 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Continuous Convolutional Neural Networks: Coupled Neural PDE and ODE
Oct 30, 2021
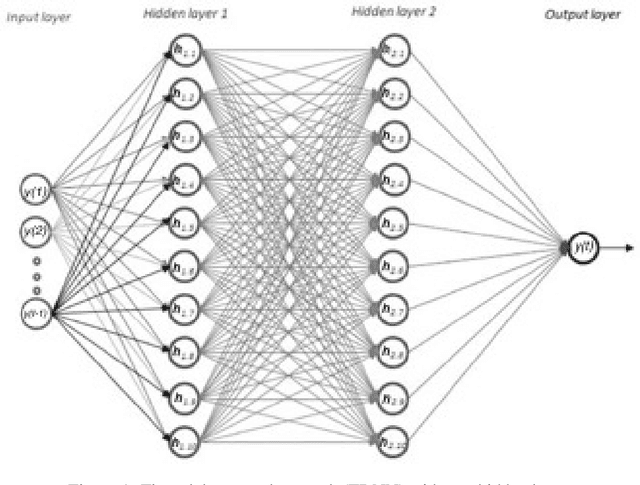
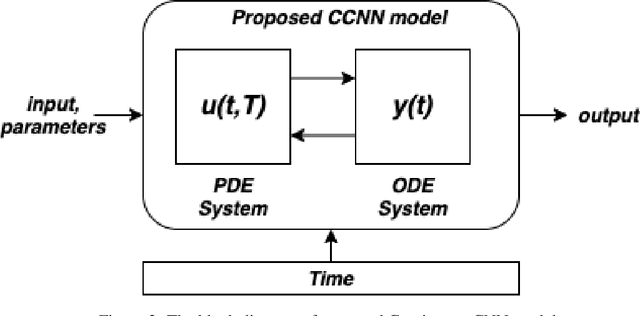
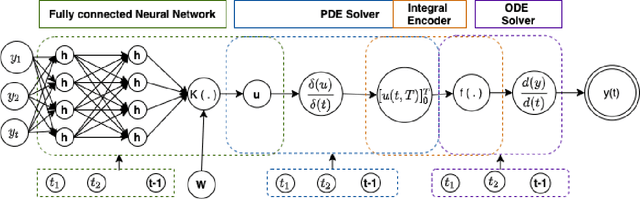
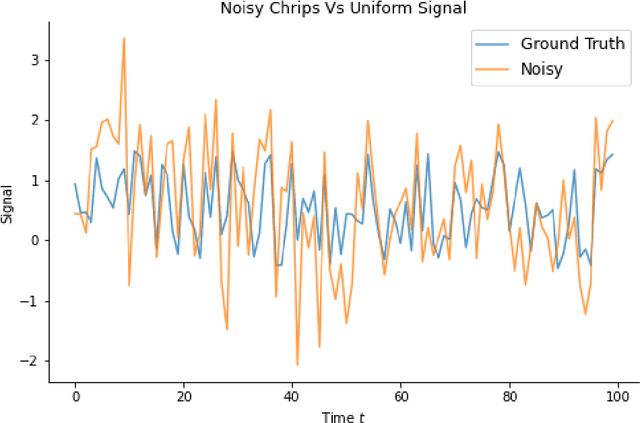
Recent work in deep learning focuses on solving physical systems in the Ordinary Differential Equation or Partial Differential Equation. This current work proposed a variant of Convolutional Neural Networks (CNNs) that can learn the hidden dynamics of a physical system using ordinary differential equation (ODEs) systems (ODEs) and Partial Differential Equation systems (PDEs). Instead of considering the physical system such as image, time -series as a system of multiple layers, this new technique can model a system in the form of Differential Equation (DEs). The proposed method has been assessed by solving several steady-state PDEs on irregular domains, including heat equations, Navier-Stokes equations.
