 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-Time Panoptic Segmentation from Dense Detections
Dec 03, 2019
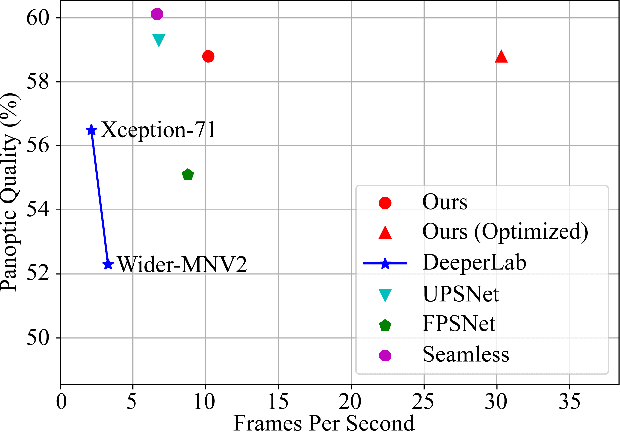
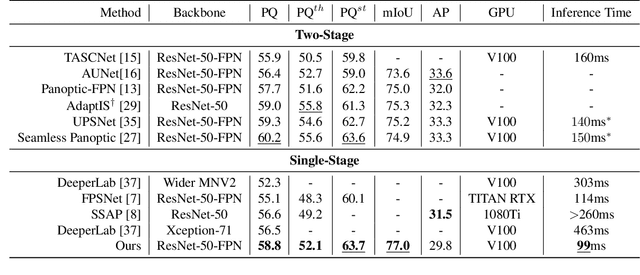
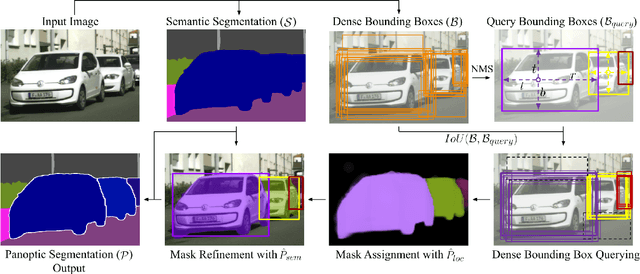
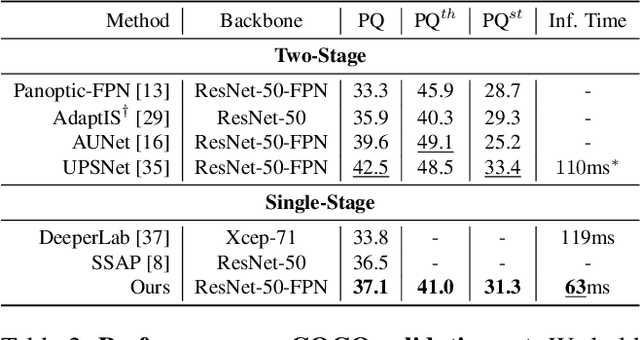
Panoptic segmentation is a complex full scene parsing task requiring simultaneous instance and semantic segmentation at high resolution. Current state-of-the-art approaches cannot run in real-time, and simplifying these architectures to improve efficiency severely degrades their accuracy. In this paper, we propose a new single-shot panoptic segmentation network that leverages dense detections and a global self-attention mechanism to operate in real-time with performance approaching the state of the art. We introduce a novel parameter-free mask construction method that substantially reduces computational complexity by efficiently reusing information from the object detection and semantic segmentation sub-tasks. The resulting network has a simple data flow that does not require feature map re-sampling or clustering post-processing, enabling significant hardware acceleration. Our experiments on the Cityscapes and COCO benchmarks show that our network works at 30 FPS on 1024x2048 resolution, trading a 3% relative performance degradation from the current state of the art for up to 440% faster inference.
