 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Convergence Time Optimization for Federated Learning over Wireless Networks
Jan 22, 2020
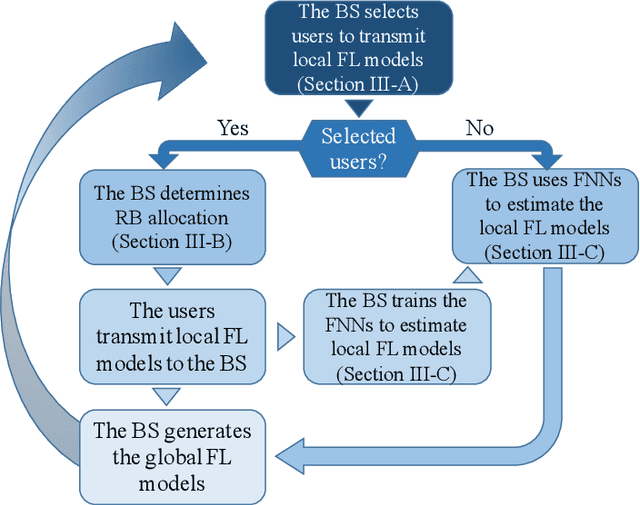
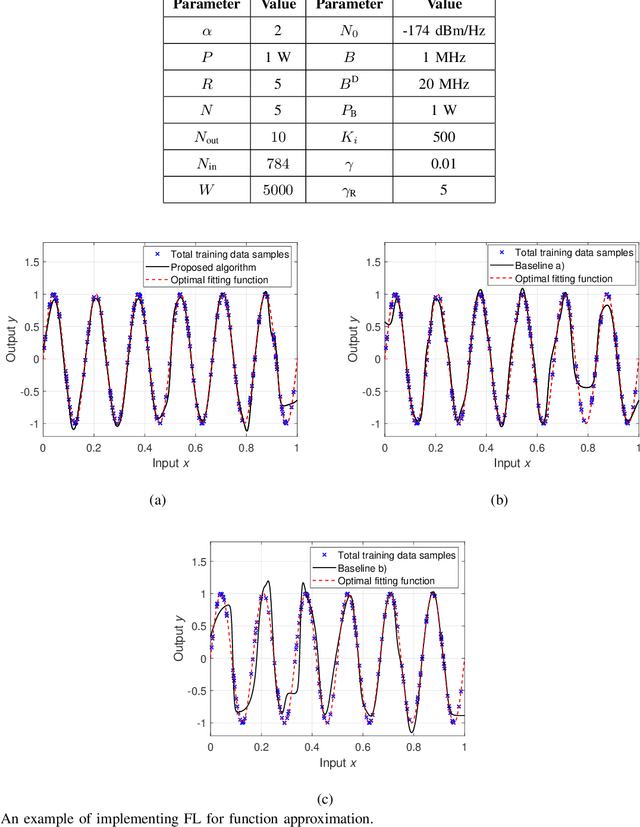

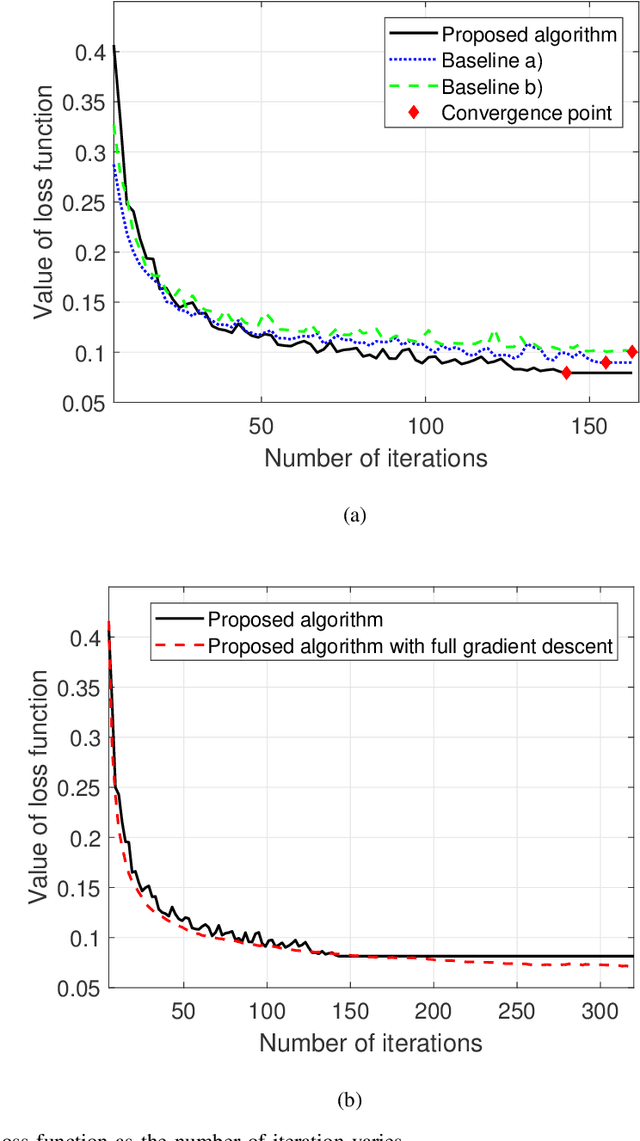
In this paper, the convergence time of federated learning (FL), when deployed over a realistic wireless network, is studied. In particular, a wireless network is considered in which wireless users transmit their local FL models (trained using their locally collected data) to a base station (BS). The BS, acting as a central controller, generates a global FL model using the received local FL models and broadcasts it back to all users. Due to the limited number of resource blocks (RBs) in a wireless network, only a subset of users can be selected to transmit their local FL model parameters to the BS at each learning step. Moreover, since each user has unique training data samples, the BS prefers to include all local user FL models to generate a converged global FL model. Hence, the FL performance and convergence time will be significantly affected by the user selection scheme. Therefore, it is necessary to design an appropriate user selection scheme that enables users of higher importance to be selected more frequently. This joint learning, wireless resource allocation, and user selection problem is formulated as an optimization problem whose goal is to minimize the FL convergence time while optimizing the FL performance. To solve this problem, a probabilistic user selection scheme is proposed such that the BS is connected to the users whose local FL models have significant effects on its global FL model with high probabilities. Given the user selection policy, the uplink RB allocation can be determined. To further reduce the FL convergence time, artificial neural networks (ANNs) are used to estimate the local FL models of the users that are not allocated any RBs for local FL model transmission at each given learning step, which enables the BS to enhance its global FL model and improve the FL convergence speed and performance.
