 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Robotic Antenna Alignment and Tracking System for Millimeter Wave Propagation Modeling
Oct 14, 2021

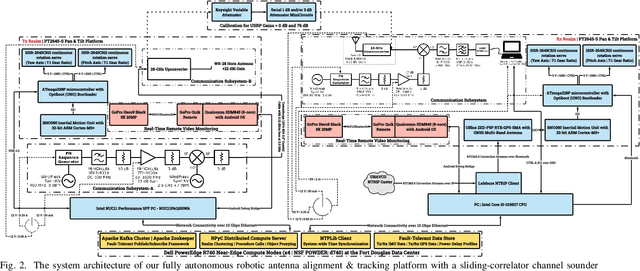
In this paper, we discuss the design of a sliding-correlator channel sounder for 28 GHz propagation modeling on the NSF POWDER testbed in Salt Lake City, UT. Beam-alignment is mechanically achieved via a fully autonomous robotic antenna tracking platform, designed using commercial off-the-shelf components. Equipped with an Apache Zookeeper/Kafka managed fault-tolerant publish-subscribe framework, we demonstrate tracking response times of 27.8 ms, in addition to superior scalability over state-of-the-art mechanical beam-steering systems. Enhanced with real-time kinematic correction streams, our geo-positioning subsystem achieves a 3D accuracy of 17 cm, while our principal axes positioning subsystem achieves an average accuracy of 1.1 degrees across yaw and pitch movements. Finally, by facilitating remote orchestration (via managed containers), uninhibited rotation (via encapsulation), and real-time positioning visualization (via Dash/MapBox), we exhibit a proven prototype well-suited for V2X measurements.
Towards a theory of quantum gravity from neural networks
Oct 28, 2021Neural network is a dynamical system described by two different types of degrees of freedom: fast-changing non-trainable variables (e.g. state of neurons) and slow-changing trainable variables (e.g. weights and biases). We show that the non-equilibrium dynamics of trainable variables can be described by the Madelung equations, if the number of neurons is fixed, and by the Schrodinger equation, if the learning system is capable of adjusting its own parameters such as the number of neurons, step size and mini-batch size. We argue that the Lorentz symmetries and curved space-time can emerge from the interplay between stochastic entropy production and entropy destruction due to learning. We show that the non-equilibrium dynamics of non-trainable variables can be described by the geodesic equation (in the emergent space-time) for localized states of neurons, and by the Einstein equations (with cosmological constant) for the entire network. We conclude that the quantum description of trainable variables and the gravitational description of non-trainable variables are dual in the sense that they provide alternative macroscopic descriptions of the same learning system, defined microscopically as a neural network.
Em-K Indexing for Approximate Query Matching in Large-scale ER
Nov 07, 2021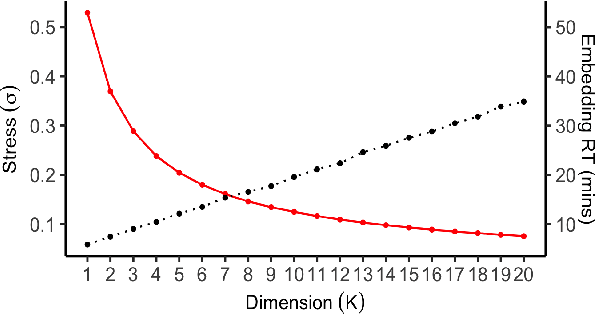
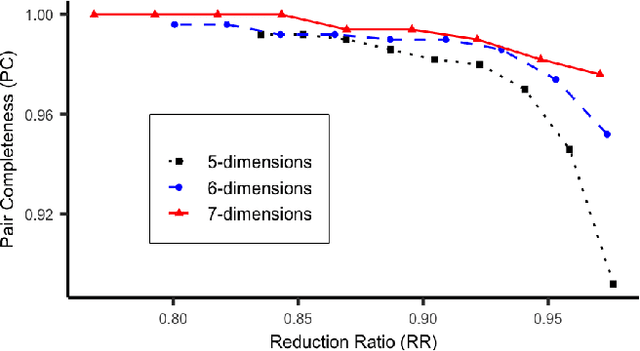
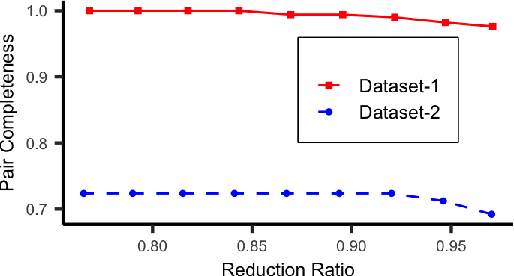
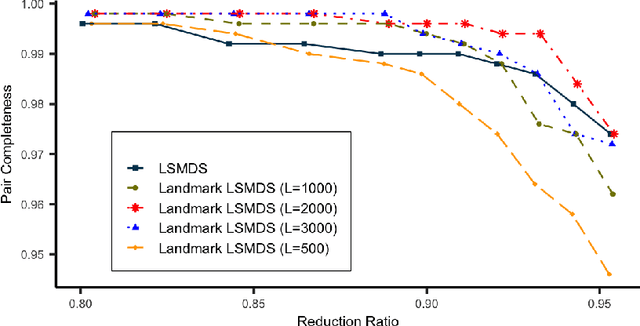
