 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Throughput Maximization for IRS-Aided MIMO FD-WPCN with Non-Linear EH Model
Dec 17, 2021
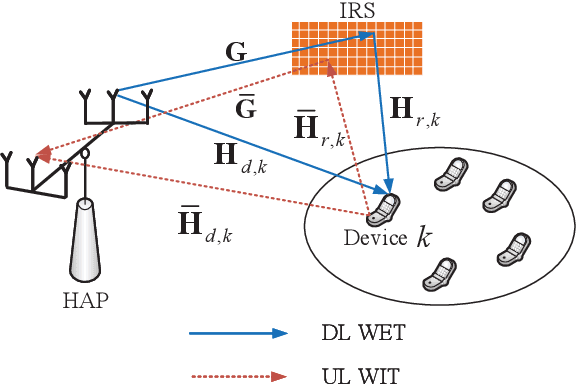
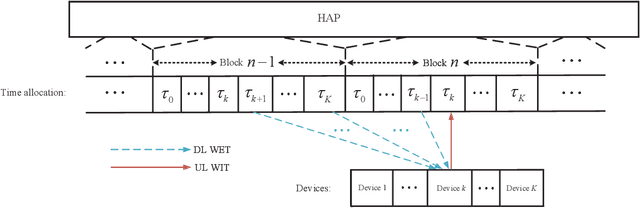
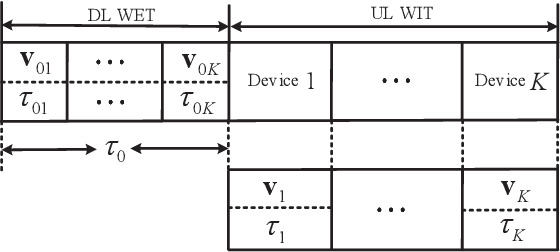
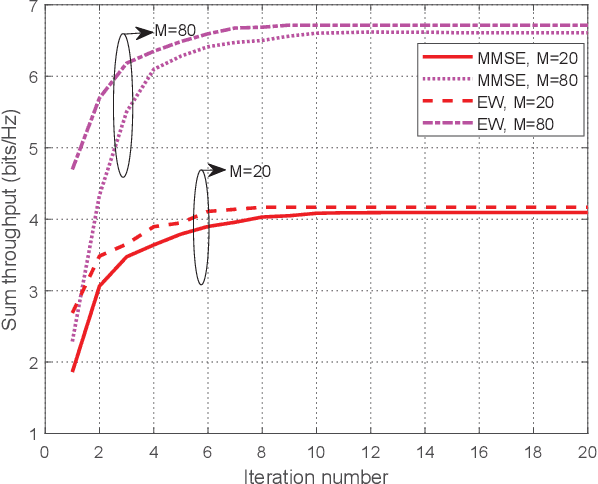
This paper studies an intelligent reflecting surface (IRS)-aided multiple-input-multiple-output (MIMO) full-duplex (FD) wireless-powered communication network (WPCN), where a hybrid access point (HAP) operating in FD broadcasts energy signals to multiple devices for their energy harvesting (EH) in the downlink (DL) and meanwhile receives information signals from devices in the uplink (UL) with the help of an IRS. Taking into account the practical finite self-interference (SI) and the non-linear EH model, we formulate the weighted sum throughput maximization optimization problem by jointly optimizing DL/UL time allocation, precoding matrices at devices, transmit covariance matrices at the HAP, and phase shifts at the IRS. Since the resulting optimization problem is non-convex, there are no standard methods to solve it optimally in general. To tackle this challenge, we first propose an element-wise (EW) based algorithm, where each IRS phase shift is alternately optimized in an iterative manner. To reduce the computational complexity, a minimum mean-square error (MMSE) based algorithm is proposed, where we transform the original problem into an equivalent form based on the MMSE method, which facilities the design of an efficient iterative algorithm. In particular, the IRS phase shift optimization problem is recast as an second-order cone program (SOCP), where all the IRS phase shifts are simultaneously optimized. For comparison, we also study two suboptimal IRS beamforming configurations in simulations, namely partially dynamic IRS beamforming (PDBF) and static IRS beamforming (SBF), which strike a balance between the system performance and practical complexity.
