 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Dr.Aid: Supporting Data-governance Rule Compliance for Decentralized Collaboration in an Automated Way
Oct 03, 2021


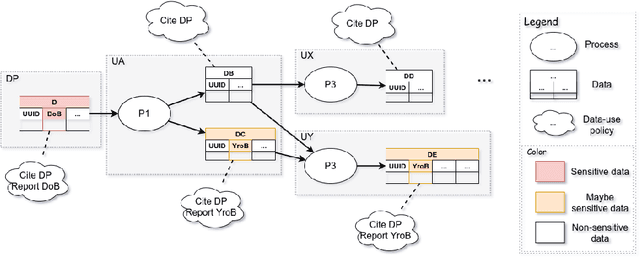
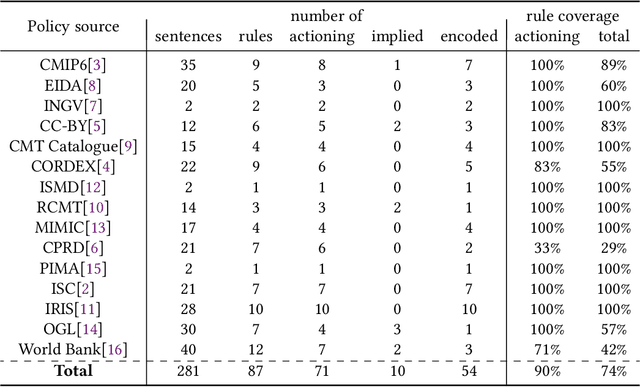
Collaboration across institutional boundaries is widespread and increasing today. It depends on federations sharing data that often have governance rules or external regulations restricting their use. However, the handling of data governance rules (aka. data-use policies) remains manual, time-consuming and error-prone, limiting the rate at which collaborations can form and respond to challenges and opportunities, inhibiting citizen science and reducing data providers' trust in compliance. Using an automated system to facilitate compliance handling reduces substantially the time needed for such non-mission work, thereby accelerating collaboration and improving productivity. We present a framework, Dr.Aid, that helps individuals, organisations and federations comply with data rules, using automation to track which rules are applicable as data is passed between processes and as derived data is generated. It encodes data-governance rules using a formal language and performs reasoning on multi-input-multi-output data-flow graphs in decentralised contexts. We test its power and utility by working with users performing cyclone tracking and earthquake modelling to support mitigation and emergency response. We query standard provenance traces to detach Dr.Aid from details of the tools and systems they are using, as these inevitably vary across members of a federation and through time. We evaluate the model in three aspects by encoding real-life data-use policies from diverse fields, showing its capability for real-world usage and its advantages compared with traditional frameworks. We argue that this approach will lead to more agile, more productive and more trustworthy collaborations and show that the approach can be adopted incrementally. This, in-turn, will allow more appropriate data policies to emerge opening up new forms of collaboration.
