 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A MIMO Radar-based Few-Shot Learning Approach for Human-ID
Oct 16, 2021
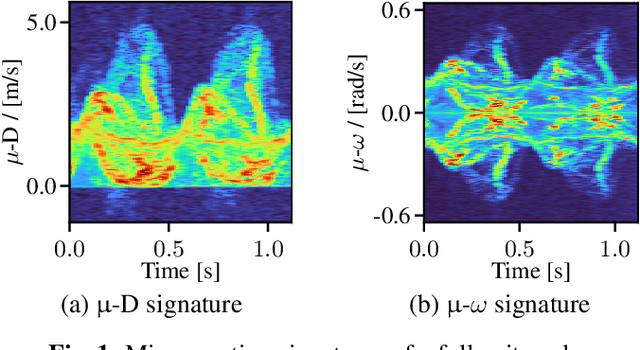
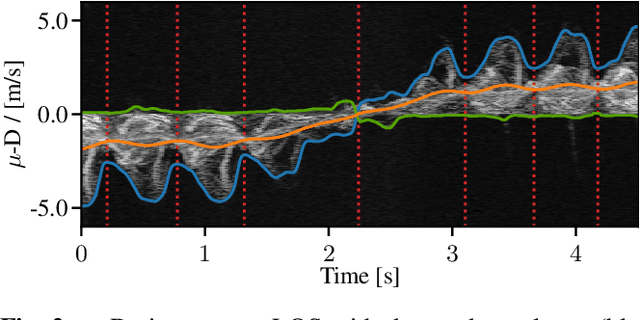
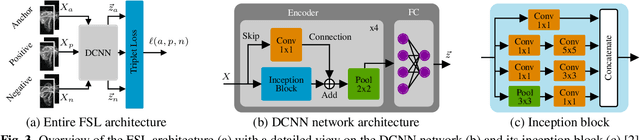

Radar for deep learning-based human identification has become a research area of increasing interest. It has been shown that micro-Doppler (\(\upmu\)-D) can reflect the walking behavior through capturing the periodic limbs' micro-motions. One of the main aspects is maximizing the number of included classes while considering the real-time and training dataset size constraints. In this paper, a multiple-input-multiple-output (MIMO) radar is used to formulate micro-motion spectrograms of the elevation angular velocity (\(\upmu\)-\(\omega\)). The effectiveness of concatenating this newly-formulated spectrogram with the commonly used \(\upmu\)-D is investigated. To accommodate for non-constrained real walking motion, an adaptive cycle segmentation framework is utilized and a metric learning network is trained on half gait cycles (\(\approx\) 0.5 s). Studies on the effects of various numbers of classes (5--20), different dataset sizes, and varying observation time windows 1--2 s are conducted. A non-constrained walking dataset of 22 subjects is collected with different aspect angles with respect to the radar. The proposed few-shot learning (FSL) approach achieves a classification error of 11.3 % with only 2 min of training data per subject.
Simulation platform for pattern recognition based on reservoir computing with memristor networks
