 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Twice regularized MDPs and the equivalence between robustness and regularization
Oct 12, 2021

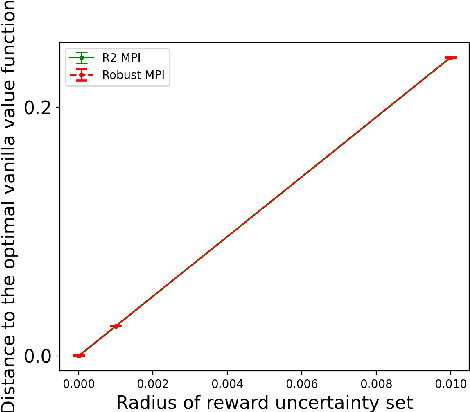
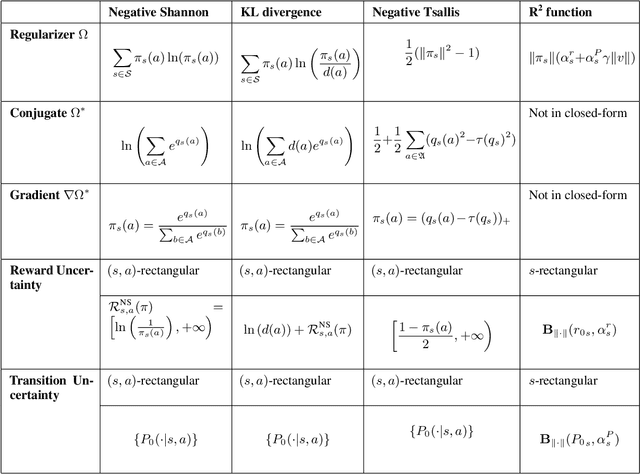
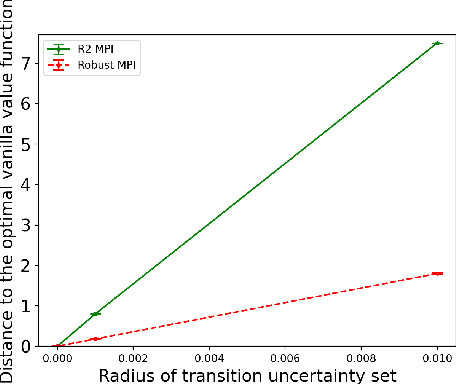
Robust Markov decision processes (MDPs) aim to handle changing or partially known system dynamics. To solve them, one typically resorts to robust optimization methods. However, this significantly increases computational complexity and limits scalability in both learning and planning. On the other hand, regularized MDPs show more stability in policy learning without impairing time complexity. Yet, they generally do not encompass uncertainty in the model dynamics. In this work, we aim to learn robust MDPs using regularization. We first show that regularized MDPs are a particular instance of robust MDPs with uncertain reward. We thus establish that policy iteration on reward-robust MDPs can have the same time complexity as on regularized MDPs. We further extend this relationship to MDPs with uncertain transitions: this leads to a regularization term with an additional dependence on the value function. We finally generalize regularized MDPs to twice regularized MDPs (R${}^2$ MDPs), i.e., MDPs with $\textit{both}$ value and policy regularization. The corresponding Bellman operators enable developing policy iteration schemes with convergence and robustness guarantees. It also reduces planning and learning in robust MDPs to regularized MDPs.
