 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
What went wrong and when? Instance-wise Feature Importance for Time-series Models
Mar 05, 2020
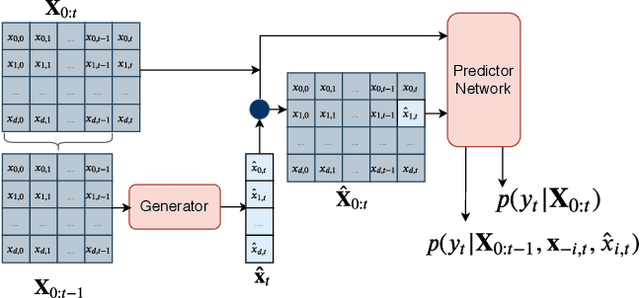
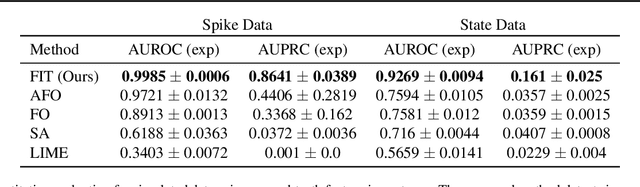
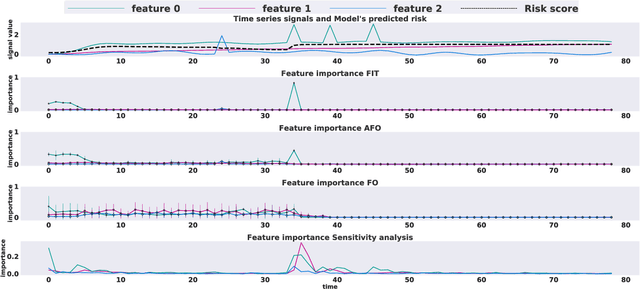
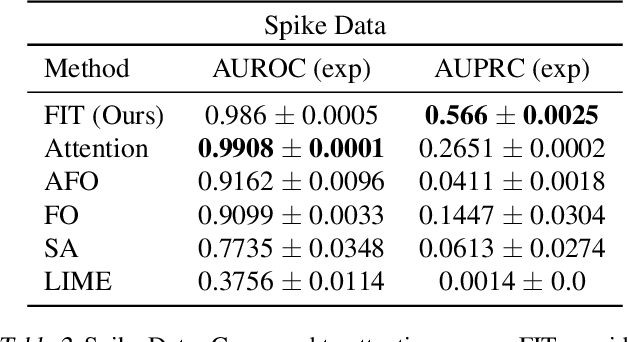
Multivariate time series models are poised to be used for decision support in high-stakes applications, such as healthcare. In these contexts, it is important to know which features at which times most influenced a prediction. We demonstrate a general approach for assigning importance to observations in multivariate time series, based on their counterfactual influence on future predictions. Specifically, we define the importance of an observation as the change in the predictive distribution, had the observation not been seen. We integrate over plausible counterfactuals by sampling from the corresponding conditional distributions of generative time series models. We compare our importance metric to gradient-based explanations, attention mechanisms, and other baselines in simulated and clinical ICU data, and show that our approach generates the most precise explanations. Our method is inexpensive, model agnostic, and can be used with arbitrarily complex time series models and predictors.
Prescriptive Machine Learning for Automated Decision Making: Challenges and Opportunities
Dec 15, 2021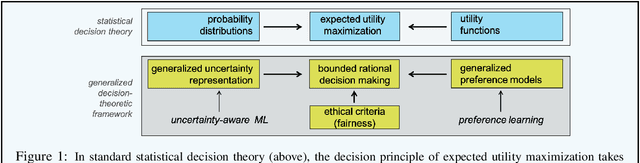
Recent applications of machine learning (ML) reveal a noticeable shift from its use for predictive modeling in the sense of a data-driven construction of models mainly used for the purpose of prediction (of ground-truth facts) to its use for prescriptive modeling. What is meant by this is the task of learning a model that stipulates appropriate decisions about the right course of action in real-world scenarios: Which medical therapy should be applied? Should this person be hired for the job? As argued in this article, prescriptive modeling comes with new technical conditions for learning and new demands regarding reliability, responsibility, and the ethics of decision making. Therefore, to support the data-driven design of decision-making agents that act in a rational but at the same time responsible manner, a rigorous methodological foundation of prescriptive ML is needed. The purpose of this short paper is to elaborate on specific characteristics of prescriptive ML and to highlight some key challenges it implies. Besides, drawing connections to other branches of contemporary AI research, the grounding of prescriptive ML in a (generalized) decision-theoretic framework is advocated.