Dec 01, 2021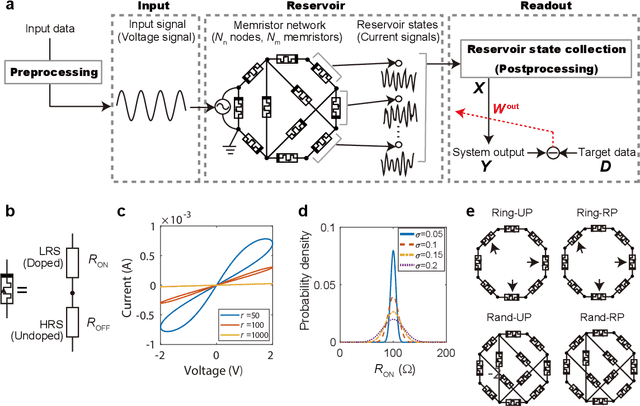
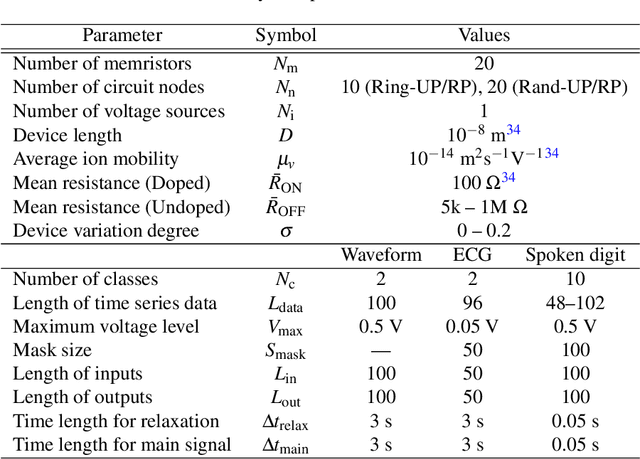
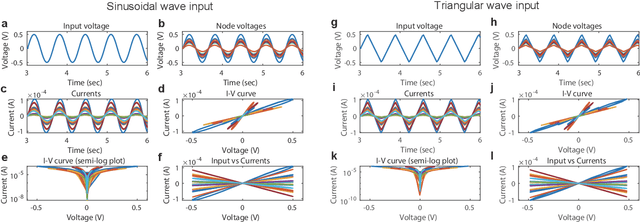
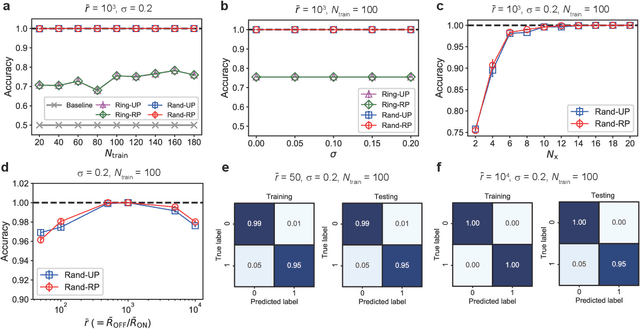
Memristive systems and devices are potentially available for implementing reservoir computing (RC) systems applied to pattern recognition. However, the computational ability of memristive RC systems depends on intertwined factors such as system architectures and physical properties of memristive elements, which complicates identifying the key factor for system performance. Here we develop a simulation platform for RC with memristor device networks, which enables testing different system designs for performance improvement. Numerical simulations show that the memristor-network-based RC systems can yield high computational performance comparable to that of state-of-the-art methods in three time series classification tasks. We demonstrate that the excellent and robust computation under device-to-device variability can be achieved by appropriately setting network structures, nonlinearity of memristors, and pre/post-processing, which increases the potential for reliable computation with unreliable component devices. Our results contribute to an establishment of a design guide for memristive reservoirs toward a realization of energy-efficient machine learning hardware.
Personalized On-Device E-health Analytics with Decentralized Block Coordinate Descent
Dec 17, 2021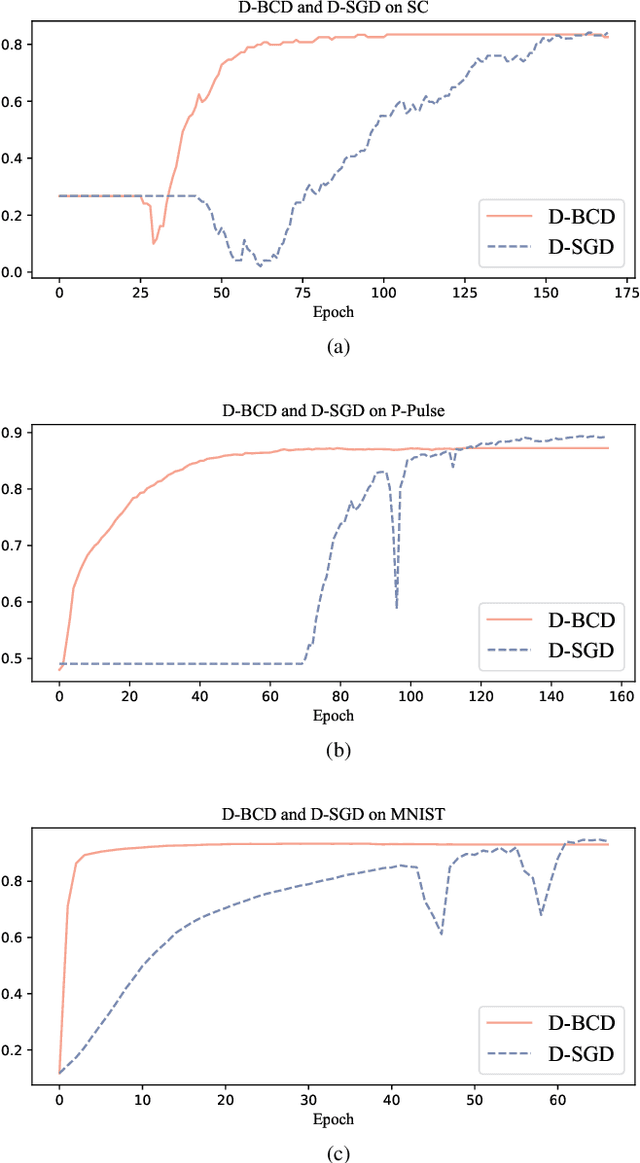
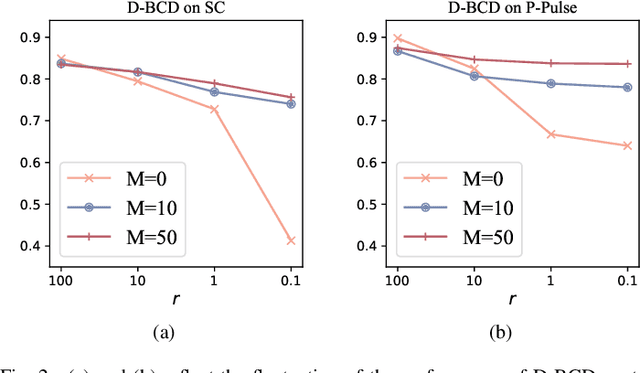
