 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Tackling Dynamics in Federated Incremental Learning with Variational Embedding Rehearsal
Oct 19, 2021
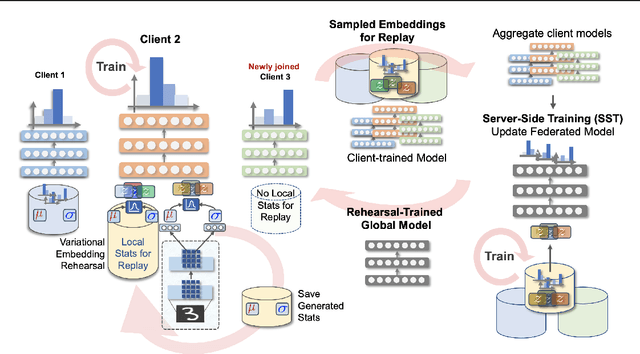
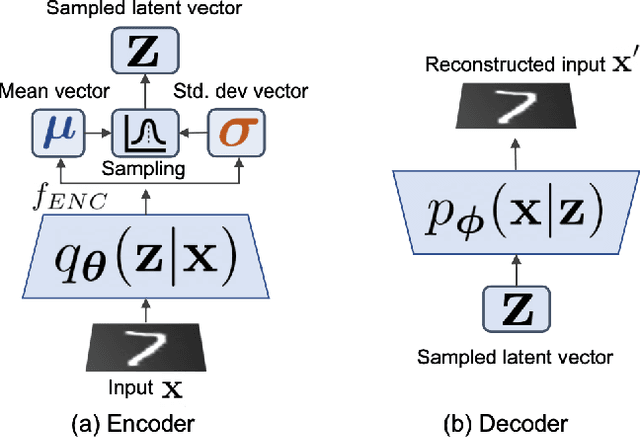
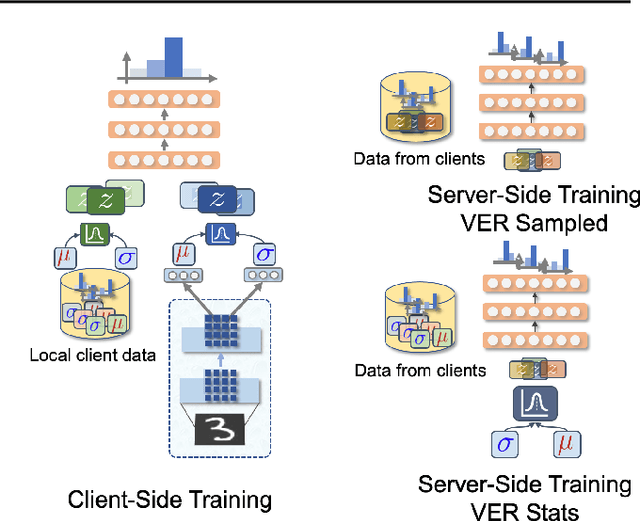
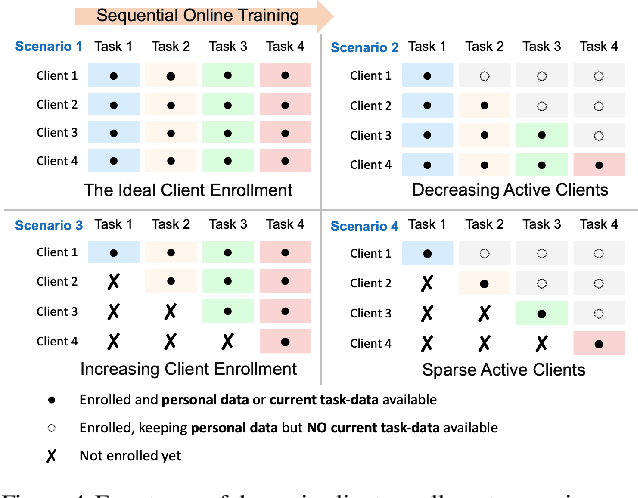
Federated Learning is a fast growing area of ML where the training datasets are extremely distributed, all while dynamically changing over time. Models need to be trained on clients' devices without any guarantees for either homogeneity or stationarity of the local private data. The need for continual training has also risen, due to the ever-increasing production of in-task data. However, pursuing both directions at the same time is challenging, since client data privacy is a major constraint, especially for rehearsal methods. Herein, we propose a novel algorithm to address the incremental learning process in an FL scenario, based on realistic client enrollment scenarios where clients can drop in or out dynamically. We first propose using deep Variational Embeddings that secure the privacy of the client data. Second, we propose a server-side training method that enables a model to rehearse the previously learnt knowledge. Finally, we investigate the performance of federated incremental learning in dynamic client enrollment scenarios. The proposed method shows parity with offline training on domain-incremental learning, addressing challenges in both the dynamic enrollment of clients and the domain shifting of client data.
