 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Modeling Combinatorial Evolution in Time Series Prediction
May 20, 2019
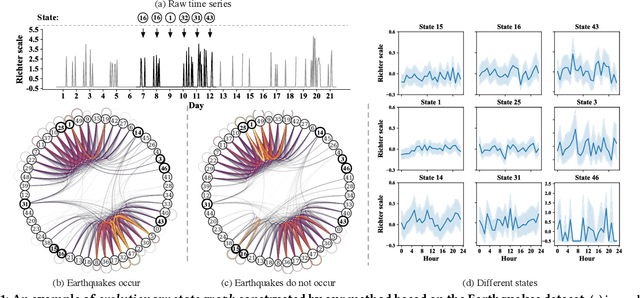
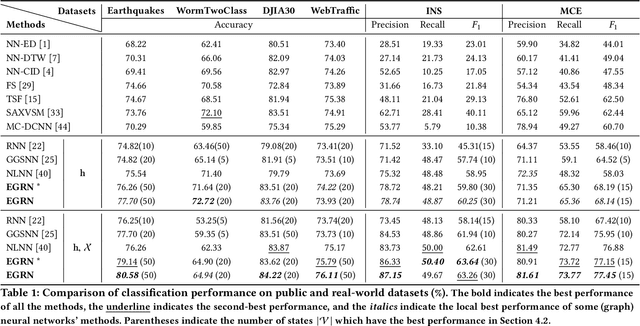
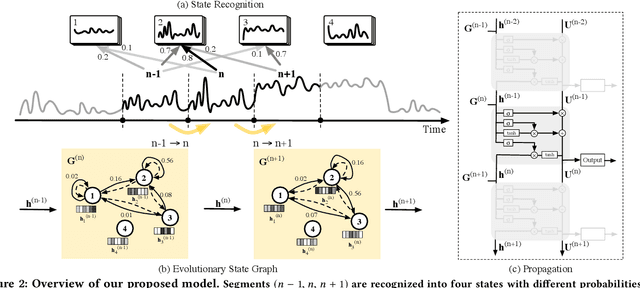
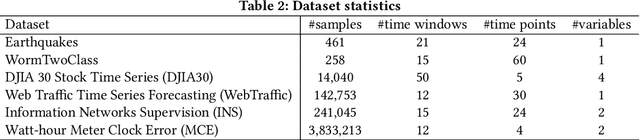
Time series modeling aims to capture the intrinsic factors underpinning observed data and its evolution. However, most existing studies ignore the evolutionary relations among these factors, which are what cause the combinatorial evolution of a given time series. In this paper, we propose to represent time-varying relations among intrinsic factors of time series data by means of an evolutionary state graph structure. Accordingly, we propose the Evolutionary Graph Recurrent Networks (EGRN) to learn representations of these factors, along with the given time series, using a graph neural network framework. The learned representations can then be applied to time series classification tasks. From our experiment results, based on six real-world datasets, it can be seen that our approach clearly outperforms ten state-of-the-art baseline methods (e.g. +5% in terms of accuracy, and +15% in terms of F1 on average). In addition, we demonstrate that due to the graph structure's improved interpretability, our method is also able to explain the logical causes of the predicted events.
DeepEdgeBench: Benchmarking Deep Neural Networks on Edge Devices
Aug 21, 2021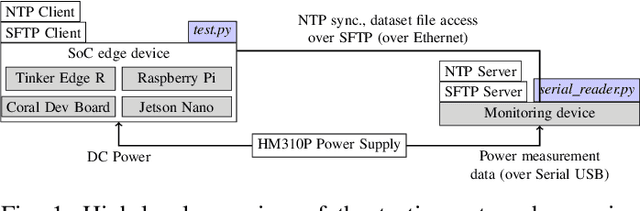
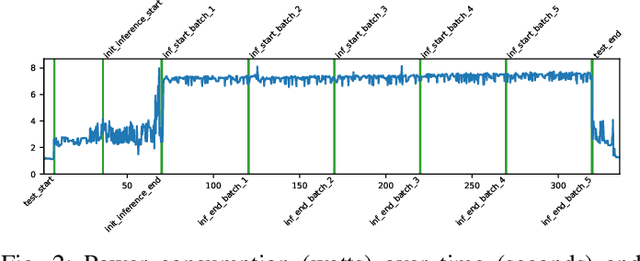

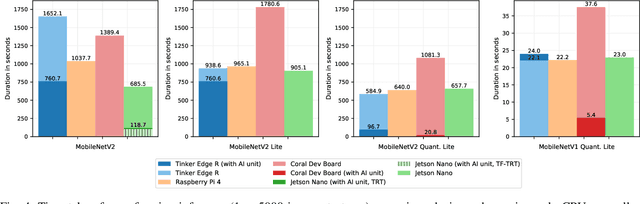
EdgeAI (Edge computing based Artificial Intelligence) has been most actively researched for the last few years to handle variety of massively distributed AI applications to meet up the strict latency requirements. Meanwhile, many companies have released edge devices with smaller form factors (low power consumption and limited resources) like the popular Raspberry Pi and Nvidia's Jetson Nano for acting as compute nodes at the edge computing environments. Although the edge devices are limited in terms of computing power and hardware resources, they are powered by accelerators to enhance their performance behavior. Therefore, it is interesting to see how AI-based Deep Neural Networks perform on such devices with limited resources. In this work, we present and compare the performance in terms of inference time and power consumption of the four Systems on a Chip (SoCs): Asus Tinker Edge R, Raspberry Pi 4, Google Coral Dev Board, Nvidia Jetson Nano, and one microcontroller: Arduino Nano 33 BLE, on different deep learning models and frameworks. We also provide a method for measuring power consumption, inference time and accuracy for the devices, which can be easily extended to other devices. Our results showcase that, for Tensorflow based quantized model, the Google Coral Dev Board delivers the best performance, both for inference time and power consumption. For a low fraction of inference computation time, i.e. less than 29.3% of the time for MobileNetV2, the Jetson Nano performs faster than the other devices.
