 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Implementation of Parallel Simplified Swarm Optimization in CUDA
Oct 01, 2021
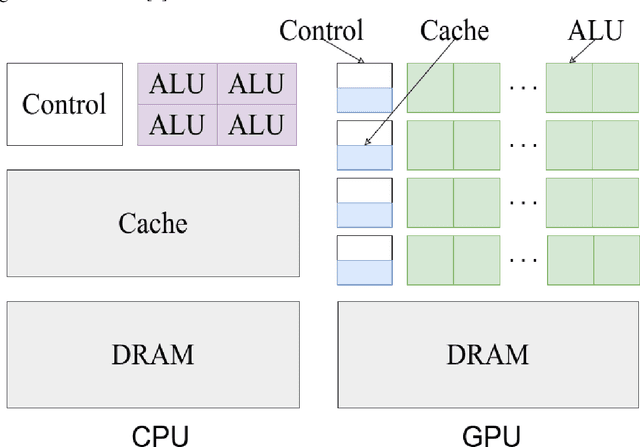
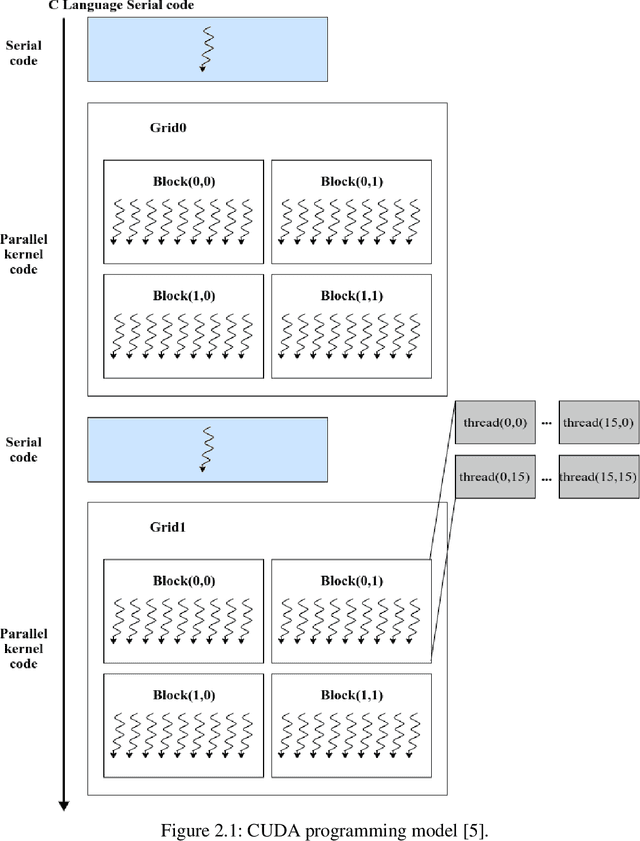
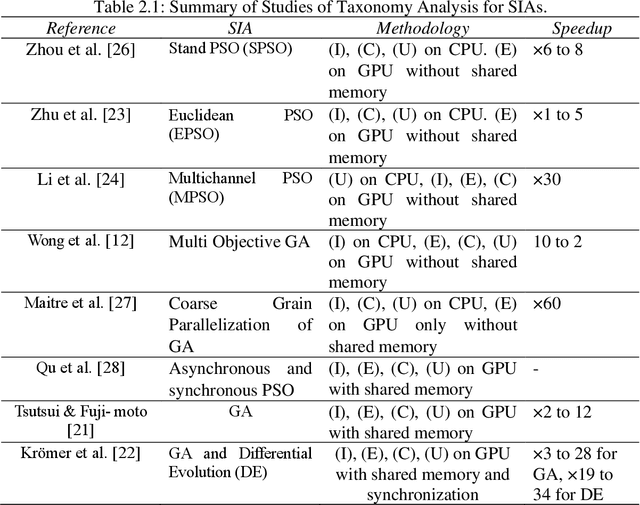
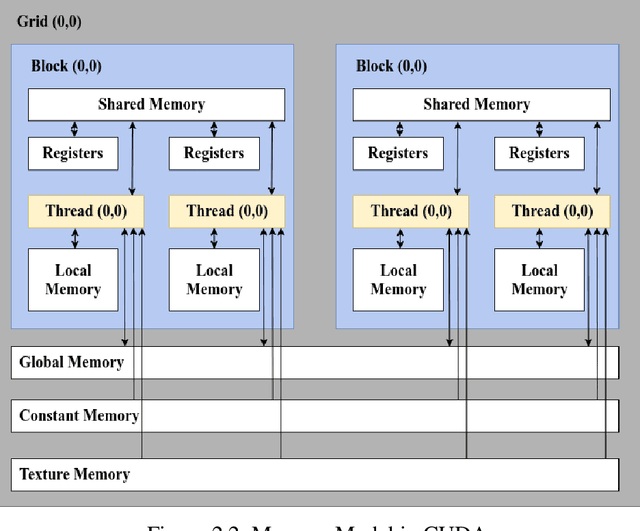
As the acquisition cost of the graphics processing unit (GPU) has decreased, personal computers (PC) can handle optimization problems nowadays. In optimization computing, intelligent swarm algorithms (SIAs) method is suitable for parallelization. However, a GPU-based Simplified Swarm Optimization Algorithm has never been proposed. Accordingly, this paper proposed Parallel Simplified Swarm Optimization (PSSO) based on the CUDA platform considering computational ability and versatility. In PSSO, the theoretical value of time complexity of fitness function is O (tNm). There are t iterations and N fitness functions, each of which required pair comparisons m times. pBests and gBest have the resource preemption when updating in previous studies. As the experiment results showed, the time complexity has successfully reduced by an order of magnitude of N, and the problem of resource preemption was avoided entirely.
Uncertainty-Aware Cascaded Dilation Filtering for High-Efficiency Deraining
Jan 07, 2022



Deraining is a significant and fundamental computer vision task, aiming to remove the rain streaks and accumulations in an image or video captured under a rainy day. Existing deraining methods usually make heuristic assumptions of the rain model, which compels them to employ complex optimization or iterative refinement for high recovery quality. This, however, leads to time-consuming methods and affects the effectiveness for addressing rain patterns deviated from from the assumptions. In this paper, we propose a simple yet efficient deraining method by formulating deraining as a predictive filtering problem without complex rain model assumptions. Specifically, we identify spatially-variant predictive filtering (SPFilt) that adaptively predicts proper kernels via a deep network to filter different individual pixels. Since the filtering can be implemented via well-accelerated convolution, our method can