 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Solving Marginal MAP Exactly by Probabilistic Circuit Transformations
Nov 08, 2021
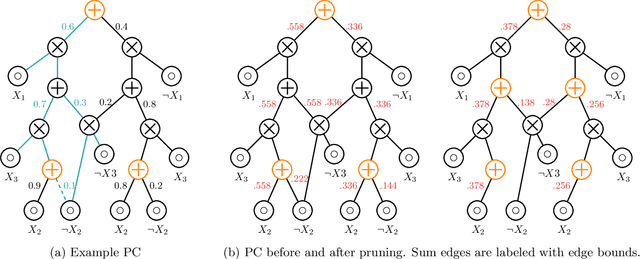
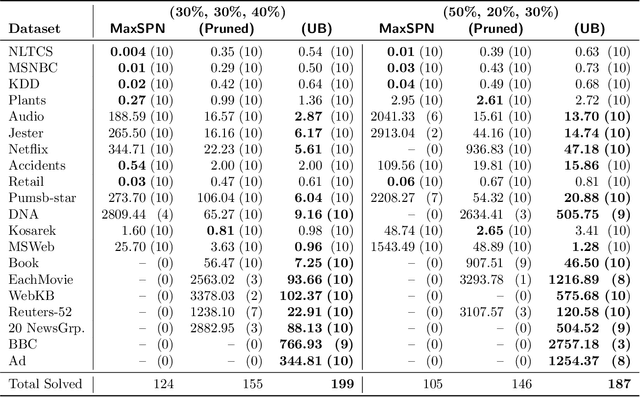
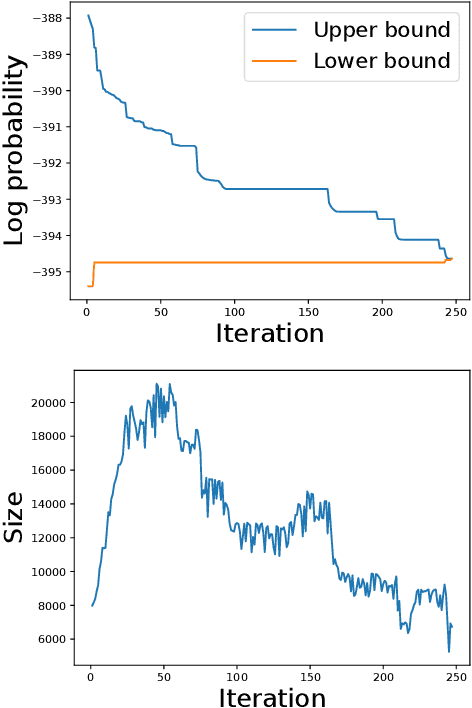
Probabilistic circuits (PCs) are a class of tractable probabilistic models that allow efficient, often linear-time, inference of queries such as marginals and most probable explanations (MPE). However, marginal MAP, which is central to many decision-making problems, remains a hard query for PCs unless they satisfy highly restrictive structural constraints. In this paper, we develop a pruning algorithm that removes parts of the PC that are irrelevant to a marginal MAP query, shrinking the PC while maintaining the correct solution. This pruning technique is so effective that we are able to build a marginal MAP solver based solely on iteratively transforming the circuit -- no search is required. We empirically demonstrate the efficacy of our approach on real-world datasets.
