 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Signal Classification using Smooth Coefficients of Multiple wavelets
Sep 21, 2021
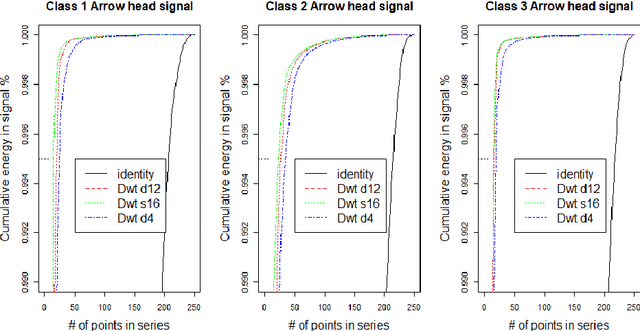
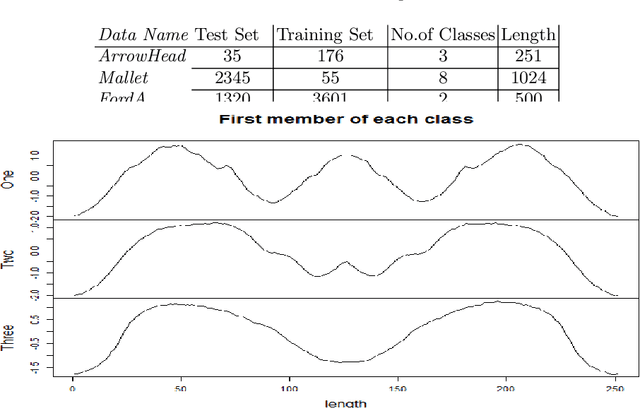
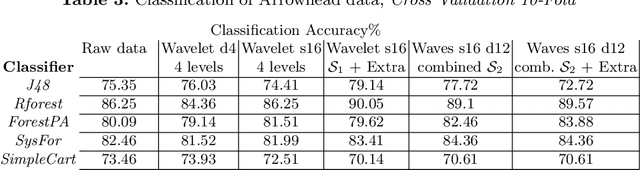
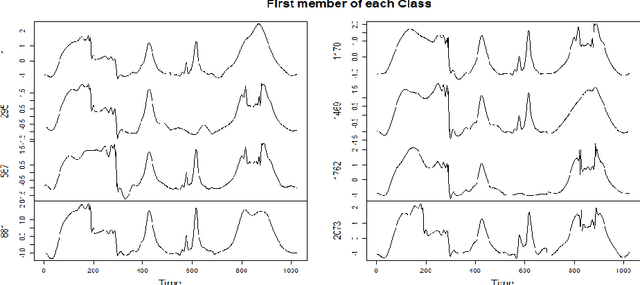
Classification of time series signals has become an important construct and has many practical applications. With existing classifiers we may be able to accurately classify signals, however that accuracy may decline if using a reduced number of attributes. Transforming the data then undertaking reduction in dimensionality may improve the quality of the data analysis, decrease time required for classification and simplify models. We propose an approach, which chooses suitable wavelets to transform the data, then combines the output from these transforms to construct a dataset to then apply ensemble classifiers to. We demonstrate this on different data sets, across different classifiers and use differing evaluation methods. Our experimental results demonstrate the effectiveness of the proposed technique, compared to the approaches that use either raw signal data or a single wavelet transform.
