 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Belief Space Planning in High-Dimensional State Spaces using PIVOT: Predictive Incremental Variable Ordering Tactic
Dec 29, 2021
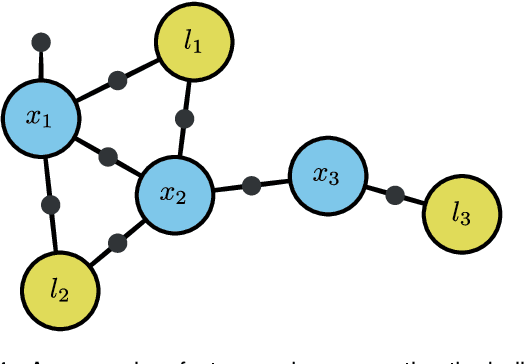
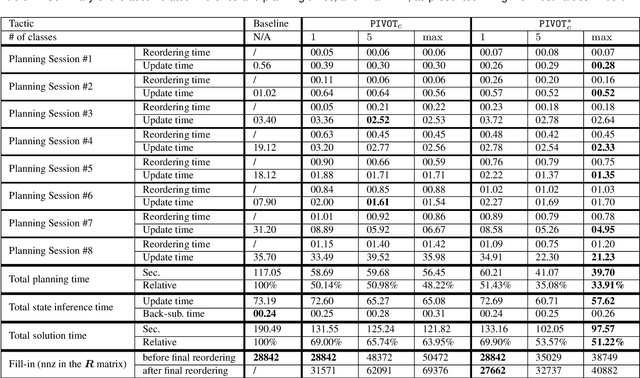
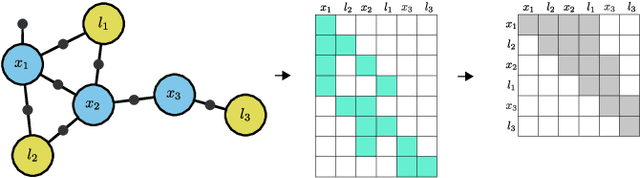
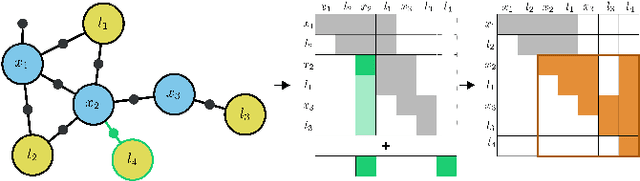
In this work, we examine the problem of online decision making under uncertainty, which we formulate as planning in the belief space. Maintaining beliefs (i.e., distributions) over high-dimensional states (e.g., entire trajectories) was not only shown to significantly improve accuracy, but also allows planning with information-theoretic objectives, as required for the tasks of active SLAM and information gathering. Nonetheless, planning under this "smoothing" paradigm holds a high computational complexity, which makes it challenging for online solution. Thus, we suggest the following idea: before planning, perform a standalone state variable reordering procedure on the initial belief, and "push forwards" all the predicted loop closing variables. Since the initial variable order determines which subset of them would be affected by incoming updates, such reordering allows us to minimize the total number of affected variables, and reduce the computational complexity of candidate evaluation during planning. We call this approach PIVOT: Predictive Incremental Variable Ordering Tactic. Applying this tactic can also improve the state inference efficiency; if we maintain the PIVOT order after the planning session, then we should similarly reduce the cost of loop closures, when they actually occur. To demonstrate its effectiveness, we applied PIVOT in a realistic active SLAM simulation, where we managed to significantly reduce the computation time of both the planning and inference sessions. The approach is applicable to general distributions, and induces no loss in accuracy.