Accurate and efficient entity resolution (ER) is a significant challenge in many data mining and analysis projects requiring integrating and processing massive data collections. It is becoming increasingly important in real-world applications to develop ER solutions that produce prompt responses for entity queries on large-scale databases. Some of these applications demand entity query matching against large-scale reference databases within a short time. We define this as the query matching problem in ER in this work. Indexing or blocking techniques reduce the search space and execution time in the ER process. However, approximate indexing techniques that scale to very large-scale datasets remain open to research. In this paper, we investigate the query matching problem in ER to propose an indexing method suitable for approximate and efficient query matching. We first use spatial mappings to embed records in a multidimensional Euclidean space that preserves the domain-specific similarity. Among the various mapping techniques, we choose multidimensional scaling. Then using a Kd-tree and the nearest neighbour search, the method returns a block of records that includes potential matches for a query. Our method can process queries against a large-scale dataset using only a fraction of the data $L$ (given the dataset size is $N$), with a $O(L^2)$ complexity where $L \ll N$. The experiments conducted on several datasets showed the effectiveness of the proposed method.
A Python Framework for Fast Modelling and Simulation of Cellular Nonlinear Networks and other Finite-difference Time-domain Systems
Feb 20, 2021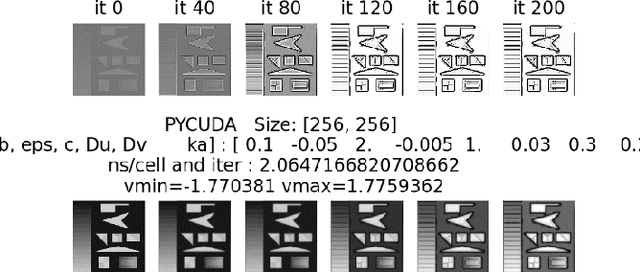

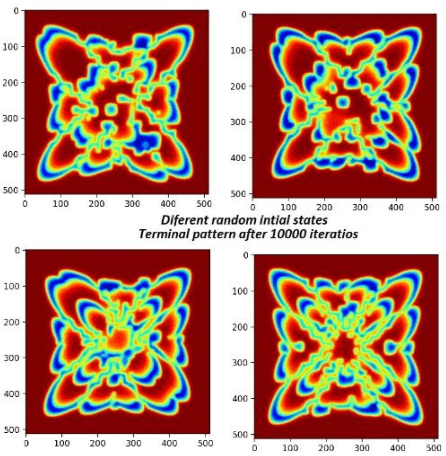
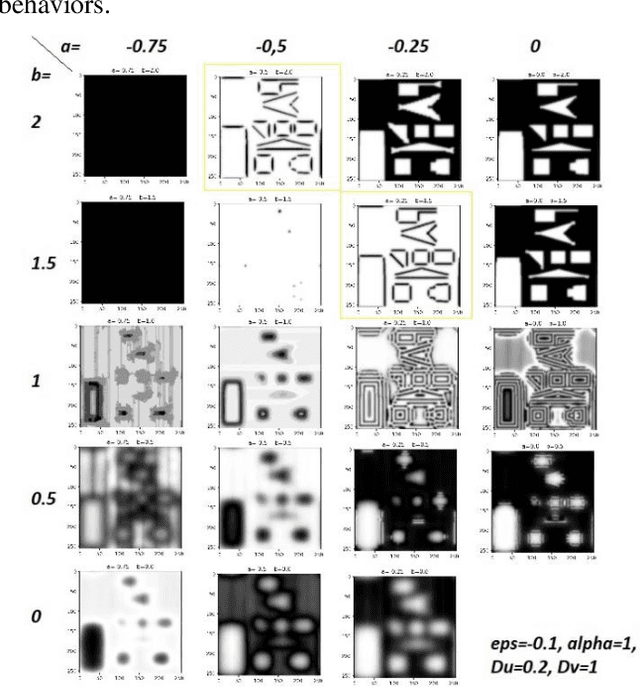
This paper introduces and evaluates a freely available cellular nonlinear network simulator optimized for the effective use of GPUs, to achieve fast modelling and simulations. Its relevance is demonstrated for several applications in nonlinear complex dynamical systems, such as slow-growth phenomena as well as for various image processing applications such as edge detection. The simulator is designed as a Jupyter notebook written in Python and functionally tested and optimized to run on the freely available cloud platform Google Collaboratory. Although the simulator, in its actual form, is designed to model the FitzHugh Nagumo Reaction-Diffusion cellular nonlinear network, it can be easily adapted for any other type of finite-difference time-domain model. Four implementation versions are considered, namely using the PyCUDA, NUMBA respectively CUPY libraries (all three supporting GPU computations) as well as a NUMPY-based implementation to be used when GPU is not available. The specificities and performances for each of the four implementations are analyzed concluding that the PyCUDA implementation ensures a very good performance being capable to run up to 14000 Mega cells per seconds (each cell referring to the basic nonlinear dynamic system composing the cellular nonlinear network).