Monocular Human Shape and Pose with Dense Mesh-borne Local Image Features
Nov 11, 2021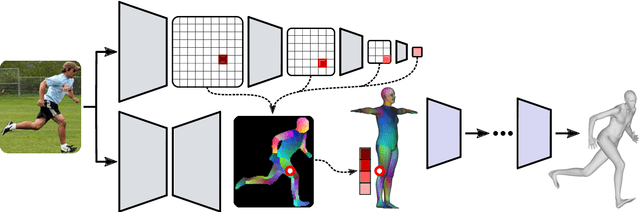

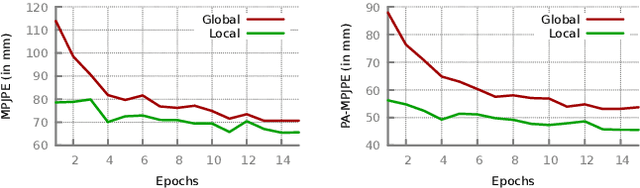
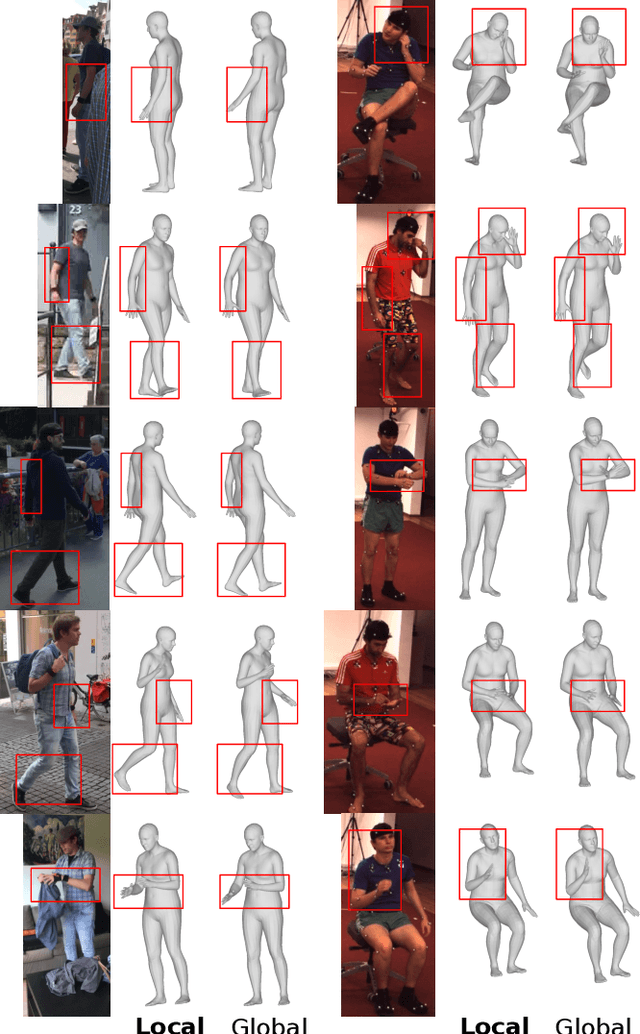
We propose to improve on graph convolution based approaches for human shape and pose estimation from monocular input, using pixel-aligned local image features. Given a single input color image, existing graph convolutional network (GCN) based techniques for human shape and pose estimation use a single convolutional neural network (CNN) generated global image feature appended to all mesh vertices equally to initialize the GCN stage, which transforms a template T-posed mesh into the target pose. In contrast, we propose for the first time the idea of using local image features per vertex. These features are sampled from the CNN image feature maps by utilizing pixel-to-mesh correspondences generated with DensePose. Our quantitative and qualitative results on standard benchmarks show that using local features improves on global ones and leads to competitive performances with respect to the state-of-the-art.
