 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Unsupervised Domain-Specific Deblurring using Scale-Specific Attention
Dec 12, 2021

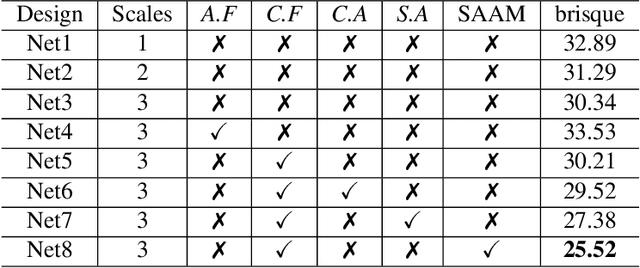
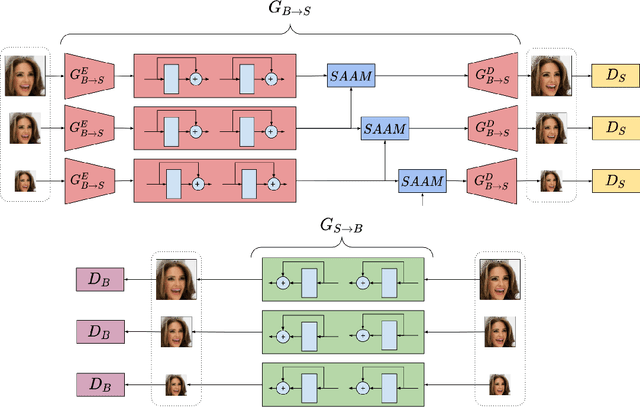
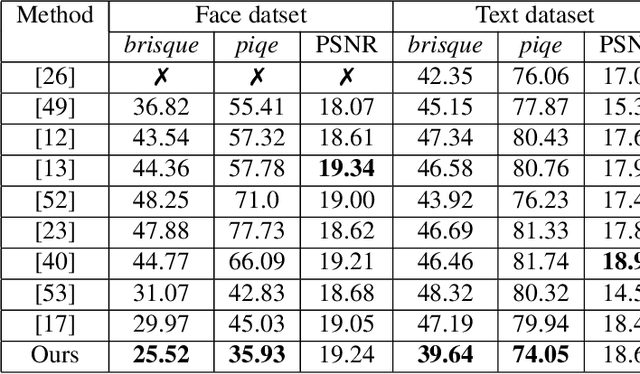
In the literature, coarse-to-fine or scale-recurrent approach i.e. progressively restoring a clean image from its low-resolution versions has been successfully employed for single image deblurring. However, a major disadvantage of existing methods is the need for paired data; i.e. sharpblur image pairs of the same scene, which is a complicated and cumbersome acquisition procedure. Additionally, due to strong supervision on loss functions, pre-trained models of such networks are strongly biased towards the blur experienced during training and tend to give sub-optimal performance when confronted by new blur kernels during inference time. To address the above issues, we propose unsupervised domain-specific deblurring using a scale-adaptive attention module (SAAM). Our network does not require supervised pairs for training, and the deblurring mechanism is primarily guided by adversarial loss, thus making our network suitable for a distribution of blur functions. Given a blurred input image, different resolutions of the same image are used in our model during training and SAAM allows for effective flow of information across the resolutions. For network training at a specific scale, SAAM attends to lower scale features as a function of the current scale. Different ablation studies show that our coarse-to-fine mechanism outperforms end-to-end unsupervised models and SAAM is able to attend better compared to attention models used in literature. Qualitative and quantitative comparisons (on no-reference metrics) show that our method outperforms prior unsupervised methods.
