 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
GEO-BLEU: Similarity Measure for Geospatial Sequences
Dec 14, 2021
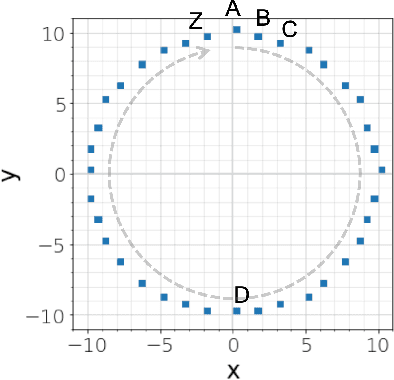

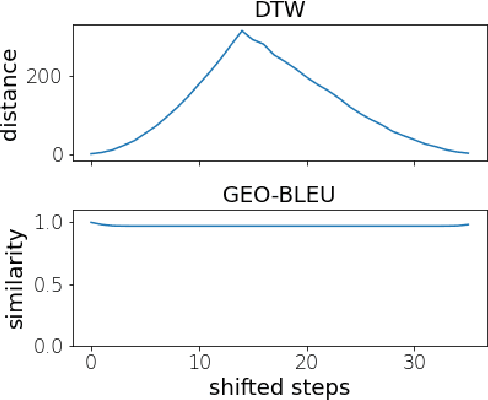
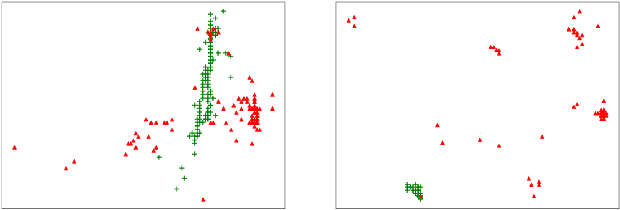
In recent geospatial research, the importance of modeling large-scale human mobility data via self-supervised learning is rising, in parallel with progress in natural language processing driven by self-supervised approaches using large-scale corpora. Whereas there are already plenty of feasible approaches applicable to geospatial sequence modeling itself, there seems to be room to improve with regard to evaluation, specifically about how to measure the similarity between generated and reference sequences. In this work, we propose a novel similarity measure, GEO-BLEU, which can be especially useful in the context of geospatial sequence modeling and generation. As the name suggests, this work is based on BLEU, one of the most popular measures used in machine translation research, while introducing spatial proximity to the idea of n-gram. We compare this measure with an established baseline, dynamic time warping, applying it to actual generated geospatial sequences. Using crowdsourced annotated data on the similarity between geospatial sequences collected from over 12,000 cases, we quantitatively and qualitatively show the proposed method's superiority.
MS-LaTTE: A Dataset of Where and When To-do Tasks are Completed
Nov 12, 2021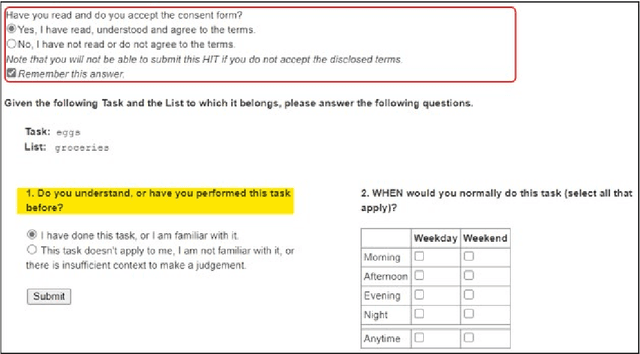
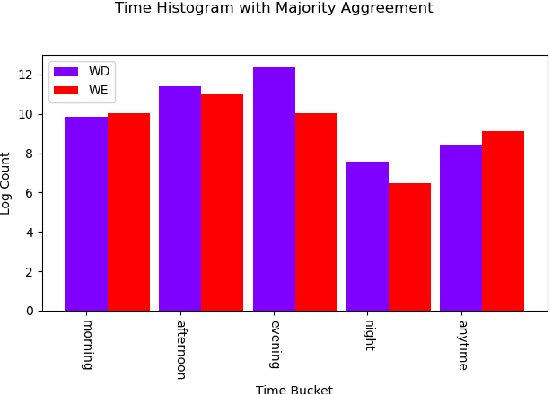
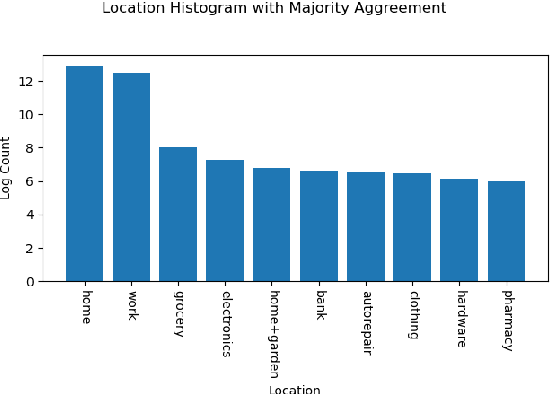
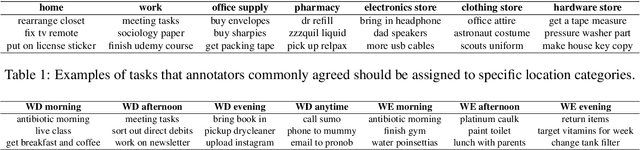
Tasks are a fundamental unit of work in the daily lives of people, who are increasingly using digital means to keep track of, organize, triage and act on them. These digital tools -- such as task management applications -- provide a unique opportunity to study and understand tasks and their connection to the real world, and through intelligent assistance, help people be more productive. By logging signals such as text, timestamp information, and social connectivity graphs, an increasingly rich and detailed picture of how tasks are created and organized, what makes them important, and who acts on them, can be progressively developed. Yet the context around actual task completion remains fuzzy, due to the basic disconnect between actions