META: Mimicking Embedding via oThers' Aggregation for Generalizable Person Re-identification
Dec 16, 2021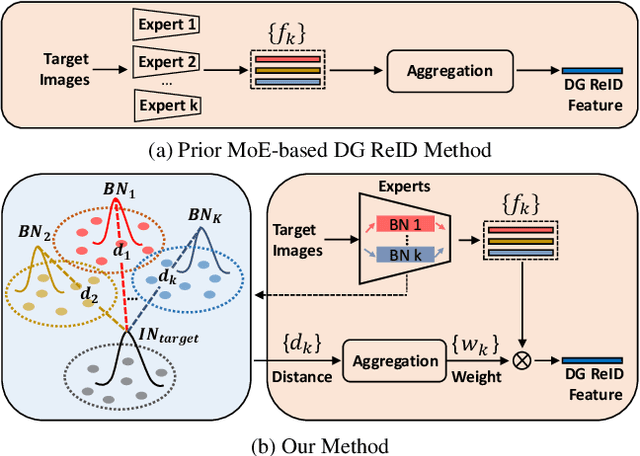
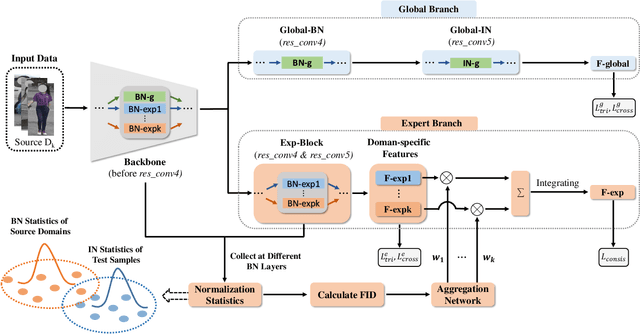
Domain generalizable (DG) person re-identification (ReID) aims to test across unseen domains without access to the target domain data at training time, which is a realistic but challenging problem. In contrast to methods assuming an identical model for different domains, Mixture of Experts (MoE) exploits multiple domain-specific networks for leveraging complementary information between domains, obtaining impressive results. However, prior MoE-based DG ReID methods suffer from a large model size with the increase of the number of source domains, and most of them overlook the exploitation of domain-invariant characteristics. To handle the two issues above, this paper presents a new approach called Mimicking Embedding via oThers' Aggregation (META) for DG ReID. To avoid the large model size, experts in META do not add a branch network for each source domain but share all the parameters except for the batch normalization layers. Besides multiple experts, META leverages Instance Normalization (IN) and introduces it into a global branch to pursue invariant features across domains. Meanwhile, META considers the relevance of an unseen target sample and source domains via normalization statistics and develops an aggregation network to adaptively integrate multiple experts for mimicking unseen target domain. Benefiting from a proposed consistency loss and an episodic training algorithm, we can expect META to mimic embedding for a truly unseen target domain. Extensive experiments verify that META surpasses state-of-the-art DG ReID methods by a large margin.
HSPACE: Synthetic Parametric Humans Animated in Complex Environments
Dec 23, 2021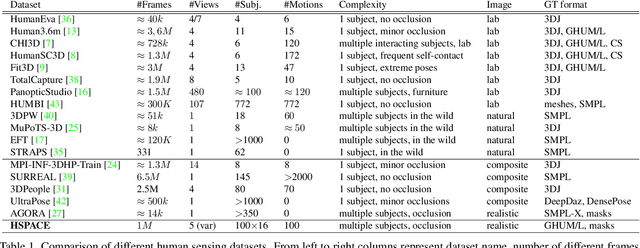
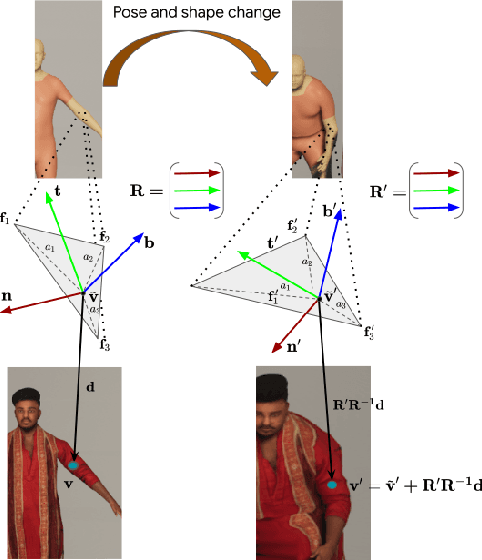
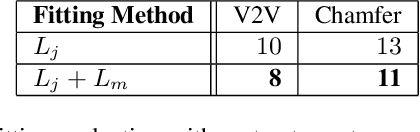
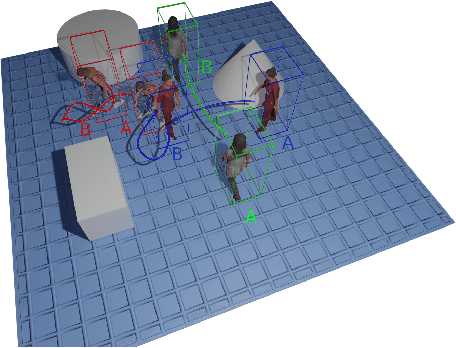
Advances in the state of the art for 3d human sensing are currently limited by the lack of visual datasets with 3d ground truth, including multiple people, in motion, operating in real-world environments, with complex illumination or occlusion, and potentially observed by a moving camera. Sophisticated scene understanding would require estimating human pose and shape as well as gestures, towards representations that ultimately combine useful metric and behavioral signals with free-viewpoint photo-realistic visualisation capabilities. To sustain progress, we build a large-scale photo-realistic dataset, Human-SPACE (HSPACE), of animated humans placed in complex synthetic indoor and outdoor environments. We combine a hundred diverse individuals of varying ages, gender, proportions, and ethnicity, with hundreds of motions and