Detecting Audio Adversarial Examples with Logit Noising
Dec 13, 2021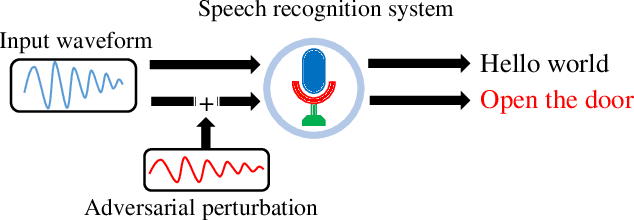


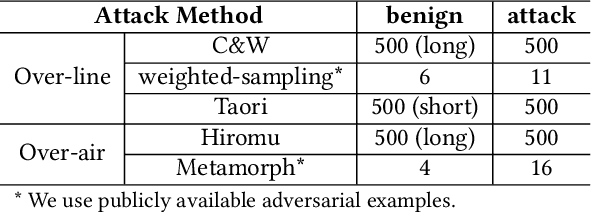
Automatic speech recognition (ASR) systems are vulnerable to audio adversarial examples that attempt to deceive ASR systems by adding perturbations to benign speech signals. Although an adversarial example and the original benign wave are indistinguishable to humans, the former is transcribed as a malicious target sentence by ASR systems. Several methods have been proposed to generate audio adversarial examples and feed them directly into the ASR system (over-line). Furthermore, many researchers have demonstrated the feasibility of robust physical audio adversarial examples(over-air). To defend against the attacks, several studies have been proposed. However, deploying them in a real-world situation is difficult because of accuracy drop or time overhead. In this paper, we propose a novel method to detect audio adversarial examples by adding noise to the logits before feeding them into the decoder of the ASR. We show that carefully selected noise can significantly impact the transcription results of the audio adversarial examples, whereas it has minimal impact on the transcription results of benign audio waves. Based on this characteristic, we detect audio adversarial examples by comparing the transcription altered by logit noising with its original transcription. The proposed method can be easily applied to ASR systems without any structural changes or additional training. The experimental results show that the proposed method is robust to over-line audio adversarial examples as well as over-air audio adversarial examples compared with state-of-the-art detection methods.
Self-supervised Monocular Depth Estimation for All Day Images using Domain Separation
Aug 17, 2021
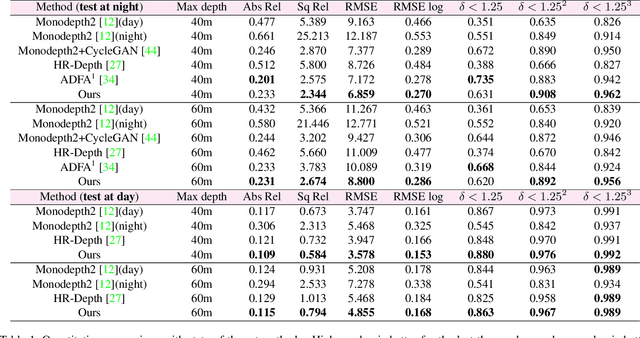
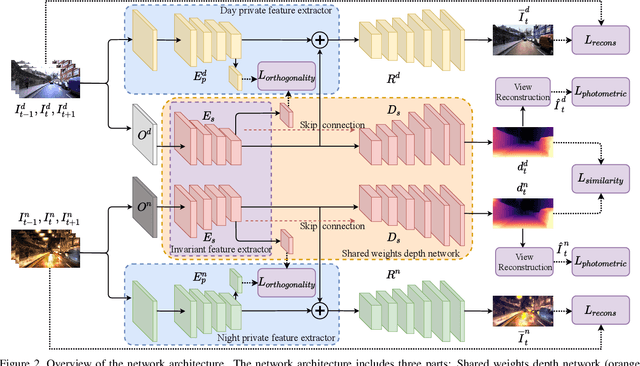
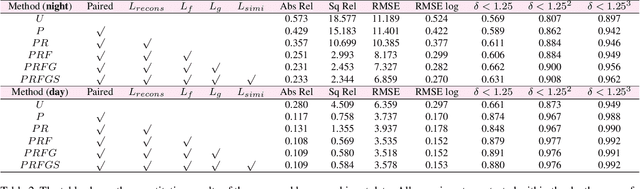
Remarkable results have been achieved by DCNN based self-supervised depth estimation approaches. However, most of these approaches can only handle either day-time or night-time images, while their performance degrades for all-day images due to large domain shift and the variation of illumination between day and night images. To relieve these limitations, we propose a domain-separated network for self-supervised depth estimation of all-day images. Specifically, to relieve the negative influence of disturbing terms (illumination, etc.), we partition the information of day and night image pairs into two complementary sub-spaces: private and invariant domains, where the former contains the unique information (illumination, etc.) of day and night images and the latter contains essential shared information (texture, etc.). Meanwhile, to guarantee that the day and night images contain the same information, the domain-separated network takes the day-time images and corresponding night-time images (generated by GAN) as input, and the private and invariant feature extractors are learned by orthogonality and similarity loss, where the domain gap can be alleviated, thus better depth maps can be expected. Meanwhile, the reconstruction and photometric losses are utilized to estimate complementary information and depth maps effectively. Experimental results demonstrate that our approach achieves state-of-the-art depth estimation results for all-day images on the challenging Oxford RobotCar dataset, proving the superiority of our proposed approach.
