 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Incremental Cross-view Mutual Distillation for Self-supervised Medical CT Synthesis
Dec 20, 2021
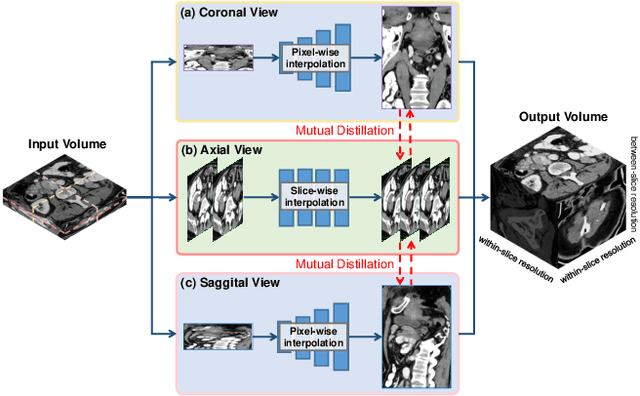
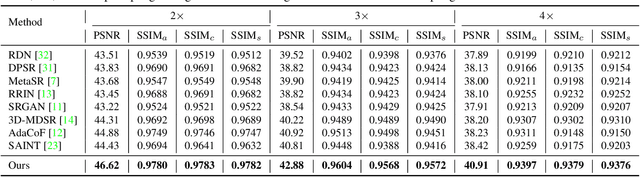

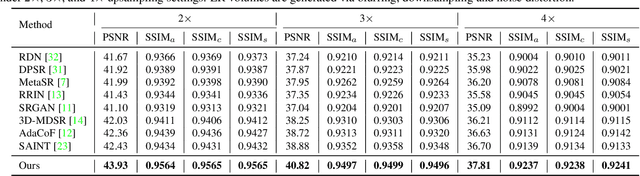
Due to the constraints of the imaging device and high cost in operation time, computer tomography (CT) scans are usually acquired with low intra-slice resolution. Improving the intra-slice resolution is beneficial to the disease diagnosis for both human experts and computer-aided systems. To this end, this paper builds a novel medical slice synthesis to increase the between-slice resolution. Considering that the ground-truth intermediate medical slices are always absent in clinical practice, we introduce the incremental cross-view mutual distillation strategy to accomplish this task in the self-supervised learning manner. Specifically, we model this problem from three different views: slice-wise interpolation from axial view and pixel-wise interpolation from coronal and sagittal views. Under this circumstance, the models learned from different views can distill valuable knowledge to guide the learning processes of each other. We can repeat this process to make the models synthesize intermediate slice data with increasing inter-slice resolution. To demonstrate the effectiveness of the proposed approach, we conduct comprehensive experiments on a large-scale CT dataset. Quantitative and qualitative comparison results show that our method outperforms state-of-the-art algorithms by clear margins.
AdaViT: Adaptive Tokens for Efficient Vision Transformer
Dec 14, 2021
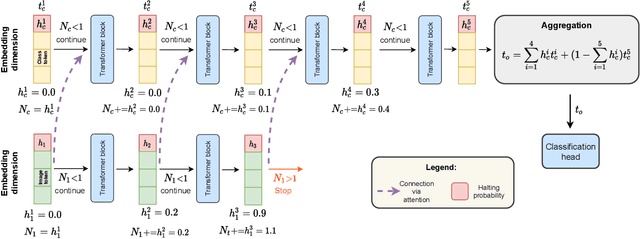
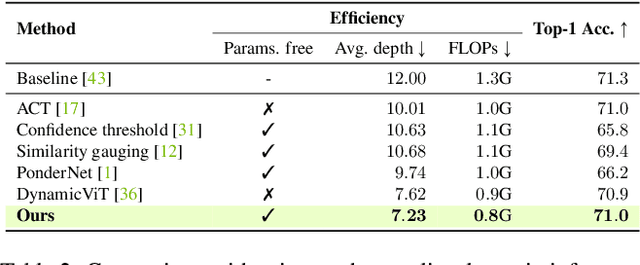

We introduce AdaViT, a method that adaptively adjusts the inference cost of vision transformer (ViT) for images of different complexity. AdaViT achieves this by automatically reducing the number of tokens in vision transformers that are processed in the network as inference proceeds. We reformulate Adaptive Computation Time (ACT) for this task, extending halting to discard redundant spatial tokens. The appealing architectural properties of vision transformers enables our adaptive token reduction mechanism to speed up inference without modifying the network architecture or inference hardware. We demonstrate that AdaViT requires no extra parameters or sub-network for halting, as we base the learning of adaptive halting on the original network parameters. We further introduce distributional prior regularization that stabilizes training compared to prior ACT approaches. On the image classification task (ImageNet1K), we show that our proposed AdaViT yields high efficacy in filtering informative spatial features and cutting down on the overall compute. The proposed method improves the throughput of DeiT-Tiny by 62% and DeiT-Small by 38% with only 0.3% accuracy drop, outperforming prior art by a large margin.