be significantly efficient. We further propose the EfDeRain+ that contains three main contributions to address residual rain traces, multi-scale, and diverse rain patterns without harming the efficiency. First, we propose the uncertainty-aware cascaded predictive filtering (UC-PFilt) that can identify the difficulties of reconstructing clean pixels via predicted kernels and remove the residual rain traces effectively. Second, we design the weight-sharing multi-scale dilated filtering (WS-MS-DFilt) to handle multi-scale rain streaks without harming the efficiency. Third, to eliminate the gap across diverse rain patterns, we propose a novel data augmentation method (i.e., RainMix) to train our deep models. By combining all contributions with sophisticated analysis on different variants, our final method outperforms baseline methods on four single-image deraining datasets and one video deraining dataset in terms of both recovery quality and speed.
Developing and Deploying Machine Learning Pipelines against Real-Time Image Streams from the PACS
Apr 20, 2020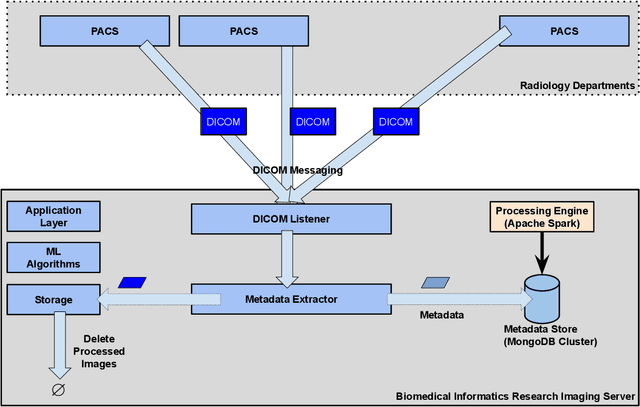
Executing machine learning (ML) pipelines on radiology images is hard due to limited computing resources in clinical environments, whereas running them in research clusters in real-time requires efficient data transfer capabilities. We propose Niffler, an integrated ML framework that runs in research clusters that receives radiology images in real-time from hospitals' Picture Archiving and Communication Systems (PACS). Niffler consists of an inter-domain data streaming approach that exploits the Digital Imaging and Communications in Medicine (DICOM) protocol to fetch data from the PACS to the data processing servers for executing the ML pipelines. It provides metadata extraction capabilities and Application programming interfaces (APIs) to apply filters on the DICOM images and run the ML pipelines. The outcomes of the ML pipelines can then be shared back with the end-users in a de-identified manner. Evaluations on the Niffler prototype highlight the feasibility and efficiency in running the ML pipelines in real-time from a research cluster on the images received in real-time from hospital PACS.