GoTube: Scalable Stochastic Verification of Continuous-Depth Models
Jul 18, 2021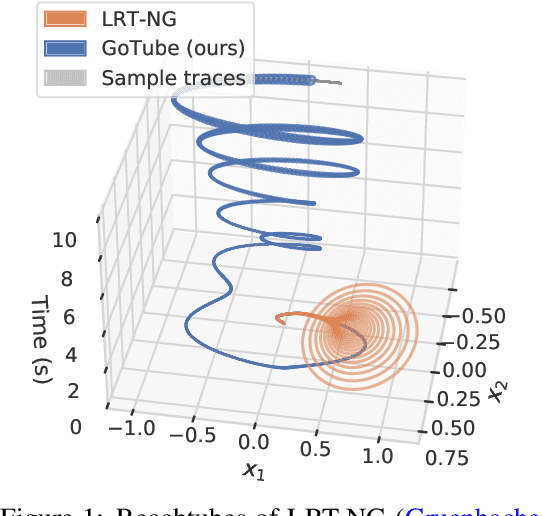
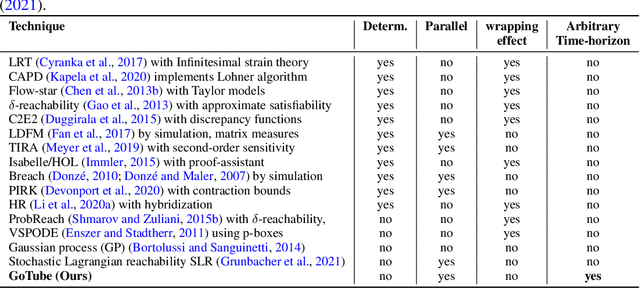
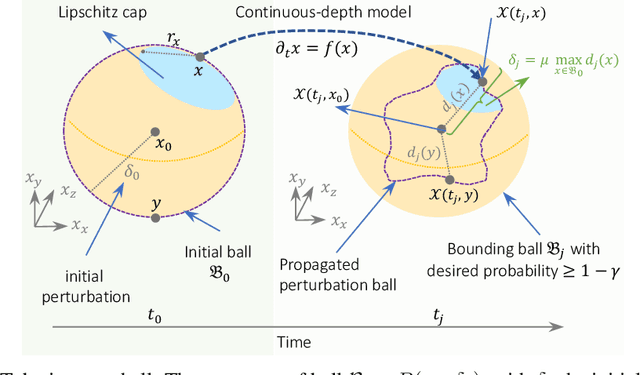
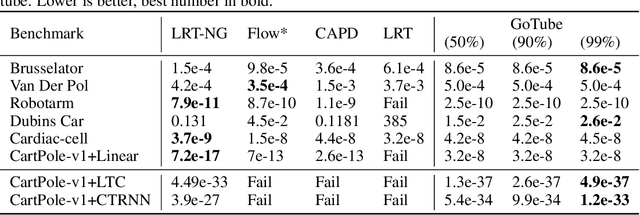
We introduce a new stochastic verification algorithm that formally quantifies the behavioral robustness of any time-continuous process formulated as a continuous-depth model. The algorithm solves a set of global optimization (Go) problems over a given time horizon to construct a tight enclosure (Tube) of the set of all process executions starting from a ball of initial states. We call our algorithm GoTube. Through its construction, GoTube ensures that the bounding tube is conservative up to a desired probability. GoTube is implemented in JAX and optimized to scale to complex continuous-depth models. Compared to advanced reachability analysis tools for time-continuous neural networks, GoTube provably does not accumulate over-approximation errors between time steps and avoids the infamous wrapping effect inherent in symbolic techniques. We show that GoTube substantially outperforms state-of-the-art verification tools in terms of the size of the initial ball, speed, time-horizon, task completion, and scalability, on a large set of experiments. GoTube is stable and sets the state-of-the-art for its ability to scale up to time horizons well beyond what has been possible before.
