 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Power efficient analog features for audio recognition
Oct 07, 2021
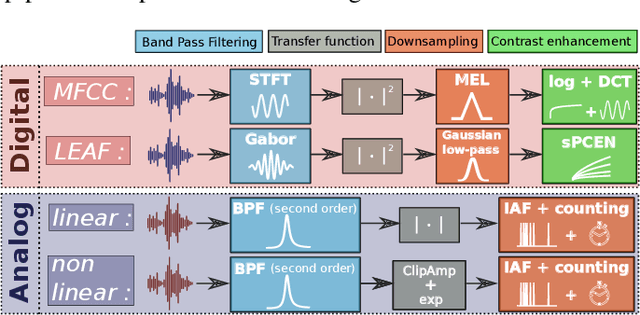
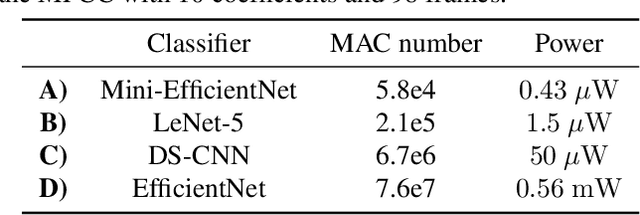
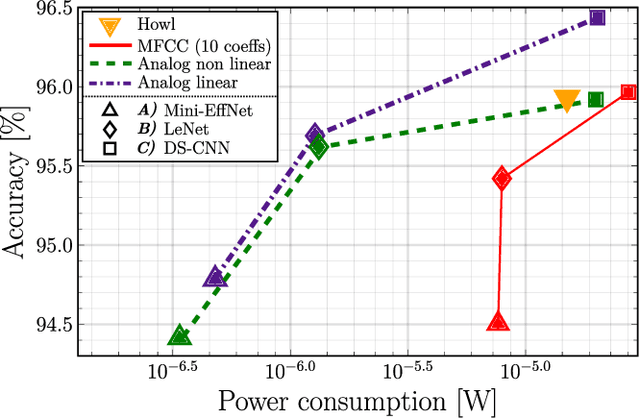
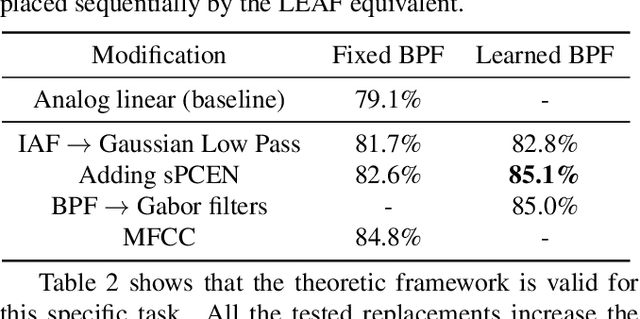
The digital signal processing-based representations like the Mel-Frequency Cepstral Coefficient are well known to be a solid basis for various audio processing tasks. Alternatively, analog feature representations, relying on analog-electronics-feasible bandpass filtering, allow much lower system power consumption compared with the digital counterpart, while parity performance on traditional tasks like voice activity detection can be achieved. This work explores the possibility of using analog features on multiple speech processing tasks that vary in time dependencies: wake word detection, keyword spotting, and speaker identification. The results of this evaluation show that the analog features are still more power-efficient and competitive on simpler tasks than digital features but yield an increasing performance drop on more complex tasks when long-time correlations are present. We also introduce a novel theoretical framework based on information theory to understand this performance drop by quantifying information flow in feature calculation which helps identify the performance bottlenecks. The theoretical claims are experimentally validated, leading to a maximum of 6% increase of keyword spotting accuracy, even surpassing the digital baseline features. The proposed analog-feature-based systems could pave the way to achieving best-in-class accuracy and power consumption simultaneously.