The Curse of Zero Task Diversity: On the Failure of Transfer Learning to Outperform MAML and their Empirical Equivalence
Dec 24, 2021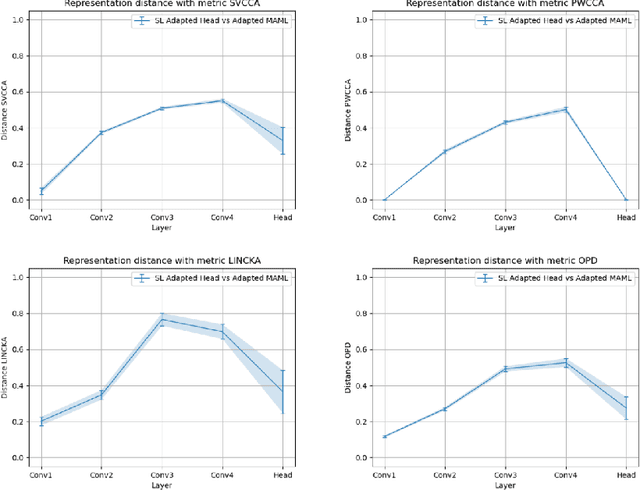
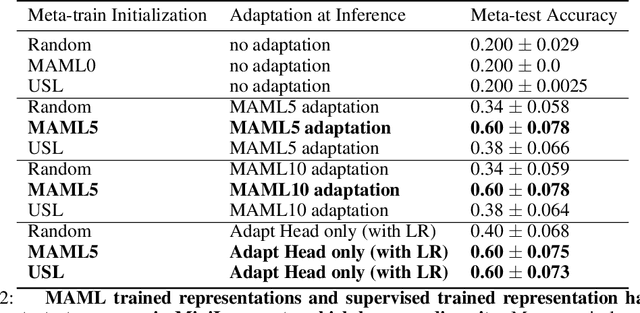
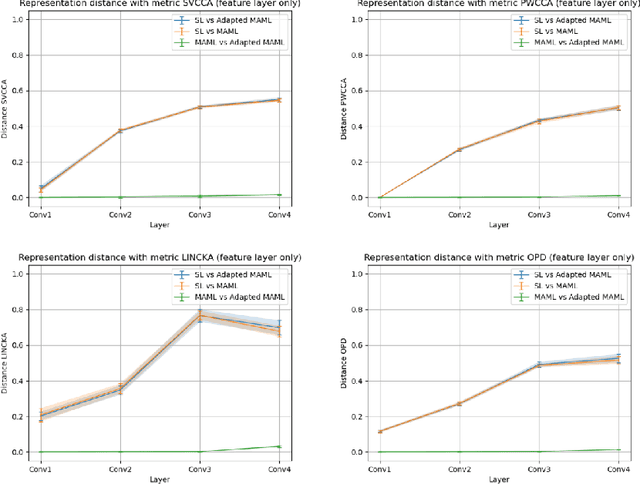
It has been recently observed that a transfer learning solution might be all we needed to solve many few-shot learning benchmarks. This raises important questions about when and how meta-learning algorithms should be deployed. In this paper, we make a first step in clarifying these questions by first formulating a computable metric for a few-shot learning benchmark that we hypothesize is predictive of whether meta-learning solutions will succeed or not. We name this metric the diversity coefficient of a few-shot learning benchmark. Using the diversity coefficient, we show that the MiniImagenet benchmark has zero diversity - according to twenty-four different ways to compute the diversity. We proceed to show that when making a fair comparison between MAML learned solutions to transfer learning, both have identical meta-test accuracy. This suggests that transfer learning fails to outperform MAML - contrary to what previous work suggests. Together, these two facts provide the first test of whether diversity correlates with meta-learning success and therefore show that a diversity coefficient of zero correlates with a high similarity between transfer learning and MAML learned solutions - especially at meta-test time. We therefore conjecture meta-learned solutions have the same meta-test performance as transfer learning when the diversity coefficient is zero.
