 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Data-Driven Interaction Analysis of Line Failure Cascading in Power Grid Networks
Dec 02, 2021
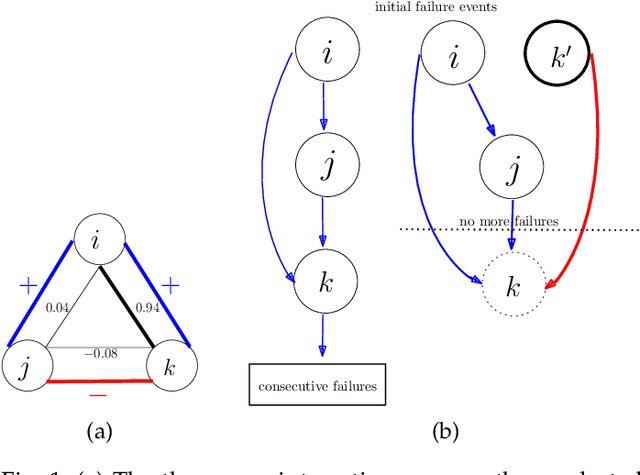
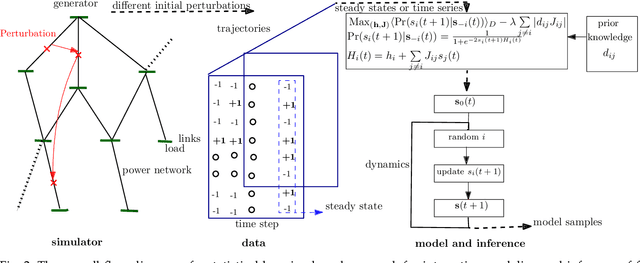
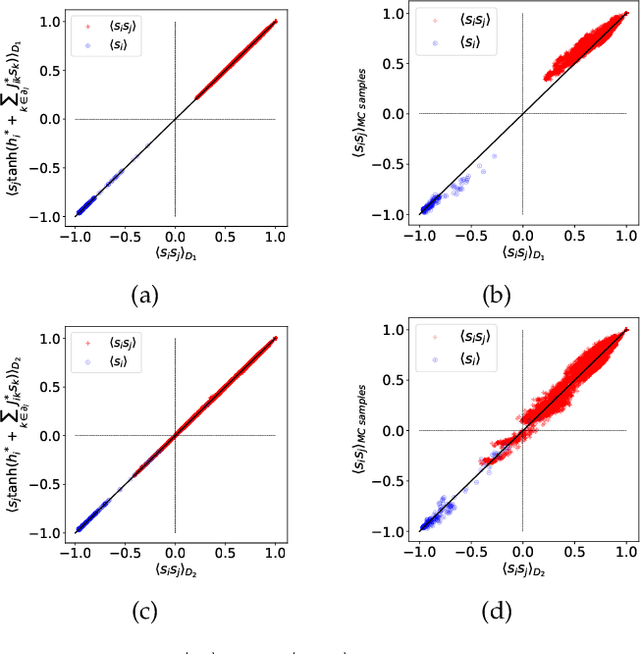
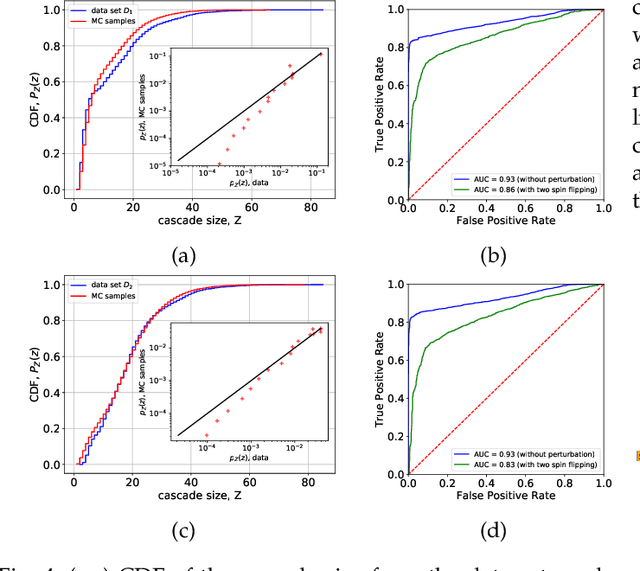
We use machine learning tools to model the line interaction of failure cascading in power grid networks. We first collect data sets of simulated trajectories of possible consecutive line failure following an initial random failure and considering actual constraints in a model power network until the system settles at a steady state. We use weighted $l_1$-regularized logistic regression-based models to find static and dynamic models that capture pairwise and latent higher-order lines' failure interactions using pairwise statistical data. The static model captures the failures' interactions near the steady states of the network, and the dynamic model captures the failure unfolding in a time series of consecutive network states. We test models over independent trajectories of failure unfolding in the network to evaluate their failure predictive power. We observe asymmetric, strongly positive, and negative interactions between different lines' states in the network. We use the static interaction model to estimate the distribution of cascade size and identify groups of lines that tend to fail together, and compare against the data. The dynamic interaction model successfully predicts the network state for long-lasting failure propagation trajectories after an initial failure.
