 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
C$^2$-Rec: An Effective Consistency Constraint for Sequential Recommendation
Dec 13, 2021
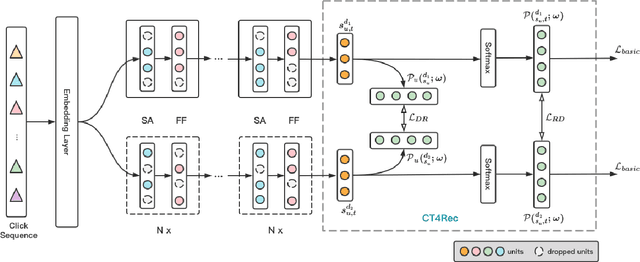
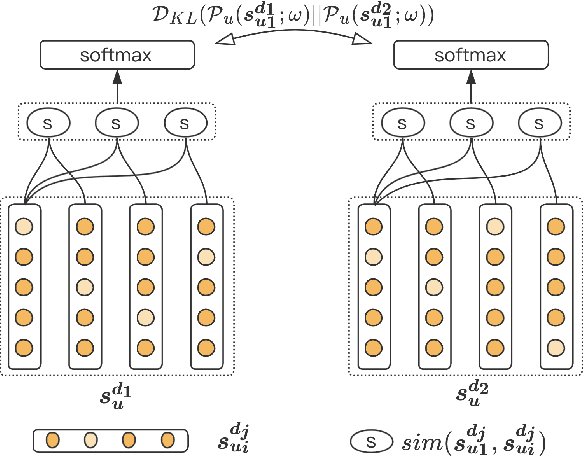

Sequential recommendation methods play an important role in real-world recommender systems. These systems are able to catch user preferences by taking advantage of historical records and then performing recommendations. Contrastive learning(CL) is a cutting-edge technology that can assist us in obtaining informative user representations, but these CL-based models need subtle negative sampling strategies, tedious data augmentation methods, and heavy hyper-parameters tuning work. In this paper, we introduce another way to generate better user representations and recommend more attractive items to users. Particularly, we put forward an effective \textbf{C}onsistency \textbf{C}onstraint for sequential \textbf{Rec}ommendation(C$^2$-Rec) in which only two extra training objectives are used without any structural modifications and data augmentation strategies. Substantial experiments have been conducted on three benchmark datasets and one real industrial dataset, which proves that our proposed method outperforms SOTA models substantially. Furthermore, our method needs much less training time than those CL-based models. Online AB-test on real-world recommendation systems also achieves 10.141\% improvement on the click-through rate and 10.541\% increase on the average click number per capita. The code is available at \url{https://github.com/zhengrongqin/C2-Rec}.
Suppressing Static Visual Cues via Normalizing Flows for Self-Supervised Video Representation Learning
Dec 08, 2021
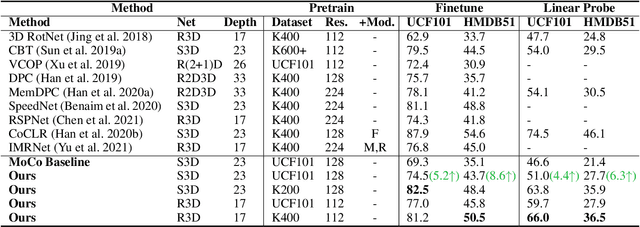

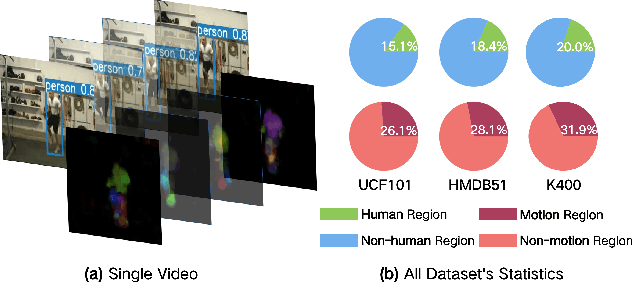
Despite the great progress in video understanding made by deep convolutional neural networks, feature representation learned by existing methods may be biased to static visual cues. To address this issue, we propose a novel method to suppress static visual cues (SSVC) based on probabilistic analysis for self-supervised video representation learning. In our method, video frames are first encoded to obtain latent variables under standard normal distribution via normalizing flows. By modelling static factors in a video as a random variable, the conditional distribution of each latent variable becomes shifted and scaled normal. Then, the less-varying latent variables along time are selected as static cues and suppressed to generate motion-preserved videos. Finally, positive pairs are constructed by motion-preserved videos for contrastive learning to alleviate the problem of representation bias to static cues. The less-biased video representation can be better generalized to various downstream tasks. Extensive experiments on publicly available benchmarks demonstrate that the proposed method outperforms the state of the art when only single RGB modality is used for pre-training.
