 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-concept adversarial attacks
Oct 19, 2021
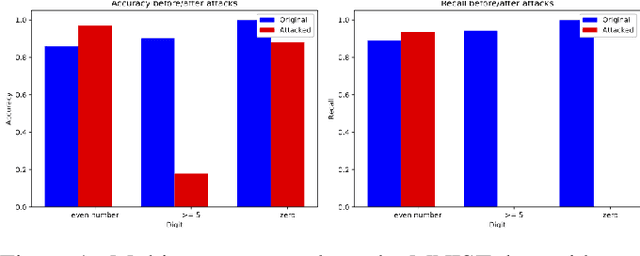
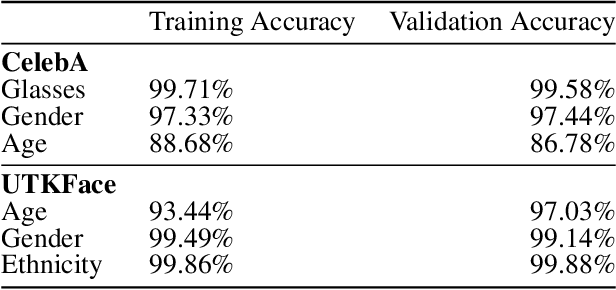

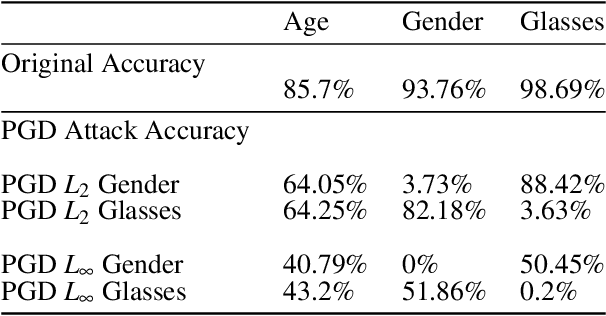
As machine learning (ML) techniques are being increasingly used in many applications, their vulnerability to adversarial attacks becomes well-known. Test time attacks, usually launched by adding adversarial noise to test instances, have been shown effective against the deployed ML models. In practice, one test input may be leveraged by different ML models. Test time attacks targeting a single ML model often neglect their impact on other ML models. In this work, we empirically demonstrate that naively attacking the classifier learning one concept may negatively impact classifiers trained to learn other concepts. For example, for the online image classification scenario, when the Gender classifier is under attack, the (wearing) Glasses classifier is simultaneously attacked with the accuracy dropped from 98.69 to 88.42. This raises an interesting question: is it possible to attack one set of classifiers without impacting the other set that uses the same test instance? Answers to the above research question have interesting implications for protecting privacy against ML model misuse. Attacking ML models that pose unnecessary risks of privacy invasion can be an important tool for protecting individuals from harmful privacy exploitation. In this paper, we address the above research question by developing novel attack techniques that can simultaneously attack one set of ML models while preserving the accuracy of the other. In the case of linear classifiers, we provide a theoretical framework for finding an optimal solution to generate such adversarial examples. Using this theoretical framework, we develop a multi-concept attack strategy in the context of deep learning. Our results demonstrate that our techniques can successfully attack the target classes while protecting the protected classes in many different settings, which is not possible with the existing test-time attack-single strategies.
Complexity assessments for decidable fragments of Set Theory. III: A quadratic reduction of constraints over nested sets to Boolean formulae
Dec 09, 2021
As a contribution to quantitative set-theoretic inferencing, a translation is proposed of conjunctions of literals of the forms $x=y\setminus z$, $x \neq y\setminus z$, and $z =\{x\}$, where $x,y,z$ stand for variables ranging over the von Neumann universe of sets, into unquantified Boolean formulae of a rather simple conjunctive normal form. The formulae in the target language involve variables ranging over a Boolean ring of sets, along with a difference operator and relators designating equality, non-disjointness and inclusion. Moreover, the result of each translation is a conjunction of literals of the forms $x=y\setminus z$, $x\neq y\setminus z$ and of implications whose antecedents are isolated literals and whose consequents are either inclusions (strict or non-strict) between variables, or equalities between variables. Besides reflecting a simple and natural semantics, which ensures satisfiability-preservation, the proposed translation has quadratic algorithmic time-complexity, and bridges two languages both of which are known to have an NP-complete satisfiability problem.