Finding General Equilibria in Many-Agent Economic Simulations Using Deep Reinforcement Learning
Jan 03, 2022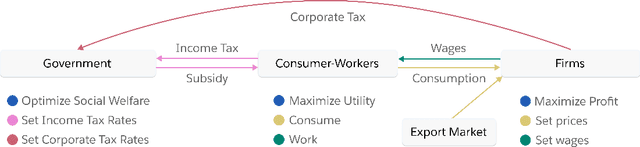

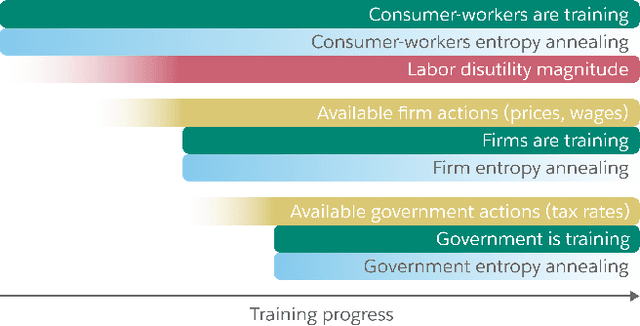
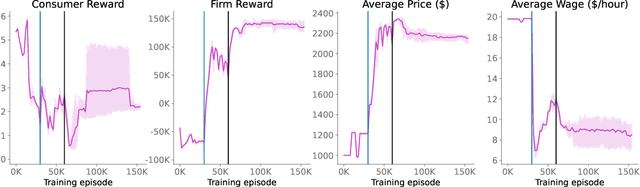
Real economies can be seen as a sequential imperfect-information game with many heterogeneous, interacting strategic agents of various agent types, such as consumers, firms, and governments. Dynamic general equilibrium models are common economic tools to model the economic activity, interactions, and outcomes in such systems. However, existing analytical and computational methods struggle to find explicit equilibria when all agents are strategic and interact, while joint learning is unstable and challenging. Amongst others, a key reason is that the actions of one economic agent may change the reward function of another agent, e.g., a consumer's expendable income changes when firms change prices or governments change taxes. We show that multi-agent deep reinforcement learning (RL) can discover stable solutions that are epsilon-Nash equilibria for a meta-game over agent types, in economic simulations with many agents, through the use of structured learning curricula and efficient GPU-only simulation and training. Conceptually, our approach is more flexible and does not need unrealistic assumptions, e.g., market clearing, that are commonly used for analytical tractability. Our GPU implementation enables training and analyzing economies with a large number of agents within reasonable time frames, e.g., training completes within a day. We demonstrate our approach in real-business-cycle models, a representative family of DGE models, with 100 worker-consumers, 10 firms, and a government who taxes and redistributes. We validate the learned meta-game epsilon-Nash equilibria through approximate best-response analyses, show that RL policies align with economic intuitions, and that our approach is constructive, e.g., by explicitly learning a spectrum of meta-game epsilon-Nash equilibria in open RBC models.