taken in the real world and telemetry recorded in the digital world. Thus, in this paper we compile and release a novel, real-life, large-scale dataset called MS-LaTTE that captures two core aspects of the context surrounding task completion: location and time. We describe our annotation framework and conduct a number of analyses on the data that were collected, demonstrating that it captures intuitive contextual properties for common tasks. Finally, we test the dataset on the two problems of predicting spatial and temporal task co-occurrence, concluding that predictors for co-location and co-time are both learnable, with a BERT fine-tuned model outperforming several other baselines. The MS-LaTTE dataset provides an opportunity to tackle many new modeling challenges in contextual task understanding and we hope that its release will spur future research in task intelligence more broadly.
SGTR: End-to-end Scene Graph Generation with Transformer
Dec 24, 2021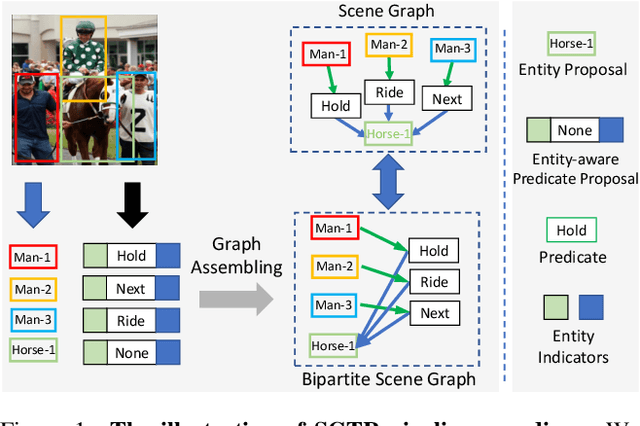

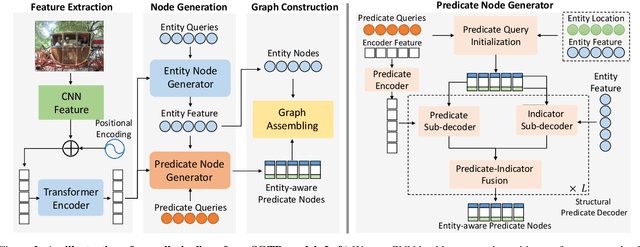

Scene Graph Generation (SGG) remains a challenging visual understanding task due to its complex compositional property. Most previous works adopt a bottom-up two-stage or a point-based one-stage approach, which often suffers from overhead time complexity or sub-optimal design assumption. In this work, we propose a novel SGG method to address the aforementioned issues, which formulates the task as a bipartite graph construction problem. To solve the problem, we develop a transformer-based end-to-end framework that first generates the entity and predicate proposal set, followed by inferring directed edges to form the relation triplets. In particular, we develop a new entity-aware predicate representation based on a structural predicate generator to leverage the compositional property of relationships. Moreover, we design a graph assembling module to infer the connectivity of the bipartite scene graph based on our entity-aware structure, enabling us to generate the scene graph in an end-to-end manner. Extensive experimental results show that our design is able to achieve the state-of-the-art or comparable performance on two challenging benchmarks, surpassing most of the existing approaches and enjoying higher efficiency in inference. We hope our model can serve as a strong baseline for the Transformer-based scene graph generation.