Characterizing and Improving the Resilience of Accelerators in Autonomous Robots
Oct 17, 2021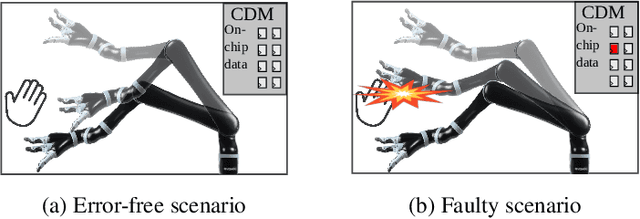
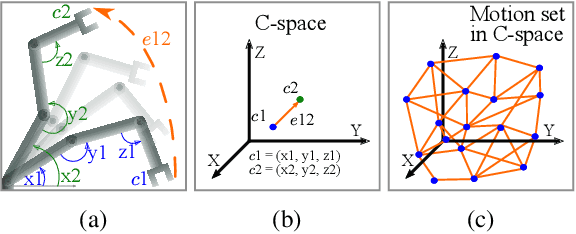

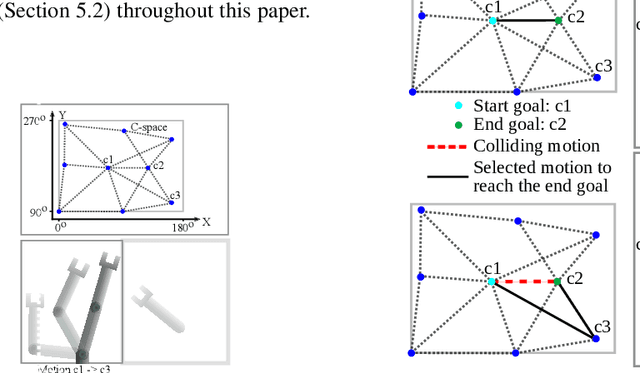
Motion planning is a computationally intensive and well-studied problem in autonomous robots. However, motion planning hardware accelerators (MPA) must be soft-error resilient for deployment in safety-critical applications, and blanket application of traditional mitigation techniques is ill-suited due to cost, power, and performance overheads. We propose Collision Exposure Factor (CEF), a novel metric to assess the failure vulnerability of circuits processing spatial relationships, including motion planning. CEF is based on the insight that the safety violation probability increases with the surface area of the physical space exposed by a bit-flip. We evaluate CEF on four MPAs. We demonstrate empirically that CEF is correlated with safety violation probability, and that CEF-aware selective error mitigation provides 12.3x, 9.6x, and 4.2x lower Failures-In-Time (FIT) rate on average for the same amount of protected memory compared to uniform, bit-position, and access-frequency-aware selection of critical data. Furthermore, we show how to employ CEF to enable fault characterization using 23,000x fewer fault injection (FI) experiments than exhaustive FI, and evaluate our FI approach on different robots and MPAs. We demonstrate that CEF-aware FI can provide insights on vulnerable bits in an MPA while taking the same amount of time as uniform statistical FI. Finally, we use the CEF to formulate guidelines for designing soft-error resilient MPAs.
Learning Physical Concepts in Cyber-Physical Systems: A Case Study
Dec 17, 2021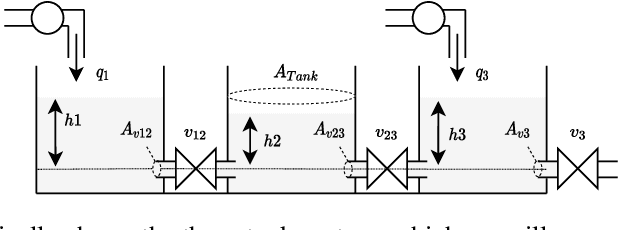
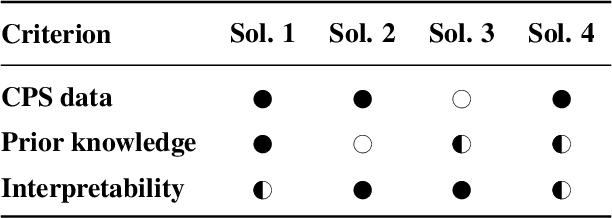
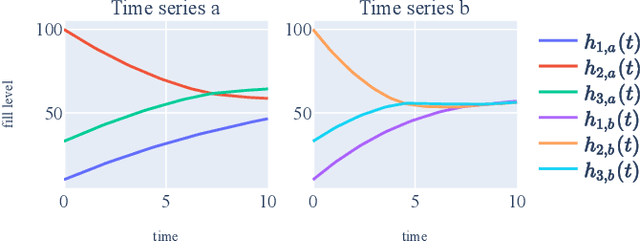
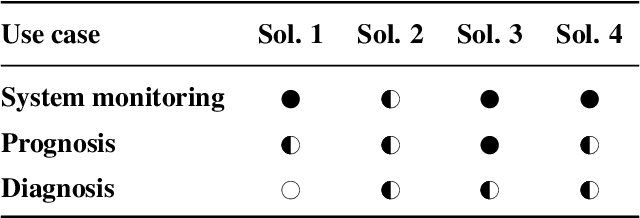