Trajectory PHD and CPHD Filters with Unknown Detection Profile
Nov 06, 2021
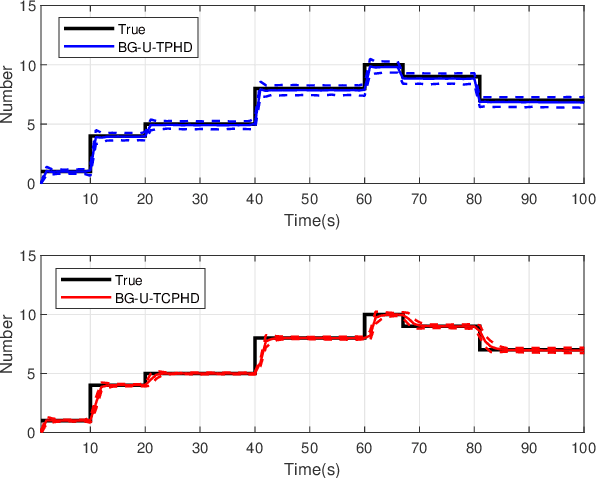
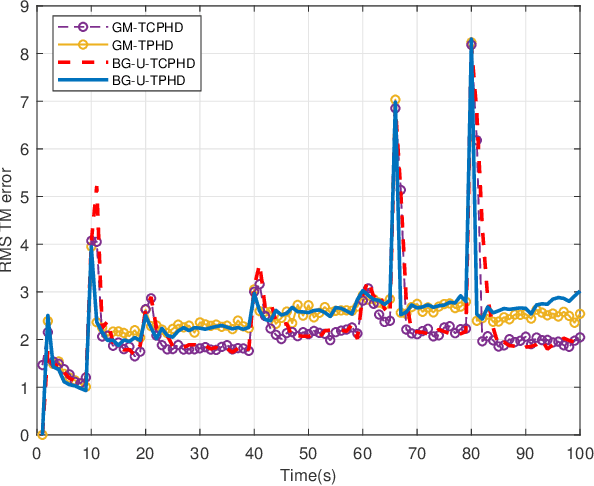
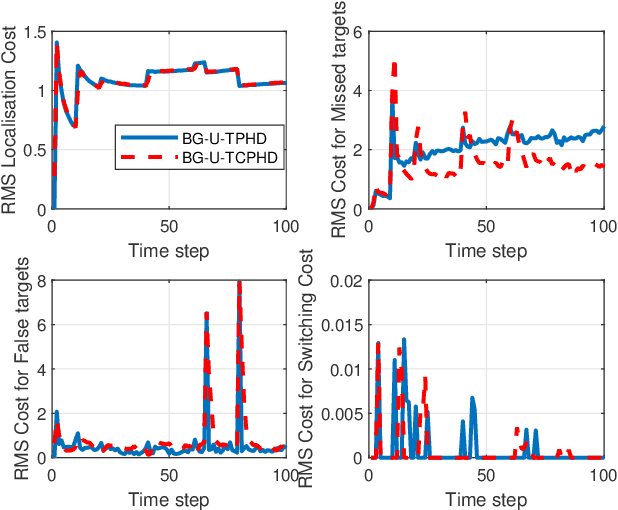
Compared to the probability hypothesis density (PHD) and cardinalized PHD (CPHD) filters, the trajectory PHD (TPHD) and trajectory CPHD (TCPHD) filters are for sets of trajectories, and thus are able to produce trajectory estimates with better estimation performance. In this paper, we develop the TPHD and TCPHD filters which can adaptively learn the history of the unknown target detection probability, and therefore they can perform more robustly in scenarios where targets are with unknown and time-varying detection probabilities. These filters are referred to as the unknown TPHD (U-TPHD) and unknown TCPHD (U-TCPHD) filters.By minimizing the Kullback-Leibler divergence (KLD), the U-TPHD and U-TCPHD filters can obtain, respectively, the best Poisson and independent identically distributed (IID) density approximations over the augmented sets of trajectories. For computational efficiency, we also propose the U-TPHD and U-TCPHD filters that only consider the unknown detection profile at the current time. Specifically, the Beta-Gaussian mixture method is adopted for the implementation of proposed filters, which are referred to as the BG-U-TPHD and BG-U-TCPHD filters. The L-scan approximations of these filters with much lower computational burden are also presented. Finally, various simulation results demonstrate that the BG-U-TPHD and BG-U-TCPHD filters can achieve robust tracking performance to adapt to unknown detection profile. Besides, it also shows that usually a small value of the L-scan approximation can achieve almost full efficiency of both filters but with a much lower computational costs.
