 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Myelin: An asynchronous, message-driven parallel framework for extreme-scale deep learning
Oct 26, 2021
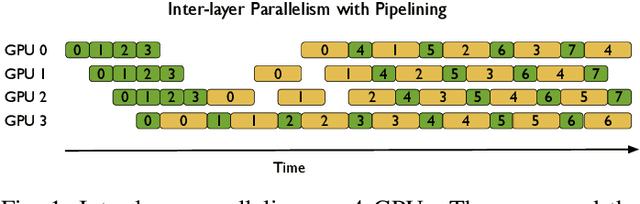
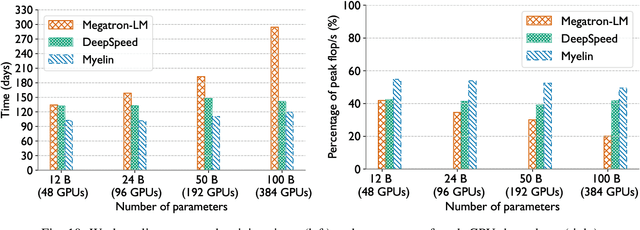
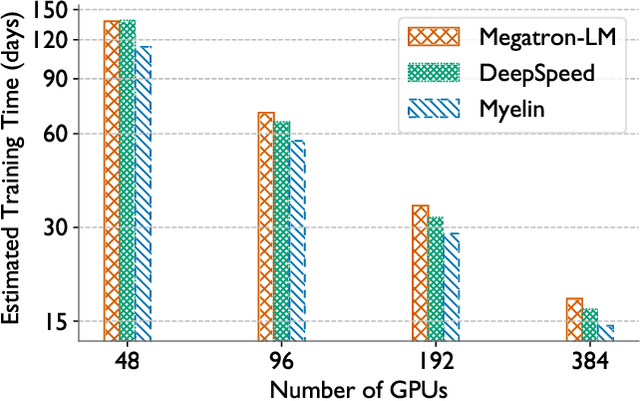
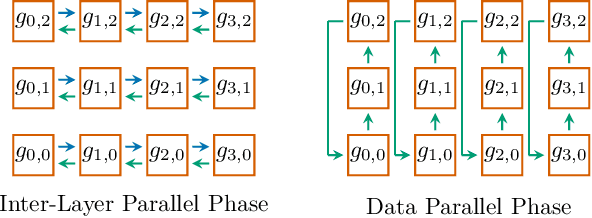
In the last few years, the memory requirements to train state-of-the-art neural networks have far exceeded the DRAM capacities of modern hardware accelerators. This has necessitated the development of efficient algorithms to train these neural networks in parallel on large-scale GPU-based clusters. Since computation is relatively inexpensive on modern GPUs, designing and implementing extremely efficient communication in these parallel training algorithms is critical for extracting the maximum performance. This paper presents Myelin, a parallel deep learning framework that exploits asynchrony and message-driven execution to schedule neural network operations on each GPU, thereby reducing GPU idle time and maximizing hardware efficiency. By using the CPU memory as a scratch space for offloading data periodically during training, Myelin is able to reduce GPU memory consumption by four times. This allows us to increase the number of parameters per GPU by four times, thus reducing the amount of communication and increasing performance by over 13%. When tested against large transformer models with 12-100 billion parameters on 48-384 NVIDIA Tesla V100 GPUs, Myelin achieves a per-GPU throughput of 49.4-54.78% of theoretical peak and reduces the training time by 22-37 days (15-25% speedup) as compared to the state-of-the-art.