Machine Learning (ML) has achieved great successes in recent decades, both in research and in practice. In Cyber-Physical Systems (CPS), ML can for example be used to optimize systems, to detect anomalies or to identify root causes of system failures. However, existing algorithms suffer from two major drawbacks: (i) They are hard to interpret by human experts. (ii) Transferring results from one systems to another (similar) system is often a challenge. Concept learning, or Representation Learning (RepL), is a solution to both of these drawbacks; mimicking the human solution approach to explain-ability and transfer-ability: By learning general concepts such as physical quantities or system states, the model becomes interpretable by humans. Furthermore concepts on this abstract level can normally be applied to a wide range of different systems. Modern ML methods are already widely used in CPS, but concept learning and transfer learning are hardly used so far. In this paper, we provide an overview of the current state of research regarding methods for learning physical concepts in time series data, which is the primary form of sensor data of CPS. We also analyze the most important methods from the current state of the art using the example of a three-tank system. Based on these concrete implementations1, we discuss the advantages and disadvantages of the methods and show for which purpose and under which conditions they can be used.
MTS-CycleGAN: An Adversarial-based Deep Mapping Learning Network for Multivariate Time Series Domain Adaptation Applied to the Ironmaking Industry
Jul 15, 2020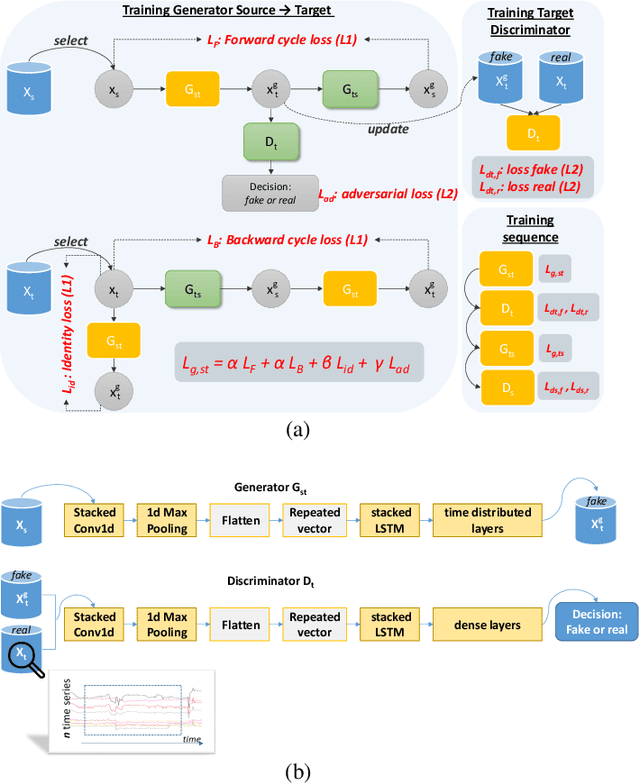
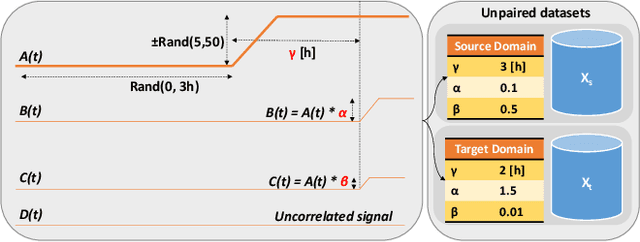
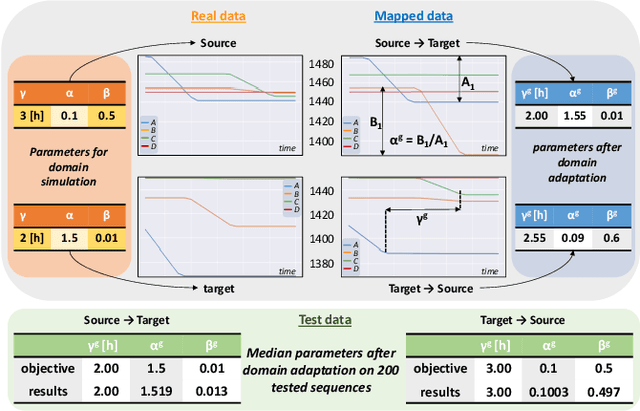
In the current era, an increasing number of machine learning models is generated for the automation of industrial processes. To that end, machine learning models are trained using historical data of each single asset leading to the development of asset-based models. To elevate machine learning models to a higher level of learning capability, domain adaptation has opened the door for extracting relevant patterns from several assets combined together. In this research we are focusing on translating the specific asset-based historical data (source domain) into data corresponding to one reference asset (target domain), leading to the creation of a multi-assets global dataset required for training domain invariant generic machine learning models. This research is conducted to apply domain adaptation