 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Single Image Super-Resolution Using Dual Path Connections with Multiple Scale Learning
Dec 31, 2021

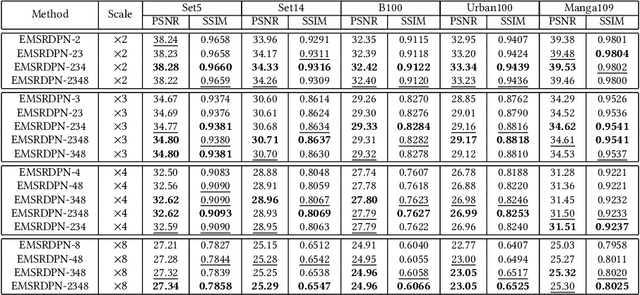
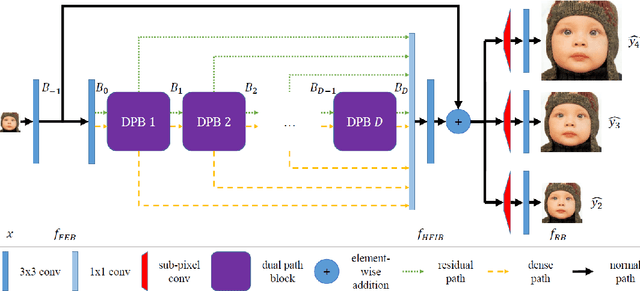
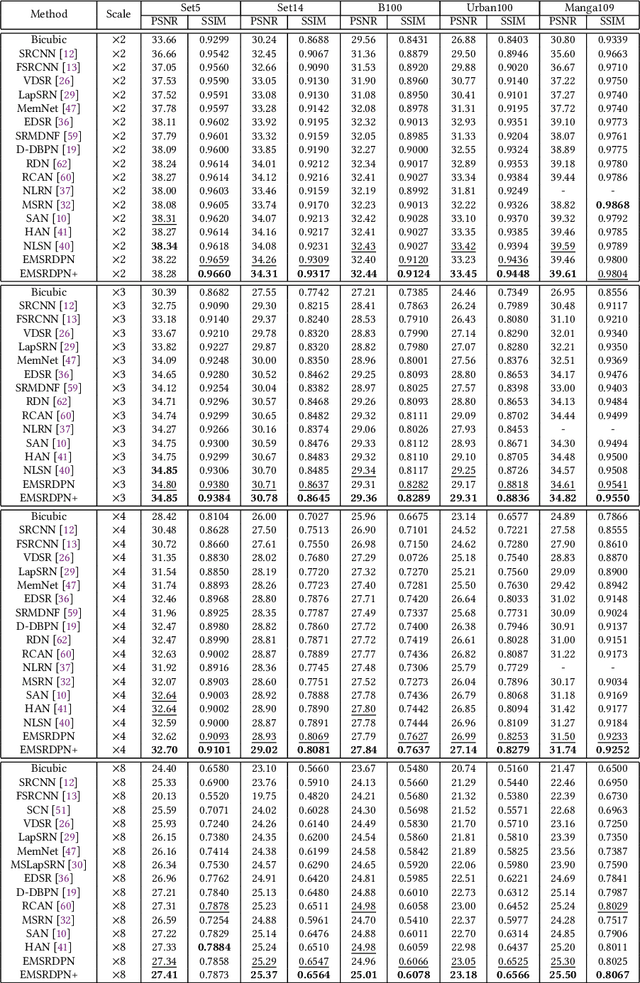
Deep convolutional neural networks have been demonstrated to be effective for SISR in recent years. On the one hand, residual connections and dense connections have been used widely to ease forward information and backward gradient flows to boost performance. However, current methods use residual connections and dense connections separately in most network layers in a sub-optimal way. On the other hand, although various networks and methods have been designed to improve computation efficiency, save parameters, or utilize training data of multiple scale factors for each other to boost performance, it either do super-resolution in HR space to have a high computation cost or can not share parameters between models of different scale factors to save parameters and inference time. To tackle these challenges, we propose an efficient single image super-resolution network using dual path connections with multiple scale learning named as EMSRDPN. By introducing dual path connections inspired by Dual Path Networks into EMSRDPN, it uses residual connections and dense connections in an integrated way in most network layers. Dual path connections have the benefits of both reusing common features of residual connections and exploring new features of dense connections to learn a good representation for SISR. To utilize the feature correlation of multiple scale factors, EMSRDPN shares all network units in LR space between different scale factors to learn shared features and only uses a separate reconstruction unit for each scale factor, which can utilize training data of multiple scale factors to help each other to boost performance, meanwhile which can save parameters and support shared inference for multiple scale factors to improve efficiency. Experiments show EMSRDPN achieves better performance and comparable or even better parameter and inference efficiency over SOTA methods.