RTS3D: Real-time Stereo 3D Detection from 4D Feature-Consistency Embedding Space for Autonomous Driving
Dec 30, 2020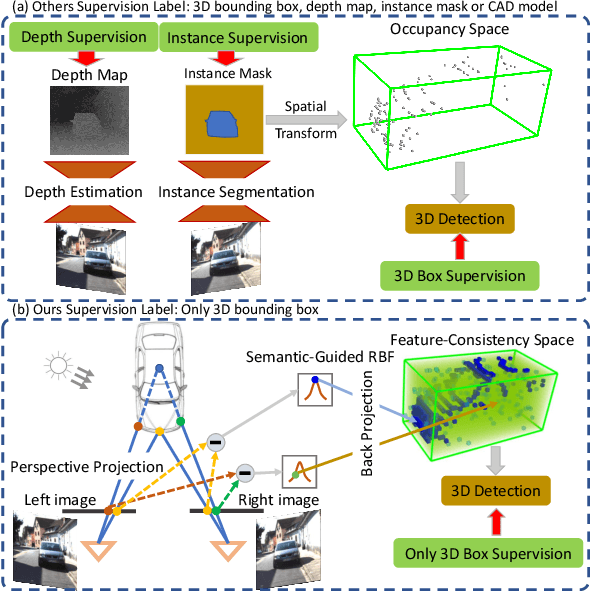

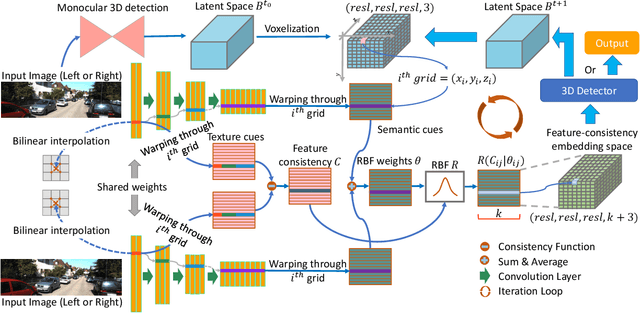
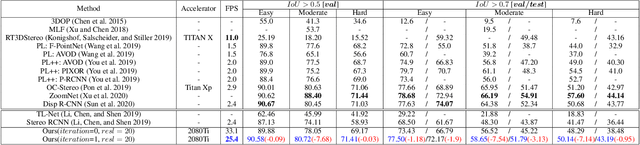
Although the recent image-based 3D object detection methods using Pseudo-LiDAR representation have shown great capabilities, a notable gap in efficiency and accuracy still exist compared with LiDAR-based methods. Besides, over-reliance on the stand-alone depth estimator, requiring a large number of pixel-wise annotations in the training stage and more computation in the inferencing stage, limits the scaling application in the real world. In this paper, we propose an efficient and accurate 3D object detection method from stereo images, named RTS3D. Different from the 3D occupancy space in the Pseudo-LiDAR similar methods, we design a novel 4D feature-consistent embedding (FCE) space as the intermediate representation of the 3D scene without depth supervision. The FCE space encodes the object's structural and semantic information by exploring the multi-scale feature consistency warped from stereo pair. Furthermore, a semantic-guided RBF (Radial Basis Function) and a structure-aware attention module are devised to reduce the influence of FCE space noise without instance