Embedded Hardware Appropriate Fast 3D Trajectory Optimization for Fixed Wing Aerial Vehicles by Leveraging Hidden Convex Structures
Sep 26, 2021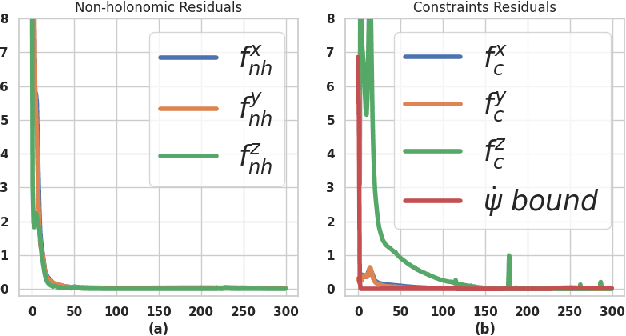
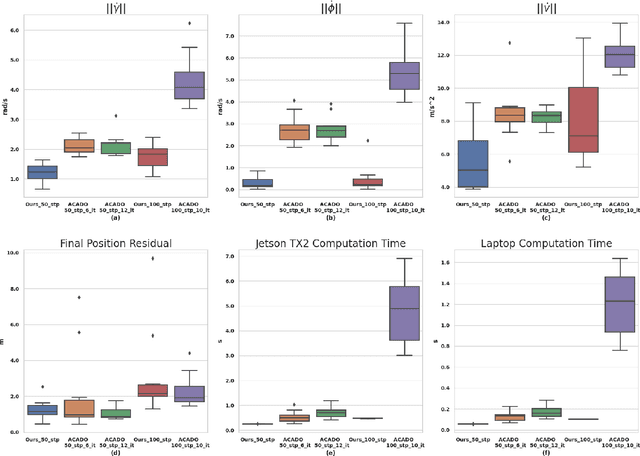
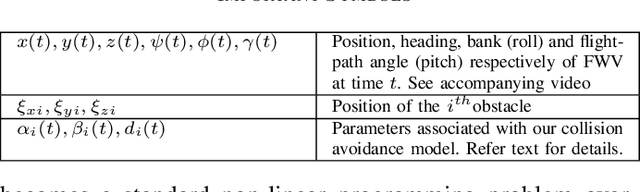
Most commercially available fixed-wing aerial vehicles (FWV) can carry only small, lightweight computing hardware such as Jetson TX2 onboard. Solving non-linear trajectory optimization on these computing resources is computationally challenging even while considering only the kinematic motion model. Most importantly, the computation time increases sharply as the environment becomes more cluttered. In this paper, we take a step towards overcoming this bottleneck and propose a trajectory optimizer that achieves online performance on both conventional laptops/desktops and Jetson TX2 in a typical urban environment setting. Our optimizer builds on the novel insight that the seemingly non-linear trajectory optimization problem for FWV has an implicit multi-convex structure. Our optimizer exploits these computational structures by bringing together diverse concepts from Alternating Minimization, Bregman iteration, and Alternating Direction Method of Multipliers. We show that our optimizer outperforms the state-of-the-art implementation of sequential quadratic programming approach in optimal control solver ACADO in computation time and solution quality measured in terms of control and goal reaching cost.