Overcoming Pedestrian Blockage in mm-Wave Bands using Ground Reflections
Oct 26, 2021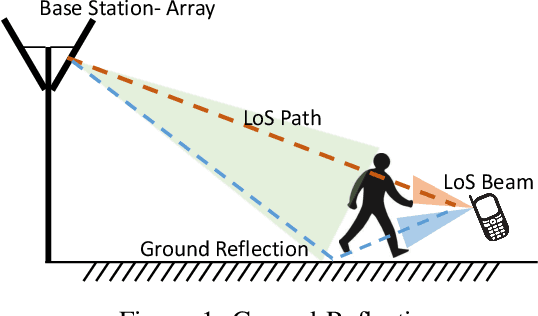
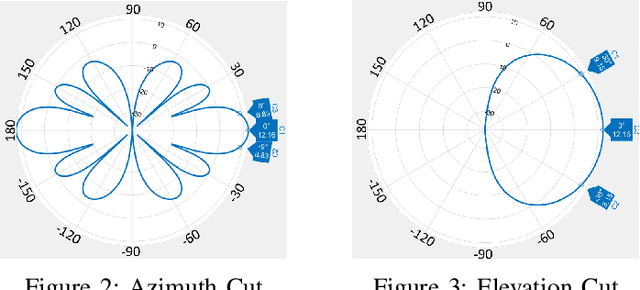
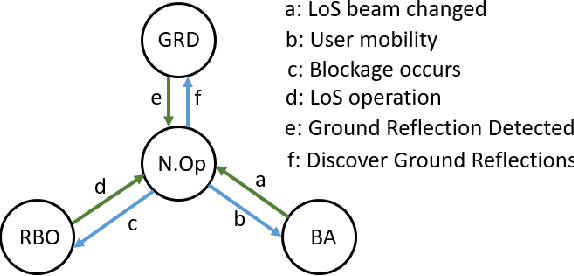
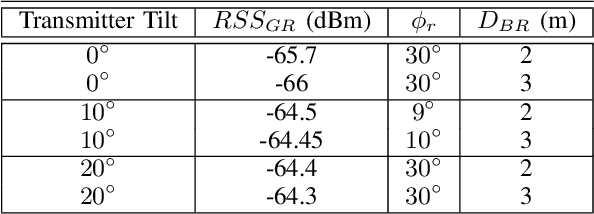
mm-Wave communication employs directional beams to overcome high path loss. High data rate communication is typically along line-of-sight (LoS). In outdoor environments, such communication is susceptible to temporary blockage by pedestrians interposed between the transmitter and receiver. It results in outages in which the user is lost, and has to be reacquired as a new user, severely disrupting interactive and high throughput applications. It has been presumed that the solution is to have a densely deployed set of base stations that will allow the mobile to perform a handover to a different non-blocked base station every time a current base station is blocked. This is however a very costly solution for outdoor environments. Through extensive experiments we show that it is possible to exploit a strong ground reflection with a received signal strength (RSS) about 4dB less than the LoS path in outdoor built environments with concrete or gravel surfaces, for beams that are narrow in azimuth but wide in zenith. While such reflected paths cannot support the high data rates of LoS paths, they can support control channel communication, and, importantly, sustain time synchronization between the mobile and the base station. This allows a mobile to quickly recover to the LoS path upon the cessation of the temporary blockage, which typically lasts a few hundred milliseconds. We present a simple in-band protocol that quickly discovers ground reflected radiation and uses it to recover the LoS link when the temporary blockage disappears.