Are E2E ASR models ready for an industrial usage?
Dec 09, 2021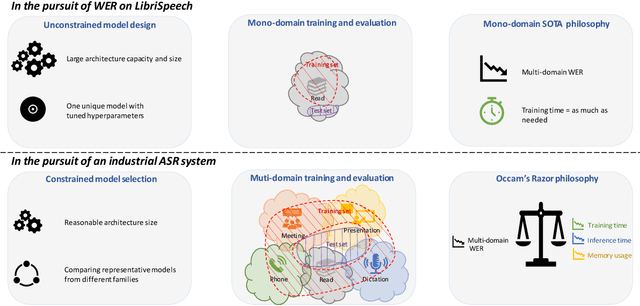
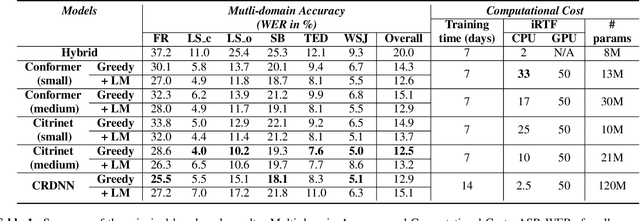
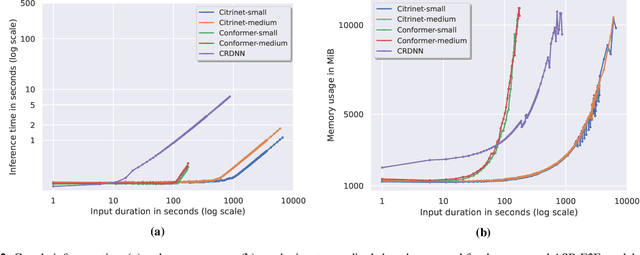
The Automated Speech Recognition (ASR) community experiences a major turning point with the rise of the fully-neural (End-to-End, E2E) approaches. At the same time, the conventional hybrid model remains the standard choice for the practical usage of ASR. According to previous studies, the adoption of E2E ASR in real-world applications was hindered by two main limitations: their ability to generalize on unseen domains and their high operational cost. In this paper, we investigate both above-mentioned drawbacks by performing a comprehensive multi-domain benchmark of several contemporary E2E models and a hybrid baseline. Our experiments demonstrate that E2E models are viable alternatives for the hybrid approach, and even outperform the baseline both in accuracy and in operational efficiency. As a result, our study shows that the generalization and complexity issues are no longer the major obstacle for industrial integration, and draws the community's attention to other potential limitations of the E2E approaches in some specific use-cases.