Intelligent Reflecting Surface-Aided LEO Satellite Communication: Cooperative Passive Beamforming and Distributed Channel Estimation
Jan 09, 2022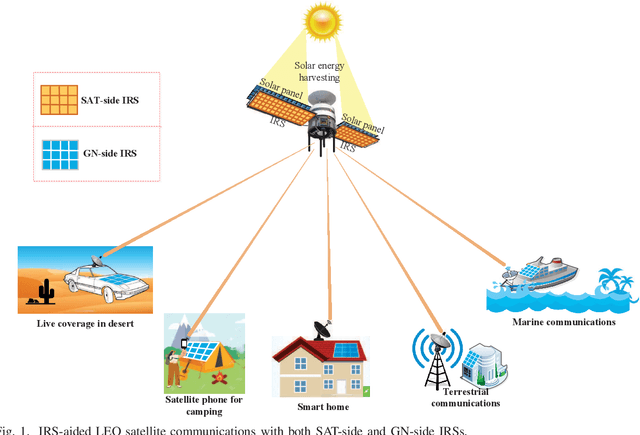
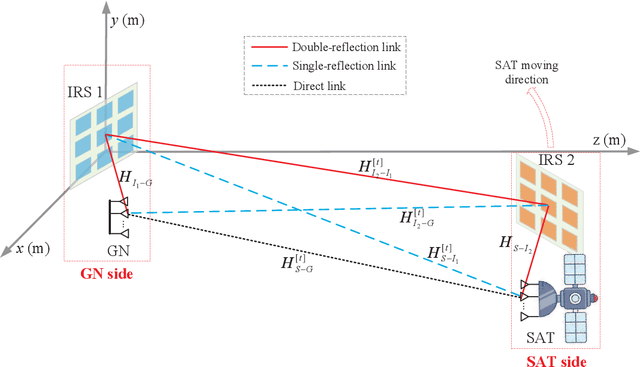
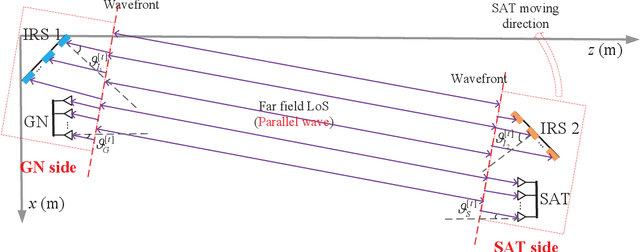
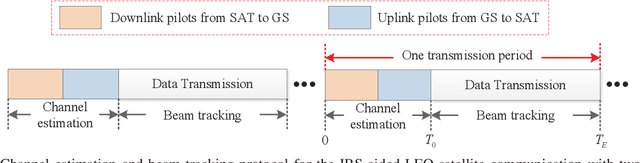
We consider in this paper a new intelligent reflecting surface (IRS)-aided LEO satellite communication system, by utilizing the controllable phase shifts of massive passive reflecting elements to achieve flexible beamforming, which copes with the time-varying channel between the high-mobility satellite (SAT) and ground node (GN) cost-effectively. In particular, we propose a new architecture for IRS-aided LEO satellite communication where IRSs are deployed at both sides of the SAT and GN, and study their cooperative passive beamforming (CPB) design over line-of-sight (LoS)-dominant single-reflection and double-reflection channels. Specifically, we jointly optimize the active transmit/receive beamforming at the SAT/GN as well as the CPB at two-sided IRSs to maximize the overall channel gain from the SAT to each GN. Interestingly, we show that under LoS channel conditions, the high-dimensional SAT-GN channel can be decomposed into the outer product of two low-dimensional vectors. By exploiting the decomposed SAT-GN channel, we decouple the original beamforming optimization problem into two simpler subproblems corresponding to the SAT and GN sides, respectively, which are both solved in closed-form. Furthermore, we propose an efficient transmission protocol to conduct channel estimation and beam tracking, which only requires independent processing of the SAT and GN in a distributed manner, thus substantially reducing the implementation complexity. Simulation results validate the performance advantages of the proposed IRS-aided LEO satellite communication system with two-sided cooperative IRSs, as compared to various baseline schemes such as the conventional reflect-array and one-sided IRS.