mask supervision. Experiments on the KITTI benchmark show that RTS3D is the first true real-time system (FPS$>$24) for stereo image 3D detection meanwhile achieves $10\%$ improvement in average precision comparing with the previous state-of-the-art method. The code will be available at https://github.com/Banconxuan/RTS3D
Approximate Time-Optimal Trajectories for Damped Double Integrator in 2D Obstacle Environments under Bounded Inputs
Jul 10, 2020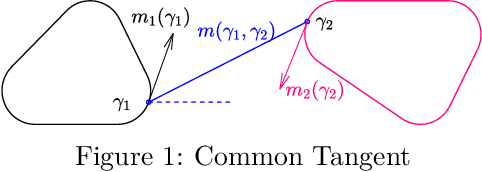
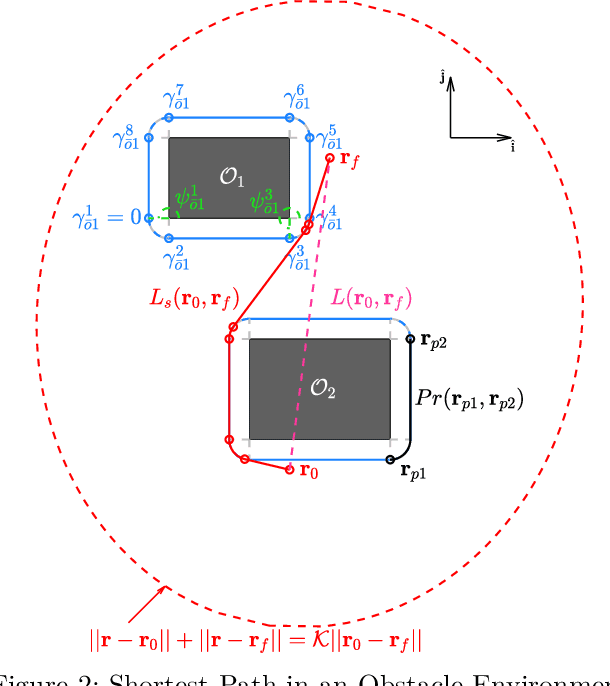
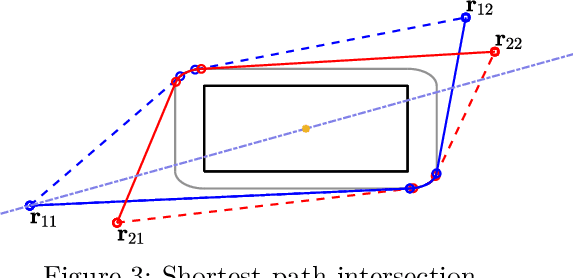
This article provides extensions to existing path-velocity decomposition based time optimal trajectory planning algorithm \cite{kant1986toward} to scenarios in which agents move in 2D obstacle environment under double integrator dynamics with drag term (damped double integrator). Particularly, we extend the idea of a tangent graph \cite{liu1992path} to $\calC^1$-Tangent graph to find continuously differentiable ($\calC^1$) shortest path between any two points. $\calC^1$-Tangent graph has a continuously differentiable ($\calC^1$) path between any two nodes. We also provide analytical expressions for a near time-optimal velocity profile for an agent moving on these shortest paths under the damped double integrator with bounded acceleration.