FUSeg: The Foot Ulcer Segmentation Challenge
Jan 02, 2022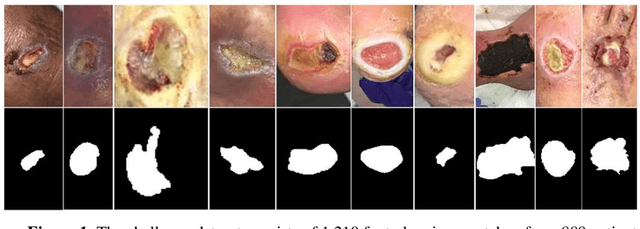
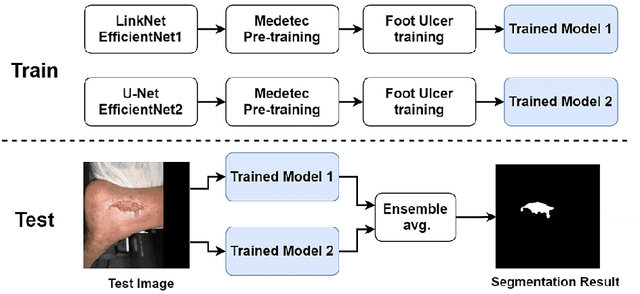
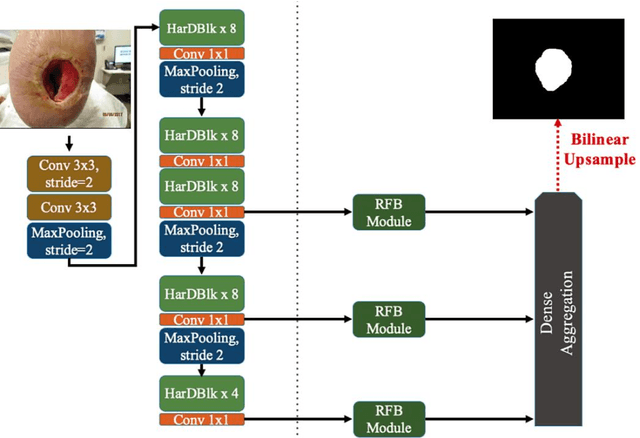
Acute and chronic wounds with varying etiologies burden the healthcare systems economically. The advanced wound care market is estimated to reach $22 billion by 2024. Wound care professionals provide proper diagnosis and treatment with heavy reliance on images and image documentation. Segmentation of wound boundaries in images is a key component of the care and diagnosis protocol since it is important to estimate the area of the wound and provide quantitative measurement for the treatment. Unfortunately, this process is very time-consuming and requires a high level of expertise. Recently automatic wound segmentation methods based on deep learning have shown promising performance but require large datasets for training and it is unclear which methods perform better. To address these issues, we propose the Foot Ulcer Segmentation challenge (FUSeg) organized in conjunction with the 2021 International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI). We built a wound image dataset containing 1,210 foot ulcer images collected over 2 years from 889 patients. It is pixel-wise annotated by wound care experts and split into a training set with 1010 images and a testing set with 200 images for evaluation. Teams around the world developed automated methods to predict wound segmentations on the testing set of which annotations were kept private. The predictions were evaluated and ranked based on the average Dice coefficient. The FUSeg challenge remains an open challenge as a benchmark for wound segmentation after the conference.
An Adaptive Neuro-Fuzzy System with Integrated Feature Selection and Rule Extraction for High-Dimensional Classification Problems
