 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Bayesian autoregressive spectral estimation
Oct 05, 2021
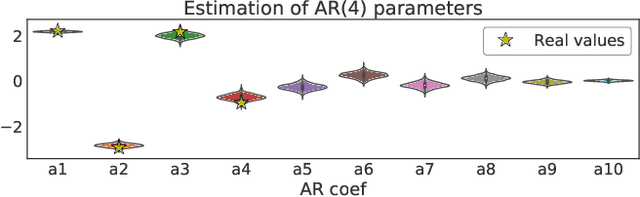
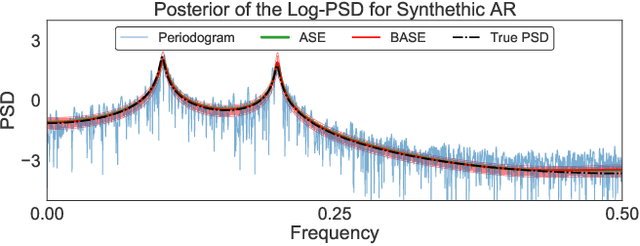
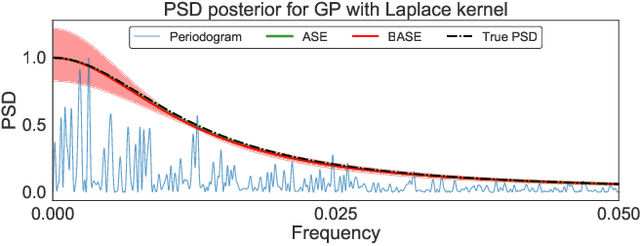
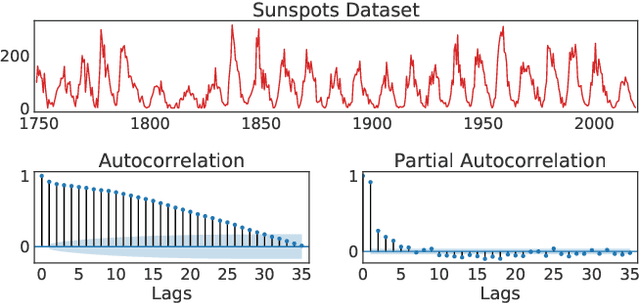
Autoregressive (AR) time series models are widely used in parametric spectral estimation (SE), where the power spectral density (PSD) of the time series is approximated by that of the \emph{best-fit} AR model, which is available in closed form. Since AR parameters are usually found via maximum-likelihood, least squares or the method of moments, AR-based SE fails to account for the uncertainty of the approximate PSD, and thus only yields point estimates. We propose to handle the uncertainty related to the AR approximation by finding the full posterior distribution of the AR parameters to then propagate this uncertainty to the PSD approximation by \emph{integrating out the AR parameters}; we implement this concept by assuming two different priors over the model noise. Through practical experiments, we show that the proposed Bayesian autoregressive spectral estimation (BASE) provides point estimates that follow closely those of standard autoregressive spectral estimation (ASE), while also providing error bars. BASE is validated against ASE and the Periodogram on both synthetic and real-world signals.
Frequency Fitness Assignment: Optimization without a Bias for Good Solutions can be Efficient
Dec 02, 2021
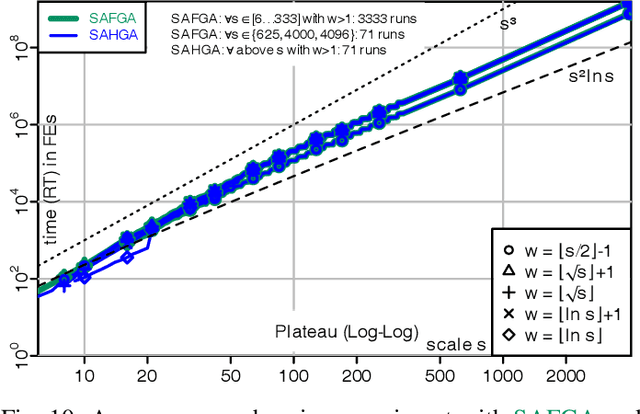
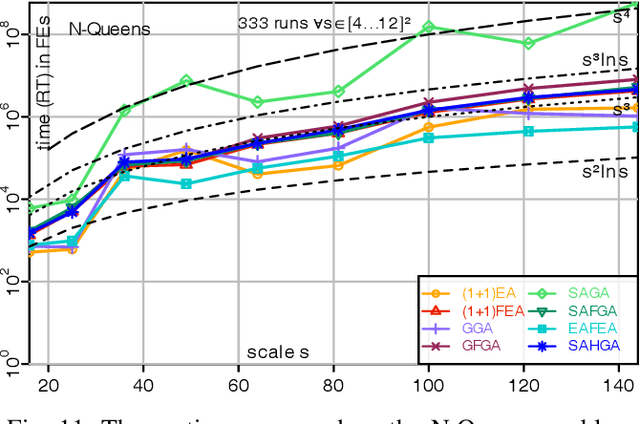
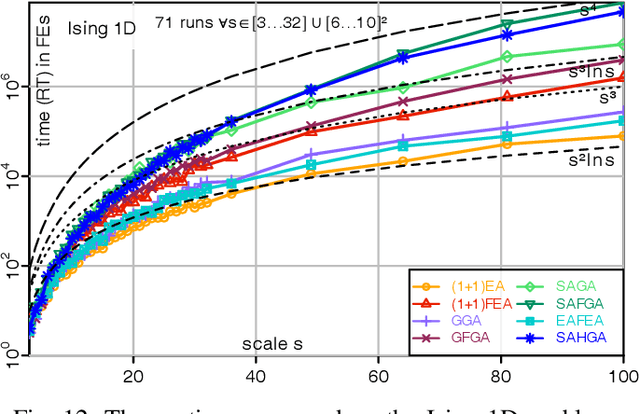
A fitness assignment process transforms the features (such as the objective value) of a candidate solution to a scalar fitness, which then is the basis for selection. Under Frequency Fitness Assignment (FFA), the fitness corresponding to an objective value is its encounter frequency and is subject to minimization. FFA creates algorithms that are not biased towards better solutions and are invariant under all bijections of the objective function value. We