A Comprehensive Study on Various Statistical Techniques for Prediction of Movie Success
Dec 01, 2021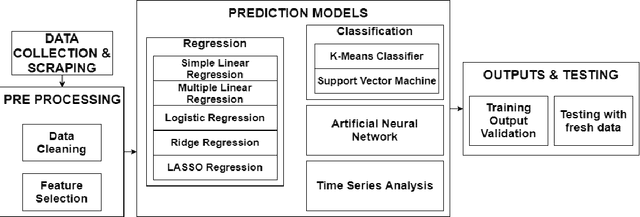
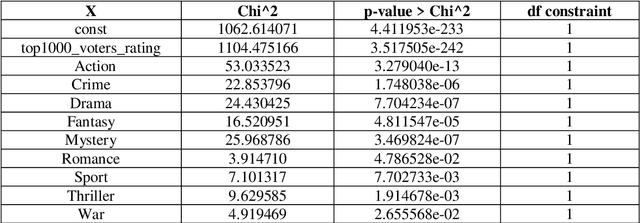
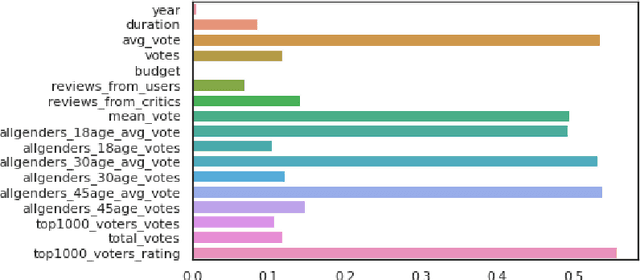
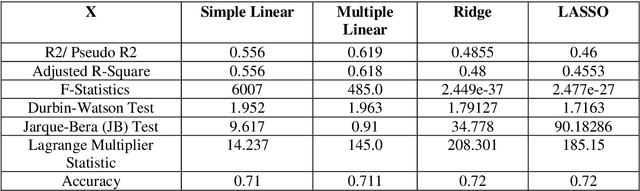
The film industry is one of the most popular entertainment industries and one of the biggest markets for business. Among the contributing factors to this would be the success of a movie in terms of its popularity as well as its box office performance. Hence, we create a comprehensive comparison between the various machine learning models to predict the rate of success of a movie. The effectiveness of these models along with their statistical significance is studied to conclude which of these models is the best predictor. Some insights regarding factors that affect the success of the movies are also found. The models studied include some Regression models, Machine Learning models, a Time Series model and a Neural Network with the Neural Network being the best performing model with an accuracy of about 86%. Additionally, as part of the testing data for the movies released in 2020 are analysed.