Jan 10, 2022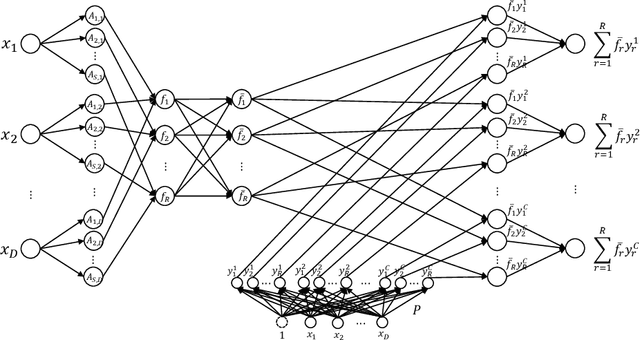
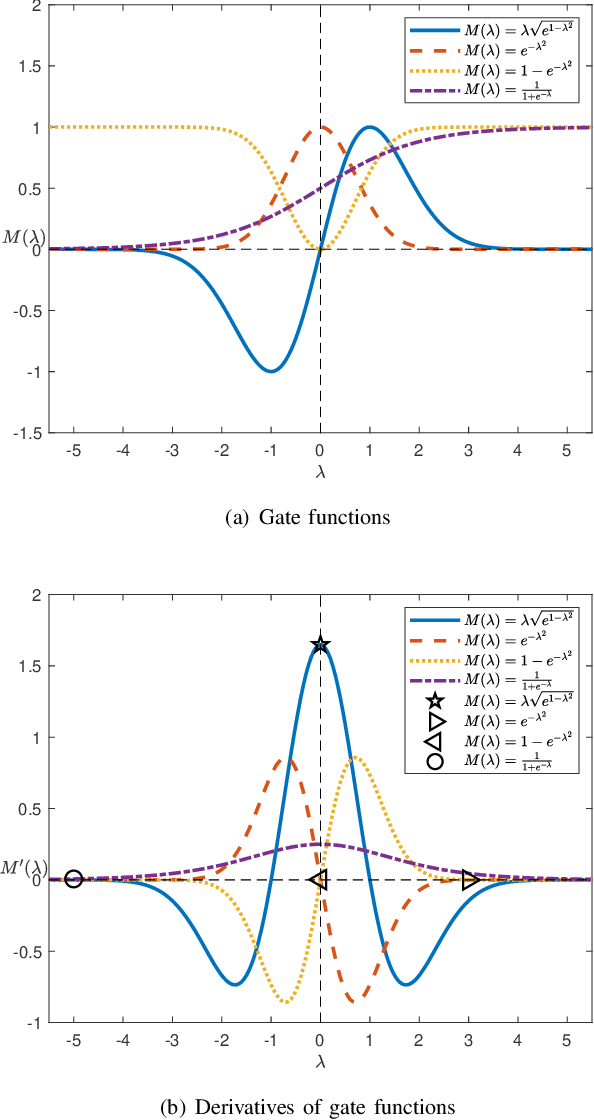
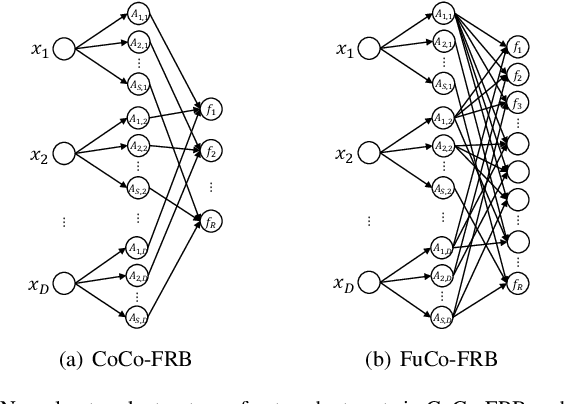
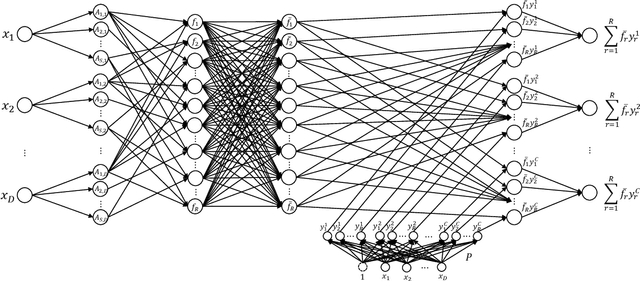
A major limitation of fuzzy or neuro-fuzzy systems is their failure to deal with high-dimensional datasets. This happens primarily due to the use of T-norm, particularly, product or minimum (or a softer version of it). Thus, there are hardly any work dealing with datasets with dimensions more than hundred or so. Here, we propose a neuro-fuzzy framework that can handle datasets with dimensions even more than 7000! In this context, we propose an adaptive softmin (Ada-softmin) which effectively overcomes the drawbacks of ``numeric underflow" and ``fake minimum" that arise for existing fuzzy systems while dealing with high-dimensional problems. We call it an Adaptive Takagi-Sugeno-Kang (AdaTSK) fuzzy system. We then equip the AdaTSK system to perform feature selection and rule extraction in an integrated manner. In this context, a novel gate function is introduced and embedded only in the consequent parts, which can determine the useful features and rules, in two successive phases of learning. Unlike conventional fuzzy rule bases, we design an enhanced fuzzy rule base (En-FRB), which maintains adequate rules but does not grow the number of rules exponentially with dimension that typically happens for fuzzy neural networks. The integrated Feature Selection and Rule Extraction AdaTSK (FSRE-AdaTSK) system consists of three sequential phases: (i) feature selection, (ii) rule extraction, and (iii) fine tuning. The effectiveness of the FSRE-AdaTSK is demonstrated on 19 datasets of which five are in more than 2000 dimension including two with dimension greater than 7000. This may be the first time fuzzy systems are realized for classification involving more than 7000 input features.