SMARRT: Self-Repairing Motion-Reactive Anytime RRT for Dynamic Environments
Sep 10, 2021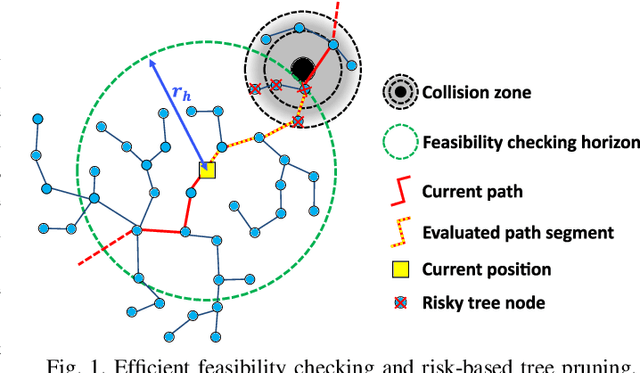
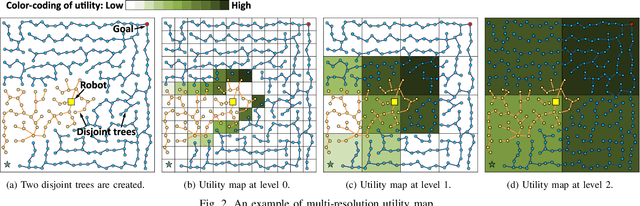
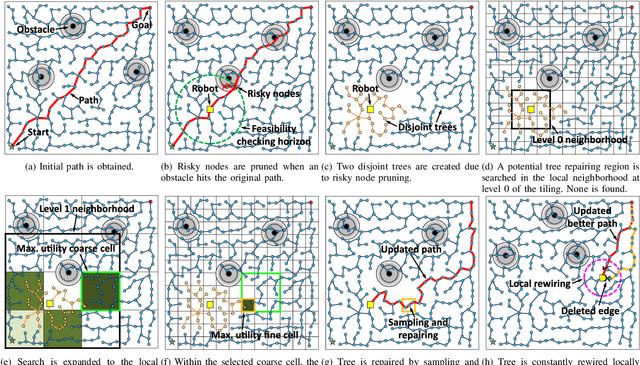
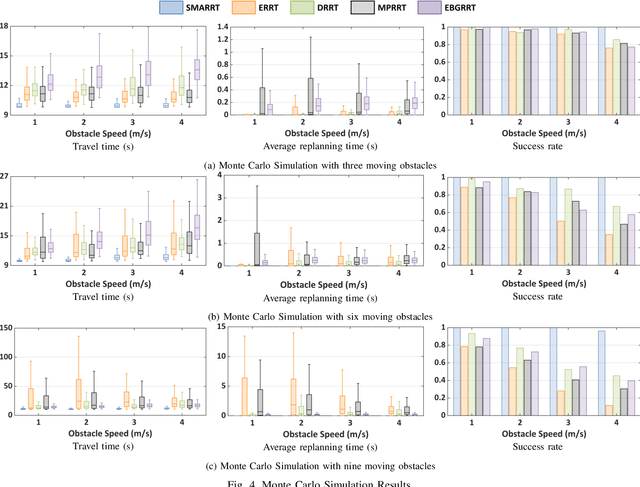
This paper addresses the fast replanning problem in dynamic environments with moving obstacles. Since for randomly moving obstacles the future states are unpredictable, the proposed method, called SMARRT, reacts to obstacle motions and revises the path in real-time based on the current interfering obstacle state (i.e., position and velocity). SMARRT is fast and efficient and performs collision checking only on the partial path segment close to the robot within a feasibility checking horizon. If the path is infeasible, then tree parts associated with the path inside the horizon are pruned while maintaining the maximal tree structure of already-explored regions. Then, a multi-resolution utility map is created to capture the environmental information used to compute the replanning utility for each cell on the multi-scale tiling. A hierarchical searching method is applied on the map to find the sampling cell efficiently. Finally, uniform samples are drawn within the sampling cell for fast replanning. The SMARRT method is validated via simulation runs, and the results are evaluated in comparison to four existing methods. The SMARRT method yields significant improvements in travel time, replanning time, and success rate compared against the existing methods.
Estimating Parameters of the Tree Root in Heterogeneous Soil Environments via Mask-Guided Multi-Polarimetric Integration Neural Network
Dec 27, 2021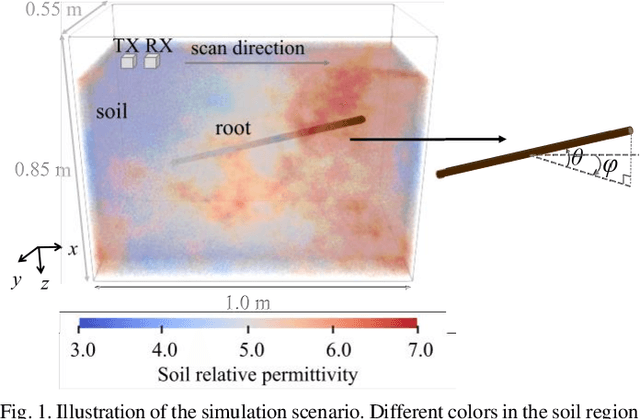

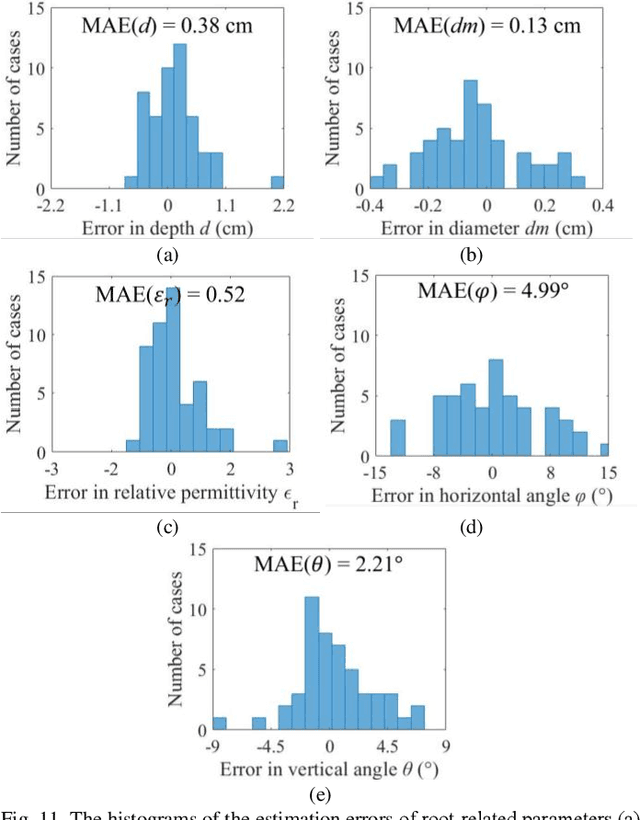