to the ironmaking industry, and particularly for the creation of a domain invariant dataset by gathering data from different blast furnaces. The blast furnace data is characterized by multivariate time series. Domain adaptation for multivariate time series data hasn't been covered extensively in the literature. We propose MTS-CycleGAN, an algorithm for Multivariate Time Series data based on CycleGAN. To the best of our knowledge, this is the first time CycleGAN is applied on multivariate time series data. Our contribution is the integration in the CycleGAN architecture of a Long Short-Term Memory (LSTM)-based AutoEncoder (AE) for the generator and a stacked LSTM-based discriminator, together with dedicated extended features extraction mechanisms. MTS-CycleGAN is validated using two artificial datasets embedding the complex temporal relations between variables reflecting the blast furnace process. MTS-CycleGAN is successfully learning the mapping between both artificial multivariate time series datasets, allowing an efficient translation from a source to a target artificial blast furnace dataset.
Distributed Online Optimization with Byzantine Adversarial Agents
Sep 25, 2021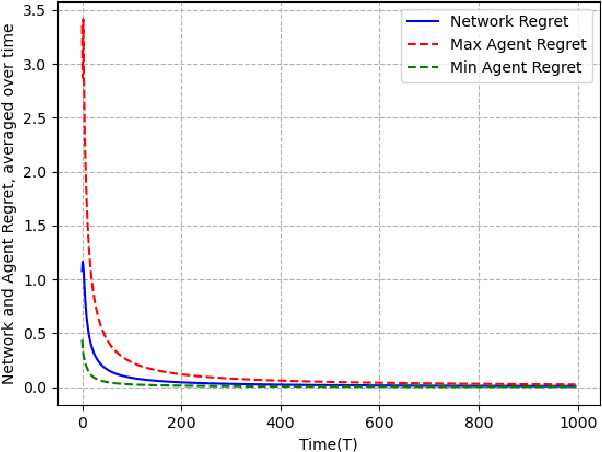
We study the problem of non-constrained, discrete-time, online distributed optimization in a multi-agent system where some of the agents do not follow the prescribed update rule either due to failures or malicious intentions. None of the agents have prior information about the identities of the faulty agents and any agent can communicate only with its immediate neighbours. At each time step, a Lipschitz strongly convex cost function is revealed locally to all the agents and the non-faulty agents update their states using their local information and the information obtained from their neighbours. We measure the performance of the online algorithm by comparing it to its offline version when the cost functions are known apriori. The difference between the same is termed as regret. Under sufficient conditions on the graph topology, the number and location of the adversaries, the defined regret grows sublinearly. We further conduct numerical experiments to validate our theoretical results.