Geometry-Guided Progressive NeRF for Generalizable and Efficient Neural Human Rendering
Dec 08, 2021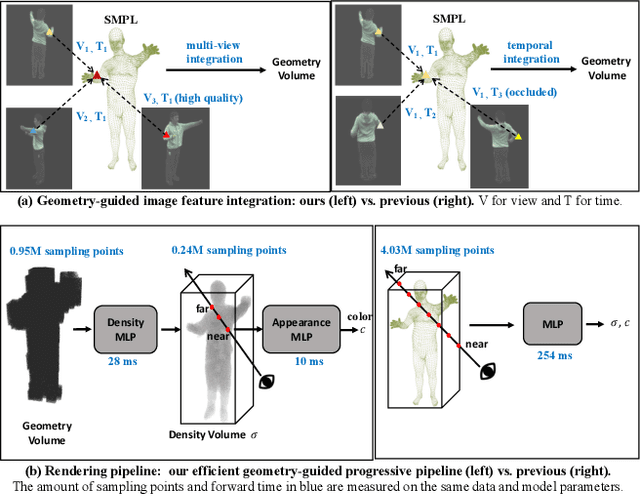
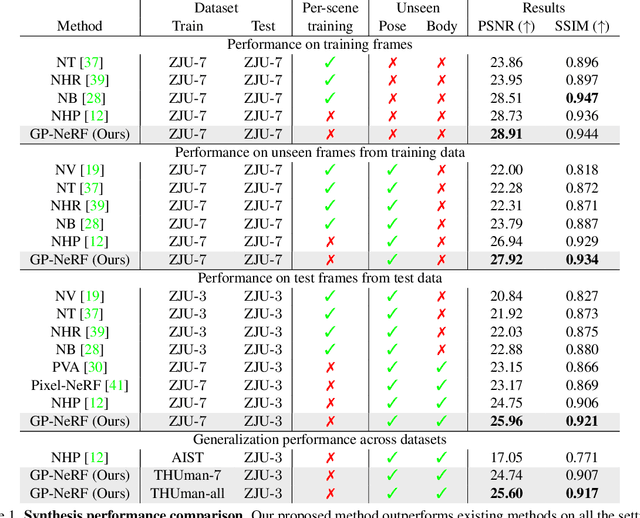
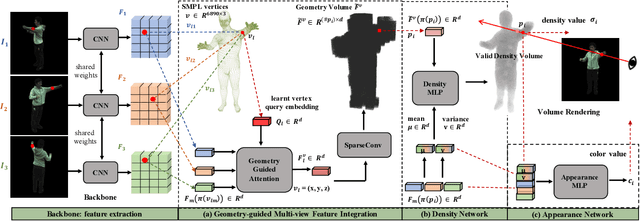
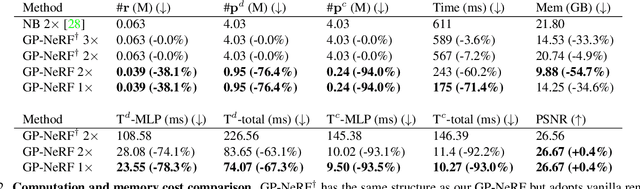
In this work we develop a generalizable and efficient Neural Radiance Field (NeRF) pipeline for high-fidelity free-viewpoint human body synthesis under settings with sparse camera views. Though existing NeRF-based methods can synthesize rather realistic details for human body, they tend to produce poor results when the input has self-occlusion, especially for unseen humans under sparse views. Moreover, these methods often require a large number of sampling points for rendering, which leads to low efficiency and limits their real-world applicability. To address these challenges, we propose a Geometry-guided Progressive NeRF~(GP-NeRF). In particular, to better tackle self-occlusion, we devise a geometry-guided multi-view feature integration approach that utilizes the estimated geometry prior to integrate the incomplete information from input views and construct a complete geometry volume for the target human body. Meanwhile, for achieving higher rendering efficiency, we introduce a geometry-guided progressive rendering pipeline, which leverages the geometric feature volume and the predicted density values to progressively reduce the number of sampling points and speed up the rendering process. Experiments on the ZJU-MoCap and THUman datasets show that our method outperforms the state-of-the-arts significantly across multiple generalization settings, while the time cost is reduced >70% via applying our efficient progressive rendering pipeline.