Fast BATLLNN: Fast Box Analysis of Two-Level Lattice Neural Networks
Nov 17, 2021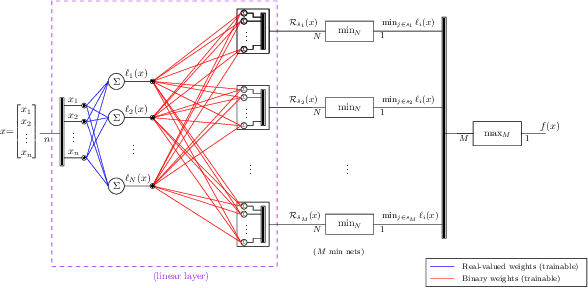
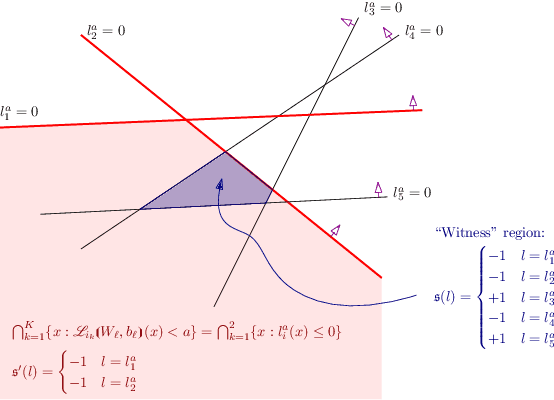
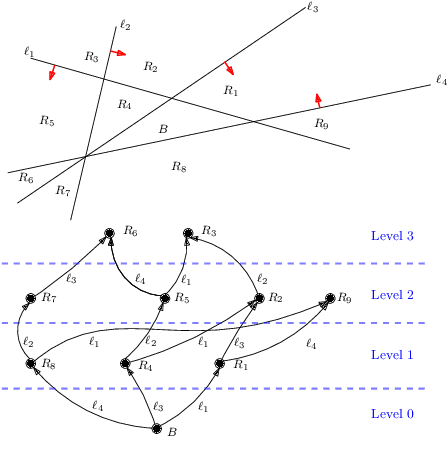
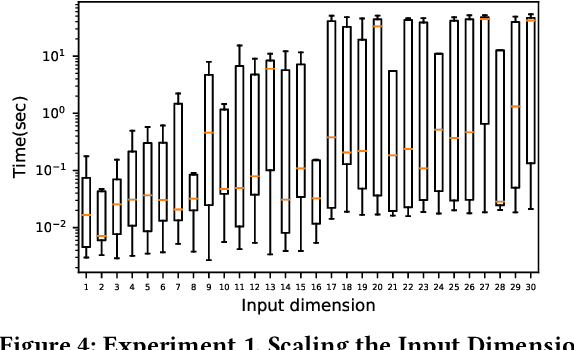
In this paper, we present the tool Fast Box Analysis of Two-Level Lattice Neural Networks (Fast BATLLNN) as a fast verifier of box-like output constraints for Two-Level Lattice (TLL) Neural Networks (NNs). In particular, Fast BATLLNN can verify whether the output of a given TLL NN always lies within a specified hyper-rectangle whenever its input constrained to a specified convex polytope (not necessarily a hyper-rectangle). Fast BATLLNN uses the unique semantics of the TLL architecture and the decoupled nature of box-like output constraints to dramatically improve verification performance relative to known polynomial-time verification algorithms for TLLs with generic polytopic output constraints. In this paper, we evaluate the performance and scalability of Fast BATLLNN, both in its own right and compared to state-of-the-art NN verifiers applied to TLL NNs. Fast BATLLNN compares very favorably to even the fastest NN verifiers, completing our synthetic TLL test bench more than 400x faster than its nearest competitor.
