 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-Task Meta-Learning Modification with Stochastic Approximation
Oct 25, 2021




Meta-learning methods aim to build learning algorithms capable of quickly adapting to new tasks in low-data regime. One of the main benchmarks of such an algorithms is a few-shot learning problem. In this paper we investigate the modification of standard meta-learning pipeline that takes a multi-task approach during training. The proposed method simultaneously utilizes information from several meta-training tasks in a common loss function. The impact of each of these tasks in the loss function is controlled by the corresponding weight. Proper optimization of these weights can have a big influence on training of the entire model and might improve the quality on test time tasks. In this work we propose and investigate the use of methods from the family of simultaneous perturbation stochastic approximation (SPSA) approaches for meta-train tasks weights optimization. We have also compared the proposed algorithms with gradient-based methods and found that stochastic approximation demonstrates the largest quality boost in test time. Proposed multi-task modification can be applied to almost all methods that use meta-learning pipeline. In this paper we study applications of this modification on Prototypical Networks and Model-Agnostic Meta-Learning algorithms on CIFAR-FS, FC100, tieredImageNet and miniImageNet few-shot learning benchmarks. During these experiments, multi-task modification has demonstrated improvement over original methods. The proposed SPSA-Tracking algorithm shows the largest accuracy boost. Our code is available online.
Monaural source separation: From anechoic to reverberant environments
Nov 15, 2021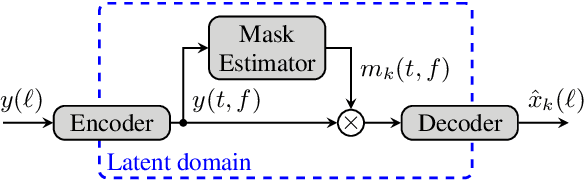
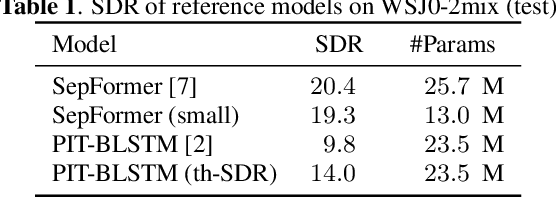
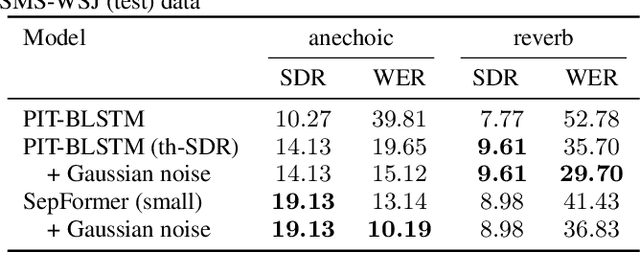
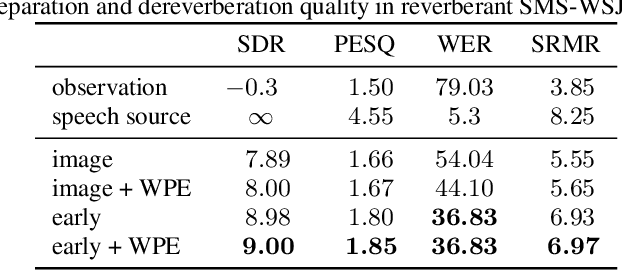
Impressive progress in neural network-based single-channel speech source separation has been made in recent years. But those improvements have been mostly reported on anechoic data, a situation that is hardly met in practice. Taking the SepFormer as a starting point, which achieves state-of-the-art performance on anechoic mixtures, we gradually modify it to optimize its performance on reverberant mixtures. Although this leads to a word error rate improvement by 8 percentage points compared to the standard SepFormer implementation, the system ends up with only marginally better performance than our improved PIT-BLSTM separation system, that is optimized with rather straightforward means. This is surprising and at the same time sobering, challenging the practical usefulness of many improvements reported in recent years for monaural source separation on nonreverberant data.
