 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Robust Real-Time Computing-based Environment Sensing System for Intelligent Vehicle
Jan 27, 2020
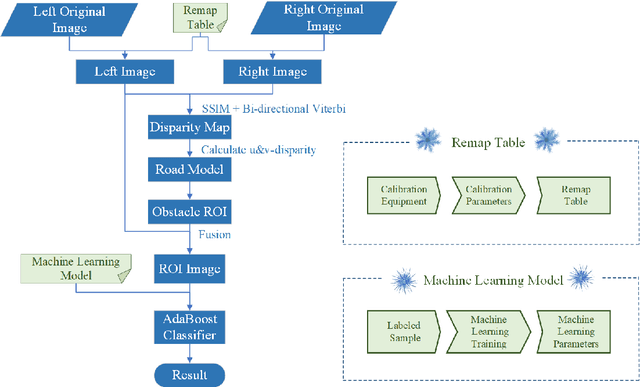
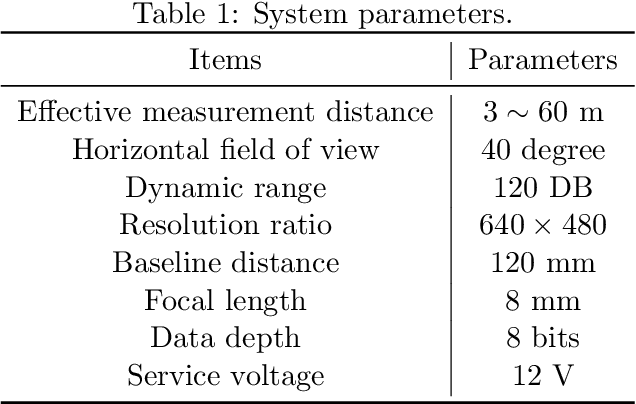

For intelligent vehicles, sensing the 3D environment is the first but crucial step. In this paper, we build a real-time advanced driver assistance system based on a low-power mobile platform. The system is a real-time multi-scheme integrated innovation system, which combines stereo matching algorithm with machine learning based obstacle detection approach and takes advantage of the distributed computing technology of a mobile platform with GPU and CPUs. First of all, a multi-scale fast MPV (Multi-Path-Viterbi) stereo matching algorithm is proposed, which can generate robust and accurate disparity map. Then a machine learning, which is based on fusion technology of monocular and binocular, is applied to detect the obstacles. We also advance an automatic fast calibration mechanism based on Zhang's calibration method. Finally, the distributed computing and reasonable data flow programming are applied to ensure the operational efficiency of the system. The experimental results show that the system can achieve robust and accurate real-time environment perception for intelligent vehicles, which can be directly used in the commercial real-time intelligent driving applications.
ToxTree: descriptor-based machine learning models for both hERG and Nav1.5 cardiotoxicity liability predictions
Dec 27, 2021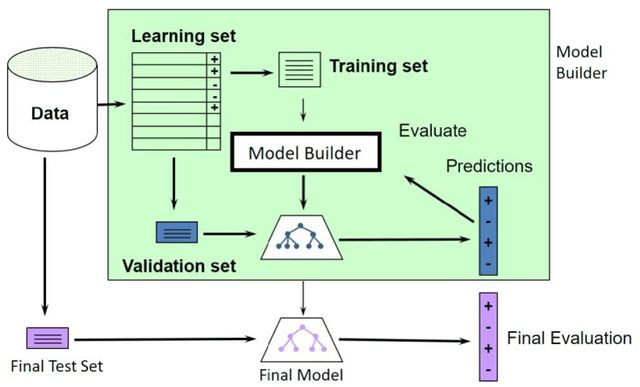
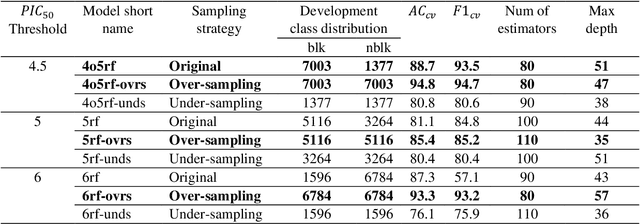
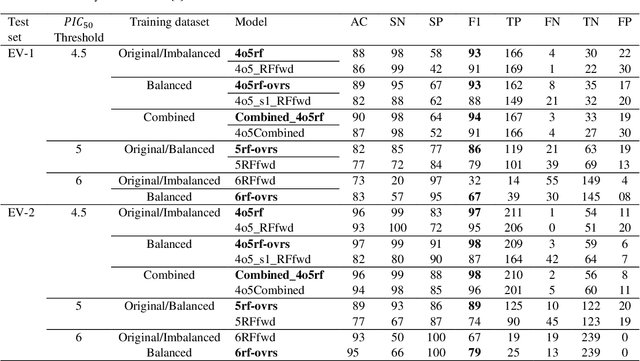
Drug-mediated blockade of the voltage-gated potassium channel(hERG) and the voltage-gated sodium channel (Nav1.5) can lead to severe cardiovascular complications. This rising concern has been reflected in the drug development arena, as the frequent emergence of cardiotoxicity from many approved drugs led to either discontinuing their use or, in some cases, their withdrawal from the market. Predicting potential hERG and Nav1.5 blockers at the outset of the drug discovery process can resolve this problem and can, therefore, decrease the time and expensive cost of developing safe drugs. One fast and cost-effective approach is to use in silico predictive methods to weed out potential hERG and Nav1.5 blockers at the early stages of drug development. Here, we introduce two robust 2D descriptor-based QSAR predictive models for both hERG and Nav1.5 liability predictions. The machine learning models were trained for both regression, predicting