 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Online Estimation and Optimization of Utility-Based Shortfall Risk
Nov 16, 2021
Utility-Based Shortfall Risk (UBSR) is a risk metric that is increasingly popular in financial applications, owing to certain desirable properties that it enjoys. We consider the problem of estimating UBSR in a recursive setting, where samples from the underlying loss distribution are available one-at-a-time. We cast the UBSR estimation problem as a root finding problem, and propose stochastic approximation-based estimations schemes. We derive non-asymptotic bounds on the estimation error in the number of samples. We also consider the problem of UBSR optimization within a parameterized class of random variables. We propose a stochastic gradient descent based algorithm for UBSR optimization, and derive non-asymptotic bounds on its convergence.
EmotionNet Nano: An Efficient Deep Convolutional Neural Network Design for Real-time Facial Expression Recognition
Jun 29, 2020
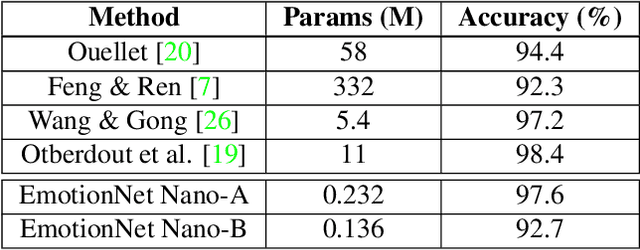
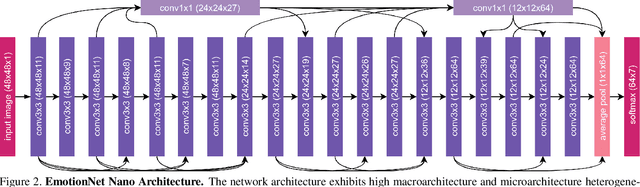
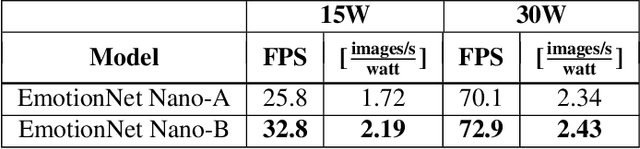
While recent advances in deep learning have led to significant improvements in facial expression classification (FEC), a major challenge that remains a bottleneck for the widespread deployment of such systems is their high architectural and computational complexities. This is especially challenging given the operational requirements of various FEC applications, such as safety, marketing, learning, and assistive living, where real-time requirements on low-cost embedded devices is desired. Motivated by this need for a compact, low latency, yet accurate system capable of performing FEC in real-time on low-cost embedded devices, this study proposes EmotionNet Nano, an efficient deep convolutional neural network created through a human-machine collaborative design strategy, where human experience is combined with machine meticulousness and speed in order to craft a deep neural network design catered towards real-time embedded usage. Two different variants of EmotionNet Nano are presented, each with a different trade-off between architectural and computational complexity and accuracy. Experimental results using the CK+ facial expression benchmark dataset demonstrate that the proposed EmotionNet Nano networks demonstrated accuracies comparable to state-of-the-art in FEC networks, while requiring significantly fewer parameters (e.g., 23$\times$ fewer at a higher accuracy). Furthermore, we demonstrate that the proposed EmotionNet Nano networks achieved real-time inference speeds (e.g. $>25$ FPS and $>70$ FPS at 15W and 30W, respectively) and high energy efficiency (e.g. $>1.7$ images/sec/watt at 15W) on an ARM embedded processor, thus further illustrating the efficacy of EmotionNet Nano for deployment on embedded devices.