Construction Cost Index Forecasting: A Multi-feature Fusion Approach
Aug 18, 2021
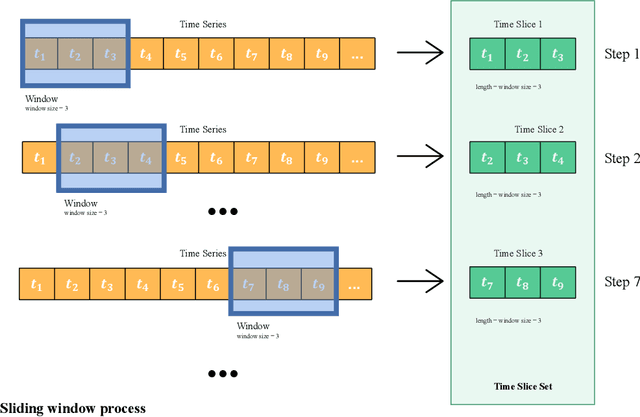

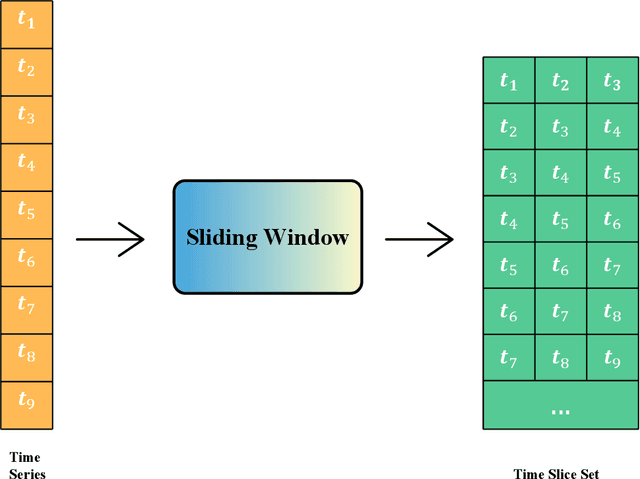
The construction cost index is an important indicator in the construction industry. Predicting CCI has great practical significance. This paper combines information fusion with machine learning, and proposes a Multi-feature Fusion framework for time series forecasting. MFF uses a sliding window algorithm and proposes a function sequence to convert the time sequence into a feature sequence for information fusion. MFF replaces the traditional information method with machine learning to achieve information fusion, which greatly improves the CCI prediction effect. MFF is of great significance to CCI and time series forecasting.