A Kernel to Exploit Informative Missingness in Multivariate Time Series from EHRs
Feb 27, 2020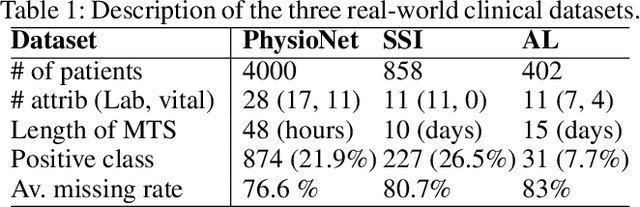
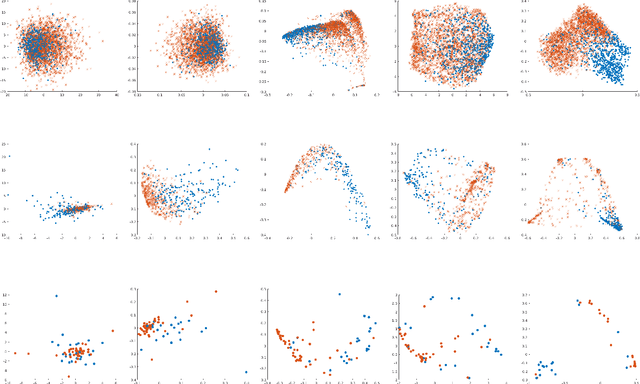
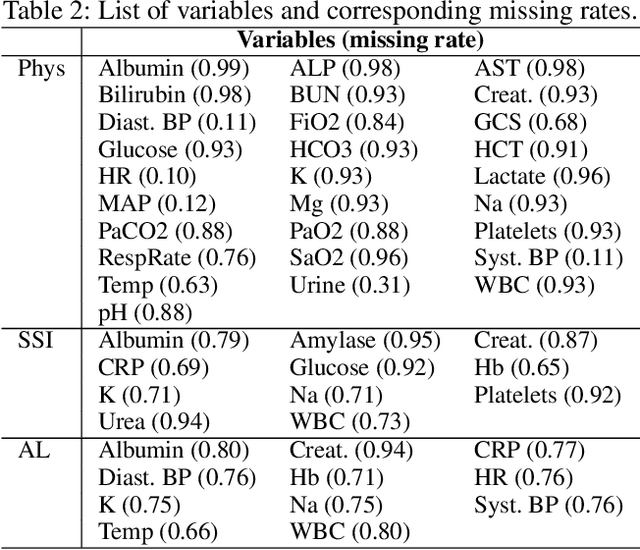
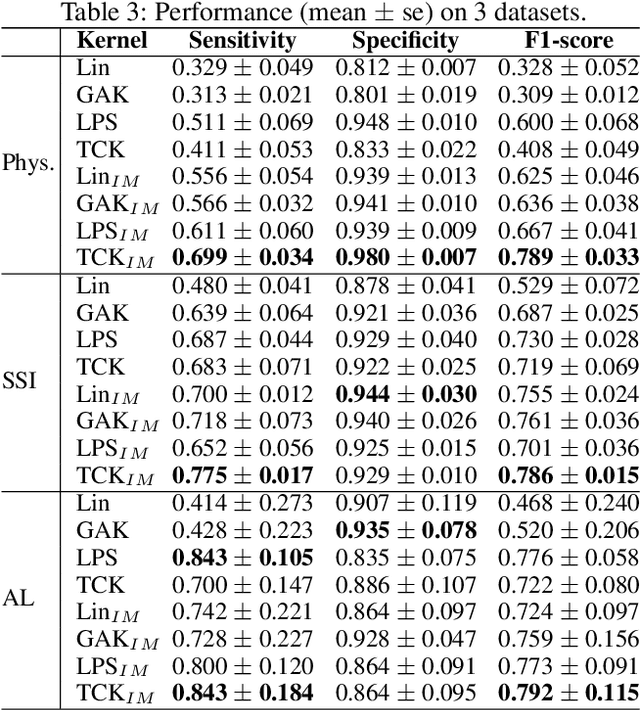
A large fraction of the electronic health records (EHRs) consists of clinical measurements collected over time, such as lab tests and vital signs, which provide important information about a patient's health status. These sequences of clinical measurements are naturally represented as time series, characterized by multiple variables and large amounts of missing data, which complicate the analysis. In this work, we propose a novel kernel which is capable of exploiting both the information from the observed values as well the information hidden in the missing patterns in multivariate time series (MTS) originating e.g. from EHRs. The kernel, called TCK$_{IM}$, is designed using an ensemble learning strategy in which the base models are novel mixed mode Bayesian mixture models which can effectively exploit informative missingness without having to resort to imputation methods. Moreover, the ensemble approach ensures robustness to hyperparameters and therefore TCK$_{IM}$ is particularly well suited if there is a lack of labels - a known challenge in medical applications. Experiments on three real-world clinical datasets demonstrate the effectiveness of the proposed kernel.