Distributed Estimation of Sparse Inverse Covariance Matrices
Sep 24, 2021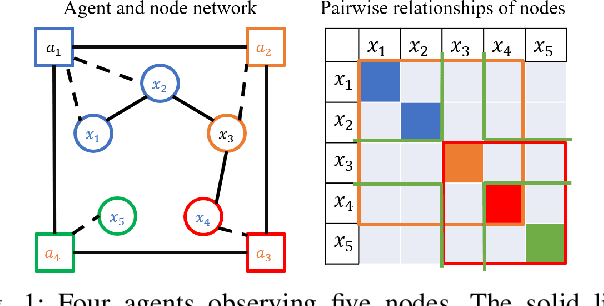
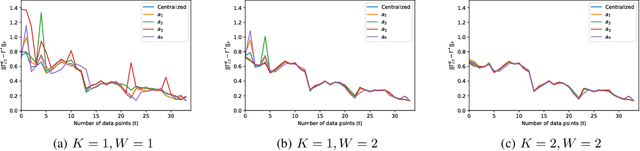
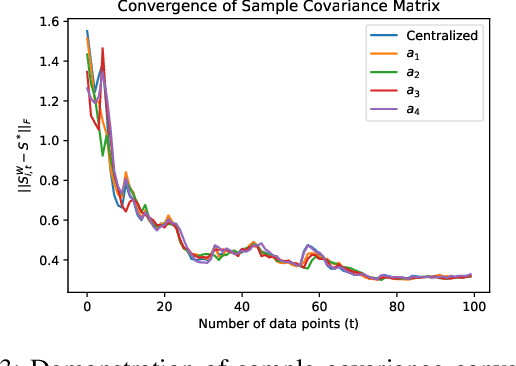
Learning the relationships between various entities from time-series data is essential in many applications. Gaussian graphical models have been studied to infer these relationships. However, existing algorithms process data in a batch at a central location, limiting their applications in scenarios where data is gathered by different agents. In this paper, we propose a distributed sparse inverse covariance algorithm to learn the network structure (i.e., dependencies among observed entities) in real-time from data collected by distributed agents. Our approach is built on an online graphical alternating minimization algorithm, augmented with a consensus term that allows agents to learn the desired structure cooperatively. We allow the system designer to select the number of communication rounds and optimization steps per data point. We characterize the rate of convergence of our algorithm and provide simulations on synthetic datasets.
Interpolation-Prediction Networks for Irregularly Sampled Time Series
Sep 13, 2019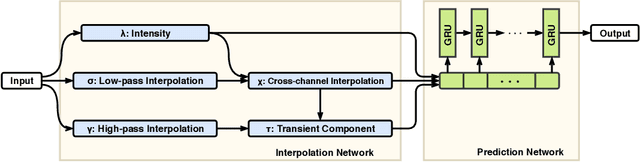
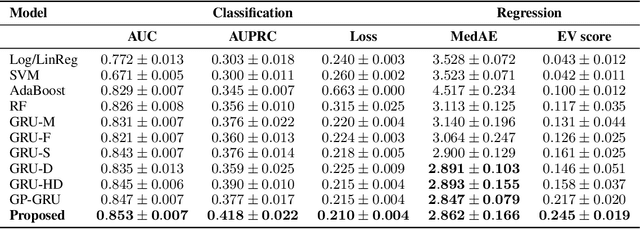
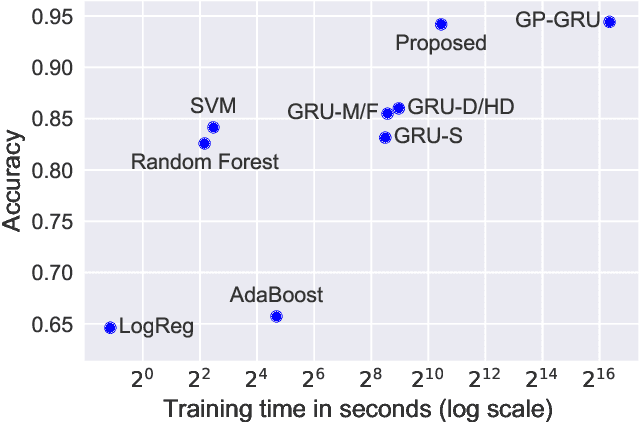

In this paper, we present a new deep learning architecture for addressing the problem of supervised learning with sparse and irregularly sampled multivariate time series. The architecture is based on the use of a semi-parametric interpolation network followed by the application of a prediction network. The interpolation network allows for information to be shared across multiple dimensions of a multivariate time series during the interpolation stage, while any standard deep learning model can be used for the prediction network. This work is motivated by the analysis of physiological time series data in electronic health records, which are sparse, irregularly sampled, and multivariate. We investigate the performance of this architecture on both classification and regression tasks, showing that our approach outperforms a range of baseline and recently proposed models.