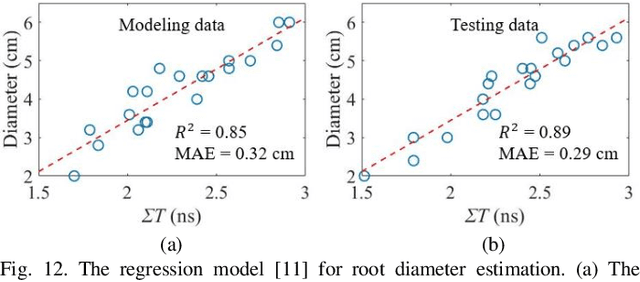
Ground-penetrating radar (GPR) has been used as a non-destructive tool for tree root inspection. Estimating root-related parameters from GPR radargrams greatly facilitates root health monitoring and imaging. However, the task of estimating root-related parameters is challenging as the root reflection is a complex function of multiple root parameters and root orientations. Existing methods can only estimate a single root parameter at a time without considering the influence of other parameters and root orientations, resulting in limited estimation accuracy under different root conditions. In addition, soil heterogeneity introduces clutter in GPR radargrams, making the data processing and interpretation even harder. To address these issues, a novel neural network architecture, called mask-guided multi-polarimetric integration neural network (MMI-Net), is proposed to automatically and simultaneously estimate multiple root-related parameters in heterogeneous soil environments. The MMI-Net includes two sub-networks: a MaskNet that predicts a mask to highlight the root reflection area to eliminate interfering environmental clutter, and a ParaNet that uses the predicted mask as guidance to integrate, extract, and emphasize informative features in multi-polarimetric radargrams for accurate estimation of five key root-related parameters. The parameters include the root depth, diameter, relative permittivity, horizontal and vertical orientation angles. Experimental results demonstrate that the proposed MMI-Net achieves high estimation accuracy in these root-related parameters. This is the first work that takes the combined contributions of root parameters and spatial orientations into account and simultaneously estimates multiple root-related parameters. The data and code implemented in the paper can be found at https://haihan-sun.github.io/GPR.html.
