 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Consistency Regularization Can Improve Robustness to Label Noise
Oct 04, 2021
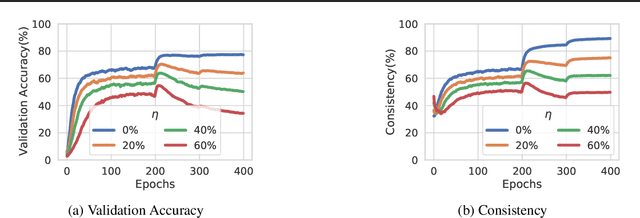
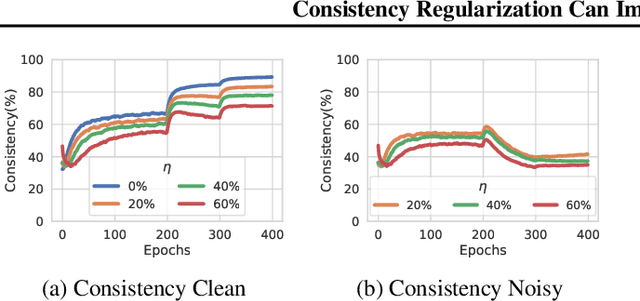
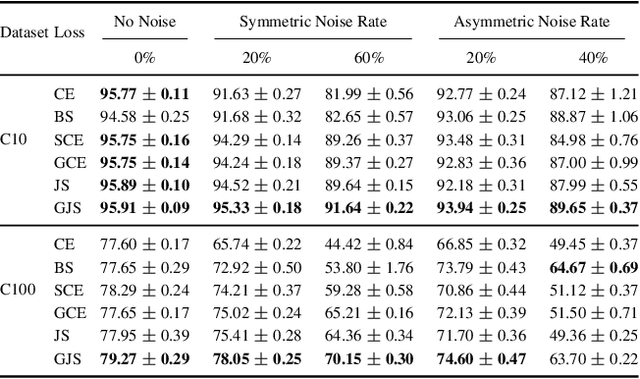
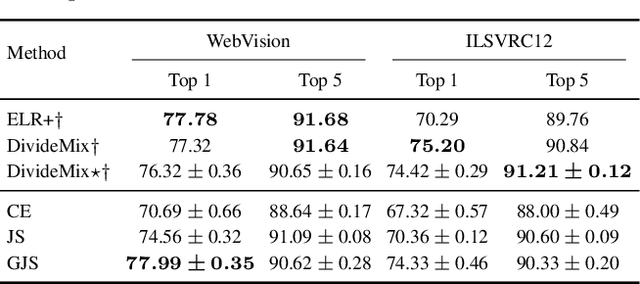
Consistency regularization is a commonly-used technique for semi-supervised and self-supervised learning. It is an auxiliary objective function that encourages the prediction of the network to be similar in the vicinity of the observed training samples. Hendrycks et al. (2020) have recently shown such regularization naturally brings test-time robustness to corrupted data and helps with calibration. This paper empirically studies the relevance of consistency regularization for training-time robustness to noisy labels. First, we make two interesting and useful observations regarding the consistency of networks trained with the standard cross entropy loss on noisy datasets which are: (i) networks trained on noisy data have lower consistency than those trained on clean data, and(ii) the consistency reduces more significantly around noisy-labelled training data points than correctly-labelled ones. Then, we show that a simple loss function that encourages consistency improves the robustness of the models to label noise on both synthetic (CIFAR-10, CIFAR-100) and real-world (WebVision) noise as well as different noise rates and types and achieves state-of-the-art results.
