 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
PatchFormer: An Efficient Point Transformer with Patch Attention
Dec 02, 2021

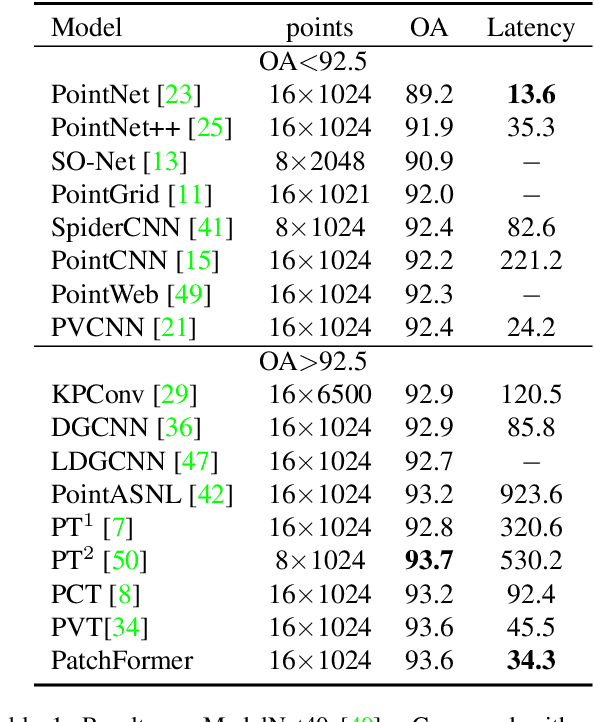
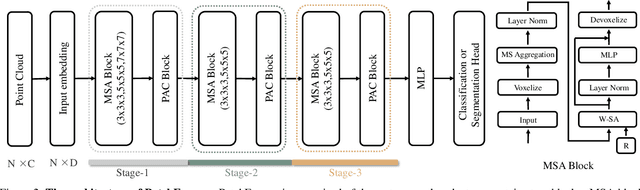
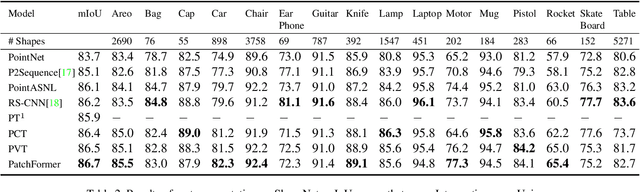
The point cloud learning community is witnesses a modeling shift from CNNs to Transformers, where pure Transformer architectures have achieved top accuracy on the major learning benchmarks. However, existing point Transformers are computationally expensive since they need to generate a large attention map, which has quadratic complexity (both in space and time) with respect to input size. To solve this shortcoming, we introduce Patch attention (PAT) to adaptively learn a much smaller set of bases upon which the attention maps are computed. By a weighted summation upon these bases, PAT not only captures the global shape context but also achieves linear complexity to input size. In addition, we propose a lightweight Multi-scale attention (MST) block to build attentions among features of different scales, providing the model with multi-scale features. Equipped with the PAT and MST, we construct our neural architecture called PatchFormer that integrates both modules into a joint framework for point cloud learning. Extensive experiments demonstrate that our network achieves comparable accuracy on general point cloud learning tasks with 9.2x speed-up than previous point Transformers.
ConTNet: Why not use convolution and transformer at the same time?