Multi-Robot On-site Shared Analytics Information and Computing
Dec 13, 2021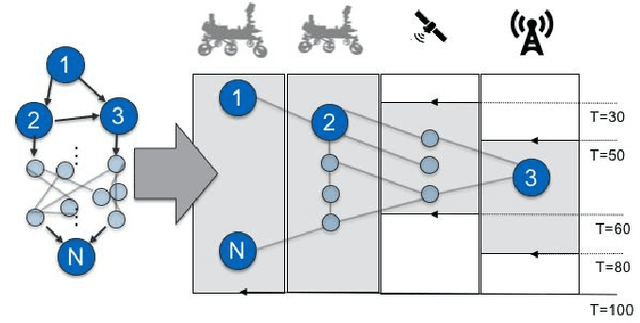
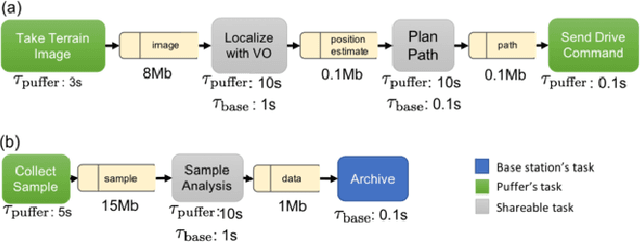

Computation load-sharing across a network of heterogeneous robots is a promising approach to increase robots capabilities and efficiency as a team in extreme environments. However, in such environments, communication links may be intermittent and connections to the cloud or internet may be nonexistent. In this paper we introduce a communication-aware, computation task scheduling problem for multi-robot systems and propose an integer linear program (ILP) that optimizes the allocation of computational tasks across a network of heterogeneous robots, accounting for the networked robots' computational capabilities and for available (and possibly time-varying) communication links. We consider scheduling of a set of inter-dependent required and optional tasks modeled by a dependency graph. We present a consensus-backed scheduling architecture for shared-world, distributed systems. We validate the ILP formulation and the distributed implementation in different computation platforms and in simulated scenarios with a bias towards lunar or planetary exploration scenarios. Our results show that the proposed implementation can optimize schedules to allow a threefold increase the amount of rewarding tasks performed (e.g., science measurements) compared to an analogous system with no computational load-sharing.
Developing and Deploying Machine Learning Pipelines against Real-Time Image Streams from the PACS
Apr 20, 2020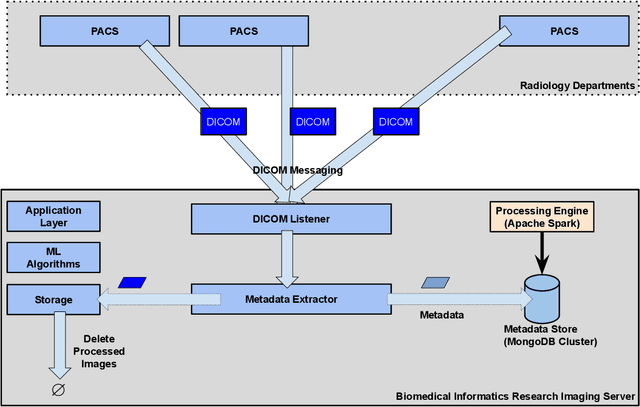
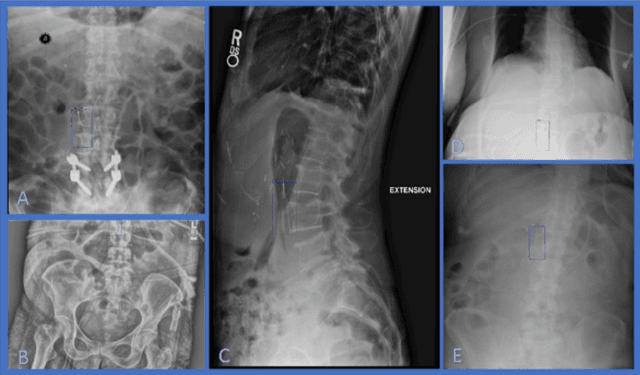
Executing machine learning (ML) pipelines on radiology images is hard due to limited computing resources in clinical environments, whereas running them in research clusters in real-time requires efficient data transfer capabilities. We propose Niffler, an integrated ML framework that runs in research clusters that receives radiology images in real-time from hospitals' Picture Archiving and Communication Systems (PACS). Niffler consists of an inter-domain data streaming approach that exploits the Digital Imaging and Communications in Medicine (DICOM) protocol to fetch data from the PACS to the data processing servers for executing the ML pipelines. It provides metadata extraction capabilities and Application programming interfaces (APIs) to apply filters on the DICOM images and run the ML pipelines. The outcomes of the ML pipelines can then be shared back with the end-users in a de-identified manner. Evaluations on the Niffler prototype highlight the feasibility and efficiency in running the ML pipelines in real-time from a research cluster on the images received in real-time from hospital PACS.