Graph recovery from graph wave equation
Nov 25, 2021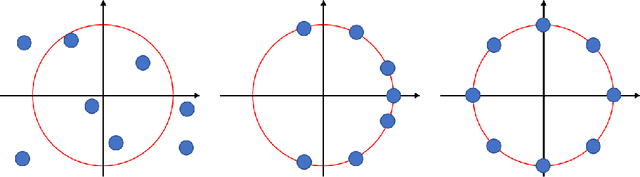
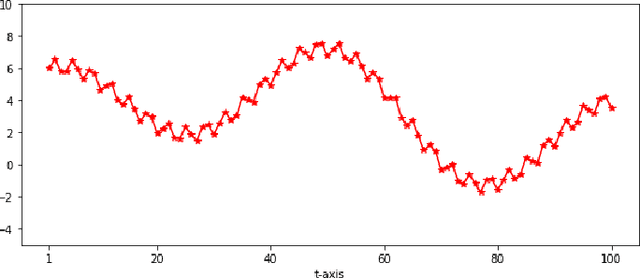
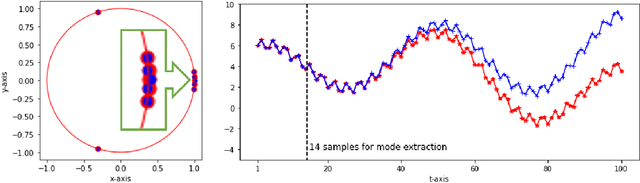
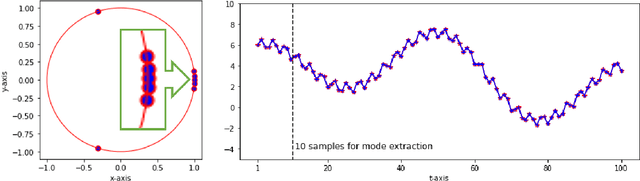
We propose a method by which to recover an underlying graph from a set of multivariate wave signals that is discretely sampled from a solution of the graph wave equation. Herein, the graph wave equation is defined with the graph Laplacian, and its solution is explicitly given as a mode expansion of the Laplacian eigenvalues and eigenfunctions. For graph recovery, our idea is to extract modes corresponding to the square root of the eigenvalues from the discrete wave signals using the DMD method, and then to reconstruct the graph (Laplacian) from the eigenfunctions obtained as amplitudes of the modes. Moreover, in order to estimate modes more precisely, we modify the DMD method under an assumption that only stationary modes exist, because graph wave functions always satisfy this assumption. In conclusion, we demonstrate the proposed method on the wave signals over a path graph. Since our graph recovery procedure can be applied to non-wave signals, we also check its performance on human joint sensor time-series data.
Solving reward-collecting problems with UAVs: a comparison of online optimization and Q-learning
Nov 30, 2021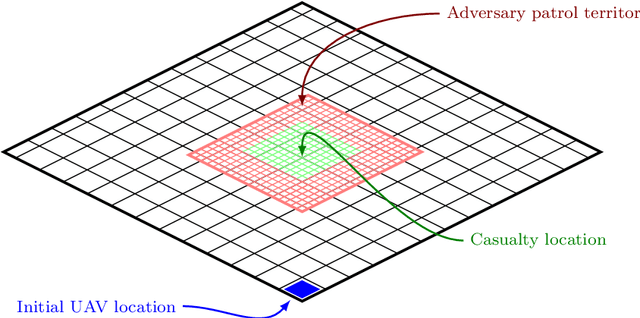
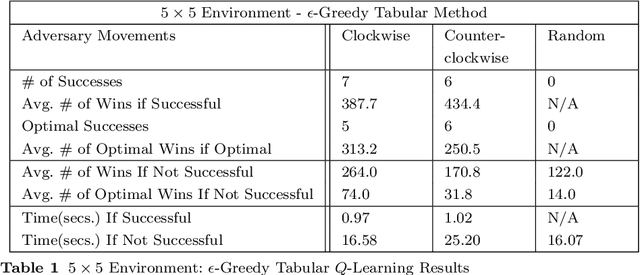
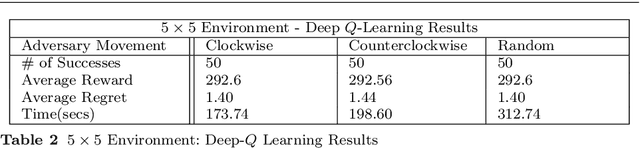
Uncrewed autonomous vehicles (UAVs) have made significant contributions to reconnaissance and surveillance missions in past US military campaigns. As the prevalence of UAVs increases, there has also been improvements in counter-UAV technology that makes it difficult for them to successfully obtain valuable intelligence within an area of interest. Hence, it has become important that modern UAVs can accomplish their missions while maximizing their chances of survival. In this work, we specifically study the problem of identifying a short path from a designated start to a goal, while collecting all rewards and avoiding adversaries that move randomly on the grid. We also provide a possible application of the framework in a military setting, that of autonomous casualty evacuation. We present a comparison of three methods to solve this problem: namely we implement a Deep Q-Learning model, an $\varepsilon$-greedy tabular Q-Learning model, and an online optimization framework. Our computational experiments, designed using simple grid-world environments with random adversaries showcase how these approaches work and compare them in terms of performance, accuracy, and computational time.