May 06, 2021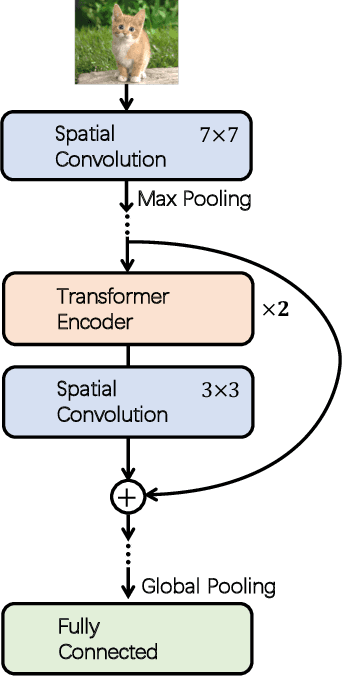
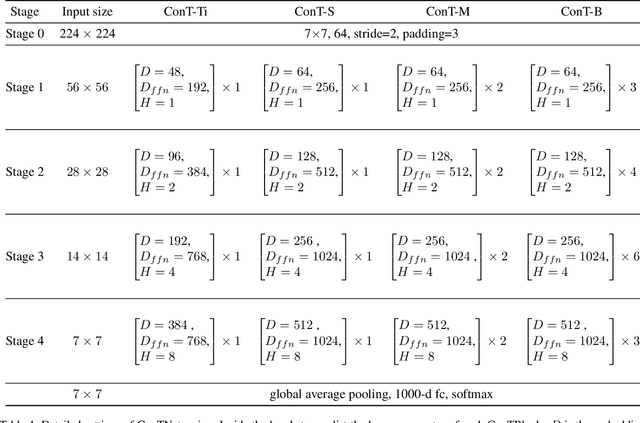

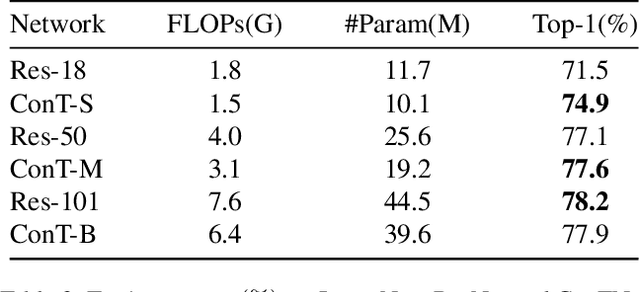
Although convolutional networks (ConvNets) have enjoyed great success in computer vision (CV), it suffers from capturing global information crucial to dense prediction tasks such as object detection and segmentation. In this work, we innovatively propose ConTNet (ConvolutionTransformer Network), combining transformer with ConvNet architectures to provide large receptive fields. Unlike the recently-proposed transformer-based models (e.g., ViT, DeiT) that are sensitive to hyper-parameters and extremely dependent on a pile of data augmentations when trained from scratch on a midsize dataset (e.g., ImageNet1k), ConTNet can be optimized like normal ConvNets (e.g., ResNet) and preserve an outstanding robustness. It is also worth pointing that, given identical strong data augmentations, the performance improvement of ConTNet is more remarkable than that of ResNet. We present its superiority and effectiveness on image classification and downstream tasks. For example, our ConTNet achieves 81.8% top-1 accuracy on ImageNet which is the same as DeiT-B with less than 40% computational complexity. ConTNet-M also outperforms ResNet50 as the backbone of both Faster-RCNN (by 2.6%) and Mask-RCNN (by 3.2%) on COCO2017 dataset. We hope that ConTNet could serve as a useful backbone for CV tasks and bring new ideas for model design
360-DFPE: Leveraging Monocular 360-Layouts for Direct Floor Plan Estimation
Dec 21, 2021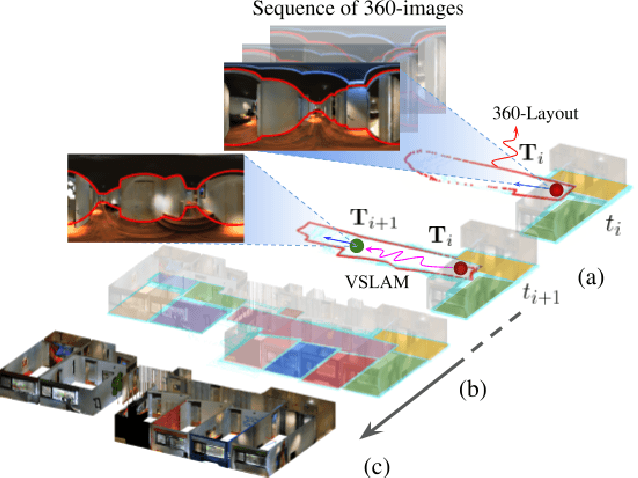
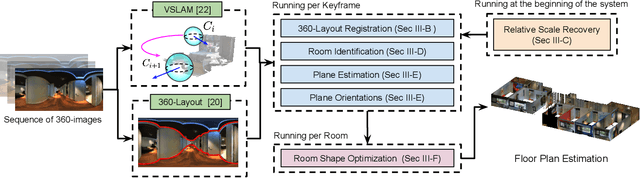
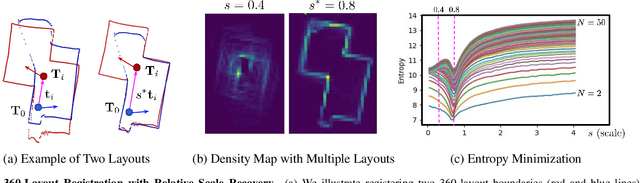
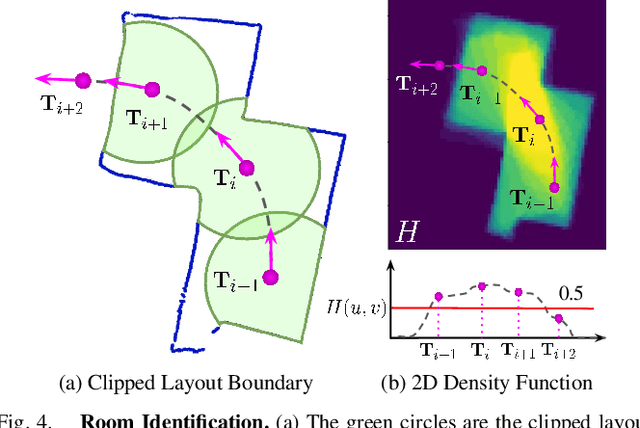
We present 360-DFPE, a sequential floor plan estimation method that directly takes 360-images as input without relying on active sensors or 3D information. Our approach leverages a loosely coupled integration between a monocular visual SLAM solution and a monocular 360-room layout approach, which estimate camera poses and layout geometries, respectively. Since our task is to sequentially capture the floor plan using monocular images, the entire scene structure, room