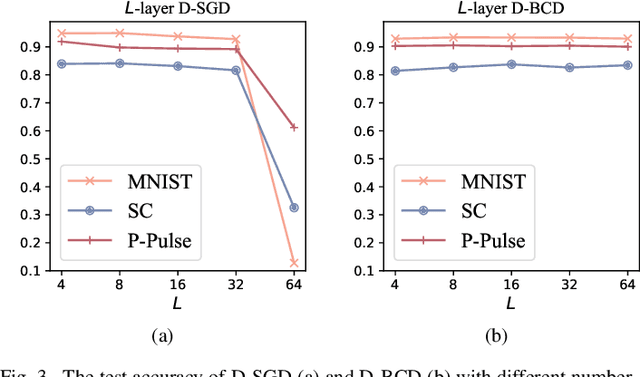
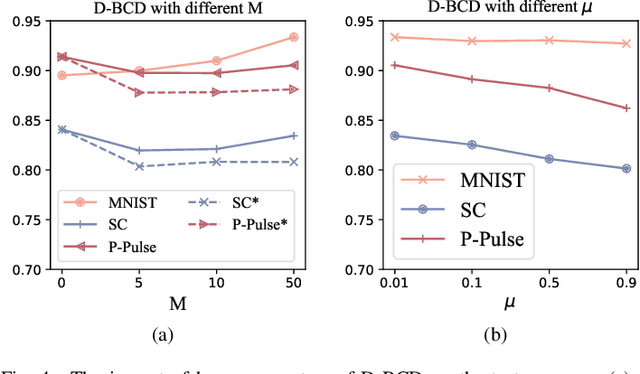
Actuated by the growing attention to personal healthcare and the pandemic, the popularity of E-health is proliferating. Nowadays, enhancement on medical diagnosis via machine learning models has been highly effective in many aspects of e-health analytics. Nevertheless, in the classic cloud-based/centralized e-health paradigms, all the data will be centrally stored on the server to facilitate model training, which inevitably incurs privacy concerns and high time delay. Distributed solutions like Decentralized Stochastic Gradient Descent (D-SGD) are proposed to provide safe and timely diagnostic results based on personal devices. However, methods like D-SGD are subject to the gradient vanishing issue and usually proceed slowly at the early training stage, thereby impeding the effectiveness and efficiency of training. In addition, existing methods are prone to learning models that are biased towards users with dense data, compromising the fairness when providing E-health analytics for minority groups. In this paper, we propose a Decentralized Block Coordinate Descent (D-BCD) learning framework that can better optimize deep neural network-based models distributed on decentralized devices for E-health analytics. Benchmarking experiments on three real-world datasets illustrate the effectiveness and practicality of our proposed D-BCD, where additional simulation study showcases the strong applicability of D-BCD in real-life E-health scenarios.
