 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Zero-Shot Machine Unlearning
Jan 14, 2022
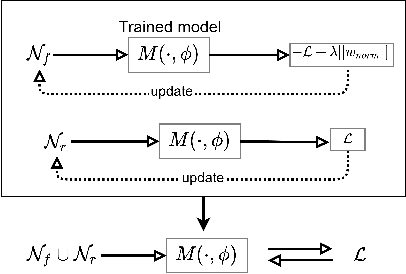
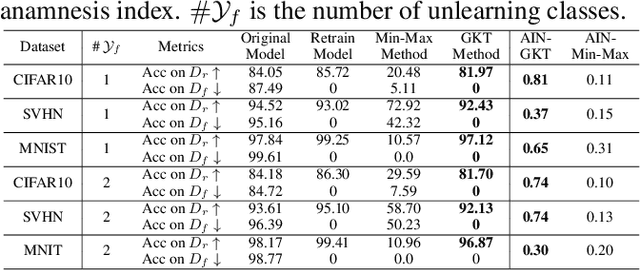
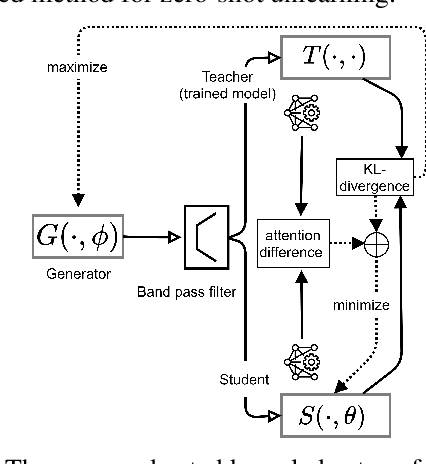
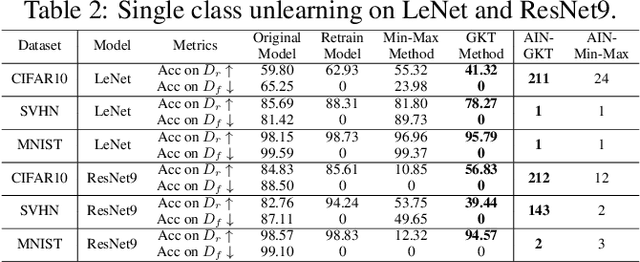
With the introduction of new privacy regulations, machine unlearning is becoming an emerging research problem due to an increasing need for regulatory compliance required for machine learning (ML) applications. Modern privacy regulations grant citizens the right to be forgotten by products, services and companies. This necessitates deletion of data not only from storage archives but also from ML model. The right to be forgotten requests come in the form of removal of a certain set or class of data from the already trained ML model. Practical considerations preclude retraining of the model from scratch minus the deleted data. The few existing studies use the whole training data, or a subset of training data, or some metadata stored during training to update the model weights for unlearning. However, strict regulatory compliance requires time-bound deletion of data. Thus, in many cases, no data related to the training process or training samples may be accessible even for the unlearning purpose. We therefore ask the question: is it possible to achieve unlearning with zero training samples? In this paper, we introduce the novel problem of zero-shot machine unlearning that caters for the extreme but practical scenario where zero original data samples are available for use. We then propose two novel solutions for zero-shot machine unlearning based on (a) error minimizing-maximizing noise and (b) gated knowledge transfer. We also introduce a new evaluation metric, Anamnesis Index (AIN) to effectively measure the quality of the unlearning method. The experiments show promising results for unlearning in deep learning models on benchmark vision data-sets. The source code will be made publicly available.
Finite-Time Analysis of Stochastic Gradient Descent under Markov Randomness
Apr 01, 2020Motivated by broad applications in reinforcement learning and machine learning, this paper considers the popular stochastic gradient descent (SGD) when the gradients of the underlying objective function are sampled from Markov processes. This Markov sampling leads to the gradient samples being biased and not independent. The existing results for the convergence of SGD under Markov randomness are often established under the assumptions on the boundedness of either the iterates or the gradient samples. Our main focus is to study the finite-time convergence of SGD for different types of objective functions, without requiring these assumptions. We show that SGD converges nearly at the same rate with Markovian gradient samples as with independent gradient samples. The only difference is a logarithmic factor that accounts for the mixing time of the Markov chain.