A Survey on Legal Question Answering Systems
Oct 12, 2021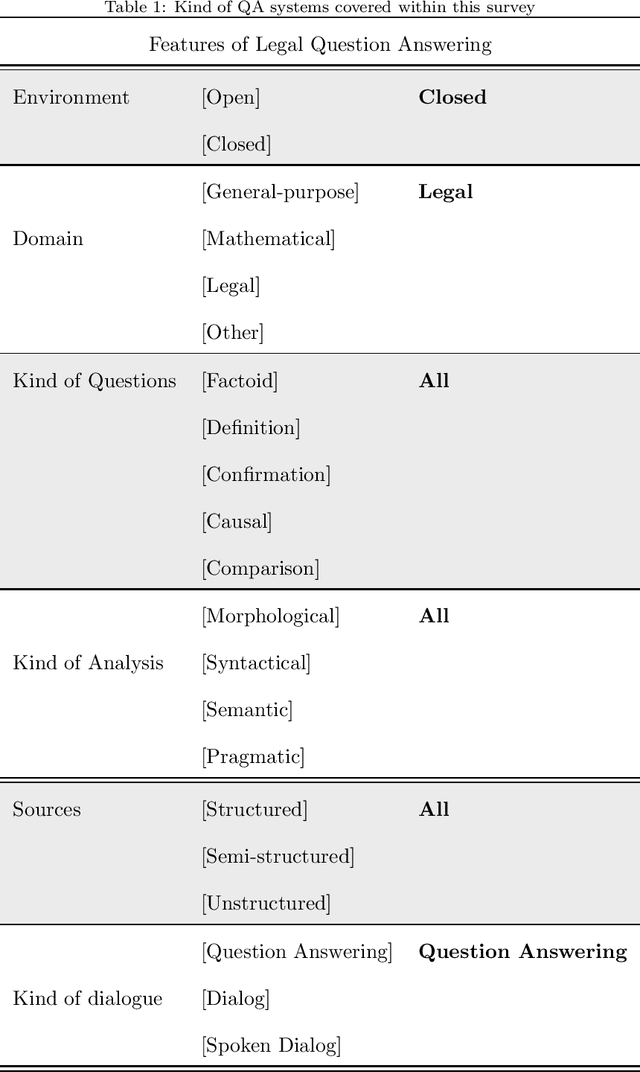
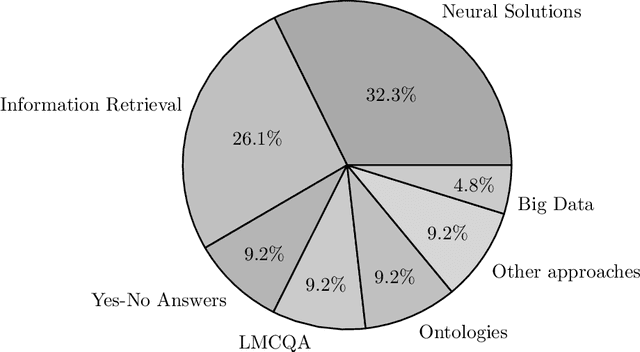
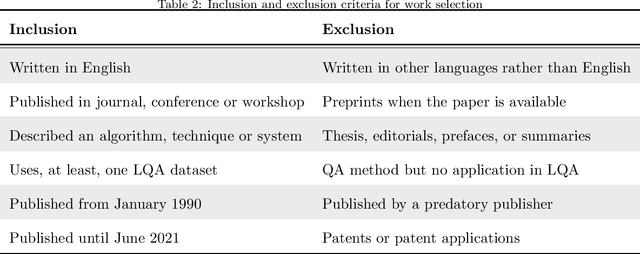
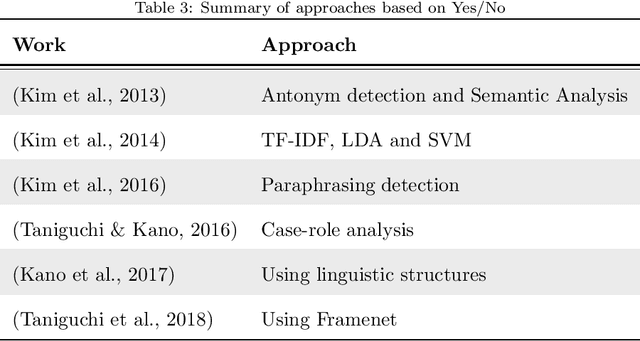
Many legal professionals think that the explosion of information about local, regional, national, and international legislation makes their practice more costly, time-consuming, and even error-prone. The two main reasons for this are that most legislation is usually unstructured, and the tremendous amount and pace with which laws are released causes information overload in their daily tasks. In the case of the legal domain, the research community agrees that a system allowing to generate automatic responses to legal questions could substantially impact many practical implications in daily activities. The degree of usefulness is such that even a semi-automatic solution could significantly help to reduce the workload to be faced. This is mainly because a Question Answering system could be able to automatically process a massive amount of legal resources to answer a question or doubt in seconds, which means that it could save resources in the form of effort, money, and time to many professionals in the legal sector. In this work, we quantitatively and qualitatively survey the solutions that currently exist to meet this challenge.