Densely-Populated Traffic Detection using YOLOv5 and Non-Maximum Suppression Ensembling
Aug 27, 2021Vehicular object detection is the heart of any intelligent traffic system. It is essential for urban traffic management. R-CNN, Fast R-CNN, Faster R-CNN and YOLO were some of the earlier state-of-the-art models. Region based CNN methods have the problem of higher inference time which makes it unrealistic to use the model in real-time. YOLO on the other hand struggles to detect small objects that appear in groups. In this paper, we propose a method that can locate and classify vehicular objects from a given densely crowded image using YOLOv5. The shortcoming of YOLO was solved my ensembling 4 different models. Our proposed model performs well on images taken from both top view and side view of the street in both day and night. The performance of our proposed model was measured on Dhaka AI dataset which contains densely crowded vehicular images. Our experiment shows that our model achieved mAP@0.5 of 0.458 with inference time of 0.75 sec which outperforms other state-of-the-art models on performance. Hence, the model can be implemented in the street for real-time traffic detection which can be used for traffic control and data collection.
Channel Estimation for STAR-RIS-aided Wireless Communication
Dec 02, 2021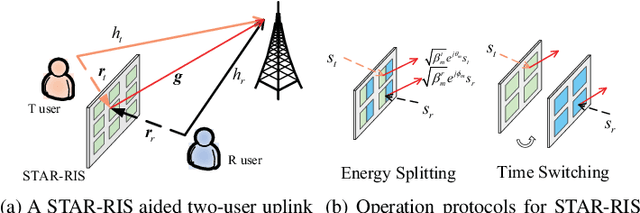
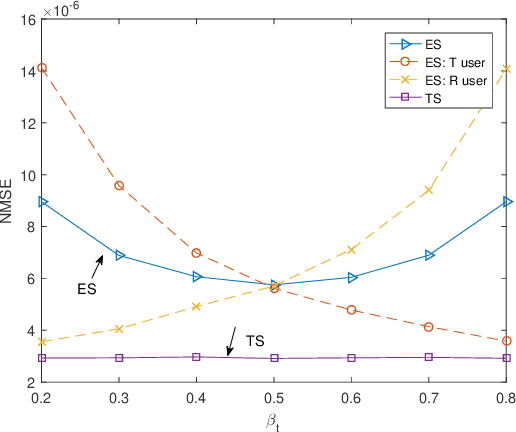
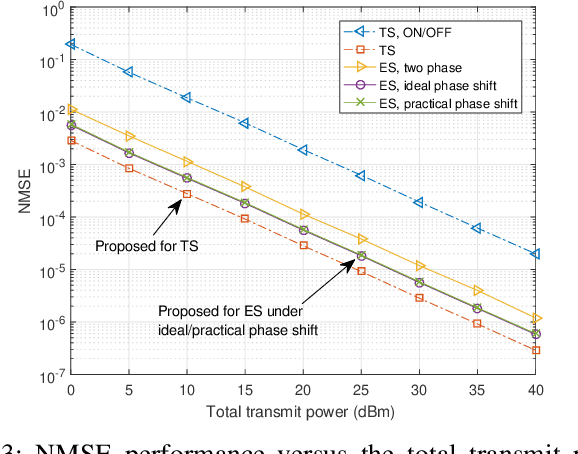
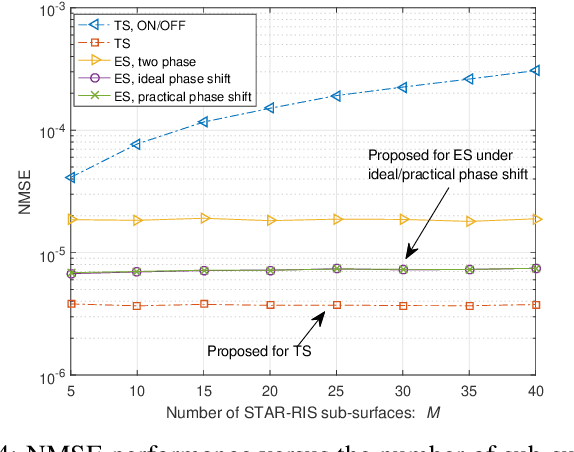
In this letter, we study efficient uplink channel estimation design for a simultaneously transmitting and reflecting reconfigurable intelligent surface (STAR-RIS) assisted two-user communication systems. We first consider the time switching (TS) protocol for STAR-RIS and propose an efficient scheme to separately estimate the channels of the two users with optimized training (transmission/reflection) pattern. Next, we consider the energy splitting (ES) protocol for STAR-RIS under the practical