Progressive Attention on Multi-Level Dense Difference Maps for Generic Event Boundary Detection
Dec 09, 2021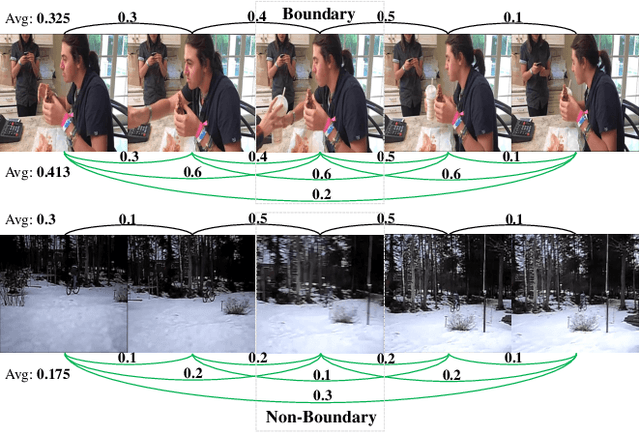
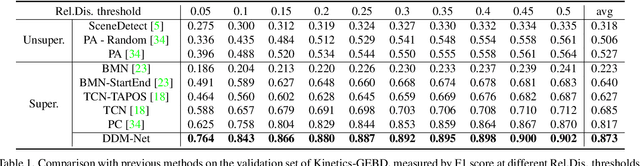
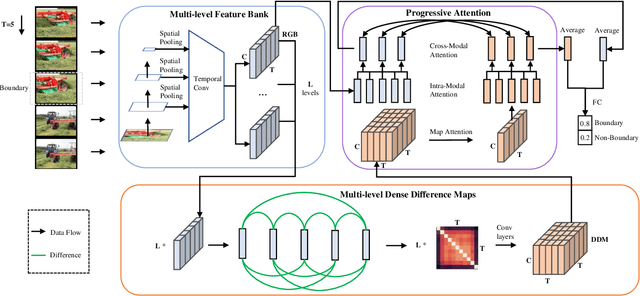
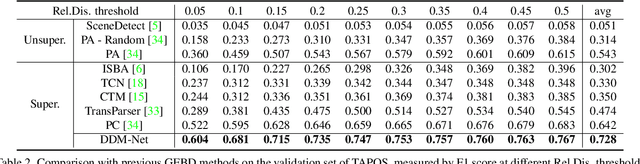
Generic event boundary detection is an important yet challenging task in video understanding, which aims at detecting the moments where humans naturally perceive event boundaries. The main challenge of this task is perceiving various temporal variations of diverse event boundaries. To this end, this paper presents an effective and end-to-end learnable framework (DDM-Net). To tackle the diversity and complicated semantics of event boundaries, we make three notable improvements. First, we construct a feature bank to store multi-level features of space and time, prepared for difference calculation at multiple scales. Second, to alleviate inadequate temporal modeling of previous methods, we present dense difference maps (DDM) to comprehensively characterize the motion pattern. Finally, we exploit progressive attention on multi-level DDM to jointly aggregate appearance and motion clues. As a result, DDM-Net respectively achieves a significant boost of 14% and 8% on Kinetics-GEBD and TAPOS benchmark, and outperforms the top-1 winner solution of LOVEU Challenge@CVPR 2021 without bells and whistles. The state-of-the-art result demonstrates the effectiveness of richer motion representation and more sophisticated aggregation, in handling the diversity of generic event boundary detection. Our codes will be made available soon.
Prompt-Based Multi-Modal Image Segmentation
Dec 18, 2021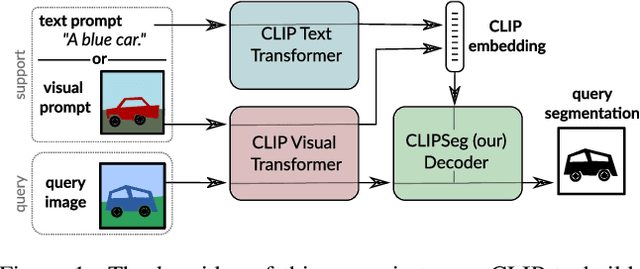

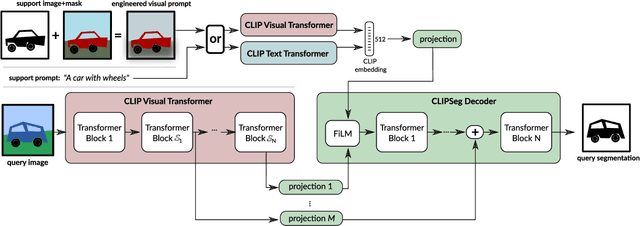

Image segmentation is usually addressed by training a model for a fixed set of object classes. Incorporating additional classes or more complex queries later is expensive as it requires re-training the model on a dataset that encompasses these expressions. Here we propose a system that can generate image segmentations based on arbitrary prompts at test time. A prompt can be either a text or an image. This approach enables us to create a unified model (trained once) for three common segmentation tasks, which come with distinct challenges: referring expression segmentation, zero-shot segmentation and one-shot segmentation. We build upon the CLIP model as a backbone which we extend with a transformer-based decoder