 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SPIN: Simplifying Polar Invariance for Neural networks Application to vision-based irradiance forecasting
Nov 29, 2021
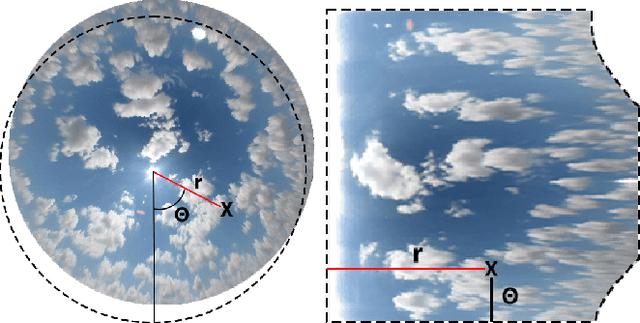
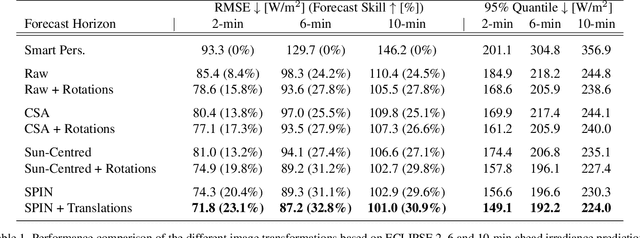

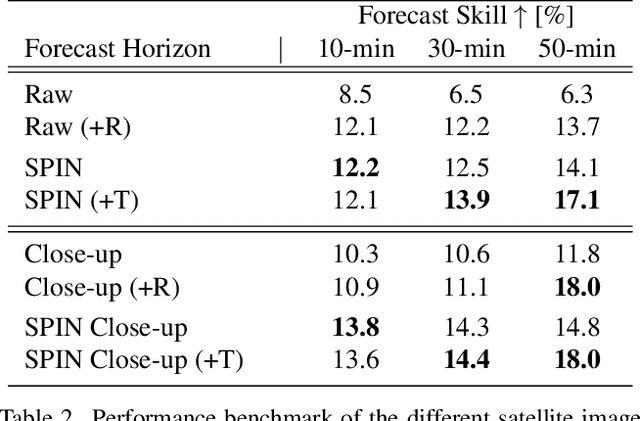
Translational invariance induced by pooling operations is an inherent property of convolutional neural networks, which facilitates numerous computer vision tasks such as classification. Yet to leverage rotational invariant tasks, convolutional architectures require specific rotational invariant layers or extensive data augmentation to learn from diverse rotated versions of a given spatial configuration. Unwrapping the image into its polar coordinates provides a more explicit representation to train a convolutional architecture as the rotational invariance becomes translational, hence the visually distinct but otherwise equivalent rotated versions of a given scene can be learnt from a single image. We show with two common vision-based solar irradiance forecasting challenges (i.e. using ground-taken sky images or satellite images), that this preprocessing step significantly improves prediction results by standardising the scene representation, while decreasing training time by a factor of 4 compared to augmenting data with rotations. In addition, this transformation magnifies the area surrounding the centre of the rotation, leading to more accurate short-term irradiance predictions.