Cinderella's shoe won't fit Soundarya: An audit of facial processing tools on Indian faces
Dec 17, 2021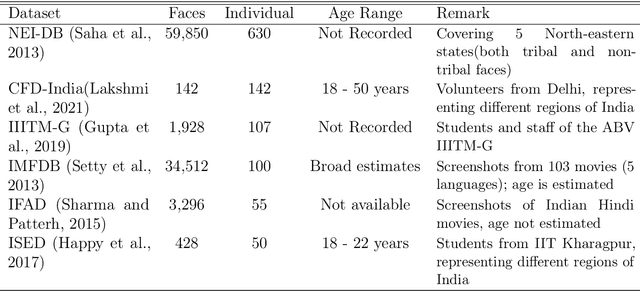
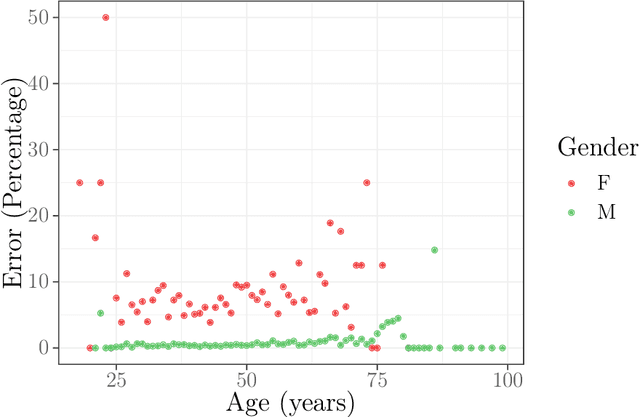
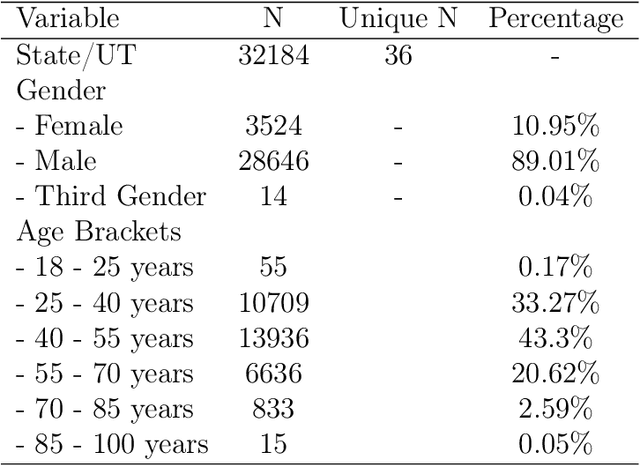
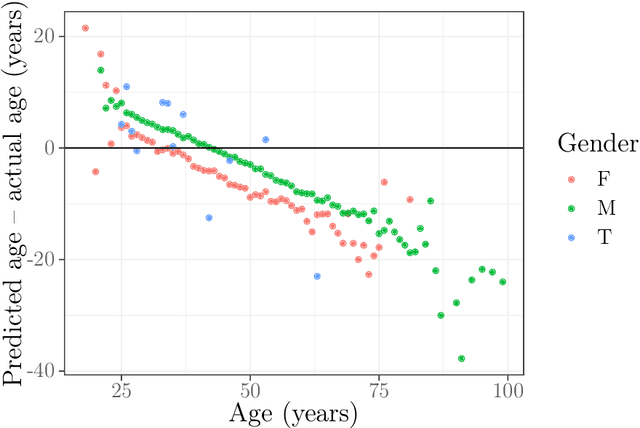
The increasing adoption of facial processing systems in India is fraught with concerns of privacy, transparency, accountability, and missing procedural safeguards. At the same time, we also know very little about how these technologies perform on the diverse features, characteristics, and skin tones of India's 1.34 billion-plus population. In this paper, we test the face detection and facial analysis functions of four commercial facial processing tools on a dataset of Indian faces. The tools display varying error rates in the face detection and gender and age classification functions. The gender classification error rate for Indian female faces is consistently higher compared to that of males -- the highest female error rate being 14.68%. In some cases, this error rate is much higher than that shown by previous studies for females of other nationalities. Age classification errors are also high. Despite taking into account an acceptable error margin of plus or minus 10 years from a person's actual age, age prediction failures are in the range of 14.3% to 42.2%. These findings point to the limited accuracy of facial processing tools, particularly for certain demographic groups, and the need for more critical thinking before adopting such systems.