Deep learning of dynamical attractors from time series measurements
Feb 14, 2020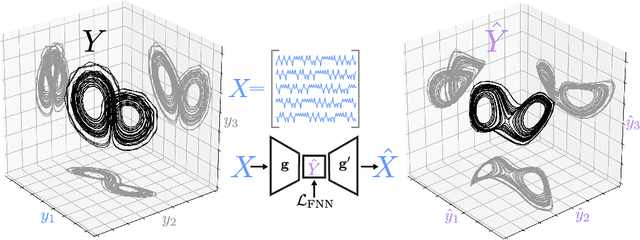
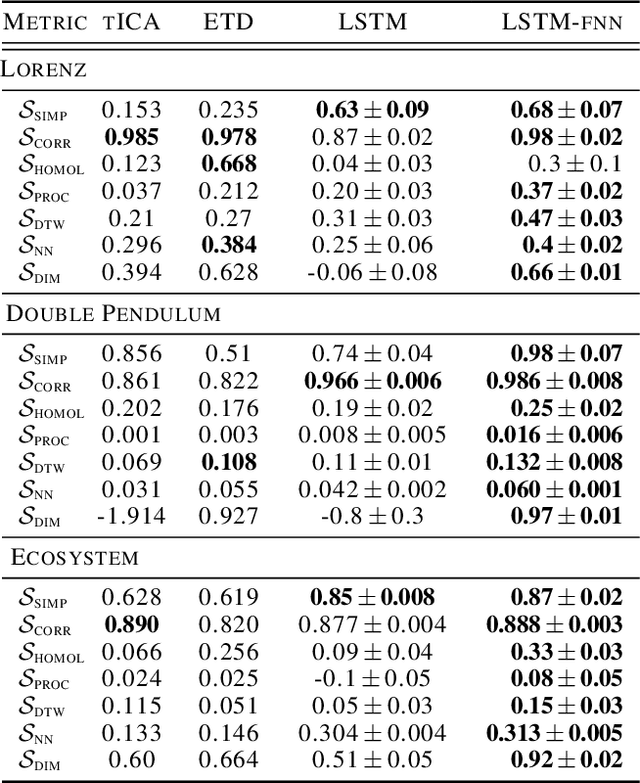
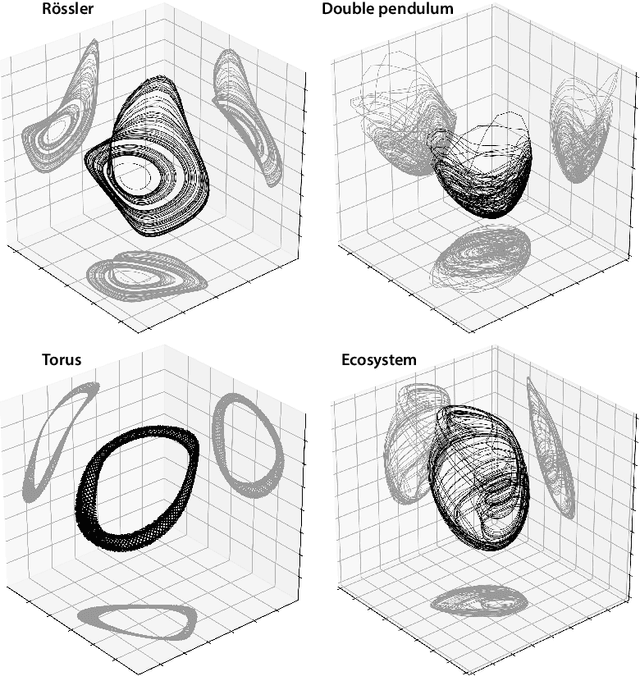
Experimental measurements of physical systems often have a finite number of independent channels, causing essential dynamical variables to remain unobserved. However, many popular methods for unsupervised inference of latent dynamics from experimental data implicitly assume that the measurements have higher intrinsic dimensionality than the underlying system---making coordinate identification a dimensionality reduction problem. Here, we study the opposite limit, in which hidden governing coordinates must be inferred from only a low-dimensional time series of measurements. Inspired by classical techniques for studying the strange attractors of chaotic systems, we introduce a general embedding technique for time series, consisting of an autoencoder trained with a novel latent-space loss function. We first apply our technique to a variety of synthetic and real-world datasets with known strange attractors, and we use established and novel measures of attractor fidelity to show that our method successfully reconstructs attractors better than existing techniques. We then use our technique to discover dynamical attractors in datasets ranging from patient electrocardiograms, to household electricity usage, to eruptions of the Old Faithful geyser---demonstrating diverse applications of our technique for exploratory data analysis.