YMIR: A Rapid Data-centric Development Platform for Vision Applications
Nov 19, 2021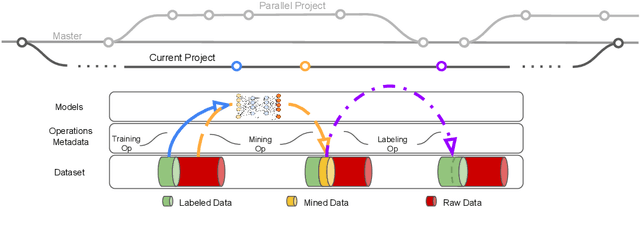
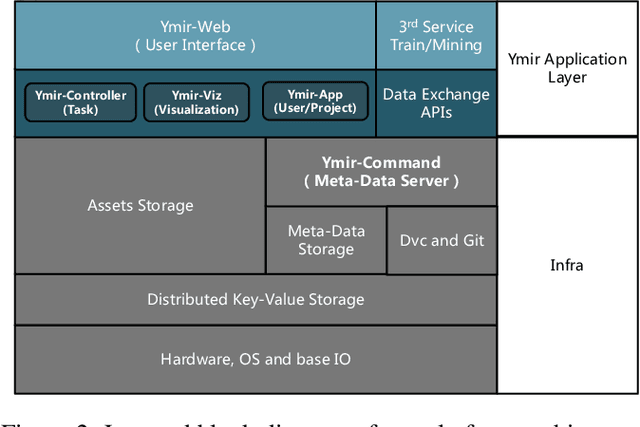
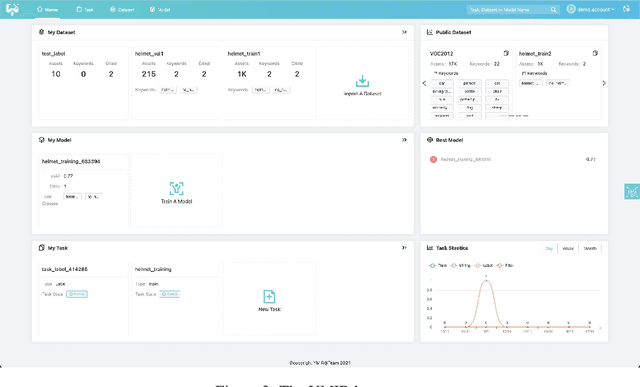
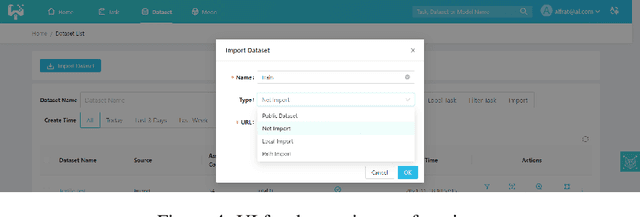
This paper introduces an open source platform for rapid development of computer vision applications. The platform puts the efficient data development at the center of the machine learning development process, integrates active learning methods, data and model version control, and uses concepts such as projects to enable fast iteration of multiple task specific datasets in parallel. We make it an open platform by abstracting the development process into core states and operations, and design open APIs to integrate third party tools as implementations of the operations. This open design reduces the development cost and adoption cost for ML teams with existing tools. At the same time, the platform supports recording project development history, through which successful projects can be shared to further boost model production efficiency on similar tasks. The platform is open source and is already used internally to meet the increasing demand from custom real world computer vision applications.