Real-time Quadrotor Navigation Through Planning in Depth Space in Unstructured Environments
Oct 18, 2020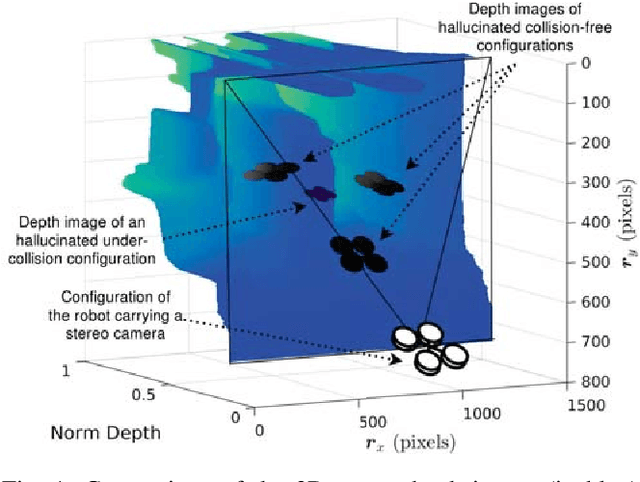
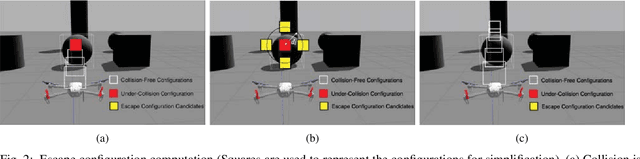
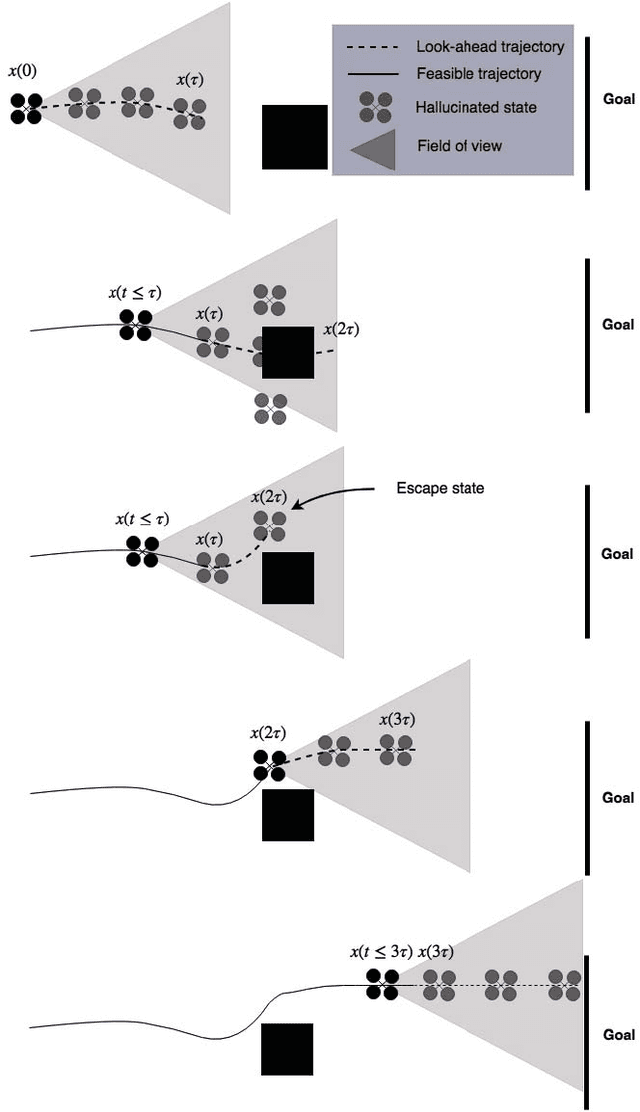
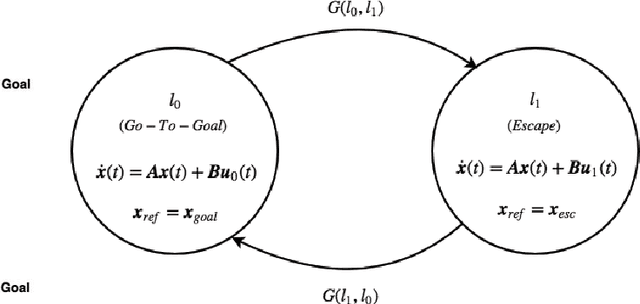
This paper addresses the problem of real-time vision-based autonomous obstacle avoidance in unstructured environments for quadrotor UAVs. We assume that our UAV is equipped with a forward facing stereo camera as the only sensor to perceive the world around it. Moreover, all the computations are performed onboard. Feasible trajectory generation in this kind of problems requires rapid collision checks along with efficient planning algorithms. We propose a trajectory generation approach in the depth image space, which refers to the environment information as depicted by the depth images. In order to predict the collision in a look ahead robot trajectory, we create depth images from the sequence of robot poses along the path. We compare these images with the depth images of the actual world sensed through the forward facing stereo camera. We aim at generating fuel optimal trajectories inside the depth image space. In case of a predicted collision, a switching strategy is used to aggressively deviate the quadrotor away from the