An Experimental Study of the Impact of Pre-training on the Pruning of a Convolutional Neural Network
Dec 15, 2021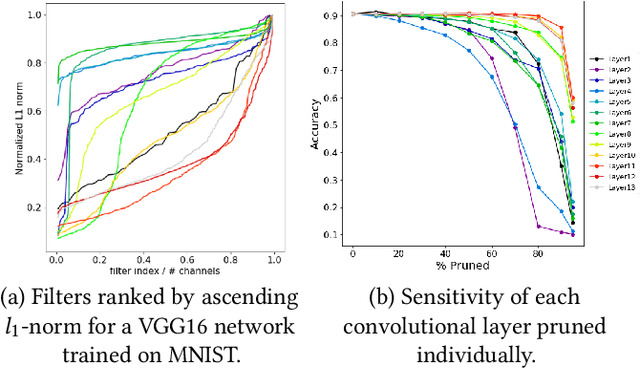
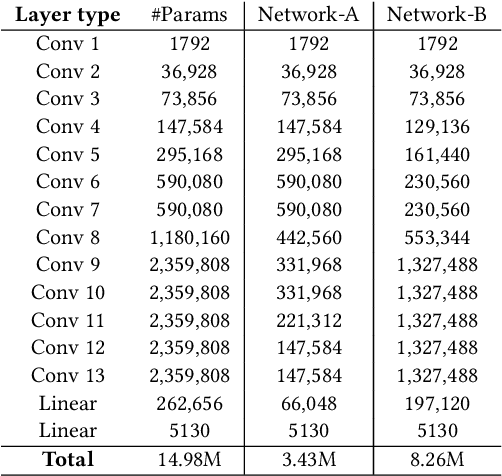
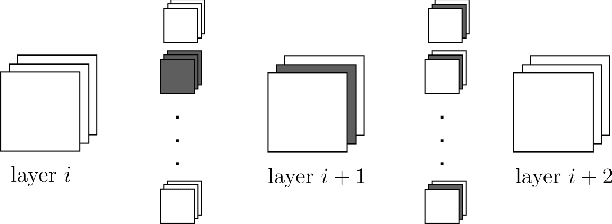
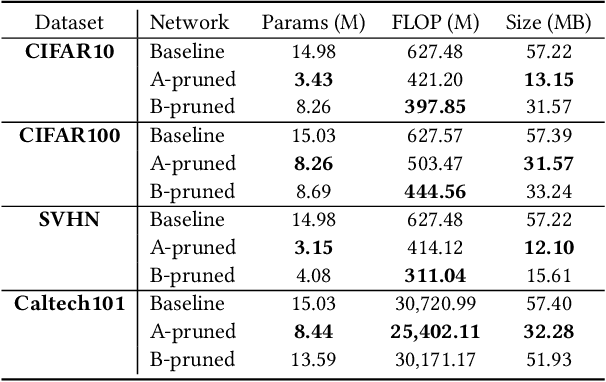
In recent years, deep neural networks have known a wide success in various application domains. However, they require important computational and memory resources, which severely hinders their deployment, notably on mobile devices or for real-time applications. Neural networks usually involve a large number of parameters, which correspond to the weights of the network. Such parameters, obtained with the help of a training process, are determinant for the performance of the network. However, they are also highly redundant. The pruning methods notably attempt to reduce the size of the parameter set, by identifying and removing the irrelevant weights. In this paper, we examine the impact of the training strategy on the pruning efficiency. Two training modalities are considered and compared: (1) fine-tuned and (2) from scratch. The experimental results obtained on four datasets (CIFAR10, CIFAR100, SVHN and Caltech101) and for two different CNNs (VGG16 and MobileNet) demonstrate that a network that has been pre-trained on a large corpus (e.g. ImageNet) and then fine-tuned on a particular dataset can be pruned much more efficiently (up to 80% of parameter reduction) than the same network trained from scratch.
Speech Separation Using an Asynchronous Fully Recurrent Convolutional Neural Network
Dec 04, 2021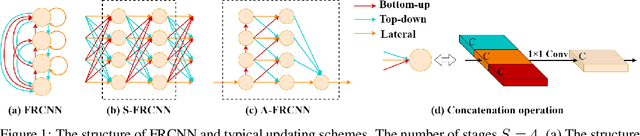

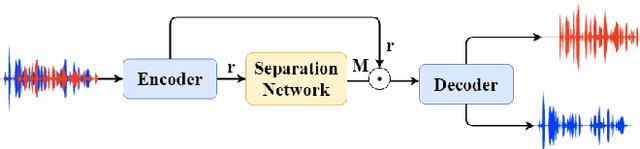
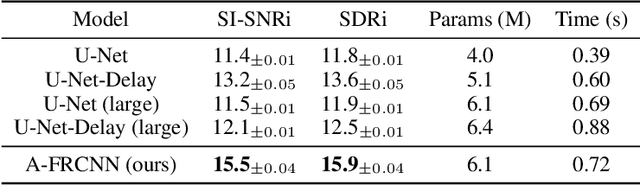
Recent advances in the design of neural network architectures, in particular those specialized in modeling sequences, have provided significant improvements in speech separation performance. In this work, we propose to use a bio-inspired architecture called Fully Recurrent Convolutional Neural Network (FRCNN) to solve the separation task. This model contains bottom-up, top-down and lateral connections to fuse information processed at various time-scales represented by \textit{stages}. In contrast to the traditional approach updating stages in parallel, we propose to first update the stages one by one in the bottom-up direction, then fuse information from adjacent stages simultaneously and finally fuse information from all stages to the bottom stage together. Experiments showed that this asynchronous updating scheme achieved significantly better results with much fewer parameters than the traditional synchronous updating scheme. In addition, the proposed model achieved good balance between speech separation accuracy and computational efficiency as compared to other state-of-the-art models on three benchmark datasets.