Safe Driving via Expert Guided Policy Optimization
Oct 30, 2021
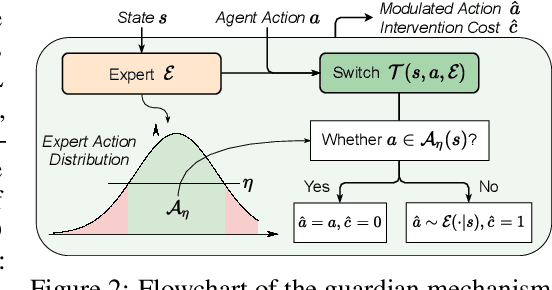
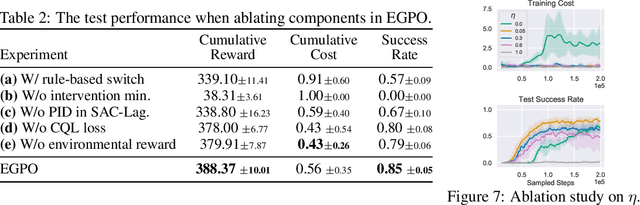

When learning common skills like driving, beginners usually have domain experts standing by to ensure the safety of the learning process. We formulate such learning scheme under the Expert-in-the-loop Reinforcement Learning where a guardian is introduced to safeguard the exploration of the learning agent. While allowing the sufficient exploration in the uncertain environment, the guardian intervenes under dangerous situations and demonstrates the correct actions to avoid potential accidents. Thus ERL enables both exploration and expert's partial demonstration as two training sources. Following such a setting, we develop a novel Expert Guided Policy Optimization (EGPO) method which integrates the guardian in the loop of reinforcement learning. The guardian is composed of an expert policy to generate demonstration and a switch function to decide when to intervene. Particularly, a constrained optimization technique is used to tackle the trivial solution that the agent deliberately behaves dangerously to deceive the expert into taking over. Offline RL technique is further used to learn from the partial demonstration generated by the expert. Safe driving experiments show that our method achieves superior training and test-time safety, outperforms baselines with a substantial margin in sample efficiency, and preserves the generalizabiliy to unseen environments in test-time. Demo video and source code are available at: https://decisionforce.github.io/EGPO/
Efficient Belief Space Planning in High-Dimensional State Spaces using PIVOT: Predictive Incremental Variable Ordering Tactic
Dec 29, 2021
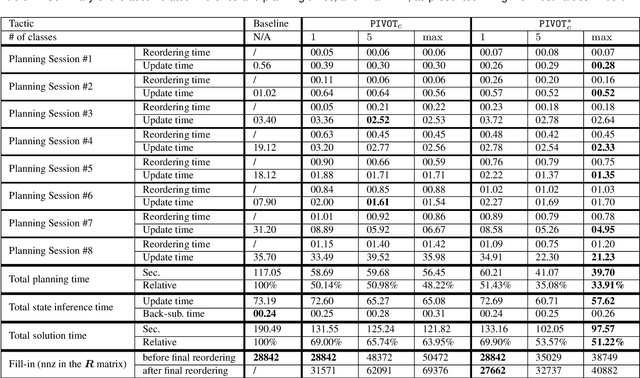
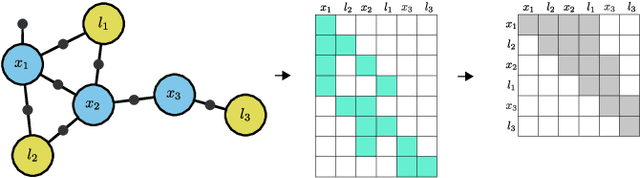
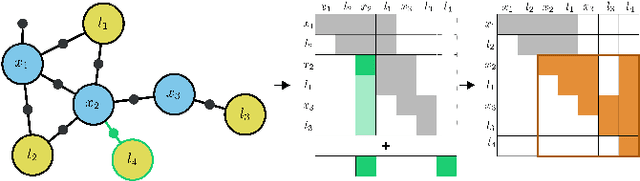
In this work, we examine the problem of online decision making under uncertainty, which we formulate as planning in the belief space. Maintaining beliefs (i.e., distributions) over high-dimensional states (e.g., entire trajectories) was not only shown to significantly improve accuracy, but also allows planning with information-theoretic objectives, as required for the tasks of active SLAM and information gathering. Nonetheless, planning under this "smoothing" paradigm holds a high computational complexity, which makes it challenging for online solution. Thus, we suggest the following idea: before planning, perform a standalone state variable reordering procedure on the initial belief, and "push forwards" all the predicted loop closing variables. Since the initial variable order determines which subset of them would be affected by incoming updates, such reordering allows us to minimize the total number of affected variables, and reduce the computational complexity of candidate evaluation during planning. We call this approach PIVOT: Predictive Incremental Variable Ordering Tactic. Applying this tactic can also improve the state inference efficiency; if we maintain the PIVOT order after the planning session, then we should similarly reduce the cost of loop closures, when they actually occur. To demonstrate its effectiveness, we applied PIVOT in a realistic active SLAM simulation, where we managed to significantly reduce the computation time of both the planning and inference sessions. The approach is applicable to general distributions, and induces no loss in accuracy.