instances, and room shapes are unknown. To tackle these challenges, we first handle the scale difference between visual odometry and layout geometry via formulating an entropy minimization process, which enables us to directly align 360-layouts without knowing the entire scene in advance. Second, to sequentially identify individual rooms, we propose a novel room identification algorithm that tracks every room along the camera exploration using geometry information. Lastly, to estimate the final shape of the room, we propose a shortest path algorithm with an iterative coarse-to-fine strategy, which improves prior formulations with higher accuracy and faster run-time. Moreover, we collect a new floor plan dataset with challenging large-scale scenes, providing both point clouds and sequential 360-image information. Experimental results show that our monocular solution achieves favorable performance against the current state-of-the-art algorithms that rely on active sensors and require the entire scene reconstruction data in advance. Our code and dataset will be released soon.
Temporally-Consistent Surface Reconstruction using Metrically-Consistent Atlases
Nov 12, 2021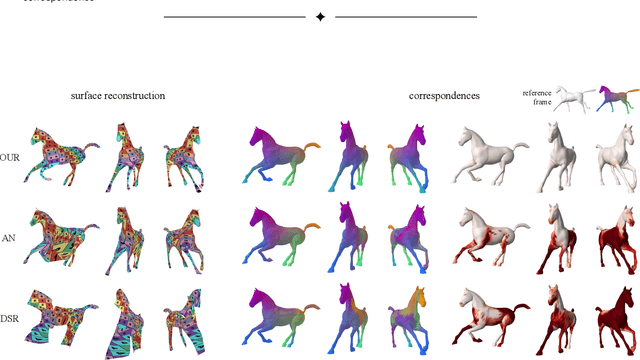
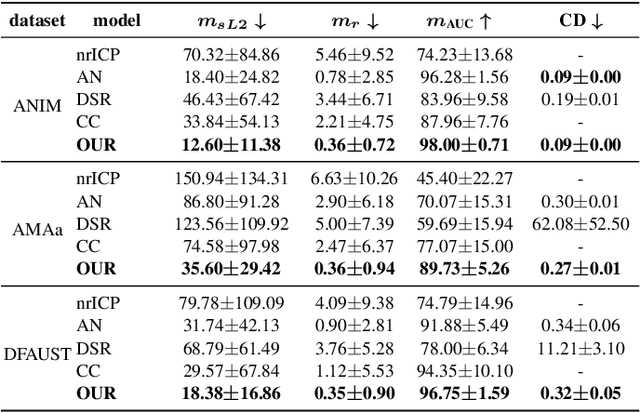
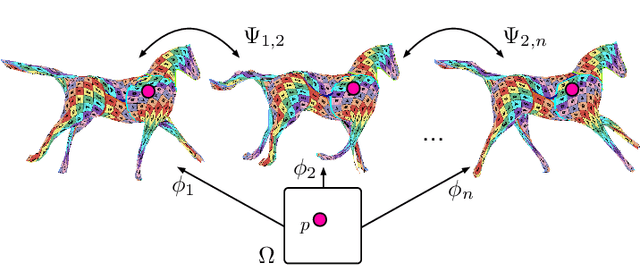
We propose a method for unsupervised reconstruction of a temporally-consistent sequence of surfaces from a sequence of time-evolving point clouds. It yields dense and semantically meaningful correspondences between frames. We represent the reconstructed surfaces as atlases computed by a neural network, which enables us to establish correspondences between frames. The key to making these correspondences semantically meaningful is to guarantee that the metric tensors computed at corresponding points are as similar as possible. We have devised an optimization strategy that makes our method robust to noise and global motions, without a priori correspondences or pre-alignment steps. As a result, our approach outperforms state-of-the-art ones on several challenging datasets. The code is available at https://github.com/bednarikjan/temporally_coherent_surface_reconstruction.