Classification of Anuran Frog Species Using Machine Learning
Dec 09, 2021
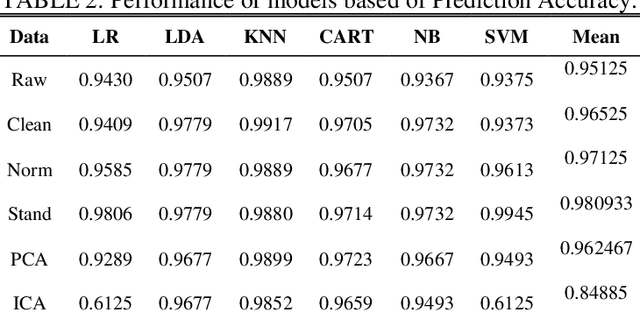
Acoustic classification of frogs has gotten a lot of attention recently due to its potential applicability in ecological investigations. Numerous studies have been presented for identifying frog species, although the majority of recorded species are thought to be monotypic. The purpose of this study is to demonstrate a method for classifying various frog species using an audio recording. To be more exact, continuous frog recordings are cut into audio snippets first (10 seconds). Then, for each ten-second recording, several time-frequency representations are constructed. Following that, rather than using manually created features, Machine Learning methods are employed to classify the frog species. Data reduction techniques; Principal Component Analysis (PCA) and Independent Component Analysis (ICA) are used to extract the most important features before classification. Finally, to validate our classification accuracy, cross validation and prediction accuracy are used. Experimental results show that PCA extracted features that achieved better classification accuracy both with cross validation and prediction accuracy.
On Slowly-varying Non-stationary Bandits
Oct 25, 2021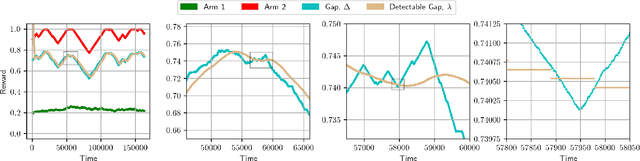
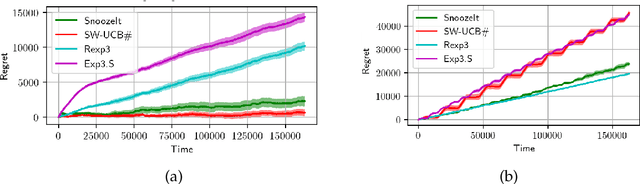
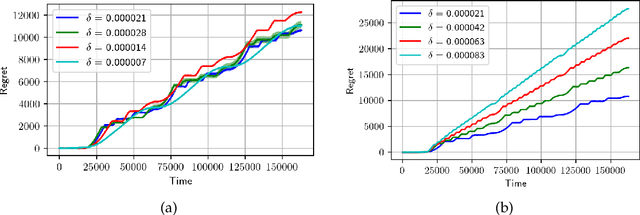
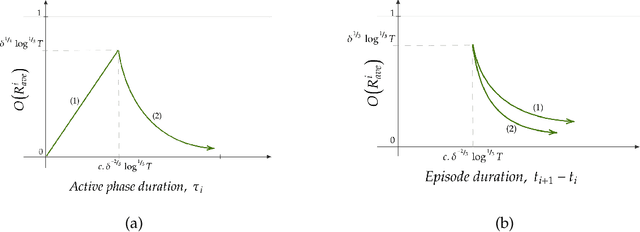
We consider minimisation of dynamic regret in non-stationary bandits with a slowly varying property. Namely, we assume that arms' rewards are stochastic and independent over time, but that the absolute difference between the expected rewards of any arm at any two consecutive time-steps is at most a drift limit $\delta > 0$. For this setting that has not received enough attention in the past, we give a new algorithm which extends naturally the well-known Successive Elimination algorithm to the non-stationary bandit setting. We establish the first instance-dependent regret upper bound for slowly varying non-stationary bandits. The analysis in turn relies on a novel characterization of the instance as a detectable gap profile that depends on the expected arm reward differences. We also provide the first minimax regret lower bound for this problem, enabling us to show that our algorithm is essentially minimax optimal. Also, this lower bound we obtain matches that of the more general total variation-budgeted bandits problem, establishing that the seemingly easier former problem is at least as hard as the more general latter problem in the minimax sense. We complement our theoretical results with experimental illustrations.