obstacle. For this purpose we use two closed loop motion primitives based on Linear Quadratic Regulator (LQR) objective functions. The proposed approach is validated through simulation and hardware experiments.
Deep Fraud Detection on Non-attributed Graph
Oct 04, 2021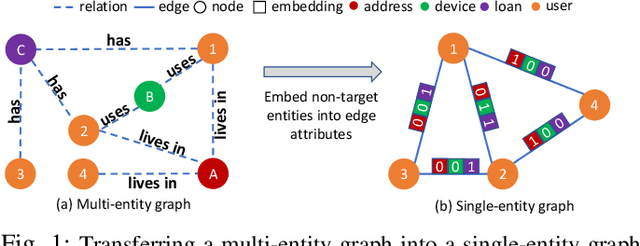
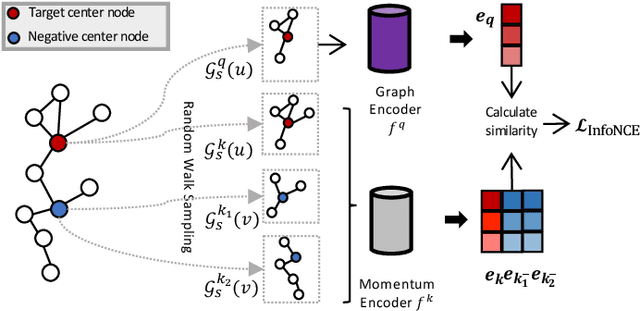
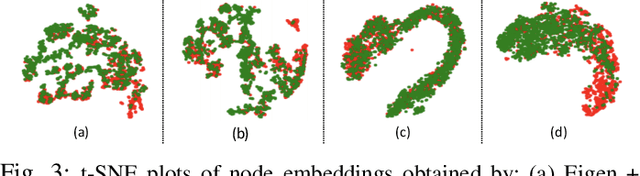

Fraud detection problems are usually formulated as a machine learning problem on a graph. Recently, Graph Neural Networks (GNNs) have shown solid performance on fraud detection. The successes of most previous methods heavily rely on rich node features and high-fidelity labels. However, labeled data is scarce in large-scale industrial problems, especially for fraud detection where new patterns emerge from time to time. Meanwhile, node features are also limited due to privacy and other constraints. In this paper, two improvements are proposed: 1) We design a graph transformation method capturing the structural information to facilitate GNNs on non-attributed fraud graphs. 2) We propose a novel graph pre-training strategy to leverage more unlabeled data via contrastive learning. Experiments on a large-scale industrial dataset demonstrate the effectiveness of the proposed framework for fraud detection.