NÜWA: Visual Synthesis Pre-training for Neural visUal World creAtion
Nov 24, 2021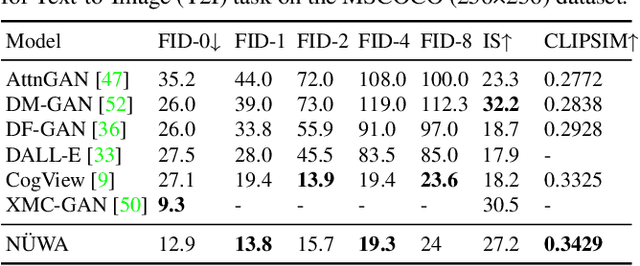
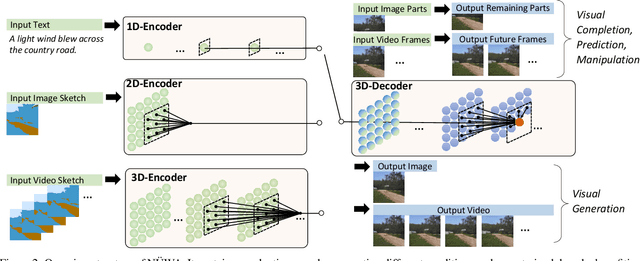
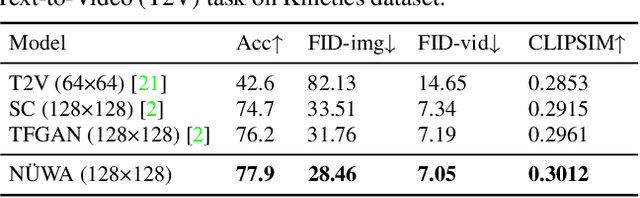

This paper presents a unified multimodal pre-trained model called N\"UWA that can generate new or manipulate existing visual data (i.e., images and videos) for various visual synthesis tasks. To cover language, image, and video at the same time for different scenarios, a 3D transformer encoder-decoder framework is designed, which can not only deal with videos as 3D data but also adapt to texts and images as 1D and 2D data, respectively. A 3D Nearby Attention (3DNA) mechanism is also proposed to consider the nature of the visual data and reduce the computational complexity. We evaluate N\"UWA on 8 downstream tasks. Compared to several strong baselines, N\"UWA achieves state-of-the-art results on text-to-image generation, text-to-video generation, video prediction, etc. Furthermore, it also shows surprisingly good zero-shot capabilities on text-guided image and video manipulation tasks. Project repo is https://github.com/microsoft/NUWA.
Receptive Field Broadening and Boosting for Salient Object Detection
Oct 15, 2021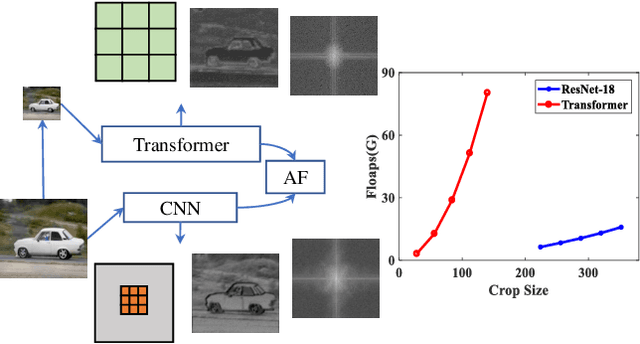
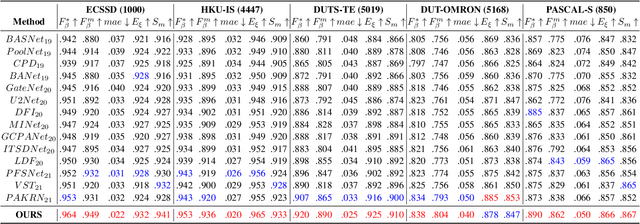
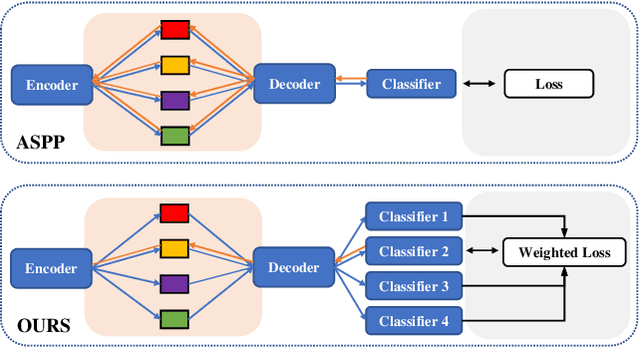
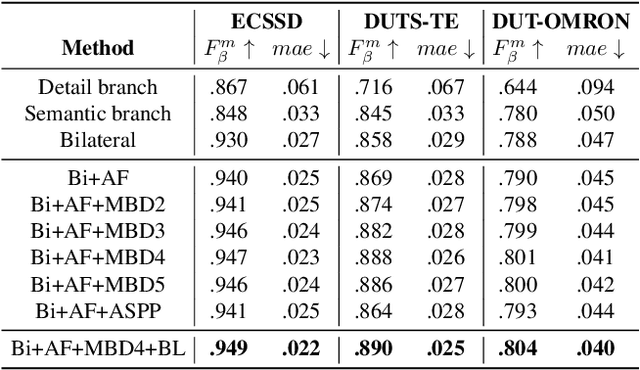
Salient object detection requires a comprehensive and scalable receptive field to locate the visually significant objects in the image. Recently, the emergence of visual transformers and multi-branch modules has significantly enhanced the ability of neural networks to perceive objects at different scales. However, compared to the traditional backbone, the calculation process of transformers is time-consuming. Moreover, different branches of the multi-branch modules could cause the same error back propagation in each training iteration, which is not conducive to extracting discriminative features. To solve these problems, we propose a bilateral network based on transformer and CNN to efficiently broaden local details and global semantic information