Classification of chaotic time series with deep learning
Jul 26, 2019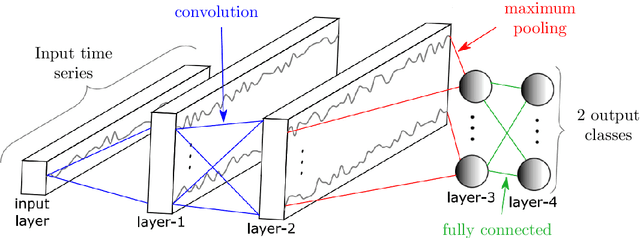

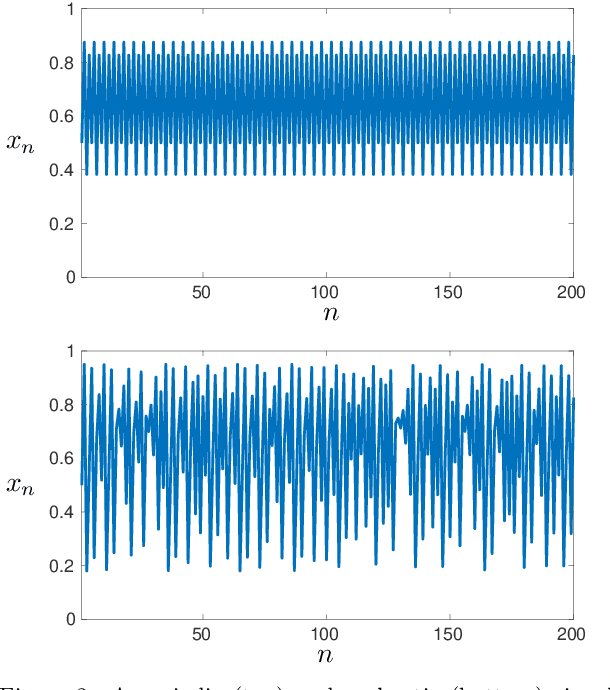
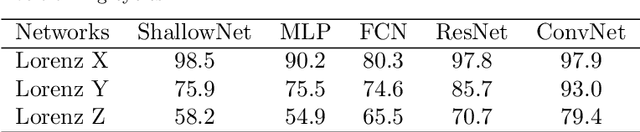
We use deep neural networks to classify time series generated by discrete and continuous dynamical systems based on their chaotic behaviour. Our approach to circumvent the lack of precise models for some of the most challenging real-life applications is to train different neural networks on a data set from a dynamical system with a basic or low-dimensional phase space and then use these networks to classify time series of a dynamical system with more intricate or high-dimensional phase space. We illustrate this extrapolation approach using the logistic map, the sine-circle map, the Lorenz system, and the Kuramoto-Sivashinsky equation. We observe that the proposed convolutional neural network with large kernel size outperforms state-of-the-art neural networks for time series classification and is able to classify time series as chaotic or non-chaotic with high accuracy.
The similarity index of scientific publications with equations and formulas, identification of self-plagiarism, and testing of the iThenticate system
Dec 21, 2021The problems of estimating the similarity index of mathematical and other scientific publications containing equations and formulas are discussed for the first time. It is shown that the presence of equations and formulas (as well as figures, drawings, and tables) is a complicating factor that significantly complicates the study of such texts. It is shown that the method for determining the similarity index of publications, based on taking into account individual mathematical symbols and parts of equations and formulas, is ineffective and can lead to erroneous and even completely absurd conclusions. The possibilities of the most popular software system iThenticate, currently used in scientific journals, are investigated for detecting plagiarism and self-plagiarism. The results of processing by the iThenticate system of specific examples and special test problems containing equations (PDEs and ODEs), exact solutions, and some formulas are presented. It has been established that this software system when analyzing inhomogeneous texts, is often unable to distinguish self-plagiarism from pseudo-self-plagiarism (false self-plagiarism). A model complex situation is considered, in which the identification of self-plagiarism requires the involvement of highly qualified specialists of a narrow profile. Various ways to improve the work of software systems for comparing inhomogeneous texts are proposed. This article will be useful to researchers and university teachers in mathematics, physics, and engineering sciences, programmers dealing with problems in image recognition and research topics of digital image processing, as well as a wide range of readers who are interested in issues of plagiarism and self-plagiarism.