Spatio-Temporal Urban Knowledge Graph Enabled Mobility Prediction
Nov 10, 2021
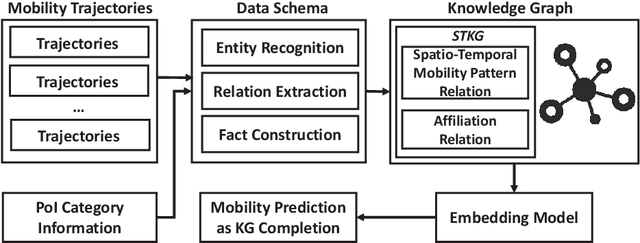

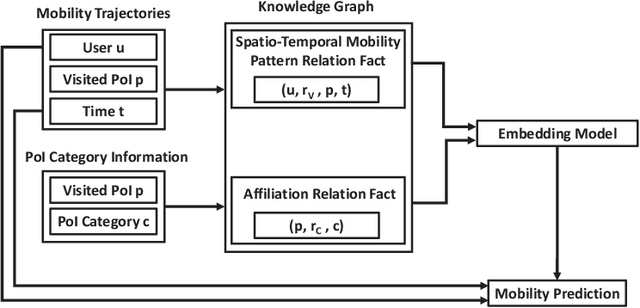
With the rapid development of the mobile communication technology, mobile trajectories of humans are massively collected by Internet service providers (ISPs) and application service providers (ASPs). On the other hand, the rising paradigm of knowledge graph (KG) provides us a promising solution to extract structured "knowledge" from massive trajectory data. In this paper, we focus on modeling users' spatio-temporal mobility patterns based on knowledge graph techniques, and predicting users' future movement based on the "knowledge'' extracted from multiple sources in a cohesive manner. Specifically, we propose a new type of knowledge graph, i.e., spatio-temporal urban knowledge graph (STKG), where mobility trajectories, category information of venues, and temporal information are jointly modeled by the facts with different relation types in STKG. The mobility prediction problem is converted to the knowledge graph completion problem in STKG. Further, a complex embedding model with elaborately designed scoring functions is proposed to measure the plausibility of facts in STKG to solve the knowledge graph completion problem, which considers temporal dynamics of the mobility patterns and utilizes PoI categories as the auxiliary information and background knowledge. Extensive evaluations confirm the high accuracy of our model in predicting users' mobility, i.e., improving the accuracy by 5.04% compared with the state-of-the-art algorithms. In addition, PoI categories as the background knowledge and auxiliary information are confirmed to be helpful by improving the performance by 3.85% in terms of accuracy. Additionally, experiments show that our proposed method is time-efficient by reducing the computational time by over 43.12% compared with existing methods.