MOI-Mixer: Improving MLP-Mixer with Multi Order Interactions in Sequential Recommendation
Aug 17, 2021
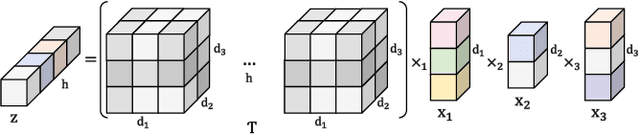
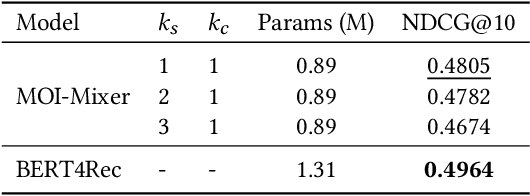
Successful sequential recommendation systems rely on accurately capturing the user's short-term and long-term interest. Although Transformer-based models achieved state-of-the-art performance in the sequential recommendation task, they generally require quadratic memory and time complexity to the sequence length, making it difficult to extract the long-term interest of users. On the other hand, Multi-Layer Perceptrons (MLP)-based models, renowned for their linear memory and time complexity, have recently shown competitive results compared to Transformer in various tasks. Given the availability of a massive amount of the user's behavior history, the linear memory and time complexity of MLP-based models make them a promising alternative to explore in the sequential recommendation task. To this end, we adopted MLP-based models in sequential recommendation but consistently observed that MLP-based methods obtain lower performance than those of Transformer despite their computational benefits. From experiments, we observed that introducing explicit high-order interactions to MLP layers mitigates such performance gap. In response, we propose the Multi-Order Interaction (MOI) layer, which is capable of expressing an arbitrary order of interactions within the inputs while maintaining the memory and time complexity of the MLP layer. By replacing the MLP layer with the MOI layer, our model was able to achieve comparable performance with Transformer-based models while retaining the MLP-based models' computational benefits.
Distributed Hypothesis Testing and Social Learning in Finite Time with a Finite Amount of Communication
Apr 02, 2020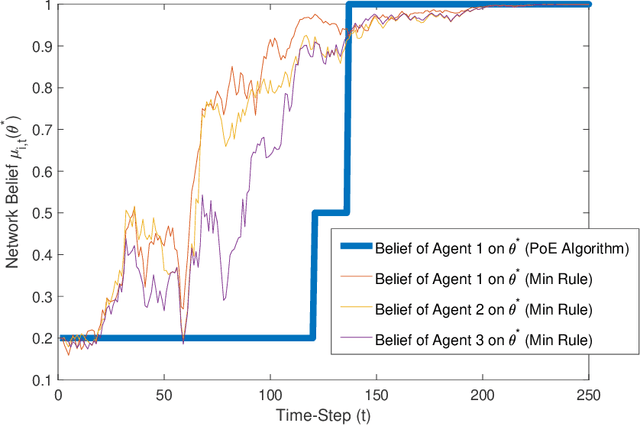
We consider the problem of distributed hypothesis testing (or social learning) where a network of agents seeks to identify the true state of the world from a finite set of hypotheses, based on a series of stochastic signals that each agent receives. Prior work on this problem has provided distributed algorithms that guarantee asymptotic learning of the true state, with corresponding efforts to improve the rate of learning. In this paper, we first argue that one can readily modify existing asymptotic learning algorithms to enable learning in finite time, effectively yielding arbitrarily large (asymptotic) rates. We then provide a simple algorithm for finite-time learning which only requires the agents to exchange a binary vector (of length equal to the number of possible hypotheses) with their neighbors at each time-step. Finally, we show that if the agents know the diameter of the network, our algorithm can be further modified to allow all agents to learn the true state and stop transmitting to their neighbors after a finite number of time-steps.