Efficient Strong Scaling Through Burst Parallel Training
Dec 19, 2021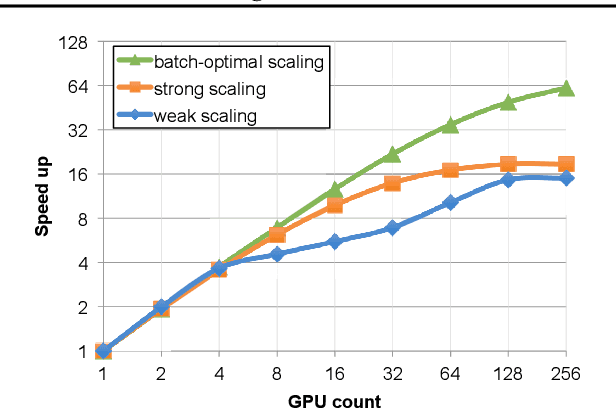
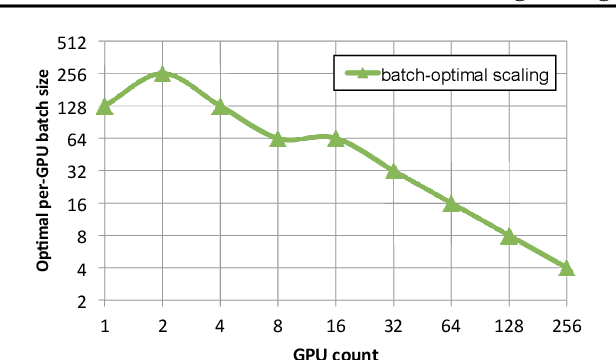

As emerging deep neural network (DNN) models continue to grow in size, using large GPU clusters to train DNNs is becoming an essential requirement to achieving acceptable training times. In this paper, we consider the case where future increases in cluster size will cause the global batch size that can be used to train models to reach a fundamental limit: beyond a certain point, larger global batch sizes cause sample efficiency to degrade, increasing overall time to accuracy. As a result, to achieve further improvements in training performance, we must instead consider "strong scaling" strategies that hold the global batch size constant and allocate smaller batches to each GPU. Unfortunately, this makes it significantly more difficult to use cluster resources efficiently. We present DeepPool, a system that addresses this efficiency challenge through two key ideas. First, burst parallelism allocates large numbers of GPUs to foreground jobs in bursts to exploit the unevenness in parallelism across layers. Second, GPU multiplexing prioritizes throughput for foreground training jobs, while packing in background training jobs to reclaim underutilized GPU resources, thereby improving cluster-wide utilization. Together, these two ideas enable DeepPool to deliver a 2.2 - 2.4x improvement in total cluster throughput over standard data parallelism with a single task when the cluster scale is large.
HLT-NUS SUBMISSION FOR 2020 NIST Conversational Telephone Speech SRE
Nov 12, 2021
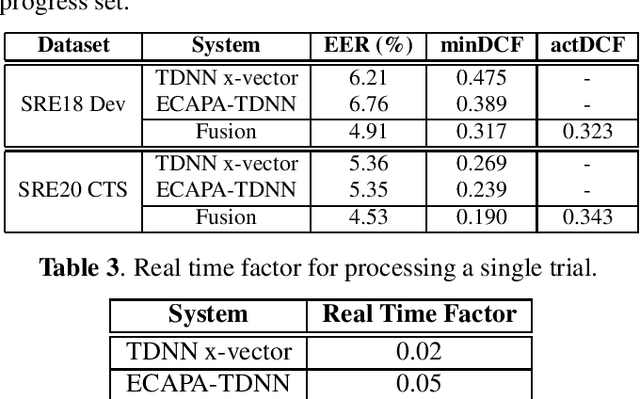
This work provides a brief description of Human Language Technology (HLT) Laboratory, National University of Singapore (NUS) system submission for 2020 NIST conversational telephone speech (CTS) speaker recognition evaluation (SRE). The challenge focuses on evaluation under CTS data containing multilingual speech. The systems developed at HLT-NUS consider time-delay neural network (TDNN) x-vector and ECAPA-TDNN systems. We also perform domain adaption of probabilistic linear discriminant analysis (PLDA) model and adaptive s-norm on our systems. The score level fusion of TDNN x-vector and ECAPA-TDNN systems is carried out, which improves the final system performance of our submission to 2020 NIST CTS SRE.