Cooperation for Scalable Supervision of Autonomy in Mixed Traffic
Dec 14, 2021

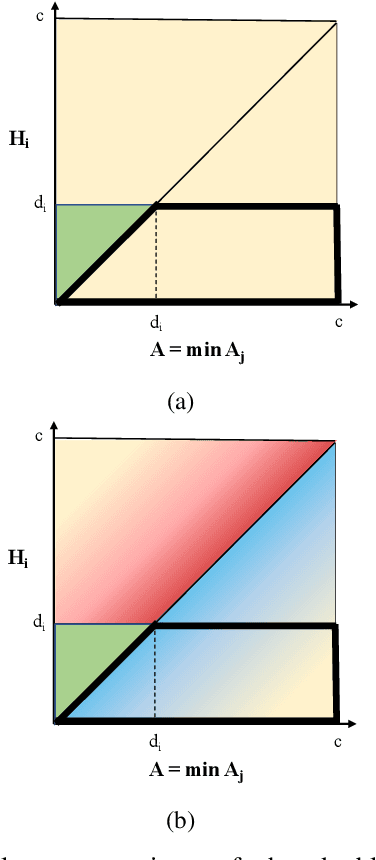
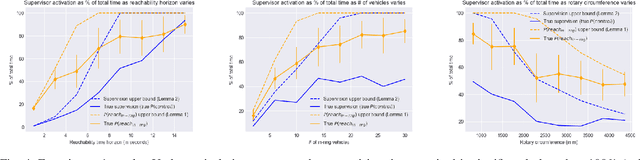
Improvements in autonomy offer the potential for positive outcomes in a number of domains, yet guaranteeing their safe deployment is difficult. This work investigates how humans can intelligently supervise agents to achieve some level of safety even when performance guarantees are elusive. The motivating research question is: In safety-critical settings, can we avoid the need to have one human supervise one machine at all times? The paper formalizes this 'scaling supervision' problem, and investigates its application to the safety-critical context of autonomous vehicles (AVs) merging into traffic. It proposes a conservative, reachability-based method to reduce the burden on the AVs' human supervisors, which allows for the establishment of high-confidence upper bounds on the supervision requirements in this setting. Order statistics and traffic simulations with deep reinforcement learning show analytically and numerically that teaming of AVs enables supervision time sublinear in AV adoption. A key takeaway is that, despite present imperfections of AVs, supervision becomes more tractable as AVs are deployed en masse. While this work focuses on AVs, the scalable supervision framework is relevant to a broader array of autonomous control challenges.
Temporal Knowledge Graph Embedding Model based on Additive Time Series Decomposition
Nov 18, 2019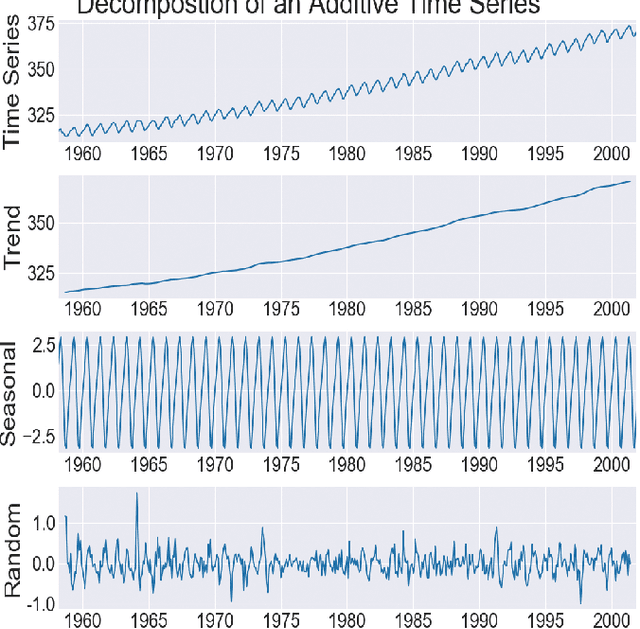
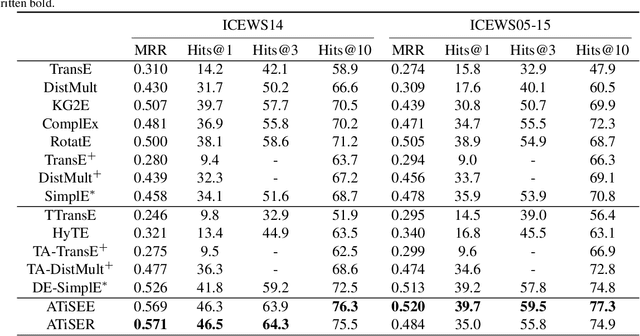
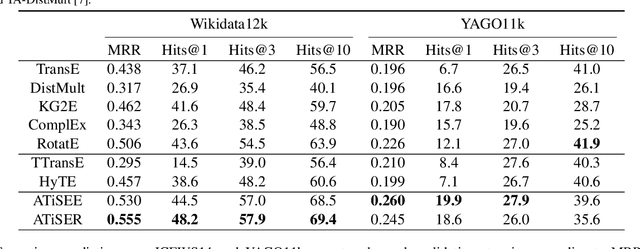
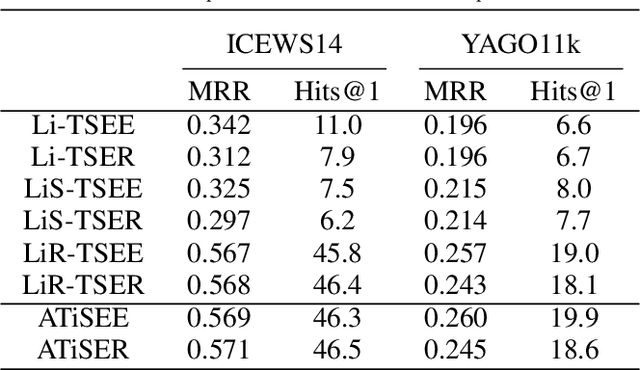