POEM: 1-bit Point-wise Operations based on Expectation-Maximization for Efficient Point Cloud Processing
Nov 26, 2021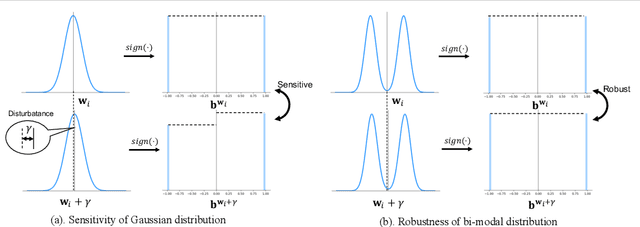
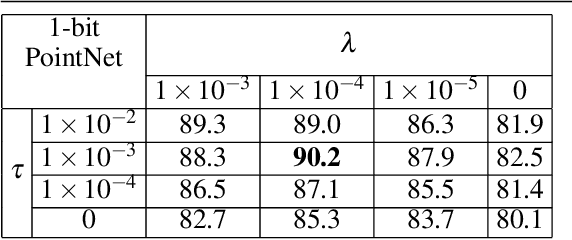
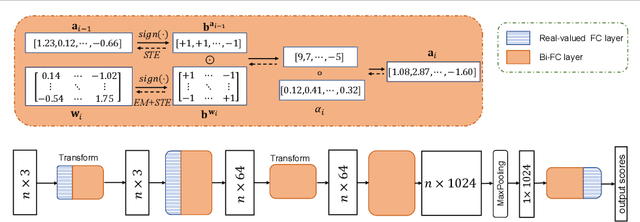

Real-time point cloud processing is fundamental for lots of computer vision tasks, while still challenged by the computational problem on resource-limited edge devices. To address this issue, we implement XNOR-Net-based binary neural networks (BNNs) for an efficient point cloud processing, but its performance is severely suffered due to two main drawbacks, Gaussian-distributed weights and non-learnable scale factor. In this paper, we introduce point-wise operations based on Expectation-Maximization (POEM) into BNNs for efficient point cloud processing. The EM algorithm can efficiently constrain weights for a robust bi-modal distribution. We lead a well-designed reconstruction loss to calculate learnable scale factors to enhance the representation capacity of 1-bit fully-connected (Bi-FC) layers. Extensive experiments demonstrate that our POEM surpasses existing the state-of-the-art binary point cloud networks by a significant margin, up to 6.7 %.
Duality Temporal-channel-frequency Attention Enhanced Speaker Representation Learning
Oct 15, 2021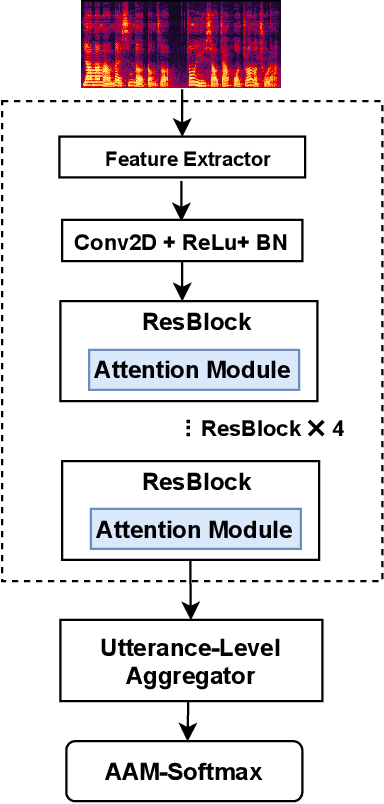
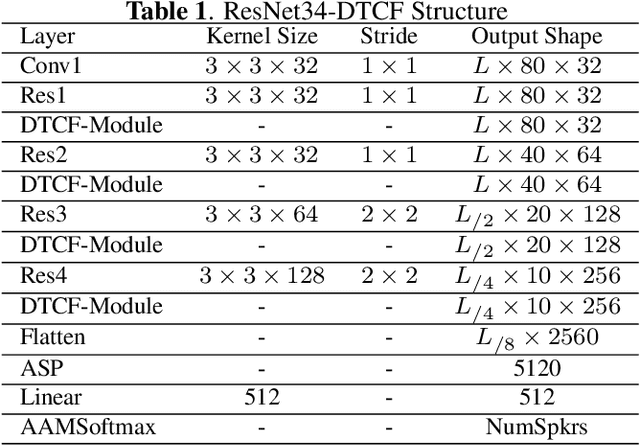
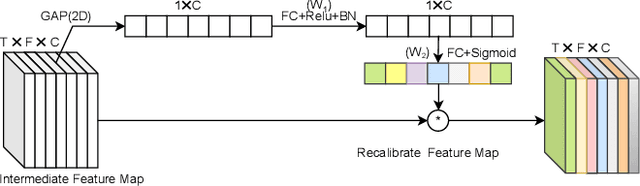
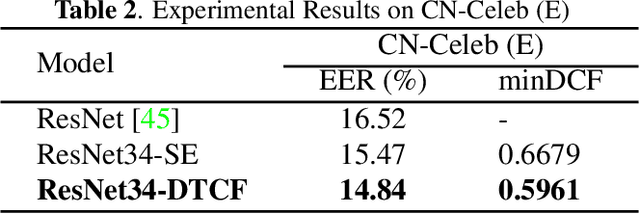
The use of channel-wise attention in CNN based speaker representation networks has achieved remarkable performance in speaker verification (SV). But these approaches do simple averaging on time and frequency feature maps before channel-wise attention learning and ignore the essential mutual interaction among temporal, channel as well as frequency scales. To address this problem, we propose the Duality Temporal-Channel-Frequency (DTCF) attention to re-calibrate the channel-wise features with aggregation of global context on temporal and frequency dimensions. Specifically, the