Scalable Learning for Optimal Load Shedding Under Power Grid Emergency Operations
Nov 23, 2021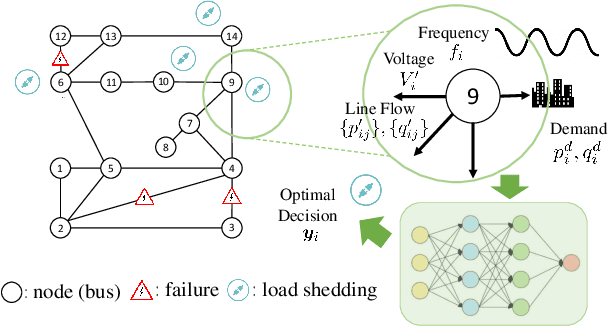
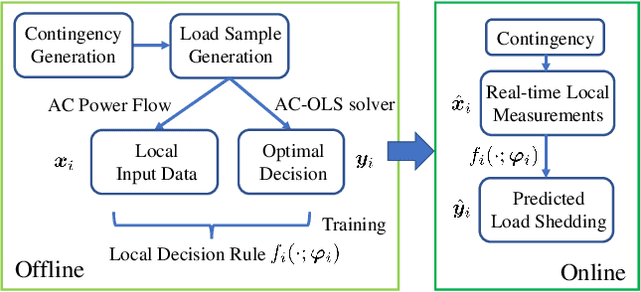
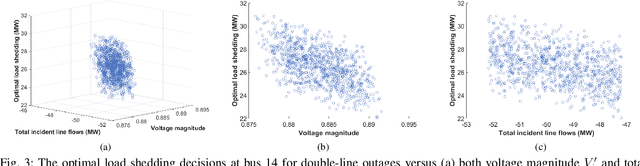
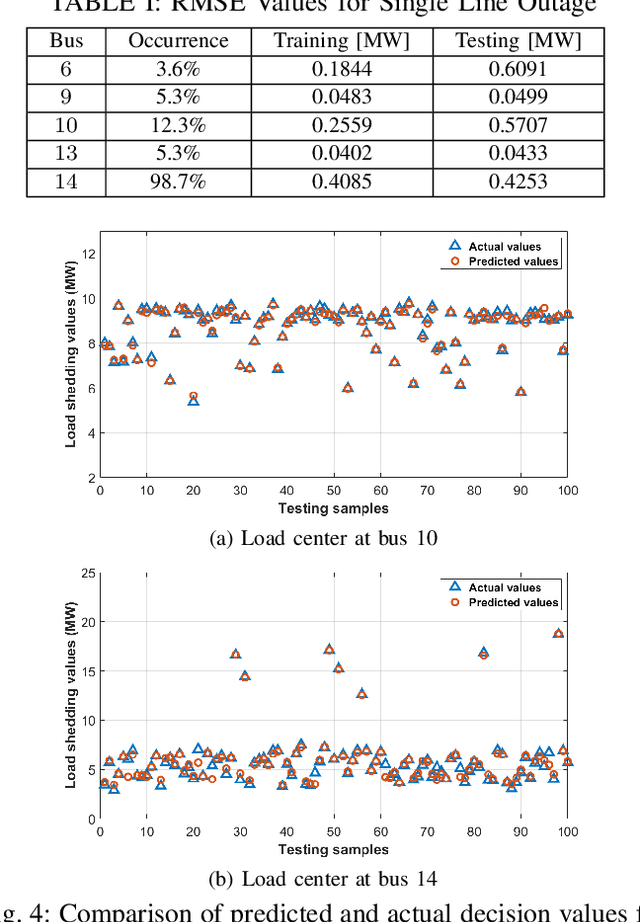
Effective and timely responses to unexpected contingencies are crucial for enhancing the resilience of power grids. Given the fast, complex process of cascading propagation, corrective actions such as optimal load shedding (OLS) are difficult to attain in large-scale networks due to the computation complexity and communication latency issues. This work puts forth an innovative learning-for-OLS approach by constructing the optimal decision rules of load shedding under a variety of potential contingency scenarios through offline neural network (NN) training. Notably, the proposed NN-based OLS decisions are fully decentralized, enabling individual load centers to quickly react to the specific contingency using readily available local measurements. Numerical studies on the IEEE 14-bus system have demonstrated the effectiveness of our scalable OLS design for real-time responses to severe grid emergency events.
Astronomical Image Colorization and upscaling with Generative Adversarial Networks
Dec 27, 2021
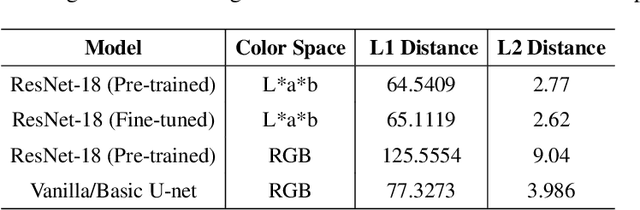

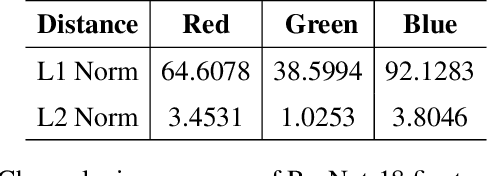
Automatic colorization of images without human intervention has been a subject of interest in the machine learning community for a brief period of time. Assigning color to an image is a highly ill-posed problem because of its innate nature of possessing very high degrees of freedom; given an image, there is often no single color-combination that is correct. Besides colorization, another problem in reconstruction of images is Single Image Super Resolution, which aims at transforming low resolution images to a higher resolution. This research aims to provide an automated approach for the problem by focusing on a very specific domain of images, namely astronomical images, and process them using Generative Adversarial Networks (GANs). We explore the usage of various models in two different color spaces, RGB and L*a*b. We use transferred learning owing to a small data set, using pre-trained ResNet-18 as a backbone, i.e. encoder for the U-net and fine-tune it further. The model produces visually appealing images which hallucinate high resolution, colorized data in these results which does not exist in the original image. We present our results by evaluating the GANs quantitatively using distance metrics such as L1 distance and L2 distance in each of the color spaces across all channels to provide a comparative analysis. We use Frechet inception distance (FID) to compare the distribution of the generated images with the distribution of the real image to assess the model's performance.