that enables dense prediction. After training on an extended version of the PhraseCut dataset, our system generates a binary segmentation map for an image based on a free-text prompt or on an additional image expressing the query. Different variants of the latter image-based prompts are analyzed in detail. This novel hybrid input allows for dynamic adaptation not only to the three segmentation tasks mentioned above, but to any binary segmentation task where a text or image query can be formulated. Finally, we find our system to adapt well to generalized queries involving affordances or properties. Source code: https://eckerlab.org/code/clipseg
An Autonomous Self-Incremental Learning Approach for Detection of Cyber Attacks on Unmanned Aerial Vehicles (UAVs)
Dec 18, 2021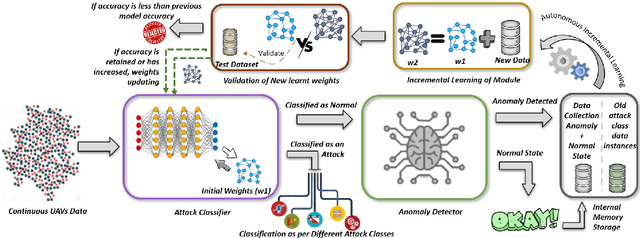
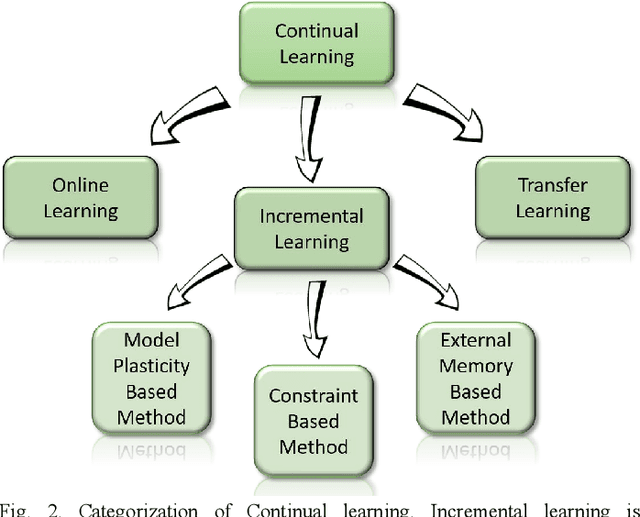
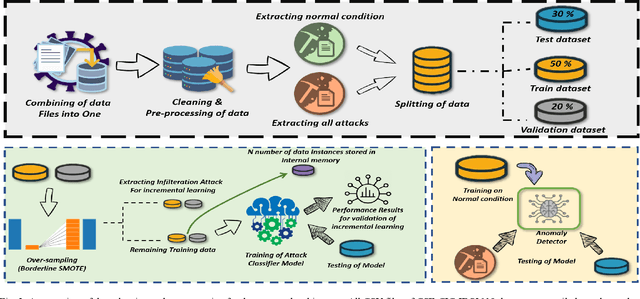
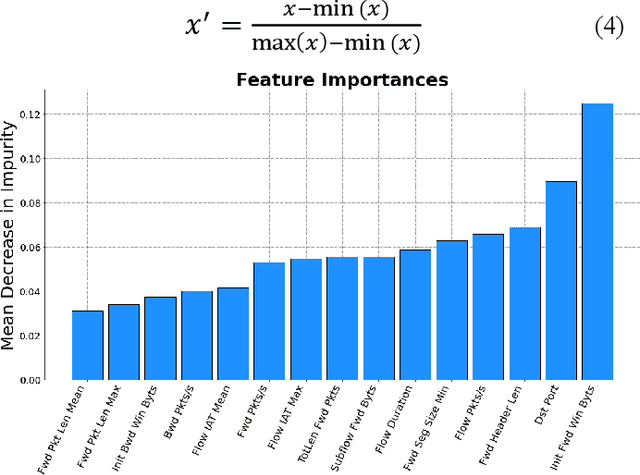
As the technological advancement and capabilities of automated systems have increased drastically, the usage of unmanned aerial vehicles for performing human-dependent tasks without human indulgence has also spiked. Since unmanned aerial vehicles are heavily dependent on Information and Communication Technology, they are highly prone to cyber-attacks. With time more advanced and new attacks are being developed and employed. However, the current Intrusion detection system lacks detection and classification of new and unknown attacks. Therefore, for having an autonomous and reliable operation of unmanned aerial vehicles, more robust and automated cyber detection and protection schemes are needed. To address this, we have proposed an autonomous self-incremental learning architecture, capable of detecting known and unknown cyber-attacks on its own without any human interference. In our approach, we have combined signature-based detection along with anomaly detection in such a way that the signature-based detector autonomously updates its attack classes with the help of an anomaly detector. To achieve this, we have implemented an incremental learning approach, updating our model to incorporate new classes without forgetting the old ones. To validate the applicability and effectiveness of our proposed architecture, we have implemented it in a trial scenario and then compared it with the traditional offline learning approach. Moreover, our anomaly-based detector has achieved a 100% detection rate for attacks.