Boosting Mobile CNN Inference through Semantic Memory
Dec 05, 2021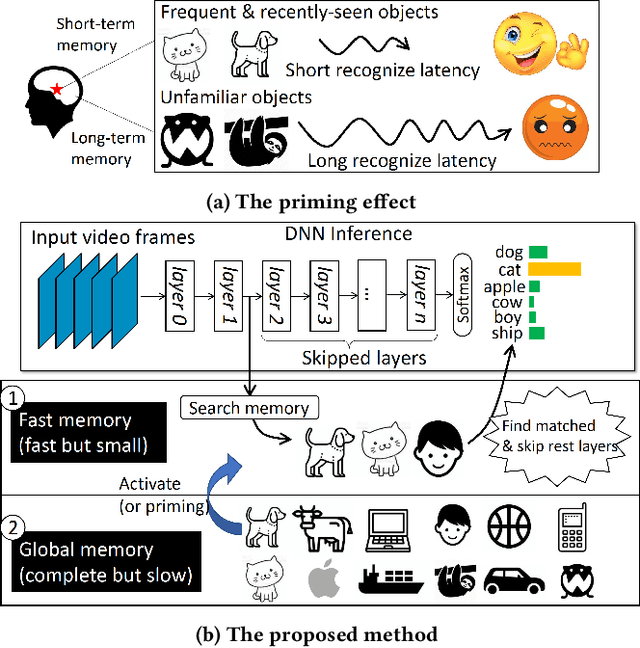
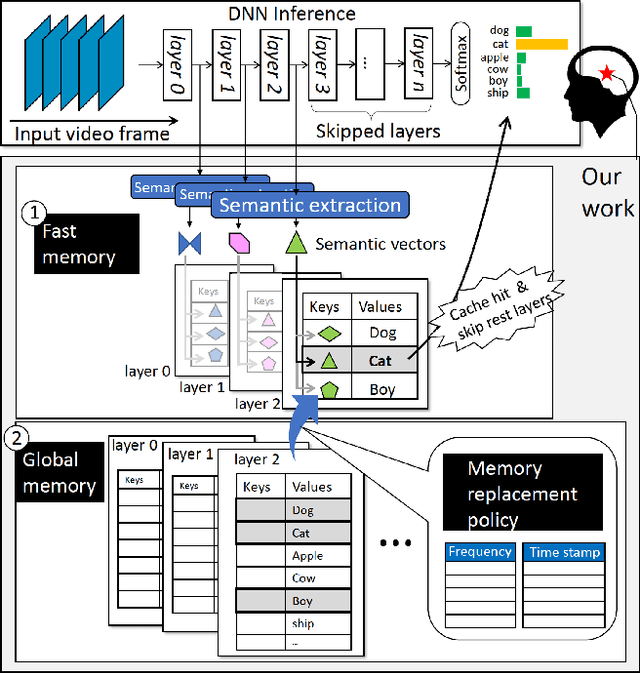
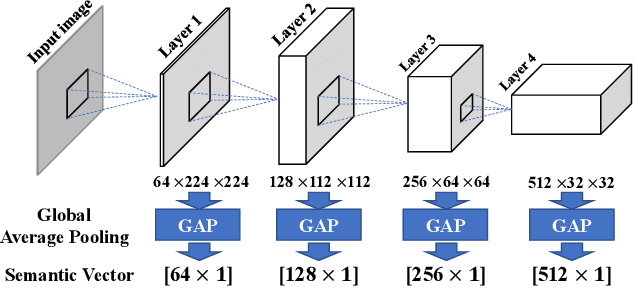
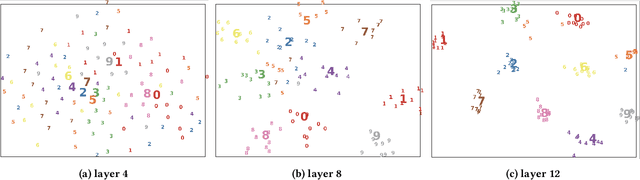
Human brains are known to be capable of speeding up visual recognition of repeatedly presented objects through faster memory encoding and accessing procedures on activated neurons. For the first time, we borrow and distill such a capability into a semantic memory design, namely SMTM, to improve on-device CNN inference. SMTM employs a hierarchical memory architecture to leverage the long-tail distribution of objects of interest, and further incorporates several novel techniques to put it into effects: (1) it encodes high-dimensional feature maps into low-dimensional, semantic vectors for low-cost yet accurate cache and lookup; (2) it uses a novel metric in determining the exit timing considering different layers' inherent characteristics; (3) it adaptively adjusts the cache size and semantic vectors to fit the scene dynamics. SMTM is prototyped on commodity CNN engine and runs on both mobile CPU and GPU. Extensive experiments on large-scale datasets and models show that SMTM can significantly speed up the model inference over standard approach (up to 2X) and prior cache designs (up to 1.5X), with acceptable accuracy loss.