investigate the impact of FFA on the performance of two theory-inspired, state-of-the-art EAs, the Greedy (2+1) GA and the Self-Adjusting (1+(lambda,lambda)) GA. FFA improves their performance significantly on some problems that are hard for them. We empirically find that one FFA-based algorithm can solve all theory-based benchmark problems in this study, including traps, jumps, and plateaus, in polynomial time. We propose two hybrid approaches that use both direct and FFA-based optimization and find that they perform well. All FFA-based algorithms also perform better on satisfiability problems than all pure algorithm variants.
Few-Shot Out-of-Domain Transfer Learning of Natural Language Explanations
Dec 12, 2021
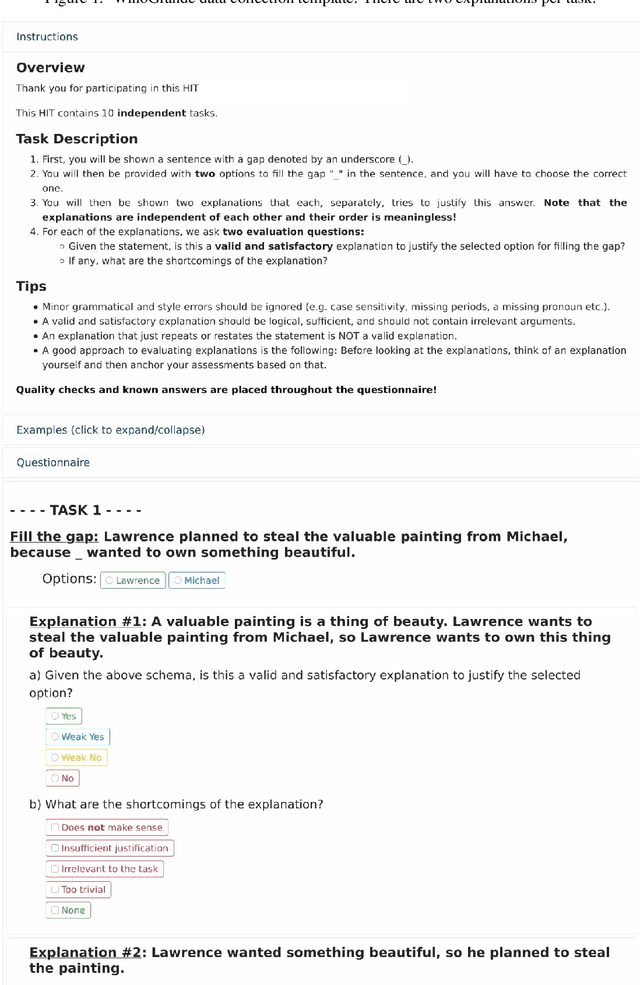

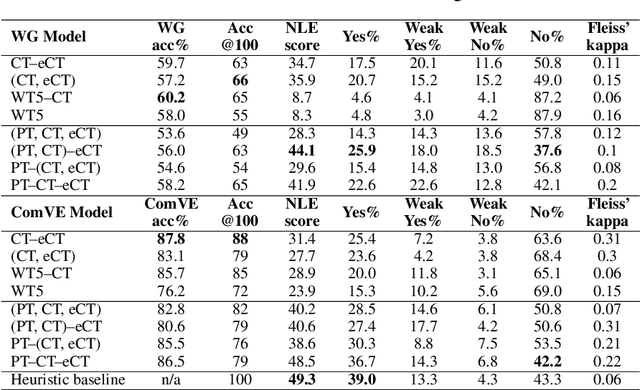
Recently, there has been an increasing interest in models that generate natural language explanations (NLEs) for their decisions. However, training a model to provide NLEs requires the acquisition of task-specific NLEs, which is time- and resource-consuming. A potential solution is the out-of-domain transfer of NLEs from a domain with a large number of NLEs to a domain with scarce NLEs but potentially a large number of labels, via few-shot transfer learning. In this work, we introduce three vanilla approaches for few-shot transfer learning of NLEs for the case of few NLEs but abundant labels, along with an adaptation of an existing vanilla fine-tuning approach. We transfer explainability from the natural language inference domain, where a large dataset of human-written NLEs exists (e-SNLI), to the domains of (1) hard cases of pronoun resolution, where we introduce a small dataset of NLEs on top of the WinoGrande dataset (small-e-WinoGrande), and (2) commonsense validation (ComVE). Our results demonstrate that the transfer of NLEs outperforms the single-task methods, and establish the best strategies out of the four identified training regimes. We also investigate the scalability of the best methods, both in terms of training data and model size.