Cybonto: Towards Human Cognitive Digital Twins for Cybersecurity
Aug 05, 2021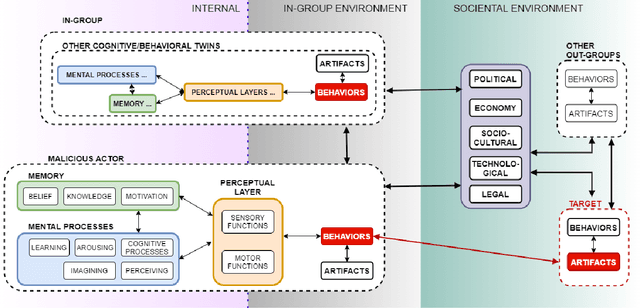
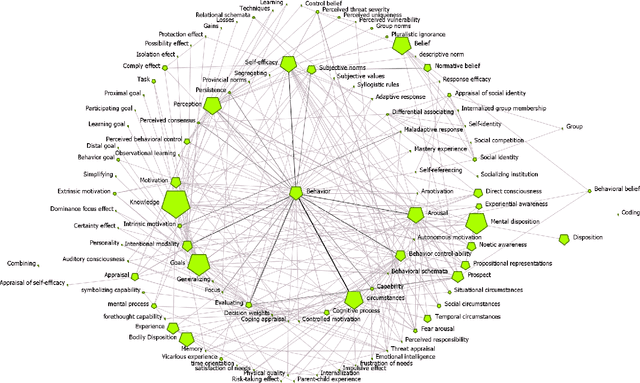
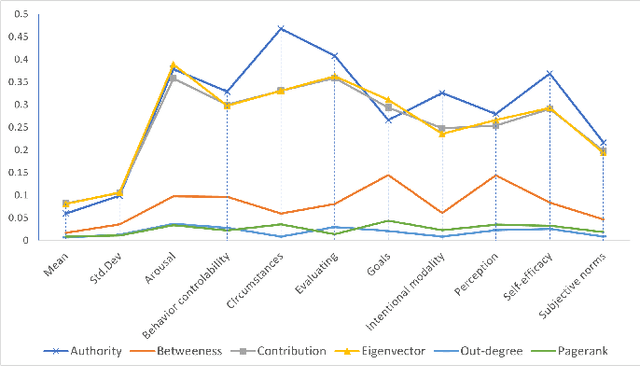
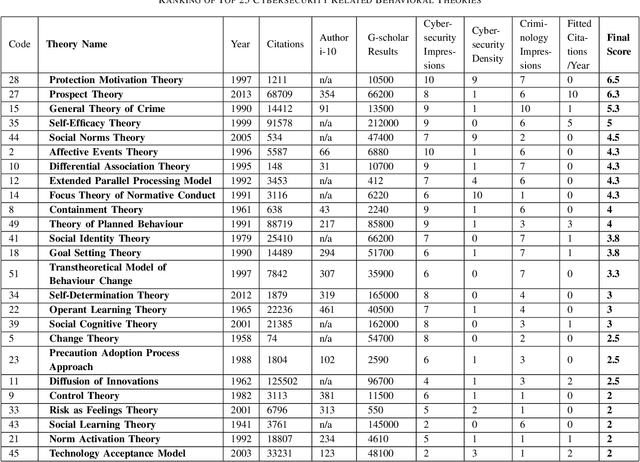
Cyber defense is reactive and slow. On average, the time-to-remedy is hundreds of times larger than the time-to-compromise. In response to the expanding ever-more-complex threat landscape, Digital Twins (DTs) and particularly Human Digital Twins (HDTs) offer the capability of running massive simulations across multiple knowledge domains. Simulated results may offer insights into adversaries' behaviors and tactics, resulting in better proactive cyber-defense strategies. For the first time, this paper solidifies the vision of DTs and HDTs for cybersecurity via the Cybonto conceptual framework proposal. The paper also contributes the Cybonto ontology, formally documenting 108 constructs and thousands of cognitive-related paths based on 20 time-tested psychology theories. Finally, the paper applied 20 network centrality algorithms in analyzing the 108 constructs. The identified top 10 constructs call for extensions of current digital cognitive architectures in preparation for the DT future.