Bounded-Memory Criteria for Streams with Application Time
Jul 30, 2020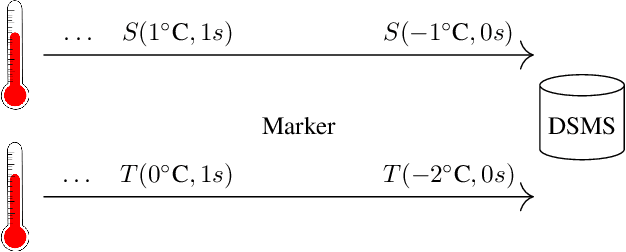
Bounded-memory computability continues to be in the focus of those areas of AI and databases that deal with feasible computations over streams---be it feasible arithmetical calculations on low-level streams or feasible query answering for declaratively specified queries on relational data streams or even feasible query answering for high-level queries on streams w.r.t. a set of constraints in an ontology such as in the paradigm of Ontology-Based Data Access (OBDA). In classical OBDA, a high-level query is answered by transforming it into a query on data source level. The transformation requires a rewriting step, where knowledge from an ontology is incorporated into the query, followed by an unfolding step with respect to a set of mappings. Given an OBDA setting it is very difficult to decide, whether and how a query can be answered efficiently. In particular it is difficult to decide whether a query can be answered in bounded memory, i.e., in constant space w.r.t. an infinitely growing prefix of a data stream. This work presents criteria for bounded-memory computability of select-project-join (SPJ) queries over streams with application time. Deciding whether an SPJ query can be answered in constant space is easier than for high-level queries, as neither an ontology nor a set of mappings are part of the input. Using the transformation process of classical OBDA, these criteria then can help deciding the efficiency of answering high-level queries on streams.