Multiple Sclerosis Lesions Segmentation using Attention-Based CNNs in FLAIR Images
Jan 05, 2022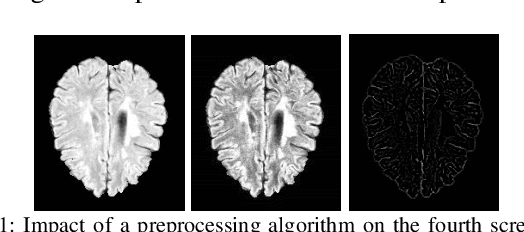
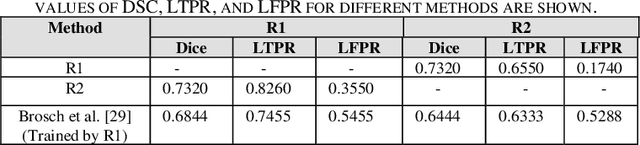
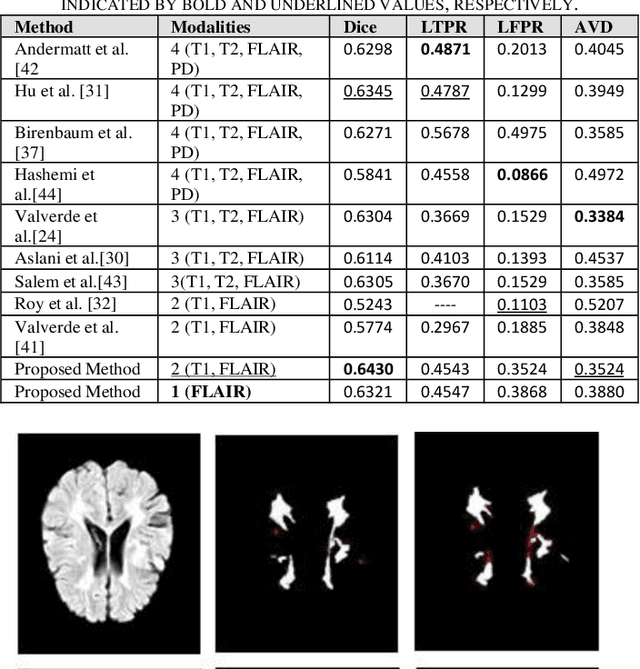
Objective: Multiple Sclerosis (MS) is an autoimmune, and demyelinating disease that leads to lesions in the central nervous system. This disease can be tracked and diagnosed using Magnetic Resonance Imaging (MRI). Up to now a multitude of multimodality automatic biomedical approaches is used to segment lesions which are not beneficial for patients in terms of cost, time, and usability. The authors of the present paper propose a method employing just one modality (FLAIR image) to segment MS lesions accurately. Methods: A patch-based Convolutional Neural Network (CNN) is designed, inspired by 3D-ResNet and spatial-channel attention module, to segment MS lesions. The proposed method consists of three stages: (1) the contrast-limited adaptive histogram equalization (CLAHE) is applied to the original images and concatenated to the extracted edges in order to create 4D images; (2) the patches of size 80 * 80 * 80 * 2 are randomly selected from the 4D images; and (3) the extracted patches are passed into an attention-based CNN which is used to segment the lesions. Finally, the proposed method was compared to previous studies of the same dataset. Results: The current study evaluates the model, with a test set of ISIB challenge data. Experimental results illustrate that the proposed approach significantly surpasses existing methods in terms of Dice similarity and Absolute Volume Difference while the proposed method use just one modality (FLAIR) to segment the lesions. Conclusions: The authors have introduced an automated approach to segment the lesions which is based on, at most, two modalities as an input. The proposed architecture is composed of convolution, deconvolution, and an SCA-VoxRes module as an attention module. The results show, the proposed method outperforms well compare to other methods.
Data-driven Hedging of Stock Index Options via Deep Learning
Nov 05, 2021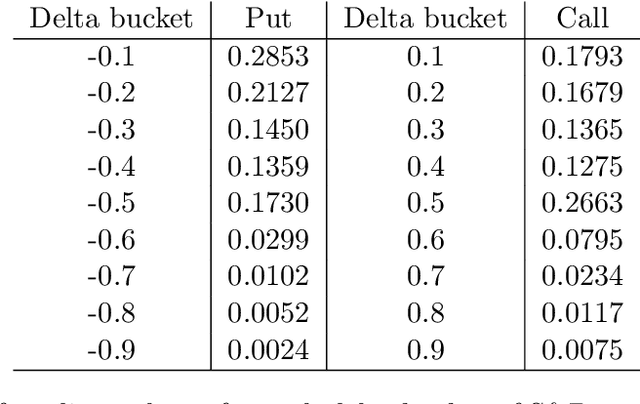
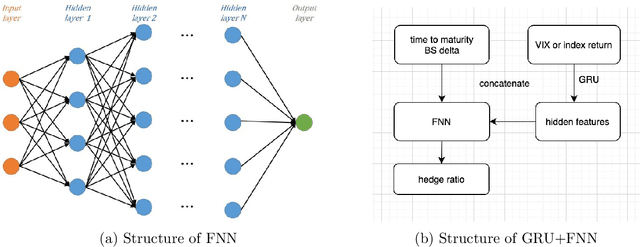

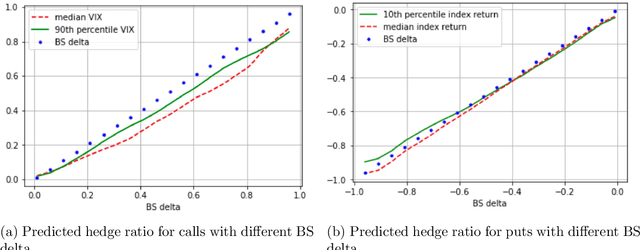
We develop deep learning models to learn the hedge ratio for S&P500 index options directly from options data. We compare different combinations of features and show that a feedforward neural network model with time to maturity, Black-Scholes delta and a sentiment variable (VIX for calls and index return for puts) as input features performs the best in the out-of-sample test. This model significantly outperforms the standard hedging practice that uses the Black-Scholes delta and a recent data-driven model. Our results demonstrate the importance of market sentiment for hedging efficiency, a factor previously ignored in developing hedging strategies.