Graph Conditioned Sparse-Attention for Improved Source Code Understanding
Dec 03, 2021
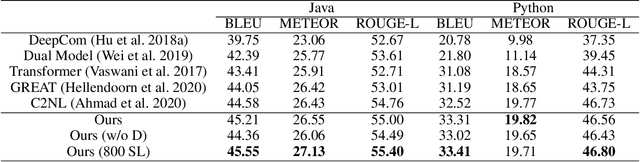
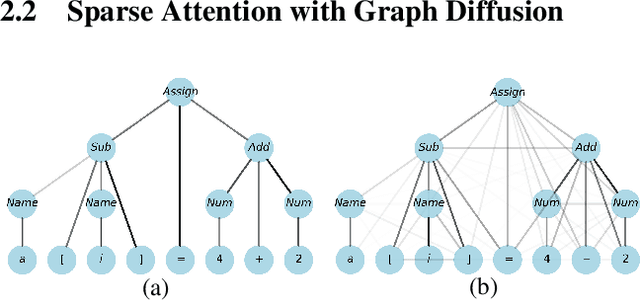
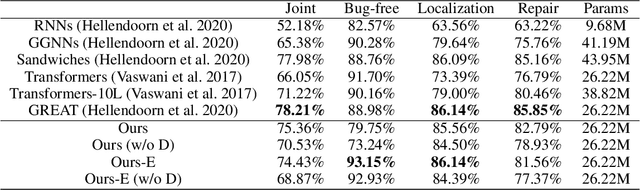
Transformer architectures have been successfully used in learning source code representations. The fusion between a graph representation like Abstract Syntax Tree (AST) and a source code sequence makes the use of current approaches computationally intractable for large input sequence lengths. Source code can have long-range dependencies that require larger sequence lengths to model effectively. Current approaches have a quadratic growth in computational and memory costs with respect to the sequence length. Using such models in practical scenarios is difficult. In this work, we propose the conditioning of a source code snippet with its graph modality by using the graph adjacency matrix as an attention mask for a sparse self-attention mechanism and the use of a graph diffusion mechanism to model longer-range token dependencies. Our model reaches state-of-the-art results in BLEU, METEOR, and ROUGE-L metrics for the code summarization task and near state-of-the-art accuracy in the variable misuse task. The memory use and inference time of our model have linear growth with respect to the input sequence length as compared to the quadratic growth of previous works.
Embeddings and labeling schemes for A*
Nov 19, 2021
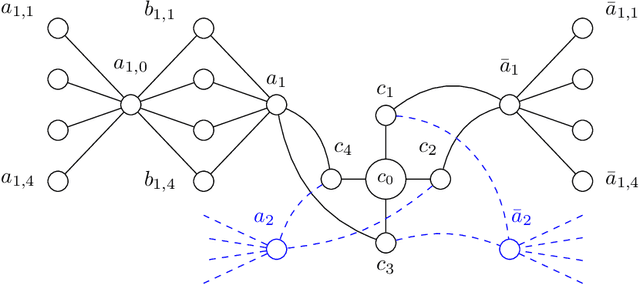
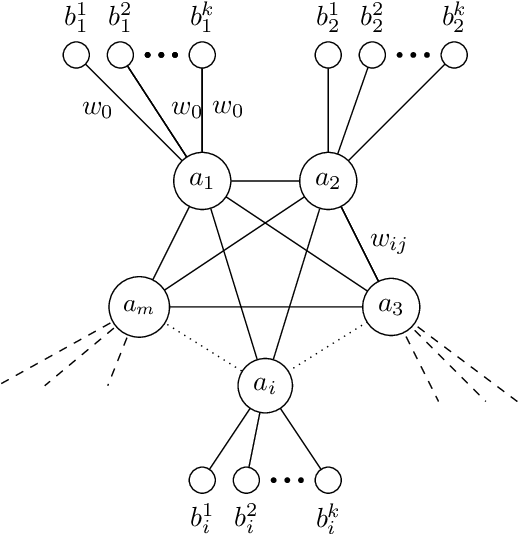
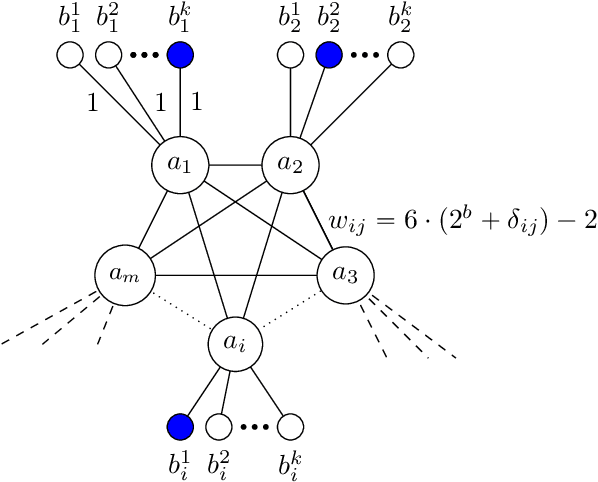
A* is a classic and popular method for graphs search and path finding. It assumes the existence of a heuristic function $h(u,t)$ that estimates the shortest distance from any input node $u$ to the destination $t$. Traditionally, heuristics have been handcrafted by domain experts. However, over the last few years, there has been a growing interest in learning heuristic functions. Such learned heuristics estimate the distance between given nodes based