Neural ODE and DAE Modules for Power System Dynamic Modeling
Oct 25, 2021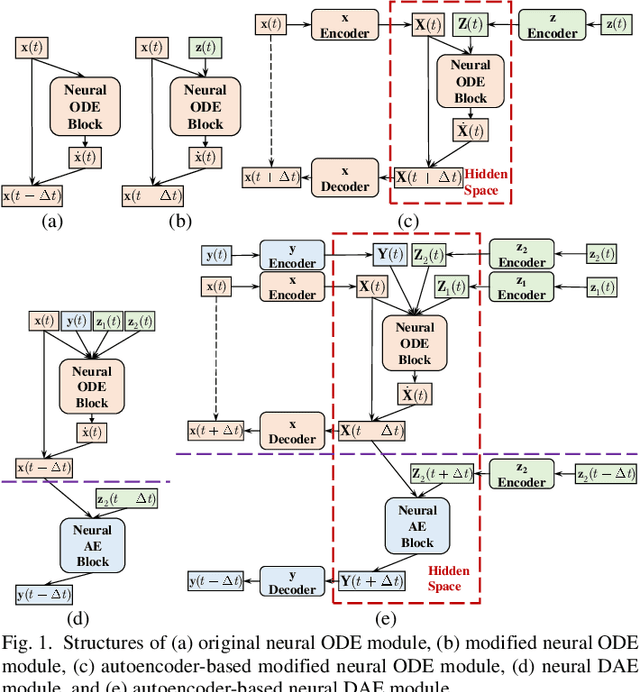
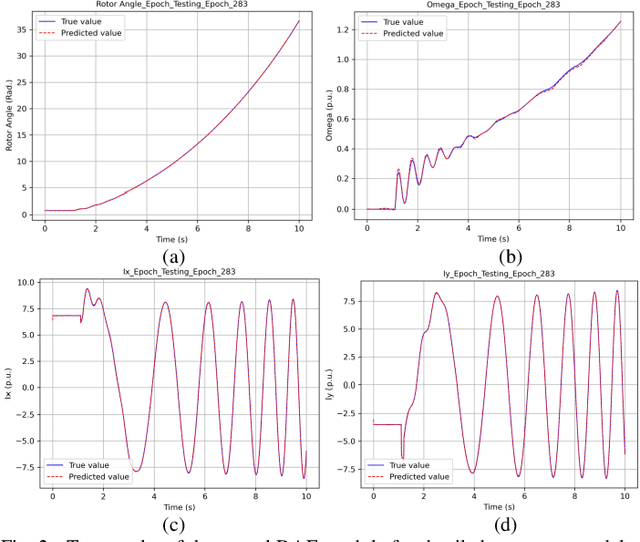
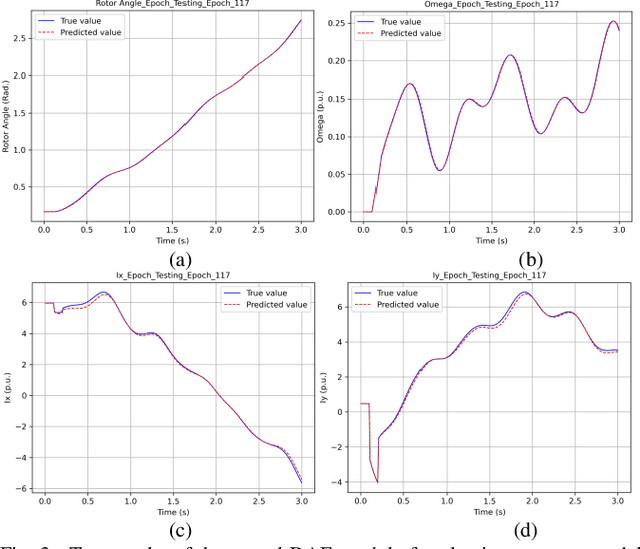
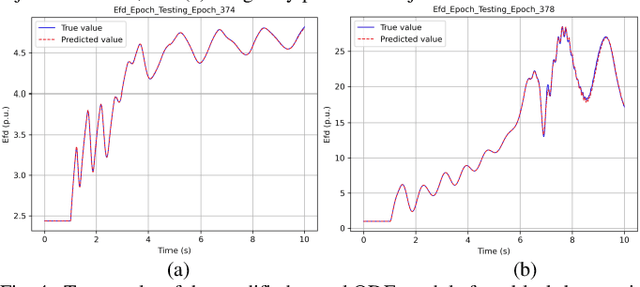
The time-domain simulation is the fundamental tool for power system transient stability analysis. Accurate and reliable simulations rely on accurate dynamic component modeling. In practical power systems, dynamic component modeling has long faced the challenges of model determination and model calibration, especially with the rapid development of renewable generation and power electronics. In this paper, based on the general framework of neural ordinary differential equations (ODEs), a modified neural ODE module and a neural differential-algebraic equations (DAEs) module for power system dynamic component modeling are proposed. The modules adopt an autoencoder to raise the dimension of state variables, model the dynamics of components with artificial neural networks (ANNs), and keep the numerical integration structure. In the neural DAE module, an additional ANN is used to calculate injection currents. The neural models can be easily integrated into time-domain simulations. With datasets consisting of sampled curves of input variables and output variables, the proposed modules can be used to fulfill the tasks of parameter inference, physics-data-integrated modeling, black-box modeling, etc., and can be easily integrated into power system dynamic simulations. Some simple numerical tests are carried out in the IEEE-39 system and prove the validity and potentiality of the proposed modules.