Enhancing Food Intake Tracking in Long-Term Care with Automated Food Imaging and Nutrient Intake Tracking (AFINI-T) Technology
Dec 08, 2021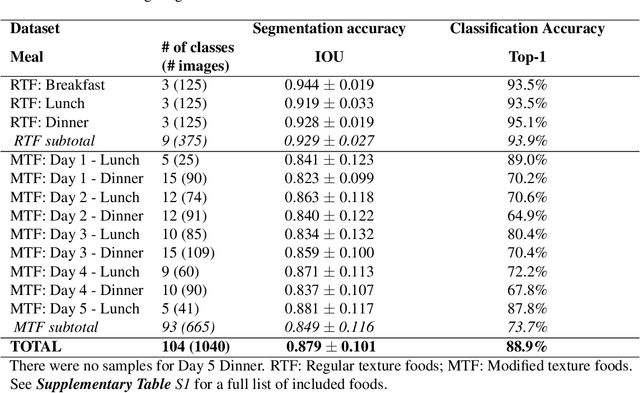
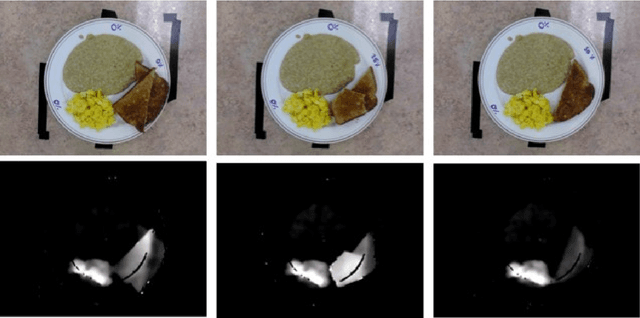
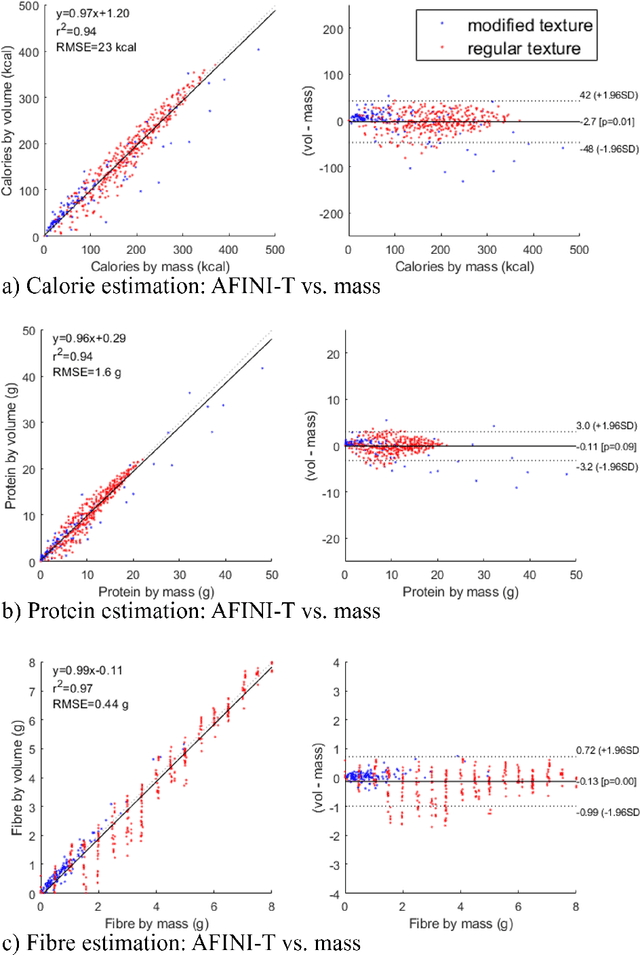

Half of long-term care (LTC) residents are malnourished increasing hospitalization, mortality, morbidity, with lower quality of life. Current tracking methods are subjective and time consuming. This paper presents the automated food imaging and nutrient intake tracking (AFINI-T) technology designed for LTC. We propose a novel convolutional autoencoder for food classification, trained on an augmented UNIMIB2016 dataset and tested on our simulated LTC food intake dataset (12 meal scenarios; up to 15 classes each; top-1 classification accuracy: 88.9%; mean intake error: -0.4 mL$\pm$36.7 mL). Nutrient intake estimation by volume was strongly linearly correlated with nutrient estimates from mass ($r^2$ 0.92 to 0.99) with good agreement between methods ($\sigma$= -2.7 to -0.01; zero within each of the limits of agreement). The AFINI-T approach is a deep-learning powered computational nutrient sensing system that may provide a novel means for more accurately and objectively tracking LTC resident food intake to support and prevent malnutrition tracking strategies.