The channel-spatial attention-based vision transformer network for automated, accurate prediction of crop nitrogen status from UAV imagery
Nov 12, 2021
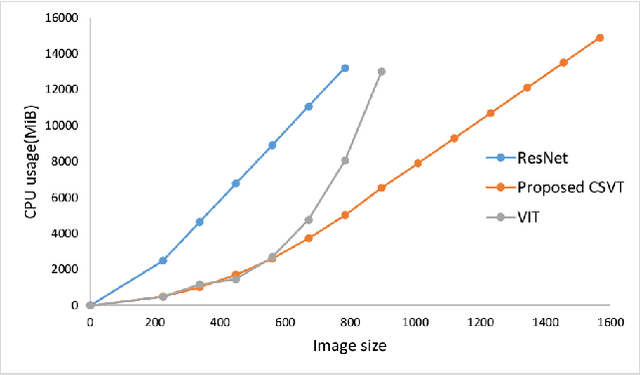
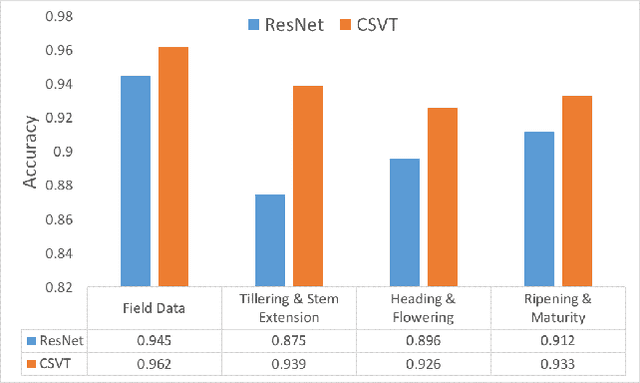
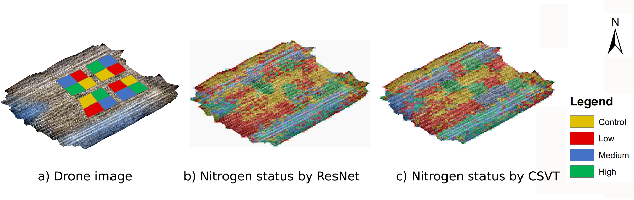
Nitrogen (N) fertiliser is routinely applied by farmers to increase crop yields. At present, farmers often over-apply N fertilizer in some locations or timepoints because they do not have high-resolution crop N status data. N-use efficiency can be low, with the remaining N lost to the environment, resulting in high production costs and environmental pollution. Accurate and timely estimation of N status in crops is crucial to improving cropping systems' economic and environmental sustainability. The conventional approaches based on tissue analysis in the laboratory for estimating N status in plants are time consuming and destructive. Recent advances in remote sensing and machine learning have shown promise in addressing the aforementioned challenges in a non-destructive way. We propose a novel deep learning framework: a channel-spatial attention-based vision transformer (CSVT) for estimating crop N status from large images collected from a UAV in a wheat field. Unlike the existing works, the proposed CSVT introduces a Channel Attention Block (CAB) and a Spatial Interaction Block (SIB), which allows capturing nonlinear characteristics of spatial-wise and channel-wise features from UAV digital aerial imagery, for accurate N status prediction in wheat crops. Moreover, since acquiring labeled data is time consuming and costly, local-to-global self-supervised learning is introduced to pre-train the CSVT with extensive unlabelled data. The proposed CSVT has been compared with the state-of-the-art models, tested and validated on both testing and independent datasets. The proposed approach achieved high accuracy (0.96) with good generalizability and reproducibility for wheat N status estimation.