simultaneously. Besides, a Multi-Head Boosting (MHB) strategy is proposed to enhance the specificity of different network branches. By calculating the errors of different prediction heads, each branch can separately pay more attention to the pixels that other branches predict incorrectly. Moreover, Unlike multi-path parallel training, MHB randomly selects one branch each time for gradient back propagation in a boosting way. Additionally, an Attention Feature Fusion Module (AF) is proposed to fuse two types of features according to respective characteristics. Comprehensive experiments on five benchmark datasets demonstrate that the proposed method can achieve a significant performance improvement compared with the state-of-the-art methods.
LatentHuman: Shape-and-Pose Disentangled Latent Representation for Human Bodies
Nov 30, 2021
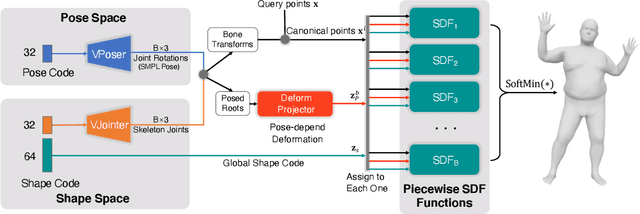
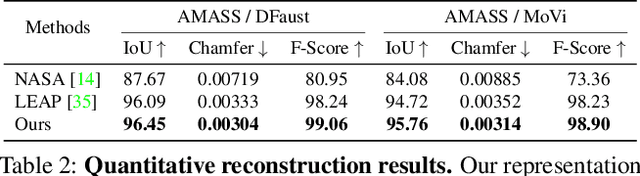

3D representation and reconstruction of human bodies have been studied for a long time in computer vision. Traditional methods rely mostly on parametric statistical linear models, limiting the space of possible bodies to linear combinations. It is only recently that some approaches try to leverage neural implicit representations for human body modeling, and while demonstrating impressive results, they are either limited by representation capability or not physically meaningful and controllable. In this work, we propose a novel neural implicit representation for the human body, which is fully differentiable and optimizable with disentangled shape and pose latent spaces. Contrary to prior work, our representation is designed based on the kinematic model, which makes the representation controllable for tasks like pose animation, while simultaneously allowing the optimization of shape and pose for tasks like 3D fitting and pose tracking. Our model can be trained and fine-tuned directly on non-watertight raw data with well-designed losses. Experiments demonstrate the improved 3D reconstruction performance over SoTA approaches and show the applicability of our method to shape interpolation, model fitting, pose tracking, and motion retargeting.