DeepFilterNet: A Low Complexity Speech Enhancement Framework for Full-Band Audio based on Deep Filtering
Oct 11, 2021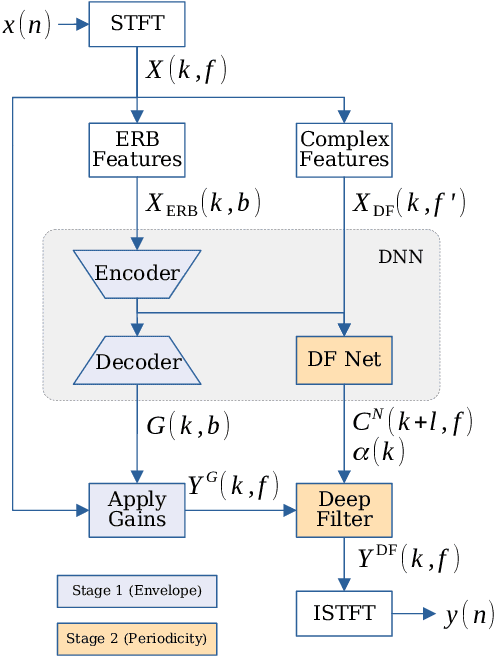
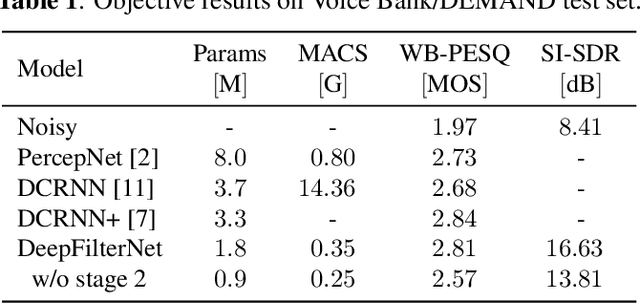
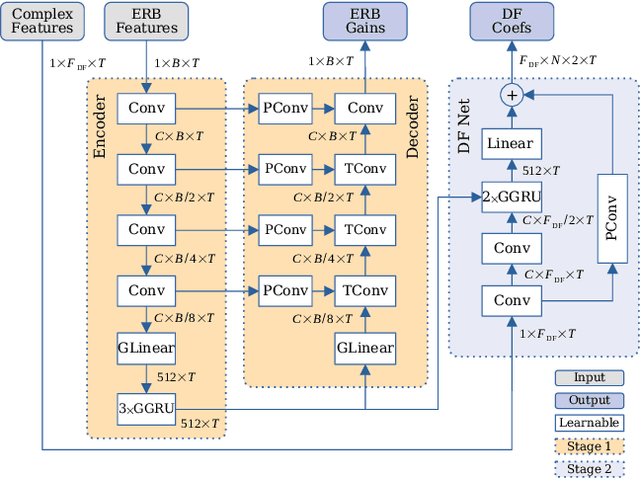
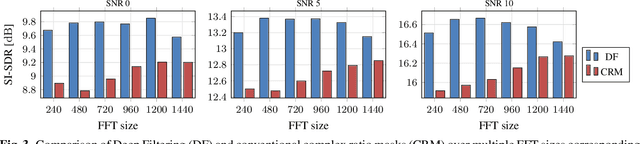
Complex-valued processing has brought deep learning-based speech enhancement and signal extraction to a new level. Typically, the process is based on a time-frequency (TF) mask which is applied to a noisy spectrogram, while complex masks (CM) are usually preferred over real-valued masks due to their ability to modify the phase. Recent work proposed to use a complex filter instead of a point-wise multiplication with a mask. This allows to incorporate information from previous and future time steps exploiting local correlations within each frequency band. In this work, we propose DeepFilterNet, a two stage speech enhancement framework utilizing deep filtering. First, we enhance the spectral envelope using ERB-scaled gains modeling the human frequency perception. The second stage employs deep filtering to enhance the periodic components of speech. Additionally to taking advantage of perceptual properties of speech, we enforce network sparsity via separable convolutions and extensive grouping in linear and recurrent layers to design a low complexity architecture. We further show that our two stage deep filtering approach outperforms complex masks over a variety of frequency resolutions and latencies and demonstrate convincing performance compared to other state-of-the-art models.