the potency value of a drug, and multiclass classification at three different potency cut-offs (i.e. 1$\mu$M, 10$\mu$M, and 30$\mu$M), where ToxTree-hERG Classifier, a pipeline of Random Forest models, was trained on a large curated dataset of 8380 unique molecular compounds. Whereas ToxTree-Nav1.5 Classifier, a pipeline of kernelized SVM models, was trained on a large manually curated set of 1550 unique compounds retrieved from both ChEMBL and PubChem publicly available bioactivity databases. The proposed hERG inducer outperformed most metrics of the state-of-the-art published model and other existing tools. Additionally, we are introducing the first Nav1.5 liability predictive model achieving a Q4 = 74.9% and a binary classification of Q2 = 86.7% with MCC = 71.2% evaluated on an external test set of 173 unique compounds. The curated datasets used in this project are made publicly available to the research community.
Batched Data-Driven Evolutionary Multi-Objective Optimization Based on Manifold Interpolation
Sep 12, 2021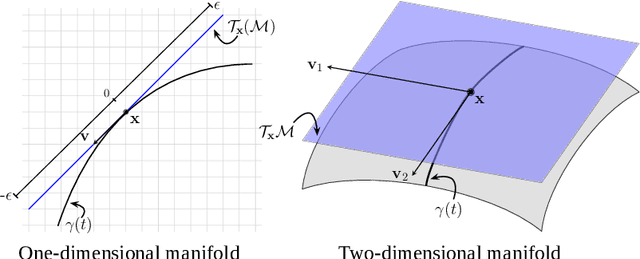


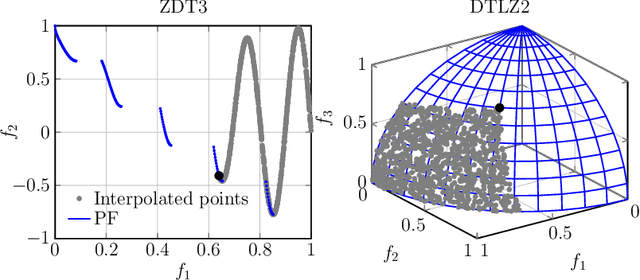
Multi-objective optimization problems are ubiquitous in real-world science, engineering and design optimization problems. It is not uncommon that the objective functions are as a black box, the evaluation of which usually involve time-consuming and/or costly physical experiments. Data-driven evolutionary optimization can be used to search for a set of non-dominated trade-off solutions, where the expensive objective functions are approximated as a surrogate model. In this paper, we propose a framework for implementing batched data-driven evolutionary multi-objective optimization. It is so general that any off-the-shelf evolutionary multi-objective optimization algorithms can be applied in a plug-in manner. In particular, it has two unique components: 1) based on the Karush-Kuhn-Tucker conditions, a manifold interpolation approach that explores more diversified solutions with a convergence guarantee along the manifold of the approximated Pareto-optimal set; and 2) a batch recommendation approach that reduces the computational time of the optimization process by evaluating multiple samples at a time in parallel. Experiments on 136 benchmark test problem instances with irregular Pareto-optimal front shapes against six state-of-the-art surrogate-assisted EMO algorithms fully demonstrate the effectiveness and superiority of our proposed framework. In particular, our proposed framework is featured with a faster convergence and a stronger resilience to various PF shapes.