* 11 pages, 2 figures
CCasGNN: Collaborative Cascade Prediction Based on Graph Neural Networks
Dec 07, 2021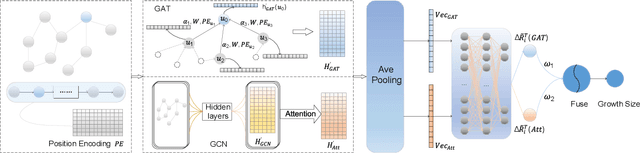
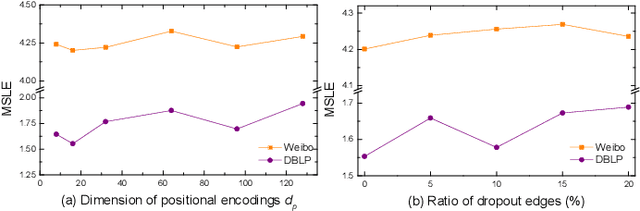
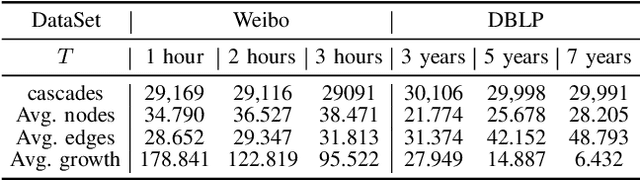
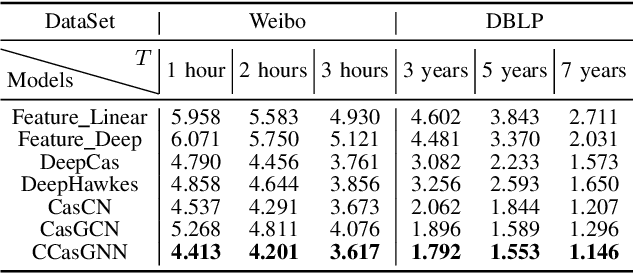
Cascade prediction aims at modeling information diffusion in the network. Most previous methods concentrate on mining either structural or sequential features from the network and the propagation path. Recent efforts devoted to combining network structure and sequence features by graph neural networks and recurrent neural networks. Nevertheless, the limitation of spectral or spatial methods restricts the improvement of prediction performance. Moreover, recurrent neural networks are time-consuming and computation-expensive, which causes the inefficiency of prediction. Here, we propose a novel method CCasGNN considering the individual profile, structural features, and sequence information. The method benefits from using a collaborative framework of GAT and GCN and stacking positional encoding into the layers of graph neural networks, which is different from all existing ones and demonstrates good performance. The experiments conducted on two real-world datasets confirm that our method significantly improves the prediction accuracy compared to state-of-the-art approaches. What's more, the ablation study investigates the contribution of each component in our method.
Stage Conscious Attention Network (SCAN) : A Demonstration-Conditioned Policy for Few-Shot Imitation
Dec 04, 2021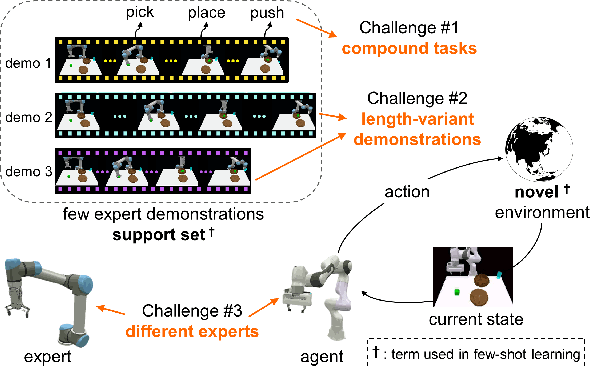

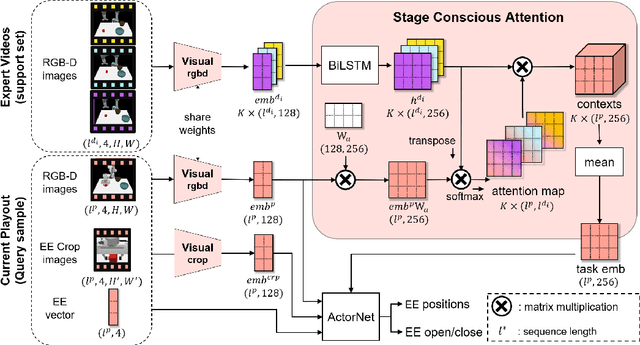
In few-shot imitation learning (FSIL), using behavioral cloning (BC) to solve unseen tasks with few expert demonstrations becomes a popular research direction. The following capabilities are essential in robotics applications: (1) Behaving in compound tasks that contain multiple stages. (2) Retrieving knowledge from few length-variant and misalignment demonstrations. (3) Learning from a different expert. No previous work can achieve these abilities at the same time. In this work, we conduct FSIL problem under the union of above settings and introduce a novel stage conscious attention network (SCAN) to retrieve knowledge from few demonstrations simultaneously. SCAN uses an attention module to identify each stage in length-variant demonstrations. Moreover, it is designed under demonstration-conditioned policy that learns the relationship between experts and agents. Experiment results show that SCAN can learn from different experts without fine-tuning and outperform baselines in complicated compound tasks with explainable visualization.