UFPMP-Det: Toward Accurate and Efficient Object Detection on Drone Imagery
Dec 20, 2021
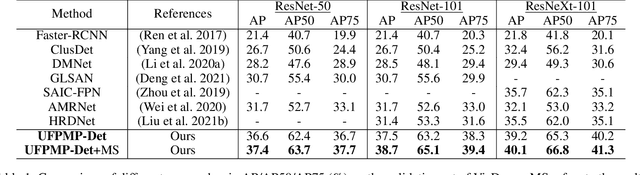
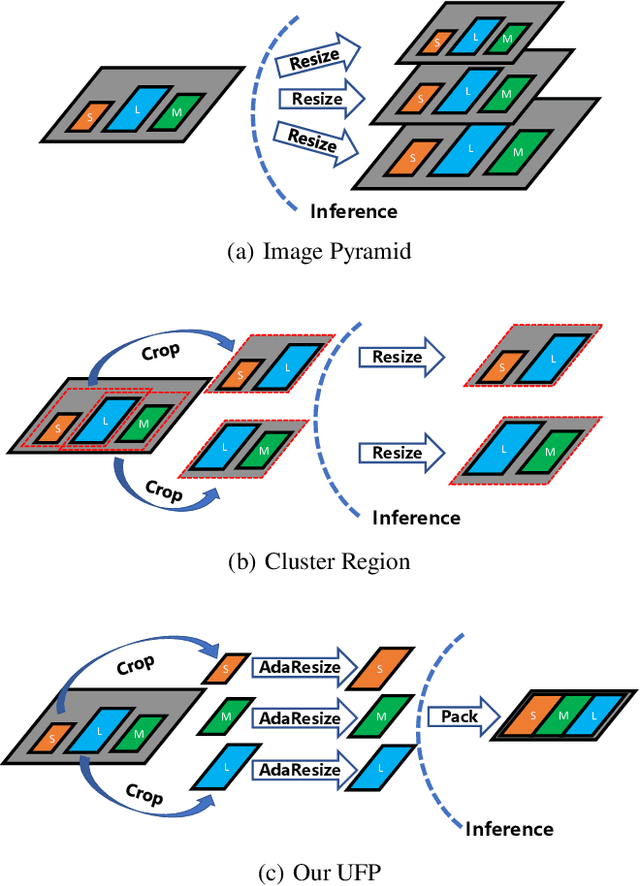
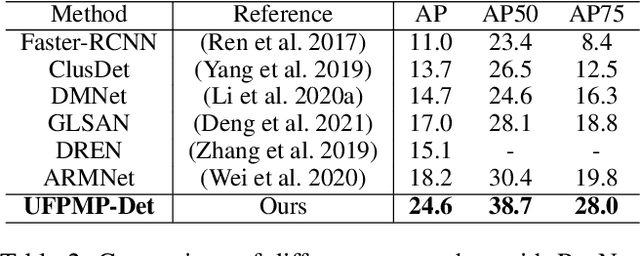
This paper proposes a novel approach to object detection on drone imagery, namely Multi-Proxy Detection Network with Unified Foreground Packing (UFPMP-Det). To deal with the numerous instances of very small scales, different from the common solution that divides the high-resolution input image into quite a number of chips with low foreground ratios to perform detection on them each, the Unified Foreground Packing (UFP) module is designed, where the sub-regions given by a coarse detector are initially merged through clustering to suppress background and the resulting ones are subsequently packed into a mosaic for a single inference, thus significantly reducing overall time cost. Furthermore, to address the more serious confusion between inter-class similarities and intra-class variations of instances, which deteriorates detection performance but is rarely discussed, the Multi-Proxy Detection Network (MP-Det) is presented to model object distributions in a fine-grained manner by employing multiple proxy learning, and the proxies are enforced to be diverse by minimizing a Bag-of-Instance-Words (BoIW) guided optimal transport loss. By such means, UFPMP-Det largely promotes both the detection accuracy and efficiency. Extensive experiments are carried out on the widely used VisDrone and UAVDT datasets, and UFPMP-Det reports new state-of-the-art scores at a much higher speed, highlighting its advantages.