Elasticity Meets Continuous-Time: Map-Centric Dense 3D LiDAR SLAM
Aug 05, 2020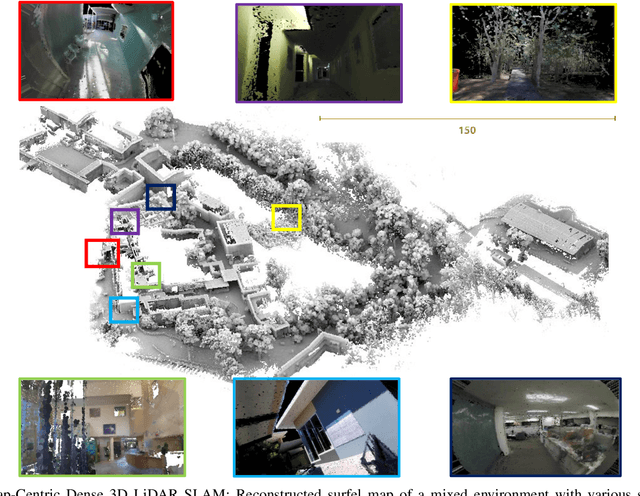

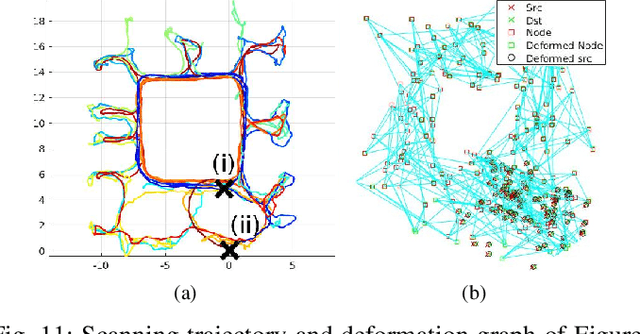
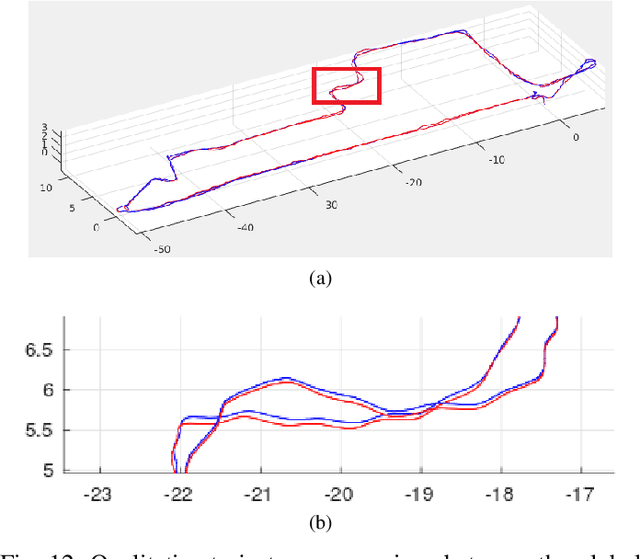
Map-centric SLAM utilizes elasticity as a means of loop closure. This approach reduces the cost of loop closure while still provides large-scale fusion-based dense maps, when compared to the trajectory-centric SLAM approaches. In this paper, we present a novel framework for 3D LiDAR-based map-centric SLAM. Having the advantages of a map-centric approach, our method exhibits new features to overcome the shortcomings of existing systems, associated with multi-modal sensor fusion and LiDAR motion distortion. This is accomplished through the use of a local Continuous-Time (CT) trajectory representation. Also, our surface resolution preservative matching algorithm and Wishart-based surfel fusion model enables non-redundant yet dense mapping. Furthermore, we present a robust metric loop closure model to make the approach stable regardless of where the loop closure occurs. Finally, we demonstrate our approach through both simulation and real data experiments using multiple sensor payload configurations and environments to illustrate its utility and robustness.
Traditional Chinese Synthetic Datasets Verified with Labeled Data for Scene Text Recognition
Nov 26, 2021

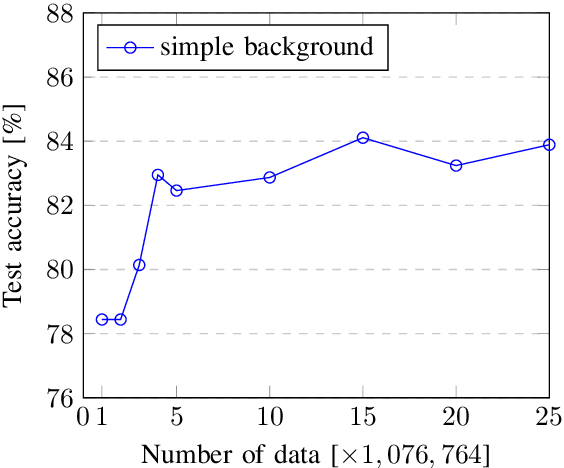
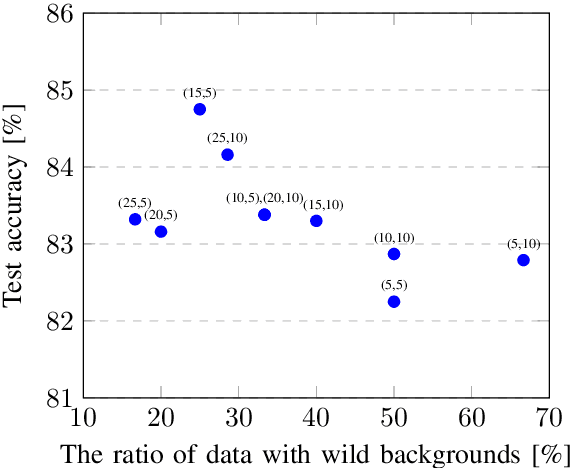
Scene text recognition (STR) has been widely studied in academia and industry. Training a text recognition model often requires a large amount of labeled data, but data labeling can be difficult, expensive, or time-consuming, especially for Traditional Chinese text recognition. To the