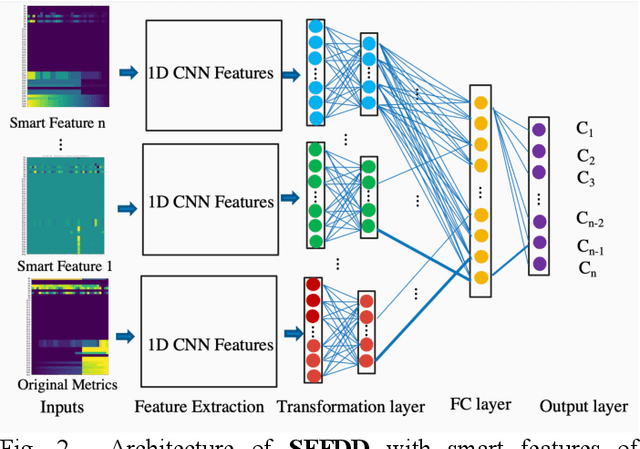
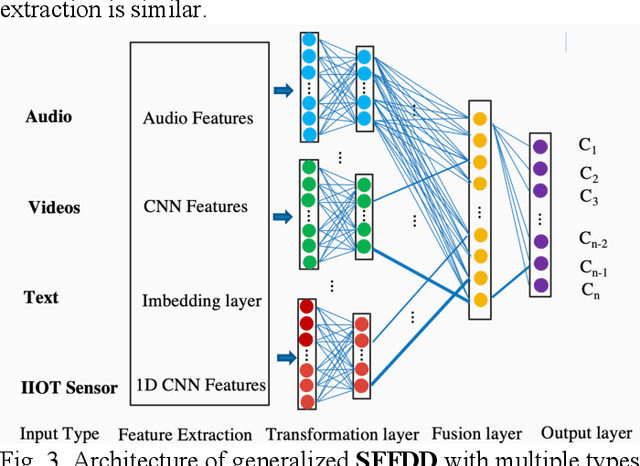
A classification technique incorporating a novel feature derivation method is proposed for predicting failure of a system or device with multivariate time series sensor data. We treat the multivariate time series sensor data as images for both visualization and computation. Failure follows various patterns which are closely related to the root causes. Different predefined transformations are applied on the original sensors data to better characterize the failure patterns. In addition to feature derivation, ensemble method is used to further improve the performance. In addition, a general algorithm architecture of deep neural network is proposed to handle multiple types of data with less manual feature engineering. We apply the proposed method on the early predict failure of computer disk drive in order to improve storage systems availability and avoid data loss. The classification accuracy is largely improved with the enriched features, named smart features.
Distributed Optimization using Heterogeneous Compute Systems
Oct 03, 2021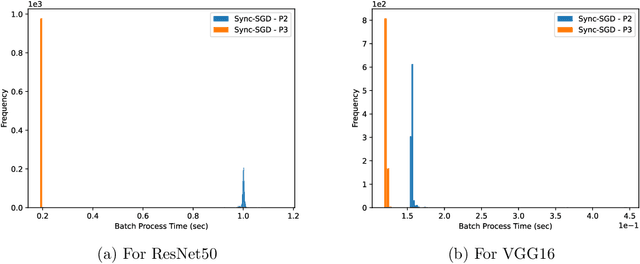
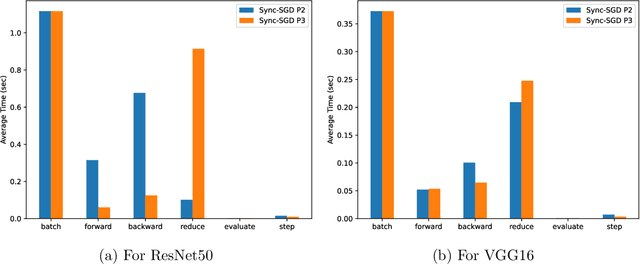
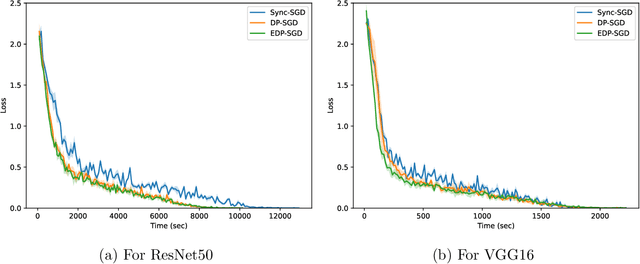
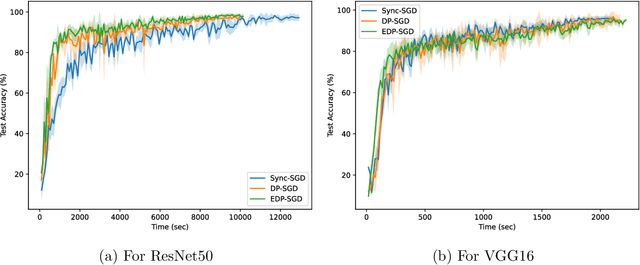
Hardware compute power has been growing at an unprecedented rate in recent years. The utilization of such advancements plays a key role in producing better results in less time -- both in academia and industry. However, merging the existing hardware with the latest hardware within the same ecosystem poses a challenging task. One of the key challenges, in this case, is varying compute power. In this paper, we consider the training of deep neural networks