YOLACT++: Better Real-time Instance Segmentation
Dec 03, 2019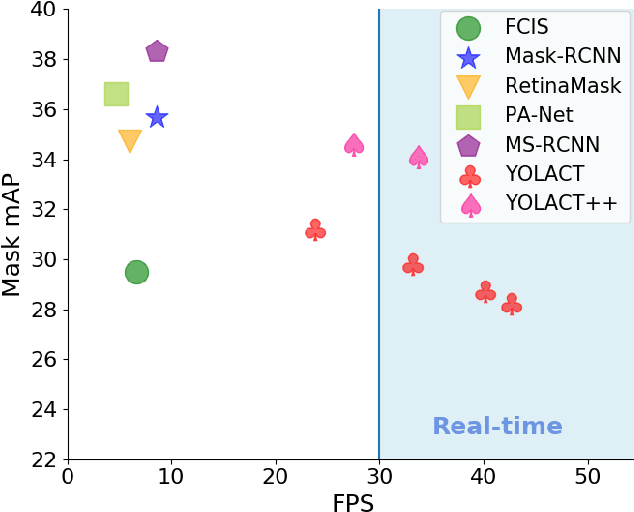
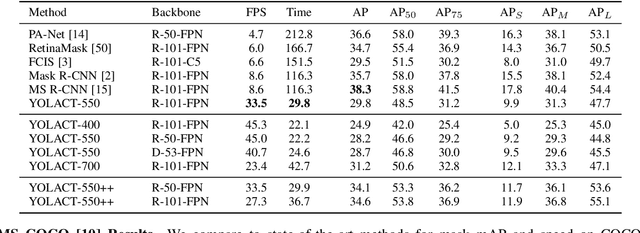
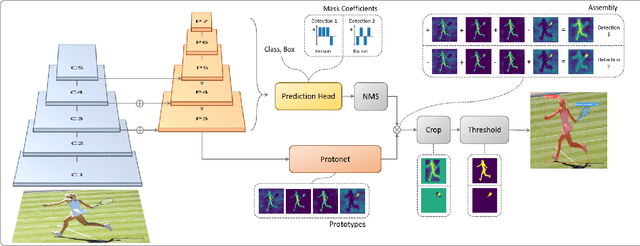

We present a simple, fully-convolutional model for real-time (>30 fps) instance segmentation that achieves competitive results on MS COCO evaluated on a single Titan Xp, which is significantly faster than any previous state-of-the-art approach. Moreover, we obtain this result after training on only one GPU. We accomplish this by breaking instance segmentation into two parallel subtasks: (1) generating a set of prototype masks and (2) predicting per-instance mask coefficients. Then we produce instance masks by linearly combining the prototypes with the mask coefficients. We find that because this process doesn't depend on repooling, this approach produces very high-quality masks and exhibits temporal stability for free. Furthermore, we analyze the emergent behavior of our prototypes and show they learn to localize instances on their own in a translation variant manner, despite being fully-convolutional. We also propose Fast NMS, a drop-in 12 ms faster replacement for standard NMS that only has a marginal performance penalty. Finally, by incorporating deformable convolutions into the backbone network, optimizing the prediction head with better anchor scales and aspect ratios, and adding a novel fast mask re-scoring branch, our YOLACT++ model can achieve 34.1 mAP on MS COCO at 33.5 fps, which is fairly close to the state-of-the-art approaches while still running at real-time.