Cyberattack Detection in Large-Scale Smart Grids using Chebyshev Graph Convolutional Networks
Dec 25, 2021
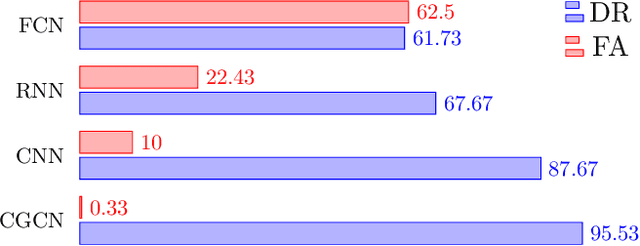
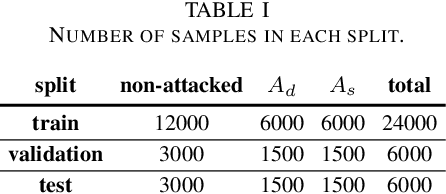
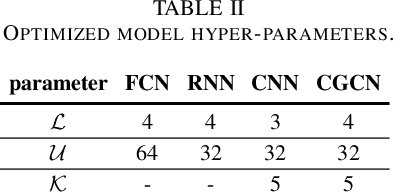
As a highly complex and integrated cyber-physical system, modern power grids are exposed to cyberattacks. False data injection attacks (FDIAs), specifically, represent a major class of cyber threats to smart grids by targeting the measurement data's integrity. Although various solutions have been proposed to detect those cyberattacks, the vast majority of the works have ignored the inherent graph structure of the power grid measurements and validated their detectors only for small test systems with less than a few hundred buses. To better exploit the spatial correlations of smart grid measurements, this paper proposes a deep learning model for cyberattack detection in large-scale AC power grids using Chebyshev Graph Convolutional Networks (CGCN). By reducing the complexity of spectral graph filters and making them localized, CGCN provides a fast and efficient convolution operation to model the graph structural smart grid data. We numerically verify that the proposed CGCN based detector surpasses the state-of-the-art model by 7.86 in detection rate and 9.67 in false alarm rate for a large-scale power grid with 2848 buses. It is notable that the proposed approach detects cyberattacks under 4 milliseconds for a 2848-bus system, which makes it a good candidate for real-time detection of cyberattacks in large systems.
An AI-based Solution for Enhancing Delivery of Digital Learning for Future Teachers
Nov 09, 2021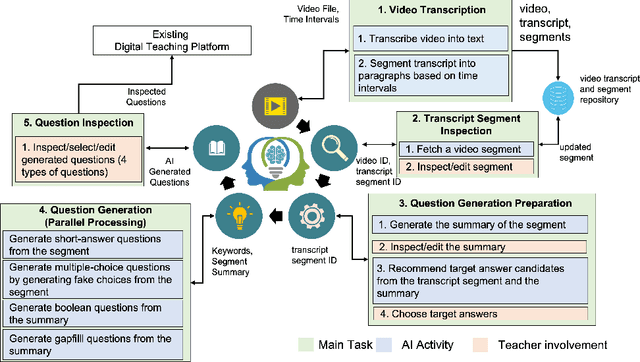

There has been a recent and rapid shift to digital learning hastened by the pandemic but also influenced by ubiquitous availability of digital tools and platforms now, making digital learning ever more accessible. An integral and one of the most difficult part of scaling digital learning and teaching is to be able to assess learner's knowledge and competency. An educator can record a lecture or create digital content that can be delivered to thousands of learners but assessing learners is extremely time consuming. In the paper, we propose an Artificial Intelligence (AI)-based solution namely VidVersityQG for generating questions automatically from pre-recorded video lectures. The solution can automatically generate different types of assessment questions (including short answer, multiple choice, true/false and fill in the blank questions) based on contextual and semantic information inferred from the videos. The proposed solution takes a human-centred approach, wherein teachers are provided the ability to modify/edit any AI generated questions. This approach encourages trust and engagement of teachers in the use and implementation of AI in education. The AI-based solution was evaluated for its accuracy in generating questions by 7 experienced teaching professionals and 117 education videos from multiple domains provided to us by our industry partner VidVersity. VidVersityQG solution showed promising results in generating high-quality questions automatically from video thereby significantly reducing the time and effort for educators in manual question generation.