Neural Topic Models with Survival Supervision: Jointly Predicting Time-to-Event Outcomes and Learning How Clinical Features Relate
Jul 15, 2020
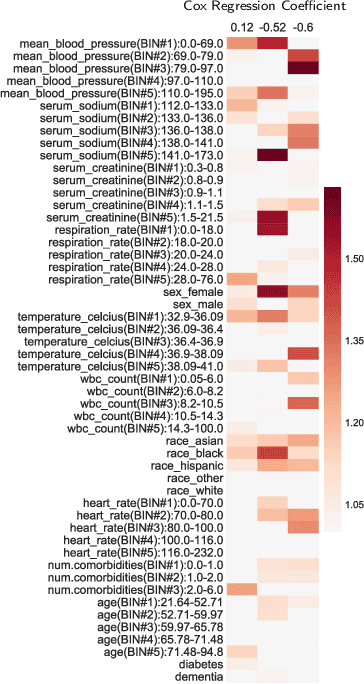
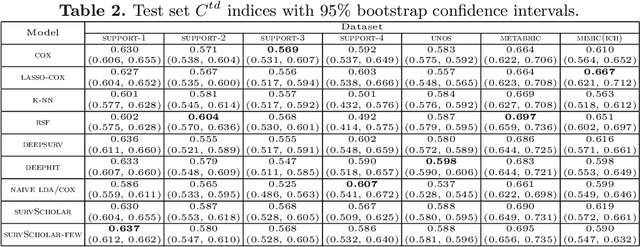
In time-to-event prediction problems, a standard approach to estimating an interpretable model is to use Cox proportional hazards, where features are selected based on lasso regularization or stepwise regression. However, these Cox-based models do not learn how different features relate. As an alternative, we present an interpretable neural network approach to jointly learn a survival model to predict time-to-event outcomes while simultaneously learning how features relate in terms of a topic model. In particular, we model each subject as a distribution over "topics", which are learned from clinical features as to help predict a time-to-event outcome. From a technical standpoint, we extend existing neural topic modeling approaches to also minimize a survival analysis loss function. We study the effectiveness of this approach on seven healthcare datasets on predicting time until death as well as hospital ICU length of stay, where we find that neural survival-supervised topic models achieves competitive accuracy with existing approaches while yielding interpretable clinical "topics" that explain feature relationships.
Investigating the Impact of 9/11 on The Simpsons through Natural Language Processing
Dec 02, 2021
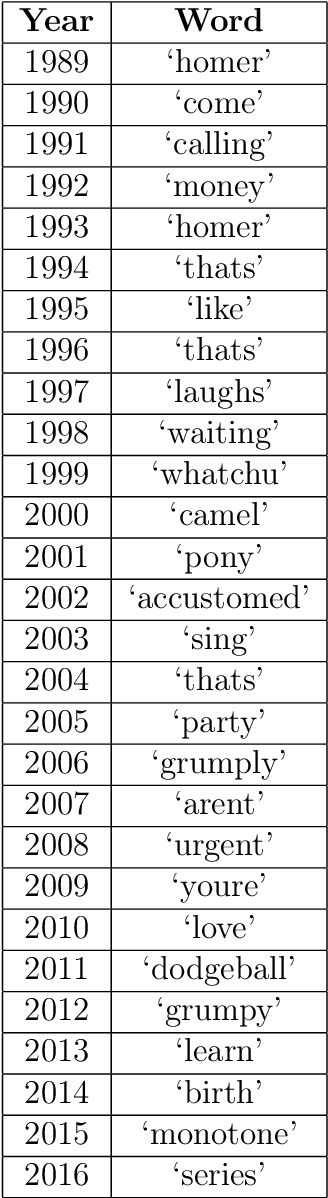
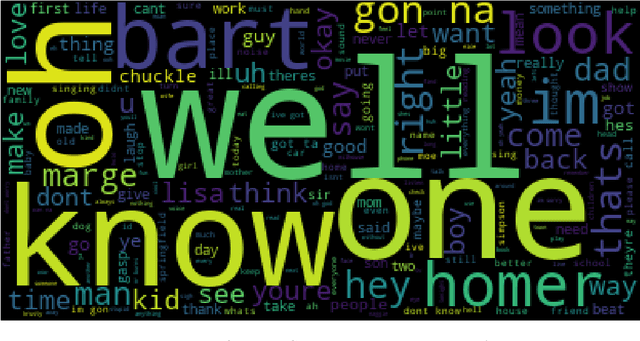

The impact of real world events on fictional media is particularly apparent in the American cartoon series The Simpsons. While there are often very direct pop culture references evident in the dialogue and visual gags of the show, subtle changes in tone or sentiment may not be so obvious. Our aim was to use Natural Language Processing to attempt to search for changes in word frequency, topic, and sentiment before and after the September 11 terrorist attacks in New York. No clear trend change was seen, there was a slight decrease in the average sentiment over time around the relevant period between 2000 and 2002, but the scripts still maintained an overall positive value, indicating that the comedic nature of The Simpsons did not wane particularly significantly. The exploration of other social issues and even specific character statistics is needed to bolster the findings here.