Machine Learning-based Efficient Ventricular Tachycardia Detection Model of ECG Signal
Dec 24, 2021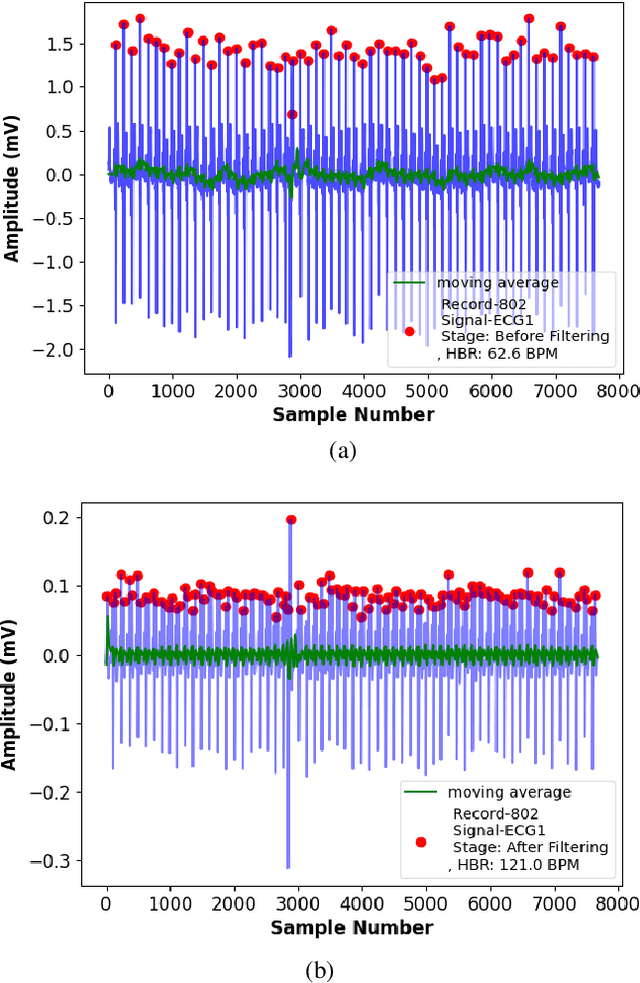
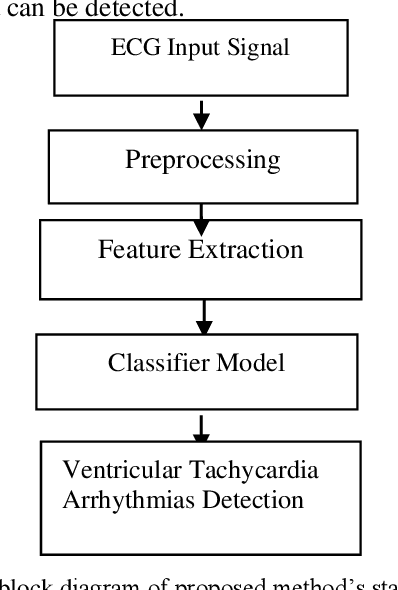
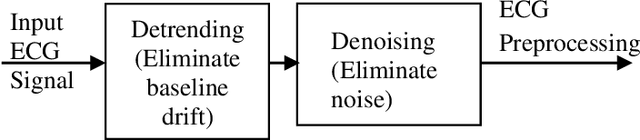
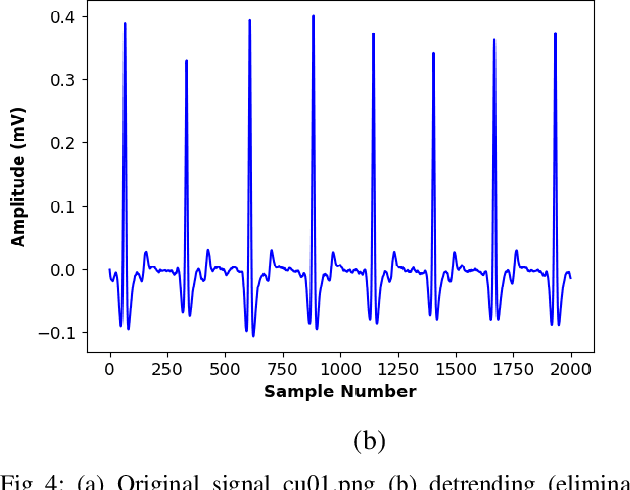
In primary diagnosis and analysis of heart defects, an ECG signal plays a significant role. This paper presents a model for the prediction of ventricular tachycardia arrhythmia using noise filtering, a unique set of ECG features, and a machine learning-based classifier model. Before signal feature extraction, we detrend and denoise the signal to eliminate the noise for detecting features properly. After that necessary features have been extracted and necessary parameters related to these features are measured. Using these parameters, we prepared one efficient multiclass classifier model using a machine learning approach that can classify different types of ventricular tachycardia arrhythmias efficiently. Our results indicate that Logistic regression and Decision tree-based models are the most efficient machine learning models for detecting ventricular tachycardia arrhythmia. In order to diagnose heart diseases and find care for a patient, an early, reliable diagnosis of different types of arrhythmia is necessary. By implementing our proposed method, this work deals with the problem of reducing the misclassification of the critical signal related to ventricular tachycardia very efficiently. Experimental findings demonstrate satisfactory enhancements and demonstrate high resilience to the algorithm that we have proposed. With this assistance, doctors can assess this type of arrhythmia of a patient early and take the right decision at the proper time.