Co-training Transformer with Videos and Images Improves Action Recognition
Dec 14, 2021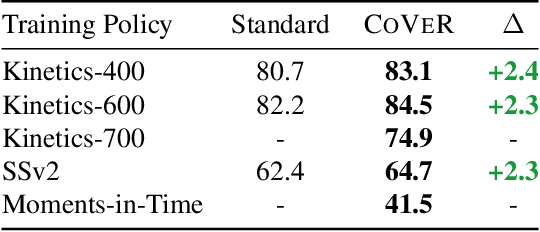
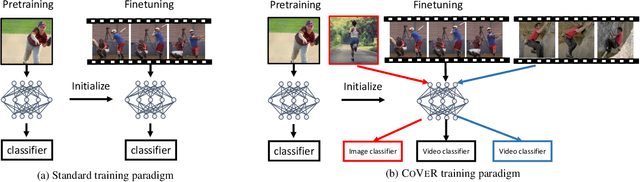

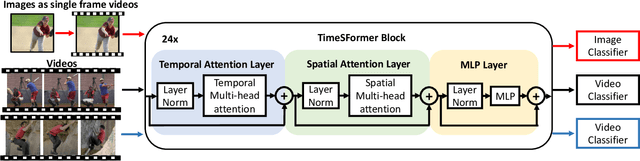
In learning action recognition, models are typically pre-trained on object recognition with images, such as ImageNet, and later fine-tuned on target action recognition with videos. This approach has achieved good empirical performance especially with recent transformer-based video architectures. While recently many works aim to design more advanced transformer architectures for action recognition, less effort has been made on how to train video transformers. In this work, we explore several training paradigms and present two findings. First, video transformers benefit from joint training on diverse video datasets and label spaces (e.g., Kinetics is appearance-focused while SomethingSomething is motion-focused). Second, by further co-training with images (as single-frame videos), the video transformers learn even better video representations. We term this approach as Co-training Videos and Images for Action Recognition (CoVeR). In particular, when pretrained on ImageNet-21K based on the TimeSFormer architecture, CoVeR improves Kinetics-400 Top-1 Accuracy by 2.4%, Kinetics-600 by 2.3%, and SomethingSomething-v2 by 2.3%. When pretrained on larger-scale image datasets following previous state-of-the-art, CoVeR achieves best results on Kinetics-400 (87.2%), Kinetics-600 (87.9%), Kinetics-700 (79.8%), SomethingSomething-v2 (70.9%), and Moments-in-Time (46.1%), with a simple spatio-temporal video transformer.
Which images to label for few-shot medical landmark detection?
Dec 09, 2021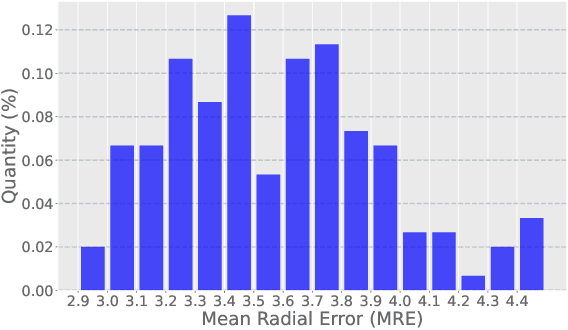

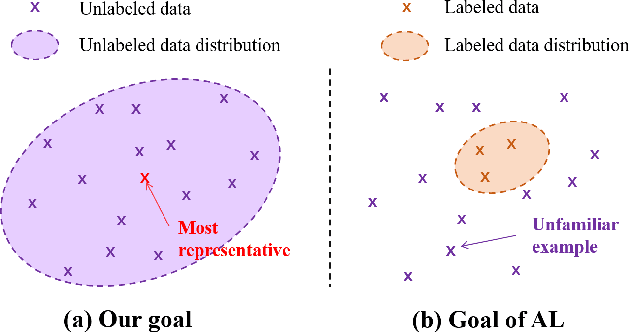
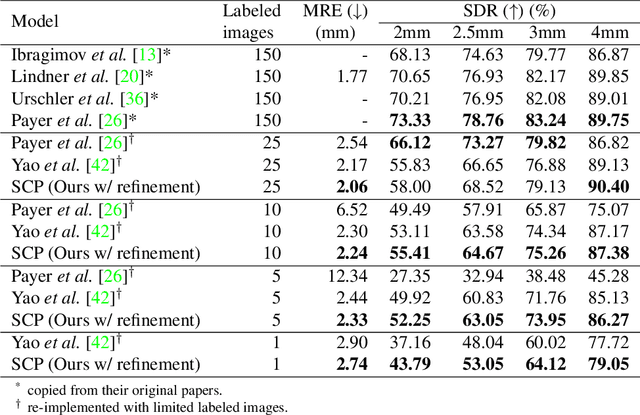