on a distributed system of workers with varying compute power. A naive implementation of synchronous distributed training will result in the faster workers waiting for the slowest worker to complete processing. To mitigate this issue, we propose to dynamically adjust the data assigned for each worker during the training. We assign each worker a partition of total data proportional to its computing power. Our experiments show that dynamically adjusting the data partition helps to improve the utilization of the system and significantly reduces the time taken for training. Code is available at the repository: \url{https://github.com/vineeths96/Heterogeneous-Systems}.
System Identification with Time-Aware Neural Sequence Models
Nov 21, 2019
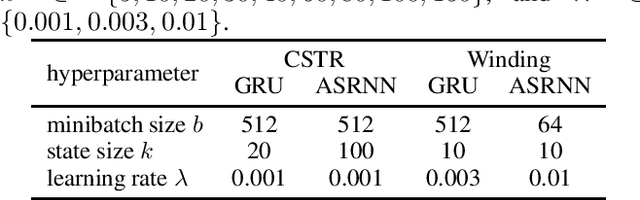
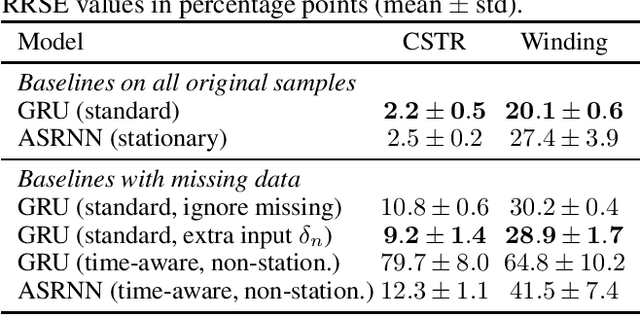
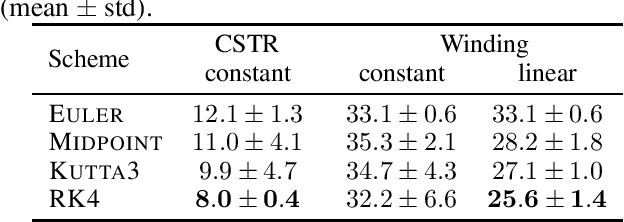
Established recurrent neural networks are well-suited to solve a wide variety of prediction tasks involving discrete sequences. However, they do not perform as well in the task of dynamical system identification, when dealing with observations from continuous variables that are unevenly sampled in time, for example due to missing observations. We show how such neural sequence models can be adapted to deal with variable step sizes in a natural way. In particular, we introduce a time-aware and stationary extension of existing models (including the Gated Recurrent Unit) that allows them to deal with unevenly sampled system observations by adapting to the observation times, while facilitating higher-order temporal behavior. We discuss the properties and demonstrate the validity of the proposed approach, based on samples from two industrial input/output processes.