Unsupervised Learning for Identifying High Eigenvector Centrality Nodes: A Graph Neural Network Approach
Nov 08, 2021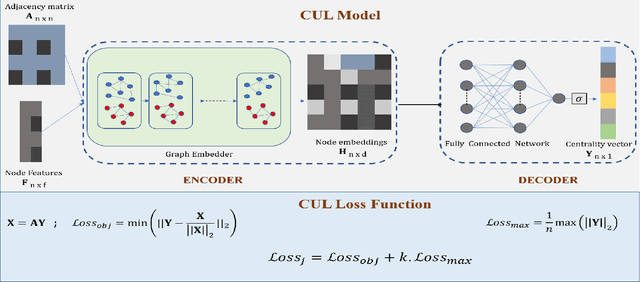
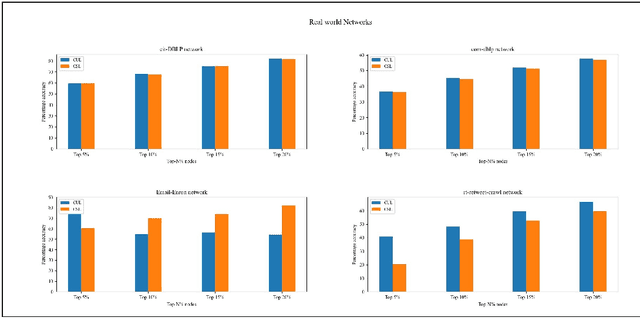

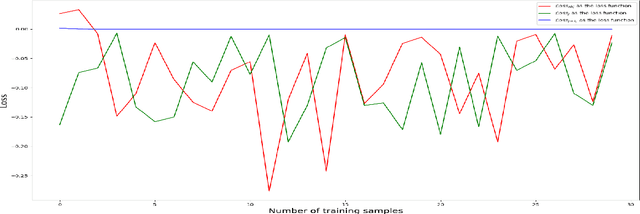
The existing methods to calculate the Eigenvector Centrality(EC) tend to not be robust enough for determination of EC in low time complexity or not well-scalable for large networks, hence rendering them practically unreliable/ computationally expensive. So, it is of the essence to develop a method that is scalable in low computational time. Hence, we propose a deep learning model for the identification of nodes with high Eigenvector Centrality. There have been a few previous works in identifying the high ranked nodes with supervised learning methods, but in real-world cases, the graphs are not labelled and hence deployment of supervised learning methods becomes a hazard and its usage becomes impractical. So, we devise CUL(Centrality with Unsupervised Learning) method to learn the relative EC scores in a network in an unsupervised manner. To achieve this, we develop an Encoder-Decoder based framework that maps the nodes to their respective estimated EC scores. Extensive experiments were conducted on different synthetic and real-world networks. We compared CUL against a baseline supervised method for EC estimation similar to some of the past works. It was observed that even with training on a minuscule number of training datasets, CUL delivers a relatively better accuracy score when identifying the higher ranked nodes than its supervised counterpart. We also show that CUL is much faster and has a smaller runtime than the conventional baseline method for EC computation. The code is available at https://github.com/codexhammer/CUL.