coupled phase-shift model and devise a customized scheme to simultaneously estimate the channels of both users. Although the problem of minimizing the resultant channel estimation error for the ES protocol is difficult to solve, we propose an efficient algorithm to obtain a high-quality solution by jointly designing the pilot sequences, power-splitting ratio, and training patterns. Numerical results show the effectiveness of the proposed channel estimation designs and reveal that the STAR-RIS under the TS protocol achieves a smaller channel estimation error than the ES case.
Iterative Frame-Level Representation Learning And Classification For Semi-Supervised Temporal Action Segmentation
Dec 02, 2021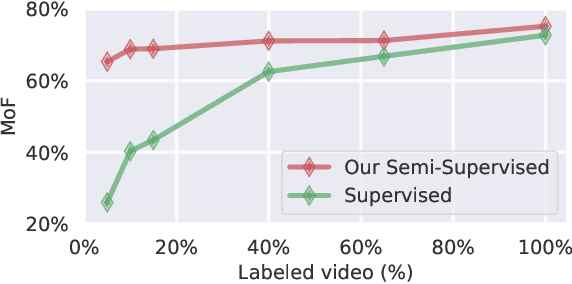
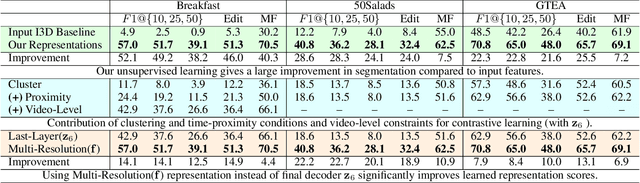
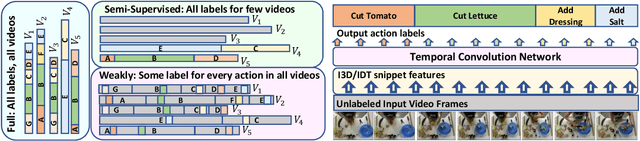
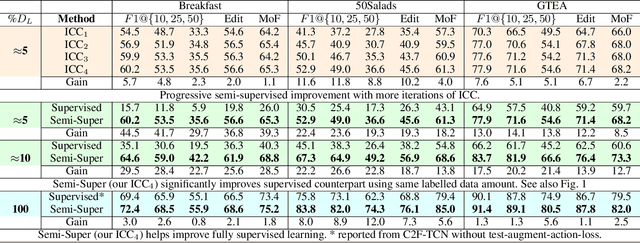
Temporal action segmentation classifies the action of each frame in (long) video sequences. Due to the high cost of frame-wise labeling, we propose the first semi-supervised method for temporal action segmentation. Our method hinges on unsupervised representation learning, which, for temporal action segmentation, poses unique challenges. Actions in untrimmed videos vary in length and have unknown labels and start/end times. Ordering of actions across videos may also vary. We propose a novel way to learn frame-wise representations from temporal convolutional networks (TCNs) by clustering input features with added time-proximity condition and multi-resolution similarity. By merging representation learning with conventional supervised learning, we develop an "Iterative-Contrast-Classify (ICC)" semi-supervised learning scheme. With more labelled data, ICC progressively improves in performance; ICC semi-supervised learning, with 40% labelled videos, performs similar to fully-supervised counterparts. Our ICC improves MoF by {+1.8, +5.6, +2.5}% on Breakfast, 50Salads and GTEA respectively for 100% labelled videos.