scenes, as well as parametric variations in body shape (for a total of 1,600 different humans), in order to generate an initial dataset of over 1 million frames. Human animations are obtained by fitting an expressive human body model, GHUM, to single scans of people, followed by novel re-targeting and positioning procedures that support the realistic animation of dressed humans, statistical variation of body proportions, and jointly consistent scene placement of multiple moving people. Assets are generated automatically, at scale, and are compatible with existing real time rendering and game engines. The dataset with evaluation server will be made available for research. Our large-scale analysis of the impact of synthetic data, in connection with real data and weak supervision, underlines the considerable potential for continuing quality improvements and limiting the sim-to-real gap, in this practical setting, in connection with increased model capacity.
Energy-bounded Learning for Robust Models of Code
Dec 20, 2021
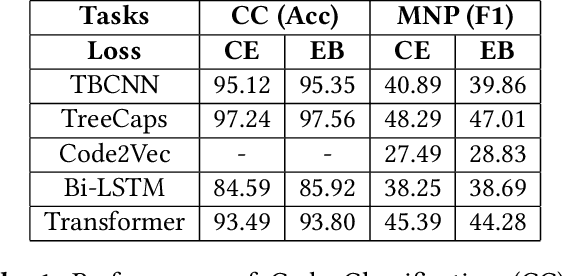
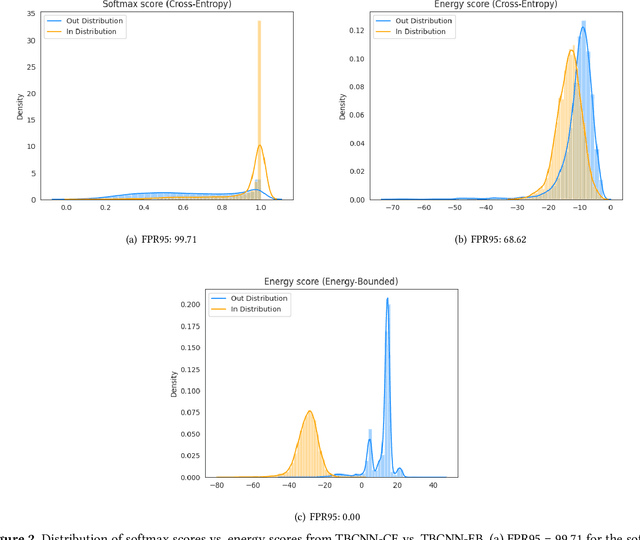

In programming, learning code representations has a variety of applications, including code classification, code search, comment generation, bug prediction, and so on. Various representations of code in terms of tokens, syntax trees, dependency graphs, code navigation paths, or a combination of their variants have been proposed, however, existing vanilla learning techniques have a major limitation in robustness, i.e., it is easy for the models to make incorrect predictions when the inputs are altered in a subtle way. To enhance the robustness, existing approaches focus on recognizing adversarial samples rather than on the valid samples that fall outside a given distribution, which we refer to as out-of-distribution (OOD) samples. Recognizing such OOD samples is the novel problem investigated in this paper. To this end, we propose to first augment the in=distribution datasets with out-of-distribution samples such that, when trained together, they will enhance the model's robustness. We propose the use of an energy-bounded learning objective function to assign a higher score to in-distribution samples and a lower score to out-of-distribution samples in order to incorporate such out-of-distribution samples into the training process of source code models. In terms of OOD detection and adversarial samples detection, our evaluation results demonstrate a greater robustness for existing source code models to become more accurate at recognizing OOD data while being more resistant to adversarial attacks at the same time. Furthermore, the proposed energy-bounded score outperforms all existing OOD detection scores by a large margin, including the softmax confidence score, the Mahalanobis score, and ODIN.
