 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
LetsGo: Large-Scale Garage Modeling and Rendering via LiDAR-Assisted Gaussian Primitives
Apr 15, 2024
Large garages are ubiquitous yet intricate scenes in our daily lives, posing challenges characterized by monotonous colors, repetitive patterns, reflective surfaces, and transparent vehicle glass. Conventional Structure from Motion (SfM) methods for camera pose estimation and 3D reconstruction fail in these environments due to poor correspondence construction. To address these challenges, this paper introduces LetsGo, a LiDAR-assisted Gaussian splatting approach for large-scale garage modeling and rendering. We develop a handheld scanner, Polar, equipped with IMU, LiDAR, and a fisheye camera, to facilitate accurate LiDAR and image data scanning. With this Polar device, we present a GarageWorld dataset consisting of five expansive garage scenes with diverse geometric structures and will release the dataset to the community for further research. We demonstrate that the collected LiDAR point cloud by the Polar device enhances a suite of 3D Gaussian splatting algorithms for garage scene modeling and rendering. We also propose a novel depth regularizer for 3D Gaussian splatting algorithm training, effectively eliminating floating artifacts in rendered images, and a lightweight Level of Detail (LOD) Gaussian renderer for real-time viewing on web-based devices. Additionally, we explore a hybrid representation that combines the advantages of traditional mesh in depicting simple geometry and colors (e.g., walls and the ground) with modern 3D Gaussian representations capturing complex details and high-frequency textures. This strategy achieves an optimal balance between memory performance and rendering quality. Experimental results on our dataset, along with ScanNet++ and KITTI-360, demonstrate the superiority of our method in rendering quality and resource efficiency.
Using Long Short-term Memory (LSTM) to merge precipitation data over mountainous area in Sierra Nevada
Apr 15, 2024Obtaining reliable precipitation estimation with high resolutions in time and space is of great importance to hydrological studies. However, accurately estimating precipitation is a challenging task over high mountainous complex terrain. The three widely used precipitation measurement approaches, namely rainfall gauge, precipitation radars, and satellite-based precipitation sensors, have their own pros and cons in producing reliable precipitation products over complex areas. One way to decrease the detection error probability and improve data reliability is precipitation data merging. With the rapid advancements in computational capabilities and the escalating volume and diversity of earth observational data, Deep Learning (DL) models have gained considerable attention in geoscience. In this study, a deep learning technique, namely Long Short-term Memory (LSTM), was employed to merge a radar-based and a satellite-based Global Precipitation Measurement (GPM) precipitation product Integrated Multi-Satellite Retrievals for GPM (IMERG) precipitation product at hourly scale. The merged results are compared with the widely used reanalysis precipitation product, Multi-Radar Multi-Sensor (MRMS), and assessed against gauge observational data from the California Data Exchange Center (CDEC). The findings indicated that the LSTM-based merged precipitation notably underestimated gauge observations and, at times, failed to provide meaningful estimates, showing predominantly near-zero values. Relying solely on individual Quantitative Precipitation Estimates (QPEs) without additional meteorological input proved insufficient for generating reliable merged QPE. However, the merged results effectively captured the temporal trends of the observations, outperforming MRMS in this aspect. This suggested that incorporating bias correction techniques could potentially enhance the accuracy of the merged product.