Joint Optimization of Beam-Hopping Design and NOMA-Assisted Transmission for Flexible Satellite Systems
Oct 13, 2021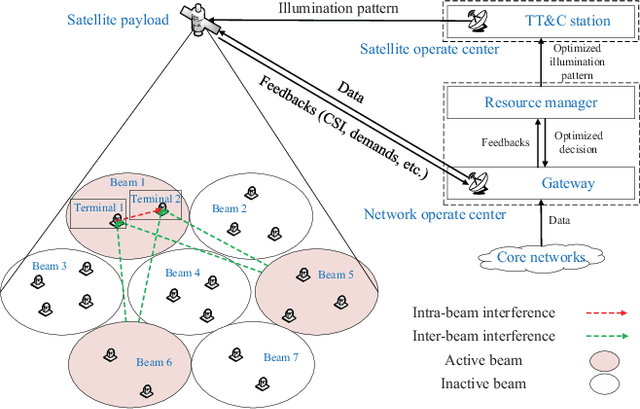
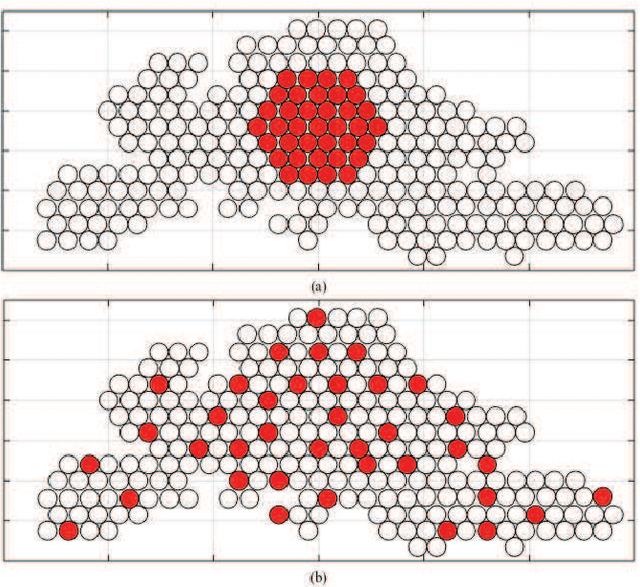
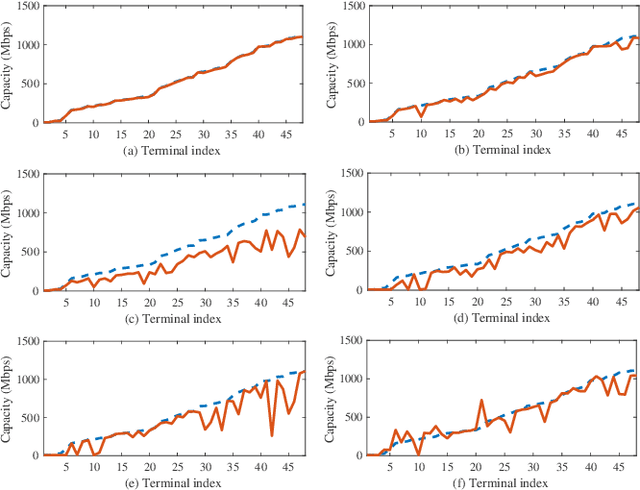
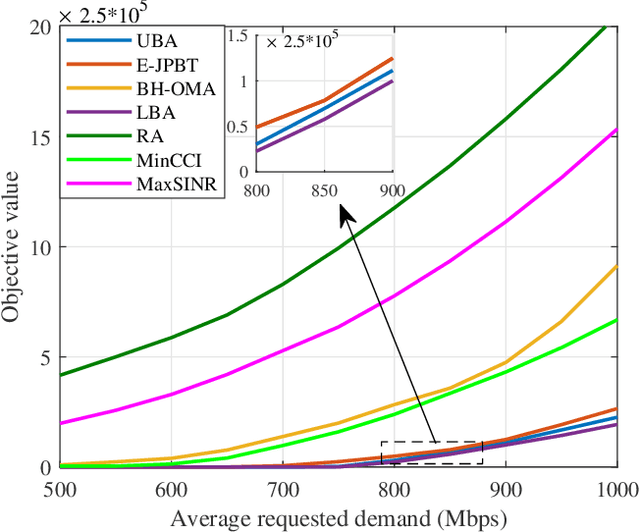
Next-generation satellite systems require more flexibility in resource management such that available radio resources can be dynamically allocated to meet time-varying and non-uniform traffic demands. Considering potential benefits of beam hopping (BH) and non-orthogonal multiple access (NOMA), we exploit the time-domain flexibility in multi-beam satellite systems by optimizing BH design, and enhance the power-domain flexibility via NOMA. In this paper, we investigate the synergy and mutual influence of beam hopping and NOMA. We jointly optimize power allocation, beam scheduling, and terminal-timeslot assignment to minimize the gap between requested traffic demand and offered capacity. In the solution development, we formally prove the NP-hardness of the optimization problem. Next, we develop a bounding scheme to tightly gauge the global optimum and propose a suboptimal algorithm to enable efficient resource assignment. Numerical results demonstrate the benefits of combining NOMA and BH, and validate the superiority of the proposed BH-NOMA schemes over benchmarks.