On the Feasibility of Predicting Questions being Forgotten in Stack Overflow
Oct 29, 2021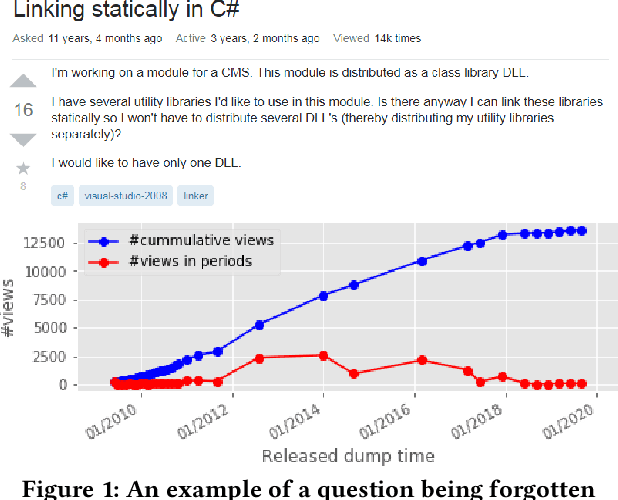
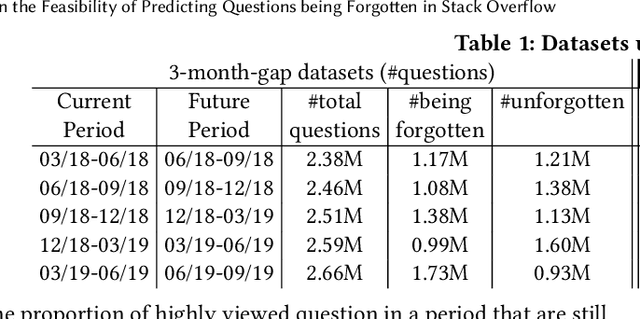
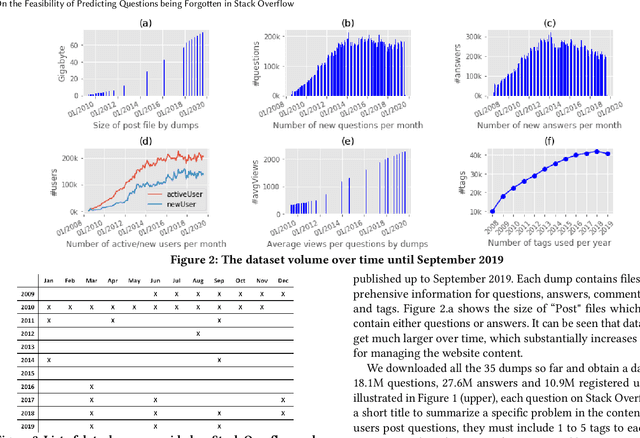
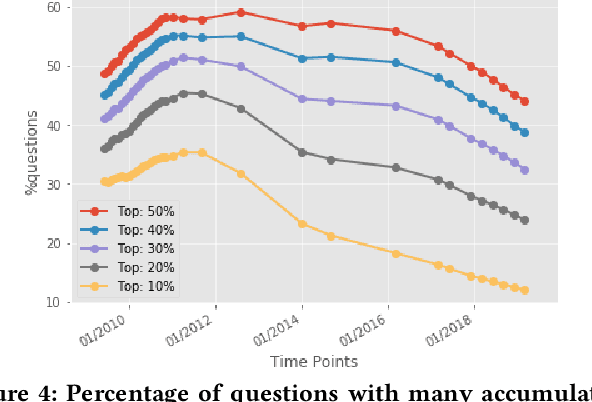
For their attractiveness, comprehensiveness and dynamic coverage of relevant topics, community-based question answering sites such as Stack Overflow heavily rely on the engagement of their communities: Questions on new technologies, technology features as well as technology versions come up and have to be answered as technology evolves (and as community members gather experience with it). At the same time, other questions cease in importance over time, finally becoming irrelevant to users. Beyond filtering low-quality questions, "forgetting" questions, which have become redundant, is an important step for keeping the Stack Overflow content concise and useful. In this work, we study this managed forgetting task for Stack Overflow. Our work is based on data from more than a decade (2008 - 2019) - covering 18.1M questions, that are made publicly available by the site itself. For establishing a deeper understanding, we first analyze and characterize the set of questions about to be forgotten, i.e., questions that get a considerable number of views in the current period but become unattractive in the near future. Subsequently, we examine the capability of a wide range of features in predicting such forgotten questions in different categories. We find some categories in which those questions are more predictable. We also discover that the text-based features are surprisingly not helpful in this prediction task, while the meta information is much more predictive.