F3S: Free Flow Fever Screening
Sep 03, 2021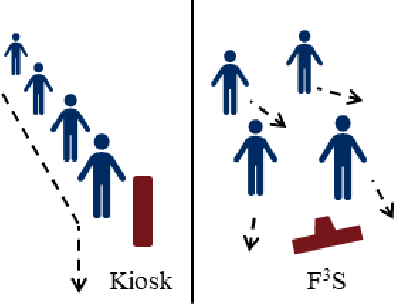
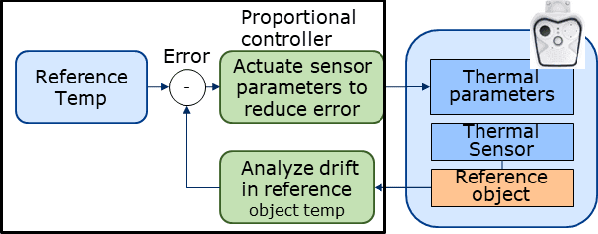
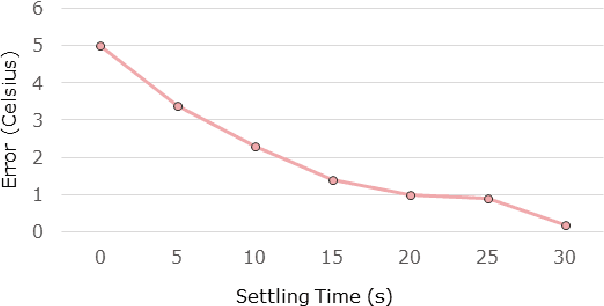
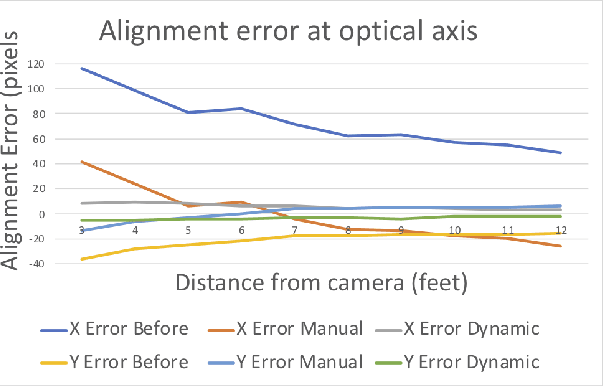
Identification of people with elevated body temperature can reduce or dramatically slow down the spread of infectious diseases like COVID-19. We present a novel fever-screening system, F3S, that uses edge machine learning techniques to accurately measure core body temperatures of multiple individuals in a free-flow setting. F3S performs real-time sensor fusion of visual camera with thermal camera data streams to detect elevated body temperature, and it has several unique features: (a) visual and thermal streams represent very different modalities, and we dynamically associate semantically-equivalent regions across visual and thermal frames by using a new, dynamic alignment technique that analyzes content and context in real-time, (b) we track people through occlusions, identify the eye (inner canthus), forehead, face and head regions where possible, and provide an accurate temperature reading by using a prioritized refinement algorithm, and (c) we robustly detect elevated body temperature even in the presence of personal protective equipment like masks, or sunglasses or hats, all of which can be affected by hot weather and lead to spurious temperature readings. F3S has been deployed at over a dozen large commercial establishments, providing contact-less, free-flow, real-time fever screening for thousands of employees and customers in indoors and outdoor settings.