Predicting Poverty Level from Satellite Imagery using Deep Neural Networks
Nov 30, 2021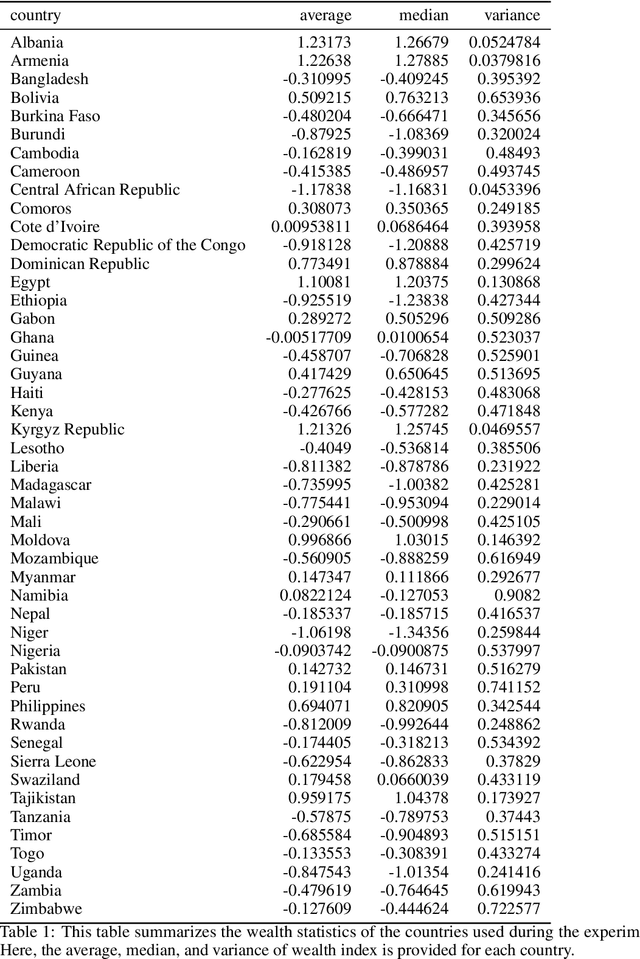
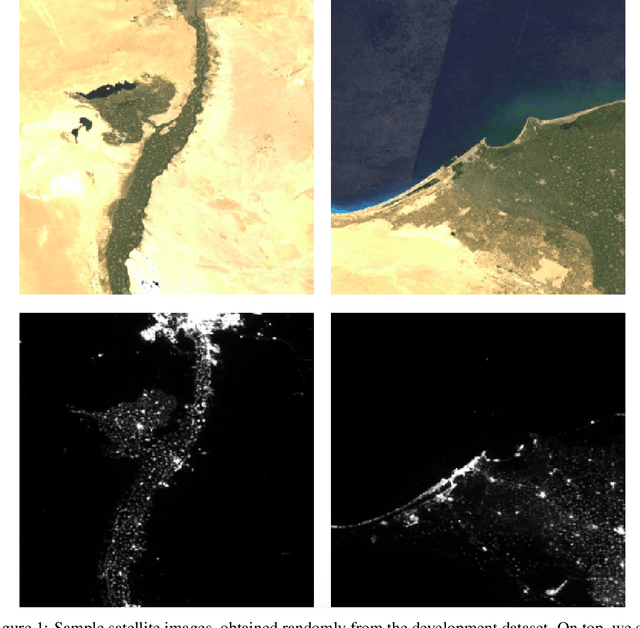
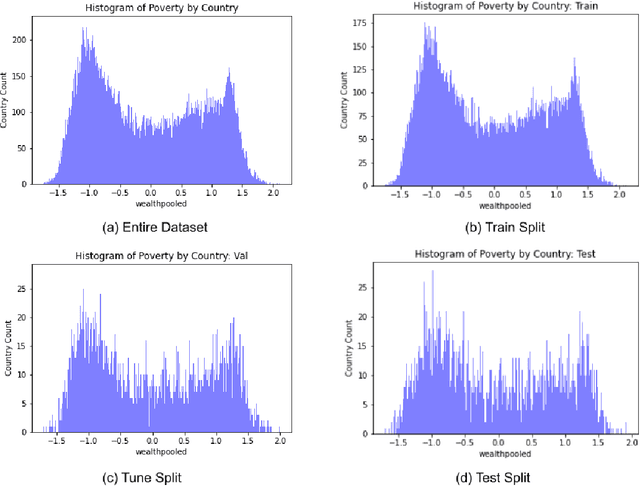
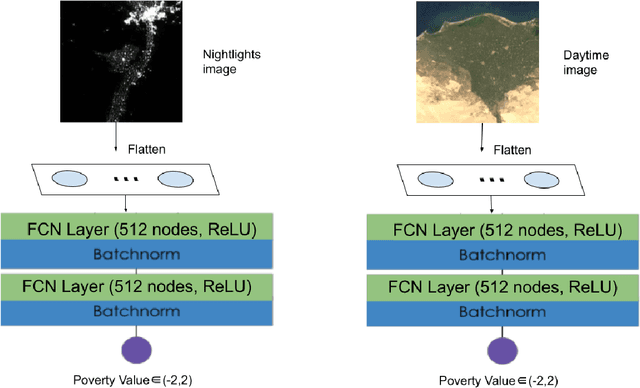
Determining the poverty levels of various regions throughout the world is crucial in identifying interventions for poverty reduction initiatives and directing resources fairly. However, reliable data on global economic livelihoods is hard to come by, especially for areas in the developing world, hampering efforts to both deploy services and monitor/evaluate progress. This is largely due to the fact that this data is obtained from traditional door-to-door surveys, which are time consuming and expensive. Overhead satellite imagery contain characteristics that make it possible to estimate the region's poverty level. In this work, I develop deep learning computer vision methods that can predict a region's poverty level from an overhead satellite image. I experiment with both daytime and nighttime imagery. Furthermore, because data limitations are often the barrier to entry in poverty prediction from satellite imagery, I explore the impact that data quantity and data augmentation have on the representational power and overall accuracy of the networks. Lastly, to evaluate the robustness of the networks, I evaluate them on data from continents that were absent in the development set.