Analysis and Evaluation of Kinect-based Action Recognition Algorithms
Dec 16, 2021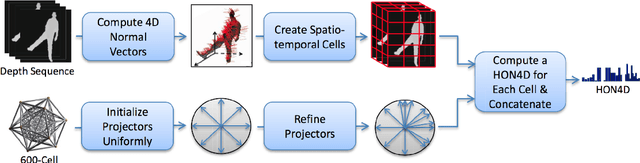

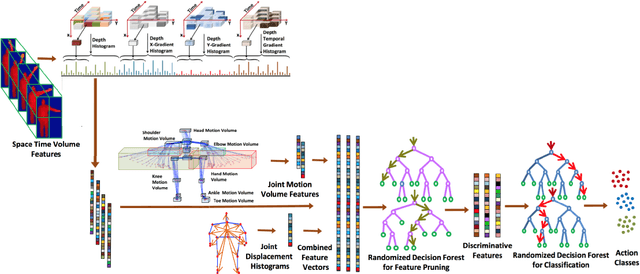

Human action recognition still exists many challenging problems such as different viewpoints, occlusion, lighting conditions, human body size and the speed of action execution, although it has been widely used in different areas. To tackle these challenges, the Kinect depth sensor has been developed to record real time depth sequences, which are insensitive to the color of human clothes and illumination conditions. Many methods on recognizing human action have been reported in the literature such as HON4D, HOPC, RBD and HDG, which use the 4D surface normals, pointclouds, skeleton-based model and depth gradients respectively to capture discriminative information from depth videos or skeleton data. In this research project, the performance of four aforementioned algorithms will be analyzed and evaluated using five benchmark datasets, which cover challenging issues such as noise, change of viewpoints, background clutters and occlusions. We also implemented and improved the HDG algorithm, and applied it in cross-view action recognition using the UWA3D Multiview Activity dataset. Moreover, we used different combinations of individual feature vectors in HDG for performance evaluation. The experimental results show that our improvement of HDG outperforms other three state-of-the-art algorithms for cross-view action recognition.
Low-complexity Rounded KLT Approximation for Image Compression
Nov 28, 2021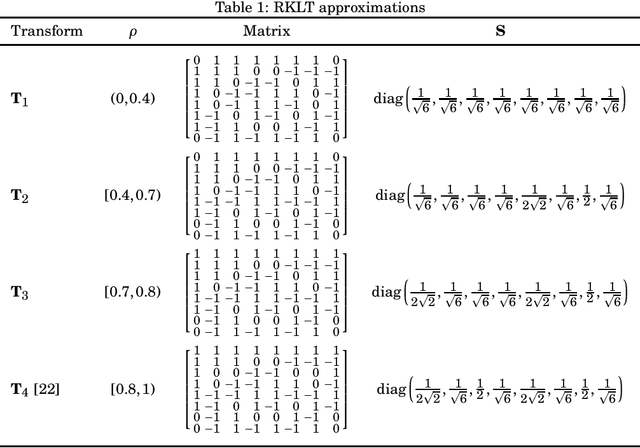
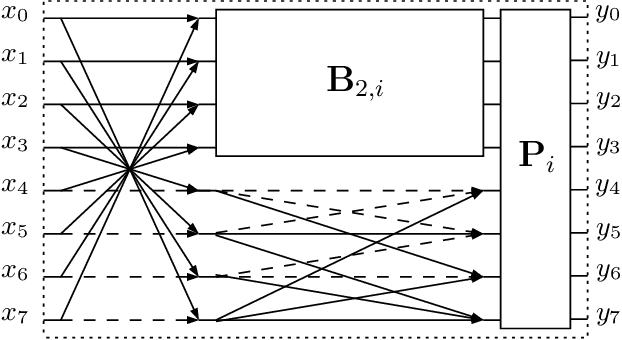

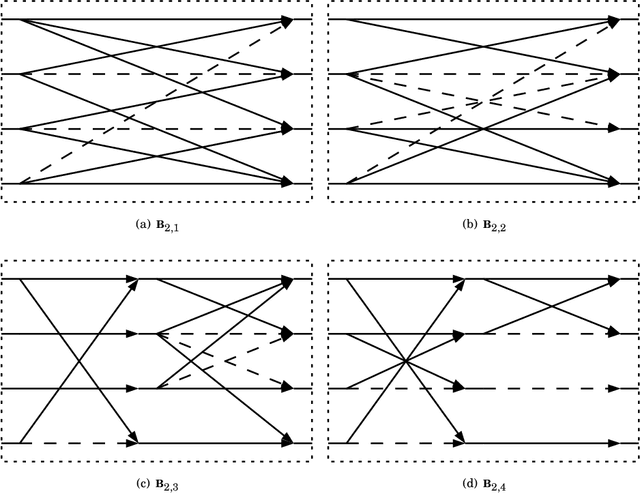