Learning Hidden Patterns from Patient Multivariate Time Series Data Using Convolutional Neural Networks: A Case Study of Healthcare Cost Prediction
Sep 14, 2020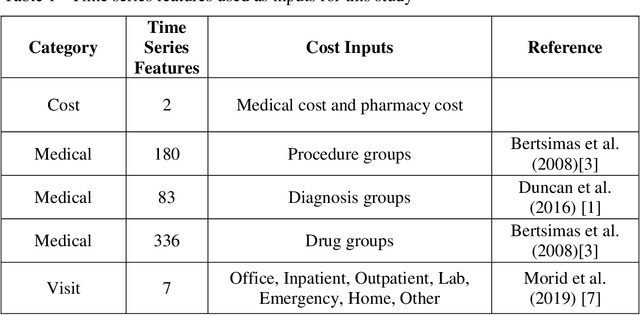
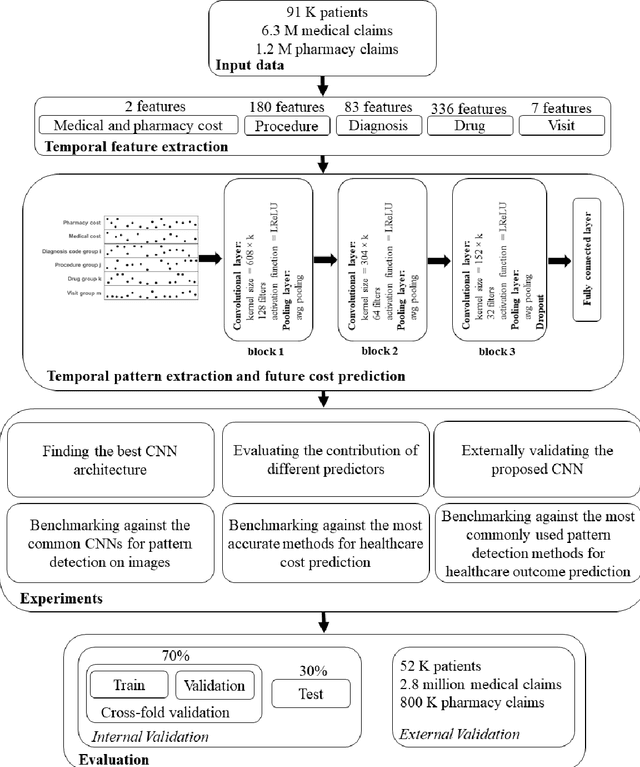
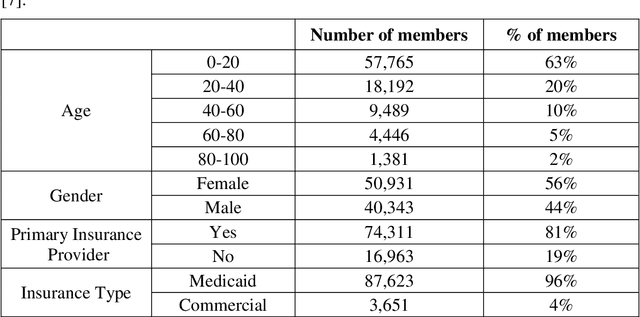
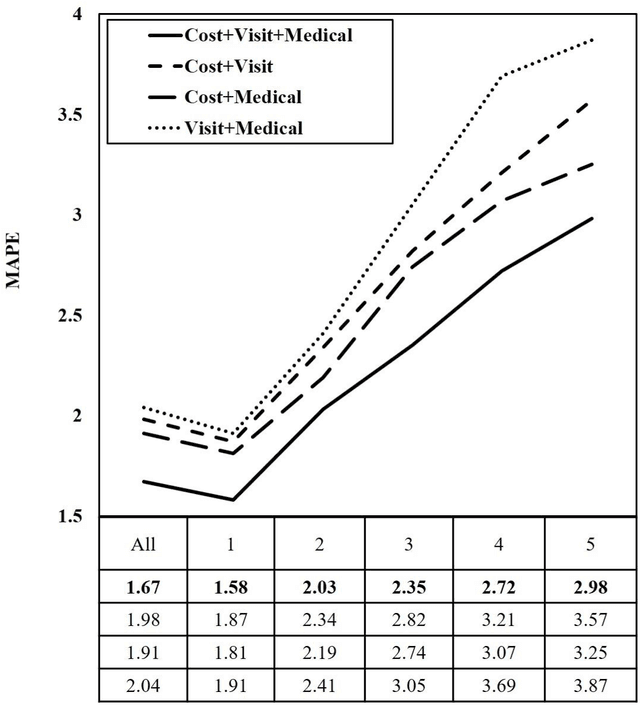
Objective: To develop an effective and scalable individual-level patient cost prediction method by automatically learning hidden temporal patterns from multivariate time series data in patient insurance claims using a convolutional neural network (CNN) architecture. Methods: We used three years of medical and pharmacy claims data from 2013 to 2016 from a healthcare insurer, where data from the first two years were used to build the model to predict costs in the third year. The data consisted of the multivariate time series of cost, visit and medical features that were shaped as images of patients' health status (i.e., matrices with time windows on one dimension and the medical, visit and cost features on the other dimension). Patients' multivariate time series images were given to a CNN method with a proposed architecture. After hyper-parameter tuning, the proposed architecture consisted of three building blocks of convolution and pooling layers with an LReLU activation function and a customized kernel size at each layer for healthcare data. The proposed CNN learned temporal patterns became inputs to a fully connected layer. Conclusions: Feature learning through the proposed CNN configuration significantly improved individual-level healthcare cost prediction. The proposed CNN was able to outperform temporal pattern detection methods that look for a pre-defined set of pattern shapes, since it is capable of extracting a variable number of patterns with