Adaptive exponential power distribution with moving estimator for nonstationary time series
Mar 23, 2020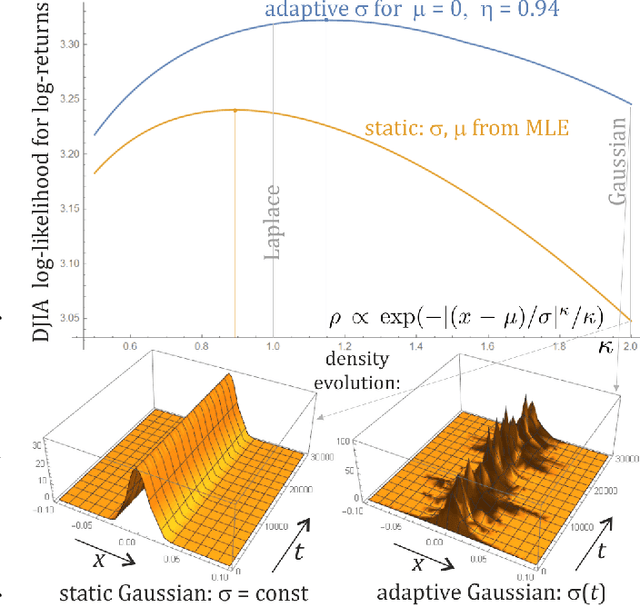
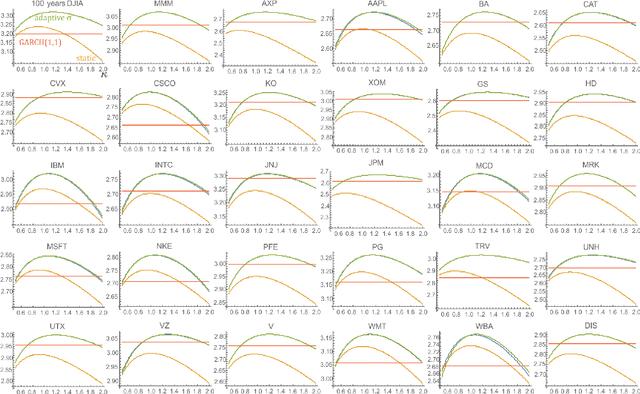
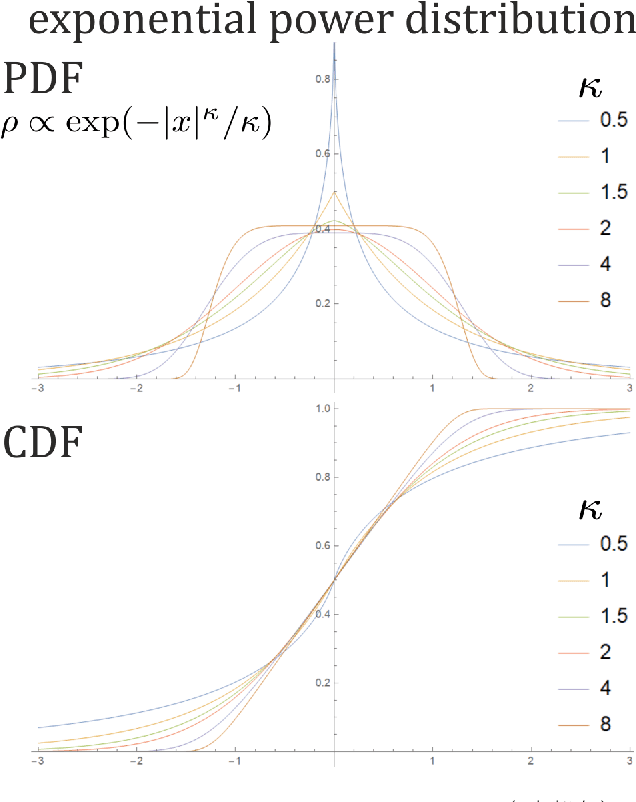
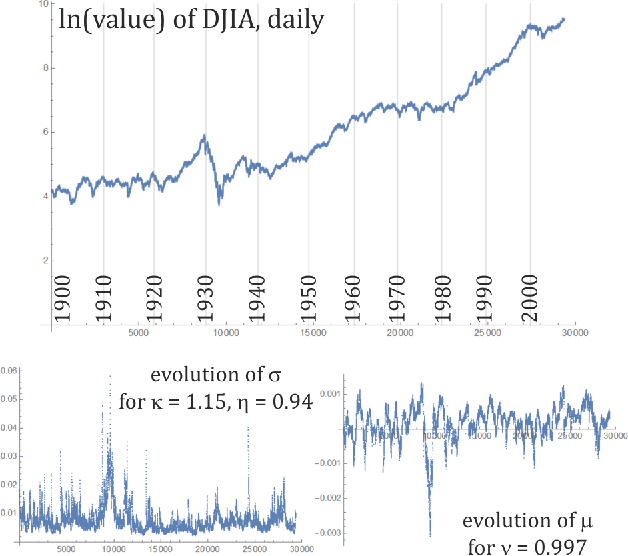
While standard estimation assumes that all datapoints are from probability distribution of the same fixed parameters $\theta$, we will focus on maximum likelihood (ML) adaptive estimation for nonstationary time series: separately estimating parameters $\theta_T$ for each time $T$ based on the earlier values $(x_t)_{t<T}$ using (exponential) moving ML estimator $\theta_T=\arg\max_\theta l_T$ for $l_T=\sum_{t<T} \eta^{T-t} \ln(\rho_\theta (x_t))$ and some $\eta\in(0,1]$. Computational cost of such moving estimator is generally much higher as we need to optimize log-likelihood multiple times, however, in many cases it can be made inexpensive thanks to dependencies. We focus on such example: $\rho(x)\propto \exp(-|(x-\mu)/\sigma|^\kappa/\kappa)$ exponential power distribution (EPD) family, which covers wide range of tail behavior like Gaussian ($\kappa=2$) or Laplace ($\kappa=1$) distribution. It is also convenient for such adaptive estimation of scale parameter $\sigma$ as its standard ML estimation is $\sigma^\kappa$ being average $\|x-\mu\|^\kappa$. By just replacing average with exponential moving average: $(\sigma_{T+1})^\kappa=\eta(\sigma_T)^\kappa +(1-\eta)|x_T-\mu|^\kappa$ we can inexpensively make it adaptive. It is tested on daily log-return series for DJIA companies, leading to essentially better log-likelihoods