Expert and Crowd-Guided Affect Annotation and Prediction
Dec 15, 2021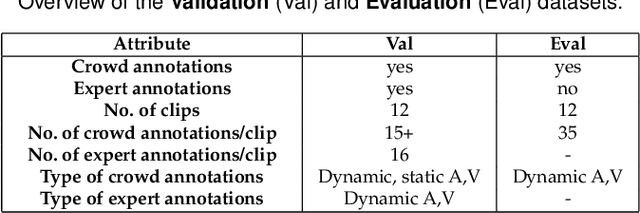
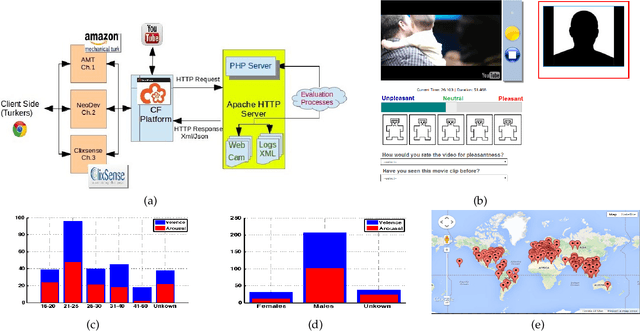

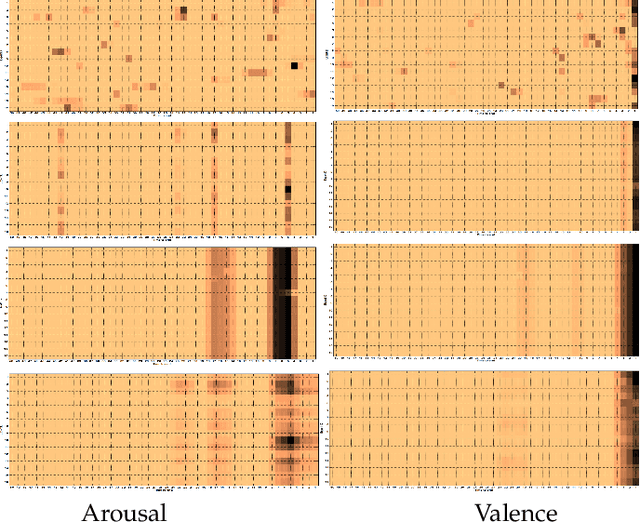
We employ crowdsourcing to acquire time-continuous affective annotations for movie clips, and refine noisy models trained from these crowd annotations incorporating expert information within a Multi-task Learning (MTL) framework. We propose a novel \textbf{e}xpert \textbf{g}uided MTL (EG-MTL) algorithm, which minimizes the loss with respect to both crowd and expert labels to learn a set of weights corresponding to each movie clip for which crowd annotations are acquired. We employ EG-MTL to solve two problems, namely, \textbf{\texttt{P1}}: where dynamic annotations acquired from both experts and crowdworkers for the \textbf{Validation} set are used to train a regression model with audio-visual clip descriptors as features, and predict dynamic arousal and valence levels on 5--15 second snippets derived from the clips; and \textbf{\texttt{P2}}: where a classification model trained on the \textbf{Validation} set using dynamic crowd and expert annotations (as features) and static affective clip labels is used for binary emotion recognition on the \textbf{Evaluation} set for which only dynamic crowd annotations are available. Observed experimental results confirm the effectiveness of the EG-MTL algorithm, which is reflected via improved arousal and valence estimation for \textbf{\texttt{P1}}, and higher recognition accuracy for \textbf{\texttt{P2}}.