Explainable Light-Weight Deep Learning Pipeline for Improved Drought Stres
Apr 15, 2024Early identification of drought stress in crops is vital for implementing effective mitigation measures and reducing yield loss. Non-invasive imaging techniques hold immense potential by capturing subtle physiological changes in plants under water deficit. Sensor based imaging data serves as a rich source of information for machine learning and deep learning algorithms, facilitating further analysis aimed at identifying drought stress. While these approaches yield favorable results, real-time field applications requires algorithms specifically designed for the complexities of natural agricultural conditions. Our work proposes a novel deep learning framework for classifying drought stress in potato crops captured by UAVs in natural settings. The novelty lies in the synergistic combination of a pretrained network with carefully designed custom layers. This architecture leverages feature extraction capabilities of the pre-trained network while the custom layers enable targeted dimensionality reduction and enhanced regularization, ultimately leading to improved performance. A key innovation of our work involves the integration of Gradient-Class Activation Mapping (Grad-CAM), an explainability technique. Grad-CAM sheds light on the internal workings of the deep learning model, typically referred to as a black box. By visualizing the focus areas of the model within the images, Grad-CAM fosters interpretability and builds trust in the decision-making process of the model. Our proposed framework achieves superior performance, particularly with the DenseNet121 pre-trained network, reaching a precision of 98% to identify the stressed class with an overall accuracy of 90%. Comparative analysis of existing state-of-the-art object detection algorithms reveals the superiority of our approach in significantly higher precision and accuracy.
Unifying Global and Local Scene Entities Modelling for Precise Action Spotting
Apr 15, 2024Sports videos pose complex challenges, including cluttered backgrounds, camera angle changes, small action-representing objects, and imbalanced action class distribution. Existing methods for detecting actions in sports videos heavily rely on global features, utilizing a backbone network as a black box that encompasses the entire spatial frame. However, these approaches tend to overlook the nuances of the scene and struggle with detecting actions that occupy a small portion of the frame. In particular, they face difficulties when dealing with action classes involving small objects, such as balls or yellow/red cards in soccer, which only occupy a fraction of the screen space. To address these challenges, we introduce a novel approach that analyzes and models scene entities using an adaptive attention mechanism. Particularly, our model disentangles the scene content into the global environment feature and local relevant scene entities feature. To efficiently extract environmental features while considering temporal information with less computational cost, we propose the use of a 2D backbone network with a time-shift mechanism. To accurately capture relevant scene entities, we employ a Vision-Language model in conjunction with the adaptive attention mechanism. Our model has demonstrated outstanding performance, securing the 1st place in the SoccerNet-v2 Action Spotting, FineDiving, and FineGym challenge with a substantial performance improvement of 1.6, 2.0, and 1.3 points in avg-mAP compared to the runner-up methods. Furthermore, our approach offers interpretability capabilities in contrast to other deep learning models, which are often designed as black boxes. Our code and models are released at: https://github.com/Fsoft-AIC/unifying-global-local-feature.
Entropy Guided Extrapolative Decoding to Improve Factuality in Large Language Models
Apr 14, 2024Large language models (LLMs) exhibit impressive natural language capabilities but suffer from hallucination -- generating content ungrounded in the realities of training data. Recent work has focused on decoding techniques to improve factuality during inference by leveraging LLMs' hierarchical representation of factual knowledge, manipulating the predicted distributions at inference time. Current state-of-the-art approaches refine decoding by contrasting early-exit distributions from a lower layer with the final layer to exploit information related to factuality within the model forward procedure. However, such methods often assume the final layer is the most reliable and the lower layer selection process depends on it. In this work, we first propose extrapolation of critical token probabilities beyond the last layer for more accurate contrasting. We additionally employ layer-wise entropy-guided lower layer selection, decoupling the selection process from the final layer. Experiments demonstrate strong performance - surpassing state-of-the-art on multiple different datasets by large margins. Analyses show different kinds of prompts respond to different selection strategies.