Classification of the Chess Endgame problem using Logistic Regression, Decision Trees, and Neural Networks
Nov 10, 2021
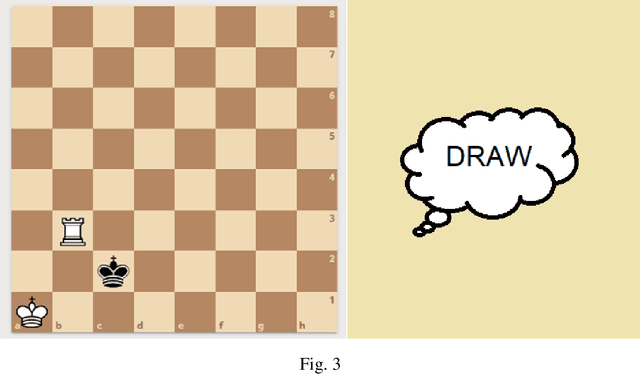
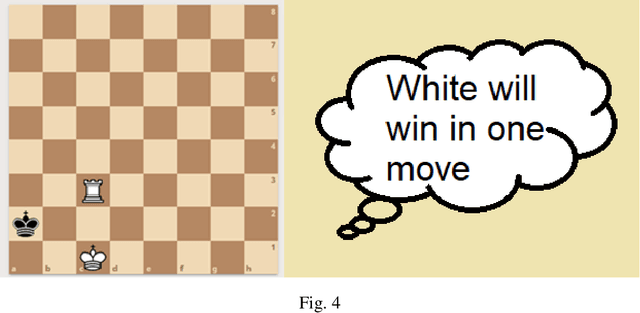
In this study we worked on the classification of the Chess Endgame problem using different algorithms like logistic regression, decision trees and neural networks. Our experiments indicates that the Neural Networks provides the best accuracy (85%) then the decision trees (79%). We did these experiments using Microsoft Azure Machine Learning as a case-study on using Visual Programming in classification. Our experiments demonstrates that this tool is powerful and save a lot of time, also it could be improved with more features that increase the usability and reduce the learning curve. We also developed an application for dataset visualization using a new programming language called Ring, our experiments demonstrates that this language have simple design like Python while integrates RAD tools like Visual Basic which is good for GUI development in the open-source world
GPU optimization of the 3D Scale-invariant Feature Transform Algorithm and a Novel BRIEF-inspired 3D Fast Descriptor
Dec 19, 2021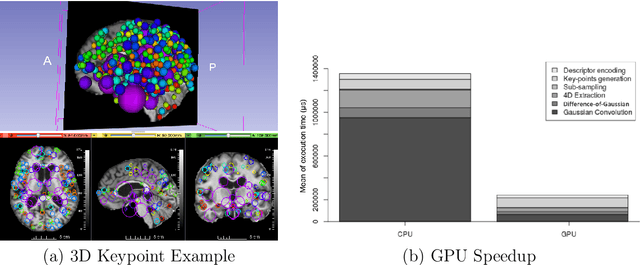
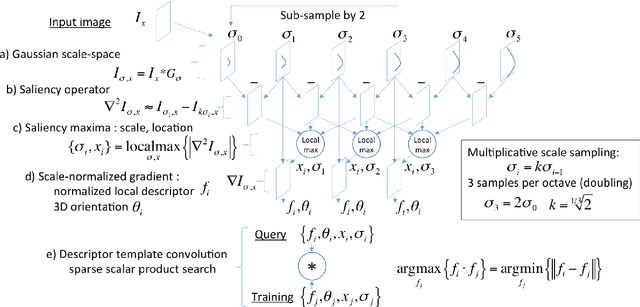
This work details a highly efficient implementation of the 3D scale-invariant feature transform (SIFT) algorithm, for the purpose of machine learning from large sets of volumetric medical image data. The primary operations of the 3D SIFT code are implemented on a graphics processing unit (GPU), including convolution, sub-sampling, and 4D peak detection from scale-space pyramids. The performance improvements are quantified in keypoint detection and image-to-image matching experiments, using 3D MRI human brain