AffRankNet+: Ranking Affect Using Privileged Information
Aug 12, 2021

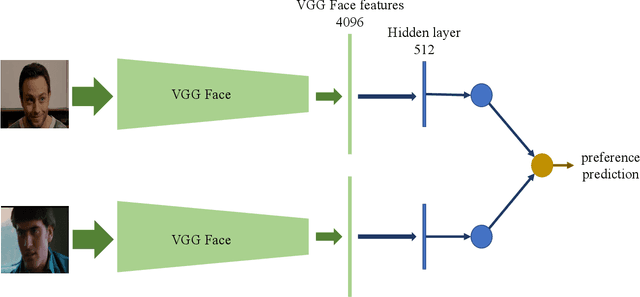
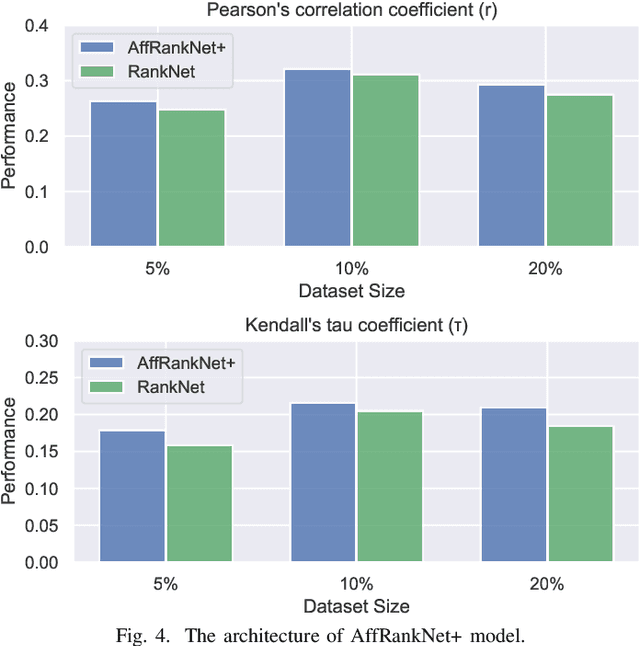
Many of the affect modelling tasks present an asymmetric distribution of information between training and test time; additional information is given about the training data, which is not available at test time. Learning under this setting is called Learning Under Privileged Information (LUPI). At the same time, due to the ordinal nature of affect annotations, formulating affect modelling tasks as supervised learning ranking problems is gaining ground within the Affective Computing research community. Motivated by the two facts above, in this study, we introduce a ranking model that treats additional information about the training data as privileged information to accurately rank affect states. Our ranking model extends the well-known RankNet model to the LUPI paradigm, hence its name AffRankNet+. To the best of our knowledge, it is the first time that a ranking model based on neural networks exploits privileged information. We evaluate the performance of the proposed model on the public available Afew-VA dataset and compare it against the RankNet model, which does not use privileged information. Experimental evaluation indicates that the AffRankNet+ model can yield significantly better performance.
A Reinforcement Learning-based Adaptive Control Model for Future Street Planning, An Algorithm and A Case Study
