 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Bayesian Sample Size Prediction for Online Activity
Nov 23, 2021
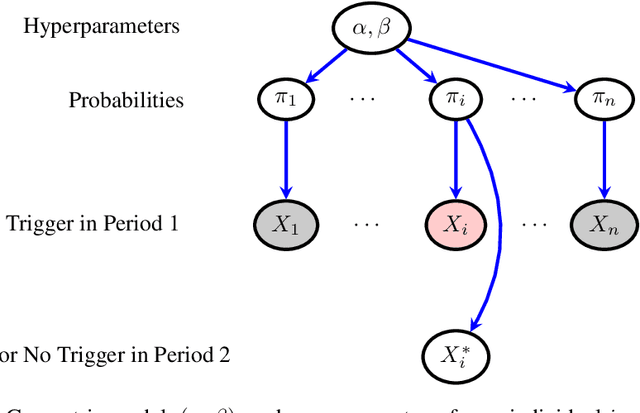
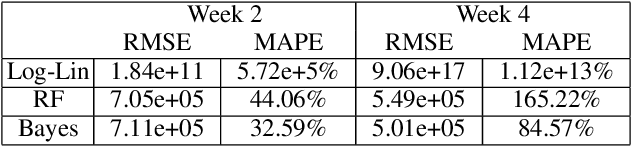
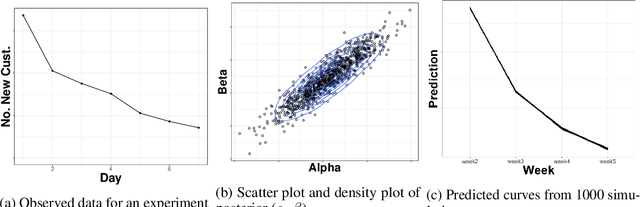
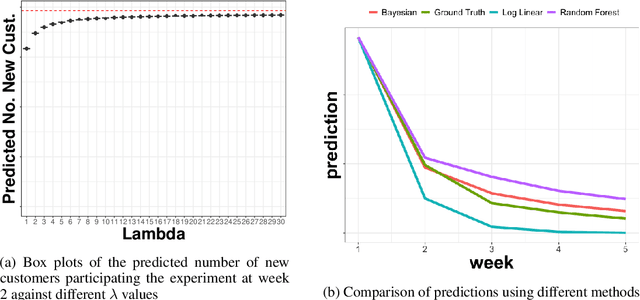
In many contexts it is useful to predict the number of individuals in some population who will initiate a particular activity during a given period. For example, the number of users who will install a software update, the number of customers who will use a new feature on a website or who will participate in an A/B test. In practical settings, there is heterogeneity amongst individuals with regard to the distribution of time until they will initiate. For these reasons it is inappropriate to assume that the number of new individuals observed on successive days will be identically distributed. Given observations on the number of unique users participating in an initial period, we present a simple but novel Bayesian method for predicting the number of additional individuals who will subsequently participate during a subsequent period. We illustrate the performance of the method in predicting sample size in online experimentation.
Generate Point Clouds with Multiscale Details from Graph-Represented Structures
Dec 13, 2021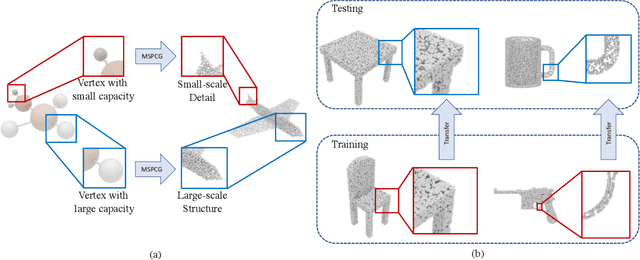
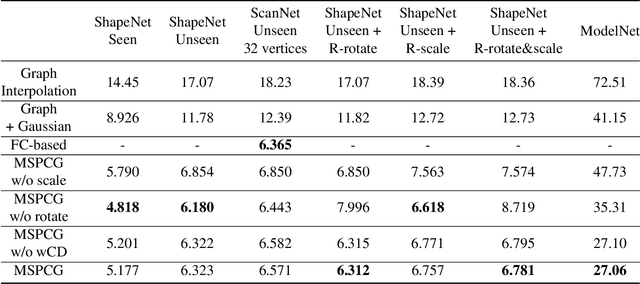
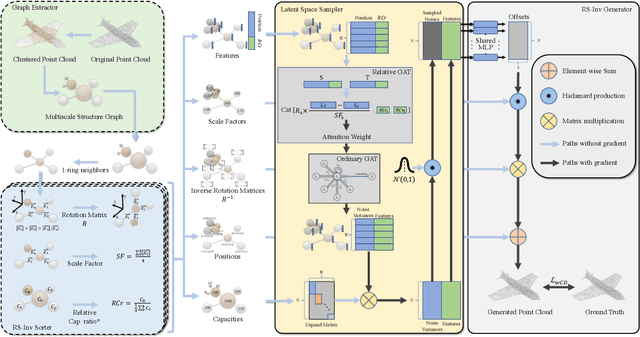

Generating point clouds from structures is a highly valued method to control the generation of point clouds.One of the major problems in structure-based controllable point cloud generation is the lack of controllability to details, as details are missing in most existing representations of structures.It can be observed that definitions of details and structures are subjective.Details can be treated as structures on small scale.To represent structures in different scales at the same time, we present a graph-based representation of structures called the Multiscale Structure Graph(MSG).By treating details as small-scale structures, similar patterns of local structures can be found at different scales, places, densities, and angles.The knowledge learned from a pattern can be transferred to similar patterns in other scales.An encoding and generation mechanism, namely the Multiscale Structure-based Point Cloud Generator(MSPCG), for generating dense point clouds from the MSG is proposed, which can simultaneously learn local patterns with miscellaneous spatial properties.Our MSPCG also has great generalization ability and scalability.An MSPCG trained on the ShapeNet dataset can enable multi-scale edition on point clouds, generate point clouds for unseen categories, and generate indoor scenes from a given structure. The experimental results show that our method significantly outperforms baseline methods.