NeurIT: Pushing the Limit of Neural Inertial Tracking for Indoor Robotic IoT
Apr 13, 2024Inertial tracking is vital for robotic IoT and has gained popularity thanks to the ubiquity of low-cost Inertial Measurement Units (IMUs) and deep learning-powered tracking algorithms. Existing works, however, have not fully utilized IMU measurements, particularly magnetometers, nor maximized the potential of deep learning to achieve the desired accuracy. To enhance the tracking accuracy for indoor robotic applications, we introduce NeurIT, a sequence-to-sequence framework that elevates tracking accuracy to a new level. NeurIT employs a Time-Frequency Block-recurrent Transformer (TF-BRT) at its core, combining the power of recurrent neural network (RNN) and Transformer to learn representative features in both time and frequency domains. To fully utilize IMU information, we strategically employ body-frame differentiation of the magnetometer, which considerably reduces the tracking error. NeurIT is implemented on a customized robotic platform and evaluated in various indoor environments. Experimental results demonstrate that NeurIT achieves a mere 1-meter tracking error over a 300-meter distance. Notably, it significantly outperforms state-of-the-art baselines by 48.21% on unseen data. NeurIT also performs comparably to the visual-inertial approach (Tango Phone) in vision-favored conditions and surpasses it in plain environments. We believe NeurIT takes an important step forward toward practical neural inertial tracking for ubiquitous and scalable tracking of robotic things. NeurIT, including the source code and the dataset, is open-sourced here: https://github.com/NeurIT-Project/NeurIT.
SMITIN: Self-Monitored Inference-Time INtervention for Generative Music Transformers
Apr 02, 2024We introduce Self-Monitored Inference-Time INtervention (SMITIN), an approach for controlling an autoregressive generative music transformer using classifier probes. These simple logistic regression probes are trained on the output of each attention head in the transformer using a small dataset of audio examples both exhibiting and missing a specific musical trait (e.g., the presence/absence of drums, or real/synthetic music). We then steer the attention heads in the probe direction, ensuring the generative model output captures the desired musical trait. Additionally, we monitor the probe output to avoid adding an excessive amount of intervention into the autoregressive generation, which could lead to temporally incoherent music. We validate our results objectively and subjectively for both audio continuation and text-to-music applications, demonstrating the ability to add controls to large generative models for which retraining or even fine-tuning is impractical for most musicians. Audio samples of the proposed intervention approach are available on our demo page http://tinyurl.com/smitin .
A Parsimonious Setup for Streamflow Forecasting using CNN-LSTM
Apr 11, 2024Significant strides have been made in advancing streamflow predictions, notably with the introduction of cutting-edge machine-learning models. Predominantly, Long Short-Term Memories (LSTMs) and Convolution Neural Networks (CNNs) have been widely employed in this domain. While LSTMs are applicable in both rainfall-runoff and time series settings, CNN-LSTMs have primarily been utilized in rainfall-runoff scenarios. In this study, we extend the application of CNN-LSTMs to time series settings, leveraging lagged streamflow data in conjunction with precipitation and temperature data to predict streamflow. Our results show a substantial improvement in predictive performance in 21 out of 32 HUC8 basins in Nebraska, showcasing noteworthy increases in the Kling-Gupta Efficiency (KGE) values. These results highlight the effectiveness of CNN-LSTMs in time series settings, particularly for spatiotemporal hydrological modeling, for more accurate and robust streamflow predictions.