Expanding the Design Space for Electrically-Driven Soft Robots through Handed Shearing Auxetics
Oct 01, 2021Handed Shearing Auxetics (HSA) are a promising structure for making electrically driven robots with distributed compliance that convert a motors rotation and torque into extension and force. We overcame past limitations on the range of actuation, blocked force, and stiffness by focusing on two key design parameters: the point of an HSA's auxetic trajectory that is energetically preferred, and the number of cells along the HSAs length. Modeling the HSA as a programmable spring, we characterize the effect of both on blocked force, minimum energy length, spring constant, angle range and holding torque. We also examined the effect viscoelasticity has on actuation forces over time. By varying the auxetic trajectory point, we were able to make actuators that can push, pull, or do both. We expanded the range of forces possible from 5N to 150N, and the range of stiffness from 2 N/mm to 89 N/mm. For a fixed point on the auxetic trajectory, we found decreasing length can improve force output, at the expense of needing higher torques, and having a shorter throw. We also found that the viscoelastic effects can limit the amount of force a 3D printed HSA can apply over time.
F3S: Free Flow Fever Screening
Sep 03, 2021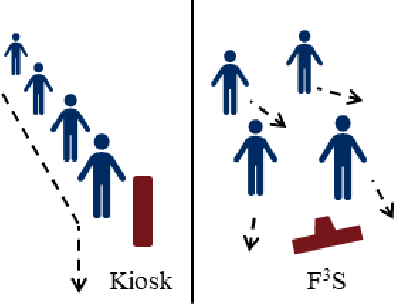
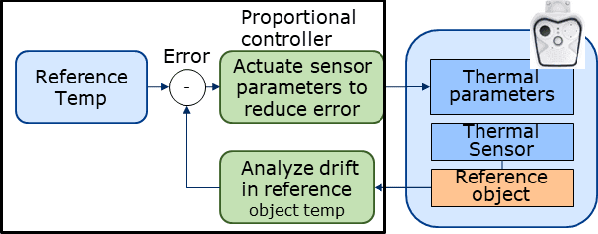
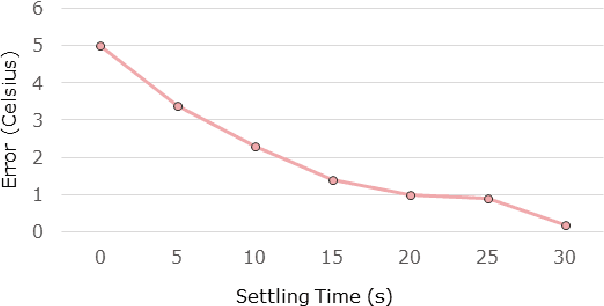
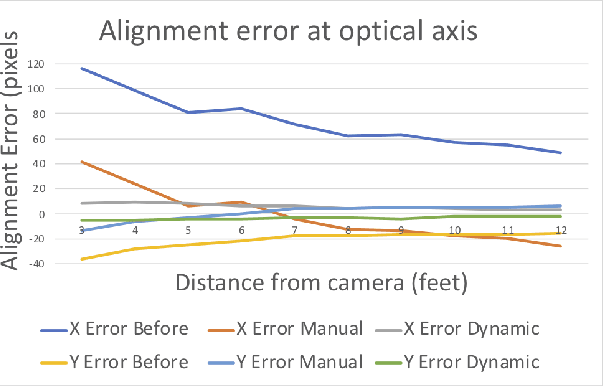
Identification of people with elevated body temperature can reduce or dramatically slow down the spread of infectious diseases like COVID-19. We present a novel fever-screening system, F3S, that uses edge machine learning techniques to accurately measure core body temperatures of multiple individuals in a free-flow setting. F3S performs real-time sensor fusion of visual camera with thermal camera data streams to detect elevated body temperature, and it has several unique features: (a) visual and thermal streams represent very different modalities, and we dynamically associate semantically-equivalent regions across visual and thermal frames by using a new, dynamic alignment technique that analyzes content and context in real-time, (b) we track people through occlusions, identify the eye (inner canthus), forehead, face and head regions where possible, and provide an accurate temperature reading by using a prioritized refinement algorithm, and (c) we robustly detect elevated body temperature even in the presence of personal protective equipment like masks, or sunglasses or hats, all of which can be affected by hot weather and lead to spurious temperature readings. F3S has been deployed at over a dozen large commercial establishments, providing contact-less, free-flow, real-time fever screening for thousands of employees and customers in indoors and outdoor settings.