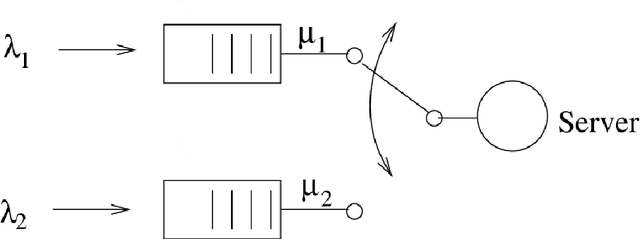
Solving the non-preemptive two queue polling model with generally distributed service and switch-over durations and Poisson arrivals as a Semi-Markov Decision Process
Dec 13, 2021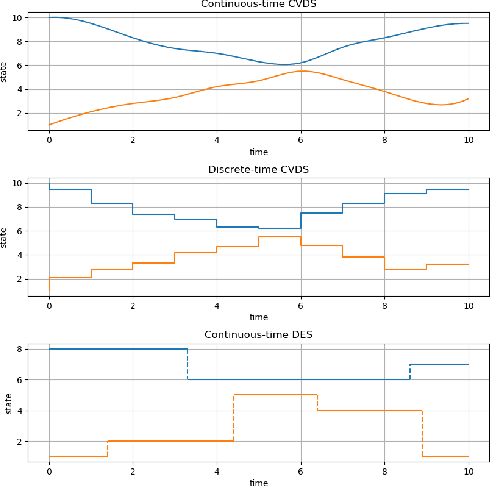
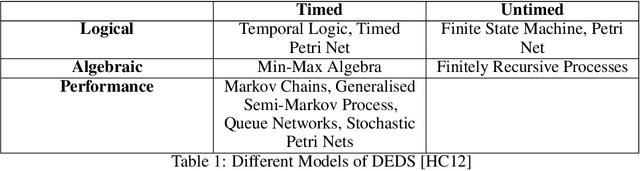
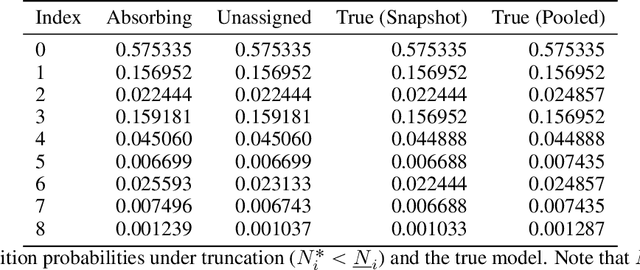
The polling system with switch-over durations is a useful model with several practical applications. It is classified as a Discrete Event Dynamic System (DEDS) for which no one agreed upon modelling approach exists. Furthermore, DEDS are quite complex. To date, the most sophisticated approach to modelling the polling system of interest has been a Continuous-time Markov Decision Process (CTMDP). This paper presents a Semi-Markov Decision Process (SMDP) formulation of the polling system as to introduce additional modelling power. Such power comes at the expense of truncation errors and expensive numerical integrals which naturally leads to the question of whether the SMDP policy provides a worthwhile advantage. To further add to this scenario, it is shown how sparsity can be exploited in the CTMDP to develop a computationally efficient model. The discounted performance of the SMDP and CTMDP policies are evaluated using a Semi-Markov Process simulator. The two policies are accompanied by a heuristic policy specifically developed for this polling system a well as an exhaustive service policy. Parametric and non-parametric hypothesis tests are used to test whether differences in performance are statistically significant.