Fast Footstep Planning on Uneven Terrain Using Deep Sequential Models
Dec 14, 2021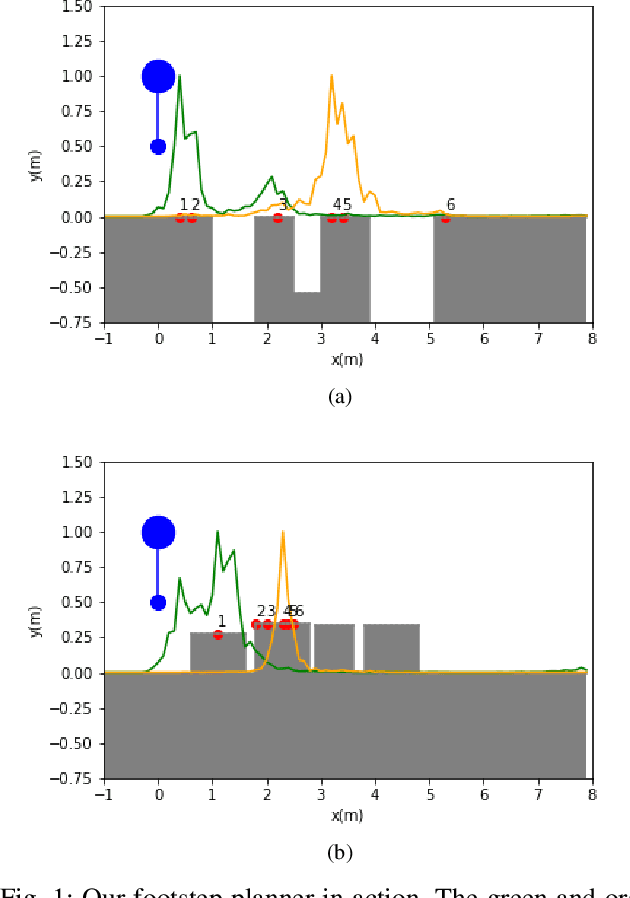
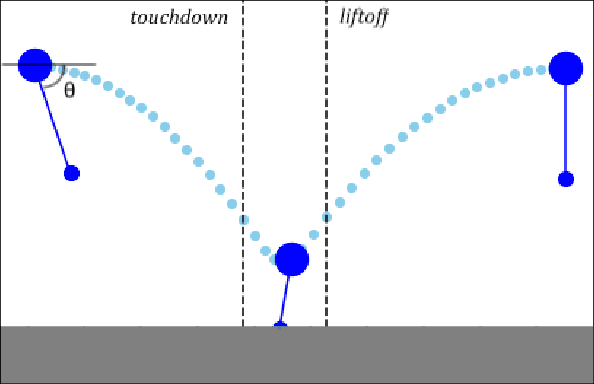
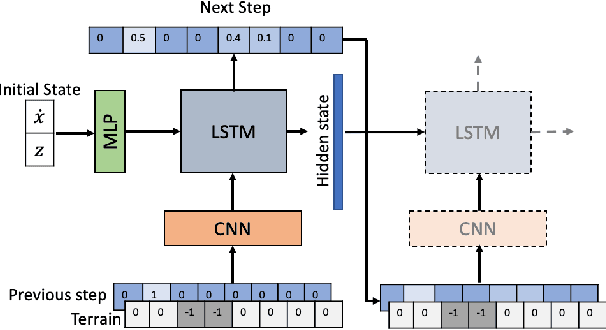
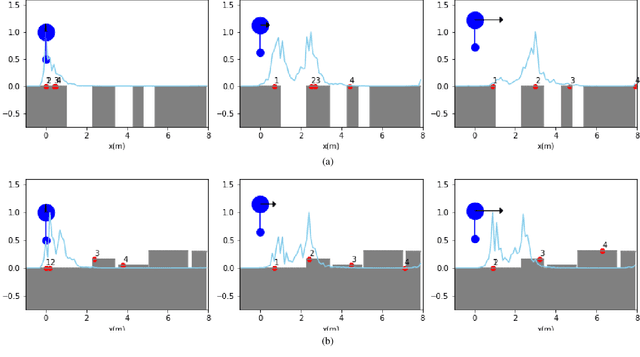
One of the fundamental challenges in realizing the potential of legged robots is generating plans to traverse challenging terrains. Control actions must be carefully selected so the robot will not crash or slip. The high dimensionality of the joint space makes directly planning low-level actions from onboard perception difficult, and control stacks that do not consider the low-level mechanisms of the robot in planning are ill-suited to handle fine-grained obstacles. One method for dealing with this is selecting footstep locations based on terrain characteristics. However, incorporating robot dynamics into footstep planning requires significant computation, much more than in the quasi-static case. In this work, we present an LSTM-based planning framework that learns probability distributions over likely footstep locations using both terrain lookahead and the robot's dynamics, and leverages the LSTM's sequential nature to find footsteps in linear time. Our framework can also be used as a module to speed up sampling-based planners. We validate our approach on a simulated one-legged hopper over a variety of uneven terrains.