On the relationship between calibrated predictors and unbiased volume estimation
Dec 23, 2021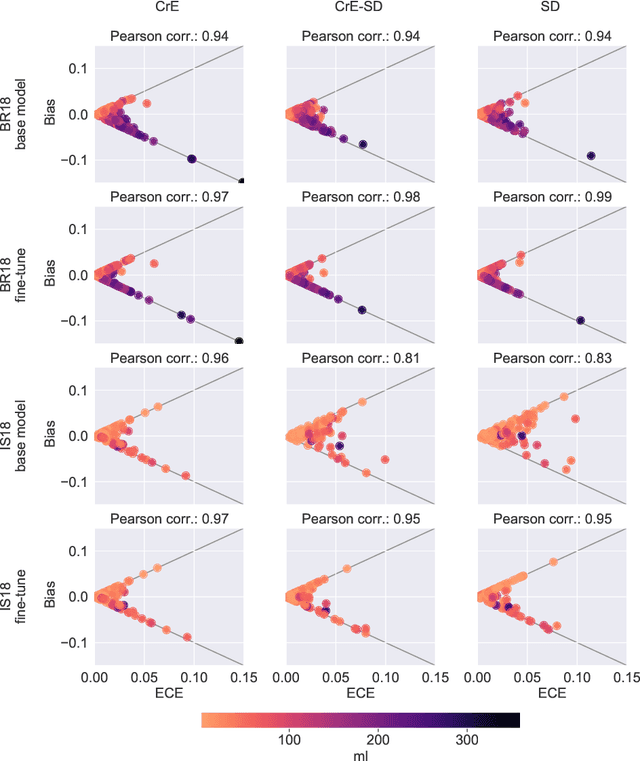
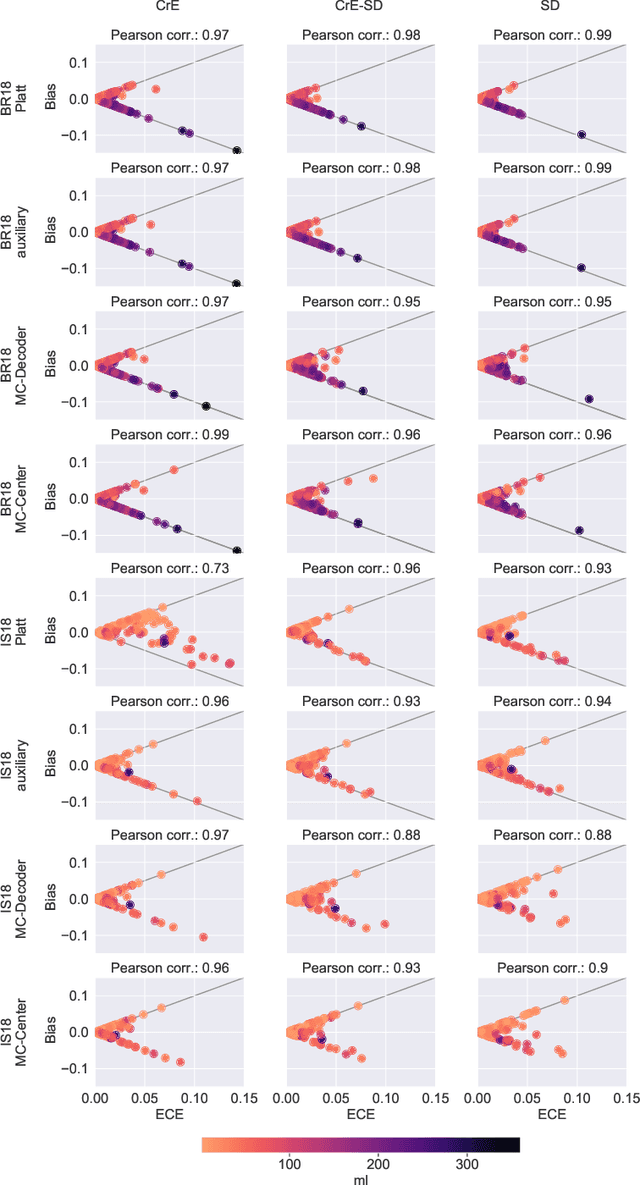
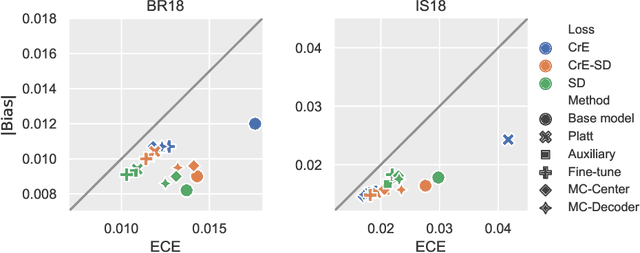
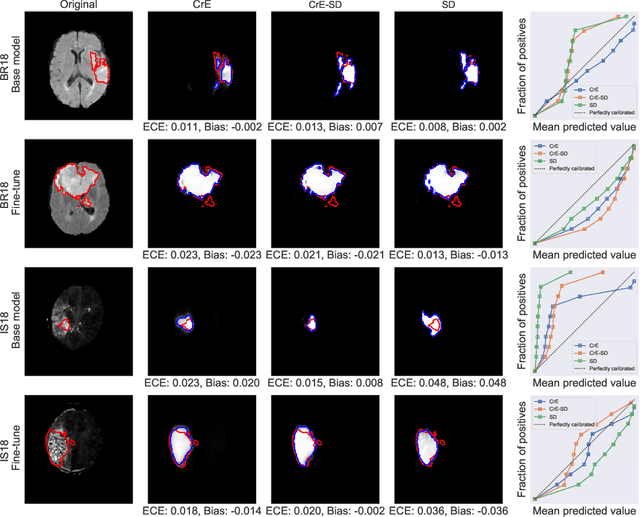
Machine learning driven medical image segmentation has become standard in medical image analysis. However, deep learning models are prone to overconfident predictions. This has led to a renewed focus on calibrated predictions in the medical imaging and broader machine learning communities. Calibrated predictions are estimates of the probability of a label that correspond to the true expected value of the label conditioned on the confidence. Such calibrated predictions have utility in a range of medical imaging applications, including surgical planning under uncertainty and active learning systems. At the same time it is often an accurate volume measurement that is of real importance for many medical applications. This work investigates the relationship between model calibration and volume estimation. We demonstrate both mathematically and empirically that if the predictor is calibrated per image, we can obtain the correct volume by taking an expectation of the probability scores per pixel/voxel of the image. Furthermore, we show that convex combinations of calibrated classifiers preserve volume estimation, but do not preserve calibration. Therefore, we conclude that having a calibrated predictor is a sufficient, but not necessary condition for obtaining an unbiased estimate of the volume. We validate our theoretical findings empirically on a collection of 18 different (calibrated) training strategies on the tasks of glioma volume estimation on BraTS 2018, and ischemic stroke lesion volume estimation on ISLES 2018 datasets.