The success of deep learning methods relies on the availability of well-labeled large-scale datasets. However, for medical images, annotating such abundant training data often requires experienced radiologists and consumes their limited time. Few-shot learning is developed to alleviate this burden, which achieves competitive performances with only several labeled data. However, a crucial yet previously overlooked problem in few-shot learning is about the selection of template images for annotation before learning, which affects the final performance. We herein propose a novel Sample Choosing Policy (SCP) to select "the most worthy" images for annotation, in the context of few-shot medical landmark detection. SCP consists of three parts: 1) Self-supervised training for building a pre-trained deep model to extract features from radiological images, 2) Key Point Proposal for localizing informative patches, and 3) Representative Score Estimation for searching the most representative samples or templates. The advantage of SCP is demonstrated by various experiments on three widely-used public datasets. For one-shot medical landmark detection, its use reduces the mean radial errors on Cephalometric and HandXray datasets by 14.2% (from 3.595mm to 3.083mm) and 35.5% (4.114mm to 2.653mm), respectively.
Online Adaptation of Neural Network Models by Modified Extended Kalman Filter for Customizable and Transferable Driving Behavior Prediction
Dec 09, 2021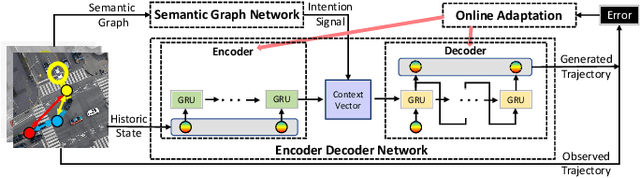
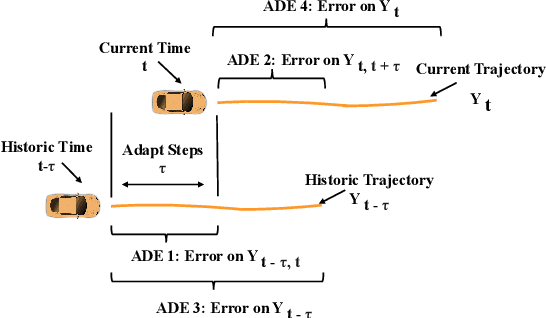
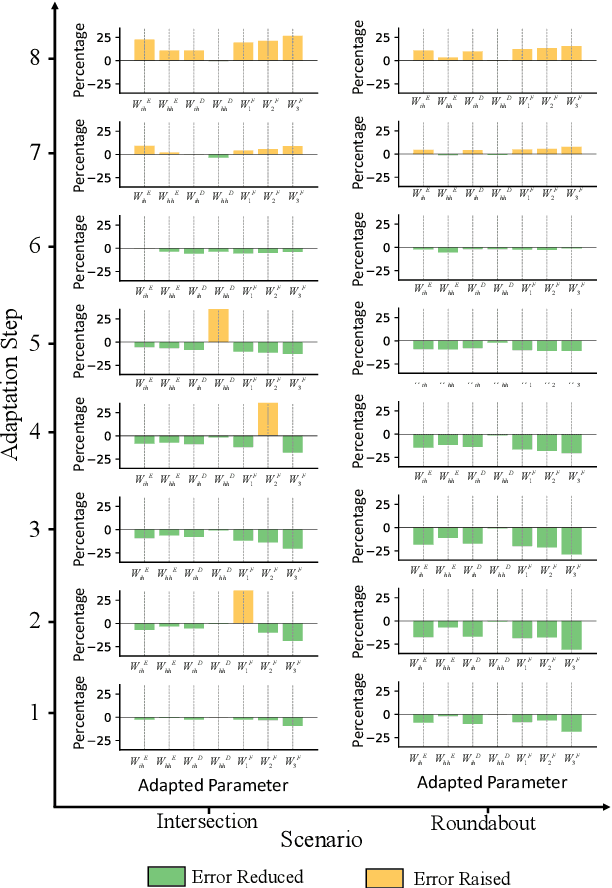
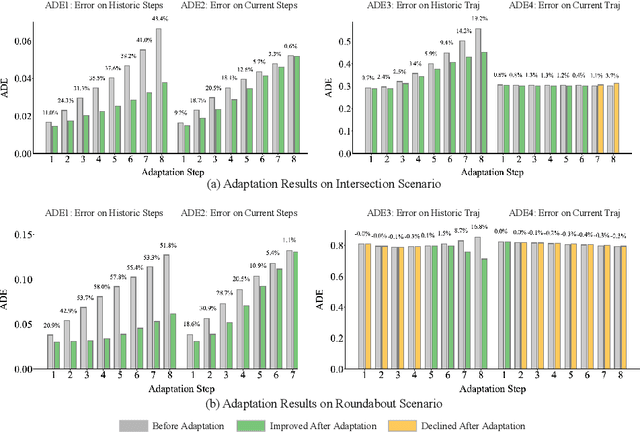
High fidelity behavior prediction of human drivers is crucial for efficient and safe deployment of autonomous vehicles, which is challenging due to the stochasticity, heterogeneity, and time-varying nature of human behaviors. On one hand, the trained prediction model can only capture the motion pattern in an average sense, while the nuances among individuals can hardly be reflected. On the other hand, the prediction model