than standard (static) estimation, with optimal $\kappa$ tails types varying between companies. Presented general alternative estimation philosophy provides tools which might be useful for building better models for analysis of nonstationary time-series.
Cross-domain Single-channel Speech Enhancement Model with Bi-projection Fusion Module for Noise-robust ASR
Aug 26, 2021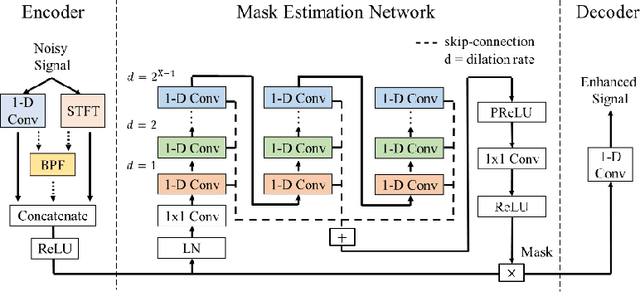
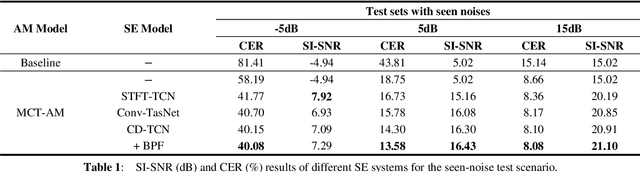
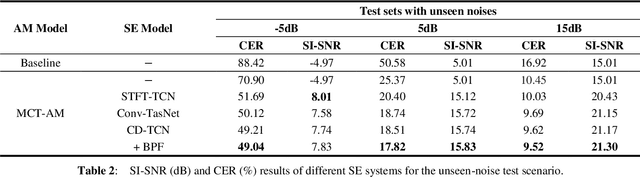
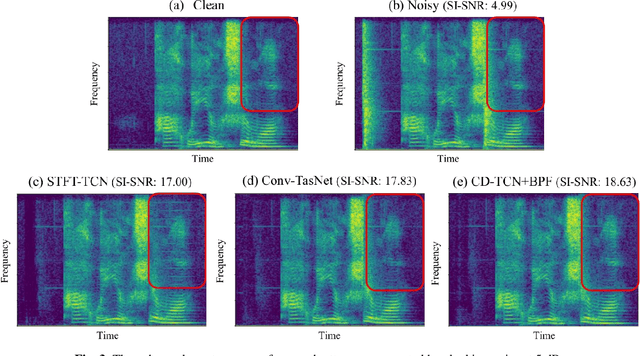
In recent decades, many studies have suggested that phase information is crucial for speech enhancement (SE), and time-domain single-channel speech enhancement techniques have shown promise in noise suppression and robust automatic speech recognition (ASR). This paper presents a continuation of the above lines of research and explores two effective SE methods that consider phase information in time domain and frequency domain of speech signals, respectively. Going one step further, we put forward a novel cross-domain speech enhancement model and a bi-projection fusion (BPF) mechanism for noise-robust ASR. To evaluate the effectiveness of our proposed method, we conduct an extensive set of experiments on the publicly-available Aishell-1 Mandarin benchmark speech corpus. The evaluation results confirm the superiority of our proposed method in relation to a few current top-of-the-line time-domain and frequency-domain SE methods in both enhancement and ASR evaluation metrics for the test set of scenarios contaminated with seen and unseen noise, respectively.