Dec 10, 2021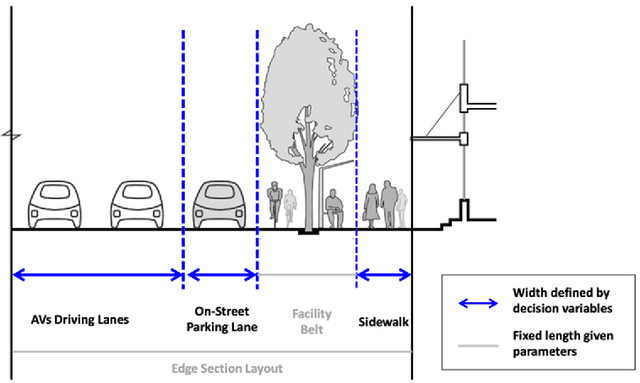
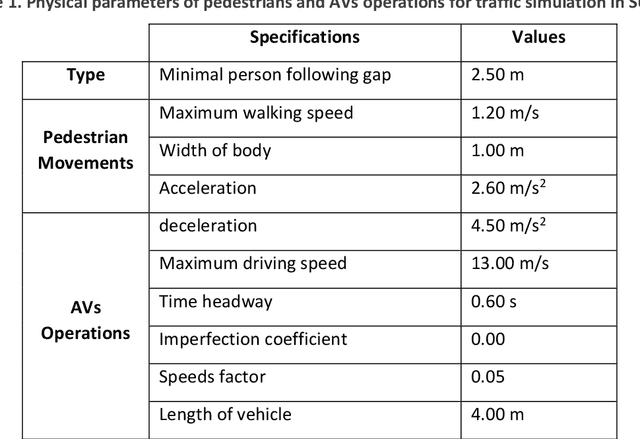
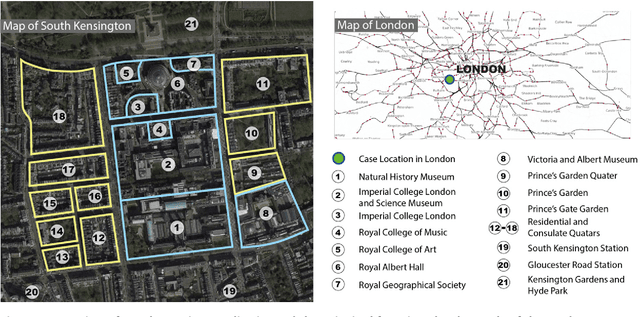
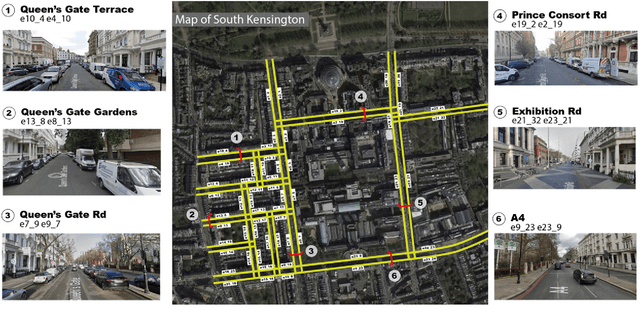
With the emerging technologies in Intelligent Transportation System (ITS), the adaptive operation of road space is likely to be realised within decades. An intelligent street can learn and improve its decision-making on the right-of-way (ROW) for road users, liberating more active pedestrian space while maintaining traffic safety and efficiency. However, there is a lack of effective controlling techniques for these adaptive street infrastructures. To fill this gap in existing studies, we formulate this control problem as a Markov Game and develop a solution based on the multi-agent Deep Deterministic Policy Gradient (MADDPG) algorithm. The proposed model can dynamically assign ROW for sidewalks, autonomous vehicles (AVs) driving lanes and on-street parking areas in real-time. Integrated with the SUMO traffic simulator, this model was evaluated using the road network of the South Kensington District against three cases of divergent traffic conditions: pedestrian flow rates, AVs traffic flow rates and parking demands. Results reveal that our model can achieve an average reduction of 3.87% and 6.26% in street space assigned for on-street parking and vehicular operations. Combined with space gained by limiting the number of driving lanes, the average proportion of sidewalks to total widths of streets can significantly increase by 10.13%.