Factorisation-based Image Labelling
Nov 19, 2021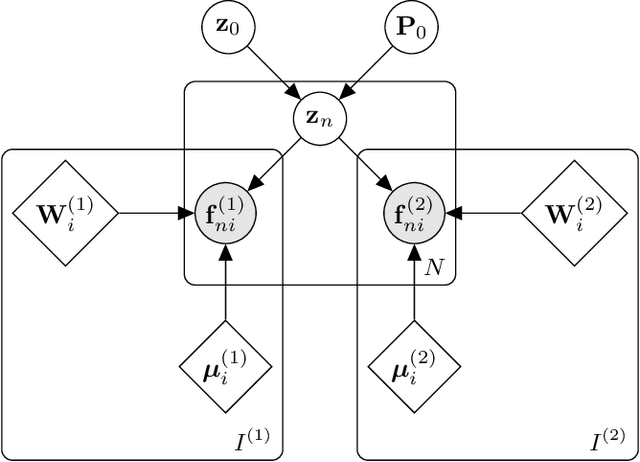
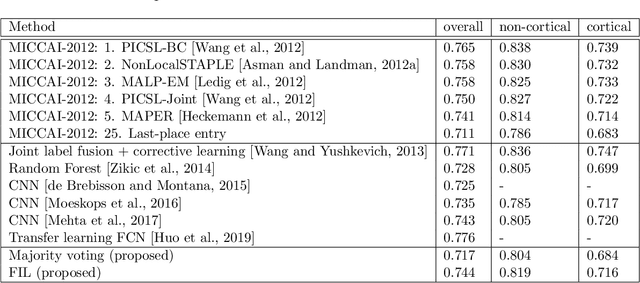
Segmentation of brain magnetic resonance images (MRI) into anatomical regions is a useful task in neuroimaging. Manual annotation is time consuming and expensive, so having a fully automated and general purpose brain segmentation algorithm is highly desirable. To this end, we propose a patched-based label propagation approach based on a generative model with latent variables. Once trained, our Factorisation-based Image Labelling (FIL) model is able to label target images with a variety of image contrasts. We compare the effectiveness of our proposed model against the state-of-the-art using data from the MICCAI 2012 Grand Challenge and Workshop on Multi-Atlas Labeling. As our approach is intended to be general purpose, we also assess how well it can handle domain shift by labelling images of the same subjects acquired with different MR contrasts.
SALSA: Spatial Cue-Augmented Log-Spectrogram Features for Polyphonic Sound Event Localization and Detection
Oct 01, 2021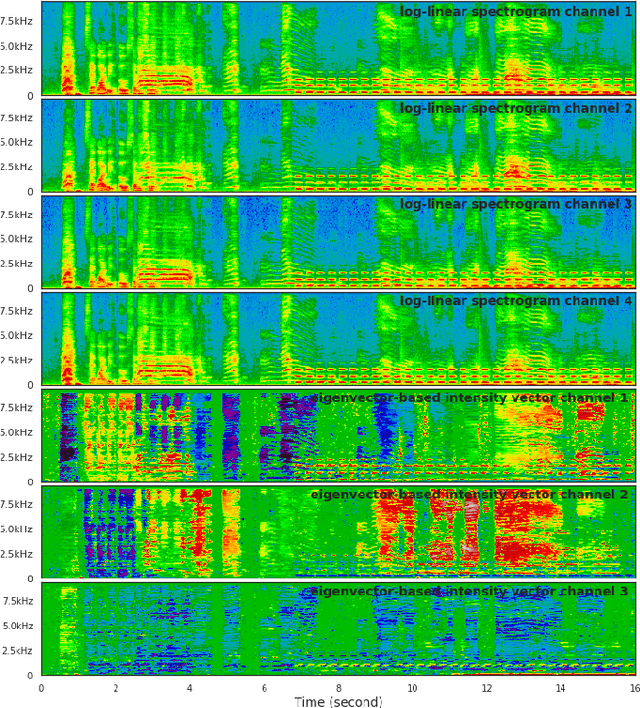
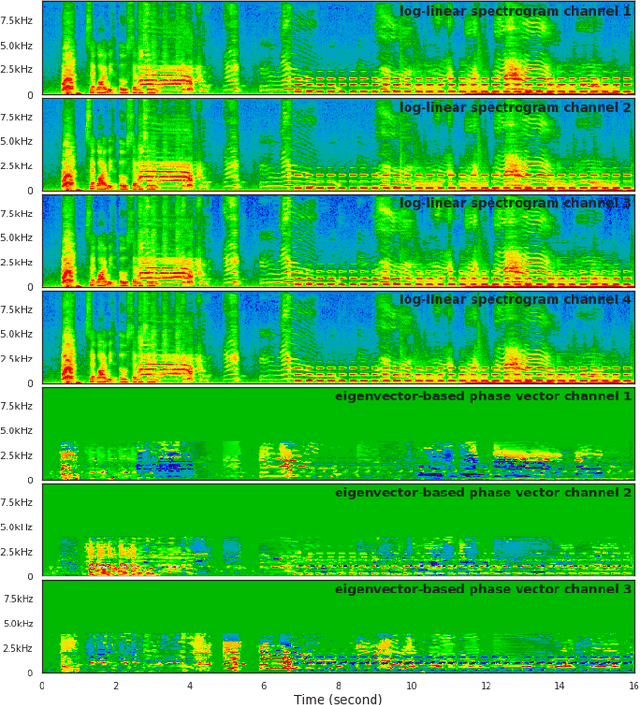
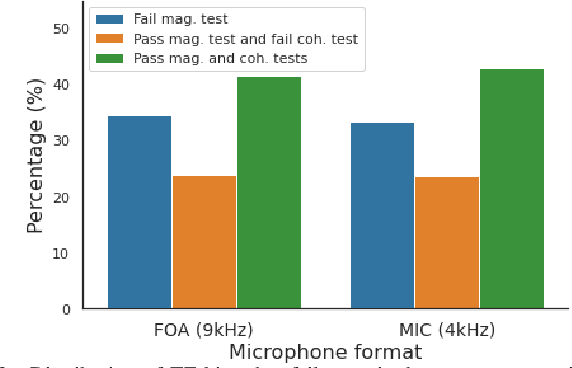
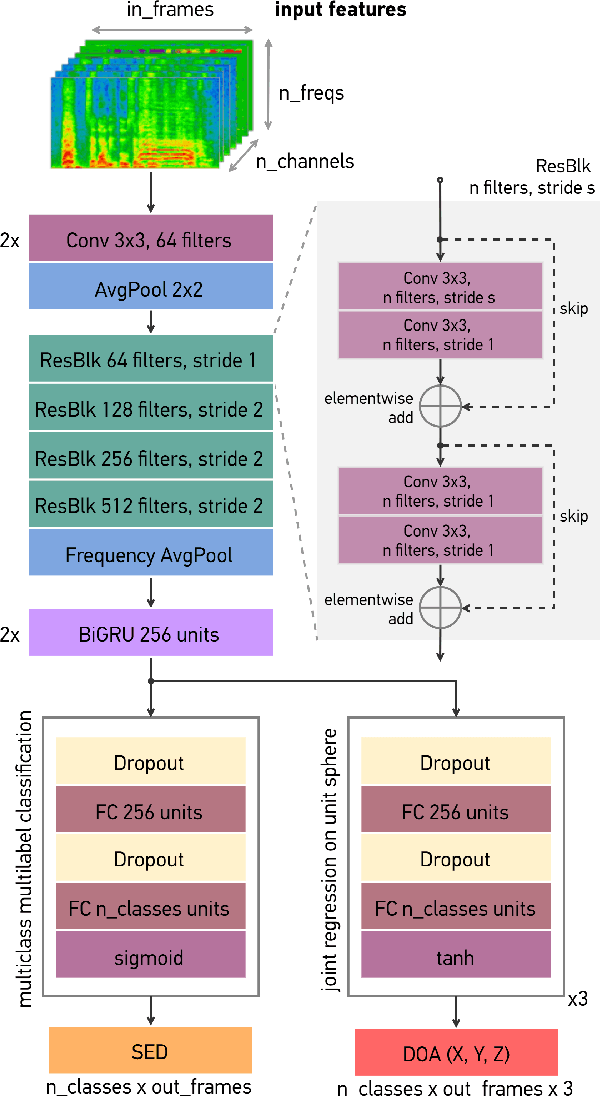
Sound event localization and detection (SELD) consists of two subtasks, which are sound event detection and direction-of-arrival estimation. While sound event detection mainly relies on time-frequency patterns to distinguish different sound classes, direction-of-arrival estimation uses amplitude and/or phase differences between microphones to estimate source directions. As a result, it is often difficult to jointly optimize these two subtasks. We propose a novel feature called Spatial cue-Augmented Log-SpectrogrAm (SALSA) with exact time-frequency mapping between the signal power and the source directional cues, which is crucial for resolving overlapping sound sources. The SALSA feature consists of multichannel log-spectrograms stacked along with the normalized principal eigenvector of the spatial covariance matrix at each corresponding time-frequency bin. Depending on the microphone array format, the principal eigenvector can be normalized differently to extract amplitude and/or phase differences between the microphones. As a result, SALSA features are applicable for different microphone array formats such as first-order ambisonics (FOA) and multichannel microphone array (MIC). Experimental results on the TAU-NIGENS Spatial Sound Events 2021 dataset with directional interferences showed that SALSA features outperformed other state-of-the-art features. Specifically, the use of SALSA features in the FOA format increased the F1 score and localization recall by 6% each, compared to the multichannel log-mel spectrograms with intensity vectors. For the MIC format, using SALSA features increased F1 score and localization recall by 16% and 7%, respectively, compared to using multichannel log-mel spectrograms with generalized cross-correlation spectra. Our ensemble model trained on SALSA features ranked second in the team category of the SELD task in the 2021 DCASE Challenge.