Fusion and Orthogonal Projection for Improved Face-Voice Association
Dec 20, 2021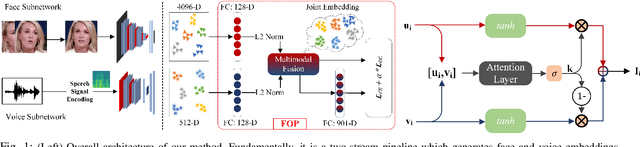
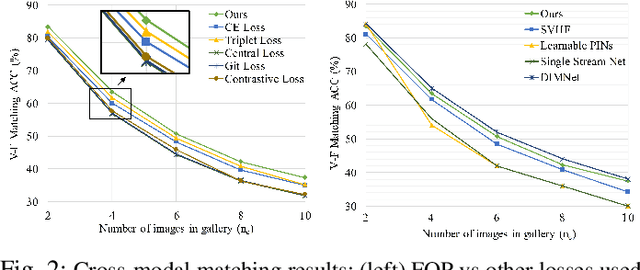
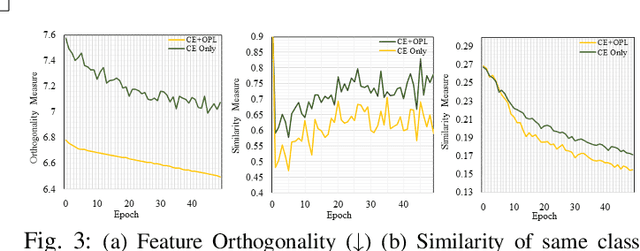
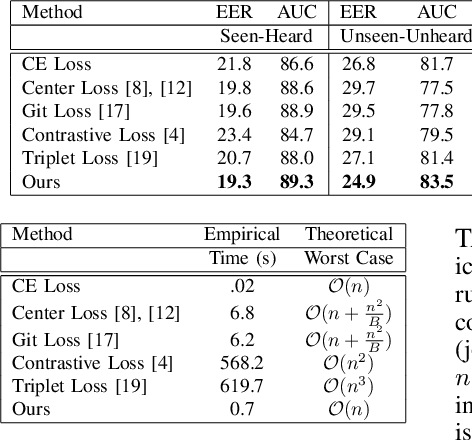
We study the problem of learning association between face and voice, which is gaining interest in the computer vision community lately. Prior works adopt pairwise or triplet loss formulations to learn an embedding space amenable for associated matching and verification tasks. Albeit showing some progress, such loss formulations are, however, restrictive due to dependency on distance-dependent margin parameter, poor run-time training complexity, and reliance on carefully crafted negative mining procedures. In this work, we hypothesize that enriched feature representation coupled with an effective yet efficient supervision is necessary in realizing a discriminative joint embedding space for improved face-voice association. To this end, we propose a light-weight, plug-and-play mechanism that exploits the complementary cues in both modalities to form enriched fused embeddings and clusters them based on their identity labels via orthogonality constraints. We coin our proposed mechanism as fusion and orthogonal projection (FOP) and instantiate in a two-stream pipeline. The overall resulting framework is evaluated on a large-scale VoxCeleb dataset with a multitude of tasks, including cross-modal verification and matching. Results show that our method performs favourably against the current state-of-the-art methods and our proposed supervision formulation is more effective and efficient than the ones employed by the contemporary methods.