Deep Learning Head Model for Real-time Estimation of Entire Brain Deformation in Concussion
Oct 20, 2020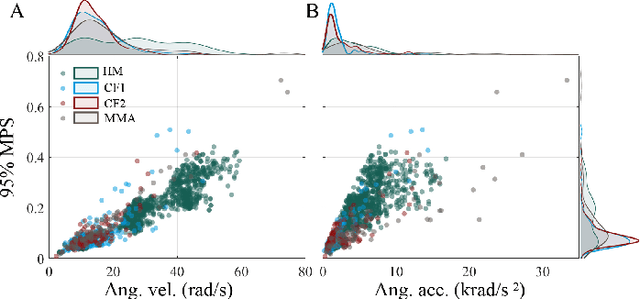

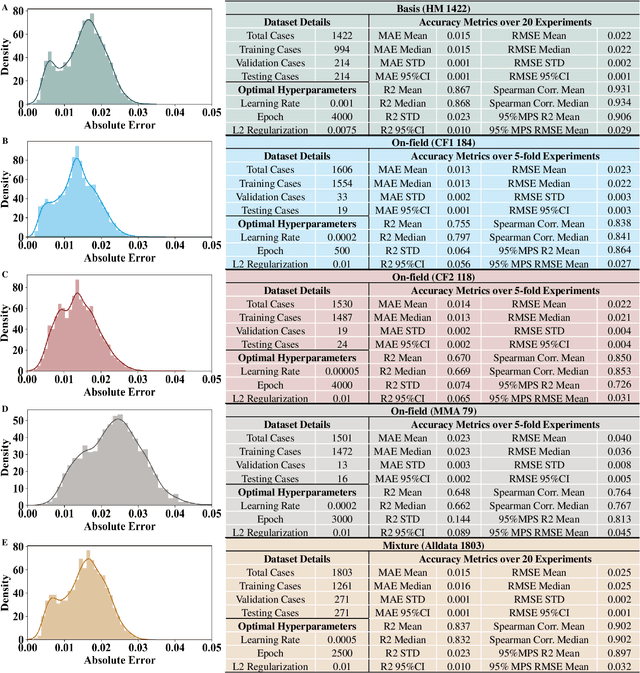
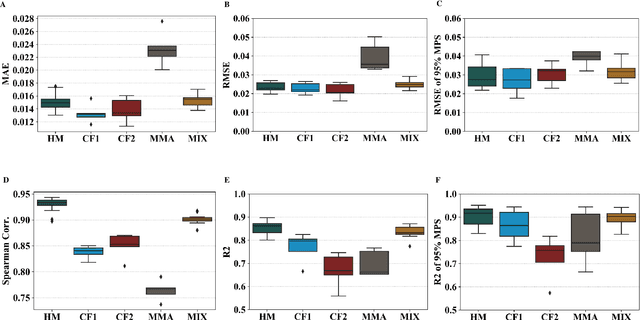
Objective: Many recent studies have suggested that brain deformation resulting from a head impact is linked to the corresponding clinical outcome, such as mild traumatic brain injury (mTBI). Even though several finite element (FE) head models have been developed and validated to calculate brain deformation based on impact kinematics, the clinical application of these FE head models is limited due to the time-consuming nature of FE simulations. This work aims to accelerate the process of brain deformation calculation and thus improve the potential for clinical applications. Methods: We propose a deep learning head model with a five-layer deep neural network and feature engineering, and trained and tested the model on 1803 total head impacts from a combination of head model simulations and on-field college football and mixed martial arts impacts. Results: The proposed deep learning head model can calculate the maximum principal strain for every element in the entire brain in less than 0.001s (with an average root mean squared error of 0.025, and with a standard deviation of 0.002 over twenty repeats with random data partition and model initialization). The contributions of various features to the predictive power of the model were investigated, and it was noted that the features based on angular acceleration were found to be more predictive than the features based on angular velocity. Conclusion: Trained using the dataset of 1803 head impacts, this model can be applied to various sports in the calculation of brain strain with accuracy, and its applicability can even further be extended by incorporating data from other types of head impacts. Significance: In addition to the potential clinical application in real-time brain deformation monitoring, this model will help researchers estimate the brain strain from a large number of head impacts more efficiently than using FE models.