Deep learning versus kernel learning: an empirical study of loss landscape geometry and the time evolution of the Neural Tangent Kernel
Oct 28, 2020
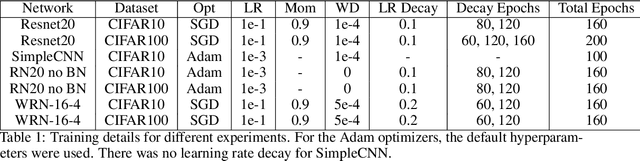
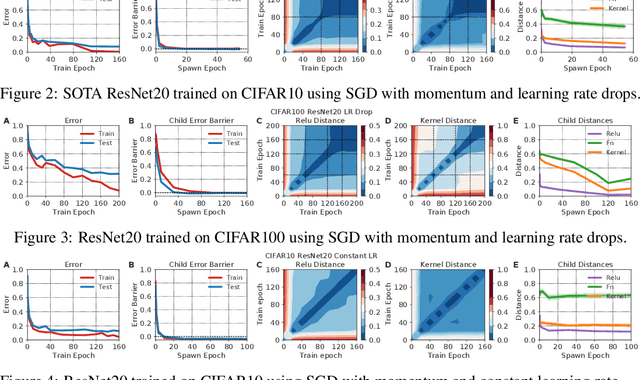
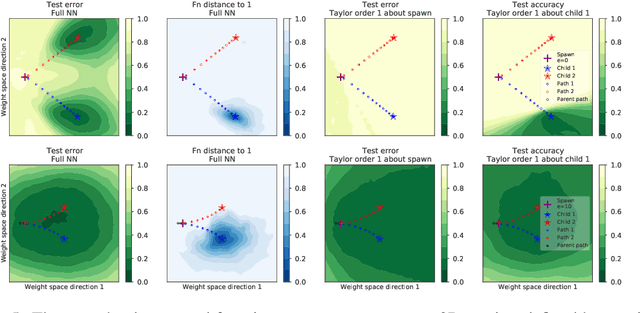
In suitably initialized wide networks, small learning rates transform deep neural networks (DNNs) into neural tangent kernel (NTK) machines, whose training dynamics is well-approximated by a linear weight expansion of the network at initialization. Standard training, however, diverges from its linearization in ways that are poorly understood. We study the relationship between the training dynamics of nonlinear deep networks, the geometry of the loss landscape, and the time evolution of a data-dependent NTK. We do so through a large-scale phenomenological analysis of training, synthesizing diverse measures characterizing loss landscape geometry and NTK dynamics. In multiple neural architectures and datasets, we find these diverse measures evolve in a highly correlated manner, revealing a universal picture of the deep learning process. In this picture, deep network training exhibits a highly chaotic rapid initial transient that within 2 to 3 epochs determines the final linearly connected basin of low loss containing the end point of training. During this chaotic transient, the NTK changes rapidly, learning useful features from the training data that enables it to outperform the standard initial NTK by a factor of 3 in less than 3 to 4 epochs. After this rapid chaotic transient, the NTK changes at constant velocity, and its performance matches that of full network training in 15% to 45% of training time. Overall, our analysis reveals a striking correlation between a diverse set of metrics over training time, governed by a rapid chaotic to stable transition in the first few epochs, that together poses challenges and opportunities for the development of more accurate theories of deep learning.