Real-Time Camera Pose Estimation for Sports Fields
Mar 31, 2020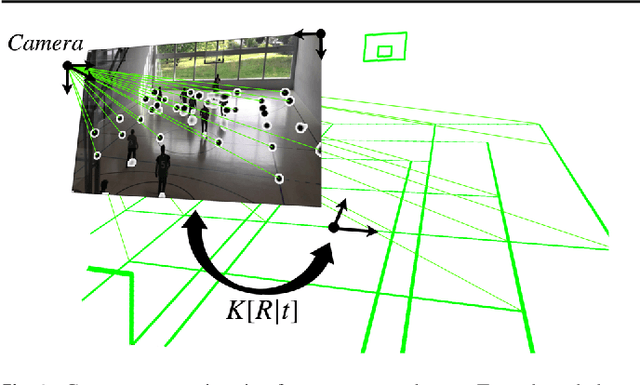
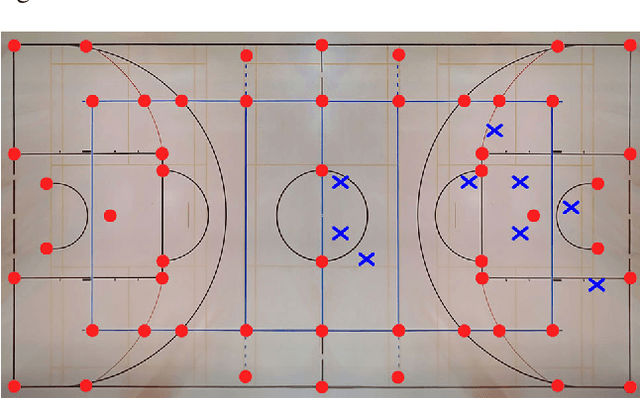
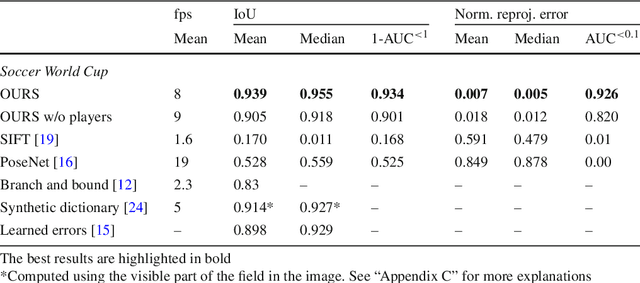
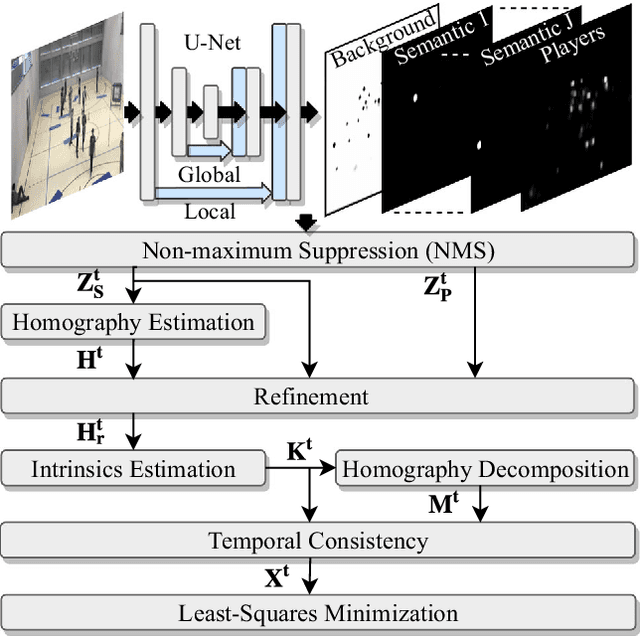
Given an image sequence featuring a portion of a sports field filmed by a moving and uncalibrated camera, such as the one of the smartphones, our goal is to compute automatically in real time the focal length and extrinsic camera parameters for each image in the sequence without using a priori knowledges of the position and orientation of the camera. To this end, we propose a novel framework that combines accurate localization and robust identification of specific keypoints in the image by using a fully convolutional deep architecture. Our algorithm exploits both the field lines and the players' image locations, assuming their ground plane positions to be given, to achieve accuracy and robustness that is beyond the current state of the art. We will demonstrate its effectiveness on challenging soccer, basketball, and volleyball benchmark datasets.