various shapes. Temporal patterns learned from medical, visit and cost data made significant contributions to the prediction performance. Hyper-parameter tuning showed that considering three-month data patterns has the highest prediction accuracy. Our results showed that patients' images extracted from multivariate time series data are different from regular images, and hence require unique designs of CNN architectures.
Multi-modal 3D Human Pose Estimation with 2D Weak Supervision in Autonomous Driving
Dec 22, 2021
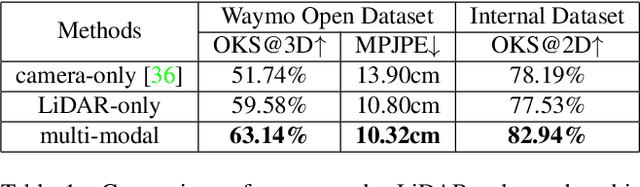
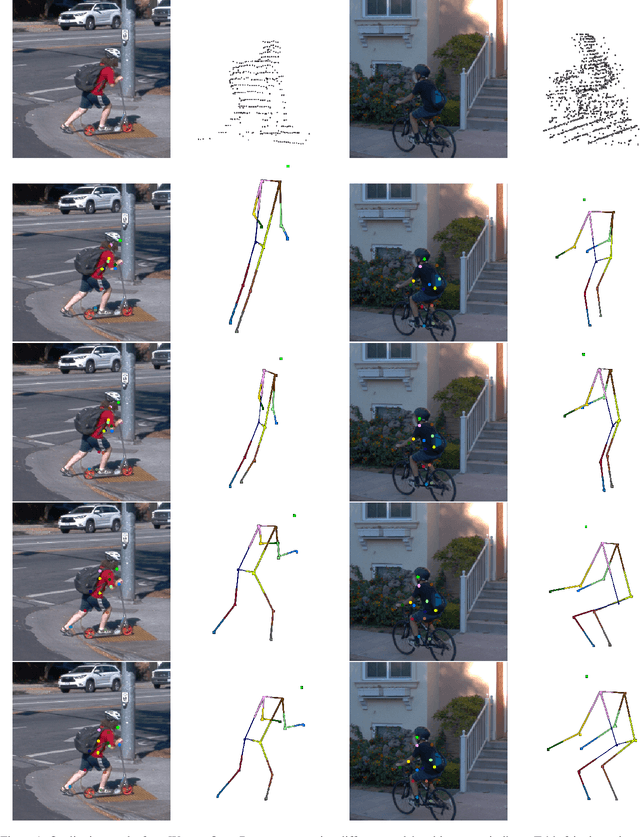
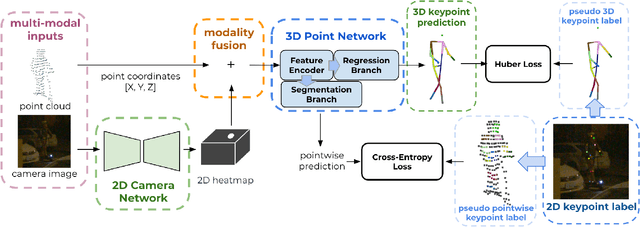
3D human pose estimation (HPE) in autonomous vehicles (AV) differs from other use cases in many factors, including the 3D resolution and range of data, absence of dense depth maps, failure modes for LiDAR, relative location between the camera and LiDAR, and a high bar for estimation accuracy. Data collected for other use cases (such as virtual reality, gaming, and animation) may therefore not be usable for AV applications. This necessitates the collection and annotation of a large amount of 3D data for HPE in AV, which is time-consuming and expensive. In this paper, we propose one of the first approaches to alleviate this problem in the AV setting. Specifically, we propose a multi-modal approach which uses 2D labels on RGB images as weak supervision to perform 3D HPE. The proposed multi-modal architecture incorporates LiDAR and camera inputs with an auxiliary segmentation branch. On the Waymo Open Dataset, our approach achieves a 22% relative improvement over camera-only 2D HPE baseline, and 6% improvement over LiDAR-only model. Finally, careful ablation studies and parts based analysis illustrate the advantages of each of our contributions.