trained on the training set may not generalize to the testing set which may be in a different scenario or data distribution, resulting in low transferability and generalizability. In this paper, we applied a $\tau$-step modified Extended Kalman Filter parameter adaptation algorithm (MEKF$_\lambda$) to the driving behavior prediction task, which has not been studied before in literature. With the feedback of the observed trajectory, the algorithm is applied to neural-network-based models to improve the performance of driving behavior predictions across different human subjects and scenarios. A new set of metrics is proposed for systematic evaluation of online adaptation performance in reducing the prediction error for different individuals and scenarios. Empirical studies on the best layer in the model and steps of observation to adapt are also provided.
Interpolation-Prediction Networks for Irregularly Sampled Time Series
Sep 13, 2019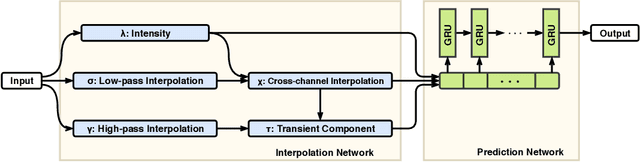
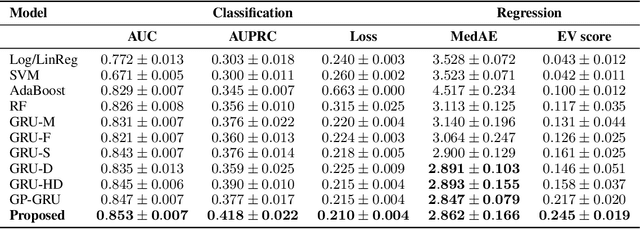
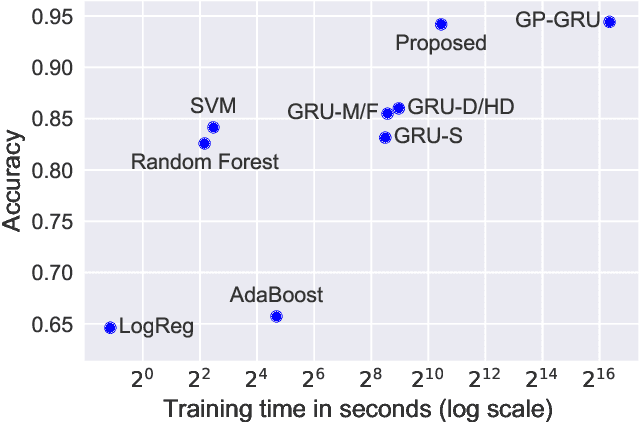

In this paper, we present a new deep learning architecture for addressing the problem of supervised learning with sparse and irregularly sampled multivariate time series. The architecture is based on the use of a semi-parametric interpolation network followed by the application of a prediction network. The interpolation network allows for information to be shared across multiple dimensions of a multivariate time series during the interpolation stage, while any standard deep learning model can be used for the prediction network. This work is motivated by the analysis of physiological time series data in electronic health records, which are sparse, irregularly sampled, and multivariate. We investigate the performance of this architecture on both classification and regression tasks, showing that our approach outperforms a range of baseline and recently proposed models.