Filling the Gaps in Ancient Akkadian Texts: A Masked Language Modelling Approach
Sep 09, 2021
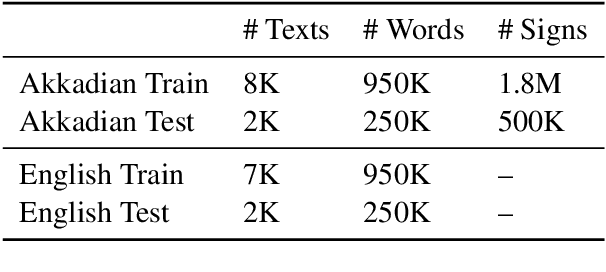

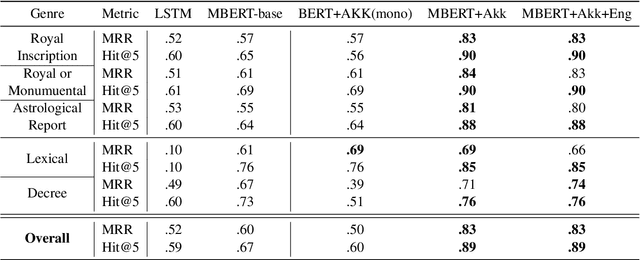
We present models which complete missing text given transliterations of ancient Mesopotamian documents, originally written on cuneiform clay tablets (2500 BCE - 100 CE). Due to the tablets' deterioration, scholars often rely on contextual cues to manually fill in missing parts in the text in a subjective and time-consuming process. We identify that this challenge can be formulated as a masked language modelling task, used mostly as a pretraining objective for contextualized language models. Following, we develop several architectures focusing on the Akkadian language, the lingua franca of the time. We find that despite data scarcity (1M tokens) we can achieve state of the art performance on missing tokens prediction (89% hit@5) using a greedy decoding scheme and pretraining on data from other languages and different time periods. Finally, we conduct human evaluations showing the applicability of our models in assisting experts to transcribe texts in extinct languages.