Spiking Generative Adversarial Networks With a Neural Network Discriminator: Local Training, Bayesian Models, and Continual Meta-Learning
Nov 02, 2021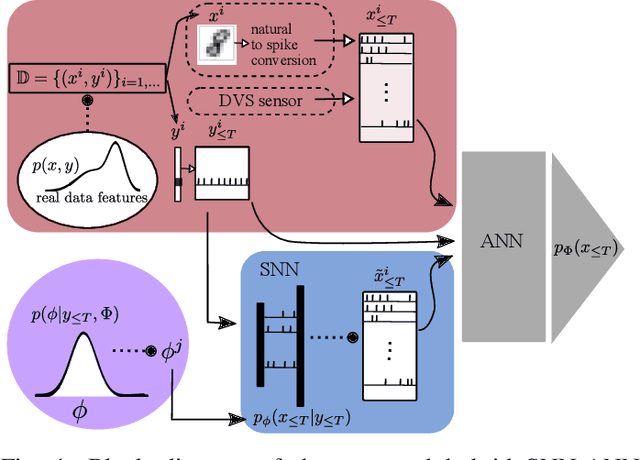
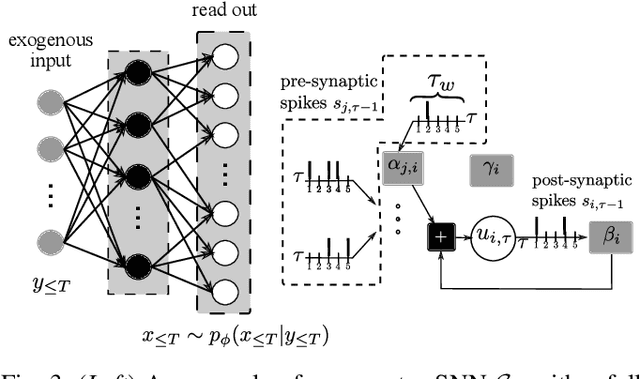
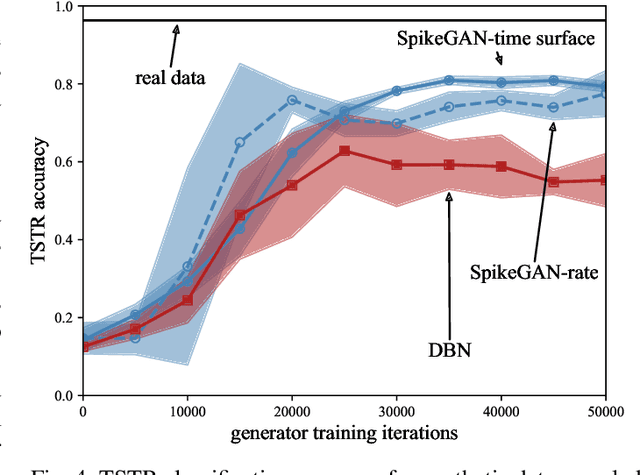
Neuromorphic data carries information in spatio-temporal patterns encoded by spikes. Accordingly, a central problem in neuromorphic computing is training spiking neural networks (SNNs) to reproduce spatio-temporal spiking patterns in response to given spiking stimuli. Most existing approaches model the input-output behavior of an SNN in a deterministic fashion by assigning each input to a specific desired output spiking sequence. In contrast, in order to fully leverage the time-encoding capacity of spikes, this work proposes to train SNNs so as to match distributions of spiking signals rather than individual spiking signals. To this end, the paper introduces a novel hybrid architecture comprising a conditional generator, implemented via an SNN, and a discriminator, implemented by a conventional artificial neural network (ANN). The role of the ANN is to provide feedback during training to the SNN within an adversarial iterative learning strategy that follows the principle of generative adversarial network (GANs). In order to better capture multi-modal spatio-temporal distribution, the proposed approach -- termed SpikeGAN -- is further extended to support Bayesian learning of the generator's weight. Finally, settings with time-varying statistics are addressed by proposing an online meta-learning variant of SpikeGAN. Experiments bring insights into the merits of the proposed approach as compared to existing solutions based on (static) belief networks and maximum likelihood (or empirical risk minimization).
Interpretable AI forecasting for numerical relativity waveforms of quasi-circular, spinning, non-precessing binary black hole mergers