A Deep Learning Based Multitask Network for Respiration Rate Estimation -- A Practical Perspective
Dec 13, 2021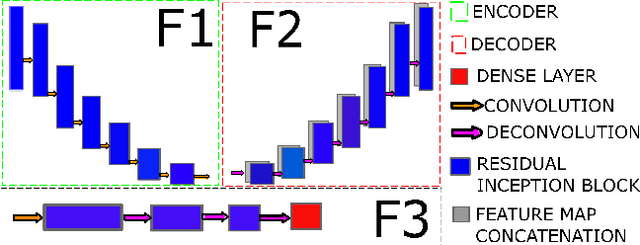
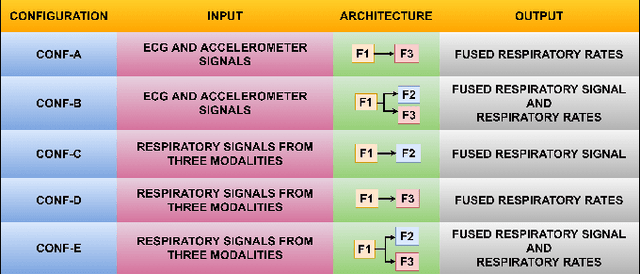
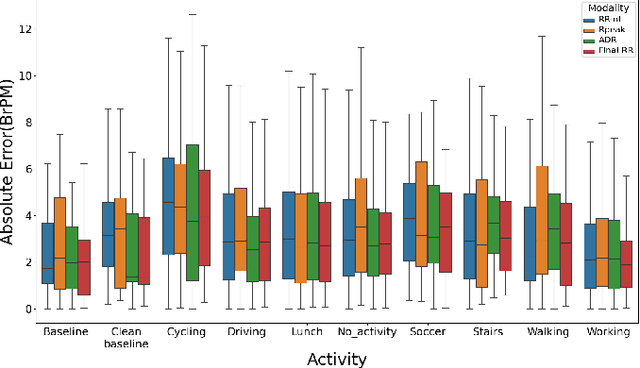
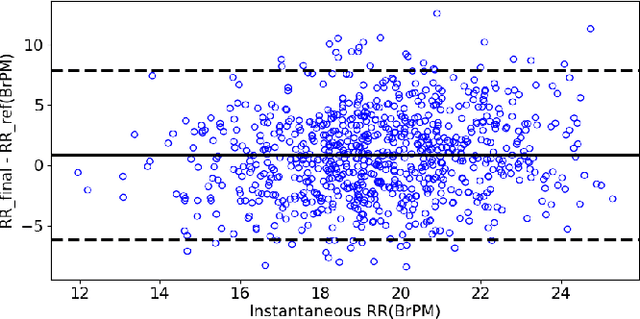
The exponential rise in wearable sensors has garnered significant interest in assessing the physiological parameters during day-to-day activities. Respiration rate is one of the vital parameters used in the performance assessment of lifestyle activities. However, obtrusive setup for measurement, motion artifacts, and other noises complicate the process. This paper presents a multitasking architecture based on Deep Learning (DL) for estimating instantaneous and average respiration rate from ECG and accelerometer signals, such that it performs efficiently under daily living activities like cycling, walking, etc. The multitasking network consists of a combination of Encoder-Decoder and Encoder-IncResNet, to fetch the average respiration rate and the respiration signal. The respiration signal can be leveraged to obtain the breathing peaks and instantaneous breathing cycles. Mean absolute error(MAE), Root mean square error (RMSE), inference time, and parameter count analysis has been used to compare the network with the current state of art Machine Learning (ML) model and other DL models developed in previous studies. Other DL configurations based on a variety of inputs are also developed as a part of the work. The proposed model showed better overall accuracy and gave better results than individual modalities during different activities.