The Curse of Zero Task Diversity: On the Failure of Transfer Learning to Outperform MAML and their Empirical Equivalence
Dec 24, 2021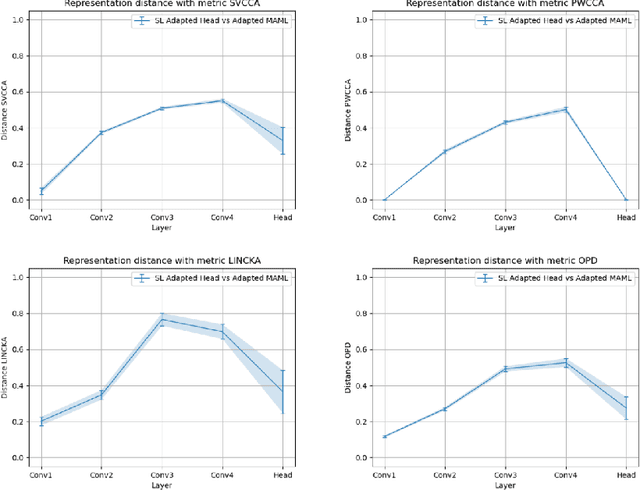
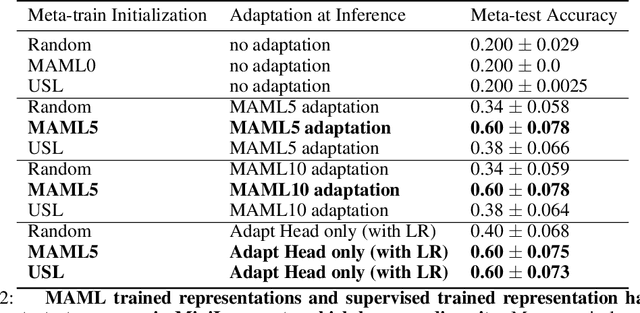
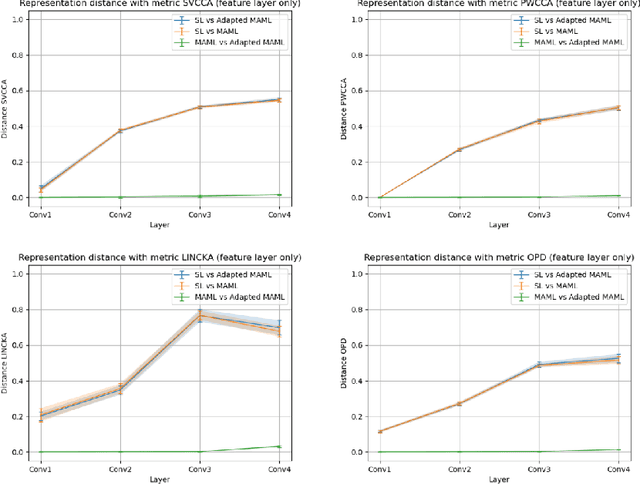
It has been recently observed that a transfer learning solution might be all we needed to solve many few-shot learning benchmarks. This raises important questions about when and how meta-learning algorithms should be deployed. In this paper, we make a first step in clarifying these questions by first formulating a computable metric for a few-shot learning benchmark that we hypothesize is predictive of whether meta-learning solutions will succeed or not. We name this metric the diversity coefficient of a few-shot learning benchmark. Using the diversity coefficient, we show that the MiniImagenet benchmark has zero diversity - according to twenty-four different ways to compute the diversity. We proceed to show that when making a fair comparison between MAML learned solutions to transfer learning, both have identical meta-test accuracy. This suggests that transfer learning fails to outperform MAML - contrary to what previous work suggests. Together, these two facts provide the first test of whether diversity correlates with meta-learning success and therefore show that a diversity coefficient of zero correlates with a high similarity between transfer learning and MAML learned solutions - especially at meta-test time. We therefore conjecture meta-learned solutions have the same meta-test performance as transfer learning when the diversity coefficient is zero.