Continual Learning In Environments With Polynomial Mixing Times
Dec 13, 2021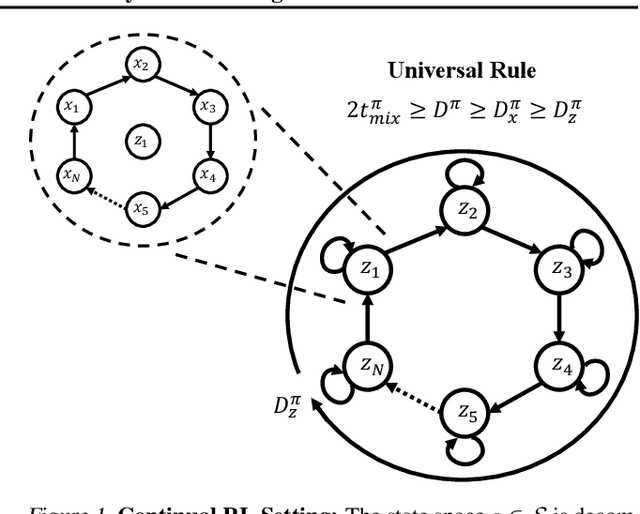

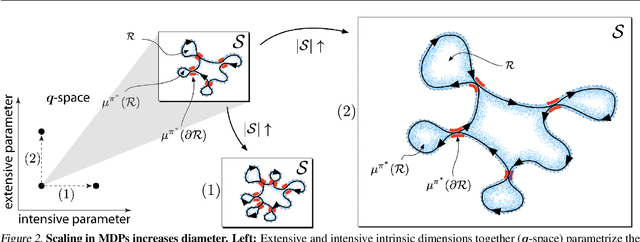
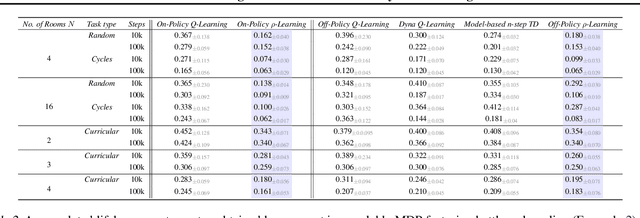
The mixing time of the Markov chain induced by a policy limits performance in real-world continual learning scenarios. Yet, the effect of mixing times on learning in continual reinforcement learning (RL) remains underexplored. In this paper, we characterize problems that are of long-term interest to the development of continual RL, which we call scalable MDPs, through the lens of mixing times. In particular, we establish that scalable MDPs have mixing times that scale polynomially with the size of the problem. We go on to demonstrate that polynomial mixing times present significant difficulties for existing approaches and propose a family of model-based algorithms that speed up learning by directly optimizing for the average reward through a novel bootstrapping procedure. Finally, we perform empirical regret analysis of our proposed approaches, demonstrating clear improvements over baselines and also how scalable MDPs can be used for analysis of RL algorithms as mixing times scale.
Online Speaker Diarization with Graph-based Label Generation
Nov 27, 2021


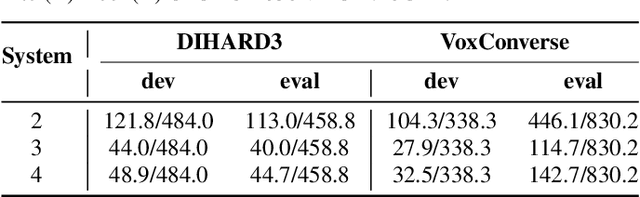
This paper introduces an online speaker diarization system that can handle long-time audio with low latency. First, a new variant of agglomerative hierarchy clustering is built to cluster the speakers in an online fashion. Then, a speaker embedding graph is proposed. We use this graph to exploit a graph-based reclustering method to further improve the performance. Finally, a label matching algorithm is introduced to generate consistent speaker labels, and we evaluate our system on both DIHARD3 and VoxConverse datasets, which contain long audios with various kinds of scenarios. The experimental results show that our online diarization system outperforms the baseline offline system and has comparable performance to our offline system.