Control of over-redundant cooperative manipulation via sampled communication
Dec 02, 2021
In this work we consider the problem of mobile robots that need to manipulate/transport an object via cables or robotic arms. We consider the scenario where the number of manipulating robots is redundant, i.e. a desired object configuration can be obtained by different configurations of the robots. The objective of this work is to show that communication can be used to implement cooperative local feedback controllers in the robots to improve disturbance rejection and reduce structural stress in the object. In particular we consider the realistic scenario where measurements are sampled and transmitted over wireless, and the sampling period is comparable with the system dynamics time constants. We first propose a kinematic model which is consistent with the overall systems dynamics under high-gain control and then we provide sufficient conditions for the exponential stability and monotonic decrease of the configuration error under different norms. Finally, we test the proposed controllers on the full dynamical systems showing the benefit of local communication.
Distributed Estimation of Sparse Inverse Covariances
Sep 30, 2021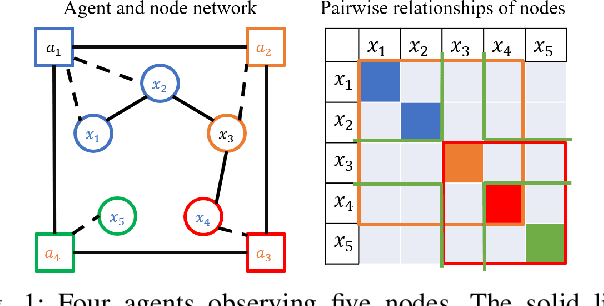
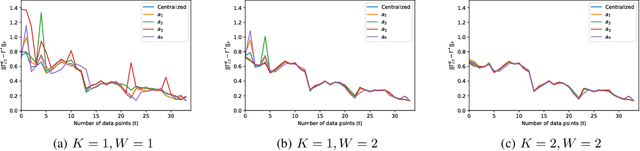
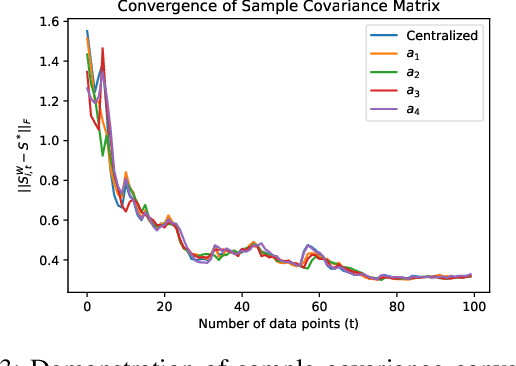
Learning the relationships between various entities from time-series data is essential in many applications. Gaussian graphical models have been studied to infer these relationships. However, existing algorithms process data in a batch at a central location, limiting their applications in scenarios where data is gathered by different agents. In this paper, we propose a distributed sparse inverse covariance algorithm to learn the network structure (i.e., dependencies among observed entities) in real-time from data collected by distributed agents. Our approach is built on an online graphical alternating minimization algorithm, augmented with a consensus term that allows agents to learn the desired structure cooperatively. We allow the system designer to select the number of communication rounds and optimization steps per data point. We characterize the rate of convergence of our algorithm and provide simulations on synthetic datasets.