Temporal Scale Estimation for Oversampled Network Cascades: Theory, Algorithms, and Experiment
Sep 22, 2021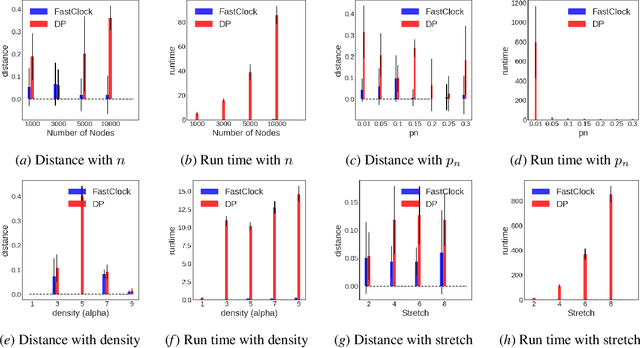
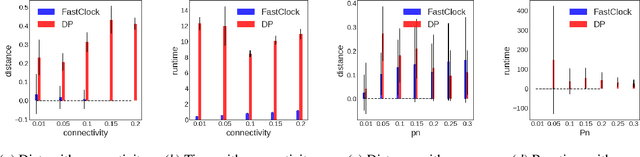
Spreading processes on graphs arise in a host of application domains, from the study of online social networks to viral marketing to epidemiology. Various discrete-time probabilistic models for spreading processes have been proposed. These are used for downstream statistical estimation and prediction problems, often involving messages or other information that is transmitted along with infections caused by the process. It is thus important to design models of cascade observation that take into account phenomena that lead to uncertainty about the process state at any given time. We highlight one such phenomenon -- temporal distortion -- caused by a misalignment between the rate at which observations of a cascade process are made and the rate at which the process itself operates, and argue that failure to correct for it results in degradation of performance on downstream statistical tasks. To address these issues, we formulate the clock estimation problem in terms of a natural distortion measure. We give a clock estimation algorithm, which we call FastClock, that runs in linear time in the size of its input and is provably statistically accurate for a broad range of model parameters when cascades are generated from the independent cascade process with known parameters and when the underlying graph is Erd\H{o}s-R\'enyi. We further give empirical results on the performance of our algorithm in comparison to the state of the art estimator, a likelihood proxy maximization-based estimator implemented via dynamic programming. We find that, in a broad parameter regime, our algorithm substantially outperforms the dynamic programming algorithm in terms of both running time and accuracy.
Long Expressive Memory for Sequence Modeling
Oct 10, 2021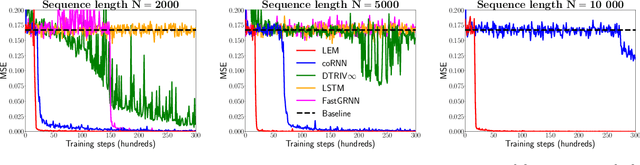
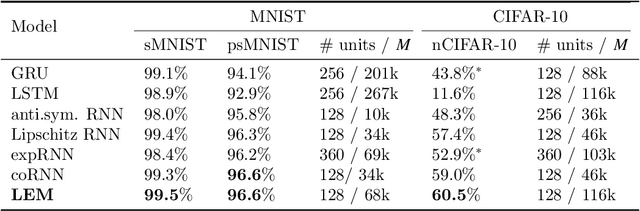
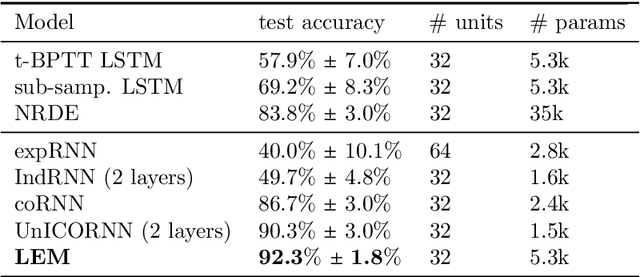
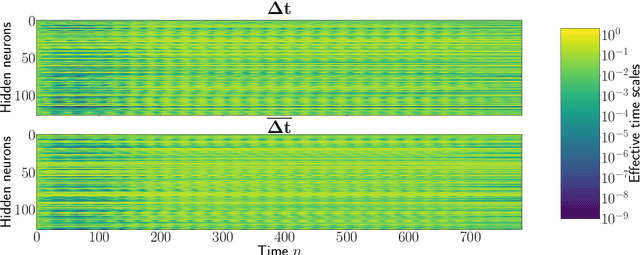
We propose a novel method called Long Expressive Memory (LEM) for learning long-term sequential dependencies. LEM is gradient-based, it can efficiently process sequential tasks with very long-term dependencies, and it is sufficiently expressive to be able to learn complicated input-output maps. To derive LEM, we consider a system of multiscale ordinary differential equations, as well as a suitable time-discretization of this system. For LEM, we derive rigorous bounds to show the mitigation of the exploding and vanishing gradients problem, a well-known challenge for gradient-based recurrent sequential learning methods. We also prove that LEM can approximate a large class of dynamical systems to high accuracy. Our empirical results, ranging from image and time-series classification through dynamical systems prediction to speech recognition and language modeling, demonstrate that LEM outperforms state-of-the-art recurrent neural networks, gated recurrent units, and long short-term memory models.