volumes of different people. Computationally efficient 3D keypoint descriptors are proposed based on the Binary Robust Independent Elementary Feature (BRIEF) code, including a novel descriptor we call Ranked Robust Independent Elementary Features (RRIEF), and compared to the original 3D SIFT-Rank method\citep{toews2013efficient}. The GPU implementation affords a speedup of approximately 7X beyond an optimised CPU implementation, where computation time is reduced from 1.4 seconds to 0.2 seconds for 3D volumes of size (145, 174, 145) voxels with approximately 3000 keypoints. Notable speedups include the convolution operation (20X), 4D peak detection (3X), sub-sampling (3X), and difference-of-Gaussian pyramid construction (2X). Efficient descriptors offer a speedup of 2X and a memory savings of 6X compared to standard SIFT-Rank descriptors, at a cost of reduced numbers of keypoint correspondences, revealing a trade-off between computational efficiency and algorithmic performance. The speedups gained by our implementation will allow for a more efficient analysis on larger data sets. Our optimized GPU implementation of the 3D SIFT-Rank extractor is available at https://github.com/CarluerJB/3D_SIFT_CUDA.
Temporally Resolution Decrement: Utilizing the Shape Consistency for Higher Computational Efficiency
Dec 02, 2021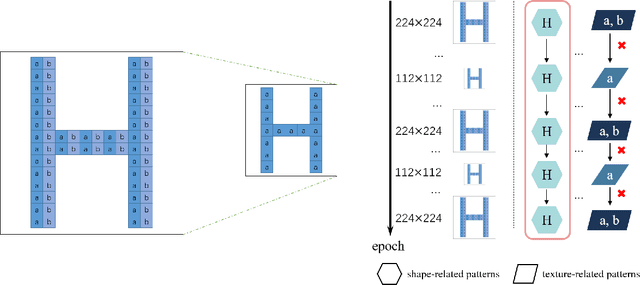
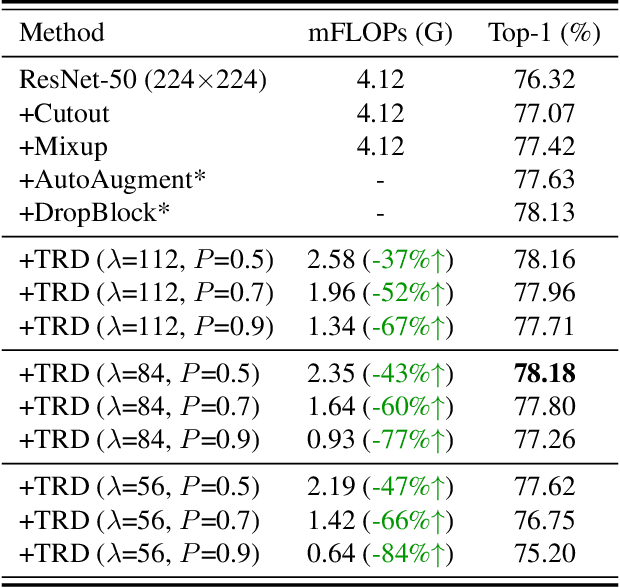
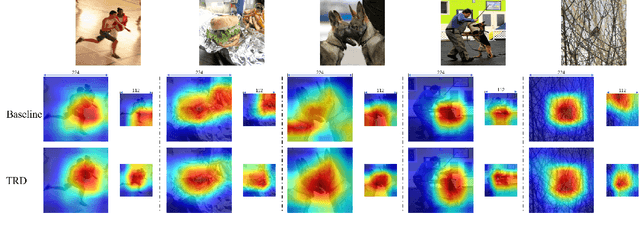
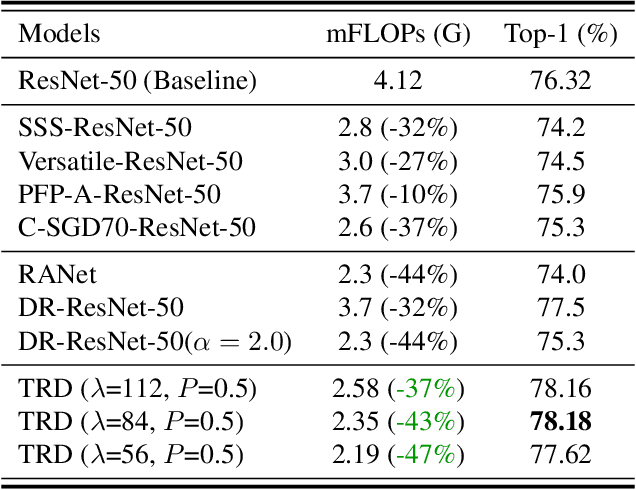
Image resolution that has close relations with accuracy and computational cost plays a pivotal role in network training. In this paper, we observe that the reduced image retains relatively complete shape semantics but loses extensive texture information. Inspired by the consistency of the shape semantics as