MOI-Mixer: Improving MLP-Mixer with Multi Order Interactions in Sequential Recommendation
Aug 17, 2021
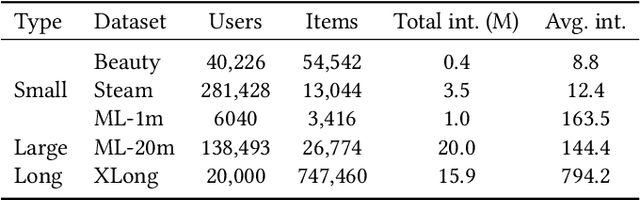
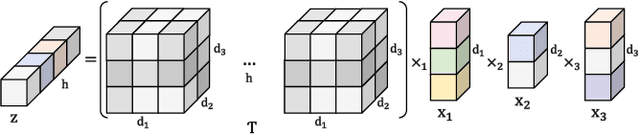
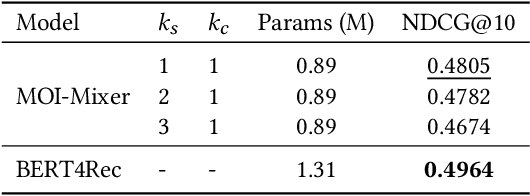
Successful sequential recommendation systems rely on accurately capturing the user's short-term and long-term interest. Although Transformer-based models achieved state-of-the-art performance in the sequential recommendation task, they generally require quadratic memory and time complexity to the sequence length, making it difficult to extract the long-term interest of users. On the other hand, Multi-Layer Perceptrons (MLP)-based models, renowned for their linear memory and time complexity, have recently shown competitive results compared to Transformer in various tasks. Given the availability of a massive amount of the user's behavior history, the linear memory and time complexity of MLP-based models make them a promising alternative to explore in the sequential recommendation task. To this end, we adopted MLP-based models in sequential recommendation but consistently observed that MLP-based methods obtain lower performance than those of Transformer despite their computational benefits. From experiments, we observed that introducing explicit high-order interactions to MLP layers mitigates such performance gap. In response, we propose the Multi-Order Interaction (MOI) layer, which is capable of expressing an arbitrary order of interactions within the inputs while maintaining the memory and time complexity of the MLP layer. By replacing the MLP layer with the MOI layer, our model was able to achieve comparable performance with Transformer-based models while retaining the MLP-based models' computational benefits.
Learning Discrete Representations via Constrained Clustering for Effective and Efficient Dense Retrieval
Oct 12, 2021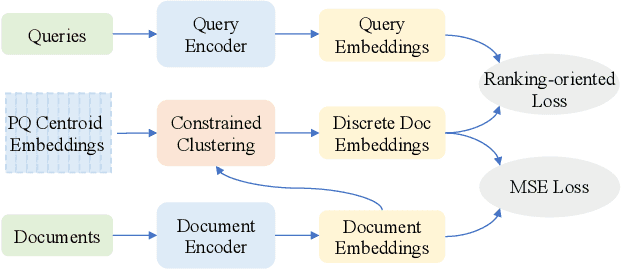
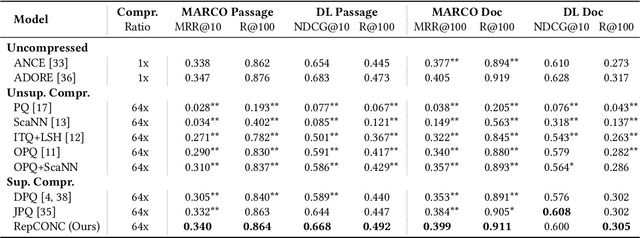
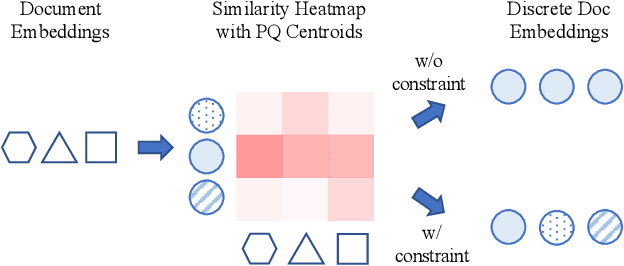
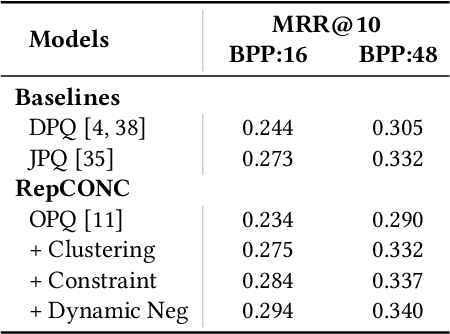
Dense Retrieval (DR) has achieved state-of-the-art first-stage ranking effectiveness. However, the efficiency of most existing DR models is limited by the large memory cost of storing dense vectors and the time-consuming nearest neighbor search (NNS) in vector space. Therefore, we present RepCONC, a novel retrieval model that learns discrete Representations via CONstrained Clustering. RepCONC jointly trains dual-encoders and the Product Quantization (PQ) method to learn discrete document representations and enables fast approximate NNS with compact indexes. It models quantization as a constrained clustering process, which requires