Enabling variable high spatial resolution retrieval from a long pulse BOTDA sensor
Sep 09, 2021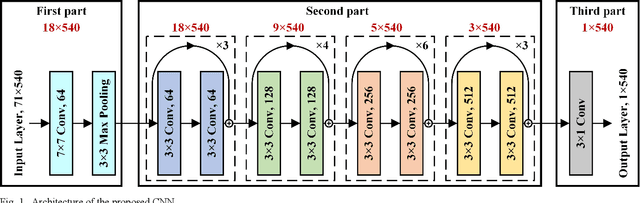
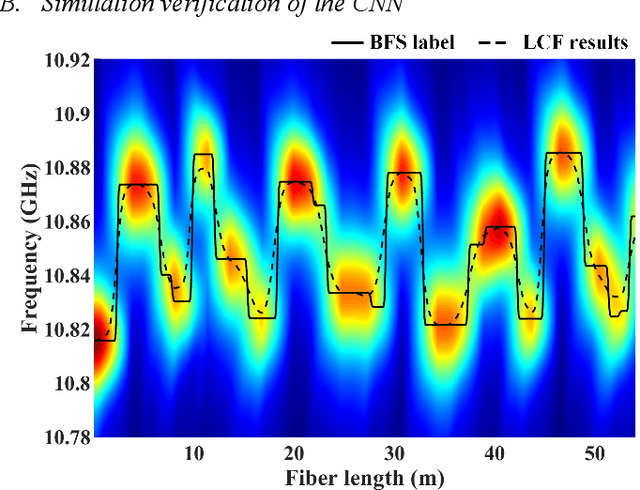
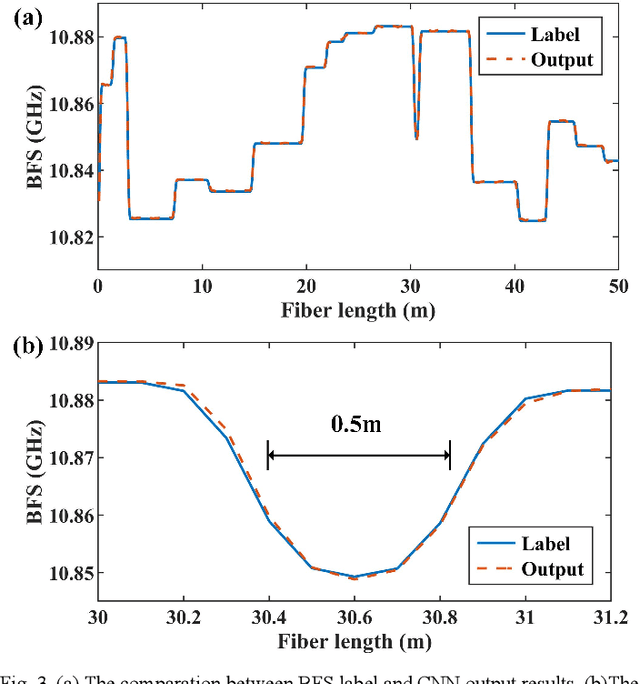
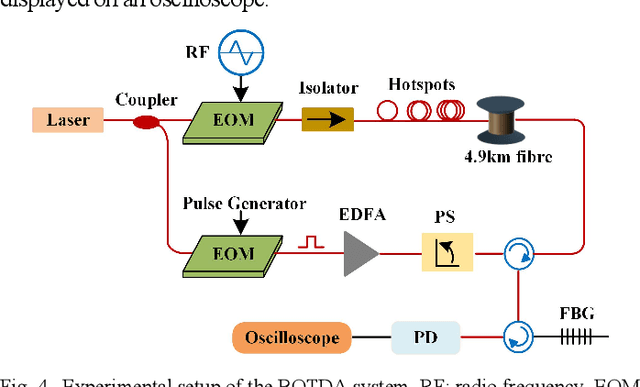
In the field of Internet of Things, there is an urgent need for sensors with large-scale sensing capability for scenarios such as intelligent monitoring of production lines and urban infrastructure. Brillouin optical time domain analysis (BOTDA) sensors, which can monitor thousands of continuous points simultaneously, show great advantages in these applications. We propose a convolutional neural network (CNN) to process the data of conventional Brillouin optical time domain analysis (BOTDA) sensors, which achieves unprecedented performance improvement that allows to directly retrieve higher spatial resolution (SR) from the sensing system that use long pump pulses. By using the simulated Brillouin gain spectrums (BGSs) as the CNN input and the corresponding high SR BFS as the output target, the trained CNN is able to obtain a SR higher than the theoretical value determined by the pump pulse width. In the experiment, the CNN accurately retrieves 0.5-m hotspots from the measured BGS with pump pulses from 20 to 50 ns, and the acquired BFS is in great agreement with 45/40 ns differential pulse-width pair (DPP) measurement results. Compared with the DPP technique, the proposed CNN demonstrates a 2-fold improvement in BFS uncertainty with only half the measurement time. In addition, by changing the training datasets, the proposed CNN can obtain tunable high SR retrieval based on conventional BOTDA sensors that use long pulses without any requirement of hardware modifications. The proposed data post-processing approach paves the way to enable novel high spatial resolution BOTDA sensors, which brings substantial improvement over the state-of-the-art techniques in terms of system complexity, measurement time and reliability, etc.
PPINN: Parareal Physics-Informed Neural Network for time-dependent PDEs