Knowledge Graph (KG) embedding has attracted more attention in recent years. Most of KG embedding models learn from time-unaware triples. However, the inclusion of temporal information beside triples would further improve the performance of a KGE model. In this regard, we propose ATiSE, a temporal KG embedding model which incorporates time information into entity/relation representations by using Additive Time Series decomposition. Moreover, considering the temporal uncertainty during the evolution of entity/relation representations over time, we map the representations of temporal KGs into the space of multi-dimensional Gaussian distributions. The mean of each entity/relation embedding at a time step shows the current expected position, whereas its covariance (which is temporally stationary) represents its temporal uncertainty. Experimental results show that ATiSE not only achieves the state-of-the-art on link prediction over temporal KGs, but also can predict the occurrence time of facts with missing time annotations, as well as the existence of future events. To the best of our knowledge, no other model is capable to perform all these tasks.
Energy-Efficient Design for a NOMA assisted STAR-RIS Network with Deep Reinforcement Learning
Nov 30, 2021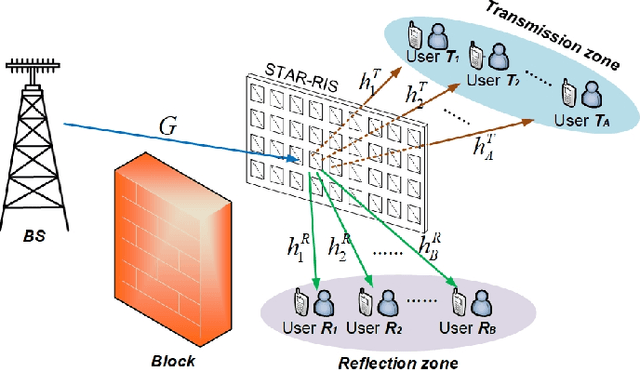
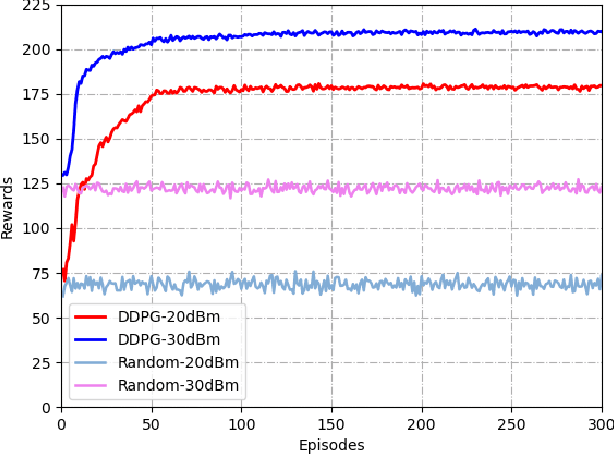
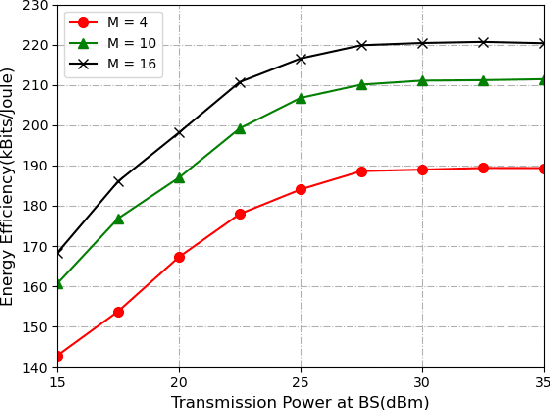
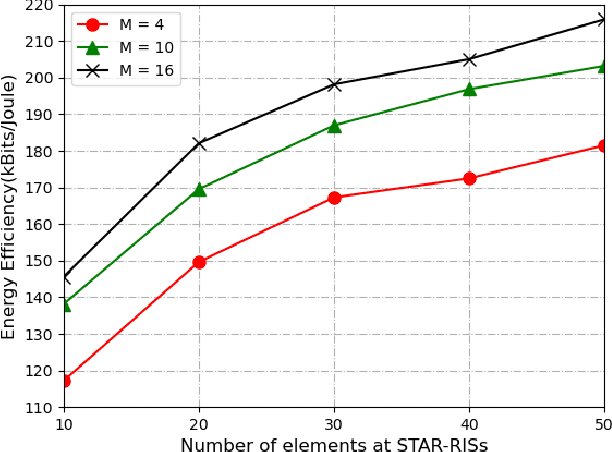
Simultaneous transmitting and reflecting reconfigurable intelligent surfaces (STAR-RISs) has been considered as a promising auxiliary device to enhance the performance of the wireless network, where users located at the different sides of the surfaces can be simultaneously served by the transmitting and reflecting signals. In this paper, the energy efficiency (EE) maximization problem for a non-orthogonal multiple access (NOMA) assisted STAR-RIS downlink network is investigated. Due to the fractional form of the EE, it is challenging to solve the EE maximization problem by the traditional convex optimization solutions. In this work, a deep deterministic policy gradient (DDPG)-based