State Selection Algorithms and Their Impact on The Performance of Stateful Network Protocol Fuzzing
Dec 24, 2021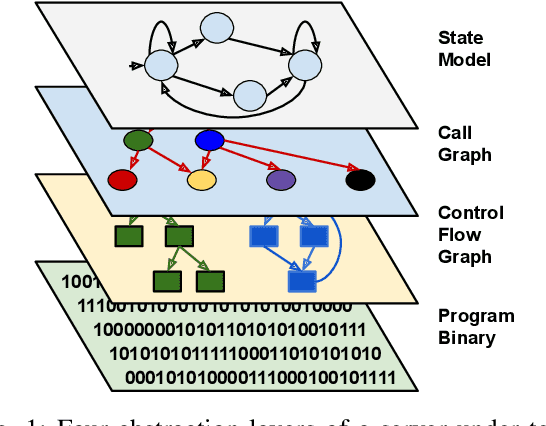
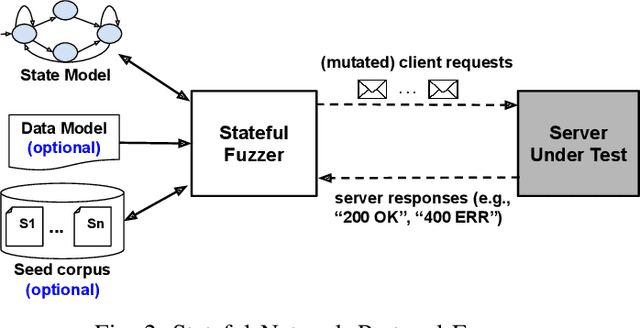
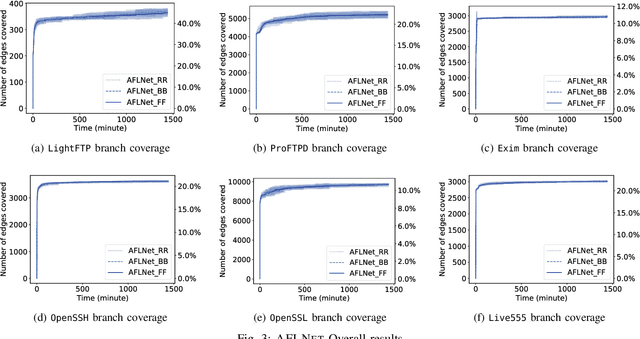

The statefulness property of network protocol implementations poses a unique challenge for testing and verification techniques, including Fuzzing. Stateful fuzzers tackle this challenge by leveraging state models to partition the state space and assist the test generation process. Since not all states are equally important and fuzzing campaigns have time limits, fuzzers need effective state selection algorithms to prioritize progressive states over others. Several state selection algorithms have been proposed but they were implemented and evaluated separately on different platforms, making it hard to achieve conclusive findings. In this work, we evaluate an extensive set of state selection algorithms on the same fuzzing platform that is AFLNet, a state-of-the-art fuzzer for network servers. The algorithm set includes existing ones supported by AFLNet and our novel and principled algorithm called AFLNetLegion. The experimental results on the ProFuzzBench benchmark show that (i) the existing state selection algorithms of AFLNet achieve very similar code coverage, (ii) AFLNetLegion clearly outperforms these algorithms in selected case studies, but (iii) the overall improvement appears insignificant. These are unexpected yet interesting findings. We identify problems and share insights that could open opportunities for future research on this topic.
On the Role of Time in Learning
Jul 14, 2019By and large the process of learning concepts that are embedded in time is regarded as quite a mature research topic. Hidden Markov models, recurrent neural networks are, amongst others, successful approaches to learning from temporal data. In this paper, we claim that the dominant approach minimizing appropriate risk functions defined over time by classic stochastic gradient might miss the deep interpretation of time given in other fields like physics. We show that a recent reformulation of learning according to the principle of Least Cognitive Action is better suited whenever time is involved in learning. The principle gives rise to a learning process that is driven by differential equations, that can somehow descrive the process within the same framework as other laws of nature.
Stochastic Saddle Point Problems with Decision-Dependent Distributions
Jan 07, 2022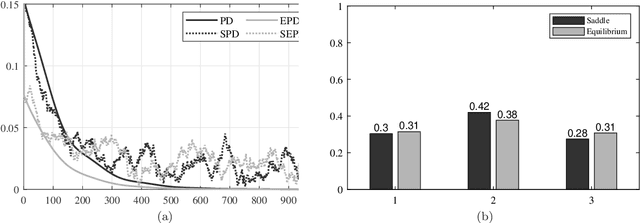
This paper focuses on stochastic saddle point problems with decision-dependent distributions in both the static and time-varying settings. These are problems whose objective is the expected value of a stochastic payoff function, where random variables are drawn from a distribution induced by a distributional map. For general distributional maps, the problem of finding saddle points is in general computationally burdensome, even if the distribution is known. To enable a tractable solution approach, we introduce the notion of equilibrium points -- which are saddle points for the stationary stochastic minimax problem that they induce -- and provide conditions for their existence and uniqueness. We demonstrate that the distance between the two classes of solutions is bounded provided that the objective has a strongly-convex-strongly-concave payoff and Lipschitz continuous distributional map. We develop deterministic and stochastic primal-dual algorithms and demonstrate their convergence to the equilibrium point. In particular, by modeling errors emerging from a stochastic gradient estimator as sub-Weibull random variables, we provide error bounds in expectation and in high probability that hold for each iteration; moreover, we show convergence to a neighborhood in expectation and almost surely. Finally, we investigate a condition on the distributional map -- which we call opposing mixture dominance -- that ensures the objective is strongly-convex-strongly-concave. Under this assumption, we show that primal-dual algorithms converge to the saddle points in a similar fashion.