The Karhunen-Lo\`eve transform (KLT) is often used for data decorrelation and dimensionality reduction. Because its computation depends on the matrix of covariances of the input signal, the use of the KLT in real-time applications is severely constrained by the difficulty in developing fast algorithms to implement it. In this context, this paper proposes a new class of low-complexity transforms that are obtained through the application of the round function to the elements of the KLT matrix. The proposed transforms are evaluated considering figures of merit that measure the coding power and distance of the proposed approximations to the exact KLT and are also explored in image compression experiments. Fast algorithms are introduced for the proposed approximate transforms. It was shown that the proposed transforms perform well in image compression and require a low implementation cost.
* 10 pages, 7 figures, 3 tables
Distributed Transmit Beamforming: Design and Demonstration from the Lab to UAVs
Oct 26, 2021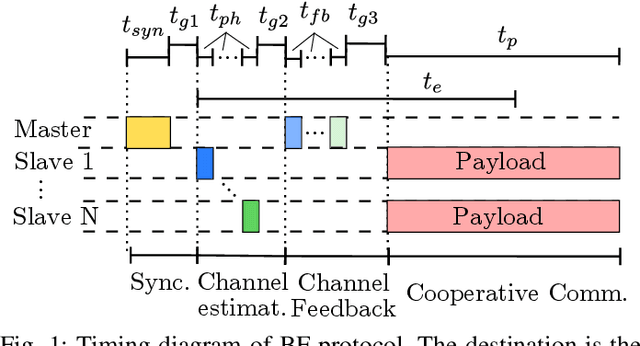
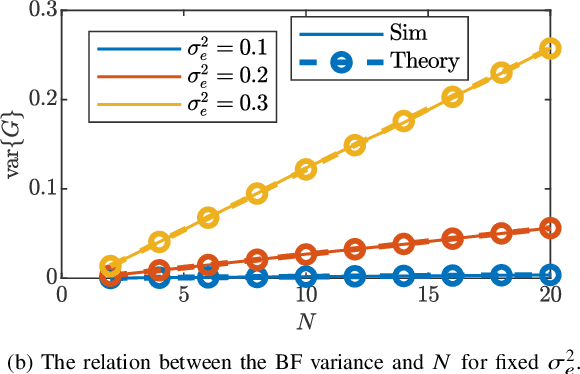
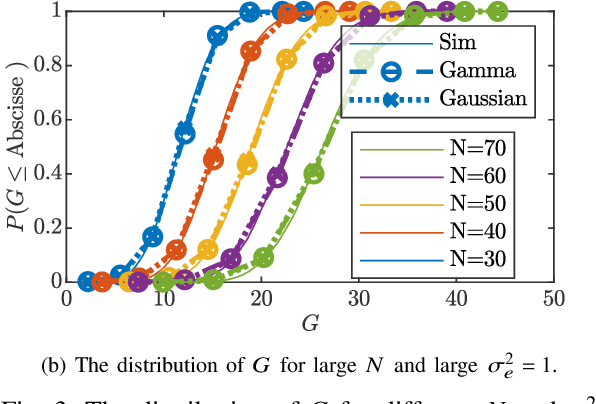
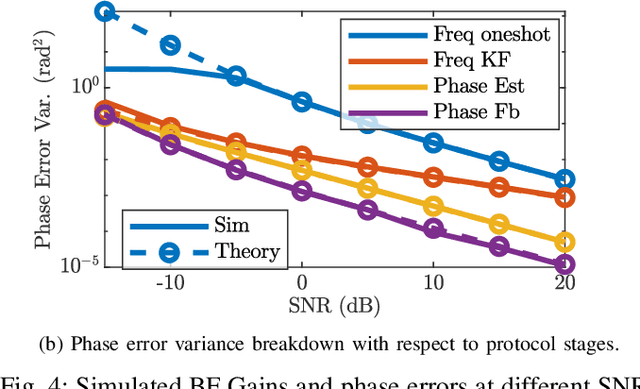
Cooperating radios can extend their communication range by adjusting their signals to ensure coherent combining at a destination radio. This technique is called distributed transmit beamforming. Beamforming (BF) relies on the BF radios having frequency synchronized carriers and phases adjusted for coherent combining. Both requirements are typically met by exchanging preambles with the destination. However, since BF aims to increase the communication range, the individually transmitted preambles are typically at low SNR and their lengths are constrained by the channel coherence time. These noisy preambles lead to errors in frequency and phase estimation, which result in randomly changing BF gains. To build reliable distributed BF systems, the impact of estimation errors on the BF gains need to be considered in the design. In this work, assuming a