Reinforcement Learning-Based Coverage Path Planning with Implicit Cellular Decomposition
Oct 18, 2021
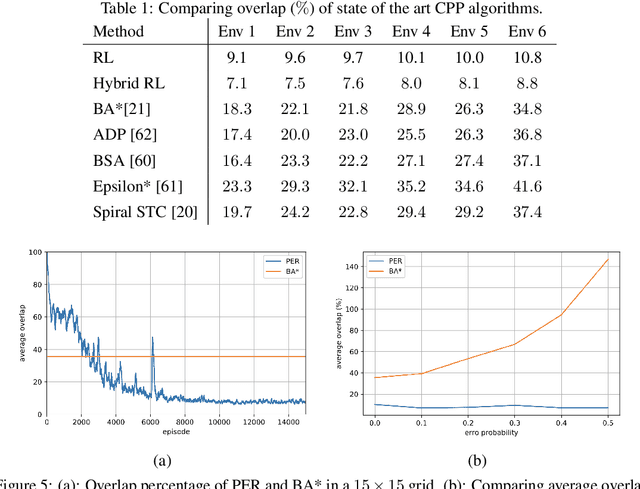
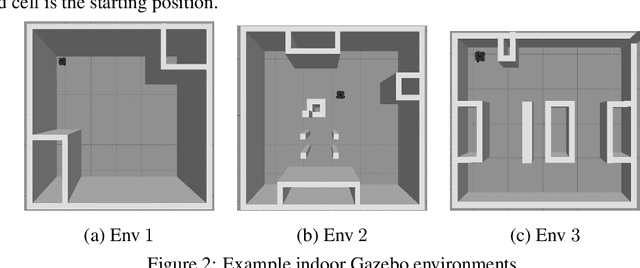
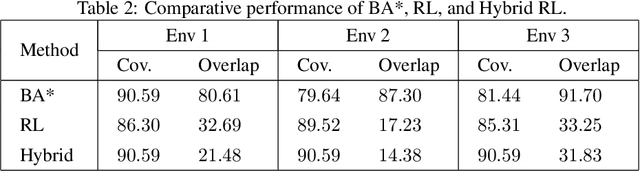
Coverage path planning in a generic known environment is shown to be NP-hard. When the environment is unknown, it becomes more challenging as the robot is required to rely on its online map information built during coverage for planning its path. A significant research effort focuses on designing heuristic or approximate algorithms that achieve reasonable performance. Such algorithms have sub-optimal performance in terms of covering the area or the cost of coverage, e.g., coverage time or energy consumption. In this paper, we provide a systematic analysis of the coverage problem and formulate it as an optimal stopping time problem, where the trade-off between coverage performance and its cost is explicitly accounted for. Next, we demonstrate that reinforcement learning (RL) techniques can be leveraged to solve the problem computationally. To this end, we provide some technical and practical considerations to facilitate the application of the RL algorithms and improve the efficiency of the solutions. Finally, through experiments in grid world environments and Gazebo simulator, we show that reinforcement learning-based algorithms efficiently cover realistic unknown indoor environments, and outperform the current state of the art.
Pattern Recognition in Vital Signs Using Spectrograms
Sep 02, 2021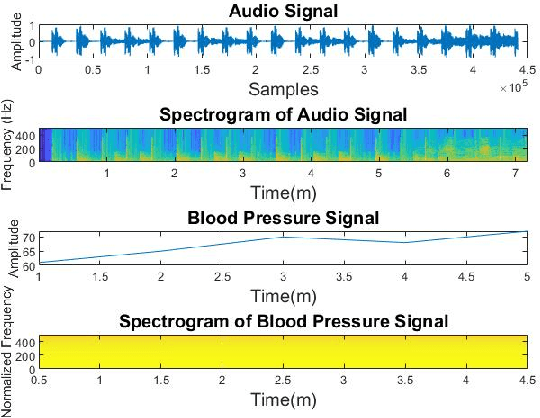
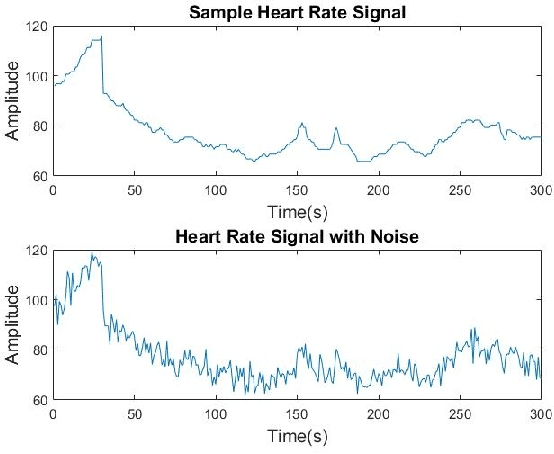
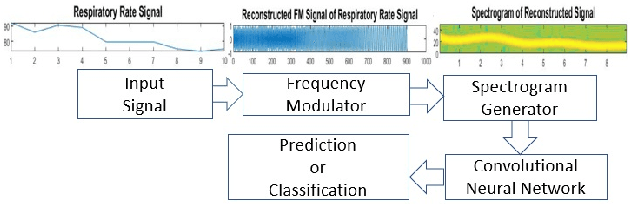
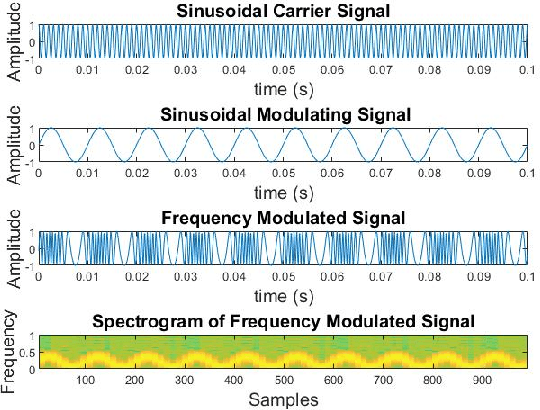
Spectrograms visualize the frequency components of a given signal which may be an audio signal or even a time-series signal. Audio signals have higher sampling rate and high variability of frequency with time. Spectrograms can capture such variations well. But, vital signs which are time-series signals have less sampling frequency and low-frequency variability due to which, spectrograms fail to express variations and patterns. In this paper, we propose a novel solution to introduce frequency variability using frequency modulation on vital signs. Then we apply spectrograms on frequency modulated signals to capture the patterns. The proposed approach has been evaluated on 4 different medical datasets across both prediction and classification tasks. Significant results are found showing the efficacy of the approach for vital sign signals. The results from the proposed approach are promising with an accuracy of 91.55% and 91.67% in prediction and classification tasks respectively.