the document embeddings to be uniformly clustered around the quantization centroids and supports end-to-end optimization of the quantization method and dual-encoders. We theoretically demonstrate the importance of the uniform clustering constraint in RepCONC and derive an efficient approximate solution for constrained clustering by reducing it to an instance of the optimal transport problem. Besides constrained clustering, RepCONC further adopts a vector-based inverted file system (IVF) to support highly efficient vector search on CPUs. Extensive experiments on two popular ad-hoc retrieval benchmarks show that RepCONC achieves better ranking effectiveness than competitive vector quantization baselines under different compression ratio settings. It also substantially outperforms a wide range of existing retrieval models in terms of retrieval effectiveness, memory efficiency, and time efficiency.
Diverse Generation from a Single Video Made Possible
Sep 17, 2021

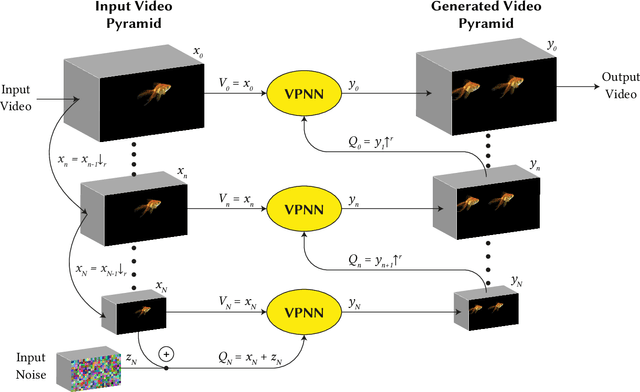
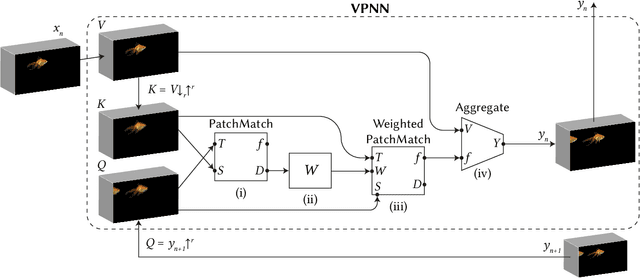
Most advanced video generation and manipulation methods train on a large collection of videos. As such, they are restricted to the types of video dynamics they train on. To overcome this limitation, GANs trained on a single video were recently proposed. While these provide more flexibility to a wide variety of video dynamics, they require days to train on a single tiny input video, rendering them impractical. In this paper we present a fast and practical method for video generation and manipulation from a single natural video, which generates diverse high-quality video outputs within seconds (for benchmark videos). Our method can be further applied to Full-HD video clips within minutes. Our approach is inspired by a recent advanced patch-nearest-neighbor based approach [Granot et al. 2021], which was shown to significantly outperform single-image GANs, both in run-time and in visual quality. Here we generalize this approach from images to videos, by casting classical space-time patch-based methods as a new generative video model. We adapt the generative image patch nearest neighbor approach to efficiently cope with the huge number of space-time patches in a single video. Our method generates more realistic and higher quality results than single-video GANs (confirmed by quantitative and qualitative evaluations). Moreover, it is disproportionally faster (runtime reduced from several days to seconds). Other than diverse video generation, we demonstrate several other challenging video applications, including spatio-temporal video retargeting, video structural analogies and conditional video-inpainting.