Novel Hybrid DNN Approaches for Speaker Verification in Emotional and Stressful Talking Environments
Dec 26, 2021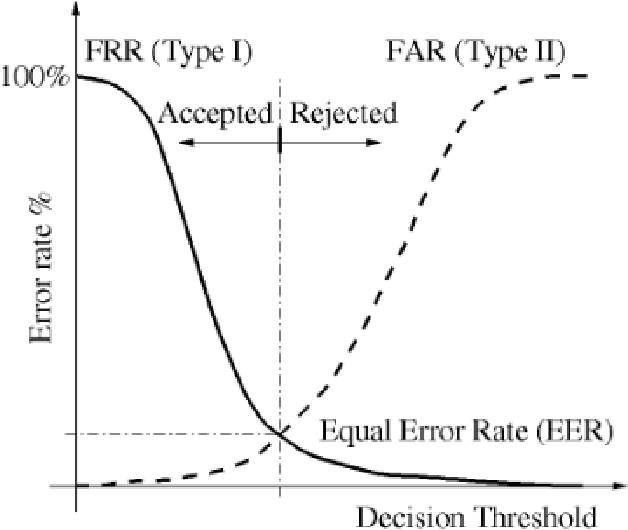
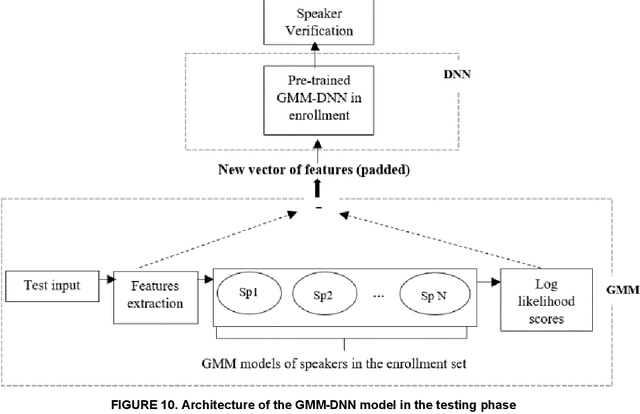
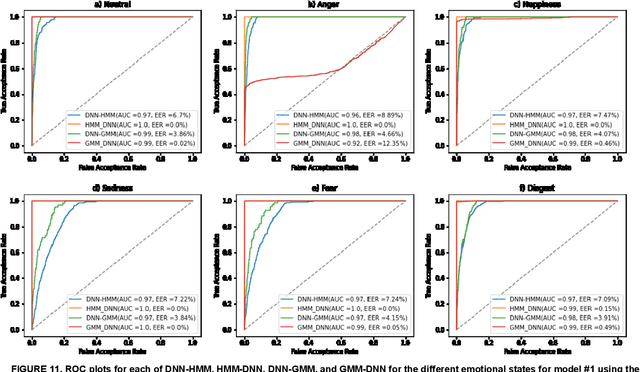
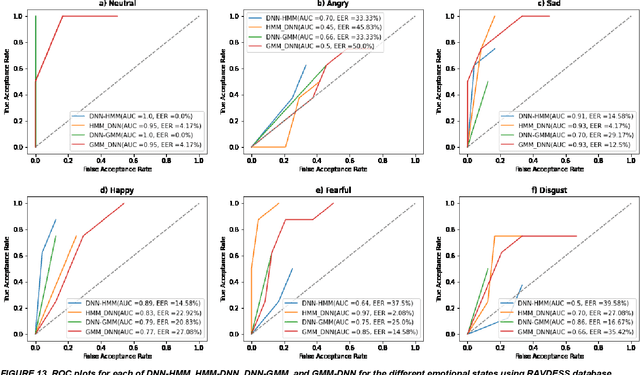
In this work, we conducted an empirical comparative study of the performance of text-independent speaker verification in emotional and stressful environments. This work combined deep models with shallow architecture, which resulted in novel hybrid classifiers. Four distinct hybrid models were utilized: deep neural network-hidden Markov model (DNN-HMM), deep neural network-Gaussian mixture model (DNN-GMM), Gaussian mixture model-deep neural network (GMM-DNN), and hidden Markov model-deep neural network (HMM-DNN). All models were based on novel implemented architecture. The comparative study used three distinct speech datasets: a private Arabic dataset and two public English databases, namely, Speech Under Simulated and Actual Stress (SUSAS) and Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS). The test results of the aforementioned hybrid models demonstrated that the proposed HMM-DNN leveraged the verification performance in emotional and stressful environments. Results also showed that HMM-DNN outperformed all other hybrid models in terms of equal error rate (EER) and area under the curve (AUC) evaluation metrics. The average resulting verification system based on the three datasets yielded EERs of 7.19%, 16.85%, 11.51%, and 11.90% based on HMM-DNN, DNN-HMM, DNN-GMM, and GMM-DNN, respectively. Furthermore, we found that the DNN-GMM model demonstrated the least computational complexity compared to all other hybrid models in both talking environments. Conversely, the HMM-DNN model required the greatest amount of training time. Findings also demonstrated that EER and AUC values depended on the database when comparing average emotional and stressful performances.