Oct 13, 2021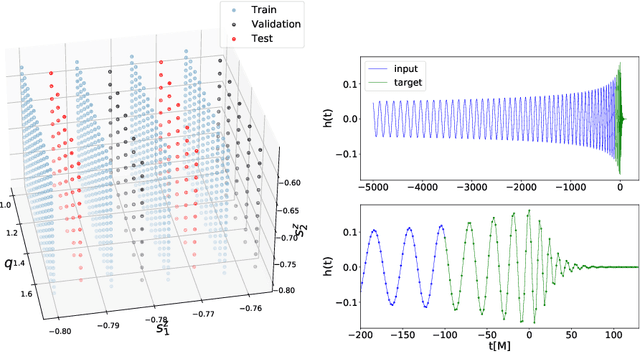
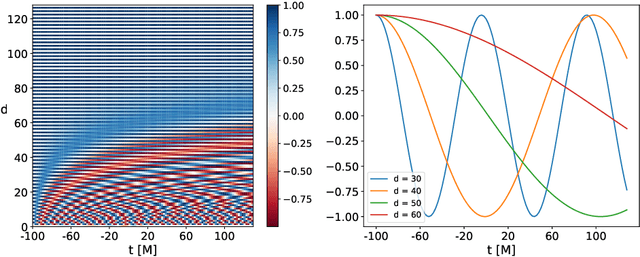
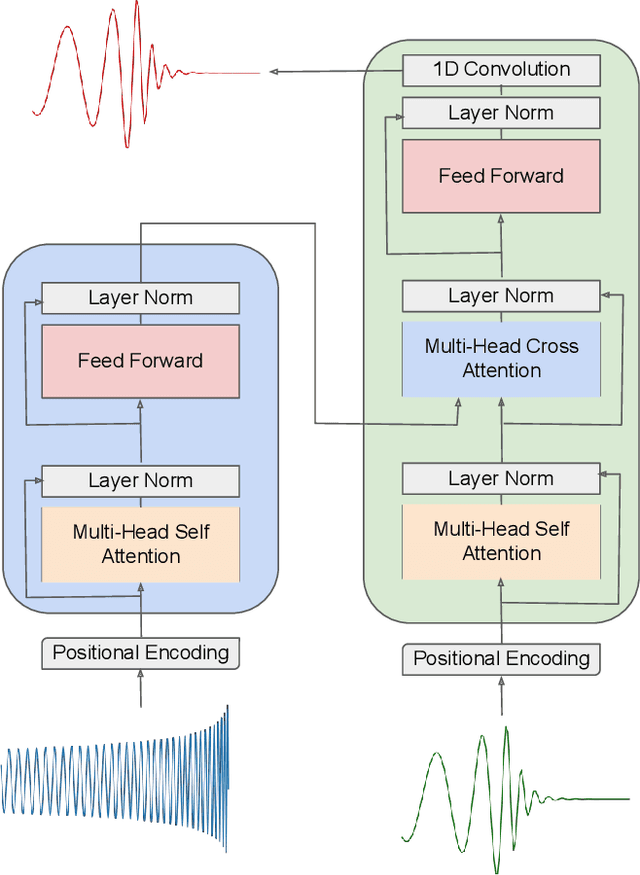
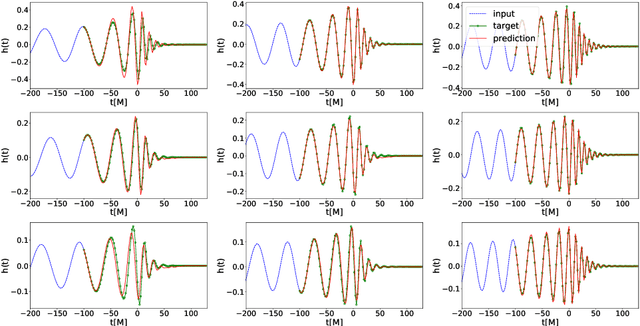
We present a deep-learning artificial intelligence model that is capable of learning and forecasting the late-inspiral, merger and ringdown of numerical relativity waveforms that describe quasi-circular, spinning, non-precessing binary black hole mergers. We used the NRHybSur3dq8 surrogate model to produce train, validation and test sets of $\ell=|m|=2$ waveforms that cover the parameter space of binary black hole mergers with mass-ratios $q\leq8$ and individual spins $|s^z_{\{1,2\}}| \leq 0.8$. These waveforms cover the time range $t\in[-5000\textrm{M}, 130\textrm{M}]$, where $t=0M$ marks the merger event, defined as the maximum value of the waveform amplitude. We harnessed the ThetaGPU supercomputer at the Argonne Leadership Computing Facility to train our AI model using a training set of 1.5 million waveforms. We used 16 NVIDIA DGX A100 nodes, each consisting of 8 NVIDIA A100 Tensor Core GPUs and 2 AMD Rome CPUs, to fully train our model within 3.5 hours. Our findings show that artificial intelligence can accurately forecast the dynamical evolution of numerical relativity waveforms in the time range $t\in[-100\textrm{M}, 130\textrm{M}]$. Sampling a test set of 190,000 waveforms, we find that the average overlap between target and predicted waveforms is $\gtrsim99\%$ over the entire parameter space under consideration. We also combined scientific visualization and accelerated computing to identify what components of our model take in knowledge from the early and late-time waveform evolution to accurately forecast the latter part of numerical relativity waveforms. This work aims to accelerate the creation of scalable, computationally efficient and interpretable artificial intelligence models for gravitational wave astrophysics.