Meta Reinforcement Learning Based Sensor Scanning in 3D Uncertain Environments for Heterogeneous Multi-Robot Systems
Sep 28, 2021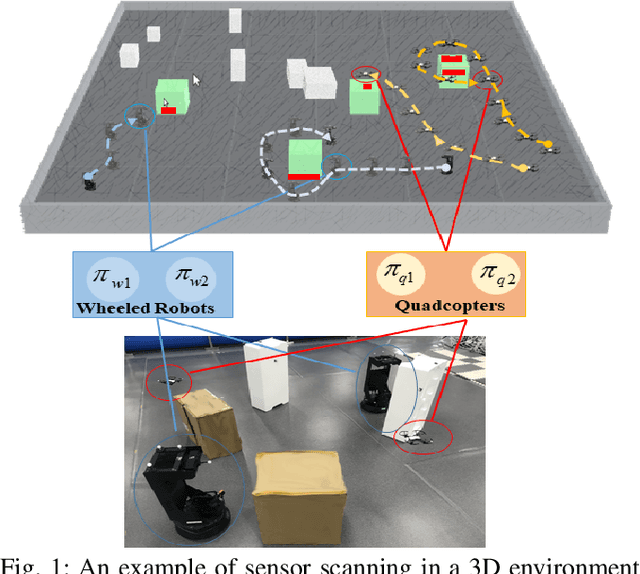
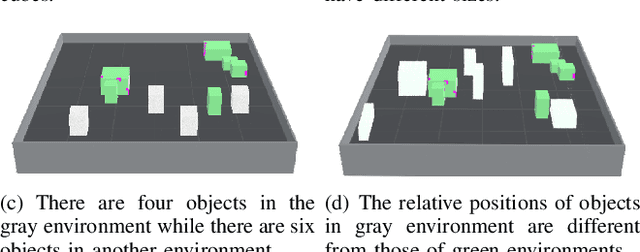
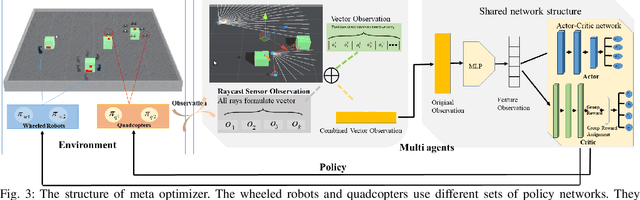
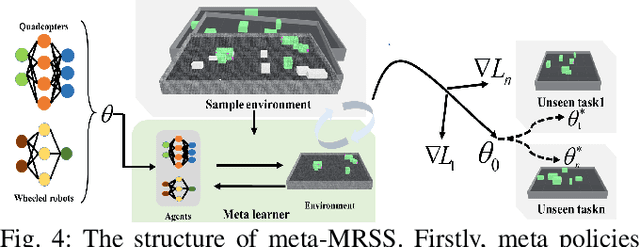
We study a novel problem that tackles learning based sensor scanning in 3D and uncertain environments with heterogeneous multi-robot systems. Our motivation is two-fold: first, 3D environments are complex, the use of heterogeneous multi-robot systems intuitively can facilitate sensor scanning by fully taking advantage of sensors with different capabilities. Second, in uncertain environments (e.g. rescue), time is of great significance. Since the learning process normally takes time to train and adapt to a new environment, we need to find an effective way to explore and adapt quickly. To this end, in this paper, we present a meta-learning approach to improve the exploration and adaptation capabilities. The experimental results demonstrate our method can outperform other methods by approximately 15%-27% on success rate and 70%-75% on adaptation speed.
Joint Prediction and Time Estimation of COVID-19 Developing Severe Symptoms using Chest CT Scan
May 07, 2020
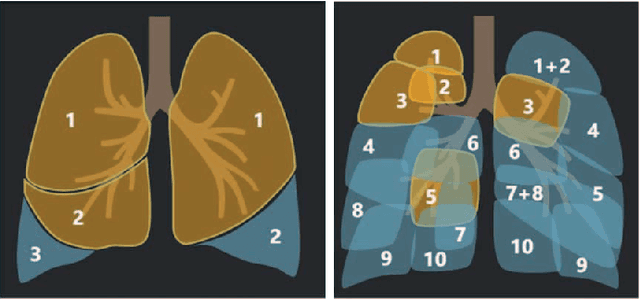
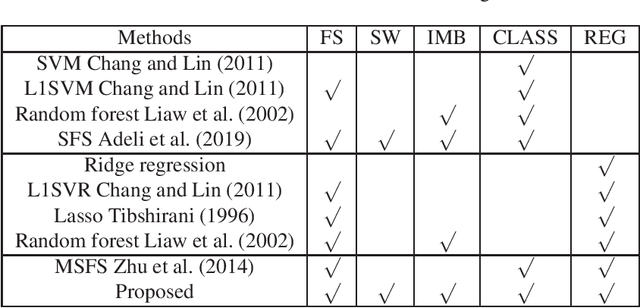
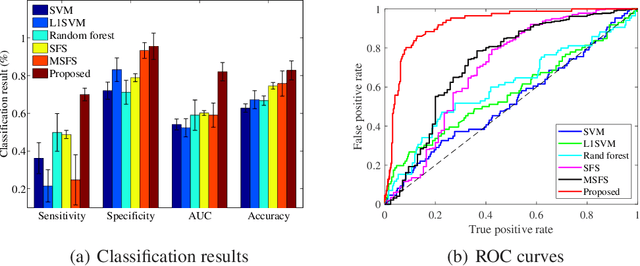