Robust Parameter-Free Season Length Detection in Time Series
Nov 14, 2019
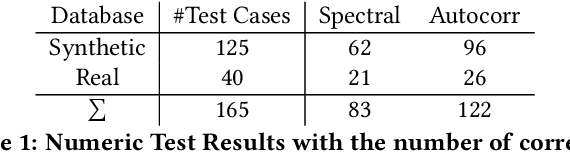

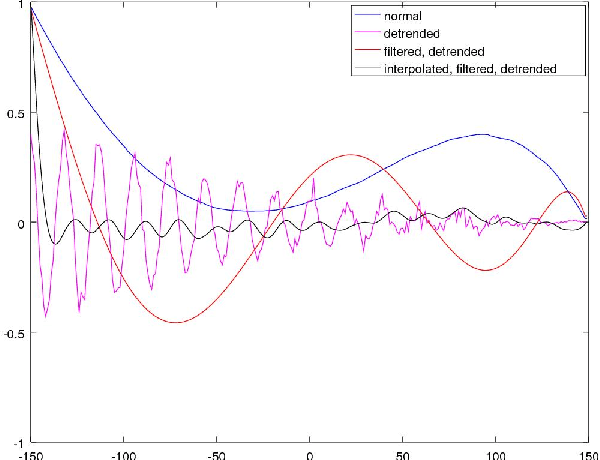
The in-depth analysis of time series has gained a lot of research interest in recent years, with the identification of periodic patterns being one important aspect. Many of the methods for identifying periodic patterns require time series' season length as input parameter. There exist only a few algorithms for automatic season length approximation. Many of these rely on simplifications such as data discretization and user defined parameters. This paper presents an algorithm for season length detection that is designed to be sufficiently reliable to be used in practical applications and does not require any input other than the time series to be analyzed. The algorithm estimates a time series' season length by interpolating, filtering and detrending the data. This is followed by analyzing the distances between zeros in the directly corresponding autocorrelation function. Our algorithm was tested against a comparable algorithm and outperformed it by passing 122 out of 165 tests, while the existing algorithm passed 83 tests. The robustness of our method can be jointly attributed to both the algorithmic approach and also to design decisions taken at the implementational level.
Path Regularization: A Convexity and Sparsity Inducing Regularization for Parallel ReLU Networks
Oct 18, 2021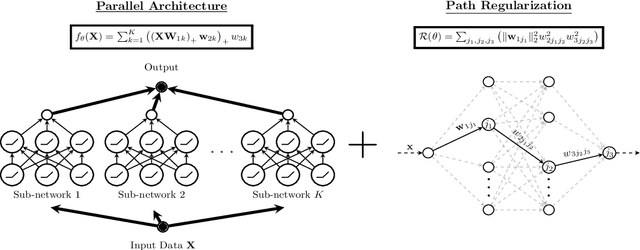

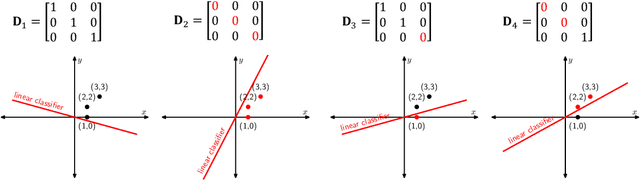
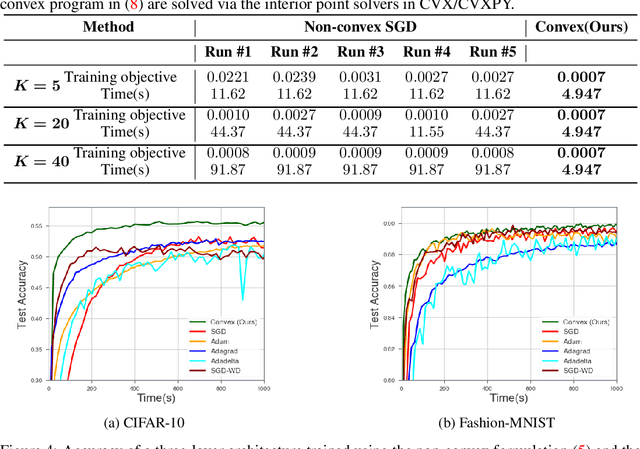
Despite several attempts, the fundamental mechanisms behind the success of deep neural networks still remain elusive. To this end, we introduce a novel analytic framework to unveil hidden convexity in training deep neural networks. We consider a parallel architecture with multiple ReLU sub-networks, which includes many standard deep architectures and ResNets as its special cases. We then show that the training problem with path regularization can be cast as a single convex optimization problem in a high-dimensional space. We further prove that the equivalent convex program is regularized via a group sparsity inducing norm. Thus, a path regularized parallel architecture with ReLU sub-networks can be viewed as a parsimonious feature selection method in high-dimensions. More importantly, we show that the computational complexity required to globally optimize the equivalent convex problem is polynomial-time with respect to the number of data samples and feature dimension. Therefore, we prove exact polynomial-time trainability for path regularized deep ReLU networks with global optimality guarantees. We also provide several numerical experiments corroborating our theory.