destination-led BF protocol and Kalman filter for frequency tracking, we optimize the number of BF radios and the preamble lengths to achieve reliable BF gain. To do that, we characterize the relations between the BF gains distribution, the channel coherence time, and design parameters like the SNR, preamble lengths, and the number of radios. The proposed relations are verified using simulations and via experiments using software-defined radios in a lab and on UAVs.
Block-Skim: Efficient Question Answering for Transformer
Dec 16, 2021

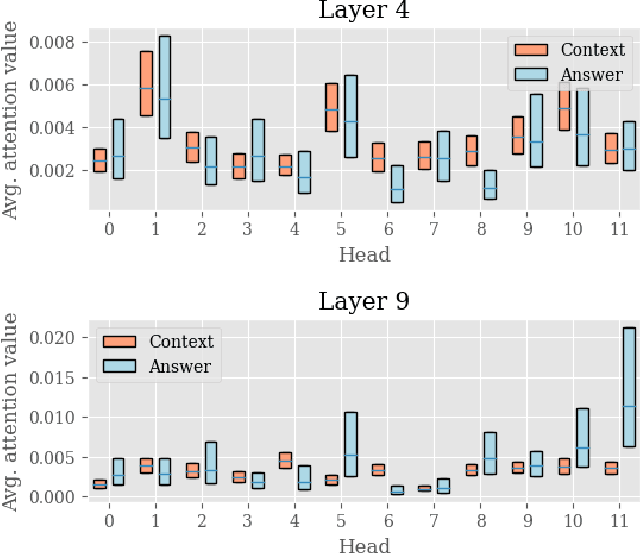
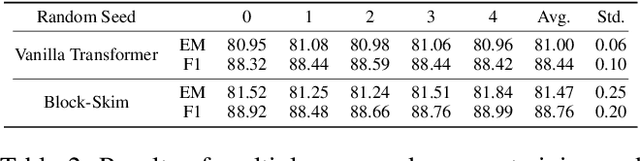
Transformer models have achieved promising results on natural language processing (NLP) tasks including extractive question answering (QA). Common Transformer encoders used in NLP tasks process the hidden states of all input tokens in the context paragraph throughout all layers. However, different from other tasks such as sequence classification, answering the raised question does not necessarily need all the tokens in the context paragraph. Following this motivation, we propose Block-skim, which learns to skim unnecessary context in higher hidden layers to improve and accelerate the Transformer performance. The key idea of Block-Skim is to identify the context that must be further processed and those that could be safely discarded early on during inference. Critically, we find that such information could be sufficiently derived from the self-attention weights inside the Transformer model. We further prune the hidden states corresponding to the unnecessary positions early in lower layers, achieving significant inference-time speedup. To our surprise, we observe that models pruned in this way outperform their full-size counterparts. Block-Skim improves QA models' accuracy on different datasets and achieves 3 times speedup on BERT-base model.