Real-Time Panoptic Segmentation from Dense Detections
Dec 04, 2019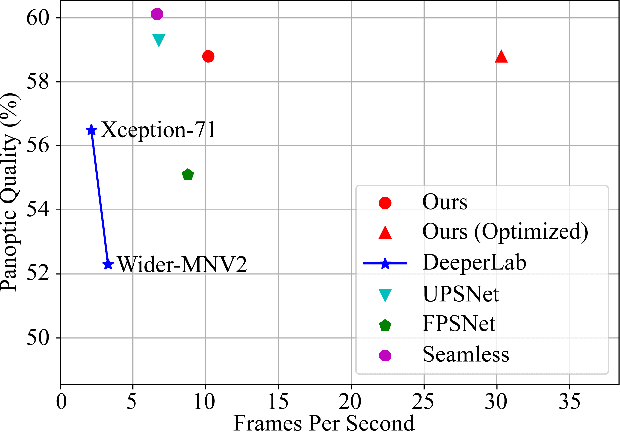
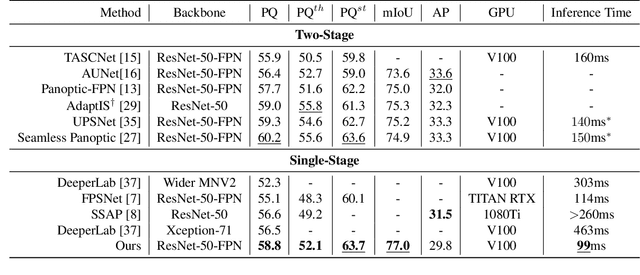
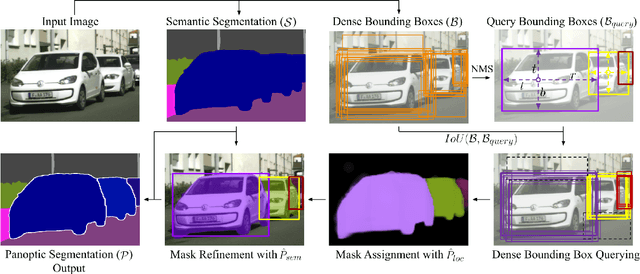
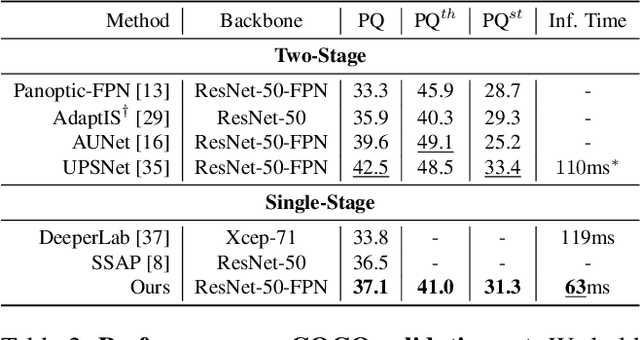
Panoptic segmentation is a complex full scene parsing task requiring simultaneous instance and semantic segmentation at high resolution. Current state-of-the-art approaches cannot run in real-time, and simplifying these architectures to improve efficiency severely degrades their accuracy. In this paper, we propose a new single-shot panoptic segmentation network that leverages dense detections and a global self-attention mechanism to operate in real-time with performance approaching the state of the art. We introduce a novel parameter-free mask construction method that substantially reduces computational complexity by efficiently reusing information from the object detection and semantic segmentation sub-tasks. The resulting network has a simple data flow that does not require feature map re-sampling or clustering post-processing, enabling significant hardware acceleration. Our experiments on the Cityscapes and COCO benchmarks show that our network works at 30 FPS on 1024x2048 resolution, trading a 3% relative performance degradation from the current state of the art for up to 440% faster inference.
Time Series Analysis and Forecasting of COVID-19 Cases Using LSTM and ARIMA Models
Jun 05, 2020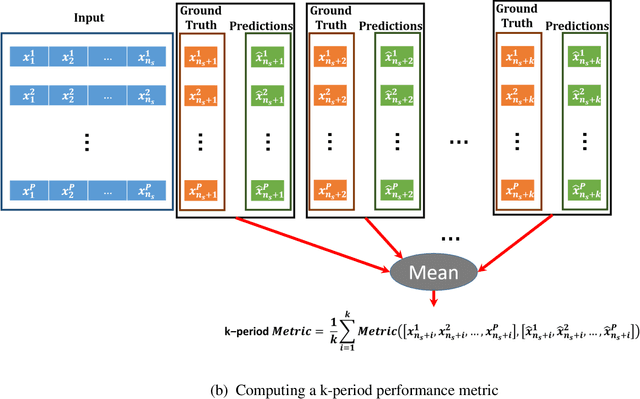
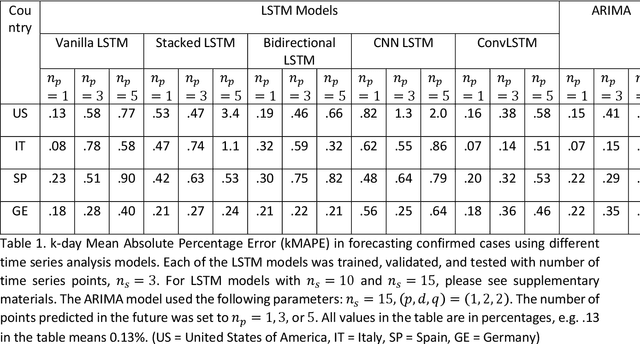
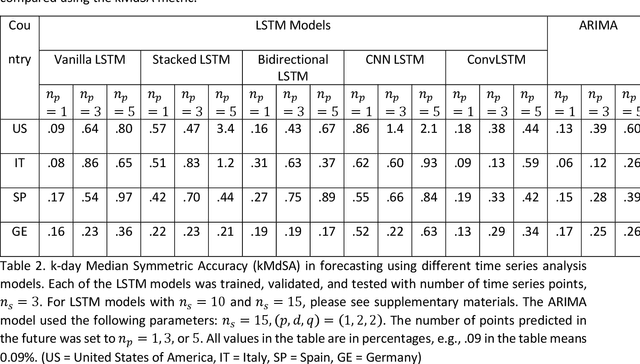
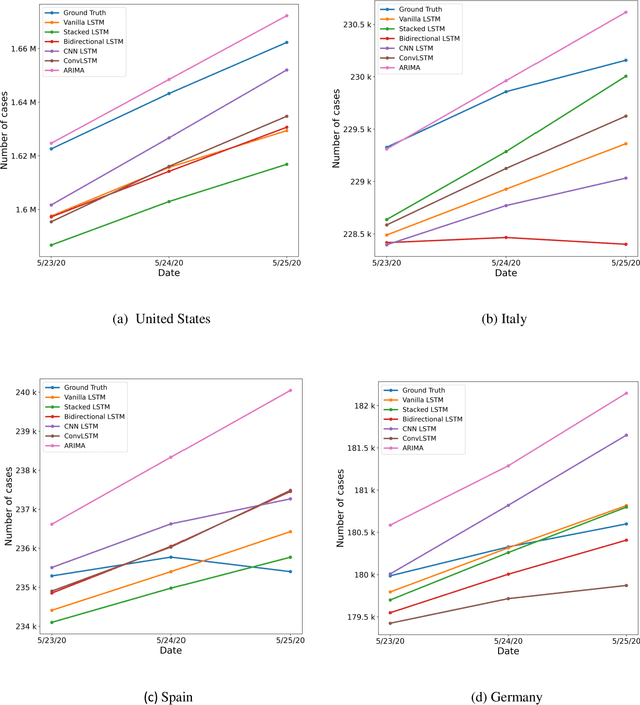