Maximum Entropy Model-based Reinforcement Learning
Dec 02, 2021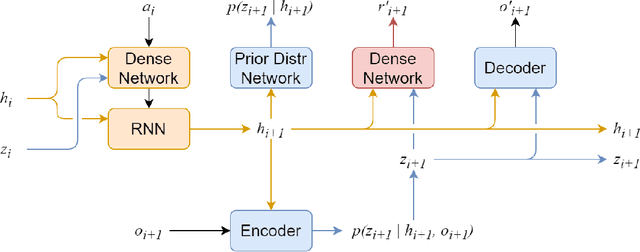
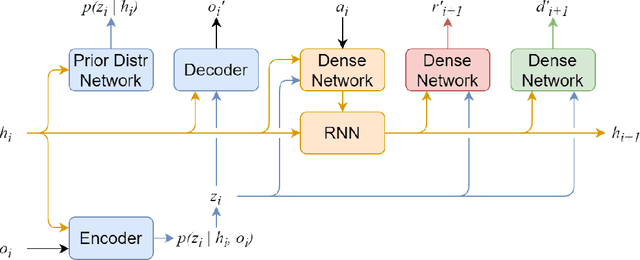
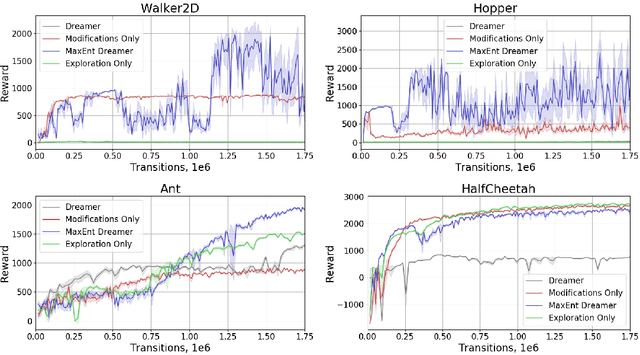
Recent advances in reinforcement learning have demonstrated its ability to solve hard agent-environment interaction tasks on a super-human level. However, the application of reinforcement learning methods to practical and real-world tasks is currently limited due to most RL state-of-art algorithms' sample inefficiency, i.e., the need for a vast number of training episodes. For example, OpenAI Five algorithm that has beaten human players in Dota 2 has trained for thousands of years of game time. Several approaches exist that tackle the issue of sample inefficiency, that either offers a more efficient usage of already gathered experience or aim to gain a more relevant and diverse experience via a better exploration of an environment. However, to our knowledge, no such approach exists for model-based algorithms, that showed their high sample efficiency in solving hard control tasks with high-dimensional state space. This work connects exploration techniques and model-based reinforcement learning. We have designed a novel exploration method that takes into account features of the model-based approach. We also demonstrate through experiments that our method significantly improves the performance of the model-based algorithm Dreamer.