Sep 23, 2019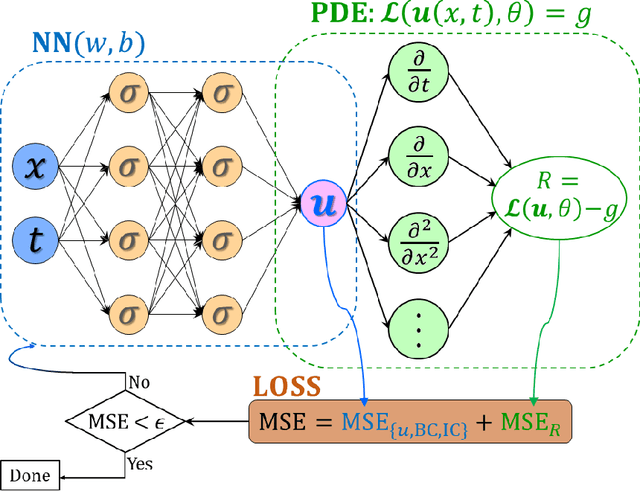
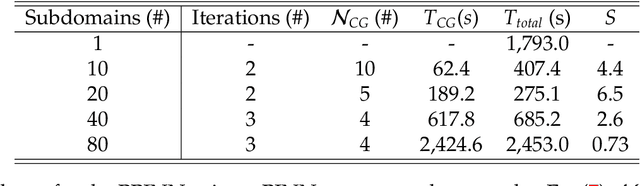
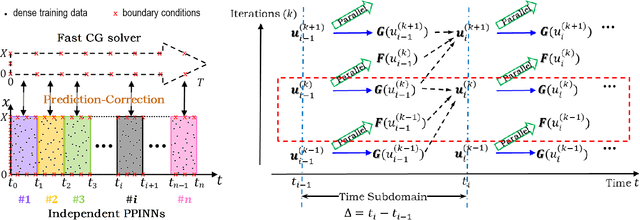
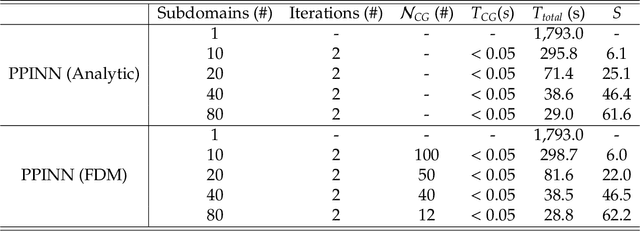
Physics-informed neural networks (PINNs) encode physical conservation laws and prior physical knowledge into the neural networks, ensuring the correct physics is represented accurately while alleviating the need for supervised learning to a great degree. While effective for relatively short-term time integration, when long time integration of the time-dependent PDEs is sought, the time-space domain may become arbitrarily large and hence training of the neural network may become prohibitively expensive. To this end, we develop a parareal physics-informed neural network (PPINN), hence decomposing a long-time problem into many independent short-time problems supervised by an inexpensive/fast coarse-grained (CG) solver. In particular, the serial CG solver is designed to provide approximate predictions of the solution at discrete times, while initiate many fine PINNs simultaneously to correct the solution iteratively. There is a two-fold benefit from training PINNs with small-data sets rather than working on a large-data set directly, i.e., training of individual PINNs with small-data is much faster, while training the fine PINNs can be readily parallelized. Consequently, compared to the original PINN approach, the proposed PPINN approach may achieve a significant speedup for long-time integration of PDEs, assuming that the CG solver is fast and can provide reasonable predictions of the solution, hence aiding the PPINN solution to converge in just a few iterations. To investigate the PPINN performance on solving time-dependent PDEs, we first apply the PPINN to solve the Burgers equation, and subsequently we apply the PPINN to solve a two-dimensional nonlinear diffusion-reaction equation. Our results demonstrate that PPINNs converge in a couple of iterations with significant speed-ups proportional to the number of time-subdomains employed.