Interactive Segmentation via Deep Learning and B-Spline Explicit Active Surfaces
Oct 25, 2021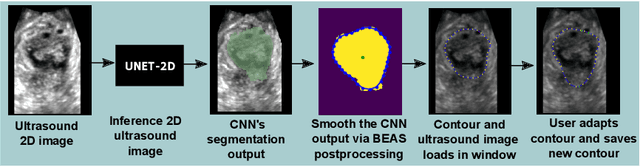
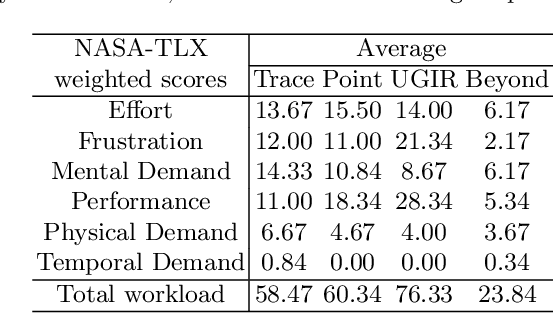
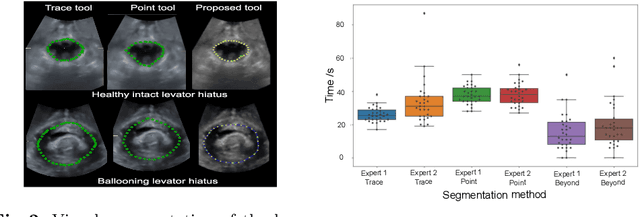
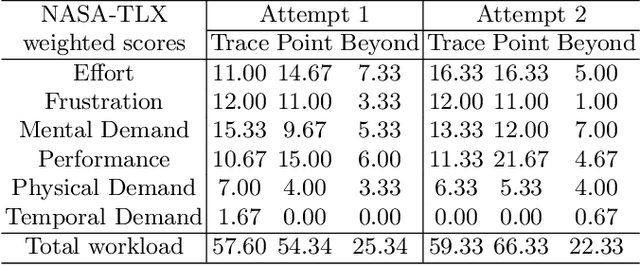
Automatic medical image segmentation via convolutional neural networks (CNNs) has shown promising results. However, they may not always be robust enough for clinical use. Sub-optimal segmentation would require clinician's to manually delineate the target object, causing frustration. To address this problem, a novel interactive CNN-based segmentation framework is proposed in this work. The aim is to represent the CNN segmentation contour as B-splines by utilising B-spline explicit active surfaces (BEAS). The interactive element of the framework allows the user to precisely edit the contour in real-time, and by utilising BEAS it ensures the final contour is smooth and anatomically plausible. This framework was applied to the task of 2D segmentation of the levator hiatus from 2D ultrasound (US) images, and compared to the current clinical tools used in pelvic floor disorder clinic (4DView, GE Healthcare; Zipf, Austria). Experimental results show that: 1) the proposed framework is more robust than current state-of-the-art CNNs; 2) the perceived workload calculated via the NASA-TLX index was reduced more than half for the proposed approach in comparison to current clinical tools; and 3) the proposed tool requires at least 13 seconds less user time than the clinical tools, which was significant (p=0.001).