Automatic Product Copywriting for E-Commerce
Dec 15, 2021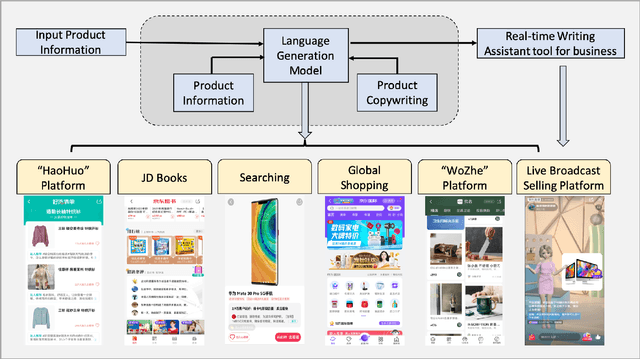

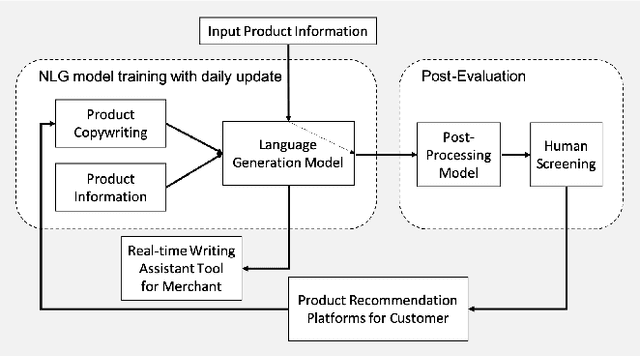
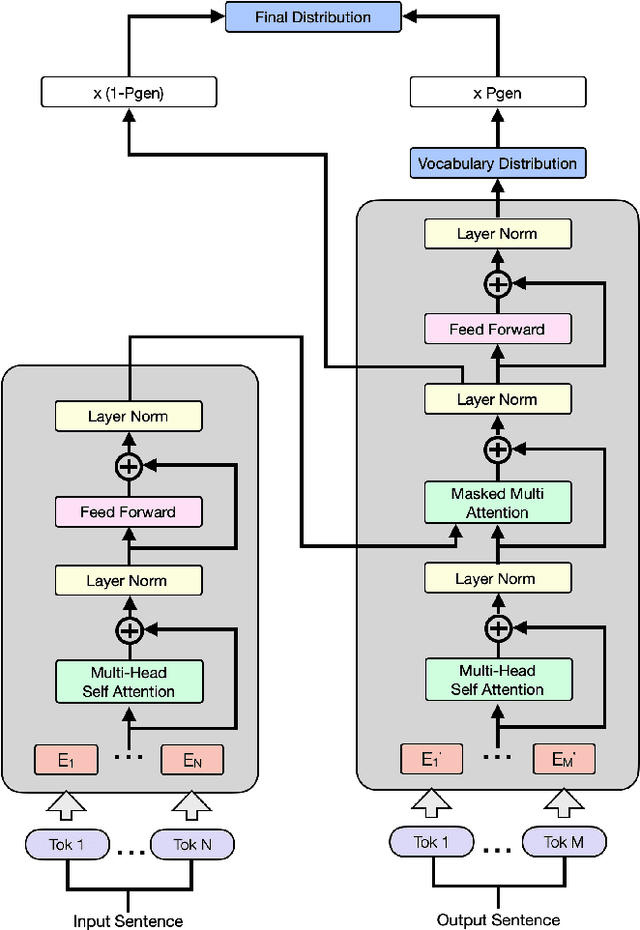
Product copywriting is a critical component of e-commerce recommendation platforms. It aims to attract users' interest and improve user experience by highlighting product characteristics with textual descriptions. In this paper, we report our experience deploying the proposed Automatic Product Copywriting Generation (APCG) system into the JD.com e-commerce product recommendation platform. It consists of two main components: 1) natural language generation, which is built from a transformer-pointer network and a pre-trained sequence-to-sequence model based on millions of training data from our in-house platform; and 2) copywriting quality control, which is based on both automatic evaluation and human screening. For selected domains, the models are trained and updated daily with the updated training data. In addition, the model is also used as a real-time writing assistant tool on our live broadcast platform. The APCG system has been deployed in JD.com since Feb 2021. By Sep 2021, it has generated 2.53 million product descriptions, and improved the overall averaged click-through rate (CTR) and the Conversion Rate (CVR) by 4.22% and 3.61%, compared to baselines, respectively on a year-on-year basis. The accumulated Gross Merchandise Volume (GMV) made by our system is improved by 213.42%, compared to the number in Feb 2021.