Geometry-Aware Multi-Task Learning for Binaural Audio Generation from Video
Nov 21, 2021
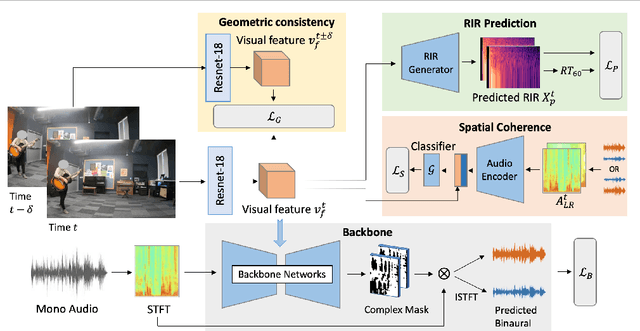

Binaural audio provides human listeners with an immersive spatial sound experience, but most existing videos lack binaural audio recordings. We propose an audio spatialization method that draws on visual information in videos to convert their monaural (single-channel) audio to binaural audio. Whereas existing approaches leverage visual features extracted directly from video frames, our approach explicitly disentangles the geometric cues present in the visual stream to guide the learning process. In particular, we develop a multi-task framework that learns geometry-aware features for binaural audio generation by accounting for the underlying room impulse response, the visual stream's coherence with the sound source(s) positions, and the consistency in geometry of the sounding objects over time. Furthermore, we introduce a new large video dataset with realistic binaural audio simulated for real-world scanned environments. On two datasets, we demonstrate the efficacy of our method, which achieves state-of-the-art results.