* 23 pages, 13 figures
Spatio-Temporal Urban Knowledge Graph Enabled Mobility Prediction
Nov 01, 2021
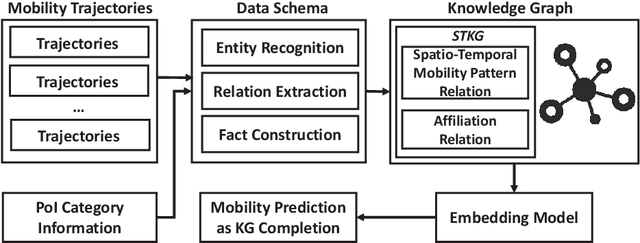

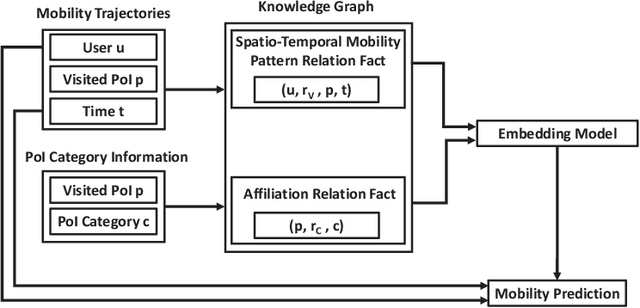
With the rapid development of the mobile communication technology, mobile trajectories of humans are massively collected by Internet service providers (ISPs) and application service providers (ASPs). On the other hand, the rising paradigm of knowledge graph (KG) provides us a promising solution to extract structured "knowledge" from massive trajectory data. In this paper, we focus on modeling users' spatio-temporal mobility patterns based on knowledge graph techniques, and predicting users' future movement based on the ``knowledge'' extracted from multiple sources in a cohesive manner. Specifically, we propose a new type of knowledge graph, i.e., spatio-temporal urban knowledge graph (STKG), where mobility trajectories, category information of venues, and temporal information are jointly modeled by the facts with different relation types in STKG. The mobility prediction problem is converted to the knowledge graph completion problem in STKG. Further, a complex embedding model with elaborately designed scoring functions is proposed to measure the plausibility of facts in STKG to solve the knowledge graph completion problem, which considers temporal dynamics of the mobility patterns and utilizes PoI categories as the auxiliary information and background knowledge. Extensive evaluations confirm the high accuracy of our model in predicting users' mobility, i.e., improving the accuracy by 5.04% compared with the state-of-the-art algorithms. In addition, PoI categories as the background knowledge and auxiliary information are confirmed to be helpful by improving the performance by 3.85% in terms of accuracy. Additionally, experiments show that our proposed method is time-efficient by reducing the computational time by over 43.12% compared with existing methods.