Video-Based Human Pose Regression via Decoupled Space-Time Aggregation
Apr 01, 2024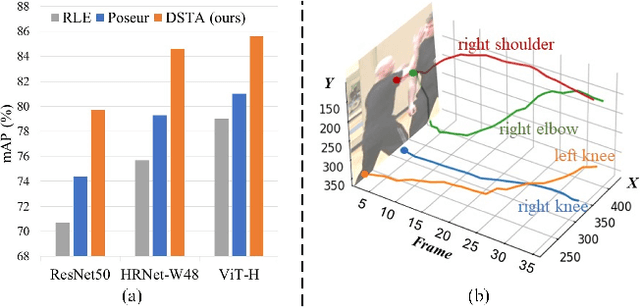

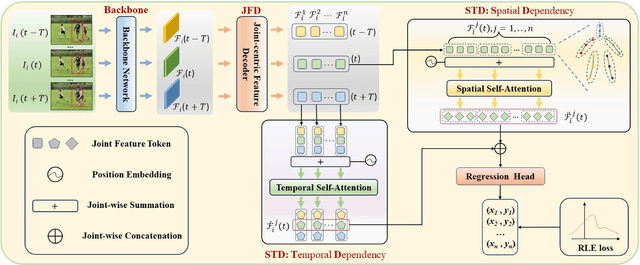
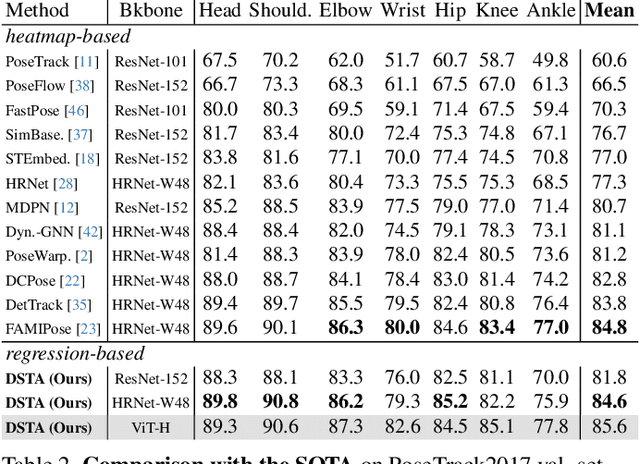
By leveraging temporal dependency in video sequences, multi-frame human pose estimation algorithms have demonstrated remarkable results in complicated situations, such as occlusion, motion blur, and video defocus. These algorithms are predominantly based on heatmaps, resulting in high computation and storage requirements per frame, which limits their flexibility and real-time application in video scenarios, particularly on edge devices. In this paper, we develop an efficient and effective video-based human pose regression method, which bypasses intermediate representations such as heatmaps and instead directly maps the input to the output joint coordinates. Despite the inherent spatial correlation among adjacent joints of the human pose, the temporal trajectory of each individual joint exhibits relative independence. In light of this, we propose a novel Decoupled Space-Time Aggregation network (DSTA) to separately capture the spatial contexts between adjacent joints and the temporal cues of each individual joint, thereby avoiding the conflation of spatiotemporal dimensions. Concretely, DSTA learns a dedicated feature token for each joint to facilitate the modeling of their spatiotemporal dependencies. With the proposed joint-wise local-awareness attention mechanism, our method is capable of efficiently and flexibly utilizing the spatial dependency of adjacent joints and the temporal dependency of each joint itself. Extensive experiments demonstrate the superiority of our method. Compared to previous regression-based single-frame human pose estimation methods, DSTA significantly enhances performance, achieving an 8.9 mAP improvement on PoseTrack2017. Furthermore, our approach either surpasses or is on par with the state-of-the-art heatmap-based multi-frame human pose estimation methods. Project page: https://github.com/zgspose/DSTA.
Optimal Kernel Tuning Parameter Prediction using Deep Sequence Models
Apr 15, 2024GPU kernels have come to the forefront of computing due to their utility in varied fields, from high-performance computing to machine learning. A typical GPU compute kernel is invoked millions, if not billions of times in a typical application, which makes their performance highly critical. Due to the unknown nature of the optimization surface, an exhaustive search is required to discover the global optimum, which is infeasible due to the possible exponential number of parameter combinations. In this work, we propose a methodology that uses deep sequence-to-sequence models to predict the optimal tuning parameters governing compute kernels. This work considers the prediction of kernel parameters as a sequence to the sequence translation problem, borrowing models from the Natural Language Processing (NLP) domain. Parameters describing the input, output and weight tensors are considered as the input language to the model that emits the corresponding kernel parameters. In essence, the model translates the problem parameter language to kernel parameter language. The core contributions of this work are: a) Proposing that a sequence to sequence model can accurately learn the performance dynamics of a GPU compute kernel b) A novel network architecture which predicts the kernel tuning parameters for GPU kernels, c) A constrained beam search which incorporates the physical limits of the GPU hardware as well as other expert knowledge reducing the search space. The proposed algorithm can achieve more than 90% accuracy on various convolutional kernels in MIOpen, the AMD machine learning primitives library. As a result, the proposed technique can reduce the development time and compute resources required to tune unseen input configurations, resulting in shorter development cycles, reduced development costs, and better user experience.