best of our knowledge, public datasets for Traditional Chinese text recognition are lacking. This paper presents a framework for a Traditional Chinese synthetic data engine which aims to improve text recognition model performance. We generated over 20 million synthetic data and collected over 7,000 manually labeled data TC-STR 7k-word as the benchmark. Experimental results show that a text recognition model can achieve much better accuracy either by training from scratch with our generated synthetic data or by further fine-tuning with TC-STR 7k-word.
InfoLM: A New Metric to Evaluate Summarization & Data2Text Generation
Dec 02, 2021
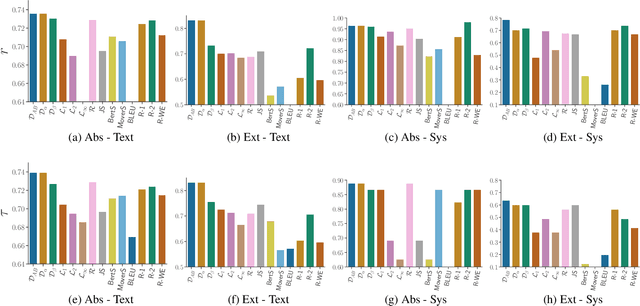
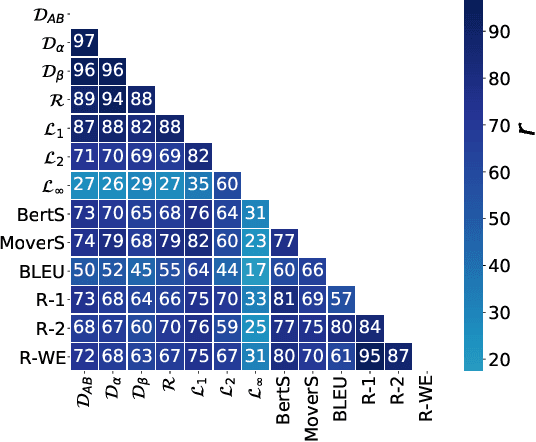
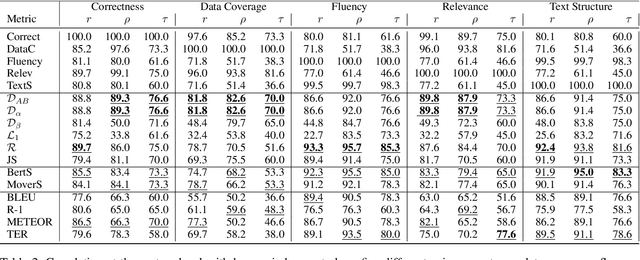
Assessing the quality of natural language generation systems through human annotation is very expensive. Additionally, human annotation campaigns are time-consuming and include non-reusable human labour. In practice, researchers rely on automatic metrics as a proxy of quality. In the last decade, many string-based metrics (e.g., BLEU) have been introduced. However, such metrics usually rely on exact matches and thus, do not robustly handle synonyms. In this paper, we introduce InfoLM a family of untrained metrics that can be viewed as a string-based metric that addresses the aforementioned flaws thanks to a pre-trained masked language model. This family of metrics also makes use of information measures allowing the adaptation of InfoLM to various evaluation criteria. Using direct assessment, we demonstrate that InfoLM achieves statistically significant improvement and over $10$ points of correlation gains in many configurations on both summarization and data2text generation.