Towards a variational Jordan-Lee-Preskill quantum algorithm
Sep 28, 2021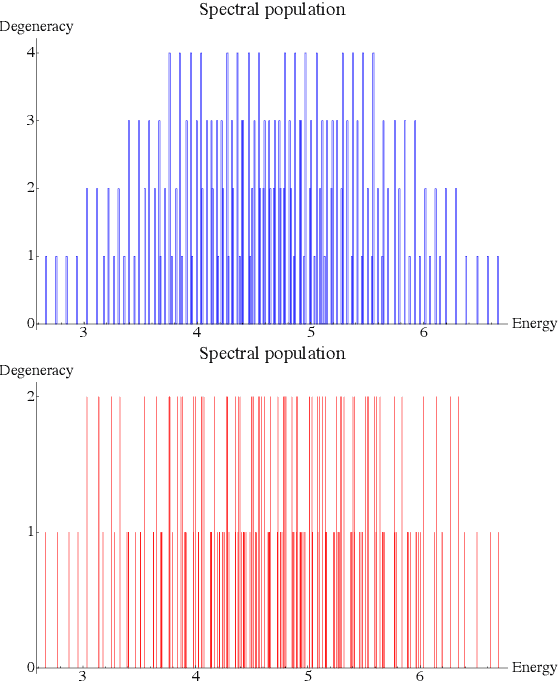
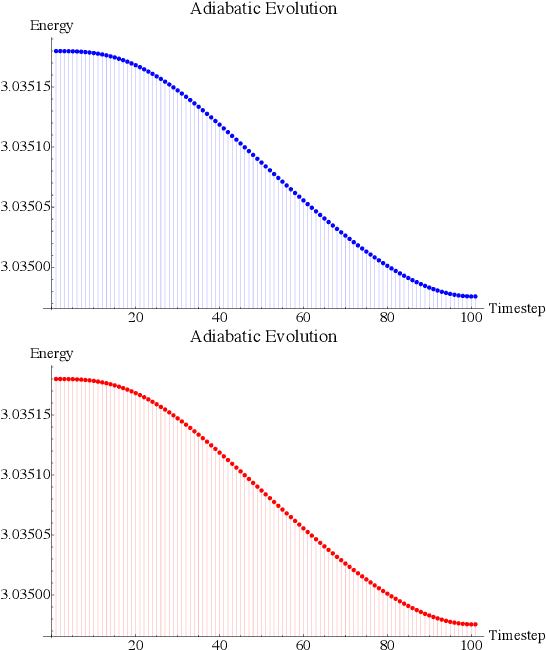
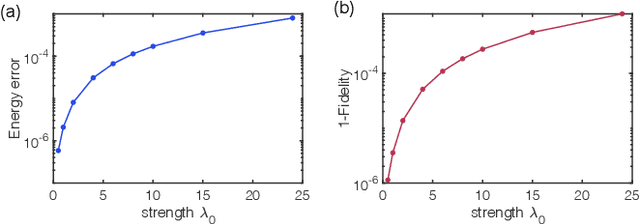
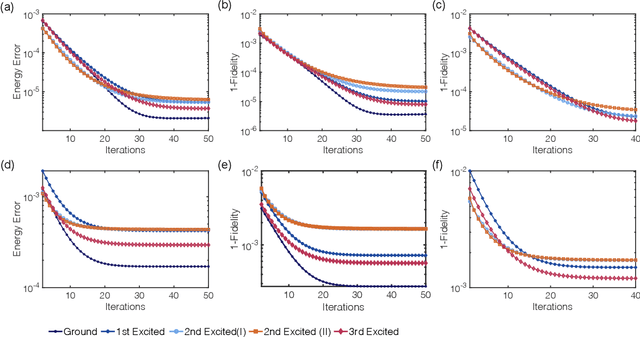
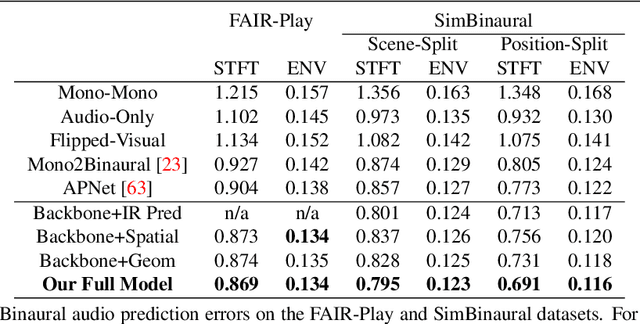
Rapid developments of quantum information technology show promising opportunities for simulating quantum field theory in near-term quantum devices. In this work, we formulate the theory of (time-dependent) variational quantum simulation, explicitly designed for quantum simulation of quantum field theory. We develop hybrid quantum-classical algorithms for crucial ingredients in particle scattering experiments, including encoding, state preparation, and time evolution, with several numerical simulations to demonstrate our algorithms in the 1+1 dimensional $\lambda \phi^4$ quantum field theory. These algorithms could be understood as near-term analogs of the Jordan-Lee-Preskill algorithm, the basic algorithm for simulating quantum field theory using universal quantum devices. Our contribution also includes a bosonic version of the Unitary Coupled Cluster ansatz with physical interpretation in quantum field theory, a discussion about the subspace fidelity, a comparison among different bases in the 1+1 dimensional $\lambda \phi^4$ theory, and the "spectral crowding" in the quantum field theory simulation.