duality attention - time-channel (T-C) attention as well as frequency-channel (F-C) attention - aims to focus on salient regions along the T-C and F-C feature maps that may have more considerable impact on the global context, leading to more discriminative speaker representations. We evaluate the effectiveness of the proposed DTCF attention on the CN-Celeb and VoxCeleb datasets. On the CN-Celeb evaluation set, the EER/minDCF of ResNet34-DTCF are reduced by 0.63%/0.0718 compared with those of ResNet34-SE. On VoxCeleb1-O, VoxCeleb1-E and VoxCeleb1-H evaluation sets, the EER/minDCF of ResNet34-DTCF achieve 0.36%/0.0263, 0.39%/0.0382 and 0.74%/0.0753 reductions compared with those of ResNet34-SE.
A Novel Sequential Coreset Method for Gradient Descent Algorithms
Dec 05, 2021
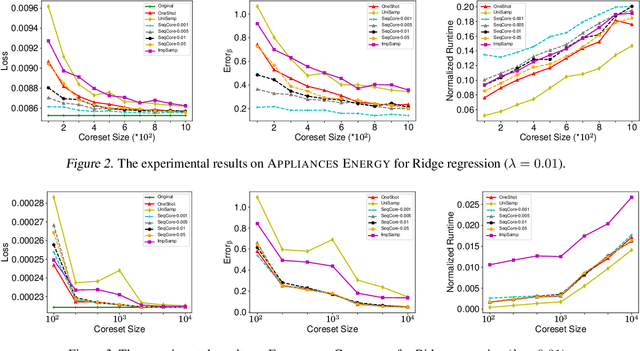
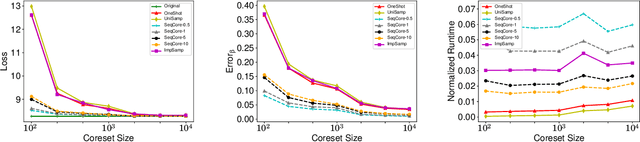
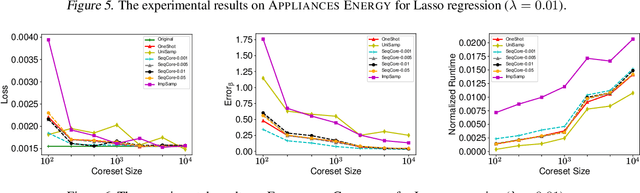
A wide range of optimization problems arising in machine learning can be solved by gradient descent algorithms, and a central question in this area is how to efficiently compress a large-scale dataset so as to reduce the computational complexity. {\em Coreset} is a popular data compression technique that has been extensively studied before. However, most of existing coreset methods are problem-dependent and cannot be used as a general tool for a broader range of applications. A key obstacle is that they often rely on the pseudo-dimension and total sensitivity bound that can be very high or hard to obtain. In this paper, based on the ''locality'' property of gradient descent algorithms, we propose a new framework, termed ''sequential coreset'', which effectively avoids these obstacles. Moreover, our method is particularly suitable for sparse optimization whence the coreset size can be further reduced to be only poly-logarithmically dependent on the dimension. In practice, the experimental results suggest that our method can save a large amount of running time compared with the baseline algorithms.