A Machine-learning Framework for Acoustic Design Assessment in Early Design Stages
Sep 14, 2021
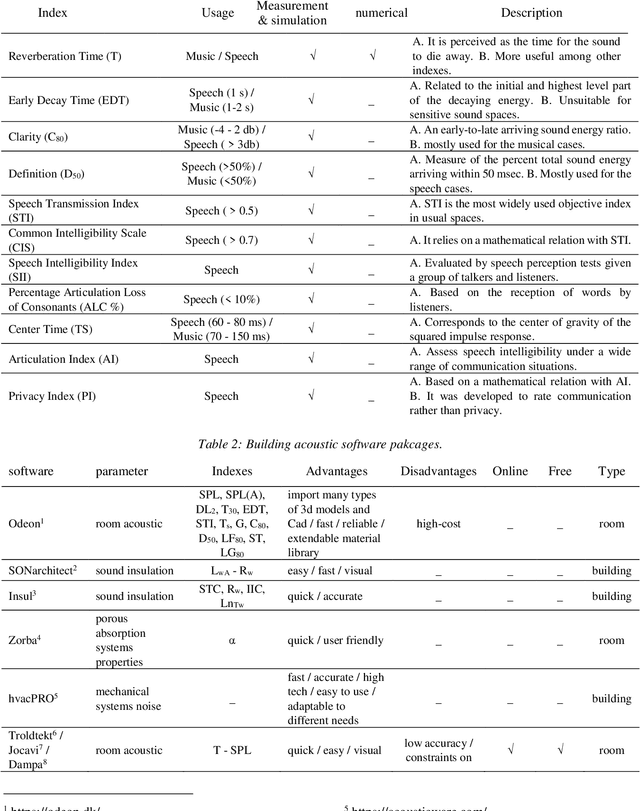
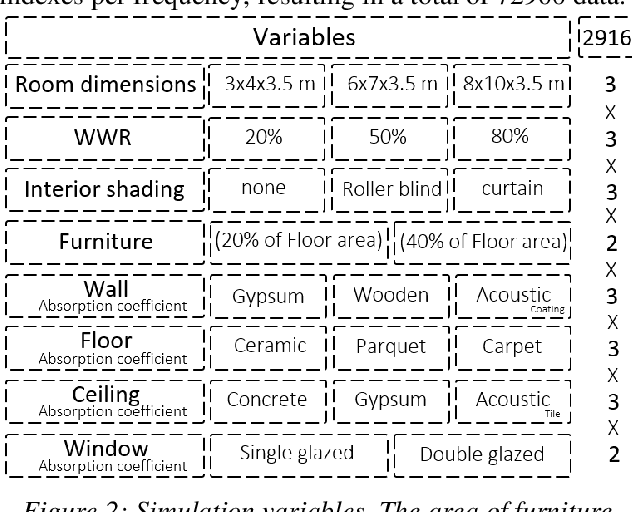
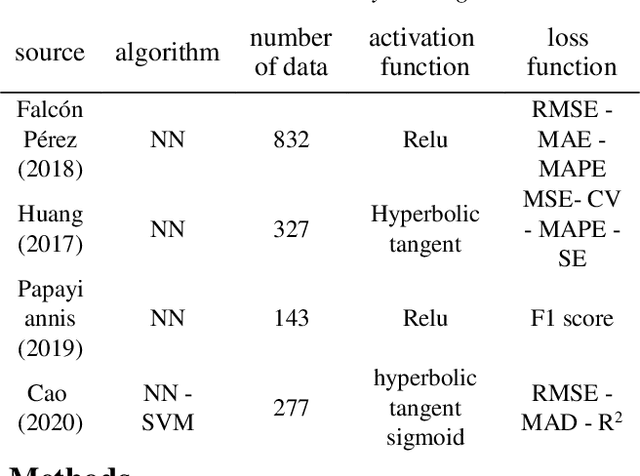
In time-cost scale model studies, predicting acoustic performance by using simulation methods is a commonly used method that is preferred. In this field, building acoustic simulation tools are complicated by several challenges, including the high cost of acoustic tools, the need for acoustic expertise, and the time-consuming process of acoustic simulation. The goal of this project is to introduce a simple model with a short calculation time to estimate the room acoustic condition in the early design stages of the building. This paper presents a working prototype for a new method of machine learning (ML) to approximate a series of typical room acoustic parameters using only geometric data as input characteristics. A novel dataset consisting of acoustical simulations of a single room with 2916 different configurations are used to train and test the proposed model. In the stimulation process, features that include room dimensions, window size, material absorption coefficient, furniture, and shading type have been analysed by using Pachyderm acoustic software. The mentioned dataset is used as the input of seven machine-learning models based on fully connected Deep Neural Networks (DNN). The average error of ML models is between 1% to 3%, and the average error of the new predicted samples after the validation process is between 2% to 12%.