CertainNet: Sampling-free Uncertainty Estimation for Object Detection
Oct 04, 2021
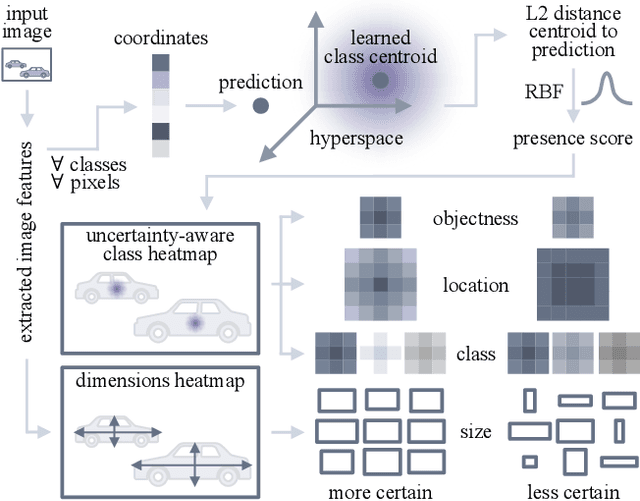
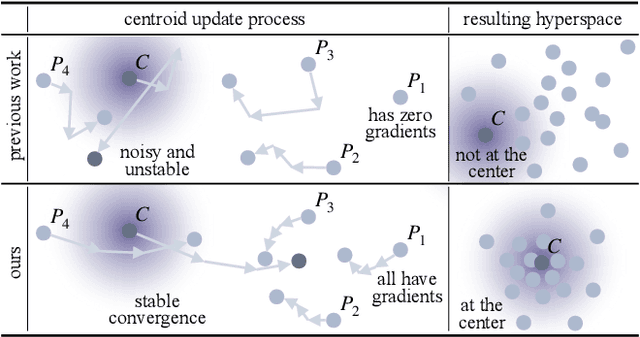
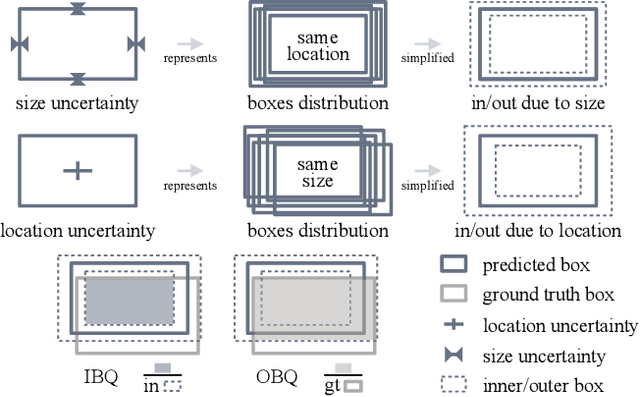
Estimating the uncertainty of a neural network plays a fundamental role in safety-critical settings. In perception for autonomous driving, measuring the uncertainty means providing additional calibrated information to downstream tasks, such as path planning, that can use it towards safe navigation. In this work, we propose a novel sampling-free uncertainty estimation method for object detection. We call it CertainNet, and it is the first to provide separate uncertainties for each output signal: objectness, class, location and size. To achieve this, we propose an uncertainty-aware heatmap, and exploit the neighboring bounding boxes provided by the detector at inference time. We evaluate the detection performance and the quality of the different uncertainty estimates separately, also with challenging out-of-domain samples: BDD100K and nuImages with models trained on KITTI. Additionally, we propose a new metric to evaluate location and size uncertainties. When transferring to unseen datasets, CertainNet generalizes substantially better than previous methods and an ensemble, while being real-time and providing high quality and comprehensive uncertainty estimates.