well as the fragility of the texture information, we propose a novel training strategy named Temporally Resolution Decrement. Wherein, we randomly reduce the training images to a smaller resolution in the time domain. During the alternate training with the reduced images and the original images, the unstable texture information in the images results in a weaker correlation between the texture-related patterns and the correct label, naturally enforcing the model to rely more on shape properties that are robust and conform to the human decision rule. Surprisingly, our approach greatly improves the computational efficiency of convolutional neural networks. On ImageNet classification, using only 33% calculation quantity (randomly reducing the training image to 112$\times$112 within 90% epochs) can still improve ResNet-50 from 76.32% to 77.71%, and using 63% calculation quantity (randomly reducing the training image to 112 x 112 within 50% epochs) can improve ResNet-50 to 78.18%.
ST-GREED: Space-Time Generalized Entropic Differences for Frame Rate Dependent Video Quality Prediction
Oct 26, 2020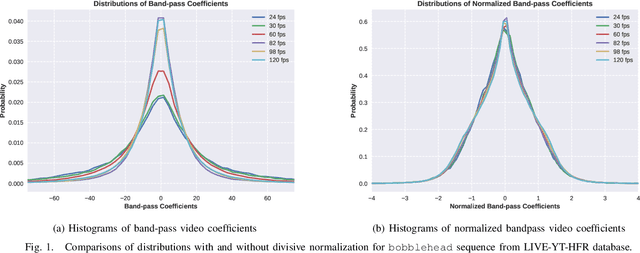
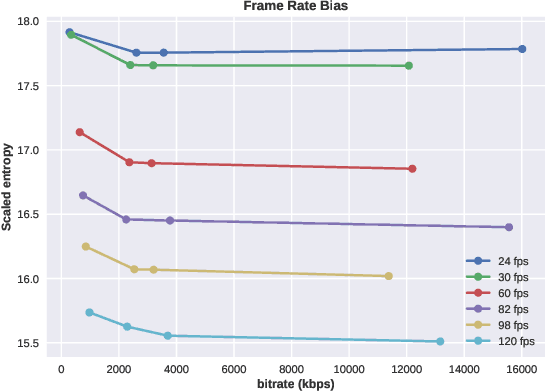
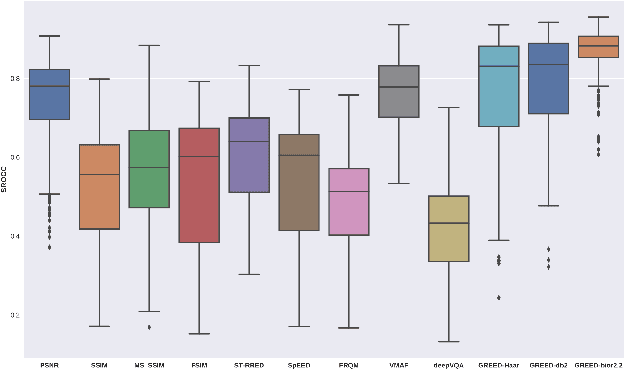
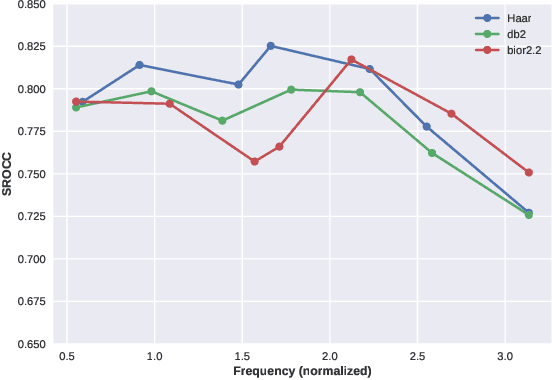
We consider the problem of conducting frame rate dependent video quality assessment (VQA) on videos of diverse frame rates, including high frame rate (HFR) videos. More generally, we study how perceptual quality is affected by frame rate, and how frame rate and compression combine to affect perceived quality. We devise an objective VQA model called Space-Time GeneRalized Entropic Difference (GREED) which analyzes the statistics of spatial and temporal band-pass video coefficients. A generalized Gaussian distribution (GGD) is used