* 23 pages, 3 figures, 2 photos
Solving Marginal MAP Exactly by Probabilistic Circuit Transformations
Nov 08, 2021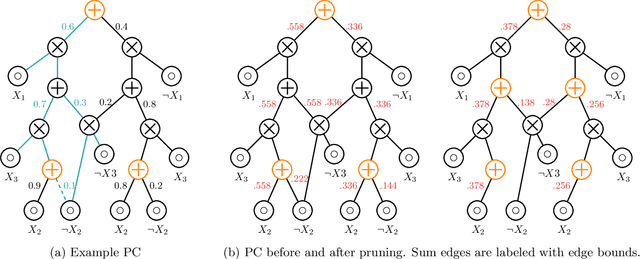
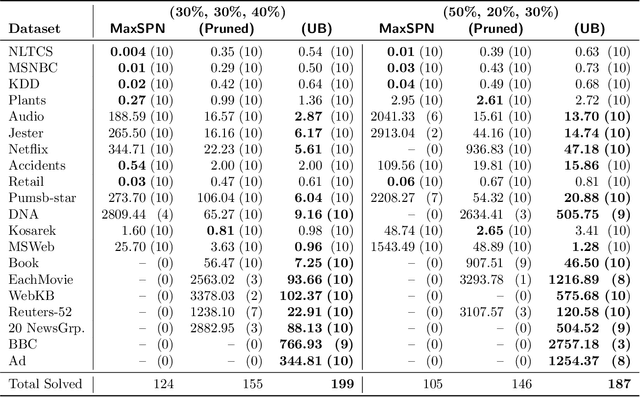
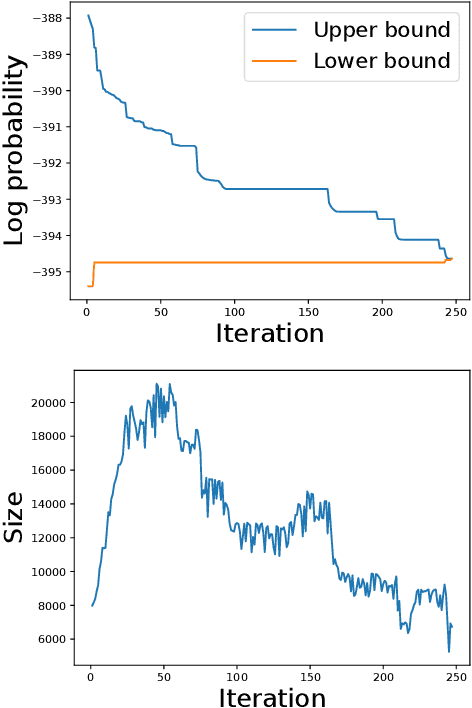
Probabilistic circuits (PCs) are a class of tractable probabilistic models that allow efficient, often linear-time, inference of queries such as marginals and most probable explanations (MPE). However, marginal MAP, which is central to many decision-making problems, remains a hard query for PCs unless they satisfy highly restrictive structural constraints. In this paper, we develop a pruning algorithm that removes parts of the PC that are irrelevant to a marginal MAP query, shrinking the PC while maintaining the correct solution. This pruning technique is so effective that we are able to build a marginal MAP solver based solely on iteratively transforming the circuit -- no search is required. We empirically demonstrate the efficacy of our approach on real-world datasets.