Logic Shrinkage: Learned FPGA Netlist Sparsity for Efficient Neural Network Inference
Jan 02, 2022
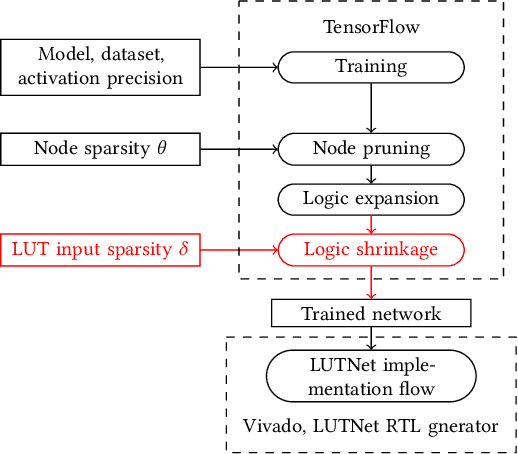

FPGA-specific DNN architectures using the native LUTs as independently trainable inference operators have been shown to achieve favorable area-accuracy and energy-accuracy tradeoffs. The first work in this area, LUTNet, exhibited state-of-the-art performance for standard DNN benchmarks. In this paper, we propose the learned optimization of such LUT-based topologies, resulting in higher-efficiency designs than via the direct use of off-the-shelf, hand-designed networks. Existing implementations of this class of architecture require the manual specification of the number of inputs per LUT, K. Choosing appropriate K a priori is challenging, and doing so at even high granularity, e.g. per layer, is a time-consuming and error-prone process that leaves FPGAs' spatial flexibility underexploited. Furthermore, prior works see LUT inputs connected randomly, which does not guarantee a good choice of network topology. To address these issues, we propose logic shrinkage, a fine-grained netlist pruning methodology enabling K to be automatically learned for every LUT in a neural network targeted for FPGA inference. By removing LUT inputs determined to be of low importance, our method increases the efficiency of the resultant accelerators. Our GPU-friendly solution to LUT input removal is capable of processing large topologies during their training with negligible slowdown. With logic shrinkage, we better the area and energy efficiency of the best-performing LUTNet implementation of the CNV network classifying CIFAR-10 by 1.54x and 1.31x, respectively, while matching its accuracy. This implementation also reaches 2.71x the area efficiency of an equally accurate, heavily pruned BNN. On ImageNet with the Bi-Real Net architecture, employment of logic shrinkage results in a post-synthesis area reduction of 2.67x vs LUTNet, allowing for implementation that was previously impossible on today's largest FPGAs.
Efficient and Optimal Algorithms for Contextual Dueling Bandits under Realizability
Nov 24, 2021We study the $K$-armed contextual dueling bandit problem, a sequential decision making setting in which the learner uses contextual information to make two decisions, but only observes \emph{preference-based feedback} suggesting that one decision was better than the other. We focus on the regret minimization problem under realizability, where the feedback is generated by a pairwise preference matrix that is well-specified by a given function class $\mathcal F$. We provide a new algorithm that achieves the optimal regret rate for a new notion of best response regret, which is a strictly stronger performance measure than those considered in prior works. The algorithm is also computationally efficient, running in polynomial time assuming access to an online oracle for square loss regression over $\mathcal F$. This resolves an open problem of Dud\'ik et al. [2015] on oracle efficient, regret-optimal algorithms for contextual dueling bandits.