Improved skin lesion recognition by a Self-Supervised Curricular Deep Learning approach
Dec 22, 2021
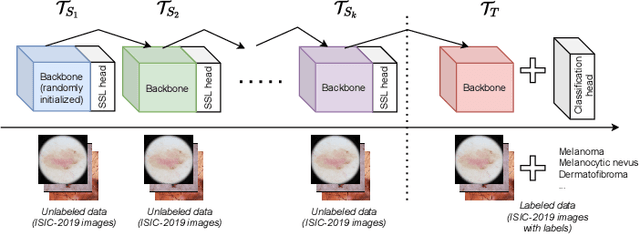
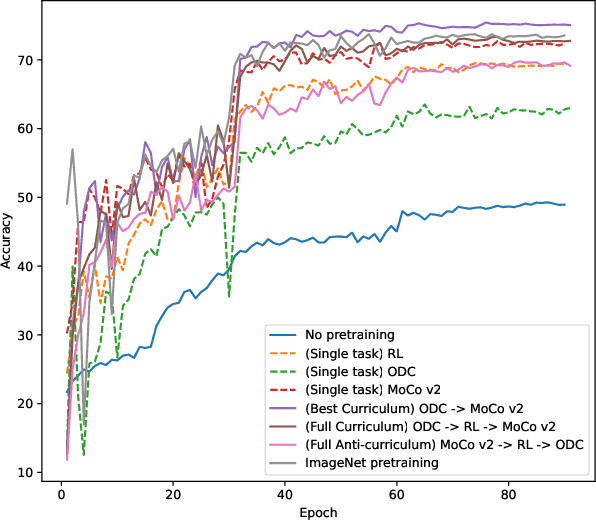
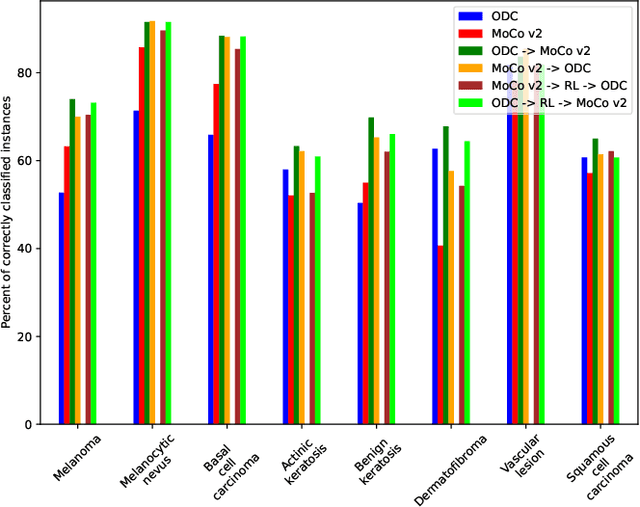
State-of-the-art deep learning approaches for skin lesion recognition often require pretraining on larger and more varied datasets, to overcome the generalization limitations derived from the reduced size of the skin lesion imaging datasets. ImageNet is often used as the pretraining dataset, but its transferring potential is hindered by the domain gap between the source dataset and the target dermatoscopic scenario. In this work, we introduce a novel pretraining approach that sequentially trains a series of Self-Supervised Learning pretext tasks and only requires the unlabeled skin lesion imaging data. We present a simple methodology to establish an ordering that defines a pretext task curriculum. For the multi-class skin lesion classification problem, and ISIC-2019 dataset, we provide experimental evidence showing that: i) a model pretrained by a curriculum of pretext tasks outperforms models pretrained by individual pretext tasks, and ii) a model pretrained by the optimal pretext task curriculum outperforms a model pretrained on ImageNet. We demonstrate that this performance gain is related to the fact that the curriculum of pretext tasks better focuses the attention of the final model on the skin lesion. Beyond performance improvement, this strategy allows for a large reduction in the training time with respect to ImageNet pretraining, which is especially advantageous for network architectures tailored for a specific problem.