Real-Time Face and Landmark Localization for Eyeblink Detection
Jun 01, 2020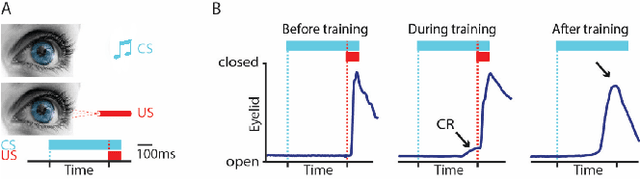
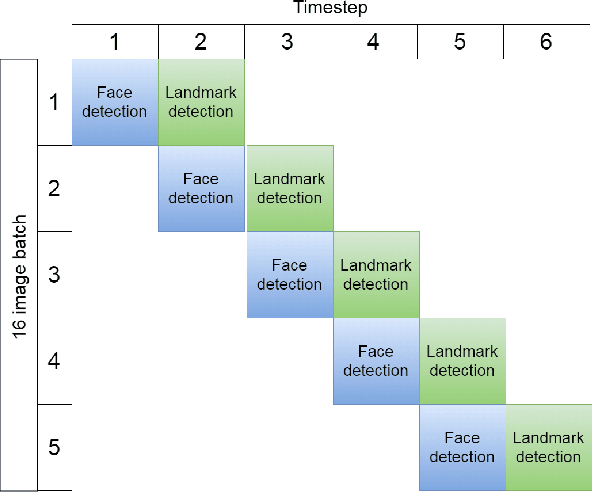
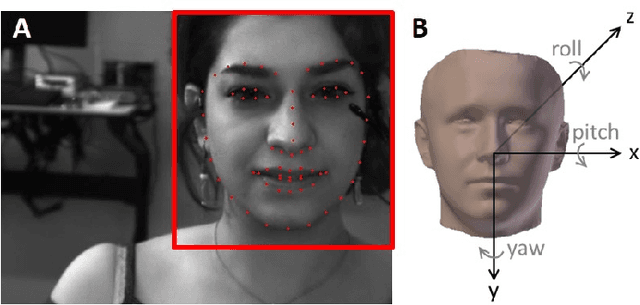
Pavlovian eyeblink conditioning is a powerful experiment used in the field of neuroscience to measure multiple aspects of how we learn in our daily life. To track the movement of the eyelid during an experiment, researchers have traditionally made use of potentiometers or electromyography. More recently, the use of computer vision and image processing alleviated the need for these techniques but currently employed methods require human intervention and are not fast enough to enable real-time processing. In this work, a face- and landmark-detection algorithm have been carefully combined in order to provide fully automated eyelid tracking, and have further been accelerated to make the first crucial step towards online, closed-loop experiments. Such experiments have not been achieved so far and are expected to offer significant insights in the workings of neurological and psychiatric disorders. Based on an extensive literature search, various different algorithms for face detection and landmark detection have been analyzed and evaluated. Two algorithms were identified as most suitable for eyelid detection: the Histogram-of-Oriented-Gradients (HOG) algorithm for face detection and the Ensemble-of-Regression-Trees (ERT) algorithm for landmark detection. These two algorithms have been accelerated on GPU and CPU, achieving speedups of 1,753$\times$ and 11$\times$, respectively. To demonstrate the usefulness of our eyelid-detection algorithm, a research hypothesis was formed and a well-established neuroscientific experiment was employed: eyeblink detection. Our experimental evaluation reveals an overall application runtime of 0.533 ms per frame, which is 1,101$\times$ faster than the sequential implementation and well within the real-time requirements of eyeblink conditioning in humans, i.e. faster than 500 frames per second.