Adversarial Attacks on Spiking Convolutional Networks for Event-based Vision
Oct 06, 2021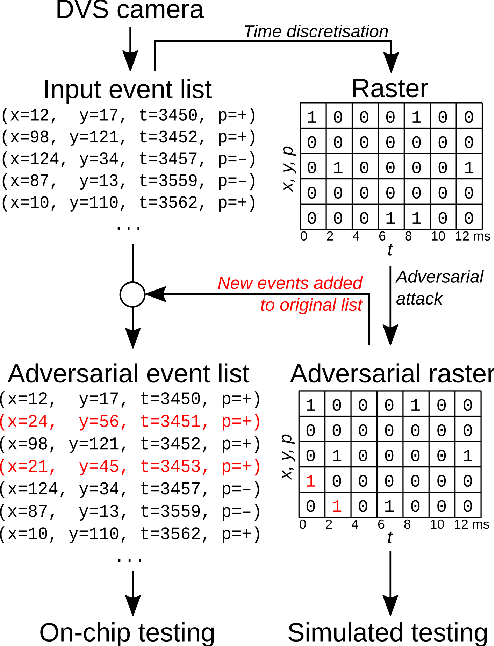
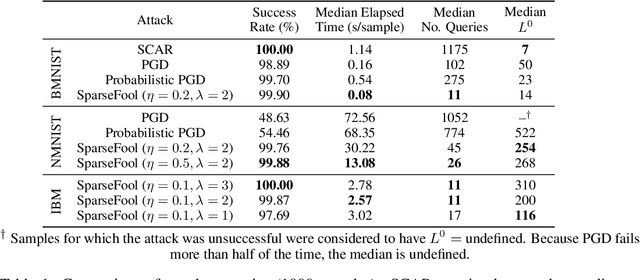


Event-based sensing using dynamic vision sensors is gaining traction in low-power vision applications. Spiking neural networks work well with the sparse nature of event-based data and suit deployment on low-power neuromorphic hardware. Being a nascent field, the sensitivity of spiking neural networks to potentially malicious adversarial attacks has received very little attention so far. In this work, we show how white-box adversarial attack algorithms can be adapted to the discrete and sparse nature of event-based visual data, and to the continuous-time setting of spiking neural networks. We test our methods on the N-MNIST and IBM Gestures neuromorphic vision datasets and show adversarial perturbations achieve a high success rate, by injecting a relatively small number of appropriately placed events. We also verify, for the first time, the effectiveness of these perturbations directly on neuromorphic hardware. Finally, we discuss the properties of the resulting perturbations and possible future directions.