Fast Neural Representations for Direct Volume Rendering
Dec 02, 2021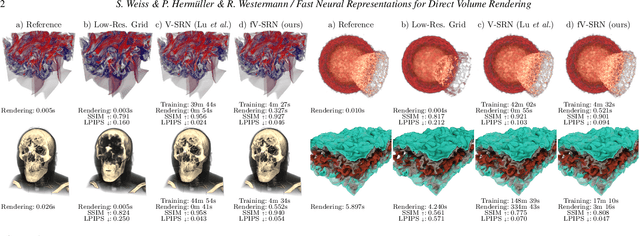

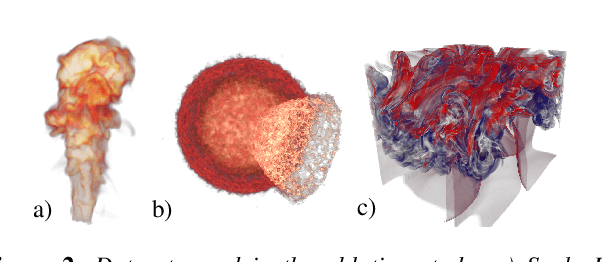
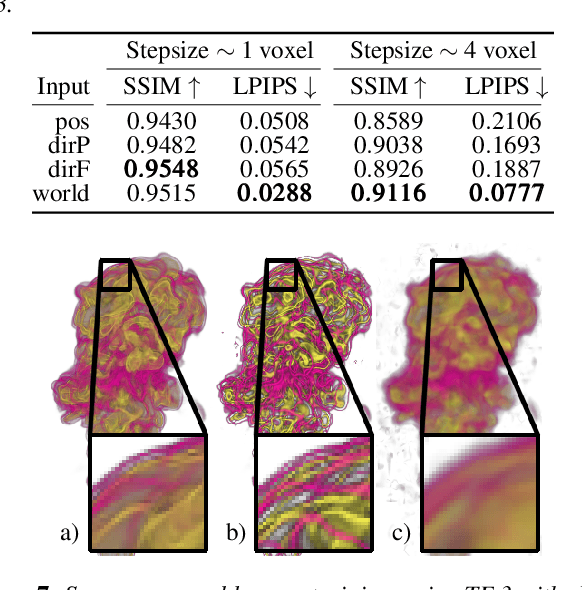
Despite the potential of neural scene representations to effectively compress 3D scalar fields at high reconstruction quality, the computational complexity of the training and data reconstruction step using scene representation networks limits their use in practical applications. In this paper, we analyze whether scene representation networks can be modified to reduce these limitations and whether these architectures can also be used for temporal reconstruction tasks. We propose a novel design of scene representation networks using GPU tensor cores to integrate the reconstruction seamlessly into on-chip raytracing kernels. Furthermore, we investigate the use of image-guided network training as an alternative to classical data-driven approaches, and we explore the potential strengths and weaknesses of this alternative regarding quality and speed. As an alternative to spatial super-resolution approaches for time-varying fields, we propose a solution that builds upon latent-space interpolation to enable random access reconstruction at arbitrary granularity. We summarize our findings in the form of an assessment of the strengths and limitations of scene representation networks for scientific visualization tasks and outline promising future research directions in this field.