WaveTransformer: A Novel Architecture for Audio Captioning Based on Learning Temporal and Time-Frequency Information
Oct 21, 2020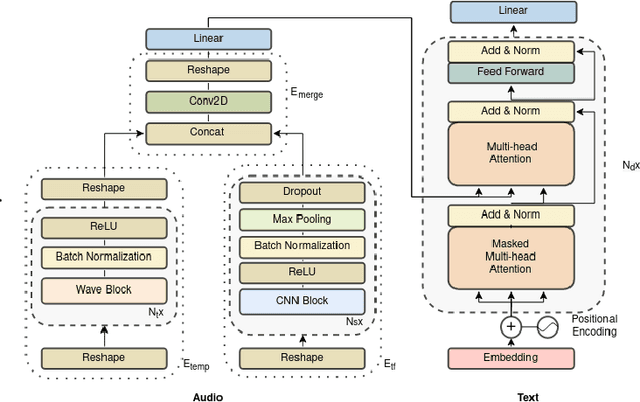

Automated audio captioning (AAC) is a novel task, where a method takes as an input an audio sample and outputs a textual description (i.e. a caption) of its contents. Most AAC methods are adapted from from image captioning of machine translation fields. In this work we present a novel AAC novel method, explicitly focused on the exploitation of the temporal and time-frequency patterns in audio. We employ three learnable processes for audio encoding, two for extracting the local and temporal information, and one to merge the output of the previous two processes. To generate the caption, we employ the widely used Transformer decoder. We assess our method utilizing the freely available splits of Clotho dataset. Our results increase previously reported highest SPIDEr to 17.3, from 16.2.
Faster Nearest Neighbor Machine Translation
Dec 15, 2021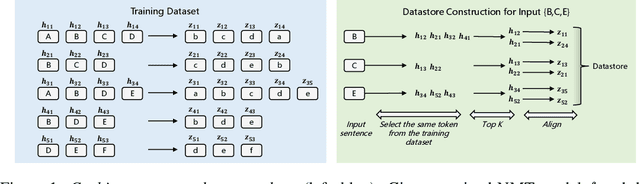


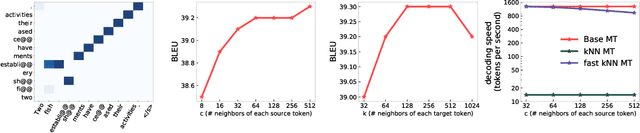
$k$NN based neural machine translation ($k$NN-MT) has achieved state-of-the-art results in a variety of MT tasks. One significant shortcoming of $k$NN-MT lies in its inefficiency in identifying the $k$ nearest neighbors of the query representation from the entire datastore, which is prohibitively time-intensive when the datastore size is large. In this work, we propose \textbf{Faster $k$NN-MT} to address this issue. The core idea of Faster $k$NN-MT is to use a hierarchical clustering strategy to approximate the distance between the query and a data point in the datastore, which is decomposed into two parts: the distance between the query and the center of the cluster that the data point belongs to, and the distance between the data point and the cluster center. We propose practical ways to compute these two parts in a significantly faster manner. Through extensive experiments on different MT benchmarks, we show that \textbf{Faster $k$NN-MT} is faster than Fast $k$NN-MT \citep{meng2021fast} and only slightly (1.2 times) slower than its vanilla counterpart while preserving model performance as $k$NN-MT. Faster $k$NN-MT enables the deployment of $k$NN-MT models on real-world MT services.