A Predictive Application Offloading Algorithm Using Small Datasets for Cloud Robotics
Aug 28, 2021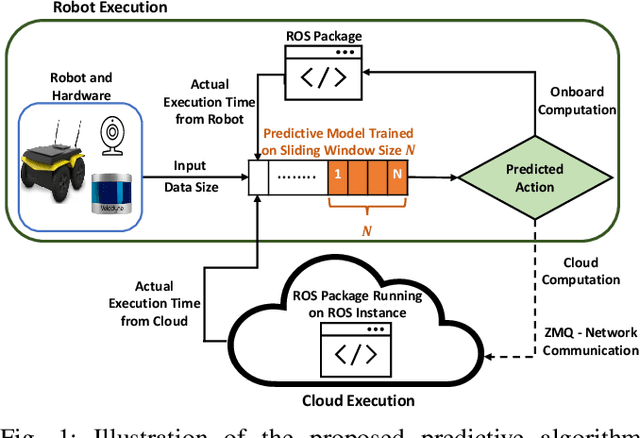
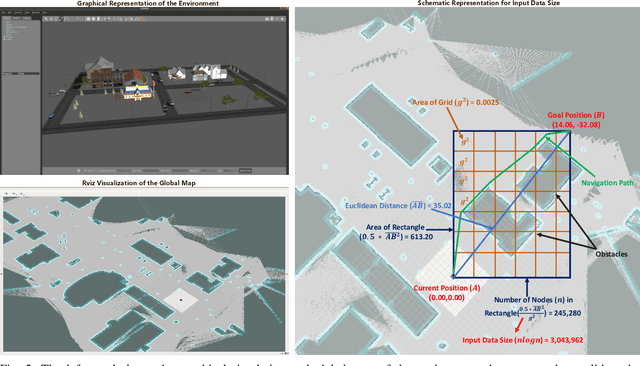
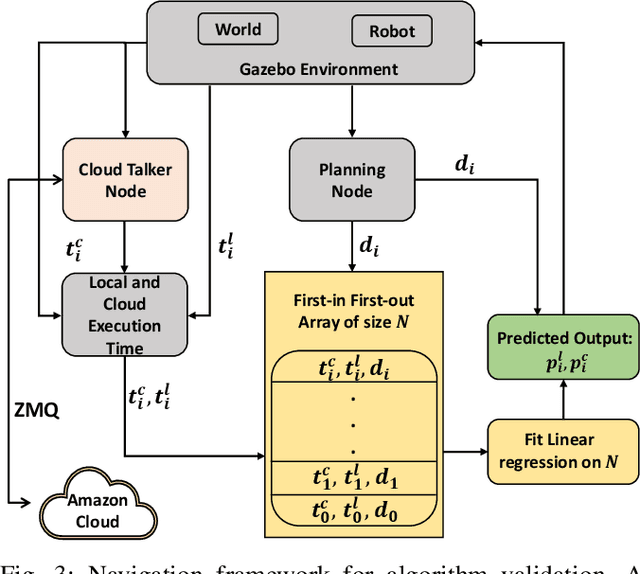

Many robotic applications that are critical for robot performance require immediate feedback, hence execution time is a critical concern. Furthermore, it is common that robots come with a fixed quantity of hardware resources; if an application requires more computational resources than the robot can accommodate, its onboard execution might be extended to a degree that degrades the robot performance. Cloud computing, on the other hand, features on-demand computational resources; by enabling robots to leverage those resources, application execution time can be reduced. The key to enabling robot use of cloud computing is designing an efficient offloading algorithm that makes optimum use of the robot onboard capabilities and also forms a quick consensus on when to offload without any prior knowledge or information about the application. In this paper, we propose a predictive algorithm to anticipate the time needed to execute an application for a given application data input size with the help of a small number of previous observations. To validate the algorithm, we train it on the previous N observations, which include independent (input data size) and dependent (execution time) variables. To understand how algorithm performance varies in terms of prediction accuracy and error, we tested various N values using linear regression and a mobile robot path planning application. From our experiments and analysis, we determined the algorithm to have acceptable error and prediction accuracy when N>40.