Comparison of Different Methods for Time Sequence Prediction in Autonomous Vehicles
Jul 16, 2020
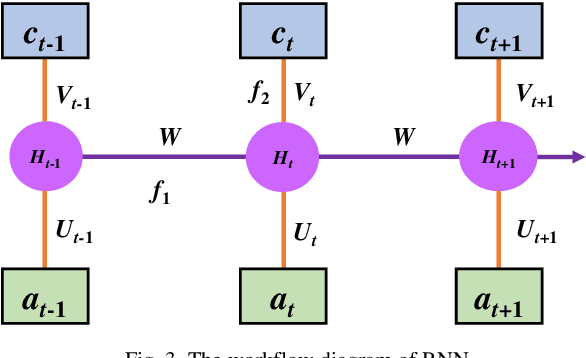
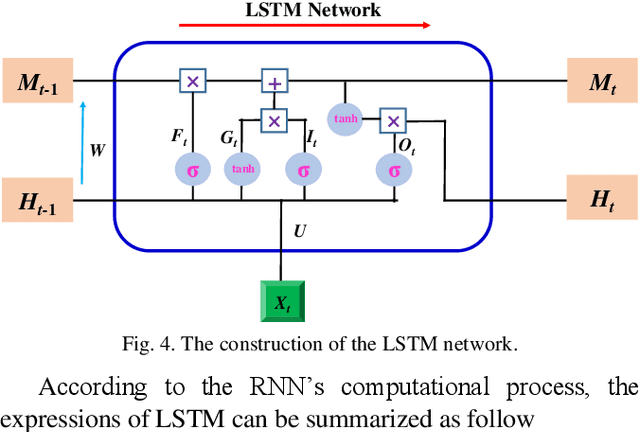
As a combination of various kinds of technologies, autonomous vehicles could complete a series of driving tasks by itself, such as perception, decision-making, planning, and control. Since there is no human driver to handle the emergency situation, future transportation information is significant for automated vehicles. This paper proposes different methods to forecast the time series for autonomous vehicles, which are the nearest neighborhood (NN), fuzzy coding (FC), and long short term memory (LSTM). First, the formulation and operational process for these three approaches are introduced. Then, the vehicle velocity is regarded as a case study and the real-world dataset is utilized to predict future information via these techniques. Finally, the performance, merits, and drawbacks of the presented methods are analyzed and discussed.
FastSurferVINN: Building Resolution-Independence into Deep Learning Segmentation Methods -- A Solution for HighRes Brain MRI
Dec 17, 2021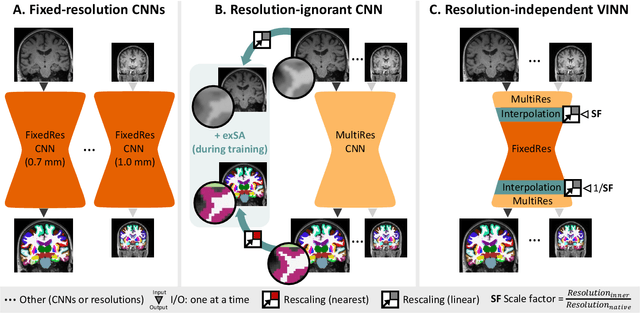

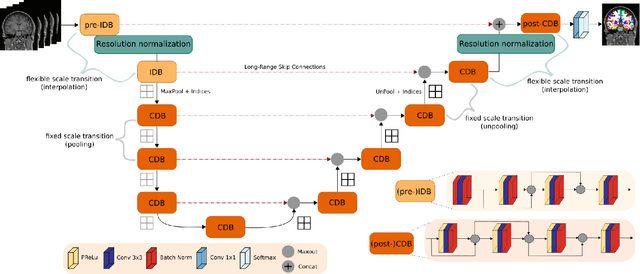
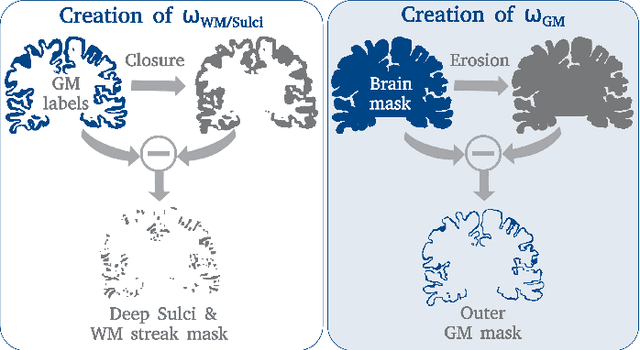
Leading neuroimaging studies have pushed 3T MRI acquisition resolutions below 1.0 mm for improved structure definition and morphometry. Yet, only few, time-intensive automated image analysis pipelines have been validated for high-resolution (HiRes) settings. Efficient deep learning approaches, on the other hand, rarely support more than one fixed resolution (usually 1.0 mm). Furthermore, the lack of a standard submillimeter resolution as well as limited availability of diverse HiRes data with sufficient coverage of scanner, age, diseases, or genetic variance poses additional, unsolved challenges for training HiRes networks. Incorporating resolution-independence into deep learning-based segmentation, i.e., the ability to segment images at their native resolution across a range of different voxel sizes, promises to overcome these challenges, yet no such approach currently