Reinforcement Learning based Sequential Batch-sampling for Bayesian Optimal Experimental Design
Dec 23, 2021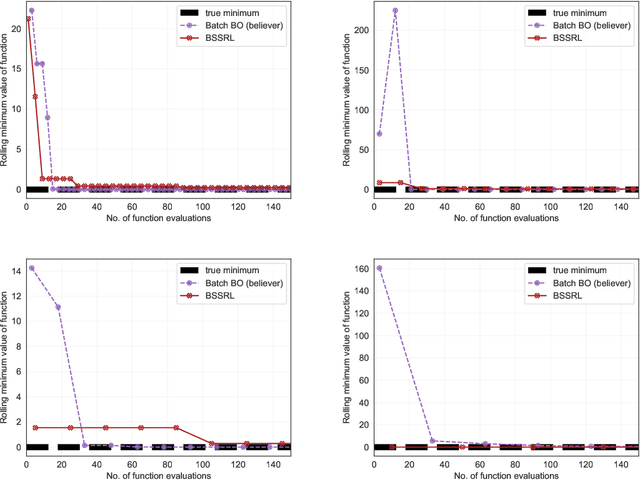
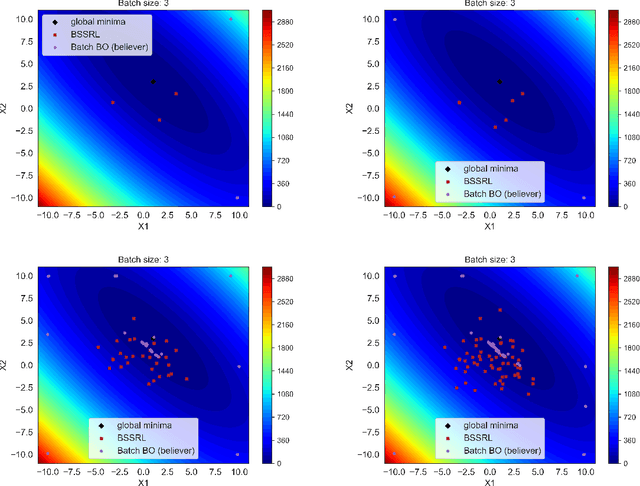
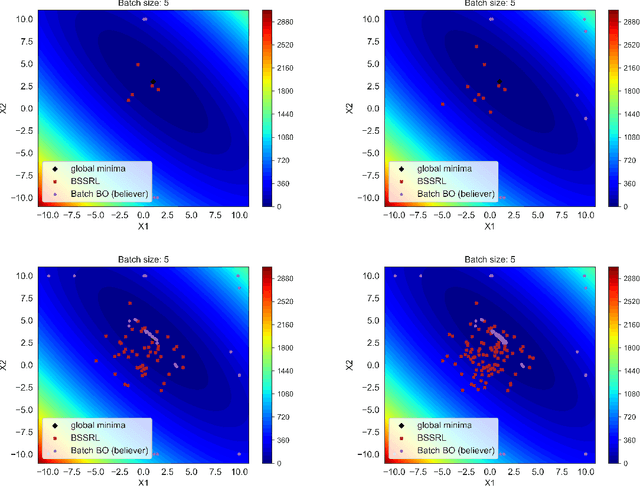
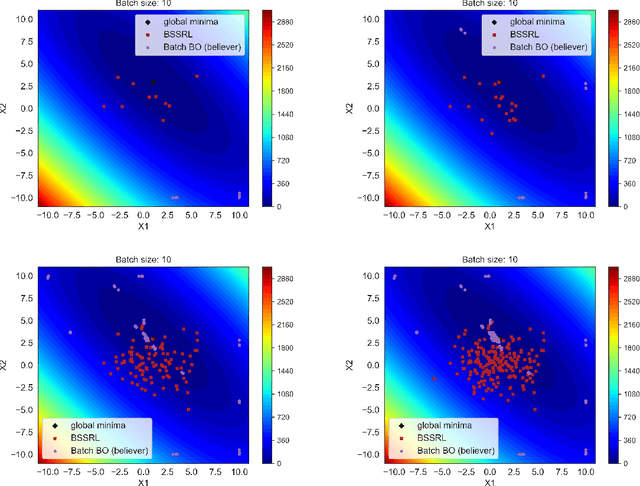
Engineering problems that are modeled using sophisticated mathematical methods or are characterized by expensive-to-conduct tests or experiments, are encumbered with limited budget or finite computational resources. Moreover, practical scenarios in the industry, impose restrictions, based on logistics and preference, on the manner in which the experiments can be conducted. For example, material supply may enable only a handful of experiments in a single-shot or in the case of computational models one may face significant wait-time based on shared computational resources. In such scenarios, one usually resorts to performing experiments in a manner that allows for maximizing one's state-of-knowledge while satisfying the above mentioned practical constraints. Sequential design of experiments (SDOE) is a popular suite of methods, that has yielded promising results in recent years across different engineering and practical problems. A common strategy, that leverages Bayesian formalism is the Bayesian SDOE, which usually works best in the one-step-ahead or myopic scenario of selecting a single experiment at each step of a sequence of experiments. In this work, we aim to extend the SDOE strategy, to query the experiment or computer code at a batch of inputs. To this end, we leverage deep reinforcement learning (RL) based policy gradient methods, to propose batches of queries that are selected taking into account entire budget in hand. The algorithm retains the sequential nature, inherent in the SDOE, while incorporating elements of reward based on task from the domain of deep RL. A unique capability of the proposed methodology is its ability to be applied to multiple tasks, for example optimization of a function, once its trained. We demonstrate the performance of the proposed algorithm on a synthetic problem, and a challenging high-dimensional engineering problem.