A Closed Loop Gradient Descent Algorithm applied to Rosenbrock's function
Aug 31, 2021
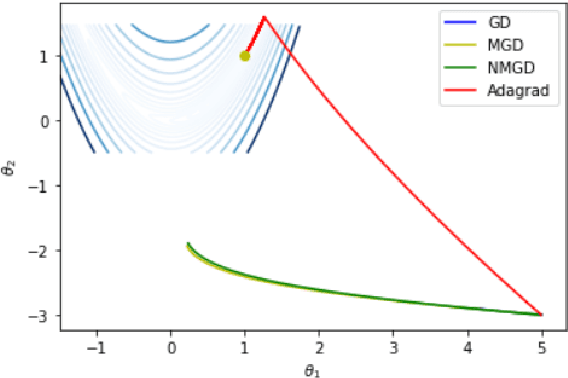
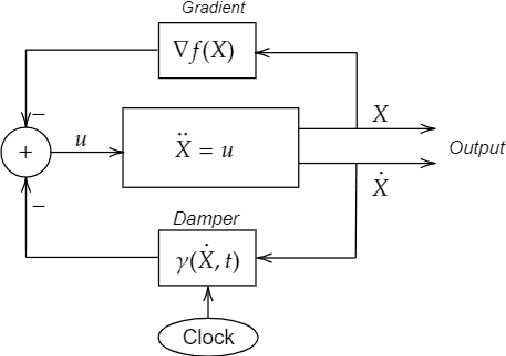
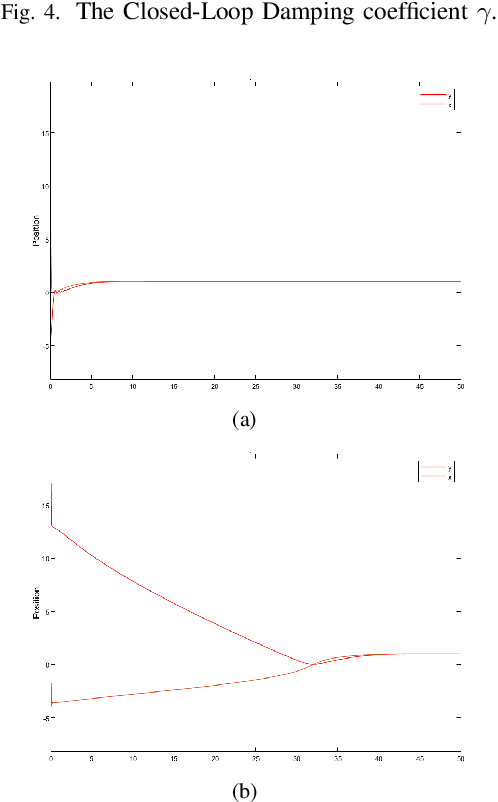
We introduce a novel adaptive damping technique for an inertial gradient system which finds application as a gradient descent algorithm for unconstrained optimisation. In an example using the non-convex Rosenbrock's function, we show an improvement on existing momentum-based gradient optimisation methods. Also using Lyapunov stability analysis, we demonstrate the performance of the continuous-time version of the algorithm. Using numerical simulations, we consider the performance of its discrete-time counterpart obtained by using the symplectic Euler method of discretisation.