Interpolation-Prediction Networks for Irregularly Sampled Time Series
Sep 13, 2019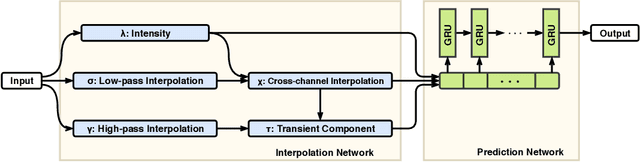
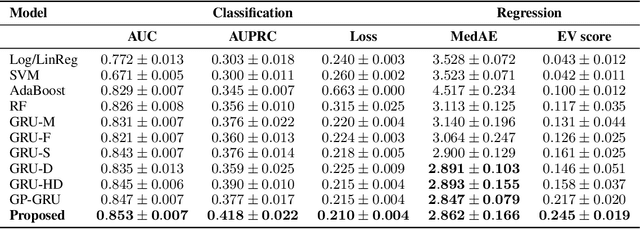
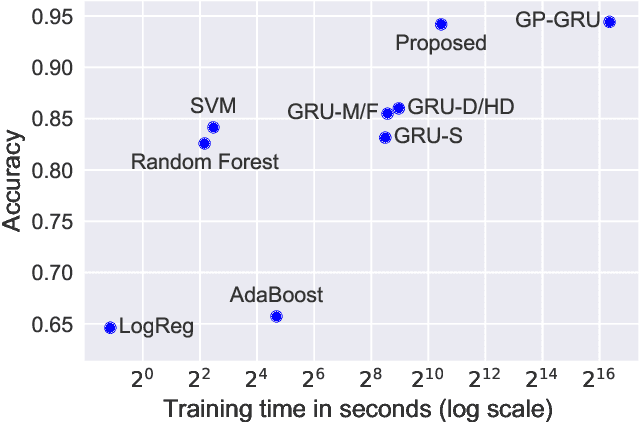

In this paper, we present a new deep learning architecture for addressing the problem of supervised learning with sparse and irregularly sampled multivariate time series. The architecture is based on the use of a semi-parametric interpolation network followed by the application of a prediction network. The interpolation network allows for information to be shared across multiple dimensions of a multivariate time series during the interpolation stage, while any standard deep learning model can be used for the prediction network. This work is motivated by the analysis of physiological time series data in electronic health records, which are sparse, irregularly sampled, and multivariate. We investigate the performance of this architecture on both classification and regression tasks, showing that our approach outperforms a range of baseline and recently proposed models.
Warp-Refine Propagation: Semi-Supervised Auto-labeling via Cycle-consistency
Sep 28, 2021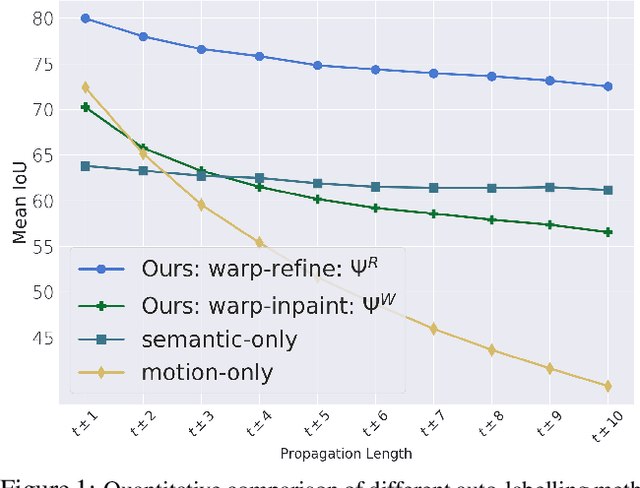
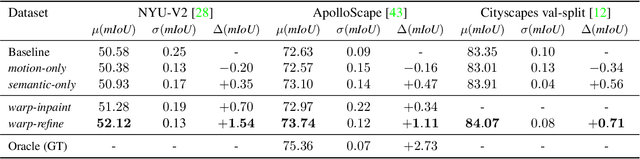
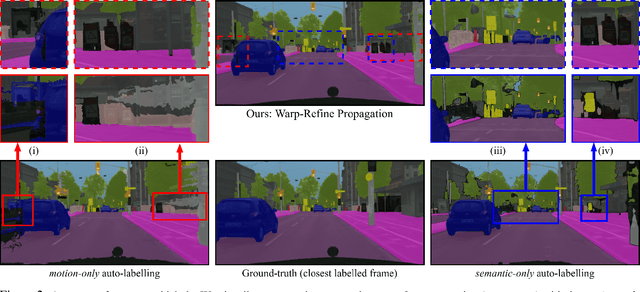

Deep learning models for semantic segmentation rely on expensive, large-scale, manually annotated datasets. Labelling is a tedious process that can take hours per image. Automatically annotating video sequences by propagating sparsely labeled frames through time is a more scalable alternative. In this work, we propose a novel label propagation method, termed Warp-Refine Propagation, that combines semantic cues with geometric cues to efficiently auto-label videos. Our method learns to refine geometrically-warped labels and infuse them with learned semantic priors in a semi-supervised setting by leveraging cycle consistency across time. We quantitatively show that our method improves label-propagation by a noteworthy margin of 13.1 mIoU on the ApolloScape dataset. Furthermore, by training with the auto-labelled frames, we achieve competitive results on three semantic-segmentation benchmarks, improving the state-of-the-art by a large margin of 1.8 and 3.61 mIoU on NYU-V2 and KITTI, while matching the current best results on Cityscapes.