DSGPT: Domain-Specific Generative Pre-Training of Transformers for Text Generation in E-commerce Title and Review Summarization
Dec 15, 2021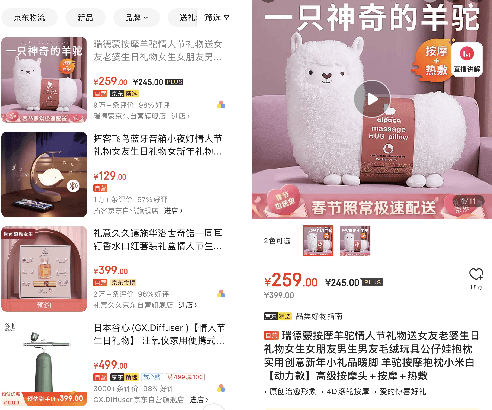
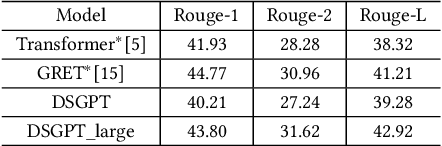
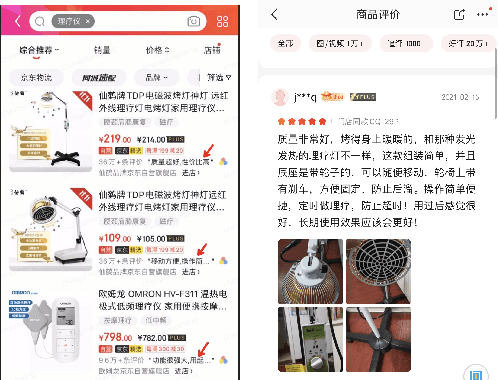
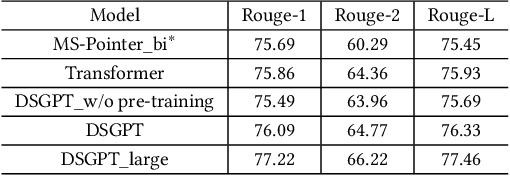
We propose a novel domain-specific generative pre-training (DS-GPT) method for text generation and apply it to the product titleand review summarization problems on E-commerce mobile display.First, we adopt a decoder-only transformer architecture, which fitswell for fine-tuning tasks by combining input and output all to-gether. Second, we demonstrate utilizing only small amount of pre-training data in related domains is powerful. Pre-training a languagemodel from a general corpus such as Wikipedia or the CommonCrawl requires tremendous time and resource commitment, andcan be wasteful if the downstream tasks are limited in variety. OurDSGPT is pre-trained on a limited dataset, the Chinese short textsummarization dataset (LCSTS). Third, our model does not requireproduct-related human-labeled data. For title summarization task,the state of art explicitly uses additional background knowledgein training and predicting stages. In contrast, our model implic-itly captures this knowledge and achieves significant improvementover other methods, after fine-tuning on the public Taobao.comdataset. For review summarization task, we utilize JD.com in-housedataset, and observe similar improvement over standard machinetranslation methods which lack the flexibility of fine-tuning. Ourproposed work can be simply extended to other domains for a widerange of text generation tasks.
SenSnake: A snake robot with contact force sensing for studying locomotion in complex 3-D terrain
Dec 15, 2021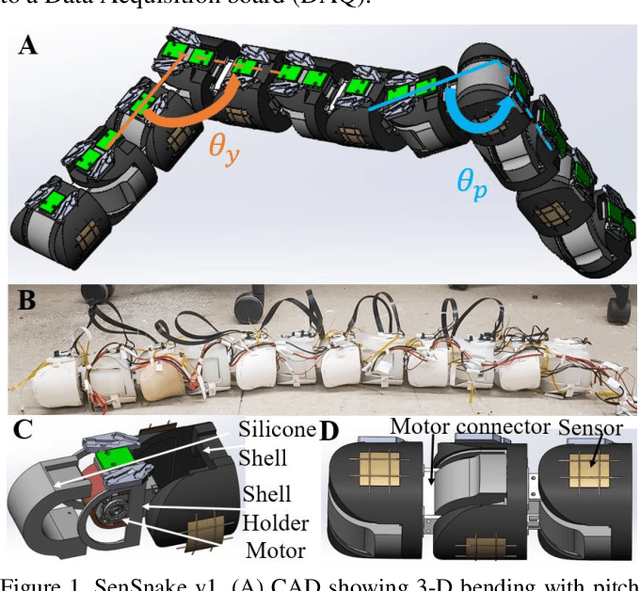
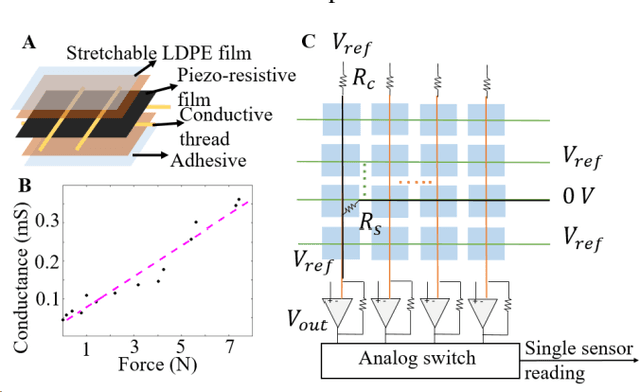
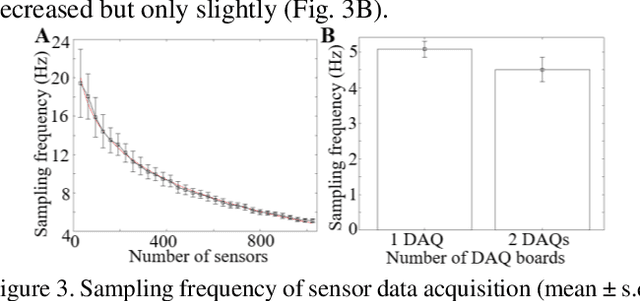
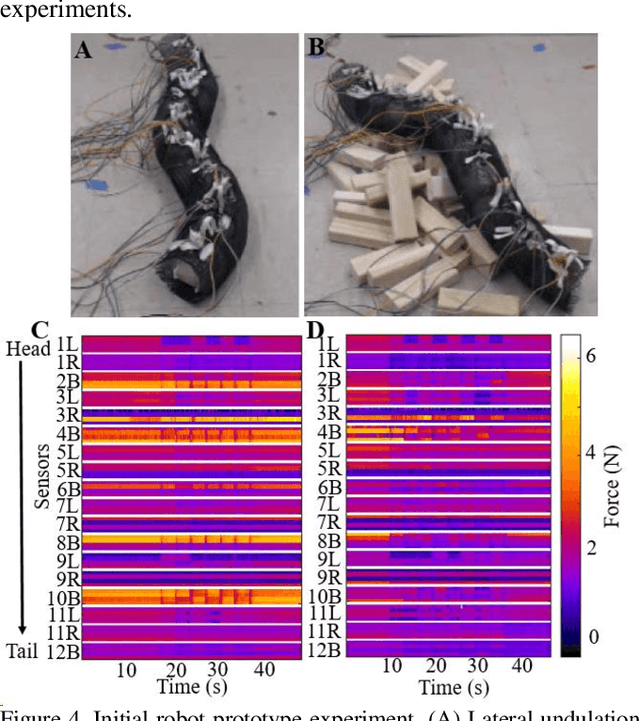