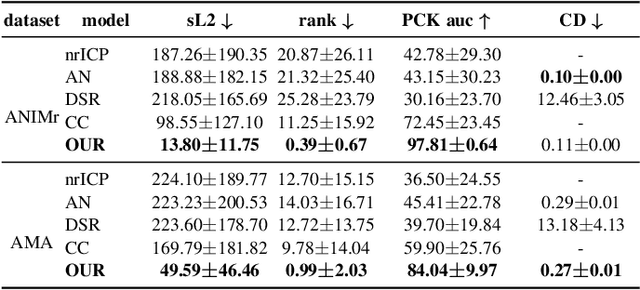
DPC: Unsupervised Deep Point Correspondence via Cross and Self Construction
Oct 16, 2021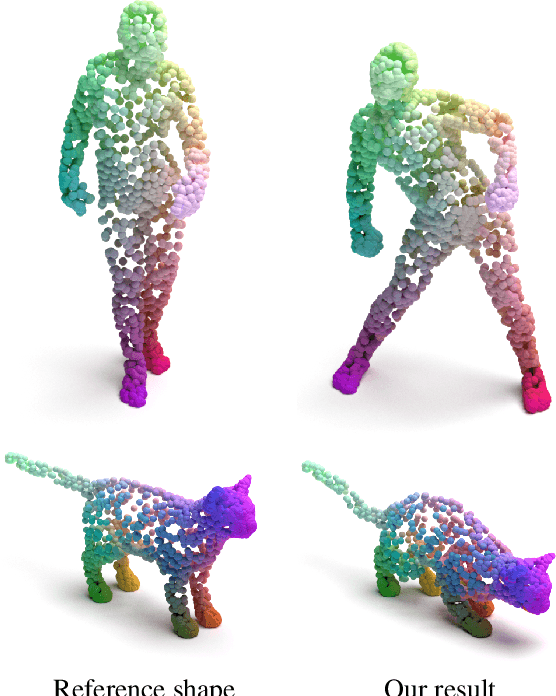
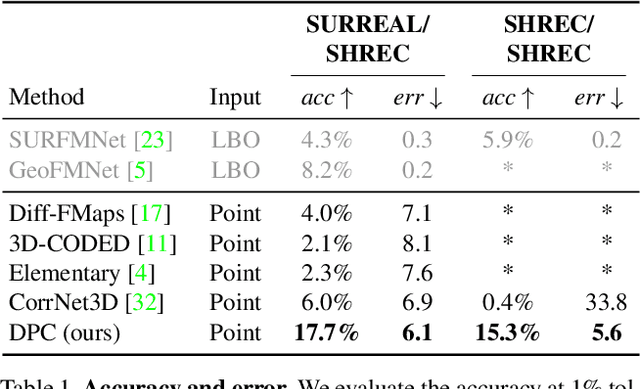
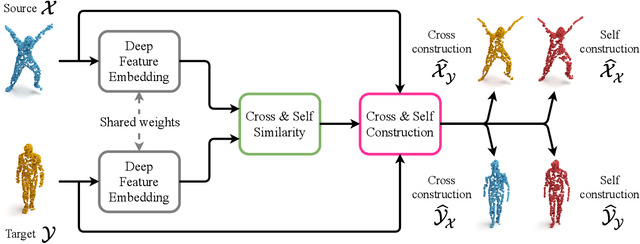
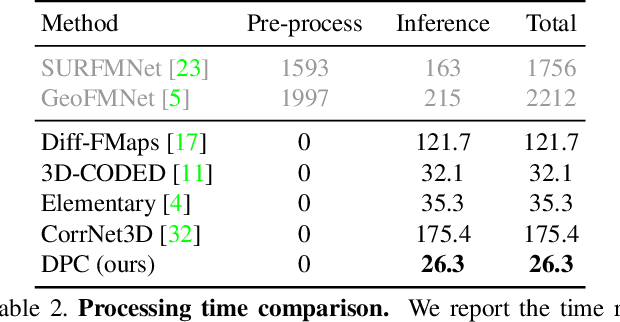
We present a new method for real-time non-rigid dense correspondence between point clouds based on structured shape construction. Our method, termed Deep Point Correspondence (DPC), requires a fraction of the training data compared to previous techniques and presents better generalization capabilities. Until now, two main approaches have been suggested for the dense correspondence problem. The first is a spectral-based approach that obtains great results on synthetic datasets but requires mesh connectivity of the shapes and long inference processing time while being unstable in real-world scenarios. The second is a spatial approach that uses an encoder-decoder framework to regress an ordered point cloud for the matching alignment from an irregular input. Unfortunately, the decoder brings considerable disadvantages, as it requires a large amount of training data and struggles to generalize well in cross-dataset evaluations. DPC's novelty lies in its lack of a decoder component. Instead, we use latent similarity and the input coordinates themselves to construct the point cloud and determine correspondence, replacing the coordinate regression done by the decoder. Extensive experiments show that our construction scheme leads to a performance boost in comparison to recent state-of-the-art correspondence methods. Our code is publicly available at https://github.com/dvirginz/DPC.
Testability-Aware Low Power Controller Design with Evolutionary Learning
Nov 26, 2021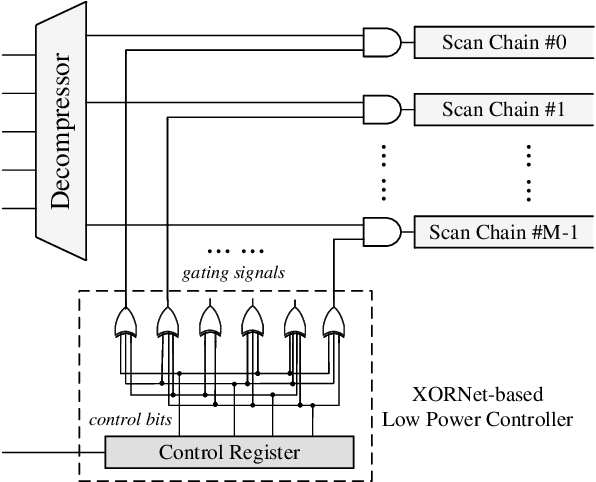