Spatio-temporal extreme event modeling of terror insurgencies
Oct 29, 2021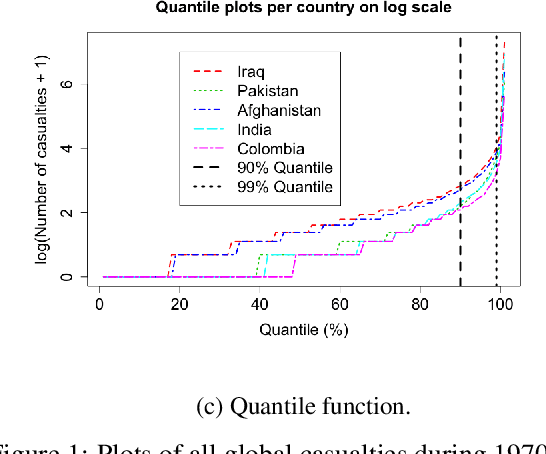
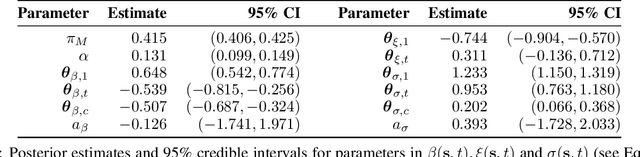
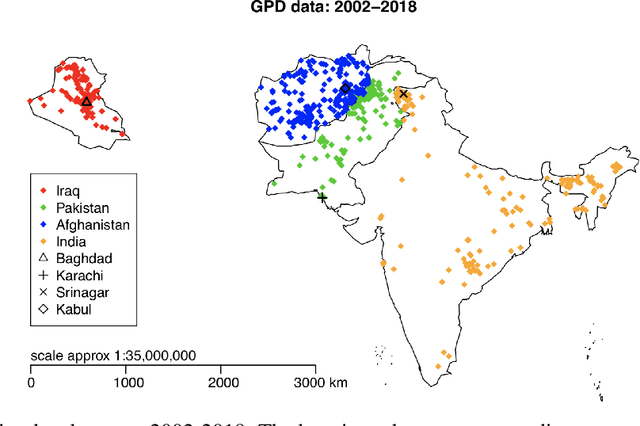
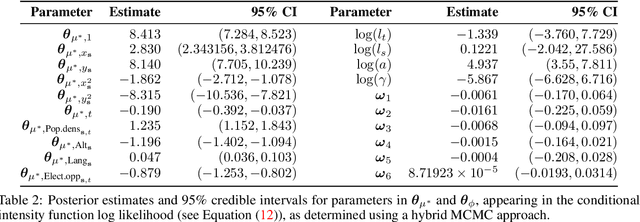
Extreme events with potential deadly outcomes, such as those organized by terror groups, are highly unpredictable in nature and an imminent threat to society. In particular, quantifying the likelihood of a terror attack occurring in an arbitrary space-time region and its relative societal risk, would facilitate informed measures that would strengthen national security. This paper introduces a novel self-exciting marked spatio-temporal model for attacks whose inhomogeneous baseline intensity is written as a function of covariates. Its triggering intensity is succinctly modeled with a Gaussian Process prior distribution to flexibly capture intricate spatio-temporal dependencies between an arbitrary attack and previous terror events. By inferring the parameters of this model, we highlight specific space-time areas in which attacks are likely to occur. Furthermore, by measuring the outcome of an attack in terms of the number of casualties it produces, we introduce a novel mixture distribution for the number of casualties. This distribution flexibly handles low and high number of casualties and the discrete nature of the data through a {\it Generalized ZipF} distribution. We rely on a customized Markov chain Monte Carlo (MCMC) method to estimate the model parameters. We illustrate the methodology with data from the open source Global Terrorism Database (GTD) that correspond to attacks in Afghanistan from 2013-2018. We show that our model is able to predict the intensity of future attacks for 2019-2021 while considering various covariates of interest such as population density, number of regional languages spoken, and the density of population supporting the opposing government.