VirtualCube: An Immersive 3D Video Communication System
Dec 13, 2021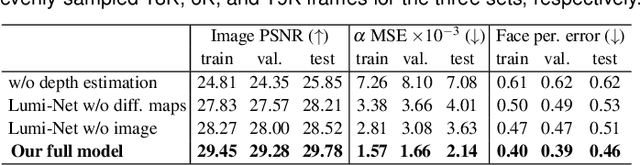
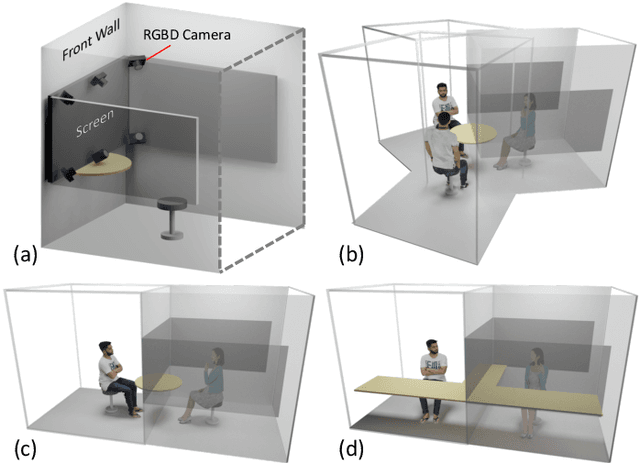

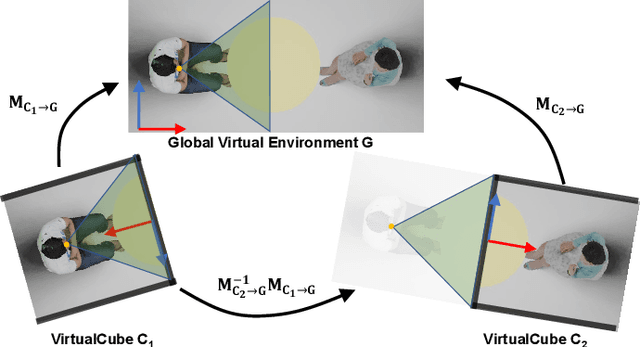
The VirtualCube system is a 3D video conference system that attempts to overcome some limitations of conventional technologies. The key ingredient is VirtualCube, an abstract representation of a real-world cubicle instrumented with RGBD cameras for capturing the 3D geometry and texture of a user. We design VirtualCube so that the task of data capturing is standardized and significantly simplified, and everything can be built using off-the-shelf hardware. We use VirtualCubes as the basic building blocks of a virtual conferencing environment, and we provide each VirtualCube user with a surrounding display showing life-size videos of remote participants. To achieve real-time rendering of remote participants, we develop the V-Cube View algorithm, which uses multi-view stereo for more accurate depth estimation and Lumi-Net rendering for better rendering quality. The VirtualCube system correctly preserves the mutual eye gaze between participants, allowing them to establish eye contact and be aware of who is visually paying attention to them. The system also allows a participant to have side discussions with remote participants as if they were in the same room. Finally, the system sheds lights on how to support the shared space of work items (e.g., documents and applications) and track the visual attention of participants to work items.
Analogue Radio over Fiber aided Multi-service Communications for High Speed Trains
Nov 27, 2021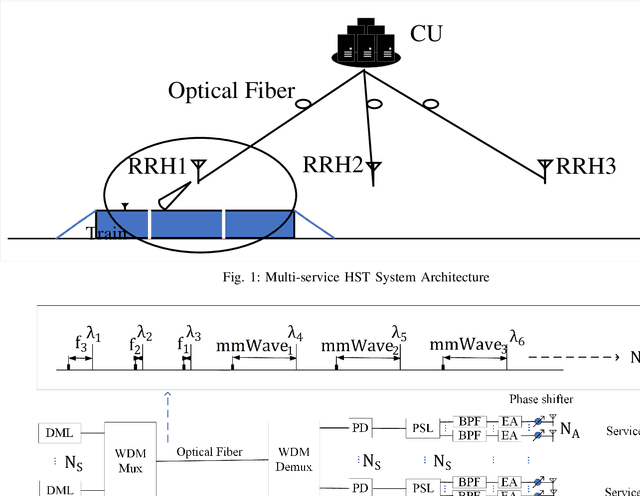
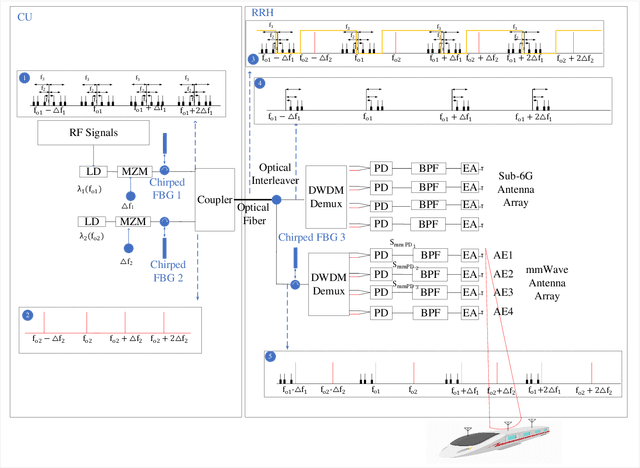
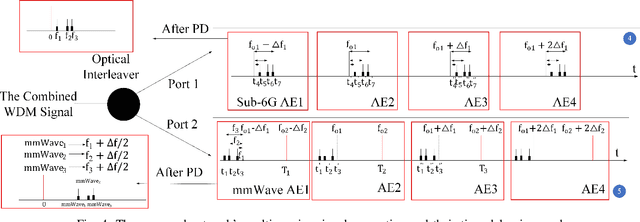
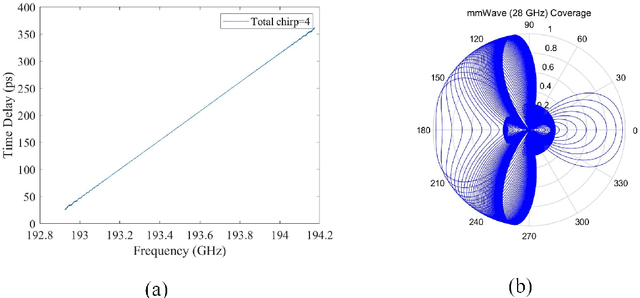
High speed trains (HST) have gradually become an essential means of transportation, where given our digital world, it is expected that passengers will be connected all the time. More specifically, the on-board passengers require fast mobile connections, which cannot be provided by the currently implemented cellular networks. Hence, in this article, we propose an analogue radio over fiber (A-RoF) aided multi-service network