A Reinforcement Learning-based Adaptive Control Model for Future Street Planning, An Algorithm and A Case Study
Dec 10, 2021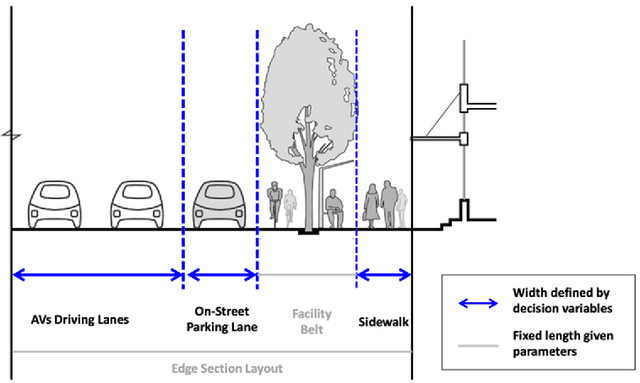
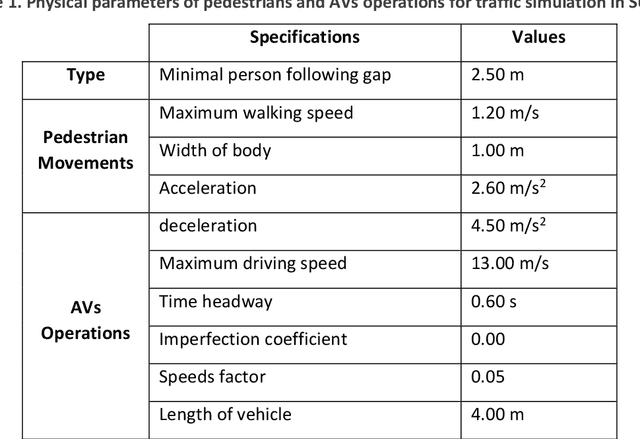
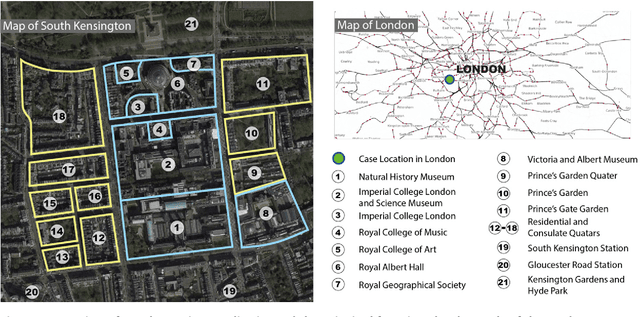
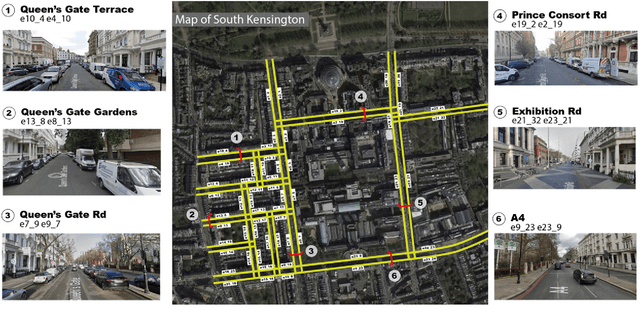
With the emerging technologies in Intelligent Transportation System (ITS), the adaptive operation of road space is likely to be realised within decades. An intelligent street can learn and improve its decision-making on the right-of-way (ROW) for road users, liberating more active pedestrian space while maintaining traffic safety and efficiency. However, there is a lack of effective controlling techniques for these adaptive street infrastructures. To fill this gap in existing studies, we formulate this control problem as a Markov Game and develop a solution based on the multi-agent Deep Deterministic Policy Gradient (MADDPG) algorithm. The proposed model can dynamically assign ROW for sidewalks, autonomous vehicles (AVs) driving lanes and on-street parking areas in real-time. Integrated with the SUMO traffic simulator, this model was evaluated using the road network of the South Kensington District against three cases of divergent traffic conditions: pedestrian flow rates, AVs traffic flow rates and parking demands. Results reveal that our model can achieve an average reduction of 3.87% and 6.26% in street space assigned for on-street parking and vehicular operations. Combined with space gained by limiting the number of driving lanes, the average proportion of sidewalks to total widths of streets can significantly increase by 10.13%.