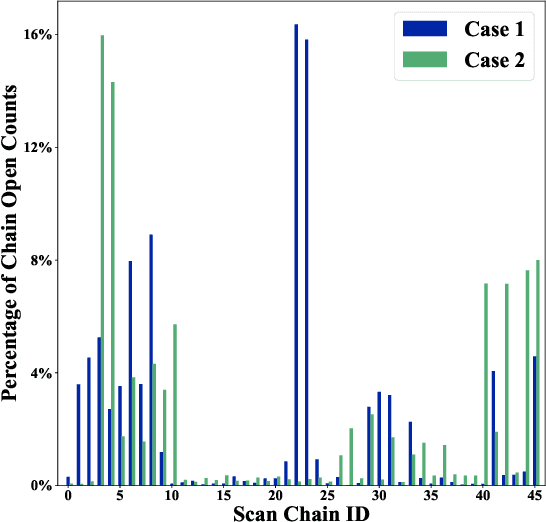
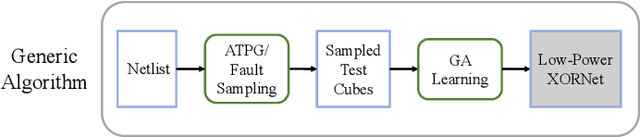
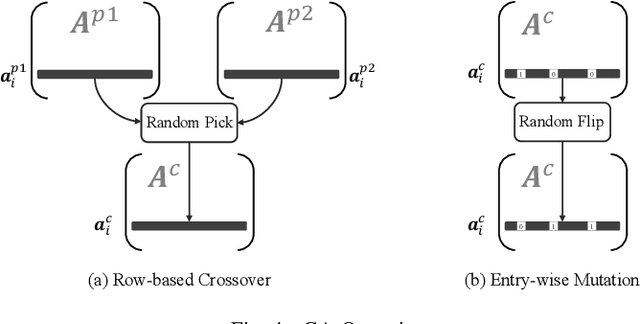
XORNet-based low power controller is a popular technique to reduce circuit transitions in scan-based testing. However, existing solutions construct the XORNet evenly for scan chain control, and it may result in sub-optimal solutions without any design guidance. In this paper, we propose a novel testability-aware low power controller with evolutionary learning. The XORNet generated from the proposed genetic algorithm (GA) enables adaptive control for scan chains according to their usages, thereby significantly improving XORNet encoding capacity, reducing the number of failure cases with ATPG and decreasing test data volume. Experimental results indicate that under the same control bits, our GA-guided XORNet design can improve the fault coverage by up to 2.11%. The proposed GA-guided XORNets also allows reducing the number of control bits, and the total testing time decreases by 20.78% on average and up to 47.09% compared to the existing design without sacrificing test coverage.
Dynamic treatment effects: high-dimensional inference under model misspecification
Nov 12, 2021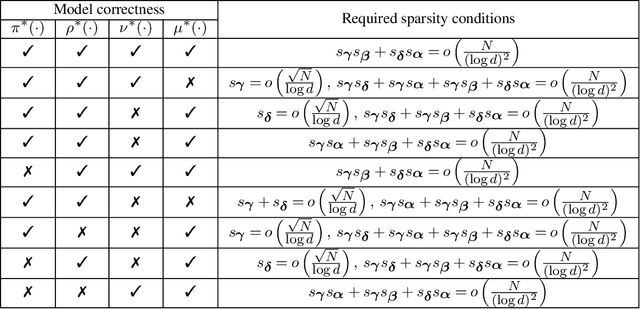
This paper considers the inference for heterogeneous treatment effects in dynamic settings that covariates and treatments are longitudinal. We focus on high-dimensional cases that the sample size, $N$, is potentially much larger than the covariate vector's dimension, $d$. The marginal structural mean models are considered. We propose a "sequential model doubly robust" estimator constructed based on "moment targeted" nuisance estimators. Such nuisance estimators are carefully designed through non-standard loss functions, reducing the bias resulting from potential model