Knowledge Graph Embedding in E-commerce Applications: Attentive Reasoning, Explanations, and Transferable Rules
Dec 16, 2021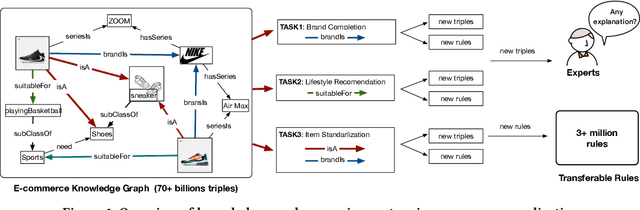
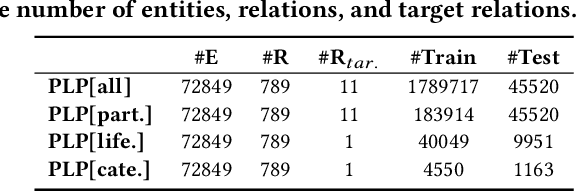
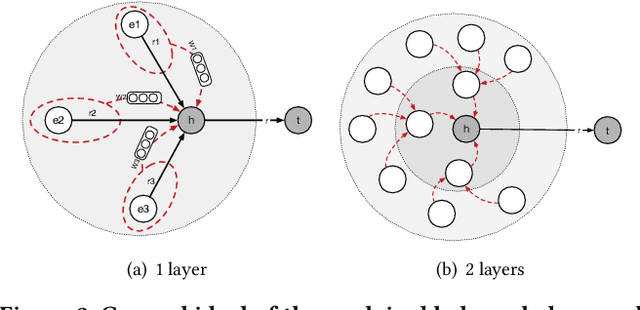
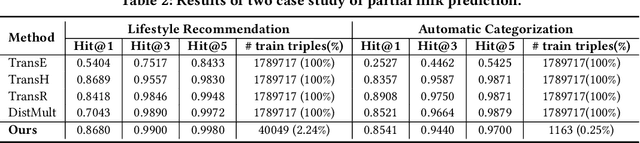
Knowledge Graphs (KGs), representing facts as triples, have been widely adopted in many applications. Reasoning tasks such as link prediction and rule induction are important for the development of KGs. Knowledge Graph Embeddings (KGEs) embedding entities and relations of a KG into continuous vector spaces, have been proposed for these reasoning tasks and proven to be efficient and robust. But the plausibility and feasibility of applying and deploying KGEs in real-work applications has not been well-explored. In this paper, we discuss and report our experiences of deploying KGEs in a real domain application: e-commerce. We first identity three important desiderata for e-commerce KG systems: 1) attentive reasoning, reasoning over a few target relations of more concerns instead of all; 2) explanation, providing explanations for a prediction to help both users and business operators understand why the prediction is made; 3) transferable rules, generating reusable rules to accelerate the deployment of a KG to new systems. While non existing KGE could meet all these desiderata, we propose a novel one, an explainable knowledge graph attention network that make prediction through modeling correlations between triples rather than purely relying on its head entity, relation and tail entity embeddings. It could automatically selects attentive triples for prediction and records the contribution of them at the same time, from which explanations could be easily provided and transferable rules could be efficiently produced. We empirically show that our method is capable of meeting all three desiderata in our e-commerce application and outperform typical baselines on datasets from real domain applications.