DynaMiTe: A Dynamic Local Motion Model with Temporal Constraints for Robust Real-Time Feature Matching
Jul 31, 2020

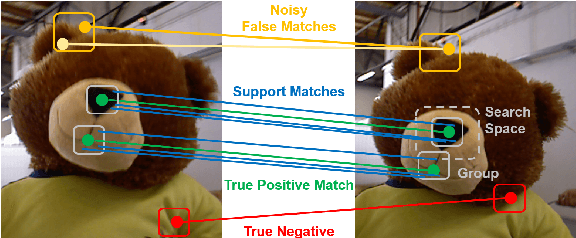
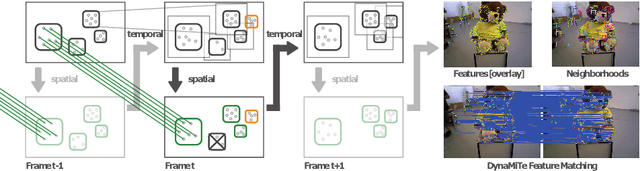
Feature based visual odometry and SLAM methods require accurate and fast correspondence matching between consecutive image frames for precise camera pose estimation in real-time. Current feature matching pipelines either rely solely on the descriptive capabilities of the feature extractor or need computationally complex optimization schemes. We present the lightweight pipeline DynaMiTe, which is agnostic to the descriptor input and leverages spatial-temporal cues with efficient statistical measures. The theoretical backbone of the method lies within a probabilistic formulation of feature matching and the respective study of physically motivated constraints. A dynamically adaptable local motion model encapsulates groups of features in an efficient data structure. Temporal constraints transfer information of the local motion model across time, thus additionally reducing the search space complexity for matching. DynaMiTe achieves superior results both in terms of matching accuracy and camera pose estimation with high frame rates, outperforming state-of-the-art matching methods while being computationally more efficient.
Lifelong Pretraining: Continually Adapting Language Models to Emerging Corpora
Oct 16, 2021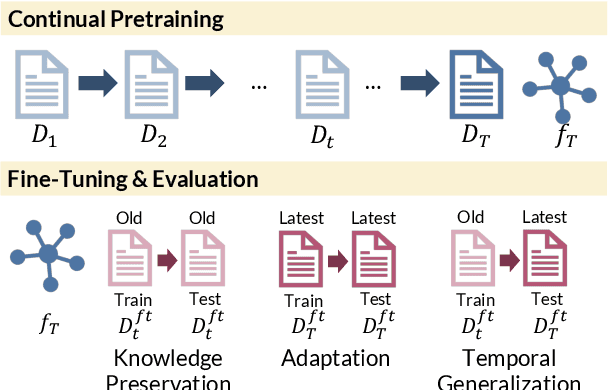
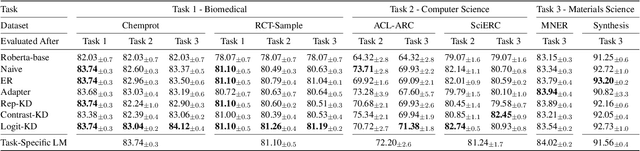
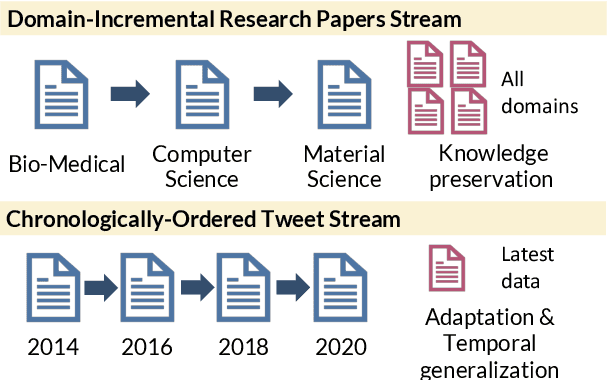
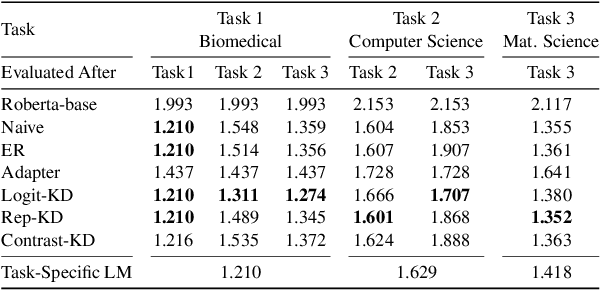
Pretrained language models (PTLMs) are typically learned over a large, static corpus and further fine-tuned for various downstream tasks. However, when deployed in the real world, a PTLM-based model must deal with data from a new domain that deviates from what the PTLM was initially trained on, or newly emerged data that contains out-of-distribution information. In this paper, we study a lifelong language model pretraining challenge where a PTLM is continually updated so as to adapt to emerging data. Over a domain-incremental research paper stream and a chronologically ordered tweet stream, we incrementally pretrain a PTLM with different continual learning algorithms, and keep track of the downstream task performance (after fine-tuning) to analyze its ability of acquiring new knowledge and preserving learned knowledge. Our experiments show continual learning algorithms improve knowledge preservation, with logit distillation being the most effective approach. We further show that continual pretraining improves generalization when training and testing data of downstream tasks are drawn from different time steps, but do not improve when they are from the same time steps. We believe our problem formulation, methods, and analysis will inspire future studies towards continual pretraining of language models.