Zero-Shot Image-to-Text Generation for Visual-Semantic Arithmetic
Nov 29, 2021
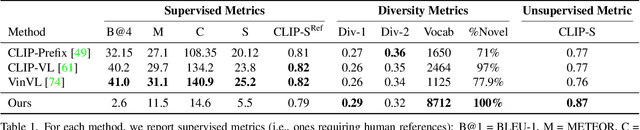
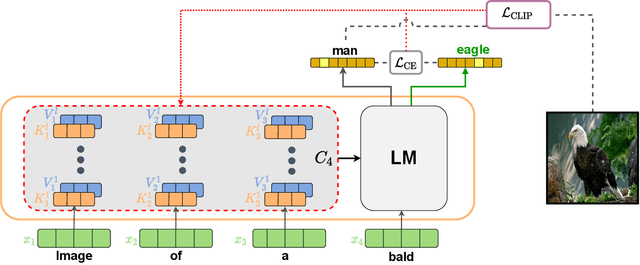

Recent text-to-image matching models apply contrastive learning to large corpora of uncurated pairs of images and sentences. While such models can provide a powerful score for matching and subsequent zero-shot tasks, they are not capable of generating caption given an image. In this work, we repurpose such models to generate a descriptive text given an image at inference time, without any further training or tuning step. This is done by combining the visual-semantic model with a large language model, benefiting from the knowledge in both web-scale models. The resulting captions are much less restrictive than those obtained by supervised captioning methods. Moreover, as a zero-shot learning method, it is extremely flexible and we demonstrate its ability to perform image arithmetic in which the inputs can be either images or text and the output is a sentence. This enables novel high-level vision capabilities such as comparing two images or solving visual analogy tests.
Implicit Neural Deformation for Multi-View Face Reconstruction
Dec 05, 2021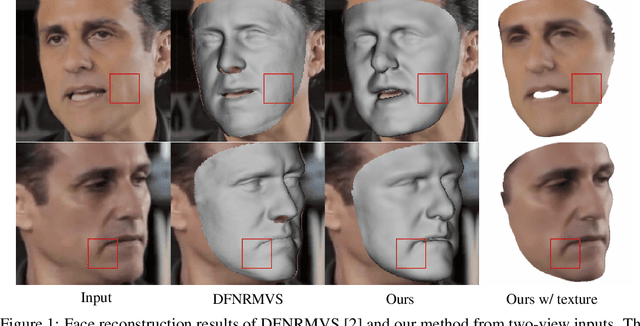
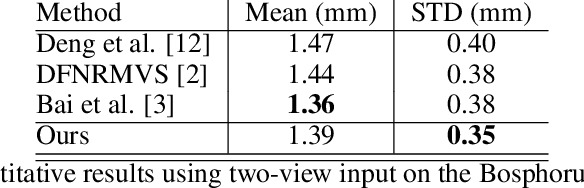

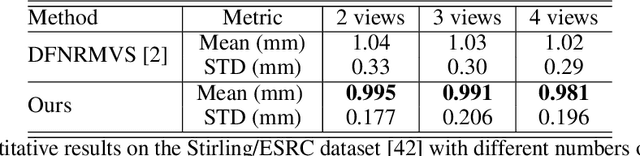
In this work, we present a new method for 3D face reconstruction from multi-view RGB images. Unlike previous methods which are built upon 3D morphable models (3DMMs) with limited details, our method leverages an implicit representation to encode rich geometric features. Our overall pipeline consists of two major components, including a geometry network, which learns a deformable neural signed distance function (SDF) as the 3D face representation, and a rendering network, which learns to render on-surface points of the neural SDF to match the input images via self-supervised optimization. To handle in-the-wild sparse-view input of the same target with different expressions at test time, we further propose residual latent code to effectively expand the shape space of the learned implicit face representation, as well as a novel view-switch loss to enforce consistency among different views. Our experimental results on several benchmark datasets demonstrate that our approach outperforms alternative baselines and achieves superior face reconstruction results compared to state-of-the-art methods.