Panoptic Multi-TSDFs: a Flexible Representation for Online Multi-resolution Volumetric Mapping and Long-term Dynamic Scene Consistency
Sep 21, 2021

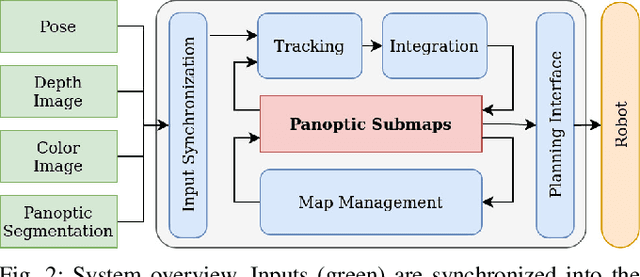
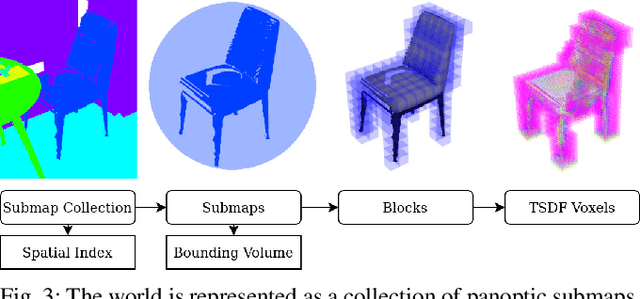
For robotic interaction in an environment shared with multiple agents, accessing a volumetric and semantic map of the scene is crucial. However, such environments are inevitably subject to long-term changes, which the map representation needs to account for.To this end, we propose panoptic multi-TSDFs, a novel representation for multi-resolution volumetric mapping over long periods of time. By leveraging high-level information for 3D reconstruction, our proposed system allocates high resolution only where needed. In addition, through reasoning on the object level, semantic consistency over time is achieved. This enables to maintain up-to-date reconstructions with high accuracy while improving coverage by incorporating and fusing previous data. We show in thorough experimental validations that our map representation can be efficiently constructed, maintained, and queried during online operation, and that the presented approach can operate robustly on real depth sensors using non-optimized panoptic segmentation as input.
MAVE: A Product Dataset for Multi-source Attribute Value Extraction
Dec 16, 2021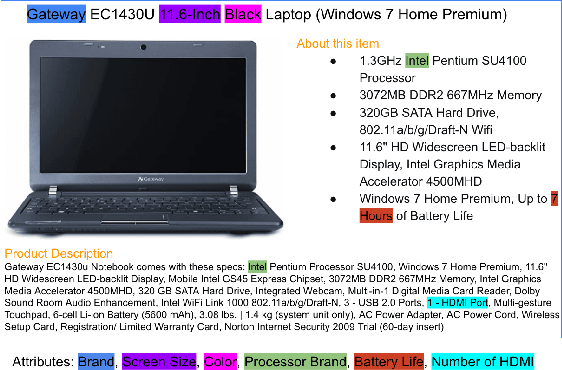
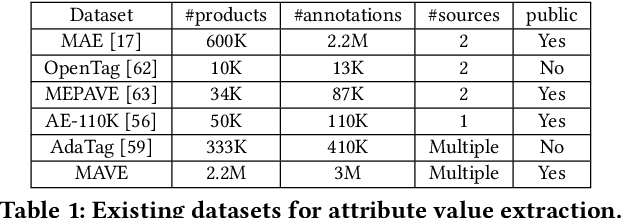

Attribute value extraction refers to the task of identifying values of an attribute of interest from product information. Product attribute values are essential in many e-commerce scenarios, such as customer service robots, product ranking, retrieval and recommendations. While in the real world, the attribute values of a product are usually incomplete and vary over time, which greatly hinders the practical applications. In this paper, we introduce MAVE, a new dataset to better facilitate research on product attribute value extraction. MAVE is composed of a curated set of 2.2 million products from Amazon pages, with 3 million attribute-value annotations across 1257 unique categories. MAVE has four main and unique advantages: First, MAVE is the largest product attribute value extraction dataset by the number of attribute-value examples. Second, MAVE includes multi-source representations from the product, which captures the full product information with high attribute coverage. Third, MAVE represents a more diverse set of attributes and values relative to what previous datasets cover. Lastly, MAVE provides a very challenging zero-shot test set, as we empirically illustrate in the experiments. We further propose a novel approach that effectively extracts the attribute value from the multi-source product information. We conduct extensive experiments with several baselines and show that MAVE is an effective dataset for attribute value extraction task. It is also a very challenging task on zero-shot attribute extraction. Data is available at {\it \url{https://github.com/google-research-datasets/MAVE}}.