misspecifications. We achieve $\sqrt N$-inference even when model misspecification occurs. We only require one nuisance model to be correctly specified at each time spot. Such model correctness conditions are weaker than all the existing work, even containing the literature on low dimensions.
Visualising and Explaining Deep Learning Models for Speech Quality Prediction
Dec 12, 2021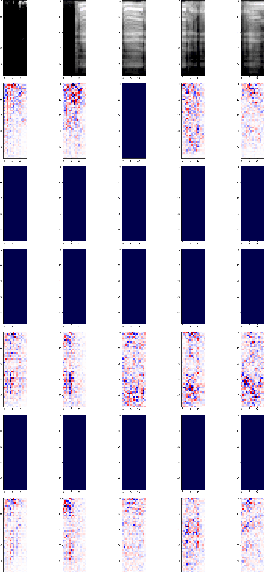
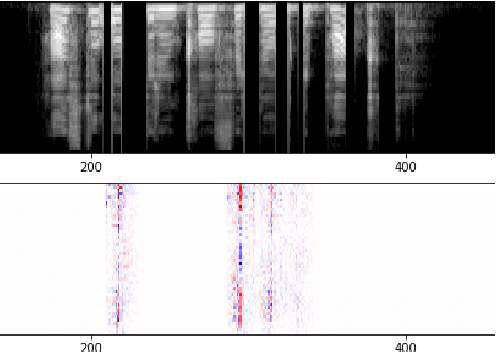
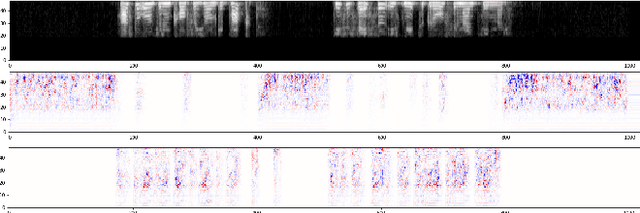

Estimating quality of transmitted speech is known to be a non-trivial task. While traditionally, test participants are asked to rate the quality of samples; nowadays, automated methods are available. These methods can be divided into: 1) intrusive models, which use both, the original and the degraded signals, and 2) non-intrusive models, which only require the degraded signal. Recently, non-intrusive models based on neural networks showed to outperform signal processing based models. However, the advantages of deep learning based models come with the cost of being more challenging to interpret. To get more insight into the prediction models the non-intrusive speech quality prediction model NISQA is analyzed in this paper. NISQA is composed of a convolutional neural network (CNN) and a recurrent neural network (RNN). The task of the CNN is to compute relevant features for the speech quality prediction on a frame level, while the RNN models time-dependencies between the individual speech frames. Different explanation algorithms are used to understand the automatically learned features of the CNN. In this way, several interpretable features could be identified, such as the sensitivity to noise or strong interruptions. On the other hand, it was found that multiple features carry redundant information.