GoTube: Scalable Stochastic Verification of Continuous-Depth Models
Jul 18, 2021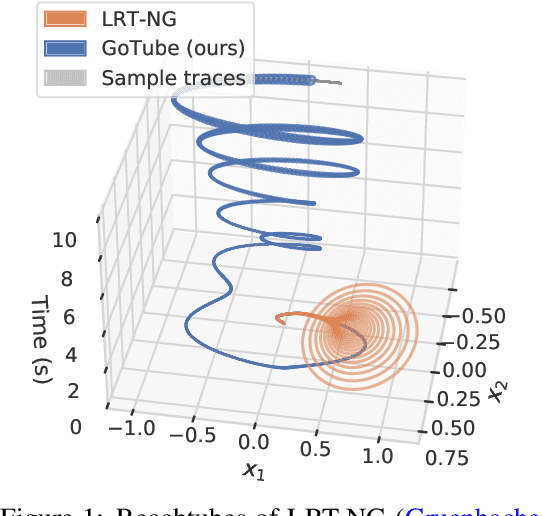
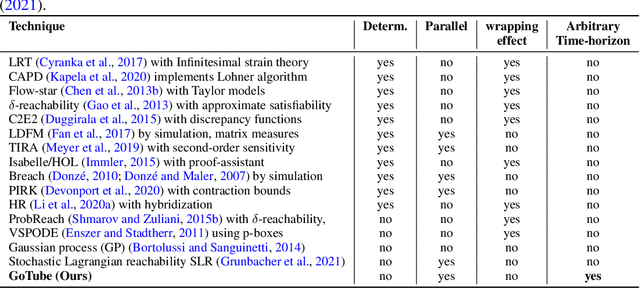
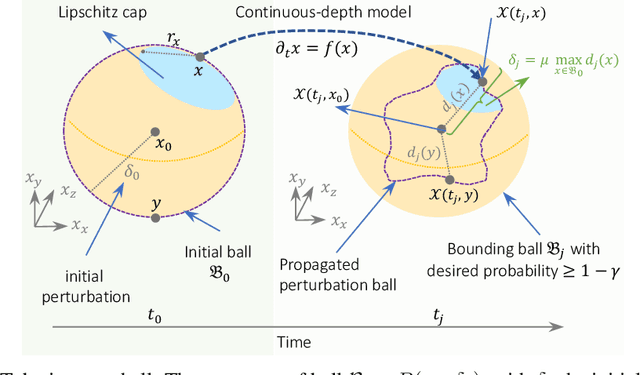
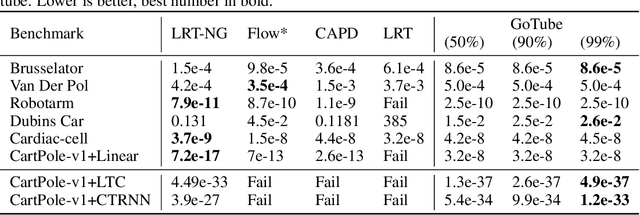
We introduce a new stochastic verification algorithm that formally quantifies the behavioral robustness of any time-continuous process formulated as a continuous-depth model. The algorithm solves a set of global optimization (Go) problems over a given time horizon to construct a tight enclosure (Tube) of the set of all process executions starting from a ball of initial states. We call our algorithm GoTube. Through its construction, GoTube ensures that the bounding tube is conservative up to a desired probability. GoTube is implemented in JAX and optimized to scale to complex continuous-depth models. Compared to advanced reachability analysis tools for time-continuous neural networks, GoTube provably does not accumulate over-approximation errors between time steps and avoids the infamous wrapping effect inherent in symbolic techniques. We show that GoTube substantially outperforms state-of-the-art verification tools in terms of the size of the initial ball, speed, time-horizon, task completion, and scalability, on a large set of experiments. GoTube is stable and sets the state-of-the-art for its ability to scale up to time horizons well beyond what has been possible before.