Activity-based and agent-based Transport model of Melbourne (AToM): an open multi-modal transport simulation model for Greater Melbourne
Dec 16, 2021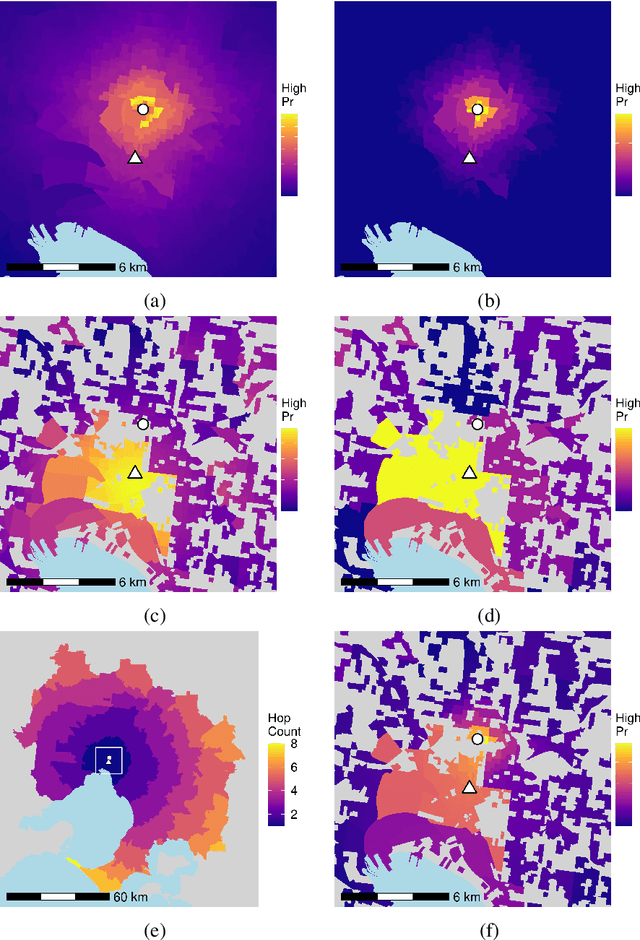
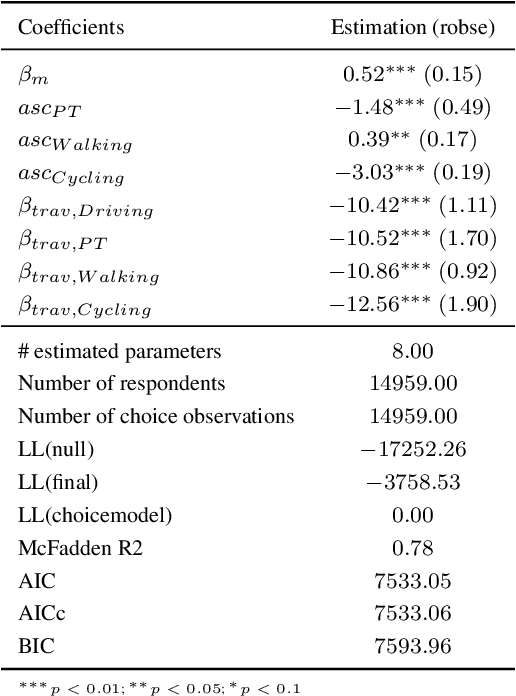
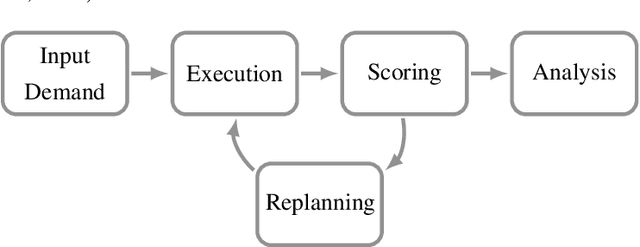
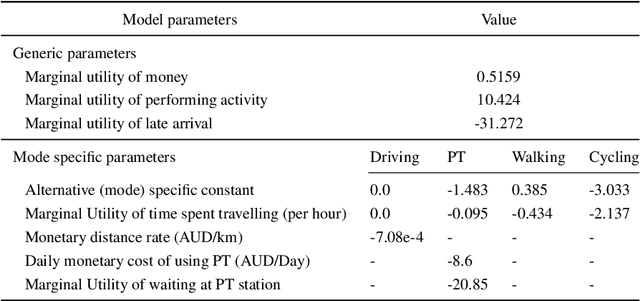
Agent-based and activity-based models for simulating transportation systems have attracted significant attention in recent years. Few studies, however, include a detailed representation of active modes of transportation - such as walking and cycling - at a city-wide level, where dominating motorised modes are often of primary concern. This paper presents an open workflow for creating a multi-modal agent-based and activity-based transport simulation model, focusing on Greater Melbourne, and including the process of mode choice calibration for the four main travel modes of driving, public transport, cycling and walking. The synthetic population generated and used as an input for the simulation model represented Melbourne's population based on Census 2016, with daily activities and trips based on the Victoria's 2016-18 travel survey data. The road network used in the simulation model includes all public roads accessible via the included travel modes. We compared the output of the simulation model with observations from the real world in terms of mode share, road volume, travel time, and travel distance. Through these comparisons, we showed that our model is suitable for studying mode choice and road usage behaviour of travellers.