exists. We now fill this gap by introducing a Voxelsize Independent Neural Network (VINN) for resolution-independent segmentation tasks and present FastSurferVINN, which (i) establishes and implements resolution-independence for deep learning as the first method simultaneously supporting 0.7-1.0 mm whole brain segmentation, (ii) significantly outperforms state-of-the-art methods across resolutions, and (iii) mitigates the data imbalance problem present in HiRes datasets. Overall, internal resolution-independence mutually benefits both HiRes and 1.0 mm MRI segmentation. With our rigorously validated FastSurferVINN we distribute a rapid tool for morphometric neuroimage analysis. The VINN architecture, furthermore, represents an efficient resolution-independent segmentation method for wider application
Implementation of interactive tools for investigating fundamental frequency response of voiced sounds to auditory stimulation
Sep 23, 2021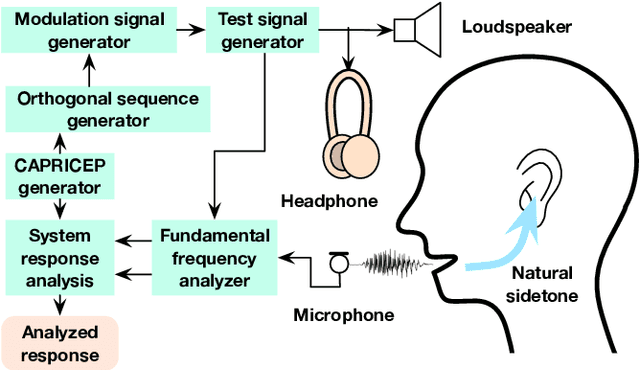
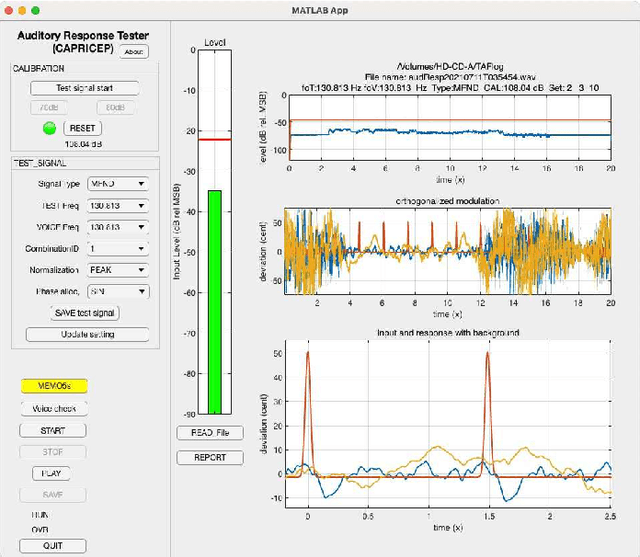
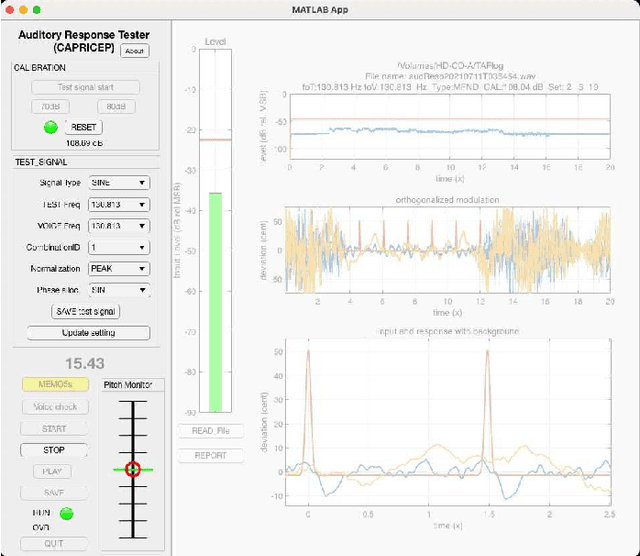
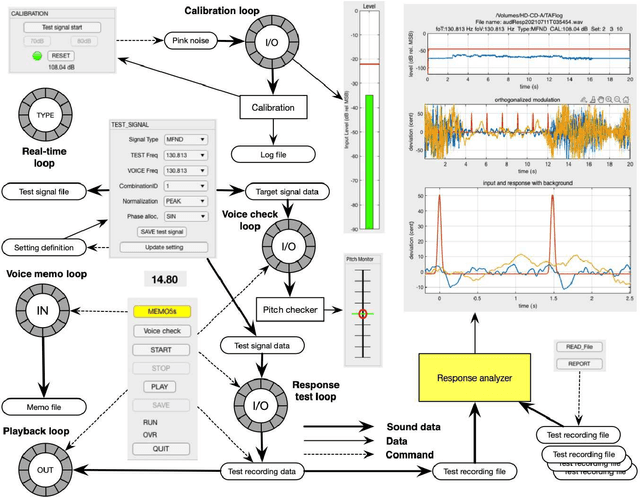
We introduced a measurement procedure for the involuntary response of voice fundamental-frequency to frequency modulated auditory stimulation. This involuntary response plays an essential role in voice fundamental frequency control while less investigated due to technical difficulties. This article introduces an interactive and real-time tool for investigating this response and supporting tools adopting our new measurement method. The method enables simultaneous measurement of multiple system properties based on a novel set of extended time-stretched pulses combined with orthogonalization. We made MATLAB implementation of these tools available as an open-source repository. This article also provides the detailed measurement procedure using the interactive tool followed by offline measurement tools for conducting subjective experiments and statistical analyses. It also provides technical descriptions of constituent signal processing subsystems as appendices. This application serves as an example for adopting our method to biological system analysis.