algorithm is proposed to maximize the EE by jointly optimizing the transmission beamforming vectors at the base station and the coefficients matrices at the STAR-RIS. Simulation results demonstrate that the proposed algorithm can effectively maximize the system EE considering the time-varying channels.
On The Reliability Of Machine Learning Applications In Manufacturing Environments
Dec 19, 2021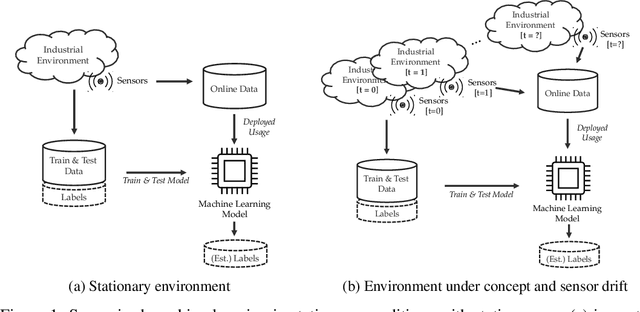
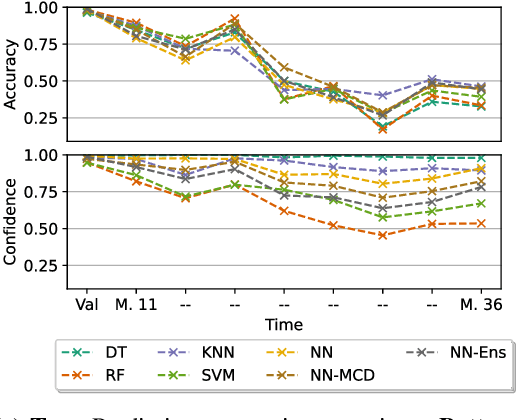
The increasing deployment of advanced digital technologies such as Internet of Things (IoT) devices and Cyber-Physical Systems (CPS) in industrial environments is enabling the productive use of machine learning (ML) algorithms in the manufacturing domain. As ML applications transcend from research to productive use in real-world industrial environments, the question of reliability arises. Since the majority of ML models are trained and evaluated on static datasets, continuous online monitoring of their performance is required to build reliable systems. Furthermore, concept and sensor drift can lead to degrading accuracy of the algorithm over time, thus compromising safety, acceptance and economics if undetected and not properly addressed. In this work, we exemplarily highlight the severity of the issue on a publicly available industrial dataset which was recorded over the course of 36 months and explain possible sources of drift. We assess the robustness of ML algorithms commonly used in manufacturing and show, that the accuracy strongly declines with increasing drift for all tested algorithms. We further investigate how uncertainty estimation may be leveraged for online performance estimation as well as drift detection as a first step towards continually learning applications. The results indicate, that ensemble algorithms like random forests show the least decay of confidence calibration under drift.