Assessing Human Interaction in Virtual Reality With Continually Learning Prediction Agents Based on Reinforcement Learning Algorithms: A Pilot Study
Dec 14, 2021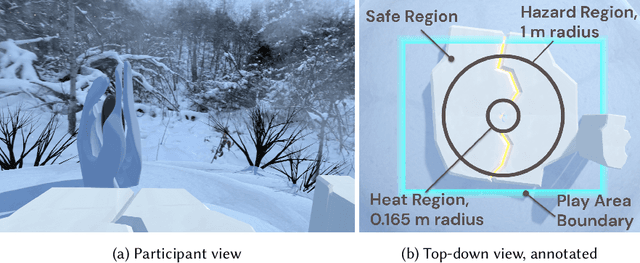
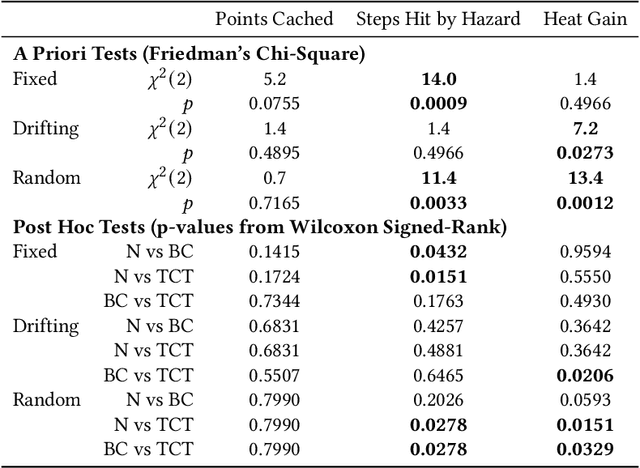
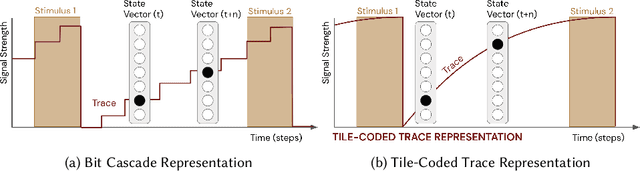
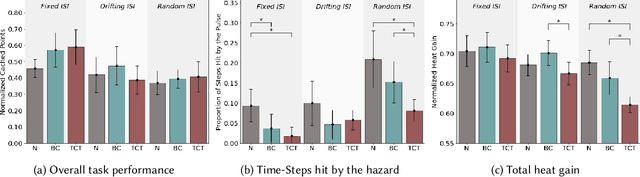
Artificial intelligence systems increasingly involve continual learning to enable flexibility in general situations that are not encountered during system training. Human interaction with autonomous systems is broadly studied, but research has hitherto under-explored interactions that occur while the system is actively learning, and can noticeably change its behaviour in minutes. In this pilot study, we investigate how the interaction between a human and a continually learning prediction agent develops as the agent develops competency. Additionally, we compare two different agent architectures to assess how representational choices in agent design affect the human-agent interaction. We develop a virtual reality environment and a time-based prediction task wherein learned predictions from a reinforcement learning (RL) algorithm augment human predictions. We assess how a participant's performance and behaviour in this task differs across agent types, using both quantitative and qualitative analyses. Our findings suggest that human trust of the system may be influenced by early interactions with the agent, and that trust in turn affects strategic behaviour, but limitations of the pilot study rule out any conclusive statement. We identify trust as a key feature of interaction to focus on when considering RL-based technologies, and make several recommendations for modification to this study in preparation for a larger-scale investigation. A video summary of this paper can be found at https://youtu.be/oVYJdnBqTwQ .