Visual Sentiment Analysis: A Natural DisasterUse-case Task at MediaEval 2021
Nov 22, 2021The Visual Sentiment Analysis task is being offered for the first time at MediaEval. The main purpose of the task is to predict the emotional response to images of natural disasters shared on social media. Disaster-related images are generally complex and often evoke an emotional response, making them an ideal use case of visual sentiment analysis. We believe being able to perform meaningful analysis of natural disaster-related data could be of great societal importance, and a joint effort in this regard can open several interesting directions for future research. The task is composed of three sub-tasks, each aiming to explore a different aspect of the challenge. In this paper, we provide a detailed overview of the task, the general motivation of the task, and an overview of the dataset and the metrics to be used for the evaluation of the proposed solutions.
AI Assurance using Causal Inference: Application to Public Policy
Dec 01, 2021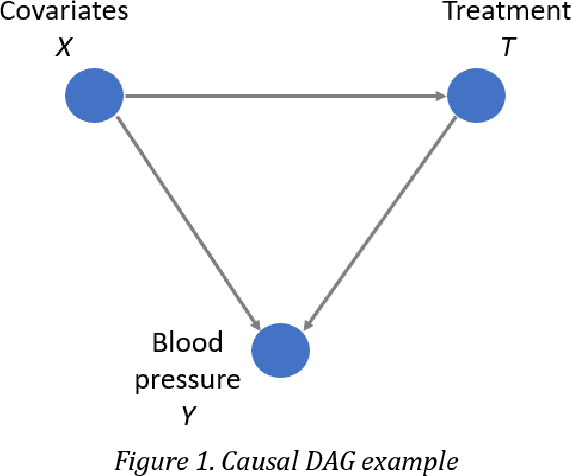
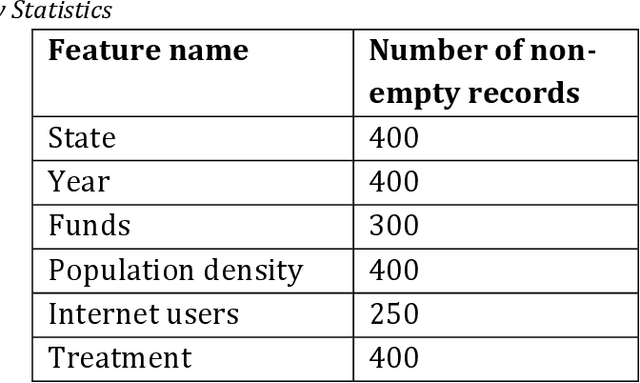

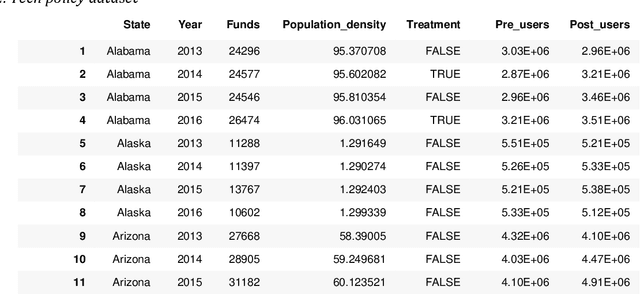
Developing and implementing AI-based solutions help state and federal government agencies, research institutions, and commercial companies enhance decision-making processes, automate chain operations, and reduce the consumption of natural and human resources. At the same time, most AI approaches used in practice can only be represented as "black boxes" and suffer from the lack of transparency. This can eventually lead to unexpected outcomes and undermine trust in such systems. Therefore, it is crucial not only to develop effective and robust AI systems, but to make sure their internal processes are explainable and fair. Our goal in this chapter is to introduce the topic of designing assurance methods for AI systems with high-impact decisions using the example of the technology sector of the US economy. We explain how these fields would benefit from revealing cause-effect relationships between key metrics in the dataset by providing the causal experiment on technology economics dataset. Several causal inference approaches and AI assurance techniques are reviewed and the transformation of the data into a graph-structured dataset is demonstrated.