Optimization of phase-only holograms calculated with scaled diffraction calculation through deep neural networks
Dec 02, 2021
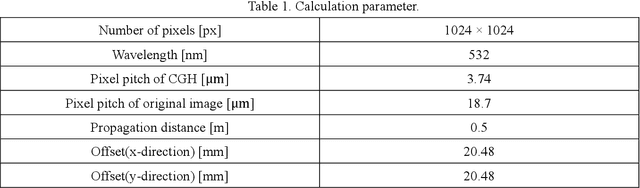
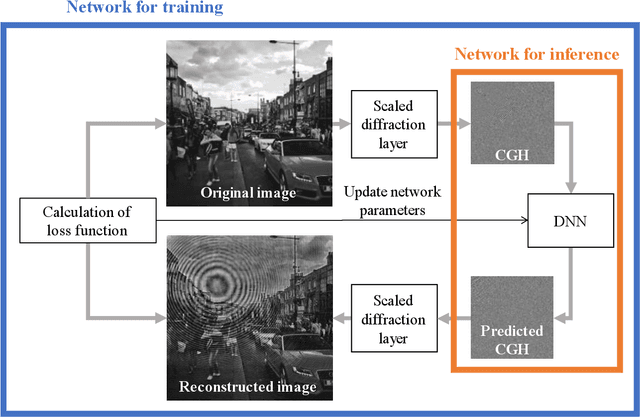
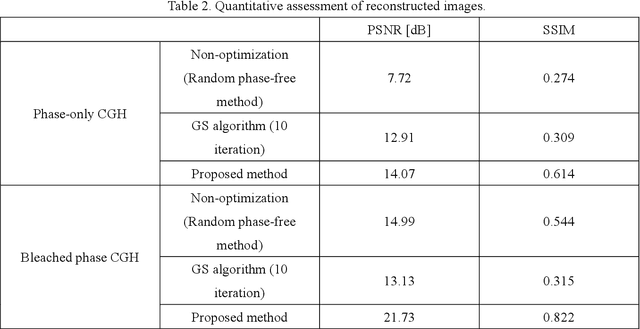
Computer-generated holograms (CGHs) are used in holographic three-dimensional (3D) displays and holographic projections. The quality of the reconstructed images using phase-only CGHs is degraded because the amplitude of the reconstructed image is difficult to control. Iterative optimization methods such as the Gerchberg-Saxton (GS) algorithm are one option for improving image quality. They optimize CGHs in an iterative fashion to obtain a higher image quality. However, such iterative computation is time consuming, and the improvement in image quality is often stagnant. Recently, deep learning-based hologram computation has been proposed. Deep neural networks directly infer CGHs from input image data. However, it is limited to reconstructing images that are the same size as the hologram. In this study, we use deep learning to optimize phase-only CGHs generated using scaled diffraction computations and the random phase-free method. By combining the random phase-free method with the scaled diffraction computation, it is possible to handle a zoomable reconstructed image larger than the hologram. In comparison to the GS algorithm, the proposed method optimizes both high quality and speed.
Intelligent Reflecting Surfaces for Enhanced NOMA-based Visible Light Communications
Nov 08, 2021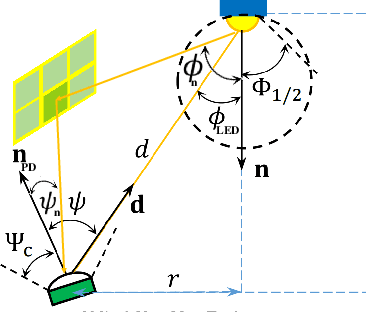
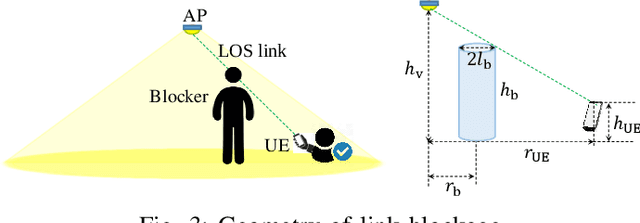
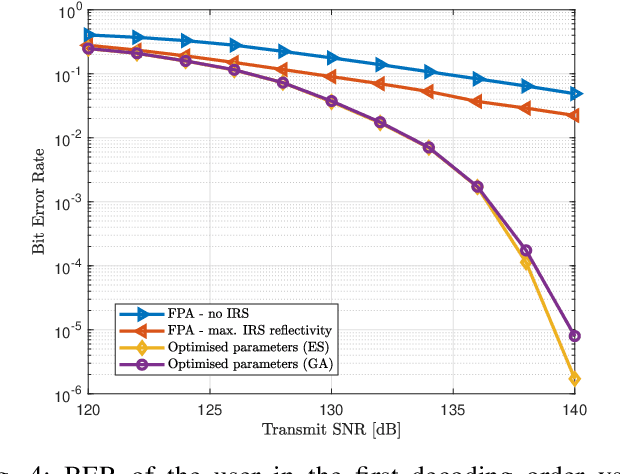
The emerging intelligent reflecting surface (IRS) technology introduces the potential of controlled light propagation in visible light communication (VLC) systems. This concept opens the door for new applications in which the channel itself can be altered to achieve specific key performance indicators. In this paper, for the first time in the open literature, we investigate the role that IRSs can play in enhancing the link reliability in VLC systems employing non-orthogonal multiple access (NOMA). We propose a framework for the joint optimisation of the NOMA and IRS parameters and show that it provides significant enhancements in link reliability. The enhancement is even more pronounced when the VLC channel is subject to blockage and random device orientation.