Fast Multi-Resolution Transformer Fine-tuning for Extreme Multi-label Text Classification
Oct 01, 2021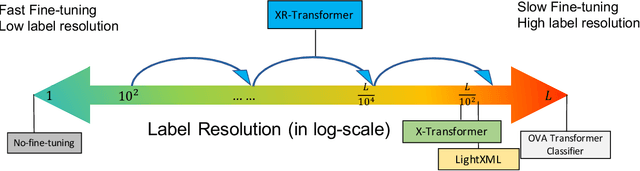
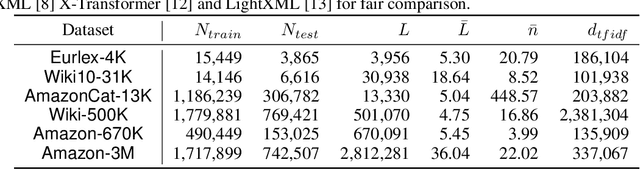
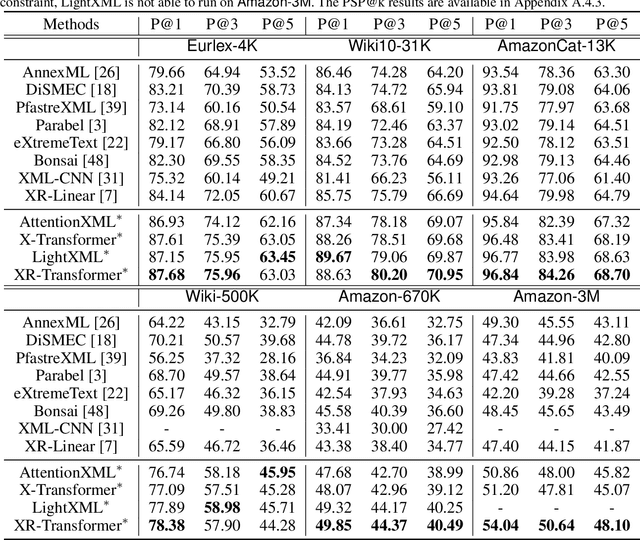

Extreme multi-label text classification (XMC) seeks to find relevant labels from an extreme large label collection for a given text input. Many real-world applications can be formulated as XMC problems, such as recommendation systems, document tagging and semantic search. Recently, transformer based XMC methods, such as X-Transformer and LightXML, have shown significant improvement over other XMC methods. Despite leveraging pre-trained transformer models for text representation, the fine-tuning procedure of transformer models on large label space still has lengthy computational time even with powerful GPUs. In this paper, we propose a novel recursive approach, XR-Transformer to accelerate the procedure through recursively fine-tuning transformer models on a series of multi-resolution objectives related to the original XMC objective function. Empirical results show that XR-Transformer takes significantly less training time compared to other transformer-based XMC models while yielding better state-of-the-art results. In particular, on the public Amazon-3M dataset with 3 million labels, XR-Transformer is not only 20x faster than X-Transformer but also improves the Precision@1 from 51% to 54%.