Bounded-Memory Criteria for Streams with Application Time
Jul 30, 2020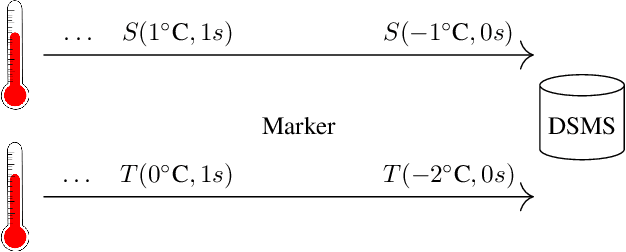
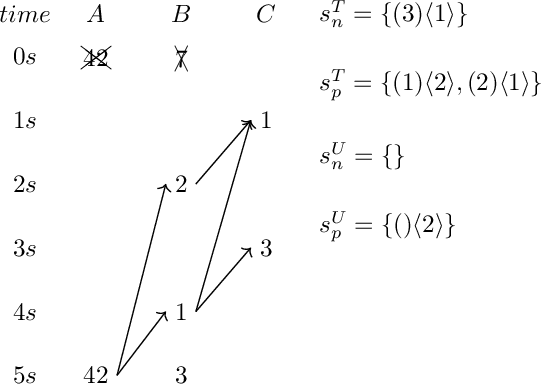
Bounded-memory computability continues to be in the focus of those areas of AI and databases that deal with feasible computations over streams---be it feasible arithmetical calculations on low-level streams or feasible query answering for declaratively specified queries on relational data streams or even feasible query answering for high-level queries on streams w.r.t. a set of constraints in an ontology such as in the paradigm of Ontology-Based Data Access (OBDA). In classical OBDA, a high-level query is answered by transforming it into a query on data source level. The transformation requires a rewriting step, where knowledge from an ontology is incorporated into the query, followed by an unfolding step with respect to a set of mappings. Given an OBDA setting it is very difficult to decide, whether and how a query can be answered efficiently. In particular it is difficult to decide whether a query can be answered in bounded memory, i.e., in constant space w.r.t. an infinitely growing prefix of a data stream. This work presents criteria for bounded-memory computability of select-project-join (SPJ) queries over streams with application time. Deciding whether an SPJ query can be answered in constant space is easier than for high-level queries, as neither an ontology nor a set of mappings are part of the input. Using the transformation process of classical OBDA, these criteria then can help deciding the efficiency of answering high-level queries on streams.
* 11 pages, 2 figures
Online Reinforcement Learning Control by Direct Heuristic Dynamic Programming: from Time-Driven to Event-Driven
Jun 16, 2020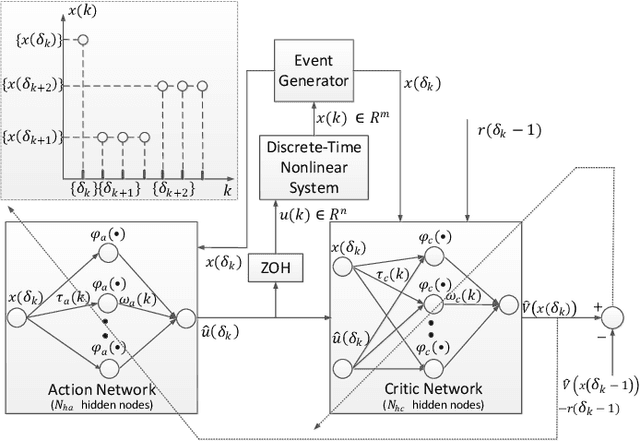
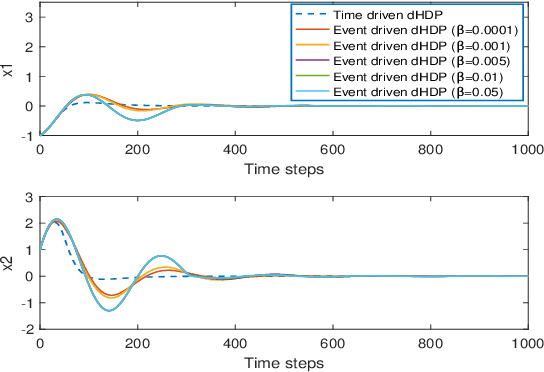
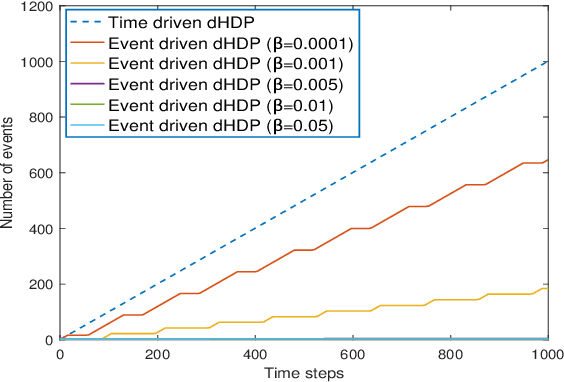
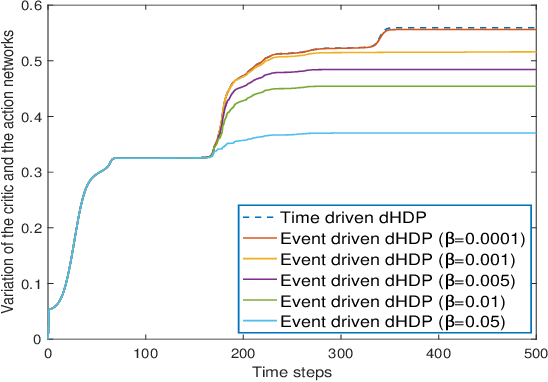