A Histopathology Study Comparing Contrastive Semi-Supervised and Fully Supervised Learning
Nov 10, 2021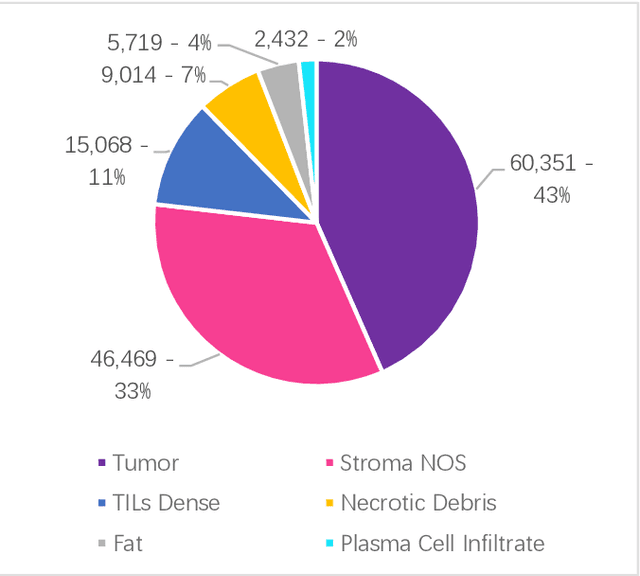
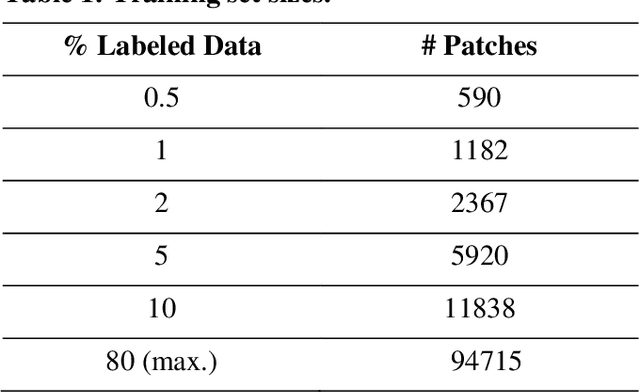
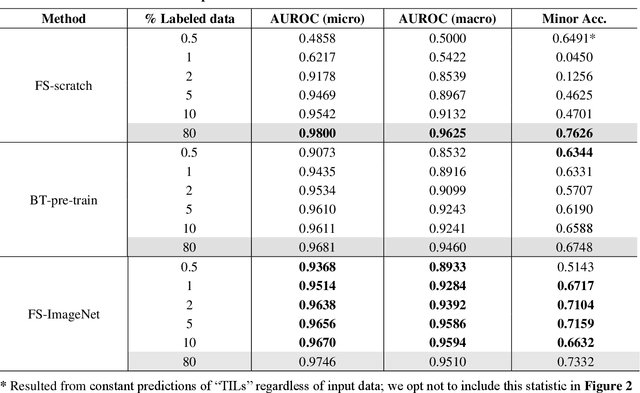
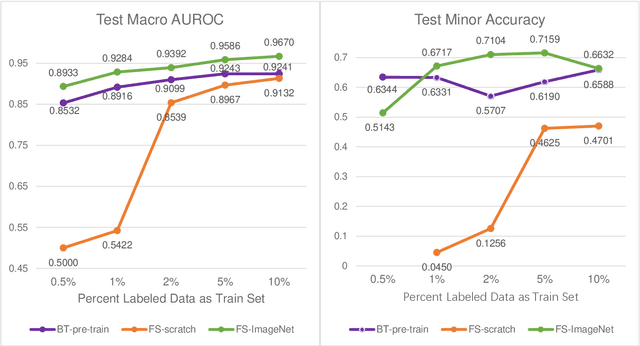
Data labeling is often the most challenging task when developing computational pathology models. Pathologist participation is necessary to generate accurate labels, and the limitations on pathologist time and demand for large, labeled datasets has led to research in areas including weakly supervised learning using patient-level labels, machine assisted annotation and active learning. In this paper we explore self-supervised learning to reduce labeling burdens in computational pathology. We explore this in the context of classification of breast cancer tissue using the Barlow Twins approach, and we compare self-supervision with alternatives like pre-trained networks in low-data scenarios. For the task explored in this paper, we find that ImageNet pre-trained networks largely outperform the self-supervised representations obtained using Barlow Twins.