YMIR: A Rapid Data-centric Development Platform for Vision Applications
Nov 19, 2021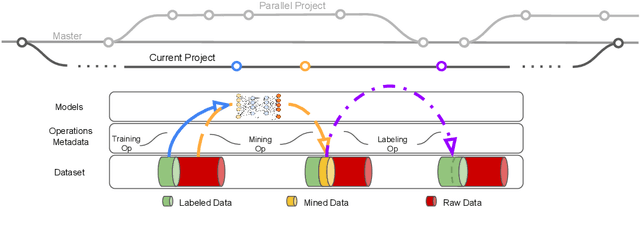
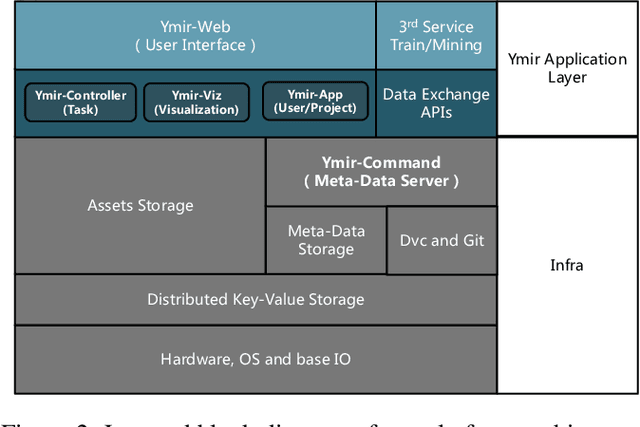
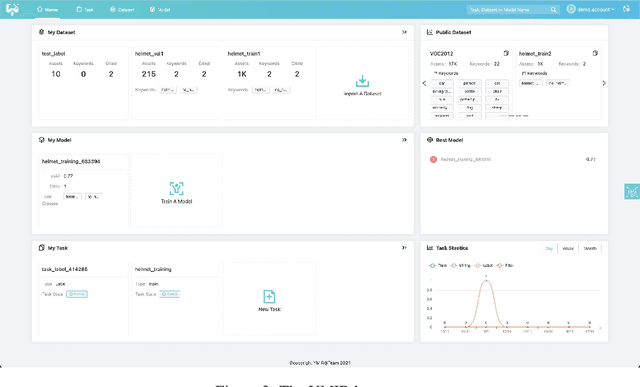
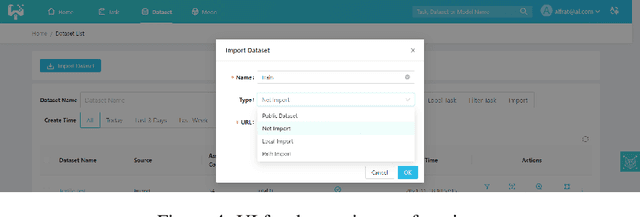
This paper introduces an open source platform for rapid development of computer vision applications. The platform puts the efficient data development at the center of the machine learning development process, integrates active learning methods, data and model version control, and uses concepts such as projects to enable fast iteration of multiple task specific datasets in parallel. We make it an open platform by abstracting the development process into core states and operations, and design open APIs to integrate third party tools as implementations of the operations. This open design reduces the development cost and adoption cost for ML teams with existing tools. At the same time, the platform supports recording project development history, through which successful projects can be shared to further boost model production efficiency on similar tasks. The platform is open source and is already used internally to meet the increasing demand from custom real world computer vision applications.
Embeddings and labeling schemes for A*
Nov 19, 2021
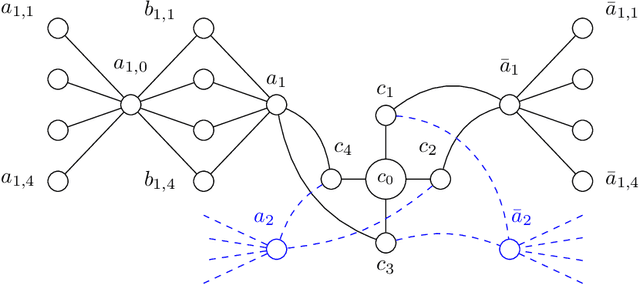
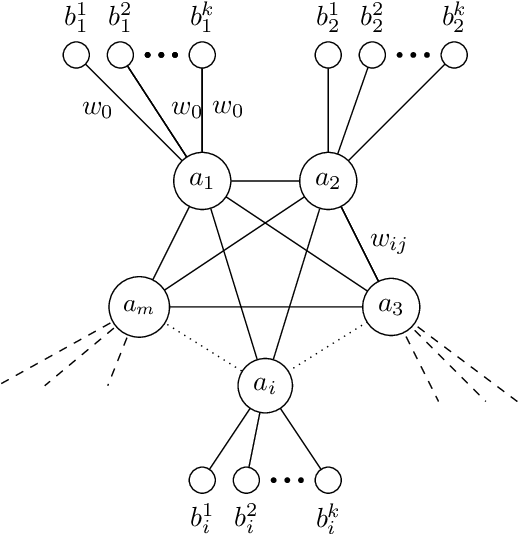
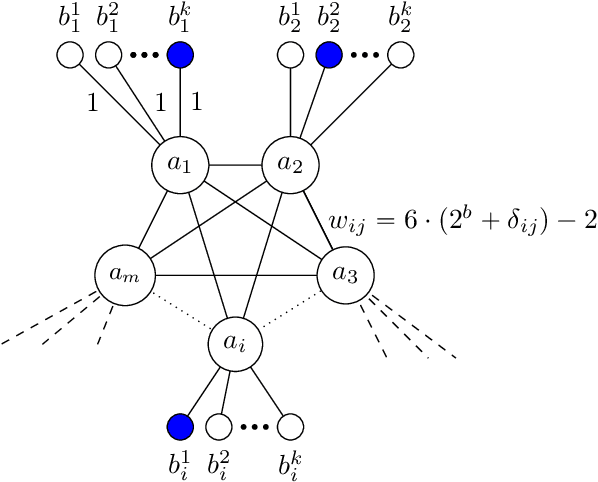
A* is a classic and popular method for graphs search and path finding. It assumes the existence of a heuristic function $h(u,t)$ that estimates the shortest distance from any input node $u$ to the destination $t$. Traditionally, heuristics have been handcrafted by domain experts. However, over the last few years, there has been a growing interest in learning heuristic functions. Such learned heuristics estimate the distance between given nodes based on "features" of those