Developing and Deploying Machine Learning Pipelines against Real-Time Image Streams from the PACS
Apr 20, 2020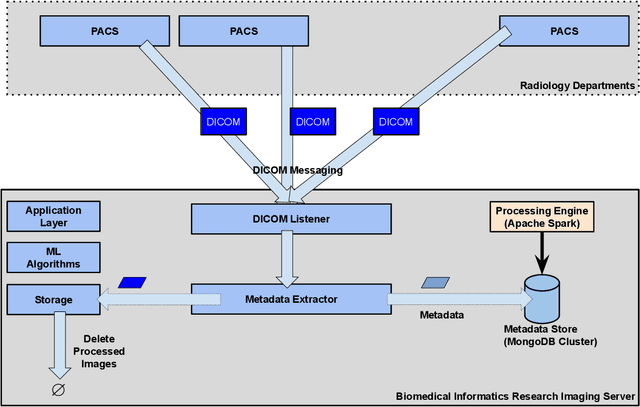
Executing machine learning (ML) pipelines on radiology images is hard due to limited computing resources in clinical environments, whereas running them in research clusters in real-time requires efficient data transfer capabilities. We propose Niffler, an integrated ML framework that runs in research clusters that receives radiology images in real-time from hospitals' Picture Archiving and Communication Systems (PACS). Niffler consists of an inter-domain data streaming approach that exploits the Digital Imaging and Communications in Medicine (DICOM) protocol to fetch data from the PACS to the data processing servers for executing the ML pipelines. It provides metadata extraction capabilities and Application programming interfaces (APIs) to apply filters on the DICOM images and run the ML pipelines. The outcomes of the ML pipelines can then be shared back with the end-users in a de-identified manner. Evaluations on the Niffler prototype highlight the feasibility and efficiency in running the ML pipelines in real-time from a research cluster on the images received in real-time from hospital PACS.
FAST-RIR: Fast neural diffuse room impulse response generator
Oct 07, 2021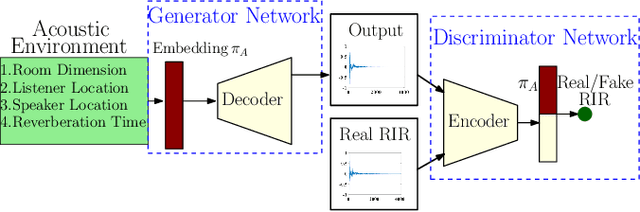
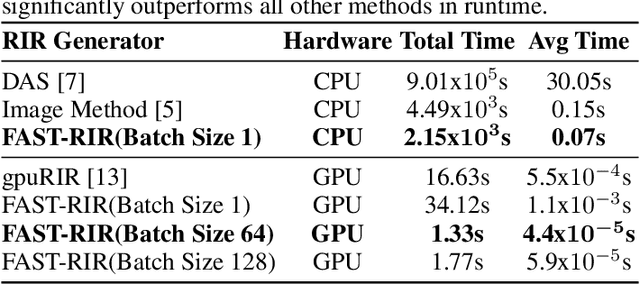

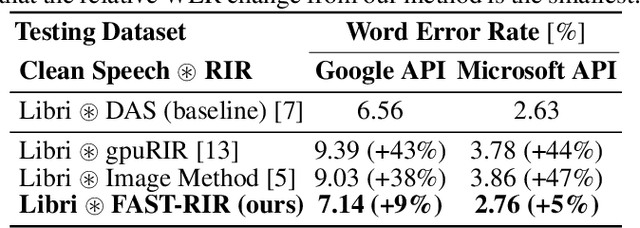
We present a neural-network-based fast diffuse room impulse response generator (FAST-RIR) for generating room impulse responses (RIRs) for a given acoustic environment. Our FAST-RIR takes rectangular room dimensions, listener and speaker positions, and reverberation time as inputs and generates specular and diffuse reflections for a given acoustic environment. Our FAST-RIR is capable of generating RIRs for a given input reverberation time with an average error of 0.02s. We evaluate our generated RIRs in automatic speech recognition (ASR) applications using Google Speech API, Microsoft Speech API, and Kaldi tools. We show that our proposed FAST-RIR with batch size 1 is 400 times faster than a state-of-the-art diffuse acoustic simulator (DAS) on a CPU and gives similar performance to DAS in ASR experiments. Our FAST-RIR is 12 times faster than an existing GPU-based RIR generator (gpuRIR). We show that our FAST-RIR outperforms gpuRIR by 2.5% in an AMI far-field ASR benchmark.