An early shutdown circuit for power reduction in high-precision dynamic comparators
Oct 05, 2021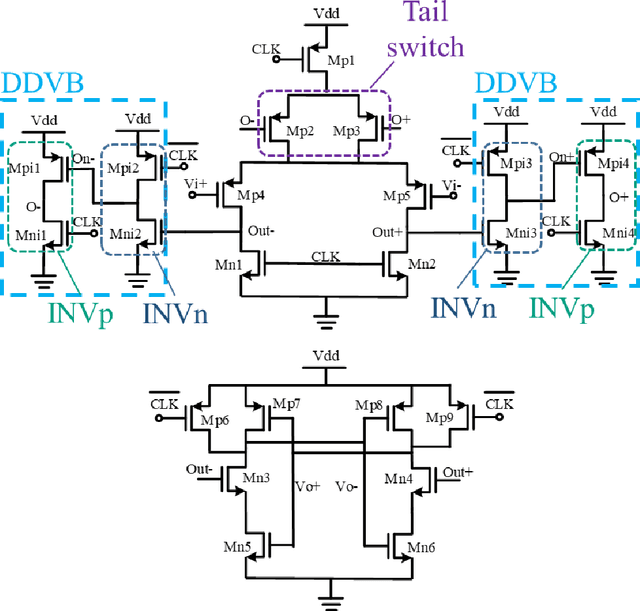
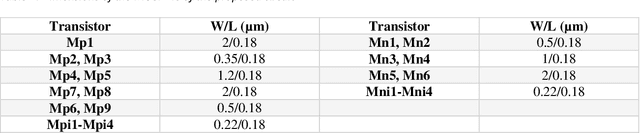
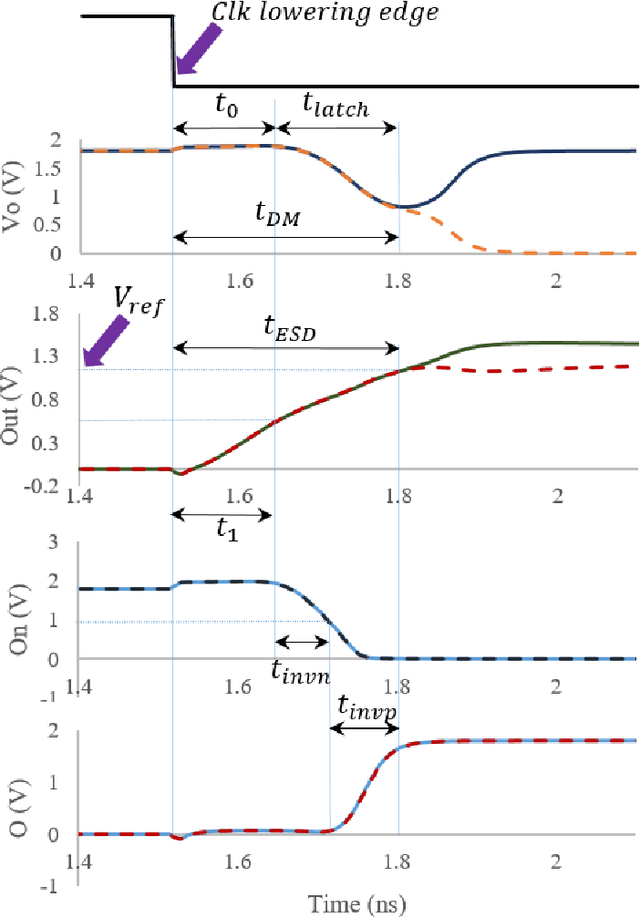
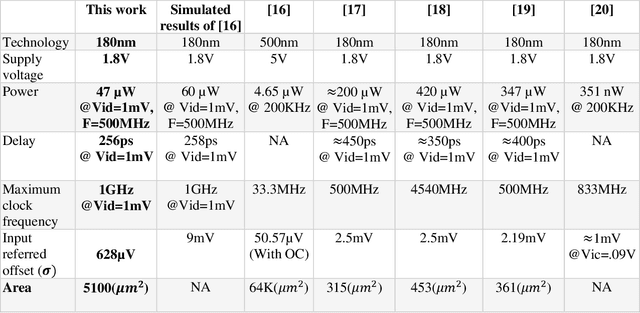
Dynamic comparators are an essential part of low-power analog to digital converters (ADCs) and are referred to as one of the most important building blocks in mixed mode circuits. The power consumption and accuracy of dynamic comparators directly affects the overall power consumption and effective number of bits of the ADC. In this paper, an early shutdown approach is proposed to deactivate the first stage preamplifier at the suitable time. Furthermore, a time domain offset cancellation technique is incorporated to reduce offset effects. With the proposed method power consumption can be reduced in low power high precision dynamic comparators. The proposed method has been simulated in a standard 0.18{\mu}m CMOS technology and the results confirm its effectiveness. The proposed circuit has the ability of reducing the power consumption by 21.7% in the worst case, while having little effect on the speed and accuracy in comparison with the conventional methods. The proposed comparator consumes only 47{\mu}W while operating at 500MHz. Furthermore, Monte Carlo evaluations showed that the standard deviation of the residual input referred offset was 620{\mu}V.