Next Day Wildfire Spread: A Machine Learning Data Set to Predict Wildfire Spreading from Remote-Sensing Data
Dec 04, 2021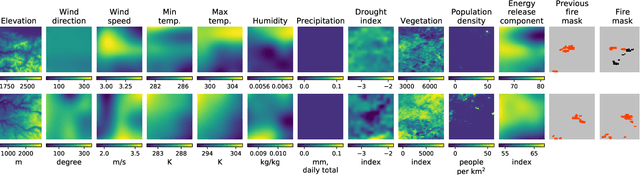
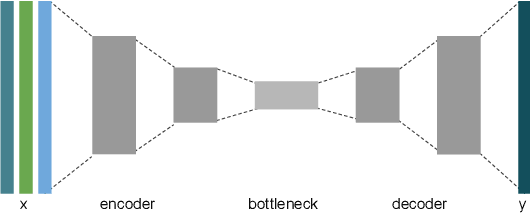
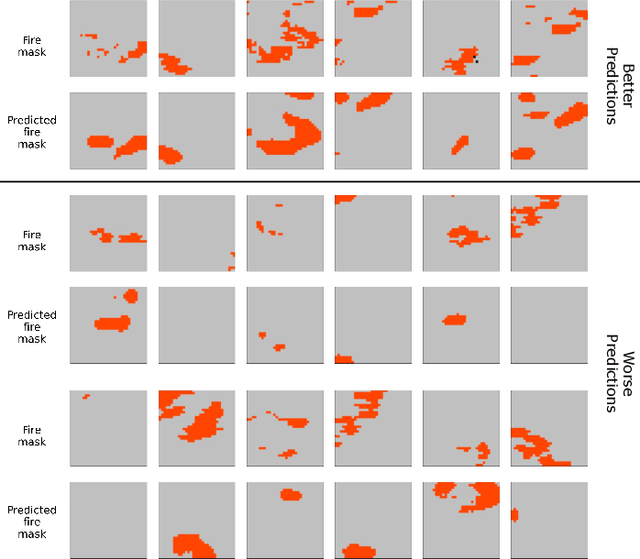
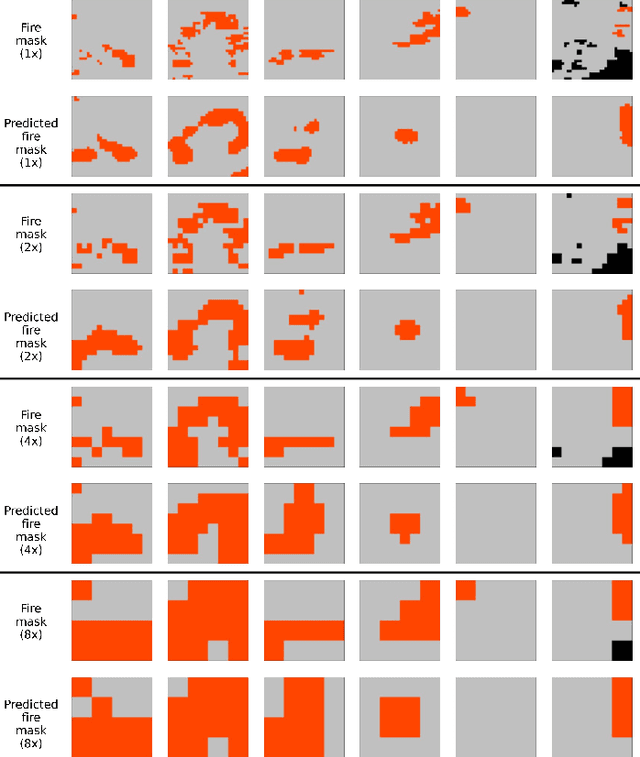
Predicting wildfire spread is critical for land management and disaster preparedness. To this end, we present `Next Day Wildfire Spread,' a curated, large-scale, multivariate data set of historical wildfires aggregating nearly a decade of remote-sensing data across the United States. In contrast to existing fire data sets based on Earth observation satellites, our data set combines 2D fire data with multiple explanatory variables (e.g., topography, vegetation, weather, drought index, population density) aligned over 2D regions, providing a feature-rich data set for machine learning. To demonstrate the usefulness of this data set, we implement a convolutional autoencoder that takes advantage of the spatial information of this data to predict wildfire spread. We compare the performance of the neural network with other machine learning models: logistic regression and random forest. This data set can be used as a benchmark for developing wildfire propagation models based on remote sensing data for a lead time of one day.
EmotionNet Nano: An Efficient Deep Convolutional Neural Network Design for Real-time Facial Expression Recognition
Jun 29, 2020
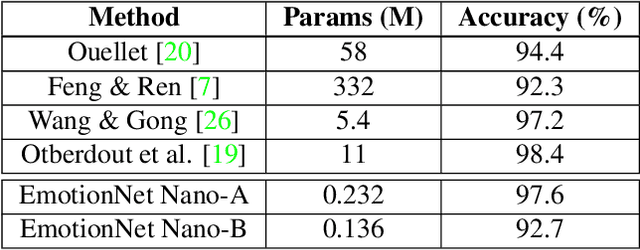
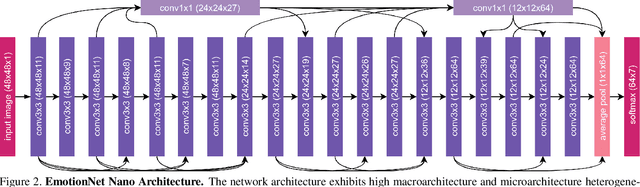
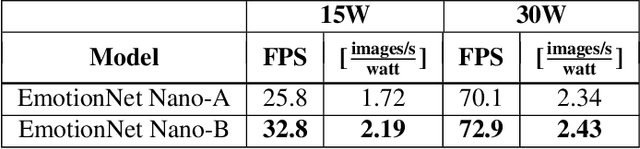