* 11 pages, 3 figures, 2 tables
Employing chunk size adaptation to overcome concept drift
Oct 25, 2021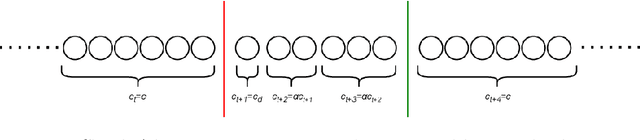
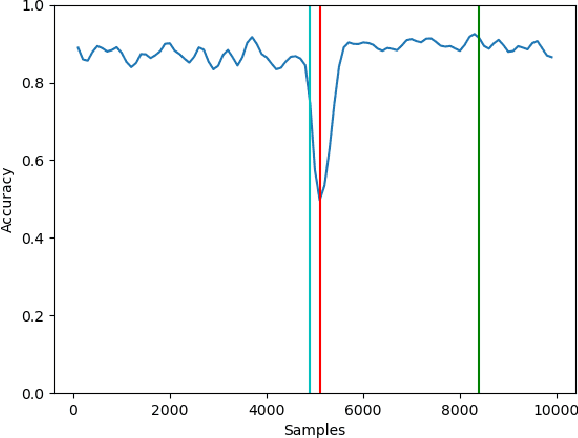
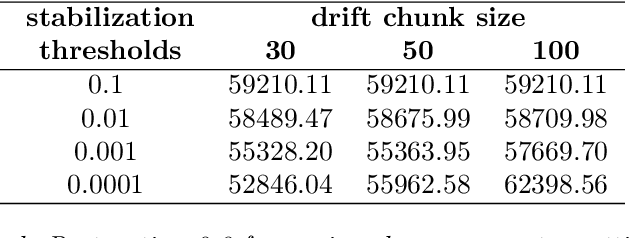
Modern analytical systems must be ready to process streaming data and correctly respond to data distribution changes. The phenomenon of changes in data distributions is called concept drift, and it may harm the quality of the used models. Additionally, the possibility of concept drift appearance causes that the used algorithms must be ready for the continuous adaptation of the model to the changing data distributions. This work focuses on non-stationary data stream classification, where a classifier ensemble is used. To keep the ensemble model up to date, the new base classifiers are trained on the incoming data blocks and added to the ensemble while, at the same time, outdated models are removed from the ensemble. One of the problems with this type of model is the fast reaction to changes in data distributions. We propose a new Chunk Adaptive Restoration framework that can be adapted to any block-based data stream classification algorithm. The proposed algorithm adjusts the data chunk size in the case of concept drift detection to minimize the impact of the change on the predictive performance of the used model. The conducted experimental research, backed up with the statistical tests, has proven that Chunk Adaptive Restoration significantly reduces the model's restoration time.
Optimizing Bayesian acquisition functions in Gaussian Processes
Nov 09, 2021

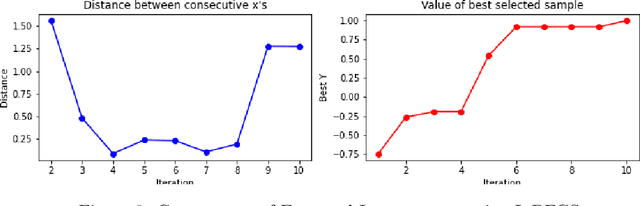
Bayesian Optimization is an effective method for searching the global maxima of an objective function especially if the function is unknown. The process comprises of using a surrogate function and choosing an acquisition function followed by optimizing the acquisition function to find the next sampling point. This paper analyzes different acquistion functions like Maximum Probability of Improvement and Expected Improvement and various optimizers like L-BFGS and TNC to optimize the acquisitions functions for finding the next sampling point. Along with the analysis of time taken, the paper also shows the importance of position of initial samples chosen.