In this paper time-driven learning refers to the machine learning method that updates parameters in a prediction model continuously as new data arrives. Among existing approximate dynamic programming (ADP) and reinforcement learning (RL) algorithms, the direct heuristic dynamic programming (dHDP) has been shown an effective tool as demonstrated in solving several complex learning control problems. It continuously updates the control policy and the critic as system states continuously evolve. It is therefore desirable to prevent the time-driven dHDP from updating due to insignificant system event such as noise. Toward this goal, we propose a new event-driven dHDP. By constructing a Lyapunov function candidate, we prove the uniformly ultimately boundedness (UUB) of the system states and the weights in the critic and the control policy networks. Consequently we show the approximate control and cost-to-go function approaching Bellman optimality within a finite bound. We also illustrate how the event-driven dHDP algorithm works in comparison to the original time-driven dHDP.
Avoiding Catastrophe: Active Dendrites Enable Multi-Task Learning in Dynamic Environments
Dec 31, 2021
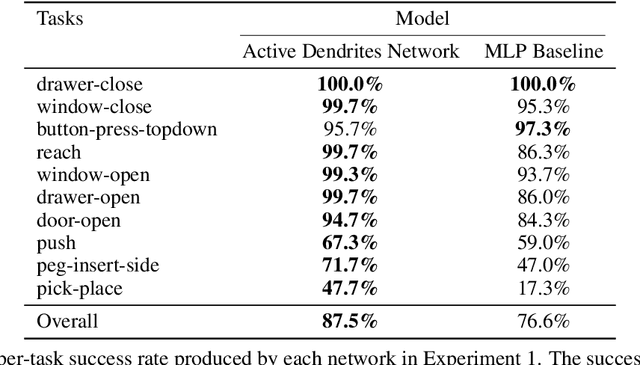
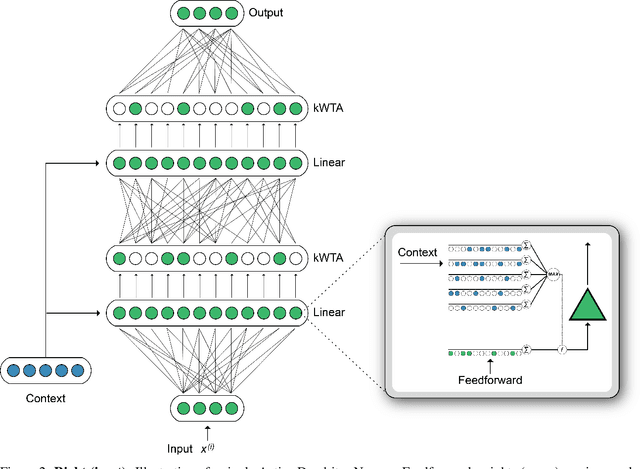
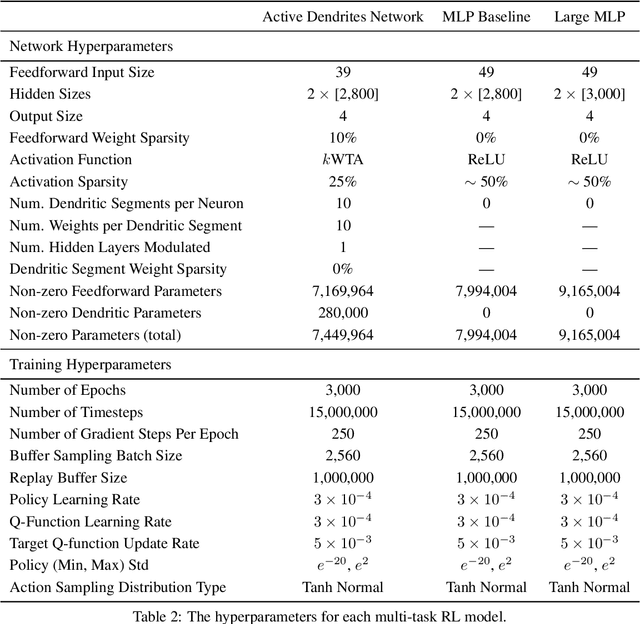
A key challenge for AI is to build embodied systems that operate in dynamically changing environments. Such systems must adapt to changing task contexts and learn continuously. Although standard deep learning systems achieve state of the art results on static benchmarks, they often struggle in dynamic scenarios. In these settings, error signals from multiple contexts can interfere with one another, ultimately leading to a phenomenon known as catastrophic forgetting. In this article we investigate biologically inspired architectures as solutions to these problems. Specifically, we show that the biophysical properties of dendrites and local inhibitory systems enable networks to dynamically restrict and route information in a context-specific manner. Our key contributions are as follows. First, we propose a novel artificial