Synthetic Map Generation to Provide Unlimited Training Data for Historical Map Text Detection
Dec 12, 2021

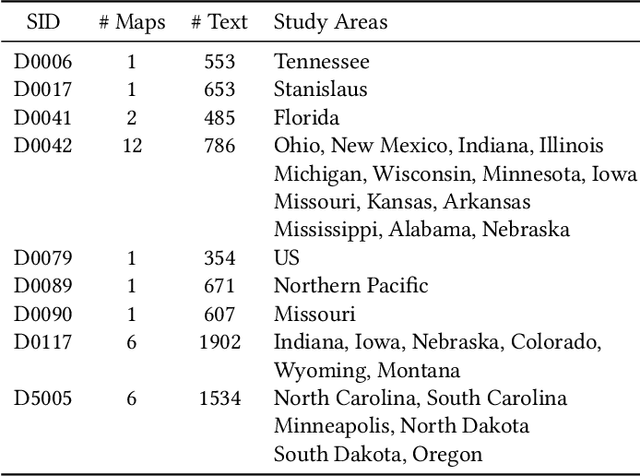
Many historical map sheets are publicly available for studies that require long-term historical geographic data. The cartographic design of these maps includes a combination of map symbols and text labels. Automatically reading text labels from map images could greatly speed up the map interpretation and helps generate rich metadata describing the map content. Many text detection algorithms have been proposed to locate text regions in map images automatically, but most of the algorithms are trained on out-ofdomain datasets (e.g., scenic images). Training data determines the quality of machine learning models, and manually annotating text regions in map images is labor-extensive and time-consuming. On the other hand, existing geographic data sources, such as Open- StreetMap (OSM), contain machine-readable map layers, which allow us to separate out the text layer and obtain text label annotations easily. However, the cartographic styles between OSM map tiles and historical maps are significantly different. This paper proposes a method to automatically generate an unlimited amount of annotated historical map images for training text detection models. We use a style transfer model to convert contemporary map images into historical style and place text labels upon them. We show that the state-of-the-art text detection models (e.g., PSENet) can benefit from the synthetic historical maps and achieve significant improvement for historical map text detection.
DCAN: Improving Temporal Action Detection via Dual Context Aggregation
Dec 07, 2021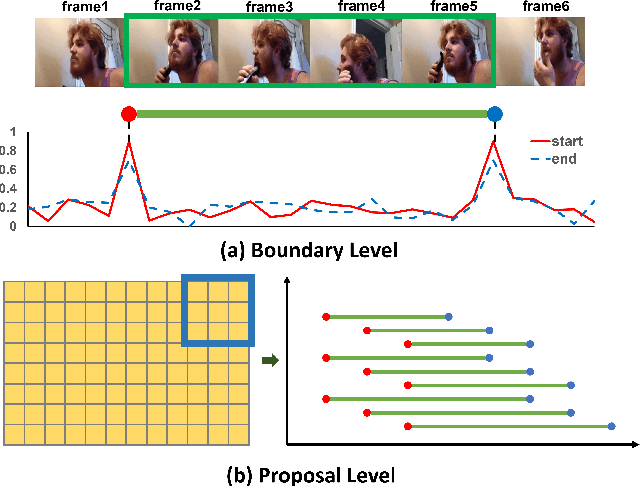
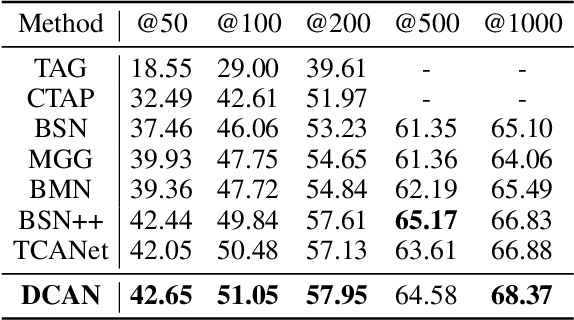
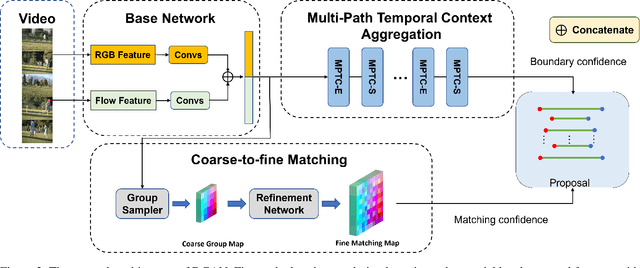
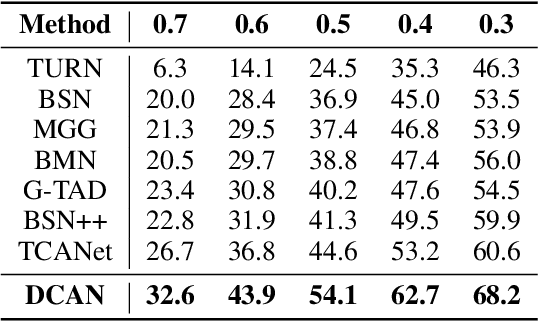
Temporal action detection aims to locate the boundaries of action in the video. The current method based on boundary matching enumerates and calculates all possible boundary matchings to generate proposals. However, these methods neglect the long-range context aggregation in boundary prediction. At the same time, due to the similar semantics of adjacent matchings, local semantic aggregation of