Coronavirus disease 2019 (COVID-19) is a global public health crisis that has been declared a pandemic by World Health Organization. Forecasting country-wise COVID-19 cases is necessary to help policymakers and healthcare providers prepare for the future. This study explores the performance of several Long Short-Term Memory (LSTM) models and Auto-Regressive Integrated Moving Average (ARIMA) model in forecasting the number of confirmed COVID-19 cases. Time series of daily cumulative COVID-19 cases were used for generating 1-day, 3-day, and 5-day forecasts using several LSTM models and ARIMA. Two novel k-period performance metrics - k-day Mean Absolute Percentage Error (kMAPE) and k-day Median Symmetric Accuracy (kMdSA) - were developed for evaluating the performance of the models in forecasting time series values for multiple days. Errors in prediction using kMAPE and kMdSA for LSTM models were both as low as 0.05%, while those for ARIMA were 0.07% and 0.06% respectively. LSTM models slightly underestimated while ARIMA slightly overestimated the numbers in the forecasts. The performance of LSTM models is comparable to ARIMA in forecasting COVID-19 cases. While ARIMA requires longer sequences, LSTMs can perform reasonably well with sequence sizes as small as 3. However, LSTMs require a large number of training samples. Further, the development of k-period performance metrics proposed is likely to be useful for performance evaluation of time series models in predicting multiple periods. Based on the k-period performance metrics proposed, both LSTMs and ARIMA are useful for time series analysis and forecasting for COVID-19.