An Informative Tracking Benchmark
Dec 13, 2021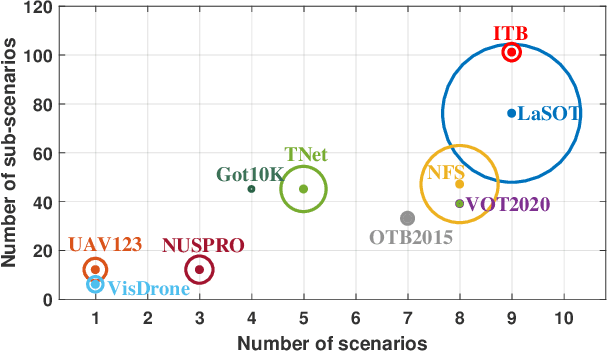
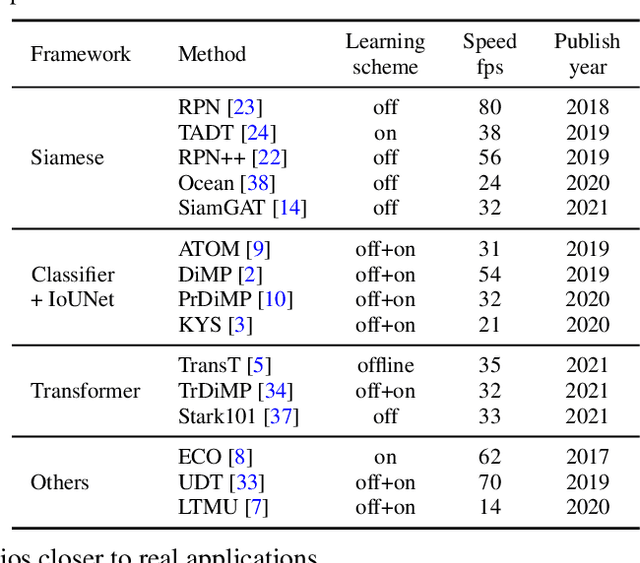
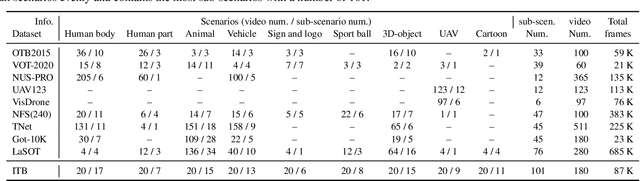
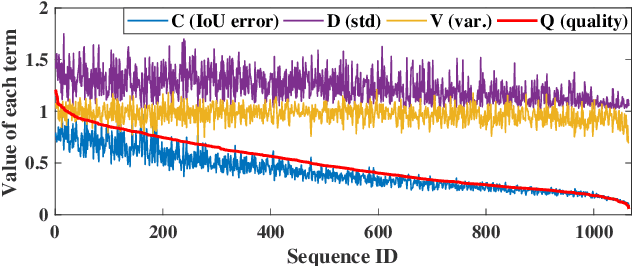
Along with the rapid progress of visual tracking, existing benchmarks become less informative due to redundancy of samples and weak discrimination between current trackers, making evaluations on all datasets extremely time-consuming. Thus, a small and informative benchmark, which covers all typical challenging scenarios to facilitate assessing the tracker performance, is of great interest. In this work, we develop a principled way to construct a small and informative tracking benchmark (ITB) with 7% out of 1.2 M frames of existing and newly collected datasets, which enables efficient evaluation while ensuring effectiveness. Specifically, we first design a quality assessment mechanism to select the most informative sequences from existing benchmarks taking into account 1) challenging level, 2) discriminative strength, 3) and density of appearance variations. Furthermore, we collect additional sequences to ensure the diversity and balance of tracking scenarios, leading to a total of 20 sequences for each scenario. By analyzing the results of 15 state-of-the-art trackers re-trained on the same data, we determine the effective methods for robust tracking under each scenario and demonstrate new challenges for future research direction in this field.