Cloud-Based Dynamic Programming for an Electric City Bus Energy Management Considering Real-Time Passenger Load Prediction
Oct 28, 2020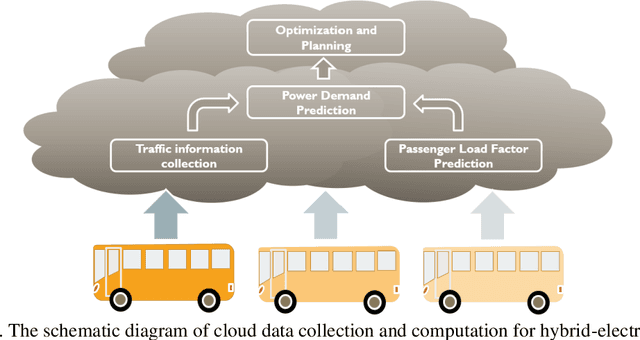
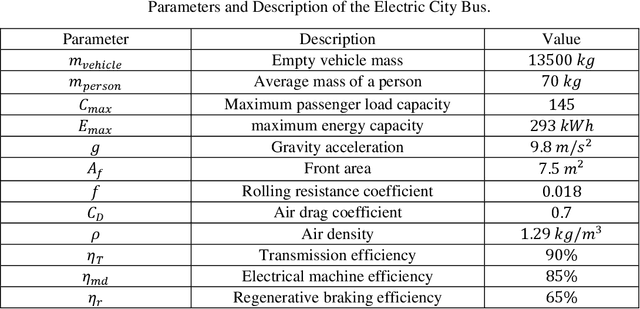
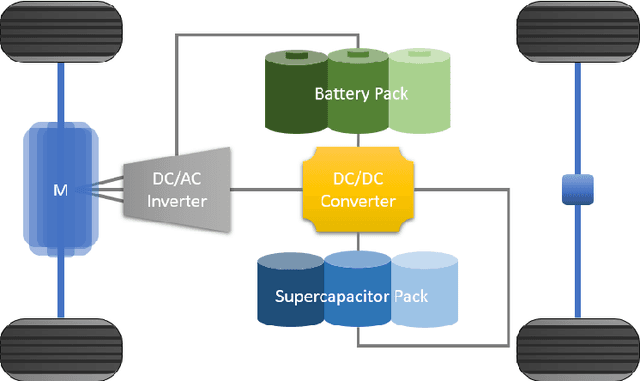

Electric city bus gains popularity in recent years for its low greenhouse gas emission, low noise level, etc. Different from a passenger car, the weight of a city bus varies significantly with different amounts of onboard passengers, which is not well studied in existing literature. This study proposes a passenger load prediction model using day-of-week, time-of-day, weather, temperatures, wind levels, and holiday information as inputs. The average model, Regression Tree, Gradient Boost Decision Tree, and Neural Networks models are compared in the passenger load prediction. The Gradient Boost Decision Tree model is selected due to its best accuracy and high stability. Given the predicted passenger load, dynamic programming algorithm determines the optimal power demand for supercapacitor and battery by optimizing the battery aging and energy usage in the cloud. Then rule extraction is conducted on dynamic programming results, and the rule is real-time loaded to onboard controllers of vehicles. The proposed cloud-based dynamic programming and rule extraction framework with the passenger load prediction shows 4% and 11% fewer bus operating costs in off-peak and peak hours, respectively. The operating cost by the proposed framework is less than 1% shy of the dynamic programming with the true passenger load information.