Bayesian autoregressive spectral estimation
Oct 05, 2021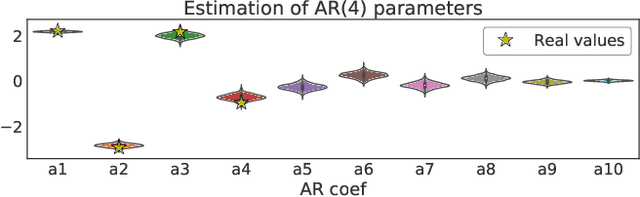
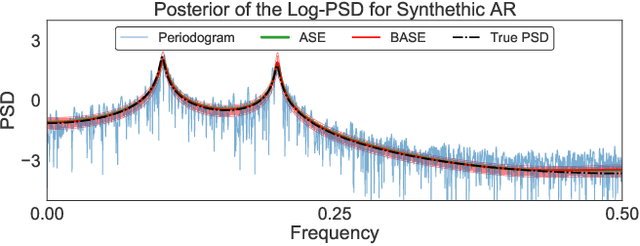
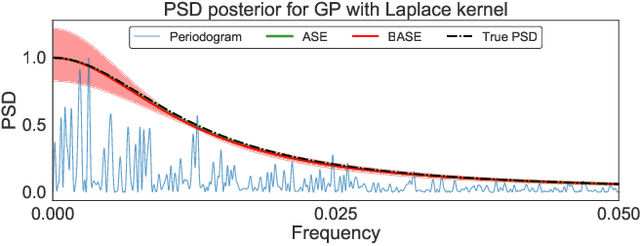
Autoregressive (AR) time series models are widely used in parametric spectral estimation (SE), where the power spectral density (PSD) of the time series is approximated by that of the \emph{best-fit} AR model, which is available in closed form. Since AR parameters are usually found via maximum-likelihood, least squares or the method of moments, AR-based SE fails to account for the uncertainty of the approximate PSD, and thus only yields point estimates. We propose to handle the uncertainty related to the AR approximation by finding the full posterior distribution of the AR parameters to then propagate this uncertainty to the PSD approximation by \emph{integrating out the AR parameters}; we implement this concept by assuming two different priors over the model noise. Through practical experiments, we show that the proposed Bayesian autoregressive spectral estimation (BASE) provides point estimates that follow closely those of standard autoregressive spectral estimation (ASE), while also providing error bars. BASE is validated against ASE and the Periodogram on both synthetic and real-world signals.