With the rapidly worldwide spread of Coronavirus disease (COVID-19), it is of great importance to conduct early diagnosis of COVID-19 and predict the time that patients might convert to the severe stage, for designing effective treatment plan and reducing the clinicians' workloads. In this study, we propose a joint classification and regression method to determine whether the patient would develop severe symptoms in the later time, and if yes, predict the possible conversion time that the patient would spend to convert to the severe stage. To do this, the proposed method takes into account 1) the weight for each sample to reduce the outliers' influence and explore the problem of imbalance classification, and 2) the weight for each feature via a sparsity regularization term to remove the redundant features of high-dimensional data and learn the shared information across the classification task and the regression task. To our knowledge, this study is the first work to predict the disease progression and the conversion time, which could help clinicians to deal with the potential severe cases in time or even save the patients' lives. Experimental analysis was conducted on a real data set from two hospitals with 422 chest computed tomography (CT) scans, where 52 cases were converted to severe on average 5.64 days and 34 cases were severe at admission. Results show that our method achieves the best classification (e.g., 85.91% of accuracy) and regression (e.g., 0.462 of the correlation coefficient) performance, compared to all comparison methods. Moreover, our proposed method yields 76.97% of accuracy for predicting the severe cases, 0.524 of the correlation coefficient, and 0.55 days difference for the converted time.