Predictive Analysis of COVID-19 Time-series Data from Johns Hopkins University
May 14, 2020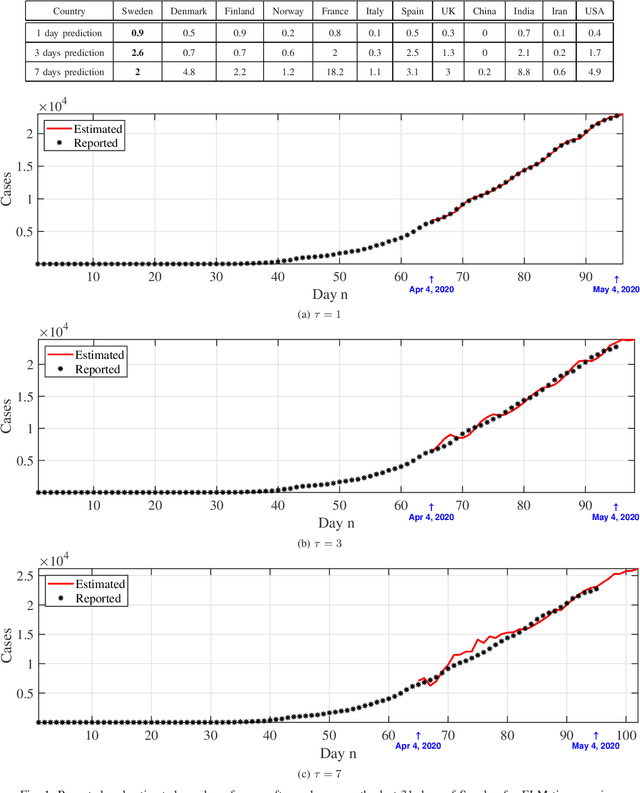
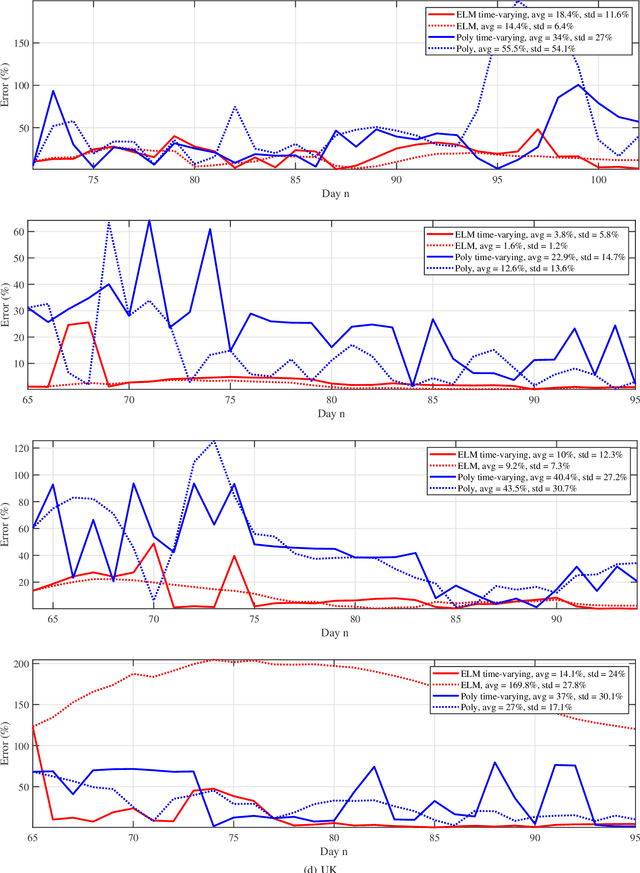
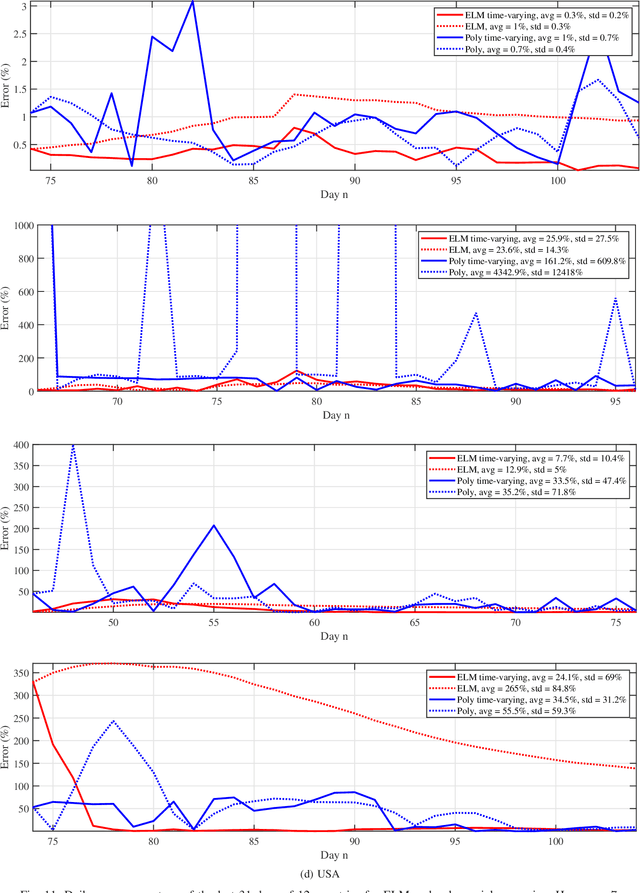
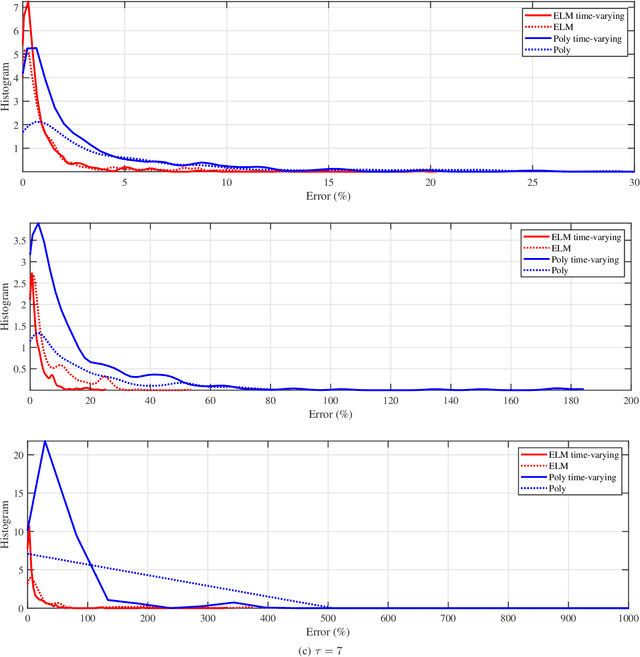
We provide a predictive analysis of the spread of COVID-19, also known as SARS-CoV-2, using the dataset made publicly available online by the Johns Hopkins University. Our main objective is to provide predictions for the number of infected people for different countries. The predictive analysis is done using time-series data transformed on a logarithmic scale. We use two well-known methods for prediction: polynomial regression and neural network. As the number of training data for each country is limited, we use a single-layer neural network called the extreme learning machine (ELM) to avoid over-fitting. Due to the non-stationary nature of the time-series, a sliding window approach is used to provide a more accurate prediction.