Applications of shapelet transform to time series classification of earthquake, wind and wave data
Apr 22, 2020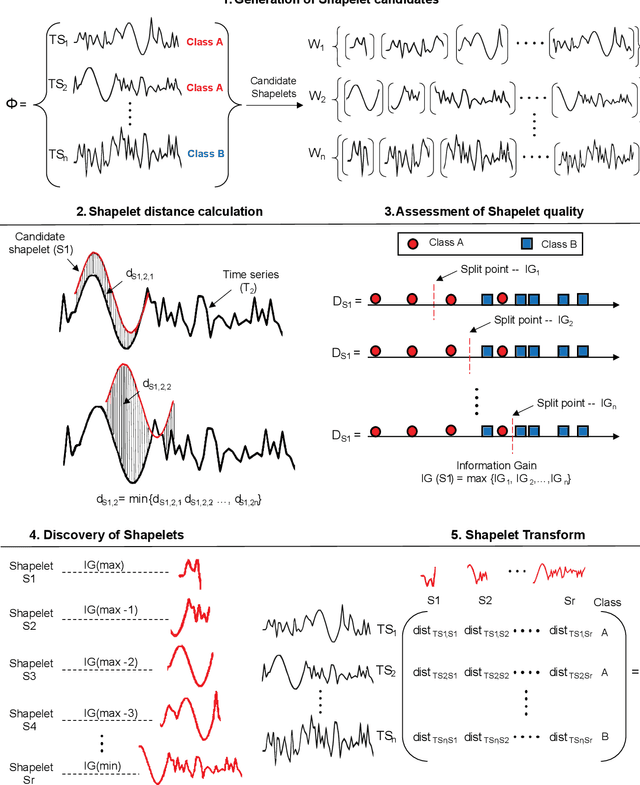
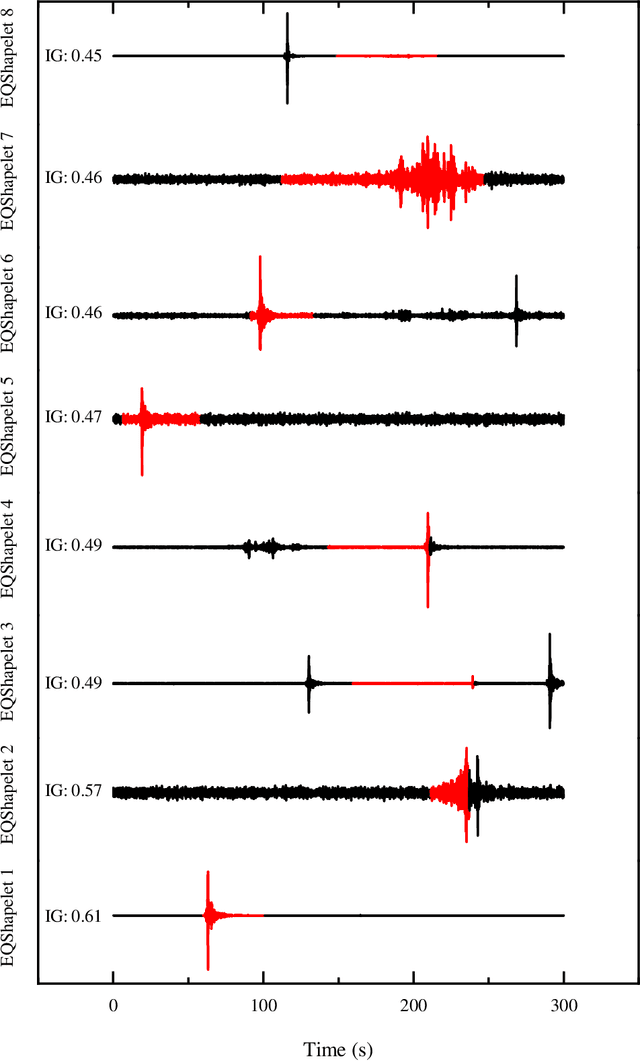
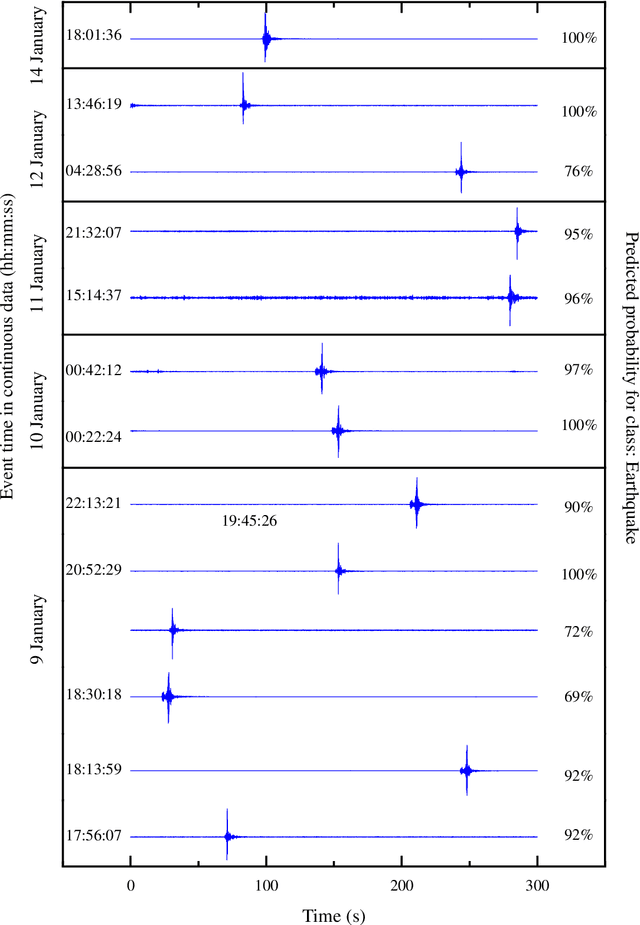
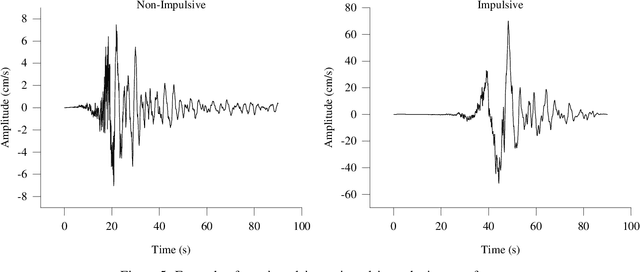
Autonomous detection of desired events from large databases using time series classification is becoming increasingly important in civil engineering as a result of continued long-term health monitoring of a large number of engineering structures encompassing buildings, bridges, towers, and offshore platforms. In this context, this paper proposes the application of a relatively new time series representation named "Shapelet transform", which is based on local similarity in the shape of the time series subsequences. In consideration of the individual attributes distinctive to time series signals in earthquake, wind and ocean engineering, the application of this transform yields a new shape-based feature representation. Combining this shape-based representation with a standard machine learning algorithm, a truly "white-box" machine learning model is proposed with understandable features and a transparent algorithm. This model automates event detection without the intervention of domain practitioners, yielding a practical event detection procedure. The efficacy of this proposed shapelet transform-based autonomous detection procedure is demonstrated by examples, to identify known and unknown earthquake events from continuously recorded ground-motion measurements, to detect pulses in the velocity time history of ground motions to distinguish between near-field and far-field ground motions, to identify thunderstorms from continuous wind speed measurements, to detect large-amplitude wind-induced vibrations from the bridge monitoring data, and to identify plunging breaking waves that have a significant impact on offshore structures.