GluonTS: Probabilistic Time Series Models in Python
Jun 14, 2019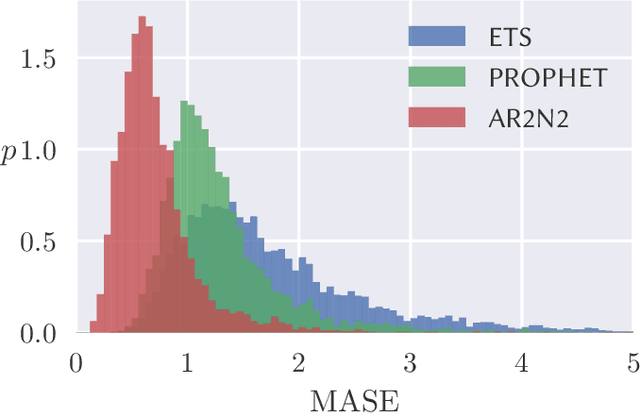

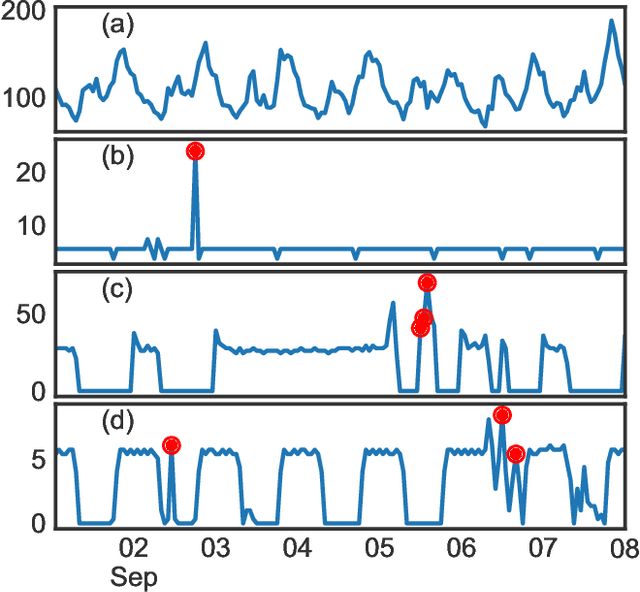
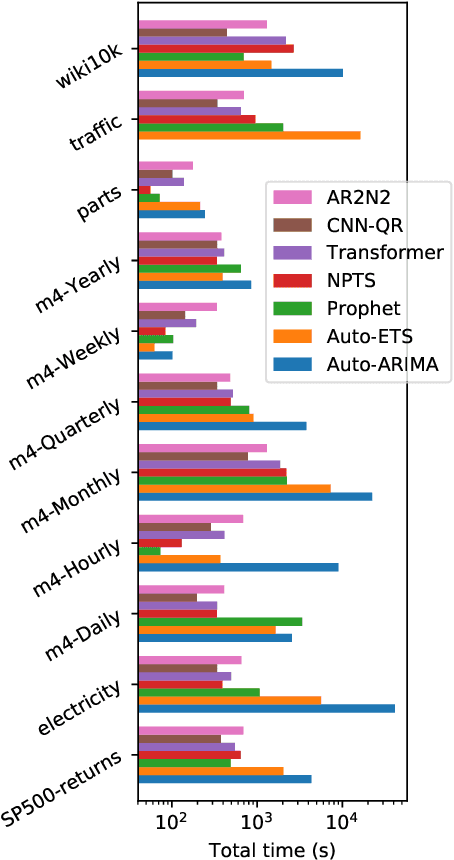
We introduce Gluon Time Series (GluonTS, available at https://gluon-ts.mxnet.io), a library for deep-learning-based time series modeling. GluonTS simplifies the development of and experimentation with time series models for common tasks such as forecasting or anomaly detection. It provides all necessary components and tools that scientists need for quickly building new models, for efficiently running and analyzing experiments and for evaluating model accuracy.