Despite advances in a diversity of environments, snake robots are still far behind snakes in traversing complex 3-D terrain with large obstacles. This is due to a lack of understanding of how to control 3-D body bending to push against terrain features to generate and control propulsion. Biological studies suggested that generalist snakes use contact force sensing to adjust body bending in real time to do so. However, studying this sensory-modulated force control in snakes is challenging, due to a lack of basic knowledge of how their force sensing organs work. Here, we take a robophysics approach to make progress, starting by developing a snake robot capable of 3-D body bending with contact force sensing to enable systematic locomotion experiments and force measurements. Through two development and testing iterations, we created a 12-segment robot with 36 piezo-resistive sheet sensors distributed on all segments with compliant shells with a sampling frequency of 30 Hz. The robot measured contact forces while traversing a large obstacle using vertical bending with high repeatability, achieving the goal of providing a platform for systematic experiments. Finally, we explored model-based calibration considering the viscoelastic behavior of the piezo-resistive sensor, which will for useful for future studies.
The Effectiveness of Discretization in Forecasting: An Empirical Study on Neural Time Series Models
May 20, 2020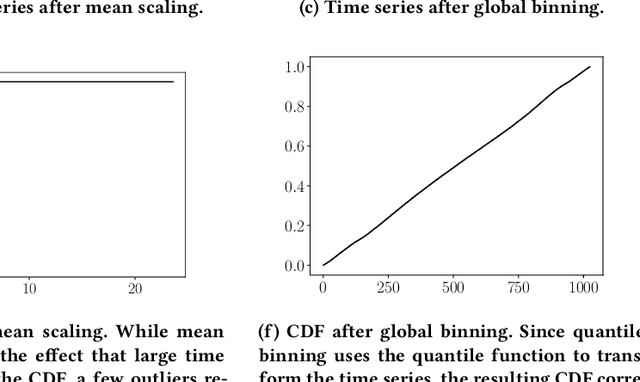
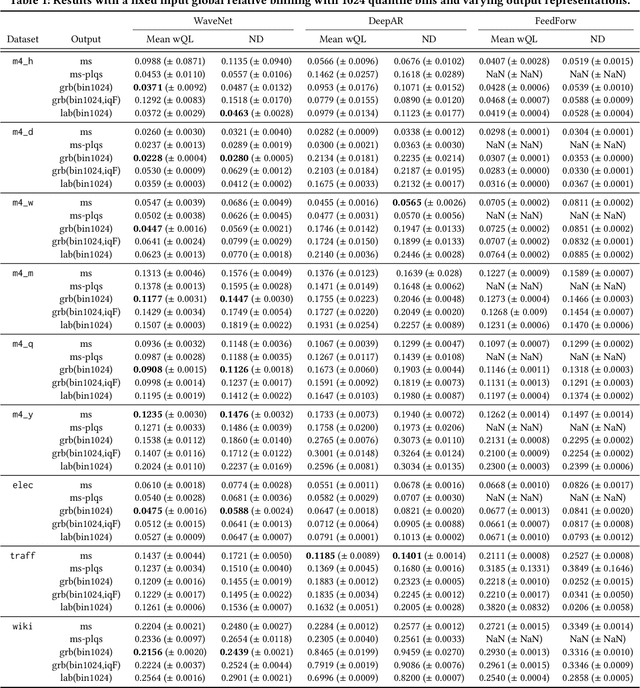
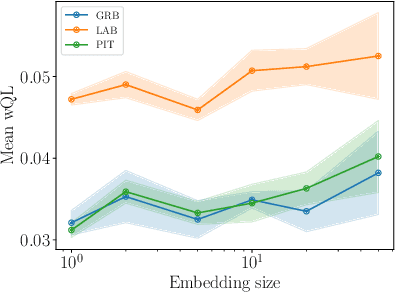
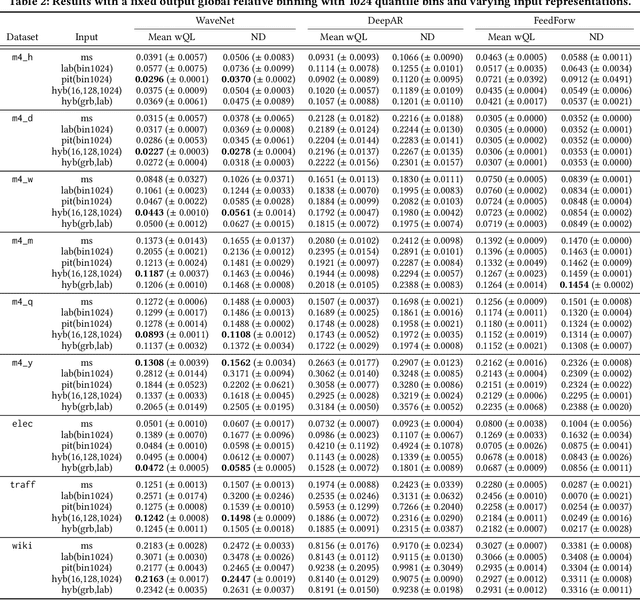
Time series modeling techniques based on deep learning have seen many advancements in recent years, especially in data-abundant settings and with the central aim of learning global models that can extract patterns across multiple time series. While the crucial importance of appropriate data pre-processing and scaling has often been noted in prior work, most studies focus on improving model architectures. In this paper we empirically investigate the effect of data input and output transformations on the predictive performance of several neural forecasting architectures. In particular, we investigate the effectiveness of several forms of data binning, i.e. converting real-valued time series into categorical ones, when combined with feed-forward, recurrent neural networks, and convolution-based sequence models. In many non-forecasting applications where these models have been very successful, the model inputs and outputs are categorical (e.g. words from a fixed