Robust Multi-Robot Trajectory Generation Using Alternating Direction Method of Multiplier
Nov 18, 2021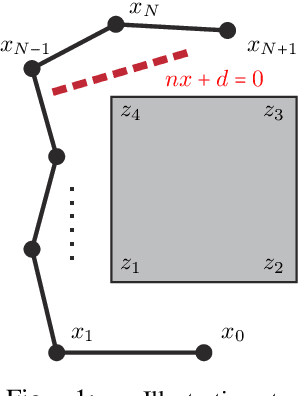
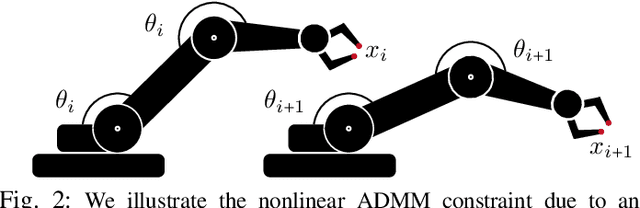
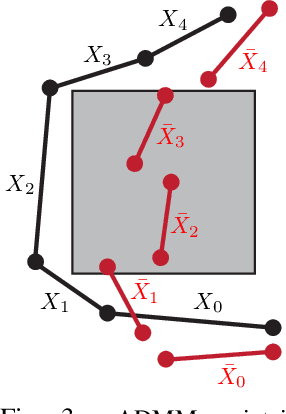
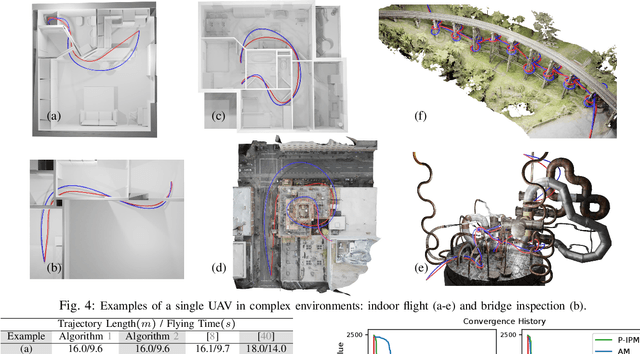
We propose a variant of alternating direction method of multiplier (ADMM) to solve constrained trajectory optimization problems. Our ADMM framework breaks a joint optimization into small sub-problems, leading to a low iteration cost and decentralized parameter updates. Our method inherits the theoretical properties of primal interior point method (P-IPM), i.e., guaranteed collision avoidance and homotopy preservation, while being orders of magnitude faster. We have analyzed the convergence and evaluated our method for time-optimal multi-UAV trajectory optimizations and simultaneous goal-reaching of multiple robot arms, where we take into consider kinematics-, dynamics-limits, and homotopy-preserving collision constraints. Our method highlights 10-100 times speedup, while generating trajectories of comparable qualities as state-of-the-art P-IPM solver.
Risk and optimal policies in bandit experiments
Dec 13, 2021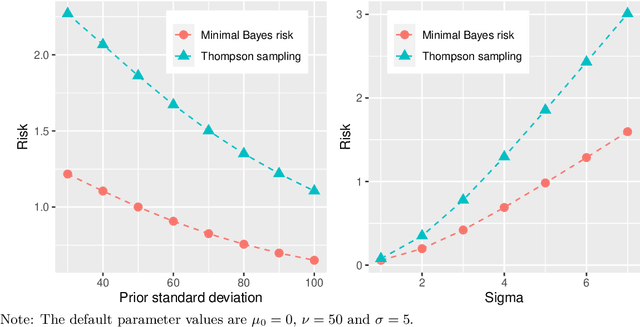
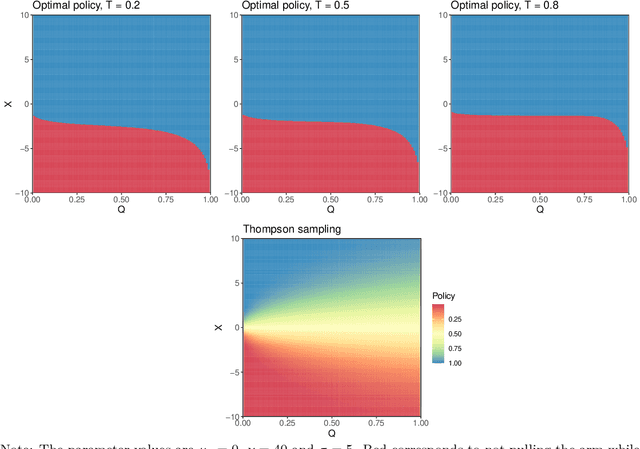
This paper provides a decision theoretic analysis of bandit experiments. The bandit setting corresponds to a dynamic programming problem, but solving this directly is typically infeasible. Working within the framework of diffusion asymptotics, we define a suitable notion of asymptotic Bayes risk for bandit settings. For normally distributed rewards, the minimal Bayes risk can be characterized as the solution to a nonlinear second-order partial differential equation (PDE). Using a limit of experiments approach, we show that this PDE characterization also holds asymptotically under both parametric and non-parametric distribution of the rewards. The approach further describes the state variables it is asymptotically sufficient to restrict attention to, and therefore suggests a practical strategy for dimension reduction. The upshot is that we can approximate the dynamic programming problem defining the bandit setting with a PDE which can be efficiently solved using sparse matrix routines. We derive near-optimal policies from the numerical solutions to these equations. The proposed policies substantially dominate existing methods such Thompson sampling. The framework also allows for substantial generalizations to the bandit problem such as time discounting and pure exploration motives.