Anomaly Detection in Univariate Time-series: A Survey on the State-of-the-Art
Apr 01, 2020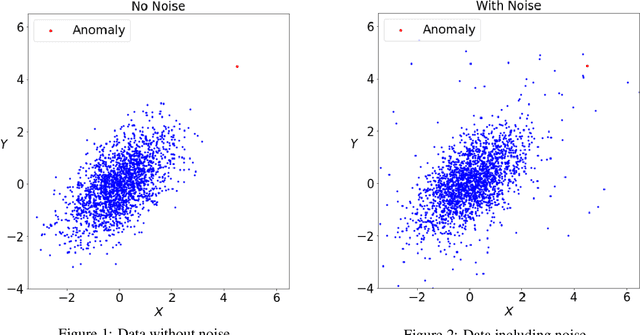


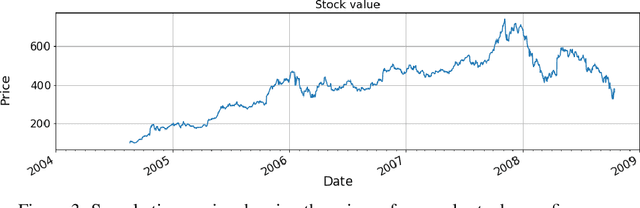
Anomaly detection for time-series data has been an important research field for a long time. Seminal work on anomaly detection methods has been focussing on statistical approaches. In recent years an increasing number of machine learning algorithms have been developed to detect anomalies on time-series. Subsequently, researchers tried to improve these techniques using (deep) neural networks. In the light of the increasing number of anomaly detection methods, the body of research lacks a broad comparative evaluation of statistical, machine learning and deep learning methods. This paper studies 20 univariate anomaly detection methods from the all three categories. The evaluation is conducted on publicly available datasets, which serve as benchmarks for time-series anomaly detection. By analyzing the accuracy of each method as well as the computation time of the algorithms, we provide a thorough insight about the performance of these anomaly detection approaches, alongside some general notion of which method is suited for a certain type of data.
Deep Snake for Real-Time Instance Segmentation
Jan 06, 2020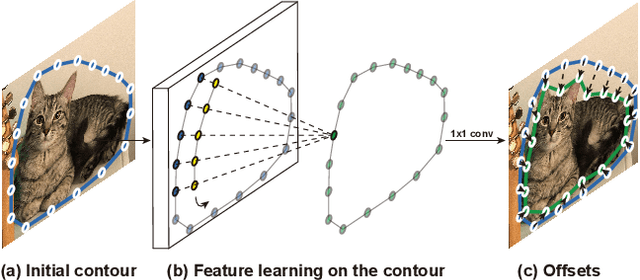

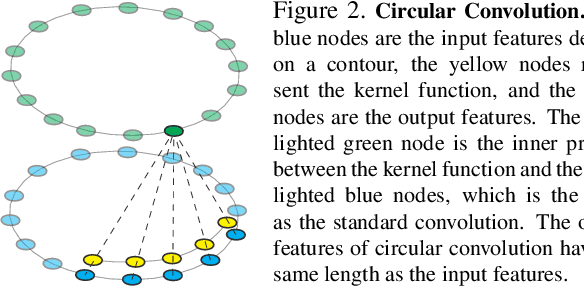

This paper introduces a novel contour-based approach named deep snake for real-time instance segmentation. Unlike some recent methods that directly regress the coordinates of the object boundary points from an image, deep snake uses a neural network to iteratively deform an initial contour to the object boundary, which implements the classic idea of snake algorithms with a learning-based approach. For structured feature learning on the contour, we propose to use circular convolution in deep snake, which better exploits the cycle-graph structure of a contour compared against generic graph convolution. Based on deep snake, we develop a two-stage pipeline for instance segmentation: initial contour proposal and contour deformation, which can handle errors in initial object localization. Experiments show that the proposed approach achieves state-of-the-art performances on the Cityscapes, Kins and Sbd datasets while being efficient for real-time instance segmentation, 32.3 fps for 512$\times$512 images on a 1080Ti GPU. The code will be available at https://github.com/zju3dv/snake/.