JUSTICE: A Benchmark Dataset for Supreme Court's Judgment Prediction
Dec 06, 2021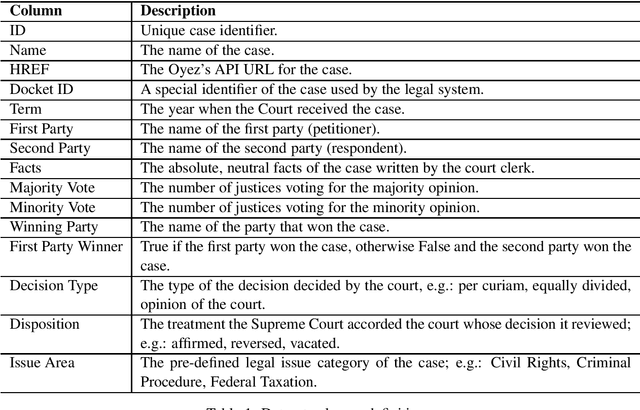



Artificial intelligence is being utilized in many domains as of late, and the legal system is no exception. However, as it stands now, the number of well-annotated datasets pertaining to legal documents from the Supreme Court of the United States (SCOTUS) is very limited for public use. Even though the Supreme Court rulings are public domain knowledge, trying to do meaningful work with them becomes a much greater task due to the need to manually gather and process that data from scratch each time. Hence, our goal is to create a high-quality dataset of SCOTUS court cases so that they may be readily used in natural language processing (NLP) research and other data-driven applications. Additionally, recent advances in NLP provide us with the tools to build predictive models that can be used to reveal patterns that influence court decisions. By using advanced NLP algorithms to analyze previous court cases, the trained models are able to predict and classify a court's judgment given the case's facts from the plaintiff and the defendant in textual format; in other words, the model is emulating a human jury by generating a final verdict.
CCA-MDD: A Coupled Cross-Attention based Framework for Streaming Mispronunciation detection and diagnosis
Nov 16, 2021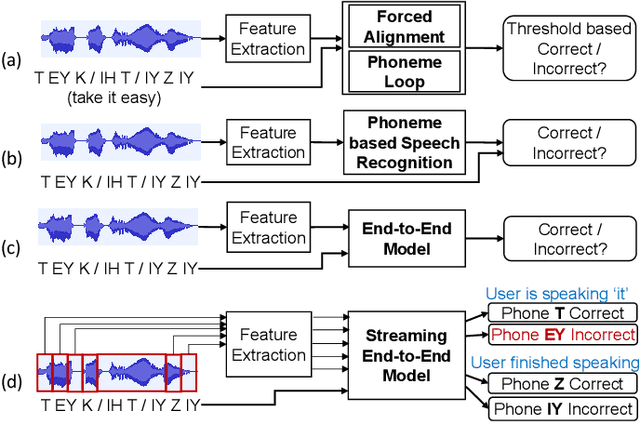
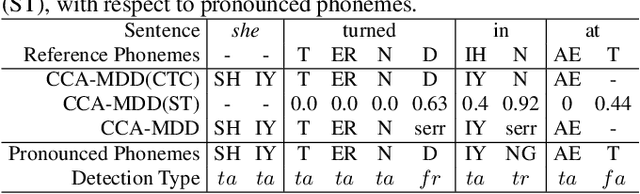
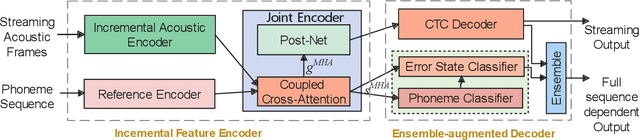

End-to-end models are becoming popular approaches for mispronunciation detection and diagnosis (MDD). A streaming MDD framework which is demanded by many practical applications still remains a challenge. This paper proposes a streaming end-to-end MDD framework called CCA-MDD. CCA-MDD supports online processing and is able to run strictly in real-time. The encoder of CCA-MDD consists of a conv-Transformer network based streaming acoustic encoder and an improved cross-attention named coupled cross-attention (CCA). The coupled cross-attention integrates encoded acoustic features with pre-encoded linguistic features. An ensemble of decoders trained from multi-task learning is applied for final MDD decision. Experiments on publicly available corpora demonstrate that CCA-MDD achieves comparable performance to published offline end-to-end MDD models.