Network-Aware 5G Edge Computing for Object Detection: Augmenting Wearables to "See'' More, Farther and Faster
Dec 25, 2021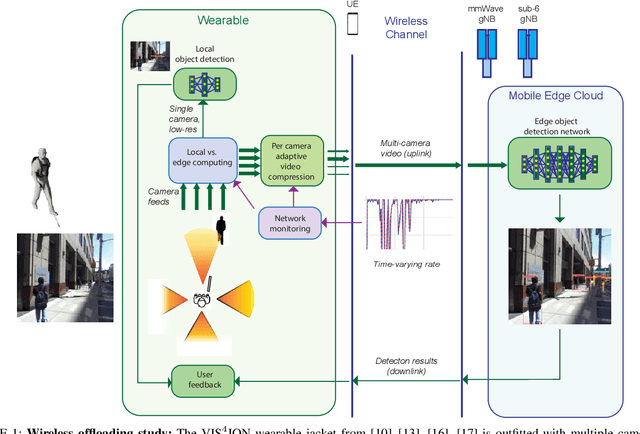
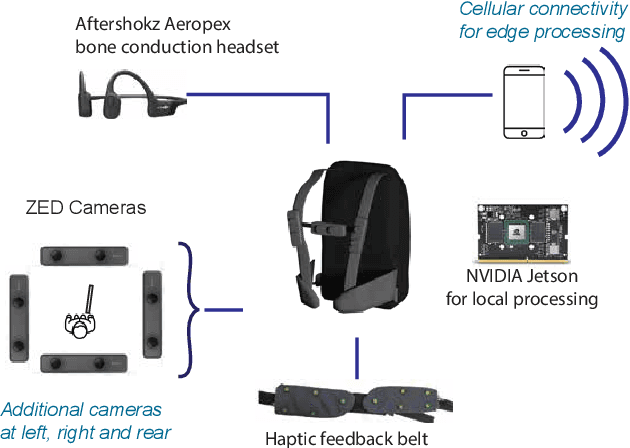
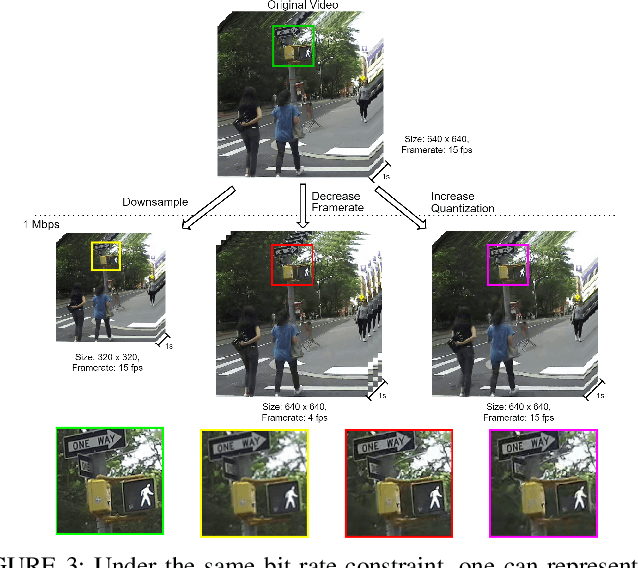
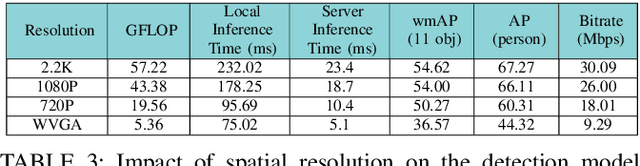
Advanced wearable devices are increasingly incorporating high-resolution multi-camera systems. As state-of-the-art neural networks for processing the resulting image data are computationally demanding, there has been growing interest in leveraging fifth generation (5G) wireless connectivity and mobile edge computing for offloading this processing to the cloud. To assess this possibility, this paper presents a detailed simulation and evaluation of 5G wireless offloading for object detection within a powerful, new smart wearable called VIS4ION, for the Blind-and-Visually Impaired (BVI). The current VIS4ION system is an instrumented book-bag with high-resolution cameras, vision processing and haptic and audio feedback. The paper considers uploading the camera data to a mobile edge cloud to perform real-time object detection and transmitting the detection results back to the wearable. To determine the video requirements, the paper evaluates the impact of video bit rate and resolution on object detection accuracy and range. A new street scene dataset with labeled objects relevant to BVI navigation is leveraged for analysis. The vision evaluation is combined with a detailed full-stack wireless network simulation to determine the distribution of throughputs and delays with real navigation paths and ray-tracing from new high-resolution 3D models in an urban environment. For comparison, the wireless simulation considers both a standard 4G-Long Term Evolution (LTE) carrier and high-rate 5G millimeter-wave (mmWave) carrier. The work thus provides a thorough and realistic assessment of edge computing with mmWave connectivity in an application with both high bandwidth and low latency requirements.