Anchoring to Exemplars for Training Mixture-of-Expert Cell Embeddings
Dec 06, 2021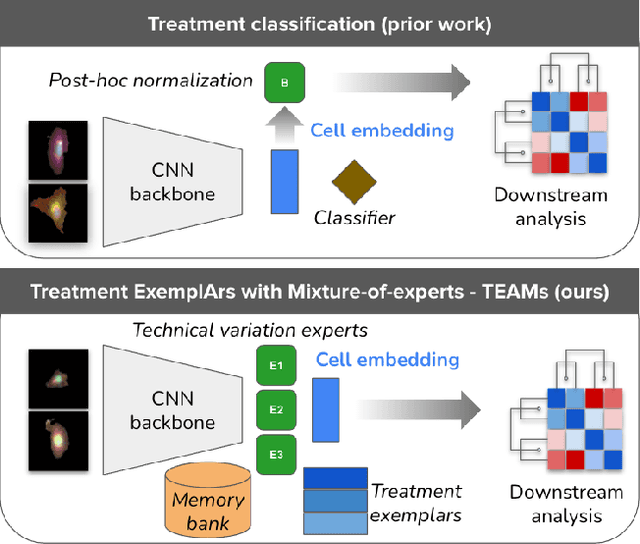
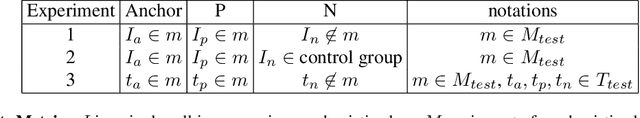
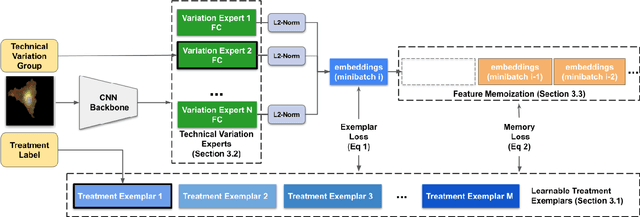
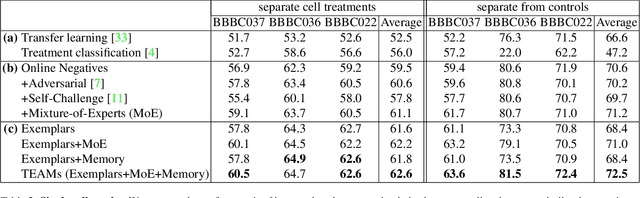
Analyzing the morphology of cells in microscopy images can provide insights into the mechanism of compounds or the function of genes. Addressing this task requires methods that can not only extract biological information from the images, but also ignore technical variations, ie, changes in experimental procedure or differences between equipments used to collect microscopy images. We propose Treatment ExemplArs with Mixture-of-experts (TEAMs), an embedding learning approach that learns a set of experts that are specialized in capturing technical variations in our training set and then aggregates specialist's predictions at test time. Thus, TEAMs can learn powerful embeddings with less technical variation bias by minimizing the noise from every expert. To train our model, we leverage Treatment Exemplars that enable our approach to capture the distribution of the entire dataset in every minibatch while still fitting into GPU memory. We evaluate our approach on three datasets for tasks like drug discovery, boosting performance on identifying the true mechanism of action of cell treatments by 5.5-11% over the state-of-the-art.