Improving Sum-Rate of Cell-Free Massive MIMO with Expanded Compute-and-Forward
Nov 21, 2021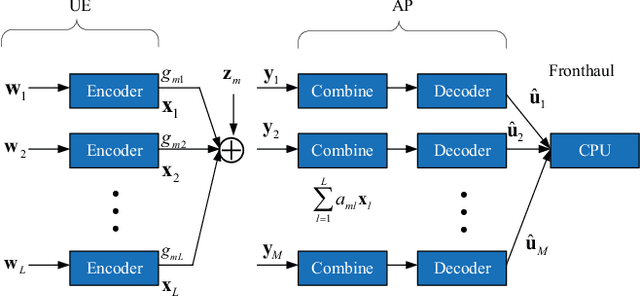

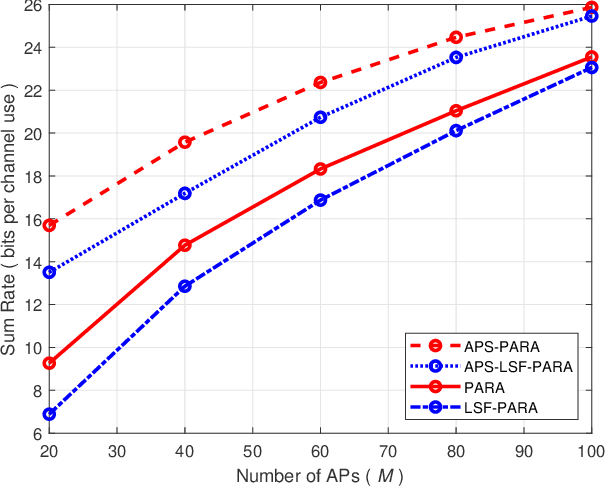
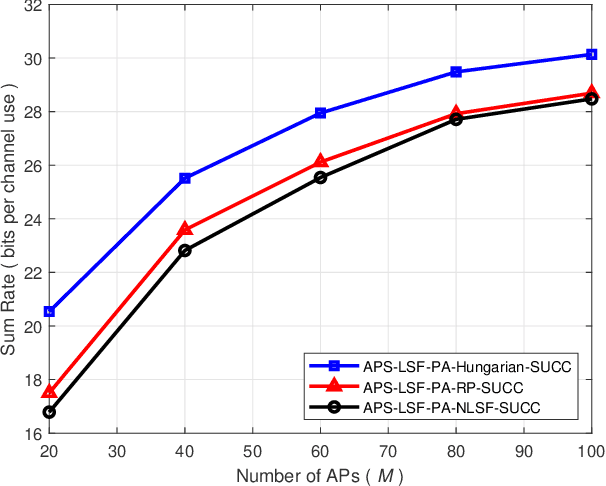
Cell-free massive multiple-input multiple-output (MIMO) employs a large number of distributed access points (APs) to serve a small number of user equipments (UEs) via the same time/frequency resource. Due to the strong macro diversity gain, cell-free massive MIMO can considerably improve the achievable sum-rate compared to conventional cellular massive MIMO. However, the performance of cell-free massive MIMO is upper limited by inter-user interference (IUI) when employing simple maximum ratio combining (MRC) at receivers. To harness IUI, the expanded compute-and-forward (ECF) framework is adopted. In particular, we propose power control algorithms for the parallel computation and successive computation in the ECF framework, respectively, to exploit the performance gain and then improve the system performance. Furthermore, we propose an AP selection scheme and the application of different decoding orders for the successive computation. Finally, numerical results demonstrate that ECF frameworks outperform the conventional CF and MRC frameworks in terms of achievable sum-rate.