An Investigation of Drivers' Dynamic Situational Trust in Conditionally Automated Driving
Dec 08, 2021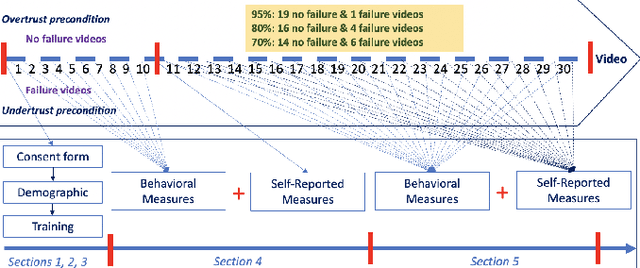
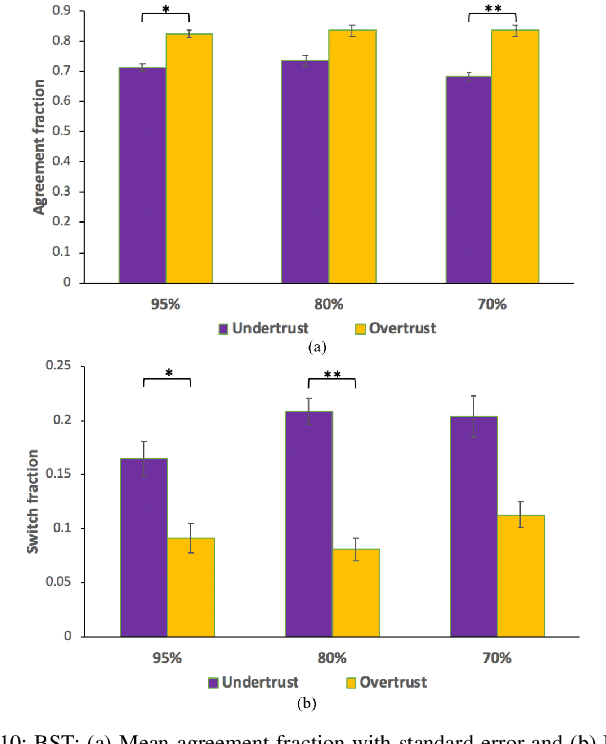
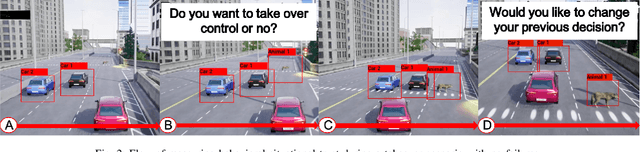

Understanding how trust is built over time is essential, as trust plays an important role in the acceptance and adoption of automated vehicles (AVs). This study aimed to investigate the effects of system performance and participants' trust preconditions on dynamic situational trust during takeover transitions. We evaluated the dynamic situational trust of 42 participants using both self-reported and behavioral measures while watching 30 videos with takeover scenarios. The study was a 3 by 2 mixed-subjects design, where the within-subjects variable was the system performance (i.e., accuracy levels of 95\%, 80\%, and 70\%) and the between-subjects variable was the preconditions of the participants' trust (i.e., overtrust and undertrust). Our results showed that participants quickly adjusted their self-reported situational trust (SST) levels which were consistent with different accuracy levels of system performance in both trust preconditions. However, participants' behavioral situational trust (BST) was affected by their trust preconditions across different accuracy levels. For instance, the overtrust precondition significantly increased the agreement fraction compared to the undertrust precondition. The undertrust precondition significantly decreased the switch fraction compared to the overtrust precondition. These results have important implications for designing an in-vehicle trust calibration system for conditional AVs.