Word Graph Guided Summarization for Radiology Findings
Dec 18, 2021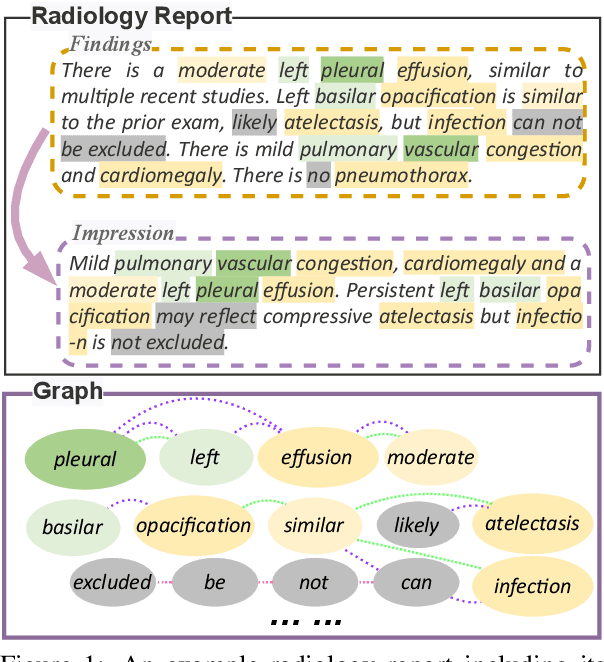
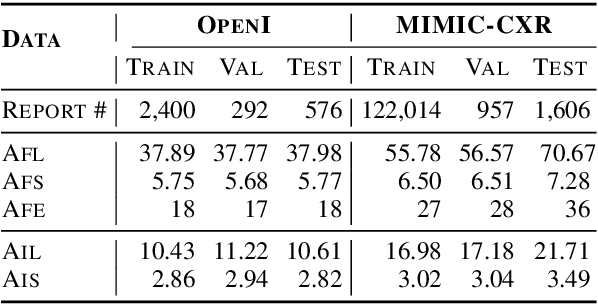
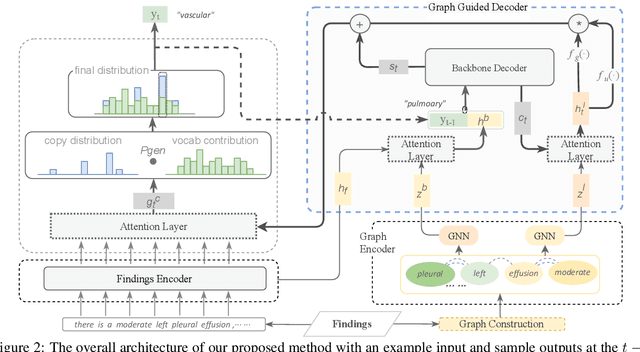
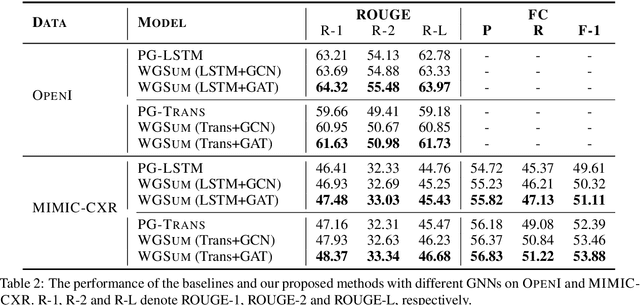
Radiology reports play a critical role in communicating medical findings to physicians. In each report, the impression section summarizes essential radiology findings. In clinical practice, writing impression is highly demanded yet time-consuming and prone to errors for radiologists. Therefore, automatic impression generation has emerged as an attractive research direction to facilitate such clinical practice. Existing studies mainly focused on introducing salient word information to the general text summarization framework to guide the selection of the key content in radiology findings. However, for this task, a model needs not only capture the important words in findings but also accurately describe their relations so as to generate high-quality impressions. In this paper, we propose a novel method for automatic impression generation, where a word graph is constructed from the findings to record the critical words and their relations, then a Word Graph guided Summarization model (WGSum) is designed to generate impressions with the help of the word graph. Experimental results on two datasets, OpenI and MIMIC-CXR, confirm the validity and effectiveness of our proposed approach, where the state-of-the-art results are achieved on both datasets. Further experiments are also conducted to analyze the impact of different graph designs to the performance of our method.