Hierarchical Segment-based Optimization for SLAM
Nov 07, 2021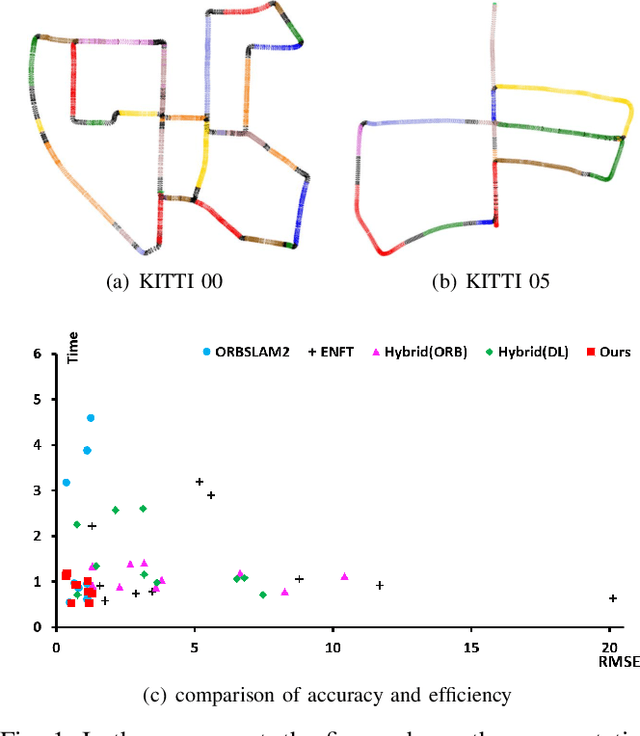
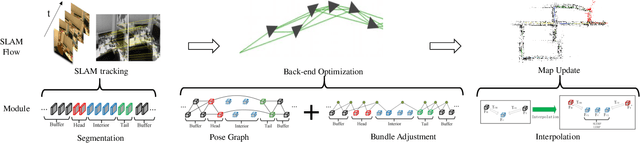
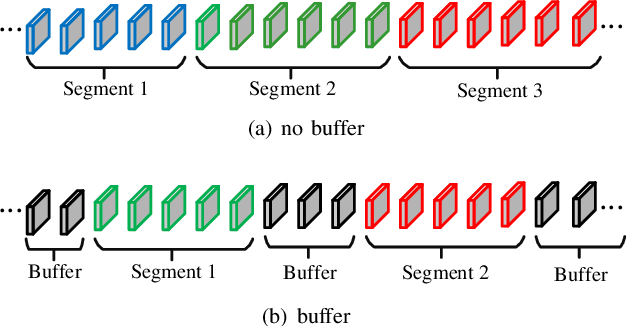
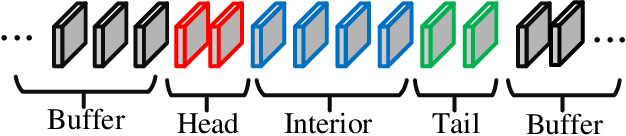
This paper presents a hierarchical segment-based optimization method for Simultaneous Localization and Mapping (SLAM) system. First we propose a reliable trajectory segmentation method that can be used to increase efficiency in the back-end optimization. Then we propose a buffer mechanism for the first time to improve the robustness of the segmentation. During the optimization, we use global information to optimize the frames with large error, and interpolation instead of optimization to update well-estimated frames to hierarchically allocate the amount of computation according to error of each frame. Comparative experiments on the benchmark show that our method greatly improves the efficiency of optimization with almost no drop in accuracy, and outperforms existing high-efficiency optimization method by a large margin.