vocabulary in natural language processing applications or quantized pixel color intensities in computer vision). For forecasting applications, where the time series are typically real-valued, various ad-hoc data transformations have been proposed, but have not been systematically compared. To remedy this, we evaluate the forecasting accuracy of instances of the aforementioned model classes when combined with different types of data scaling and binning. We find that binning almost always improves performance (compared to using normalized real-valued inputs), but that the particular type of binning chosen is of lesser importance.
BusTime: Which is the Right Prediction Model for My Bus Arrival Time?
Mar 20, 2020
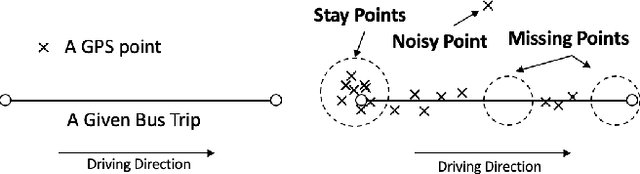
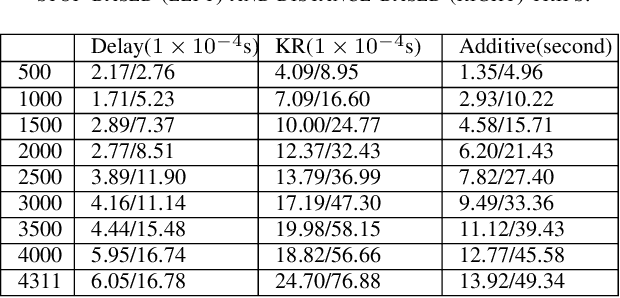
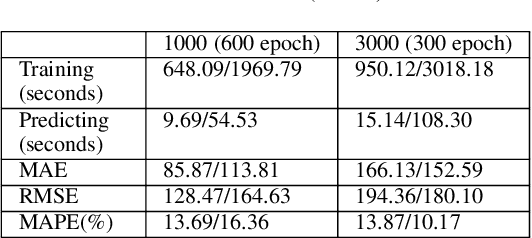
With the rise of big data technologies, many smart transportation applications have been rapidly developed in recent years including bus arrival time predictions. This type of applications help passengers to plan trips more efficiently without wasting unpredictable amount of waiting time at bus stops. Many studies focus on improving the prediction accuracy of various machine learning and statistical models, while much less work demonstrate their applicability of being deployed and used in realistic urban settings. This paper tries to fill this gap by proposing a general and practical evaluation framework for analysing various widely used prediction models (i.e. delay, k-nearest-neighbour, kernel regression, additive model, and recurrent neural network using long short term memory) for bus arrival time. In particular, this framework contains a raw bus GPS data pre-processing method that needs much less number of input data points while still maintain satisfactory prediction results. This pre-processing method enables various models to predict arrival time at bus stops only, by using a KD-tree based nearest point search method. Based on this framework, using raw bus GPS dataset in different scales from the city of Dublin, Ireland, we also present preliminary results for city managers by analysing the practical strengths and weaknesses in both training and predicting stages of commonly used prediction models.