Accelerated and instance-optimal policy evaluation with linear function approximation
Dec 24, 2021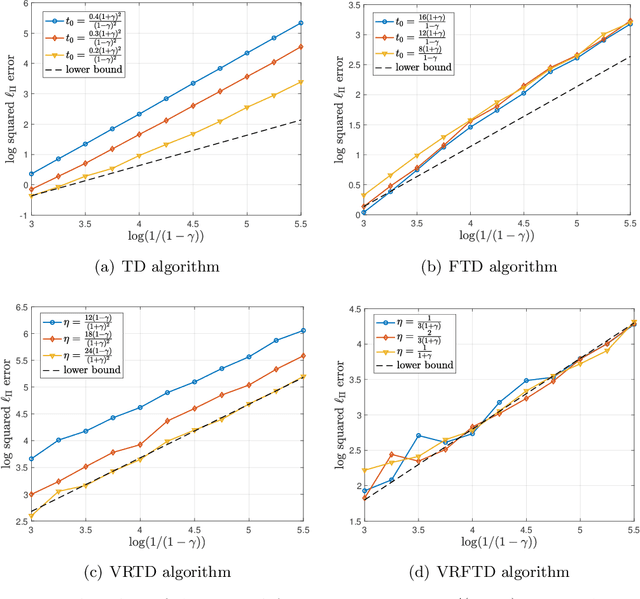
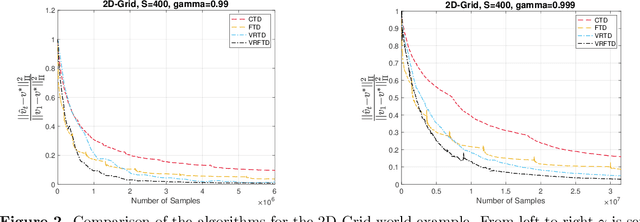
We study the problem of policy evaluation with linear function approximation and present efficient and practical algorithms that come with strong optimality guarantees. We begin by proving lower bounds that establish baselines on both the deterministic error and stochastic error in this problem. In particular, we prove an oracle complexity lower bound on the deterministic error in an instance-dependent norm associated with the stationary distribution of the transition kernel, and use the local asymptotic minimax machinery to prove an instance-dependent lower bound on the stochastic error in the i.i.d. observation model. Existing algorithms fail to match at least one of these lower bounds: To illustrate, we analyze a variance-reduced variant of temporal difference learning, showing in particular that it fails to achieve the oracle complexity lower bound. To remedy this issue, we develop an accelerated, variance-reduced fast temporal difference algorithm (VRFTD) that simultaneously matches both lower bounds and attains a strong notion of instance-optimality. Finally, we extend the VRFTD algorithm to the setting with Markovian observations, and provide instance-dependent convergence results that match those in the i.i.d. setting up to a multiplicative factor that is proportional to the mixing time of the chain. Our theoretical guarantees of optimality are corroborated by numerical experiments.
Tracking People by Predicting 3D Appearance, Location & Pose
Dec 08, 2021
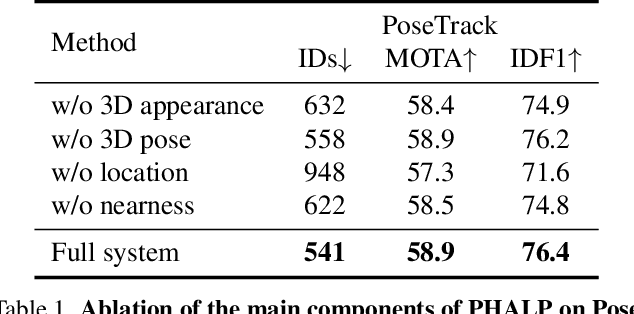
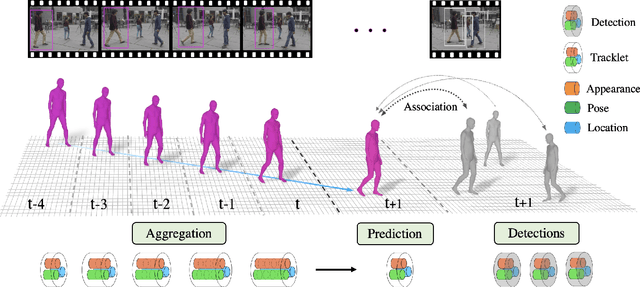

In this paper, we present an approach for tracking people in monocular videos, by predicting their future 3D representations. To achieve this, we first lift people to 3D from a single frame in a robust way. This lifting includes information about the 3D pose of the person, his or her location in the 3D space, and the 3D appearance. As we track a person, we collect 3D observations over time in a tracklet representation. Given the 3D nature of our observations, we build temporal models for each one of the previous attributes. We use these models to predict the future state of the tracklet, including 3D location, 3D appearance, and 3D pose. For a future frame, we compute the similarity between the predicted state of a tracklet and the single frame observations in a probabilistic manner. Association is solved with simple Hungarian matching, and the matches are used to update the respective tracklets. We evaluate our approach on various benchmarks and report state-of-the-art results.