Ground-Truth, Whose Truth? -- Examining the Challenges with Annotating Toxic Text Datasets
Dec 07, 2021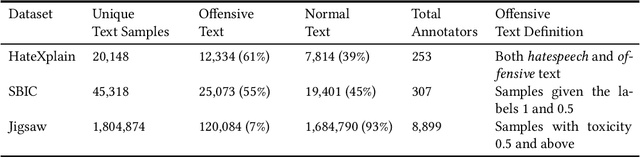
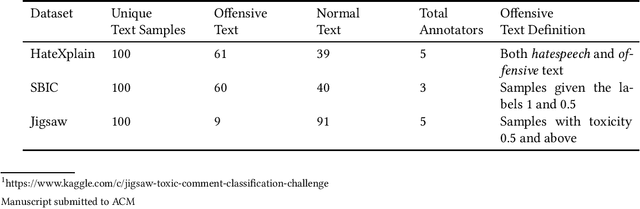
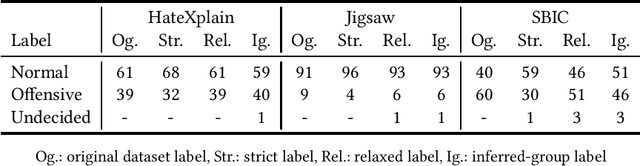

The use of machine learning (ML)-based language models (LMs) to monitor content online is on the rise. For toxic text identification, task-specific fine-tuning of these models are performed using datasets labeled by annotators who provide ground-truth labels in an effort to distinguish between offensive and normal content. These projects have led to the development, improvement, and expansion of large datasets over time, and have contributed immensely to research on natural language. Despite the achievements, existing evidence suggests that ML models built on these datasets do not always result in desirable outcomes. Therefore, using a design science research (DSR) approach, this study examines selected toxic text datasets with the goal of shedding light on some of the inherent issues and contributing to discussions on navigating these challenges for existing and future projects. To achieve the goal of the study, we re-annotate samples from three toxic text datasets and find that a multi-label approach to annotating toxic text samples can help to improve dataset quality. While this approach may not improve the traditional metric of inter-annotator agreement, it may better capture dependence on context and diversity in annotators. We discuss the implications of these results for both theory and practice.
Panoptic Multi-TSDFs: a Flexible Representation for Online Multi-resolution Volumetric Mapping and Long-term Dynamic Scene Consistency
Sep 21, 2021

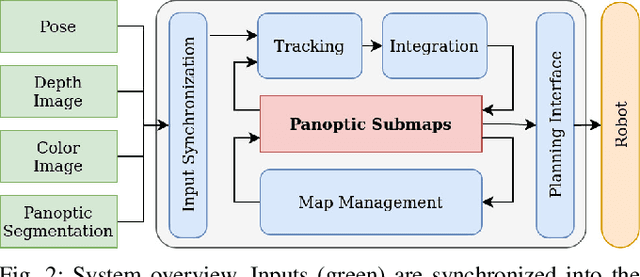
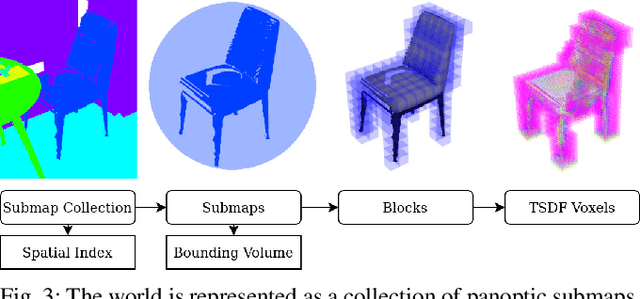
For robotic interaction in an environment shared with multiple agents, accessing a volumetric and semantic map of the scene is crucial. However, such environments are inevitably subject to long-term changes, which the map representation needs to account for.To this end, we propose panoptic multi-TSDFs, a novel representation for multi-resolution volumetric mapping over long periods of time. By leveraging high-level information for 3D reconstruction, our proposed system allocates high resolution only where needed. In addition, through reasoning on the object level, semantic consistency over time is achieved. This enables to maintain up-to-date reconstructions with high accuracy while improving coverage by incorporating and fusing previous data. We show in thorough experimental validations that our map representation can be efficiently constructed, maintained, and queried during online operation, and that the presented approach can operate robustly on real depth sensors using non-optimized panoptic segmentation as input.