A Review of Indoor Millimeter Wave Device-based Localization and Device-free Sensing Technologies
Dec 10, 2021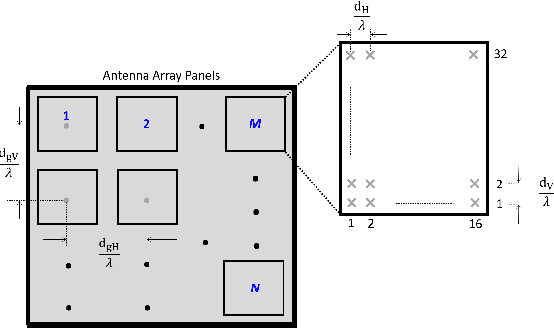
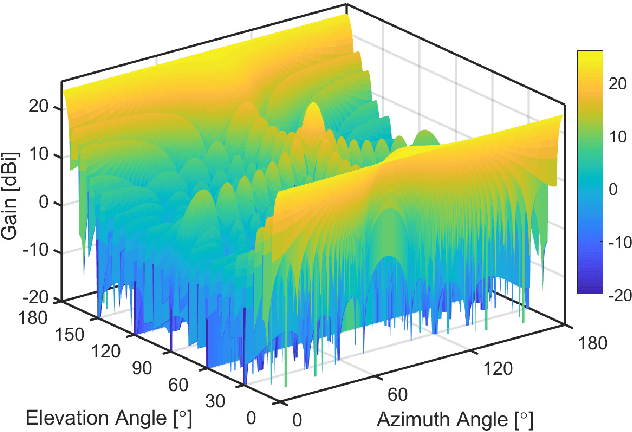
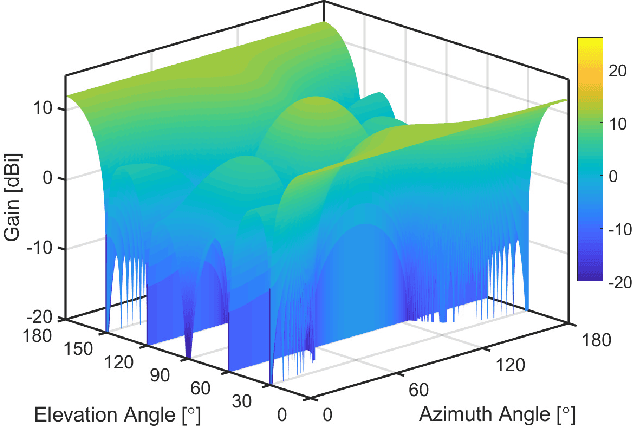
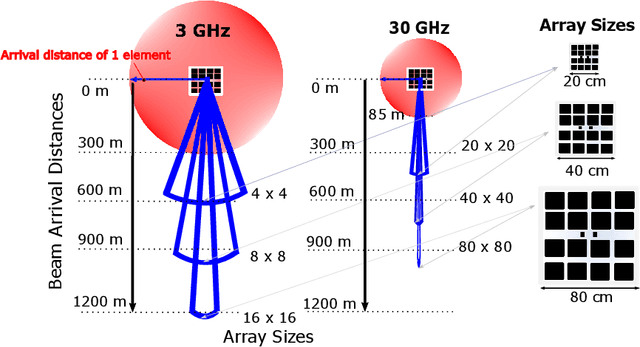
The commercial availability of low-cost millimeter wave (mmWave) communication and radar devices is starting to improve the penetration of such technologies in consumer markets, paving the way for large-scale and dense deployments in fifth-generation (5G)-and-beyond as well as 6G networks. At the same time, pervasive mmWave access will enable device localization and device-free sensing with unprecedented accuracy, especially with respect to sub-6 GHz commercial-grade devices. This paper surveys the state of the art in device-based localization and device-free sensing using mmWave communication and radar devices, with a focus on indoor deployments. We first overview key concepts about mmWave signal propagation and system design. Then, we provide a detailed account of approaches and algorithms for localization and sensing enabled by mmWaves. We consider several dimensions in our analysis, including the main objectives, techniques, and performance of each work, whether each research reached some degree of implementation, and which hardware platforms were used for this purpose. We conclude by discussing that better algorithms for consumer-grade devices, data fusion methods for dense deployments, as well as an educated application of machine learning methods are promising, relevant and timely research directions.