Machine Learning for Online Algorithm Selection under Censored Feedback
Sep 13, 2021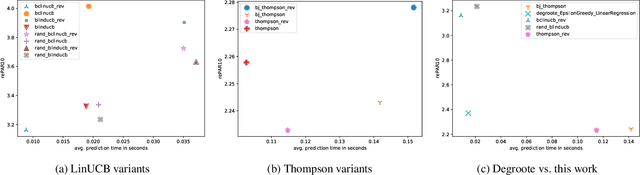
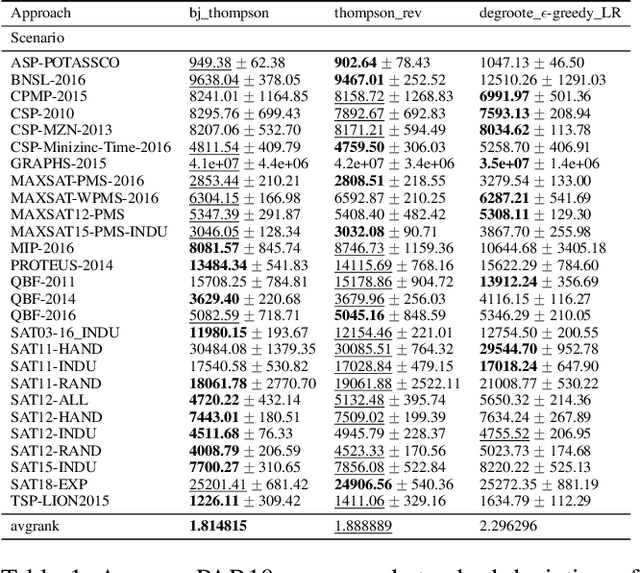
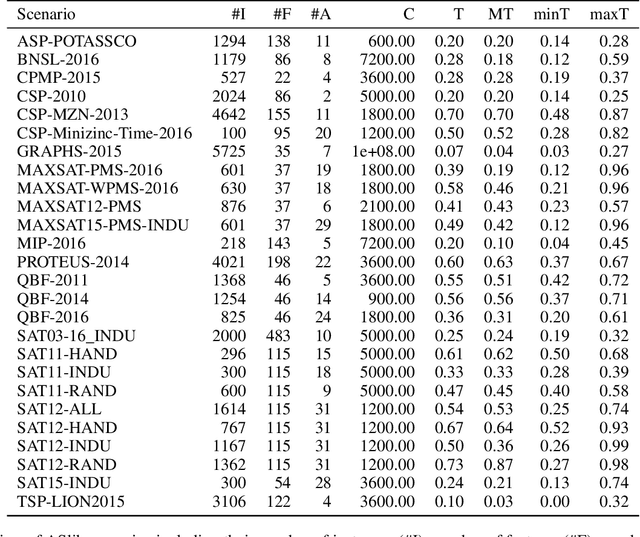
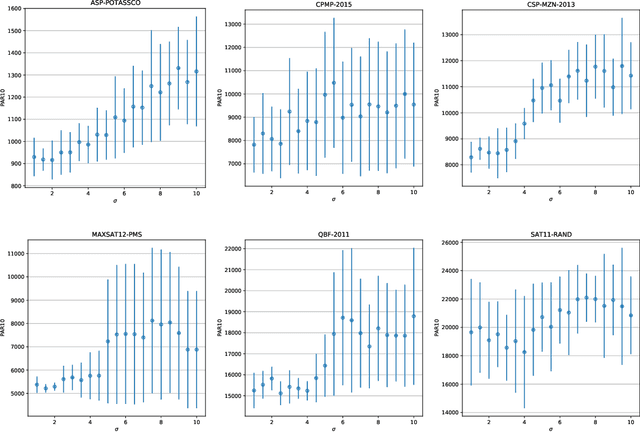
In online algorithm selection (OAS), instances of an algorithmic problem class are presented to an agent one after another, and the agent has to quickly select a presumably best algorithm from a fixed set of candidate algorithms. For decision problems such as satisfiability (SAT), quality typically refers to the algorithm's runtime. As the latter is known to exhibit a heavy-tail distribution, an algorithm is normally stopped when exceeding a predefined upper time limit. As a consequence, machine learning methods used to optimize an algorithm selection strategy in a data-driven manner need to deal with right-censored samples, a problem that has received little attention in the literature so far. In this work, we revisit multi-armed bandit algorithms for OAS and discuss their capability of dealing with the problem. Moreover, we adapt them towards runtime-oriented losses, allowing for partially censored data while keeping a space- and time-complexity independent of the time horizon. In an extensive experimental evaluation on an adapted version of the ASlib benchmark, we demonstrate that theoretically well-founded methods based on Thompson sampling perform specifically strong and improve in comparison to existing methods.