Switching Independent Vector Analysis and Its Extension to Blind and Spatially Guided Convolutional Beamforming Algorithm
Nov 20, 2021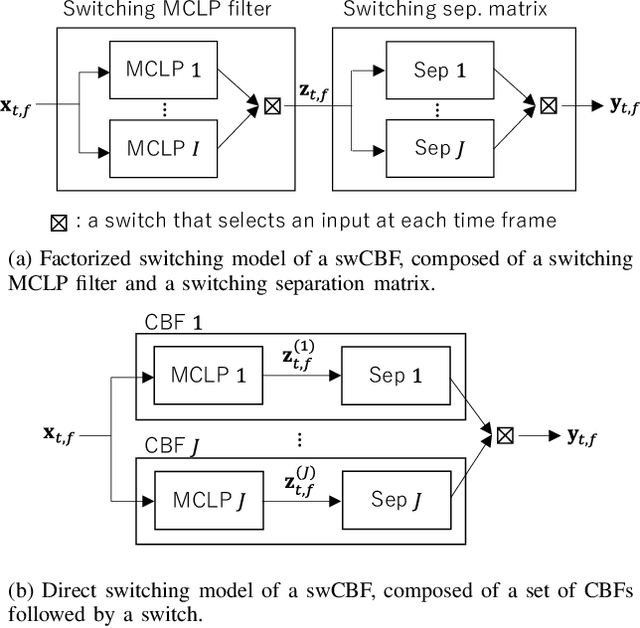
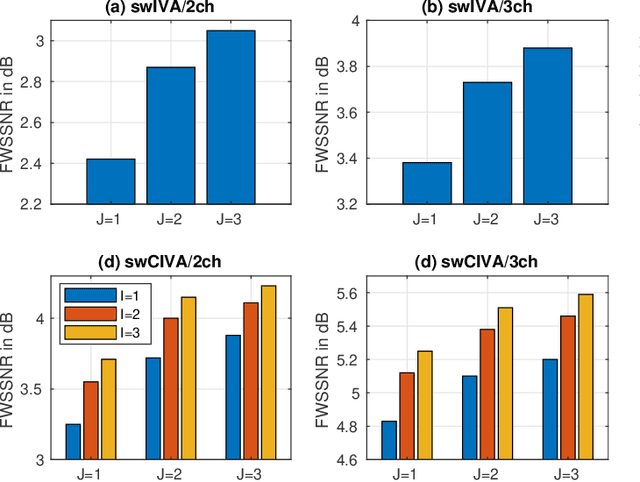
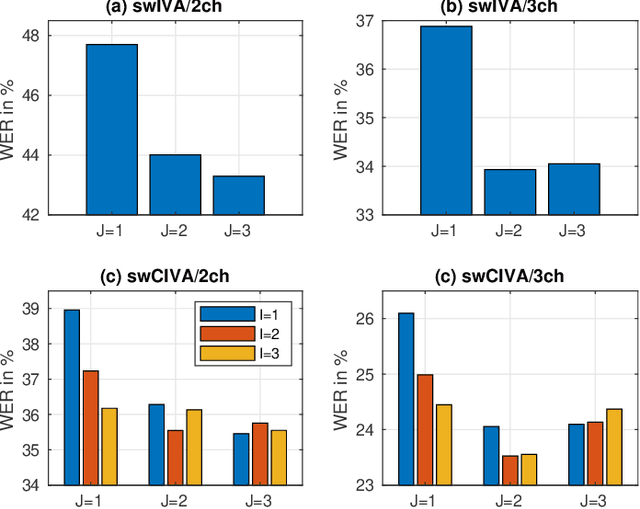
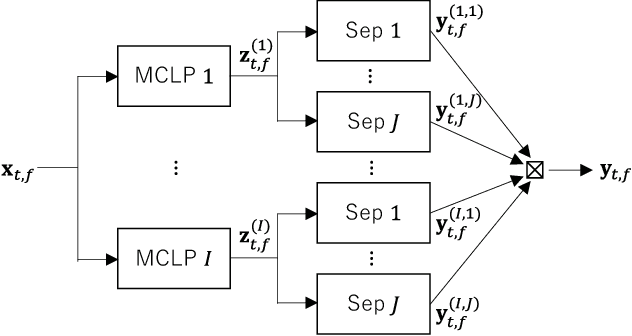
This paper develops a framework that can perform denoising, dereverberation, and source separation accurately by using a relatively small number of microphones. It has been empirically confirmed that Independent Vector Analysis (IVA) can blindly separate $N$ sources from their sound mixture even with diffuse noise when a sufficiently large number ($=M$) of microphones are available (i.e., $M\gg N)$. However, the estimation accuracy seriously degrades as the number of microphones, or more specifically $M-N$ $(\ge 0)$, decreases. To overcome this limitation of IVA, we propose switching IVA (swIVA) in this paper. With swIVA, time frames of an observed signal with time-varying characteristics are clustered into several groups, each of which can be well handled by IVA using a small number of microphones, and thus accurate estimation can be achieved by applying {\IVA} individually to each of the groups. Conventionally, a switching mechanism was introduced into a beamformer; however, no blind source separation algorithms with a switching mechanism have been successfully developed until this paper. In order to incorporate dereverberation capability, this paper further extends swIVA to blind Convolutional beamforming algorithm (swCIVA). It integrates swIVA and switching Weighted Prediction Error-based dereverberation (swWPE) in a jointly optimal way. We show that both swIVA and swIVAconv can be optimized effectively based on blind signal processing, and that their performance can be further improved using a spatial guide for the initialization. Experiments show that the both proposed methods largely outperform conventional IVA and its Convolutional beamforming extension (CIVA) in terms of objective signal quality and automatic speech recognition scores when using a relatively small number of microphones.