Learning Optimal Predictive Checklists
Dec 02, 2021


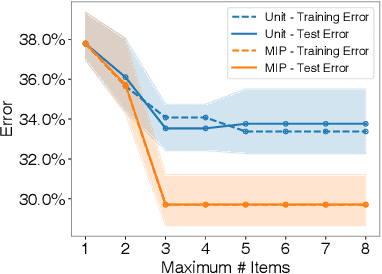
Checklists are simple decision aids that are often used to promote safety and reliability in clinical applications. In this paper, we present a method to learn checklists for clinical decision support. We represent predictive checklists as discrete linear classifiers with binary features and unit weights. We then learn globally optimal predictive checklists from data by solving an integer programming problem. Our method allows users to customize checklists to obey complex constraints, including constraints to enforce group fairness and to binarize real-valued features at training time. In addition, it pairs models with an optimality gap that can inform model development and determine the feasibility of learning sufficiently accurate checklists on a given dataset. We pair our method with specialized techniques that speed up its ability to train a predictive checklist that performs well and has a small optimality gap. We benchmark the performance of our method on seven clinical classification problems, and demonstrate its practical benefits by training a short-form checklist for PTSD screening. Our results show that our method can fit simple predictive checklists that perform well and that can easily be customized to obey a rich class of custom constraints.
Multiway sparse distance weighted discrimination
Oct 11, 2021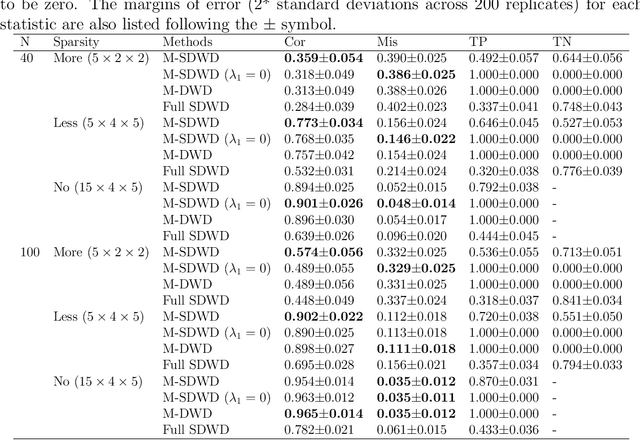
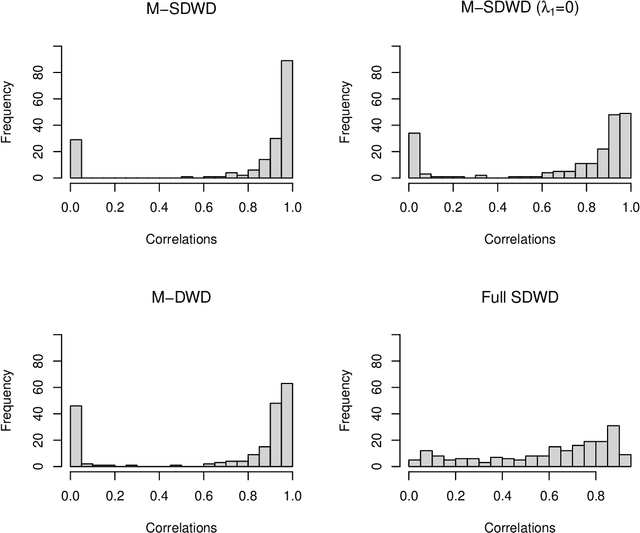
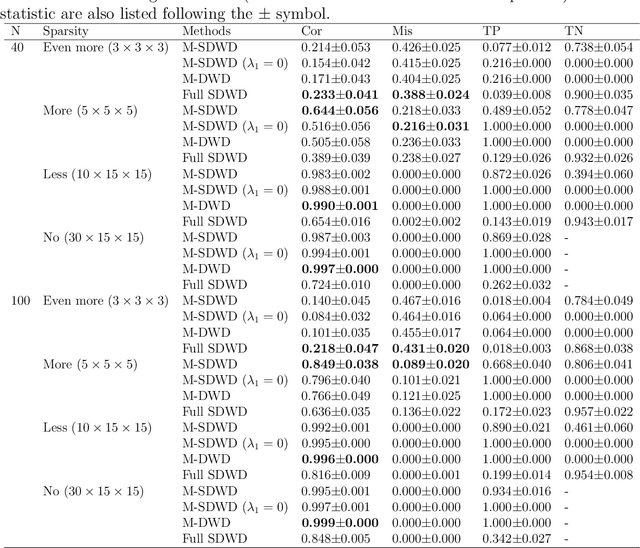
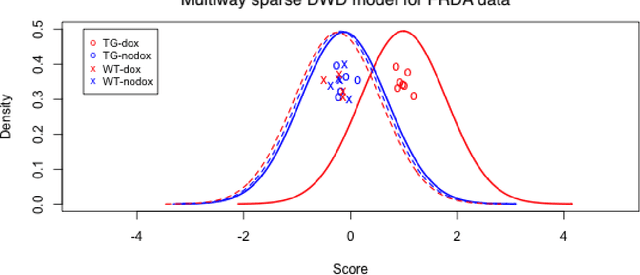
Modern data often take the form of a multiway array. However, most classification methods are designed for vectors, i.e., 1-way arrays. Distance weighted discrimination (DWD) is a popular high-dimensional classification method that has been extended to the multiway context, with dramatic improvements in performance when data have multiway structure. However, the previous implementation of multiway DWD was restricted to classification of matrices, and did not account for sparsity. In this paper, we develop a general framework for multiway classification which is applicable to any number of dimensions and any degree of sparsity. We conducted extensive simulation studies, showing that our model is robust to the degree of sparsity and improves classification accuracy when the data have multiway structure. For our motivating application, magnetic resonance spectroscopy (MRS) was used to measure the abundance of several metabolites across multiple neurological regions and across multiple time points