to model band-pass responses, while entropy variations between reference and distorted videos under the GGD model are used to capture video quality variations arising from frame rate changes. The entropic differences are calculated across multiple temporal and spatial subbands, and merged using a learned regressor. We show through extensive experiments that GREED achieves state-of-the-art performance on the LIVE-YT-HFR Database when compared with existing VQA models. The features used in GREED are highly generalizable and obtain competitive performance even on standard, non-HFR VQA databases. The implementation of GREED has been made available online: https://github.com/pavancm/GREED
Human Languages with Greater Information Density Increase Communication Speed, but Decrease Conversation Breadth
Dec 15, 2021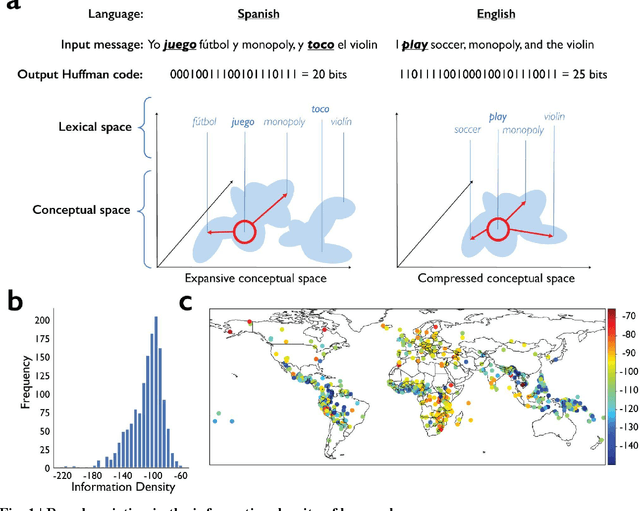
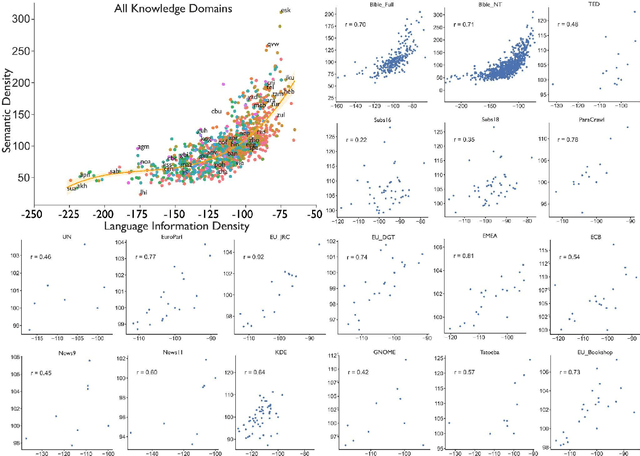
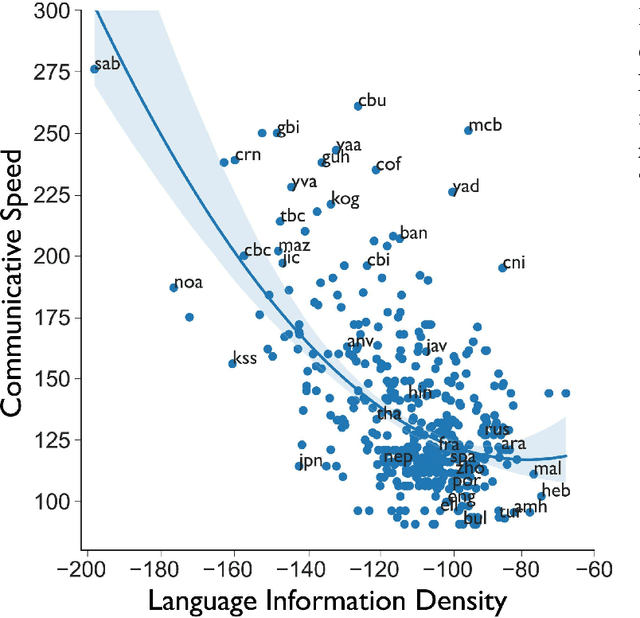
Language is the primary medium through which human information is communicated and coordination is achieved. One of the most important language functions is to categorize the world so messages can be communicated through conversation. While we know a great deal about how human languages vary in their encoding of information within semantic domains such as color, sound, number, locomotion, time, space, human activities, gender, body parts and biology, little is known about the global structure of semantic information and its effect on human communication. Using large-scale computation, artificial intelligence techniques, and massive, parallel corpora across 15 subject areas--including religion, economics, medicine, entertainment, politics, and technology--in 999 languages, here we show substantial variation in the information and semantic density of