on "features" of those nodes. In this paper we formalize and initiate the study of such feature-based heuristics. In particular, we consider heuristics induced by norm embeddings and distance labeling schemes, and provide lower bounds for the tradeoffs between the number of dimensions or bits used to represent each graph node, and the running time of the A* algorithm. We also show that, under natural assumptions, our lower bounds are almost optimal.
Geometry-Aware Fruit Grasping Estimation for Robotic Harvesting in Orchards
Dec 08, 2021

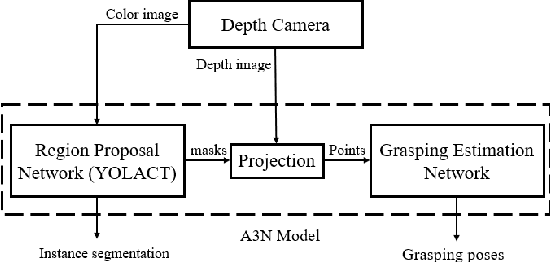
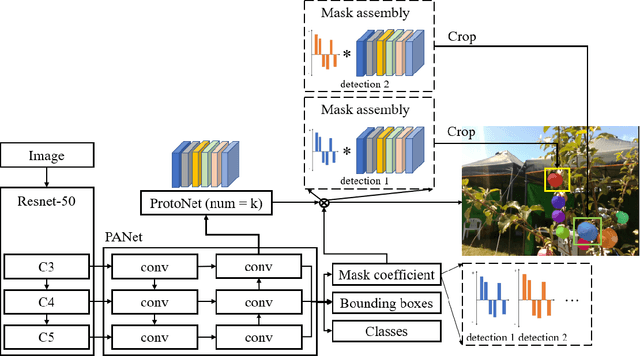
Field robotic harvesting is a promising technique in recent development of agricultural industry. It is vital for robots to recognise and localise fruits before the harvesting in natural orchards. However, the workspace of harvesting robots in orchards is complex: many fruits are occluded by branches and leaves. It is important to estimate a proper grasping pose for each fruit before performing the manipulation. In this study, a geometry-aware network, A3N, is proposed to perform end-to-end instance segmentation and grasping estimation using both color and geometry sensory data from a RGB-D camera. Besides, workspace geometry modelling is applied to assist the robotic manipulation. Moreover, we implement a global-to-local scanning strategy, which enables robots to accurately recognise and retrieve fruits in field environments with two consumer-level RGB-D cameras. We also evaluate the accuracy and robustness of proposed network comprehensively in experiments. The experimental results show that A3N achieves 0.873 on instance segmentation accuracy, with an average computation time of 35 ms. The average accuracy of grasping estimation is 0.61 cm and 4.8$^{\circ}$ in centre and orientation, respectively. Overall, the robotic system that utilizes the global-to-local scanning and A3N, achieves success rate of harvesting ranging from 70\% - 85\% in field harvesting experiments.