densely-generated matchings cannot improve semantic richness and discrimination. In this paper, we propose the end-to-end proposal generation method named Dual Context Aggregation Network (DCAN) to aggregate context on two levels, namely, boundary level and proposal level, for generating high-quality action proposals, thereby improving the performance of temporal action detection. Specifically, we design the Multi-Path Temporal Context Aggregation (MTCA) to achieve smooth context aggregation on boundary level and precise evaluation of boundaries. For matching evaluation, Coarse-to-fine Matching (CFM) is designed to aggregate context on the proposal level and refine the matching map from coarse to fine. We conduct extensive experiments on ActivityNet v1.3 and THUMOS-14. DCAN obtains an average mAP of 35.39% on ActivityNet v1.3 and reaches mAP 54.14% at IoU@0.5 on THUMOS-14, which demonstrates DCAN can generate high-quality proposals and achieve state-of-the-art performance. We release the code at https://github.com/cg1177/DCAN.
3D Visual Tracking Framework with Deep Learning for Asteroid Exploration
Nov 21, 2021

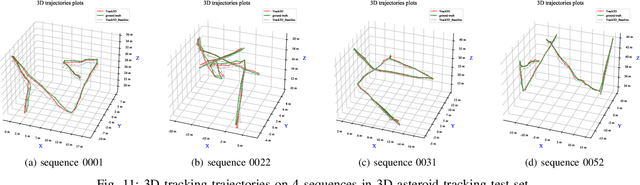
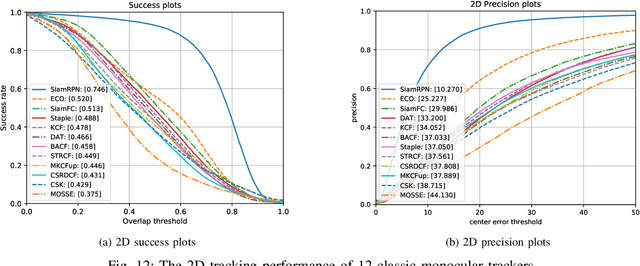
3D visual tracking is significant to deep space exploration programs, which can guarantee spacecraft to flexibly approach the target. In this paper, we focus on the studied accurate and real-time method for 3D tracking. Considering the fact that there are almost no public dataset for this topic, A new large-scale 3D asteroid tracking dataset is presented, including binocular video sequences, depth maps, and point clouds of diverse asteroids with various shapes and textures. Benefitting from the power and convenience of simulation platform, all the 2D and 3D annotations are automatically generated. Meanwhile, we propose a deep-learning based 3D tracking framework, named as Track3D, which involves 2D monocular tracker and a novel light-weight amodal axis-aligned bounding-box network, A3BoxNet. The evaluation results demonstrate that Track3D achieves state-of-the-art 3D tracking performance in both accuracy and precision, comparing to a baseline algorithm. Moreover, our framework has great generalization ability to 2D monocular tracking performance.