neural network architecture that incorporates active dendrites and sparse representations into the standard deep learning framework. Next, we study the performance of this architecture on two separate benchmarks requiring task-based adaptation: Meta-World, a multi-task reinforcement learning environment where a robotic agent must learn to solve a variety of manipulation tasks simultaneously; and a continual learning benchmark in which the model's prediction task changes throughout training. Analysis on both benchmarks demonstrates the emergence of overlapping but distinct and sparse subnetworks, allowing the system to fluidly learn multiple tasks with minimal forgetting. Our neural implementation marks the first time a single architecture has achieved competitive results on both multi-task and continual learning settings. Our research sheds light on how biological properties of neurons can inform deep learning systems to address dynamic scenarios that are typically impossible for traditional ANNs to solve.
Causal Effect Variational Autoencoder with Uniform Treatment
Nov 16, 2021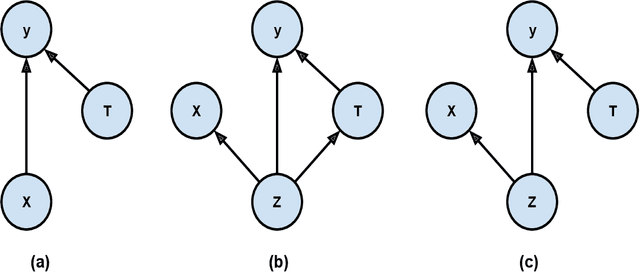


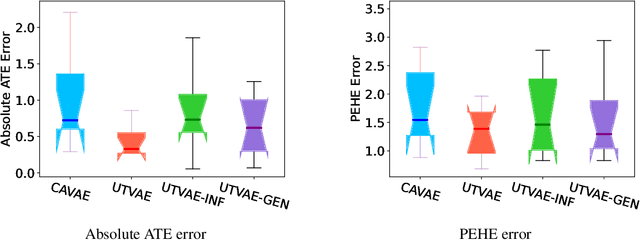
Causal effect variational autoencoder (CEVAE) are trained to predict the outcome given observational treatment data, while uniform treatment variational autoencoders (UTVAE) are trained with uniform treatment distribution using importance sampling. In this paper, we show that using uniform treatment over observational treatment distribution leads to better causal inference by mitigating the distribution shift that occurs from training to test time. We also explore the combination of uniform and observational treatment distributions with inference and generative network training objectives to find a better training procedure for inferring treatment effect. Experimentally, we find that the proposed UTVAE yields better absolute average treatment effect error and precision in estimation of heterogeneous effect error than the CEVAE on synthetic and IHDP datasets.