Hformer: Hybrid CNN-Transformer for Fringe Order Prediction in Phase Unwrapping of Fringe Projection
Dec 13, 2021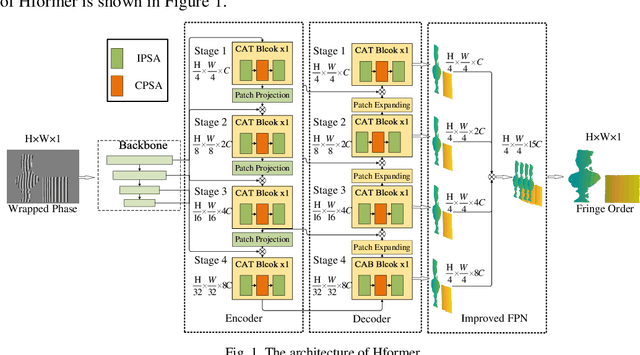
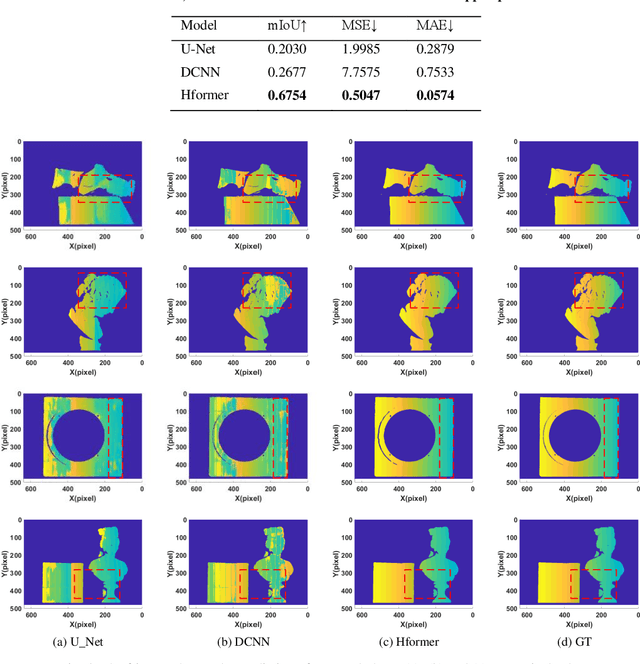
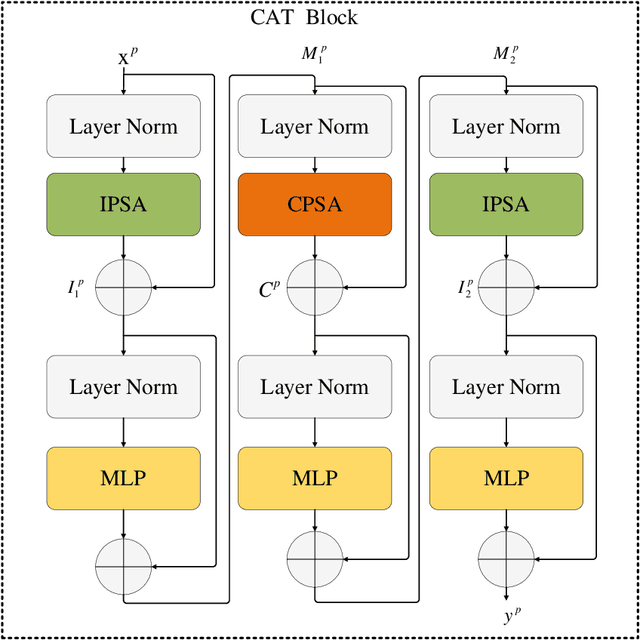
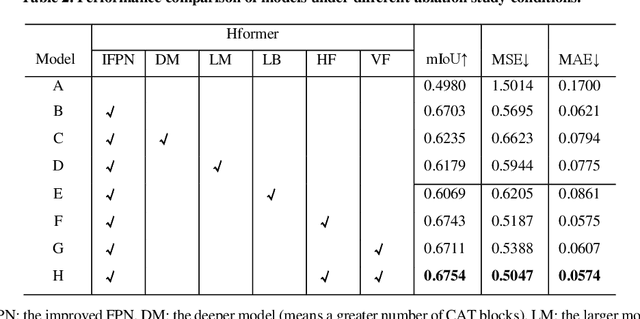
Recently, deep learning has attracted more and more attention in phase unwrapping of fringe projection three-dimensional (3D) measurement, with the aim to improve the performance leveraging the powerful Convolutional Neural Network (CNN) models. In this paper, for the first time (to the best of our knowledge), we introduce the Transformer into the phase unwrapping which is different from CNN and propose Hformer model dedicated to phase unwrapping via fringe order prediction. The proposed model has a hybrid CNN-Transformer architecture that is mainly composed of backbone, encoder and decoder to take advantage of both CNN and Transformer. Encoder and decoder with cross attention are designed for the fringe order prediction. Experimental results show that the proposed Hformer model achieves better performance in fringe order prediction compared with the CNN models such as U-Net and DCNN. Moreover, ablation study on Hformer is made to verify the improved feature pyramid networks (FPN) and testing strategy with flipping in the predicted fringe order. Our work opens an alternative way to deep learning based phase unwrapping methods, which are dominated by CNN in fringe projection 3D measurement.