nodes. In this paper we formalize and initiate the study of such feature-based heuristics. In particular, we consider heuristics induced by norm embeddings and distance labeling schemes, and provide lower bounds for the tradeoffs between the number of dimensions or bits used to represent each graph node, and the running time of the A* algorithm. We also show that, under natural assumptions, our lower bounds are almost optimal.
The Box Size Confidence Bias Harms Your Object Detector
Dec 03, 2021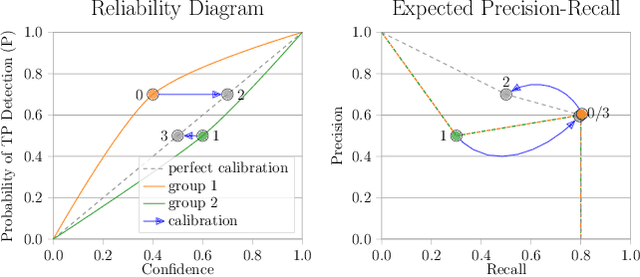
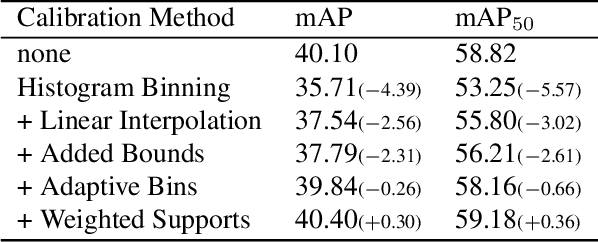
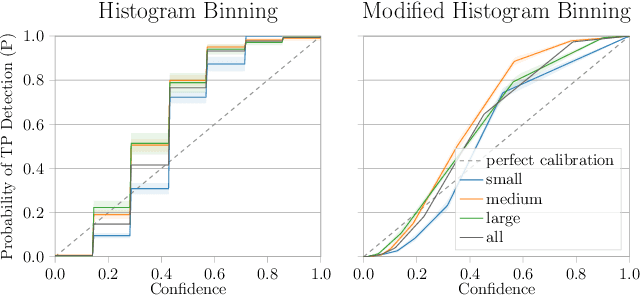

Countless applications depend on accurate predictions with reliable confidence estimates from modern object detectors. It is well known, however, that neural networks including object detectors produce miscalibrated confidence estimates. Recent work even suggests that detectors' confidence predictions are biased with respect to object size and position, but it is still unclear how this bias relates to the performance of the affected object detectors. We formally prove that the conditional confidence bias is harming the expected performance of object detectors and empirically validate these findings. Specifically, we demonstrate how to modify the histogram binning calibration to not only avoid performance impairment but also improve performance through conditional confidence calibration. We further find that the confidence bias is also present in detections generated on the training data of the detector, which we leverage to perform our de-biasing without using additional data. Moreover, Test Time Augmentation magnifies this bias, which results in even larger performance gains from our calibration method. Finally, we validate our findings on a diverse set of object detection architectures and show improvements of up to 0.6 mAP and 0.8 mAP50 without extra data or training.