InstanceMotSeg: Real-time Instance Motion Segmentation for Autonomous Driving
Aug 16, 2020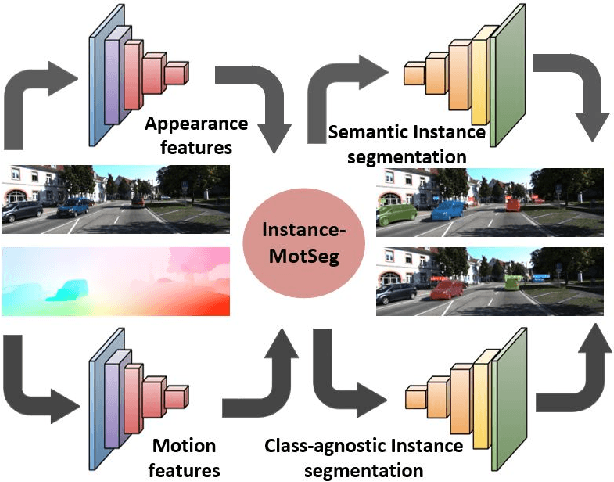
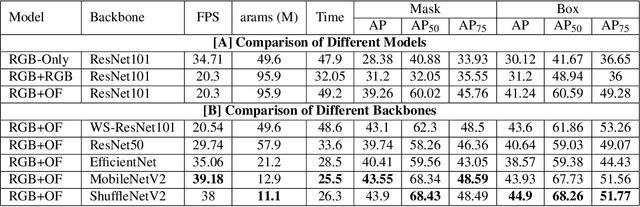
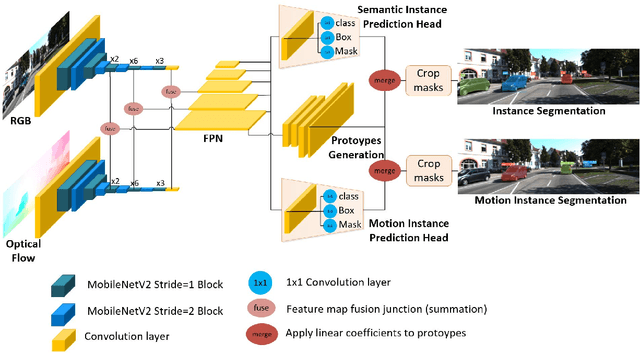
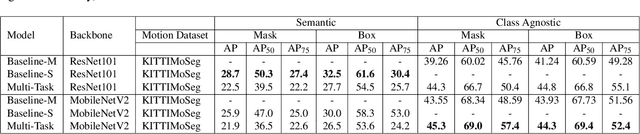
Moving object segmentation is a crucial task for autonomous vehicles as it can be used to segment objects in a class agnostic manner based on its motion cues. It will enable the detection of objects unseen during training (e.g., moose or a construction truck) generically based on their motion. Although pixel-wise motion segmentation has been studied in the literature, it is not dealt with at instance level, which would help separate connected segments of moving objects leading to better trajectory planning. In this paper, we proposed a motion-based instance segmentation task and created a new annotated dataset based on KITTI, which will be released publicly. We make use of the YOLACT model to solve the instance motion segmentation network by feeding inflow and image as input and instance motion masks as output. We extend it to a multi-task model that learns semantic and motion instance segmentation in a computationally efficient manner. Our model is based on sharing a prototype generation network between the two tasks and learning separate prototype coefficients per task. To obtain real-time performance, we study different efficient encoders and obtain 39 fps on a Titan Xp GPU using MobileNetV2 with an improvement of 10% mAP relative to the baseline. A video demonstration of our work is available in https://youtu.be/CWGZibugD9g.