Intelligent Reflecting Surfaces for Enhanced NOMA-based Visible Light Communications
Nov 08, 2021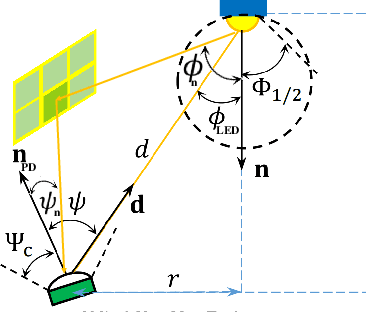
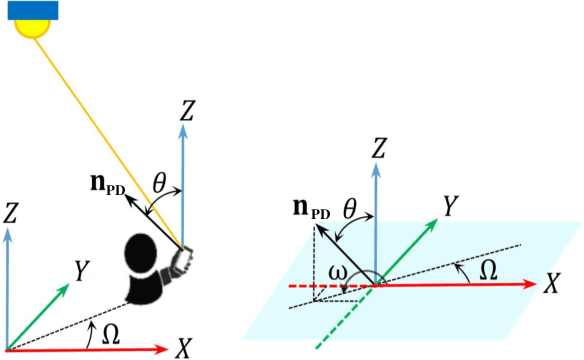
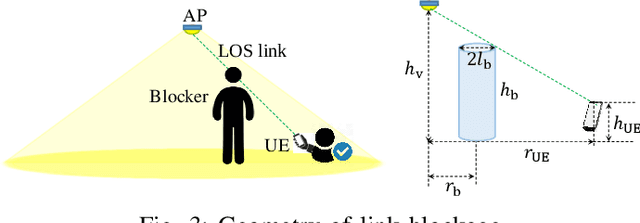
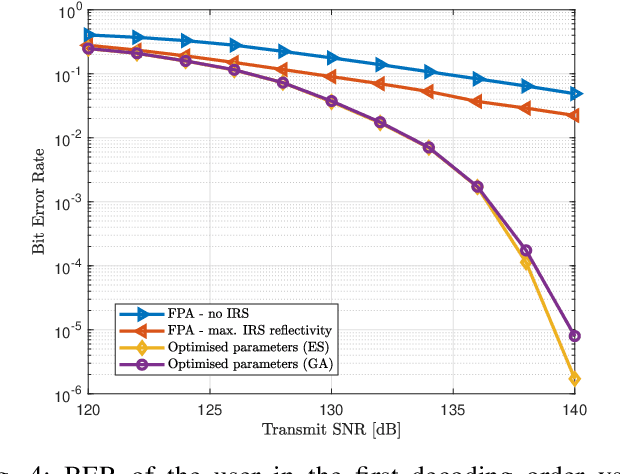
The emerging intelligent reflecting surface (IRS) technology introduces the potential of controlled light propagation in visible light communication (VLC) systems. This concept opens the door for new applications in which the channel itself can be altered to achieve specific key performance indicators. In this paper, for the first time in the open literature, we investigate the role that IRSs can play in enhancing the link reliability in VLC systems employing non-orthogonal multiple access (NOMA). We propose a framework for the joint optimisation of the NOMA and IRS parameters and show that it provides significant enhancements in link reliability. The enhancement is even more pronounced when the VLC channel is subject to blockage and random device orientation.
Real-time Universal Style Transfer on High-resolution Images via Zero-channel Pruning
Jun 16, 2020
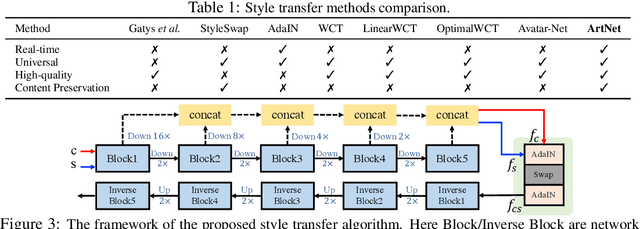


Extracting effective deep features to represent content and style information is the key to universal style transfer. Most existing algorithms use VGG19 as the feature extractor, which incurs a high computational cost and impedes real-time style transfer on high-resolution images. In this work, we propose a lightweight alternative architecture - ArtNet, which is based on GoogLeNet, and later pruned by a novel channel pruning method named Zero-channel Pruning specially designed for style transfer approaches. Besides, we propose a theoretically sound sandwich swap transform (S2) module to transfer deep features, which can create a pleasing holistic appearance and good local textures with an improved content preservation ability. By using ArtNet and S2, our method is 2.3 to 107.4 times faster than state-of-the-art approaches. The comprehensive experiments demonstrate that ArtNet can achieve universal, real-time, and high-quality style transfer on high-resolution images simultaneously, (68.03 FPS on 512 times 512 images).