ST2Vec: Spatio-Temporal Trajectory Similarity Learning in Road Networks
Dec 17, 2021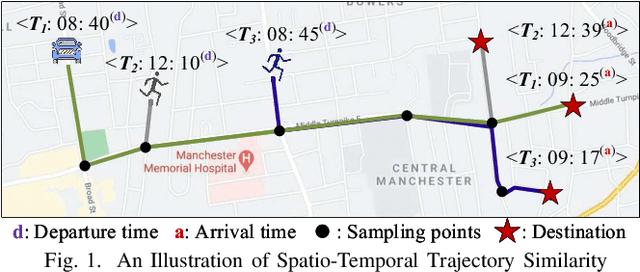

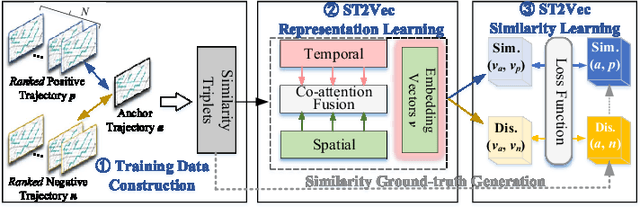
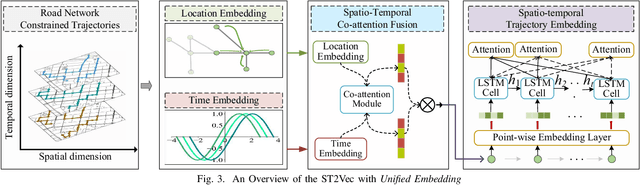
People and vehicle trajectories embody important information of transportation infrastructures, and trajectory similarity computation is functionality in many real-world applications involving trajectory data analysis. Recently, deep-learning based trajectory similarity techniques hold the potential to offer improved efficiency and adaptability over traditional similarity techniques. Nevertheless, the existing trajectory similarity learning proposals emphasize spatial similarity over temporal similarity, making them suboptimal for time-aware analyses. To this end, we propose ST2Vec, a trajectory-representation-learning based architecture that considers fine-grained spatial and temporal correlations between pairs of trajectories for spatio-temporal similarity learning in road networks. To the best of our knowledge, this is the first deep-learning proposal for spatio-temporal trajectory similarity analytics. Specifically, ST2Vec encompasses three phases: (i) training data preparation that selects representative training samples; (ii) spatial and temporal modeling that encode spatial and temporal characteristics of trajectories, where a generic temporal modeling module (TMM) is designed; and (iii) spatio-temporal co-attention fusion (STCF), where a unified fusion (UF) approach is developed to help generating unified spatio-temporal trajectory embeddings that capture the spatio-temporal similarity relations between trajectories. Further, inspired by curriculum concept, ST2Vec employs the curriculum learning for model optimization to improve both convergence and effectiveness. An experimental study offers evidence that ST2Vec outperforms all state-of-the-art competitors substantially in terms of effectiveness, efficiency, and scalability, while showing low parameter sensitivity and good model robustness.