Counteracting Dark Web Text-Based CAPTCHA with Generative Adversarial Learning for Proactive Cyber Threat Intelligence
Jan 08, 2022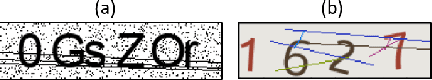
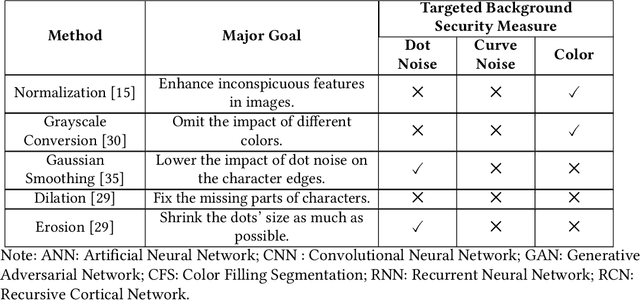
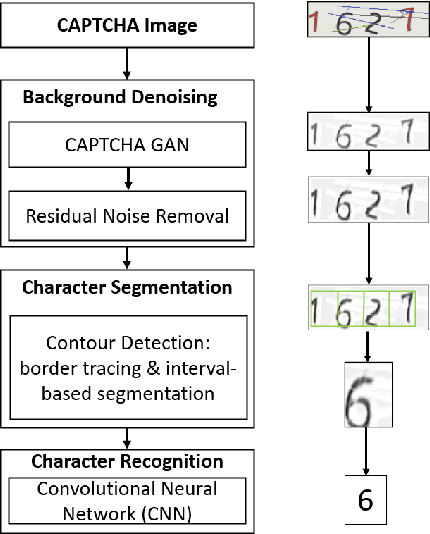
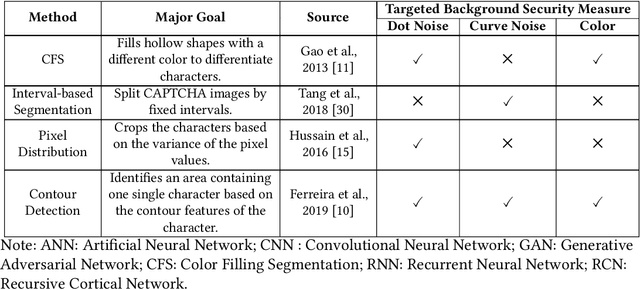
Automated monitoring of dark web (DW) platforms on a large scale is the first step toward developing proactive Cyber Threat Intelligence (CTI). While there are efficient methods for collecting data from the surface web, large-scale dark web data collection is often hindered by anti-crawling measures. In particular, text-based CAPTCHA serves as the most prevalent and prohibiting type of these measures in the dark web. Text-based CAPTCHA identifies and blocks automated crawlers by forcing the user to enter a combination of hard-to-recognize alphanumeric characters. In the dark web, CAPTCHA images are meticulously designed with additional background noise and variable character length to prevent automated CAPTCHA breaking. Existing automated CAPTCHA breaking methods have difficulties in overcoming these dark web challenges. As such, solving dark web text-based CAPTCHA has been relying heavily on human involvement, which is labor-intensive and time-consuming. In this study, we propose a novel framework for automated breaking of dark web CAPTCHA to facilitate dark web data collection. This framework encompasses a novel generative method to recognize dark web text-based CAPTCHA with noisy background and variable character length. To eliminate the need for human involvement, the proposed framework utilizes Generative Adversarial Network (GAN) to counteract dark web background noise and leverages an enhanced character segmentation algorithm to handle CAPTCHA images with variable character length. Our proposed framework, DW-GAN, was systematically evaluated on multiple dark web CAPTCHA testbeds. DW-GAN significantly outperformed the state-of-the-art benchmark methods on all datasets, achieving over 94.4% success rate on a carefully collected real-world dark web dataset...
Efficient Online Bayesian Inference for Neural Bandits
Dec 01, 2021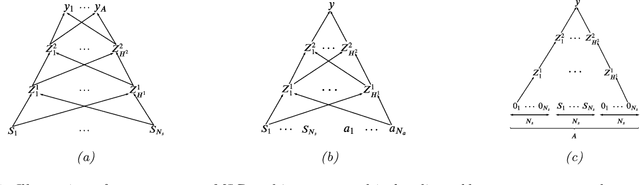
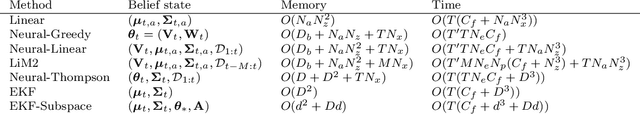
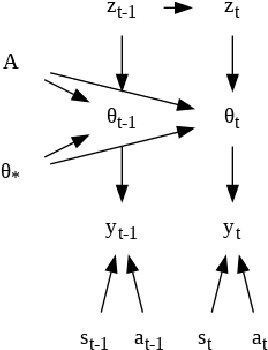
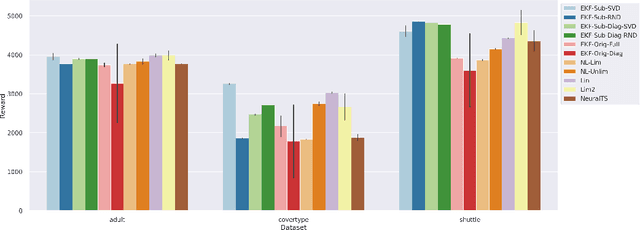
In this paper we present a new algorithm for online (sequential) inference in Bayesian neural networks, and show its suitability for tackling contextual bandit problems. The key idea is to combine the extended Kalman filter (which locally linearizes the likelihood function at each time step) with a (learned or random) low-dimensional affine subspace for the parameters; the use of a subspace enables us to scale our algorithm to models with $\sim 1M$ parameters. While most other neural bandit methods need to store the entire past dataset in order to avoid the problem of "catastrophic forgetting", our approach uses constant memory. This is possible because we represent uncertainty about all the parameters in the model, not just the final linear layer. We show good results on the "Deep Bayesian Bandit Showdown" benchmark, as well as MNIST and a recommender system.