languages and their consequences for human communication and coordination. In contrast to prior work, we demonstrate that higher density languages communicate information much more quickly relative to lower density languages. Then, using over 9,000 real-life conversations across 14 languages and 90,000 Wikipedia articles across 140 languages, we show that because there are more ways to discuss any given topic in denser languages, conversations and articles retrace and cycle over a narrower conceptual terrain. These results demonstrate an important source of variation across the human communicative channel, suggesting that the structure of language shapes the nature and texture of conversation, with important consequences for the behavior of groups, organizations, markets, and societies.
Spatiotemporal Weather Data Predictions with Shortcut Recurrent-Convolutional Networks: A Solution for the Weather4cast challenge
Nov 03, 2021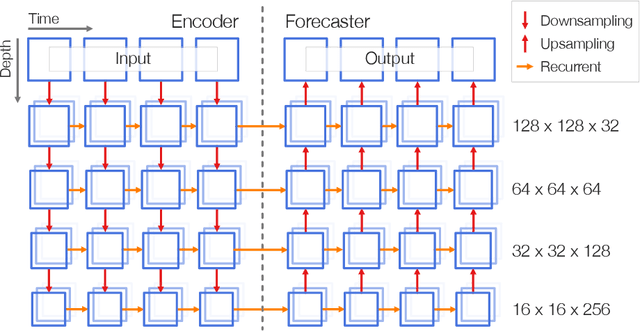
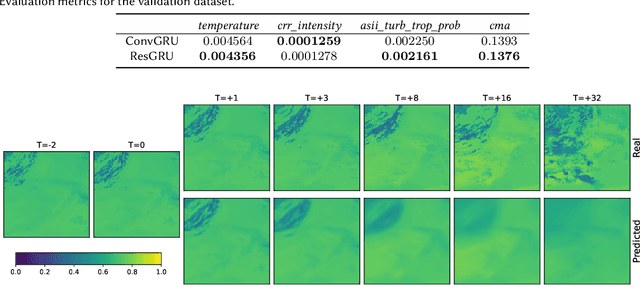
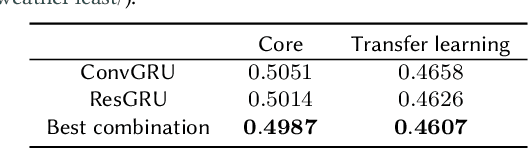

This paper presents the neural network model that was used by the author in the Weather4cast 2021 Challenge Stage 1, where the objective was to predict the time evolution of satellite-based weather data images. The network is based on an encoder-forecaster architecture making use of gated recurrent units (GRU), residual blocks and a contracting/expanding architecture with shortcuts similar to U-Net. A GRU variant utilizing residual blocks in place of convolutions is also introduced. Example predictions and evaluation metrics for the model are presented. These demonstrate that the model can retain sharp features of the input for the first predictions, while the later predictions become more blurred to reflect the increasing uncertainty.