Cybonto: Towards Human Cognitive Digital Twins for Cybersecurity
Aug 05, 2021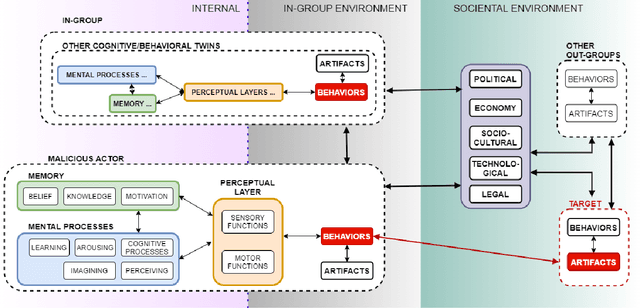
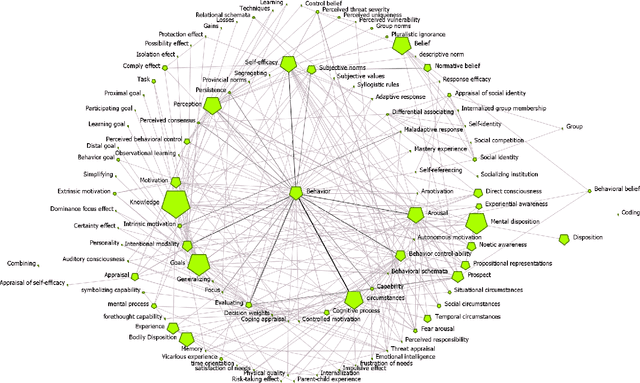
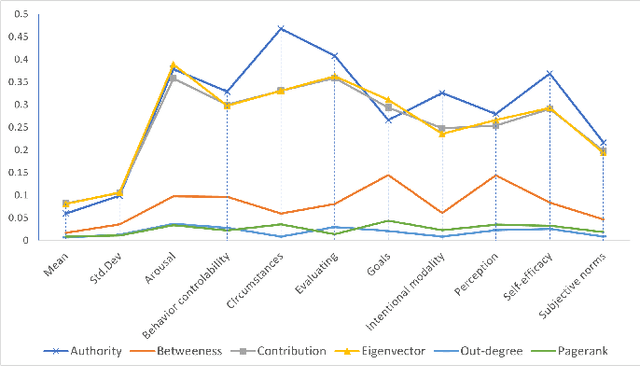
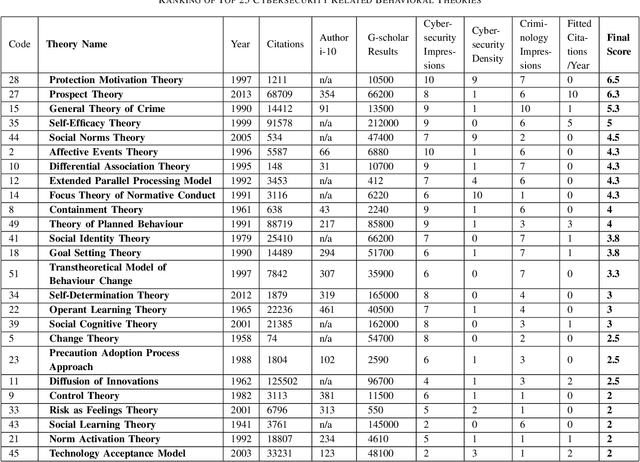
Cyber defense is reactive and slow. On average, the time-to-remedy is hundreds of times larger than the time-to-compromise. In response to the expanding ever-more-complex threat landscape, Digital Twins (DTs) and particularly Human Digital Twins (HDTs) offer the capability of running massive simulations across multiple knowledge domains. Simulated results may offer insights into adversaries' behaviors and tactics, resulting in better proactive cyber-defense strategies. For the first time, this paper solidifies the vision of DTs and HDTs for cybersecurity via the Cybonto conceptual framework proposal. The paper also contributes the Cybonto ontology, formally documenting 108 constructs and thousands of cognitive-related paths based on 20 time-tested psychology theories. Finally, the paper applied 20 network centrality algorithms in analyzing the 108 constructs. The identified top 10 constructs call for extensions of current digital cognitive architectures in preparation for the DT future.