Stain Normalized Breast Histopathology Image Recognition using Convolutional Neural Networks for Cancer Detection
Jan 04, 2022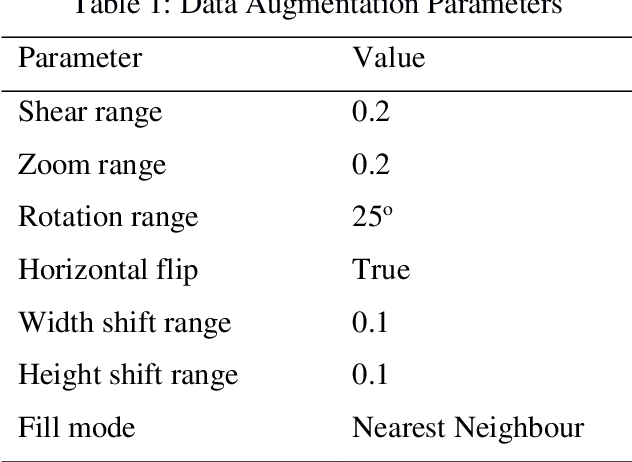
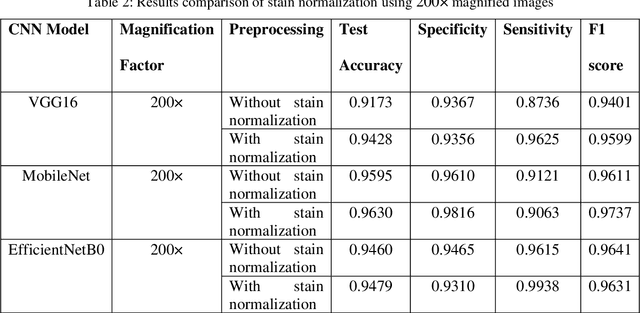
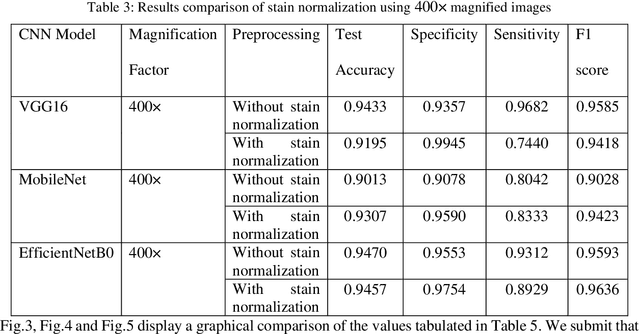
Computer assisted diagnosis in digital pathology is becoming ubiquitous as it can provide more efficient and objective healthcare diagnostics. Recent advances have shown that the convolutional Neural Network (CNN) architectures, a well-established deep learning paradigm, can be used to design a Computer Aided Diagnostic (CAD) System for breast cancer detection. However, the challenges due to stain variability and the effect of stain normalization with such deep learning frameworks are yet to be well explored. Moreover, performance analysis with arguably more efficient network models, which may be important for high throughput screening, is also not well explored.To address this challenge, we consider some contemporary CNN models for binary classification of breast histopathology images that involves (1) the data preprocessing with stain normalized images using an adaptive colour deconvolution (ACD) based color normalization algorithm to handle the stain variabilities; and (2) applying transfer learning based training of some arguably more efficient CNN models, namely Visual Geometry Group Network (VGG16), MobileNet and EfficientNet. We have validated the trained CNN networks on a publicly available BreaKHis dataset, for 200x and 400x magnified histopathology images. The experimental analysis shows that pretrained networks in most cases yield better quality results on data augmented breast histopathology images with stain normalization, than the case without stain normalization. Further, we evaluated the performance and efficiency of popular lightweight networks using stain normalized images and found that EfficientNet outperforms VGG16 and MobileNet in terms of test accuracy and F1 Score. We observed that efficiency in terms of test time is better in EfficientNet than other networks; VGG Net, MobileNet, without much drop in the classification accuracy.