Fusion of Sensor Measurements and Target-Provided Information in Multitarget Tracking
Nov 26, 2021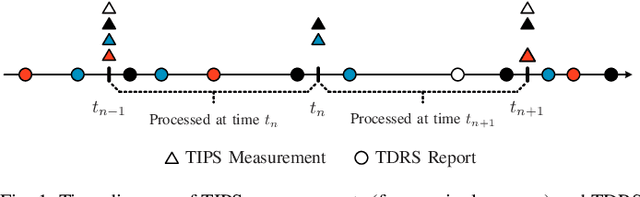
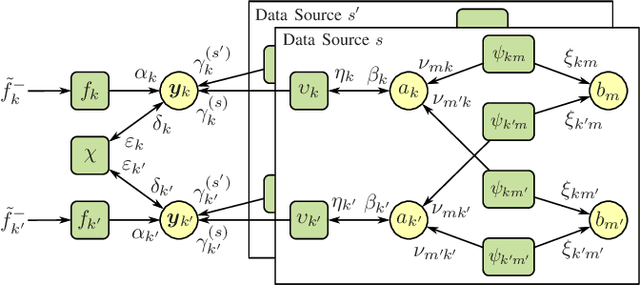
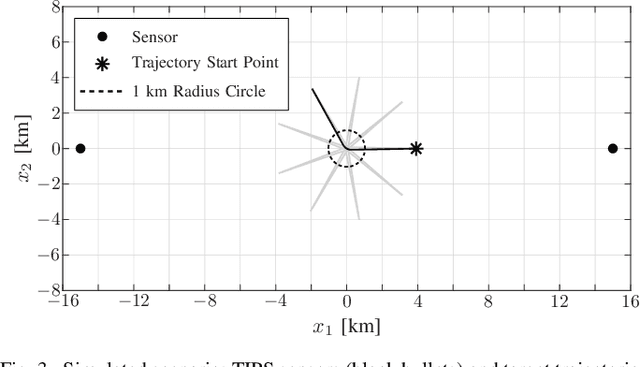
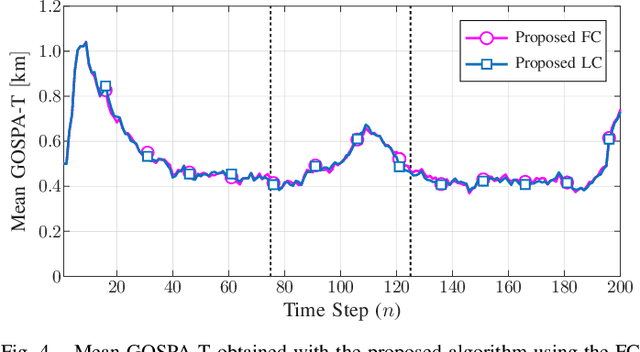
Tracking multiple time-varying states based on heterogeneous observations is a key problem in many applications. Here, we develop a statistical model and algorithm for tracking an unknown number of targets based on the probabilistic fusion of observations from two classes of data sources. The first class, referred to as target-independent perception systems (TIPSs), consists of sensors that periodically produce noisy measurements of targets without requiring target cooperation. The second class, referred to as target-dependent reporting systems (TDRSs), relies on cooperative targets that report noisy measurements of their state and their identity. We present a joint TIPS-TDRS observation model that accounts for observation-origin uncertainty, missed detections, false alarms, and asynchronicity. We then establish a factor graph that represents this observation model along with a state evolution model including target identities. Finally, by executing the sum-product algorithm on that factor graph, we obtain a scalable multitarget tracking algorithm with inherent TIPS-TDRS fusion. The performance of the proposed algorithm is evaluated using simulated data as well as real data from a maritime surveillance experiment.