architecture for high-speed trains, in order to enhance the quality of service as well as reduce the cost of the radio access network (RAN). The proposed design can simultaneously support sub- 6GHz as well as milimeter wave (mmWave) communications using the same architecture. Explicitly, we design a photonics aided beamforming technique in order to eliminate the bulky high-speed electronic phase-shifters and the hostile broadband mmWave mixers while providing a low-cost RAN solution. Finally, a beamforming range of 180 is demonstrated with a high resolution using our proposed system.
A Primal Approach to Constrained Policy Optimization: Global Optimality and Finite-Time Analysis
Nov 11, 2020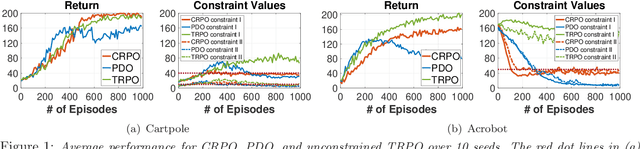
Safe reinforcement learning (SRL) problems are typically modeled as constrained Markov Decision Process (CMDP), in which an agent explores the environment to maximize the expected total reward and meanwhile avoids violating certain constraints on a number of expected total costs. In general, such SRL problems have nonconvex objective functions subject to multiple nonconvex constraints, and hence are very challenging to solve, particularly to provide a globally optimal policy. Many popular SRL algorithms adopt a primal-dual structure which utilizes the updating of dual variables for satisfying the constraints. In contrast, we propose a primal approach, called constraint-rectified policy optimization (CRPO), which updates the policy alternatingly between objective improvement and constraint satisfaction. CRPO provides a primal-type algorithmic framework to solve SRL problems, where each policy update can take any variant of policy optimization step. To demonstrate the theoretical performance of CRPO, we adopt natural policy gradient (NPG) for each policy update step and show that CRPO achieves an $\mathcal{O}(1/\sqrt{T})$ convergence rate to the global optimal policy in the constrained policy set and an $\mathcal{O}(1/\sqrt{T})$ error bound on constraint satisfaction. This is the first finite-time analysis of SRL algorithms with global optimality guarantee. Our empirical results demonstrate that CRPO can outperform the existing primal-dual baseline algorithms significantly.