While recent advances in deep learning have led to significant improvements in facial expression classification (FEC), a major challenge that remains a bottleneck for the widespread deployment of such systems is their high architectural and computational complexities. This is especially challenging given the operational requirements of various FEC applications, such as safety, marketing, learning, and assistive living, where real-time requirements on low-cost embedded devices is desired. Motivated by this need for a compact, low latency, yet accurate system capable of performing FEC in real-time on low-cost embedded devices, this study proposes EmotionNet Nano, an efficient deep convolutional neural network created through a human-machine collaborative design strategy, where human experience is combined with machine meticulousness and speed in order to craft a deep neural network design catered towards real-time embedded usage. Two different variants of EmotionNet Nano are presented, each with a different trade-off between architectural and computational complexity and accuracy. Experimental results using the CK+ facial expression benchmark dataset demonstrate that the proposed EmotionNet Nano networks demonstrated accuracies comparable to state-of-the-art in FEC networks, while requiring significantly fewer parameters (e.g., 23$\times$ fewer at a higher accuracy). Furthermore, we demonstrate that the proposed EmotionNet Nano networks achieved real-time inference speeds (e.g. $>25$ FPS and $>70$ FPS at 15W and 30W, respectively) and high energy efficiency (e.g. $>1.7$ images/sec/watt at 15W) on an ARM embedded processor, thus further illustrating the efficacy of EmotionNet Nano for deployment on embedded devices.