CSAW-M: An Ordinal Classification Dataset for Benchmarking Mammographic Masking of Cancer
Dec 02, 2021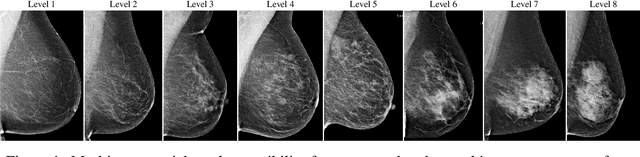

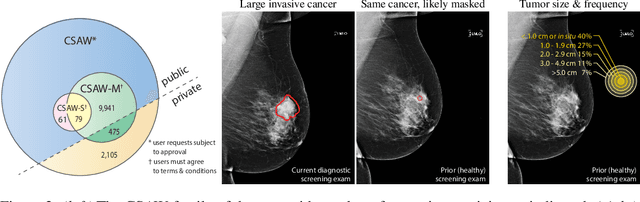

Interval and large invasive breast cancers, which are associated with worse prognosis than other cancers, are usually detected at a late stage due to false negative assessments of screening mammograms. The missed screening-time detection is commonly caused by the tumor being obscured by its surrounding breast tissues, a phenomenon called masking. To study and benchmark mammographic masking of cancer, in this work we introduce CSAW-M, the largest public mammographic dataset, collected from over 10,000 individuals and annotated with potential masking. In contrast to the previous approaches which measure breast image density as a proxy, our dataset directly provides annotations of masking potential assessments from five specialists. We also trained deep learning models on CSAW-M to estimate the masking level and showed that the estimated masking is significantly more predictive of screening participants diagnosed with interval and large invasive cancers -- without being explicitly trained for these tasks -- than its breast density counterparts.