Communication-Efficient TeraByte-Scale Model Training Framework for Online Advertising
Jan 05, 2022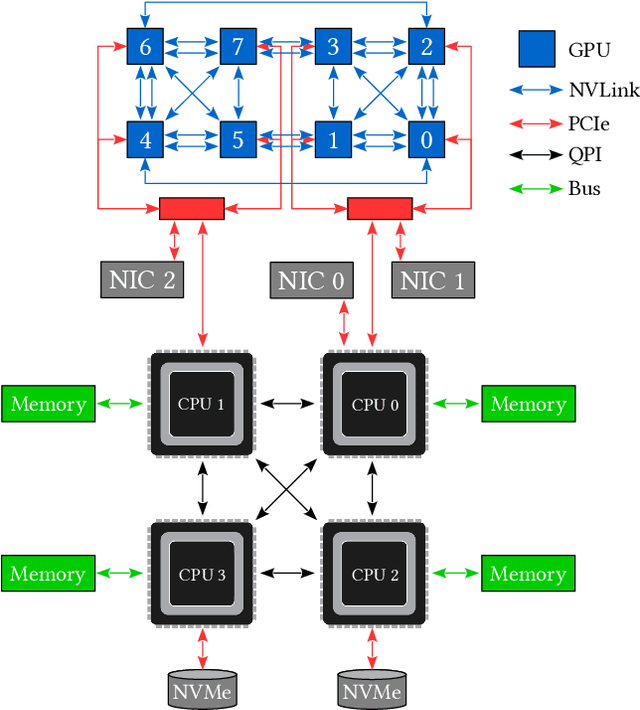
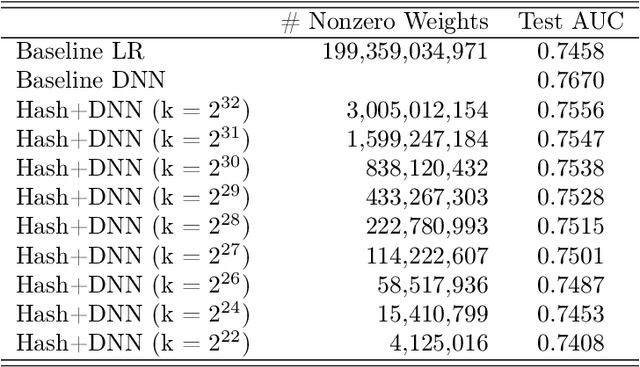
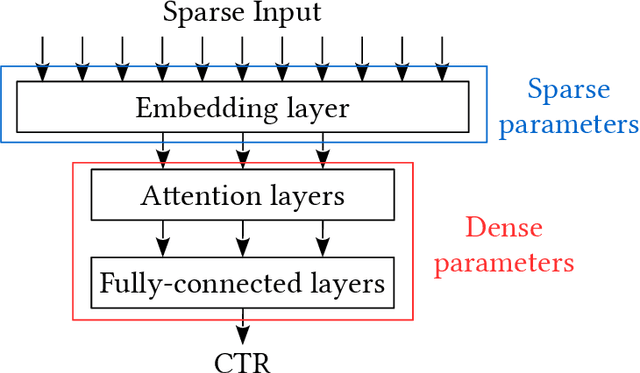
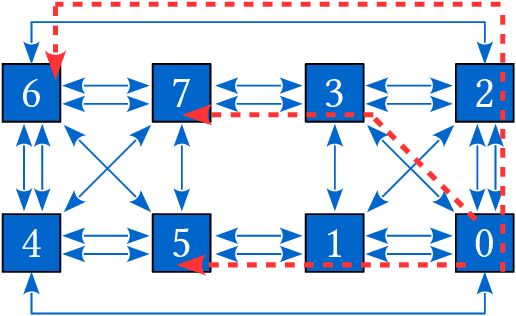
Click-Through Rate (CTR) prediction is a crucial component in the online advertising industry. In order to produce a personalized CTR prediction, an industry-level CTR prediction model commonly takes a high-dimensional (e.g., 100 or 1000 billions of features) sparse vector (that is encoded from query keywords, user portraits, etc.) as input. As a result, the model requires Terabyte scale parameters to embed the high-dimensional input. Hierarchical distributed GPU parameter server has been proposed to enable GPU with limited memory to train the massive network by leveraging CPU main memory and SSDs as secondary storage. We identify two major challenges in the existing GPU training framework for massive-scale ad models and propose a collection of optimizations to tackle these challenges: (a) the GPU, CPU, SSD rapidly communicate with each other during the training. The connections between GPUs and CPUs are non-uniform due to the hardware topology. The data communication route should be optimized according to the hardware topology; (b) GPUs in different computing nodes frequently communicates to synchronize parameters. We are required to optimize the communications so that the distributed system can become scalable. In this paper, we propose a hardware-aware training workflow that couples the hardware topology into the algorithm design. To reduce the extensive communication between computing nodes, we introduce a $k$-step model merging algorithm for the popular Adam optimizer and provide its convergence rate in non-convex optimization. To the best of our knowledge, this is the first application of $k$-step adaptive optimization method in industrial-level CTR model training. The numerical results on real-world data confirm that the optimized system design considerably reduces the training time of the massive model, with essentially no loss in accuracy.