in a mouse model of Friedreich's ataxia, yielding a four-way data array. Our method reveals a robust and interpretable multi-region metabolomic signal that discriminates the groups of interest. We also successfully apply our method to gene expression time course data for multiple sclerosis treatment. An R implementation is available in the package MultiwayClassification at http://github.com/lockEF/MultiwayClassification .
Assessing Automated Machine Learning service to detect COVID-19 from X-Ray and CT images: A Real-time Smartphone Application case study
Oct 03, 2020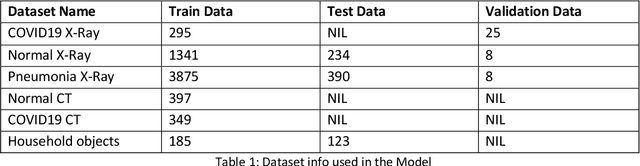
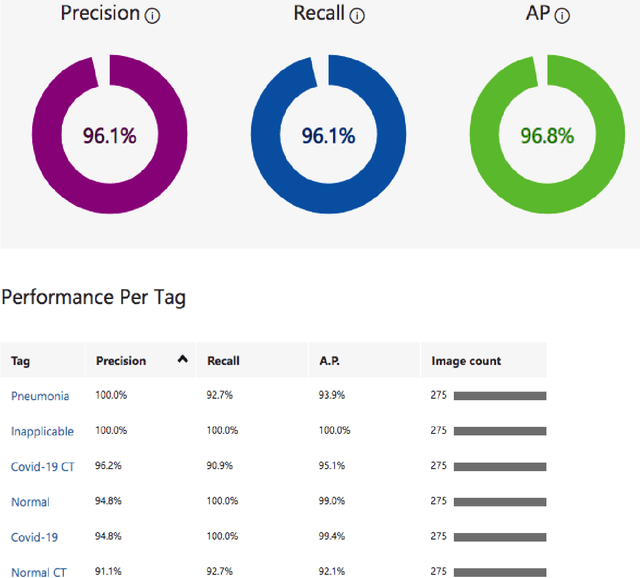
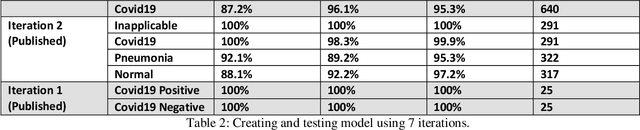
The recent outbreak of SARS COV-2 gave us a unique opportunity to study for a non interventional and sustainable AI solution. Lung disease remains a major healthcare challenge with high morbidity and mortality worldwide. The predominant lung disease was lung cancer. Until recently, the world has witnessed the global pandemic of COVID19, the Novel coronavirus outbreak. We have experienced how viral infection of lung and heart claimed thousands of lives worldwide. With the unprecedented advancement of Artificial Intelligence in recent years, Machine learning can be used to easily detect and classify medical imagery. It is much faster and most of the time more accurate than human radiologists. Once implemented, it is more cost-effective and time-saving. In our study, we evaluated the efficacy of Microsoft Cognitive Service to detect and classify COVID19 induced pneumonia from other Viral/Bacterial pneumonia based on X-Ray and CT images. We wanted to assess the implication and accuracy of the Automated ML-based Rapid Application Development (RAD) environment in the field of Medical Image diagnosis. This study will better equip us to respond with an ML-based diagnostic Decision Support System(DSS) for a Pandemic situation like COVID19. After optimization, the trained network achieved 96.8% Average Precision which was implemented as a Web Application for consumption. However, the same trained network did not perform the same like Web Application when ported to Smartphone for Real-time inference. Which was our main interest of study. The authors believe, there is scope for further study on this issue. One of the main goal of this study was to develop and evaluate the performance of AI-powered Smartphone-based Real-time Application. Facilitating primary diagnostic services in less equipped and understaffed rural healthcare centers of the world with unreliable internet service.