Developing Products Update-Alert System for e-Commerce Websites Users Using HTML Data and Web Scraping Technique
Sep 02, 2021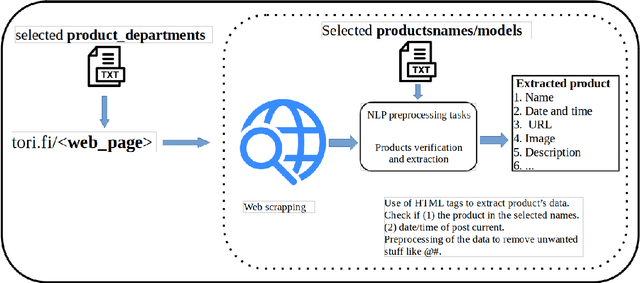

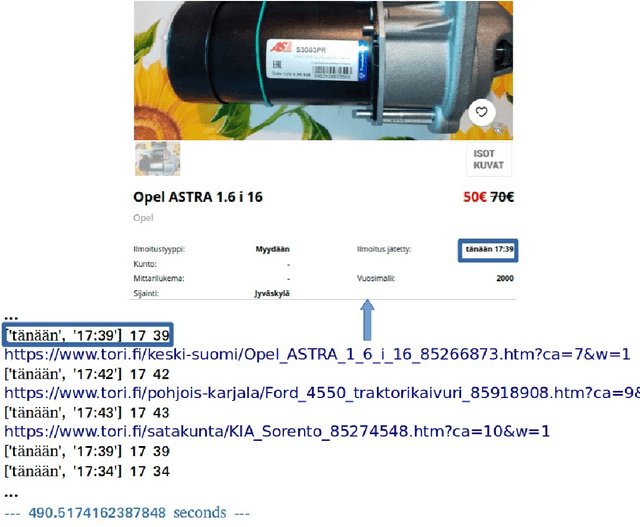
Websites are regarded as domains of limitless information which anyone and everyone can access. The new trend of technology put us to change the way we are doing our business. The Internet now is fastly becoming a new place for business and the advancement in this technology gave rise to the number of e-commerce websites. This made the lifestyle of marketers/vendors, retailers and consumers (collectively regarded as users in this paper) easy, because it provides easy platforms to sale/order items through the internet. This also requires that the users will have to spend a lot of time and effort to search for the best product deals, products updates and offers on e-commerce websites. They have to filter and compare search results by themselves which takes a lot of time and there are chances of ambiguous results. In this paper, we applied web crawling and scraping methods on an e-commerce website to get HTML data for identifying products updates based on the current time. The HTML data is preprocessed to extract details of the products such as name, price, post date and time, etc. to serve as useful information for users.
* 6 pages, 3 figures, 1 table, IJNLC Journal
Towards Lightweight Controllable Audio Synthesis with Conditional Implicit Neural Representations
Dec 02, 2021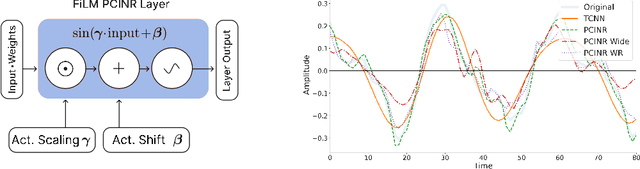
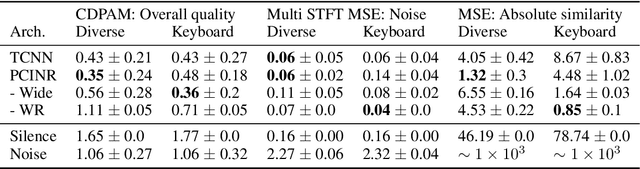
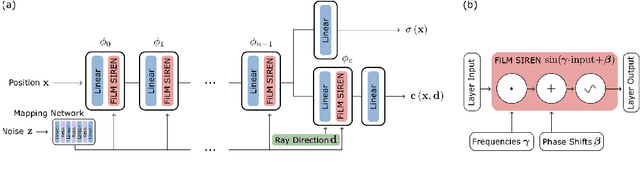
The high temporal resolution of audio and our perceptual sensitivity to small irregularities in waveforms make synthesizing at high sampling rates a complex and computationally intensive task, prohibiting real-time, controllable synthesis within many approaches. In this work we aim to shed light on the potential of Conditional Implicit Neural Representations (CINRs) as lightweight backbones in generative frameworks for audio synthesis. Our experiments show that small Periodic Conditional INRs (PCINRs) learn faster and generally produce quantitatively better audio reconstructions than Transposed Convolutional Neural Networks with equal parameter counts. However, their performance is very sensitive to activation scaling hyperparameters. When learning to represent more uniform sets, PCINRs tend to introduce artificial high-frequency components in reconstructions. We validate this noise can be minimized by applying standard weight regularization during training or decreasing the compositional depth of PCINRs, and suggest directions for future research.