* 21 Pages, 6 Tables
ToxTree: descriptor-based machine learning models for both hERG and Nav1.5 cardiotoxicity liability predictions
Dec 27, 2021
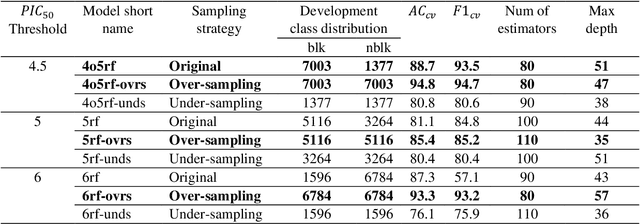
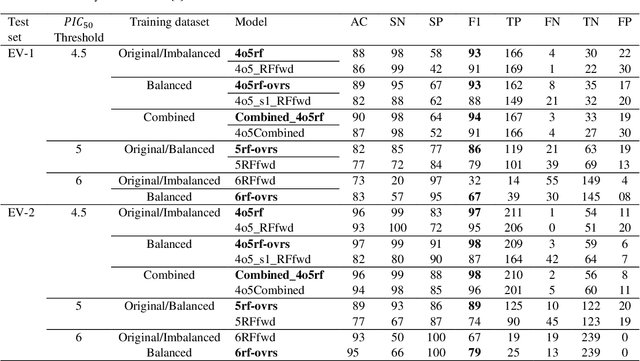
Drug-mediated blockade of the voltage-gated potassium channel(hERG) and the voltage-gated sodium channel (Nav1.5) can lead to severe cardiovascular complications. This rising concern has been reflected in the drug development arena, as the frequent emergence of cardiotoxicity from many approved drugs led to either discontinuing their use or, in some cases, their withdrawal from the market. Predicting potential hERG and Nav1.5 blockers at the outset of the drug discovery process can resolve this problem and can, therefore, decrease the time and expensive cost of developing safe drugs. One fast and cost-effective approach is to use in silico predictive methods to weed out potential hERG and Nav1.5 blockers at the early stages of drug development. Here, we introduce two robust 2D descriptor-based QSAR predictive models for both hERG and Nav1.5 liability predictions. The machine learning models were trained for both regression, predicting the potency value of a drug, and multiclass classification at three different potency cut-offs (i.e. 1$\mu$M, 10$\mu$M, and 30$\mu$M), where ToxTree-hERG Classifier, a pipeline of Random Forest models, was trained on a large curated dataset of 8380 unique molecular compounds. Whereas ToxTree-Nav1.5 Classifier, a pipeline of kernelized SVM models, was trained on a large manually curated set of 1550 unique compounds retrieved from both ChEMBL and PubChem publicly available bioactivity databases. The proposed hERG inducer outperformed most metrics of the state-of-the-art published model and other existing tools. Additionally, we are introducing the first Nav1.5 liability predictive model achieving a Q4 = 74.9% and a binary classification of Q2 = 86.7% with MCC = 71.2% evaluated on an external test set of 173 unique compounds. The curated datasets used in this project are made publicly available to the research community.