 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Forecasting Market Prices using DL with Data Augmentation and Meta-learning: ARIMA still wins!
Oct 19, 2021
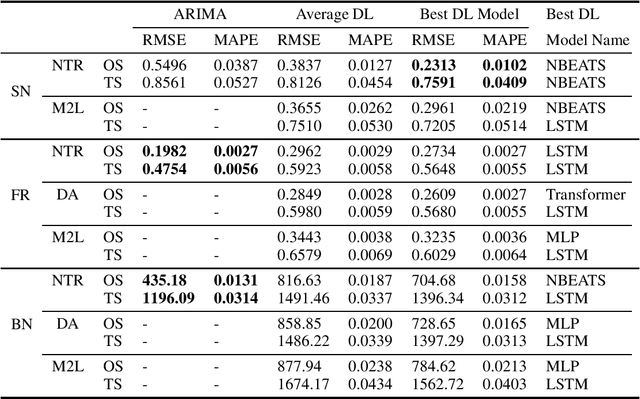
Deep-learning techniques have been successfully used for time-series forecasting and have often shown superior performance on many standard benchmark datasets as compared to traditional techniques. Here we present a comprehensive and comparative study of performance of deep-learning techniques for forecasting prices in financial markets. We benchmark state-of-the-art deep-learning baselines, such as NBeats, etc., on data from currency as well as stock markets. We also generate synthetic data using a fuzzy-logic based model of demand driven by technical rules such as moving averages, which are often used by traders. We benchmark the baseline techniques on this synthetic data as well as use it for data augmentation. We also apply gradient-based meta-learning to account for non-stationarity of financial time-series. Our extensive experiments notwithstanding, the surprising result is that the standard ARIMA models outperforms deep-learning even using data augmentation or meta-learning. We conclude by speculating as to why this might be the case.
A Mixed Integer Programming Approach to Training Dense Neural Networks
Jan 03, 2022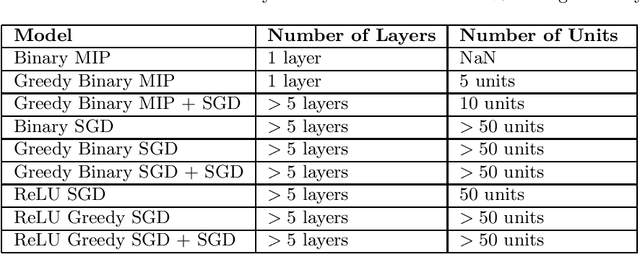



Artificial Neural Networks (ANNs) are prevalent machine learning models that have been applied across various real world classification tasks. ANNs require a large amount of data to have strong out of sample performance, and many algorithms for training ANN parameters are based on stochastic gradient descent (SGD). However, the SGD ANNs that tend to perform best on prediction tasks are trained in an end to end manner that requires a large number of model parameters and random initialization. This means training ANNs is very time consuming and the resulting models take a lot of memory to deploy. In order to train more parsimonious ANN models, we propose the use of alternative methods from the constrained optimization literature for ANN training and pretraining. In particular, we propose novel mixed integer programming (MIP) formulations for training fully-connected ANNs. Our formulations can account for both binary activation and rectified linear unit (ReLU) activation ANNs, and for the use of a log likelihood loss. We also develop a layer-wise greedy approach, a technique adapted for reducing the number of layers in the ANN, for model pretraining using our MIP formulations. We then present numerical experiments comparing our MIP based methods against existing SGD based approaches and show that we are able to achieve models with competitive out of sample performance that are significantly more parsimonious.
Real-World Graph Convolution Networks (RW-GCNs) for Action Recognition in Smart Video Surveillance
Jan 15, 2022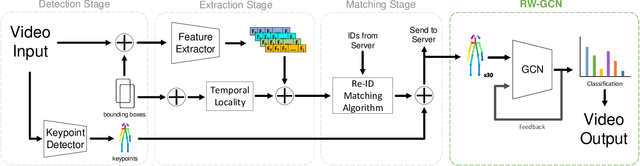
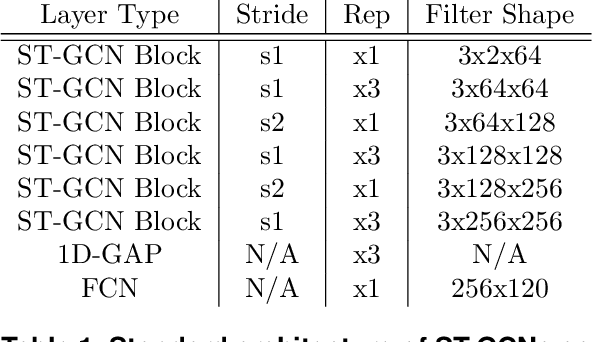

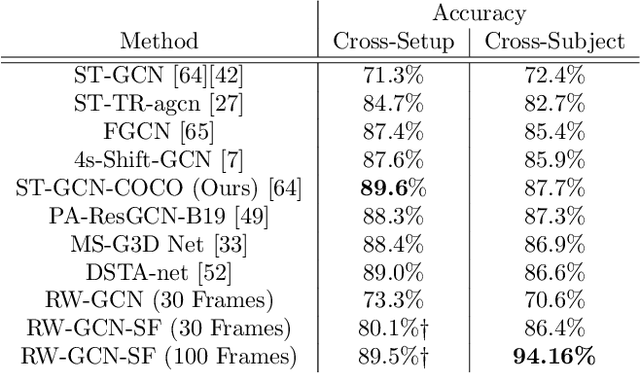
Action recognition is a key algorithmic part of emerging on-the-edge smart video surveillance and security systems. Skeleton-based action recognition is an attractive approach which, instead of using RGB pixel data, relies on human pose information to classify appropriate actions. However, existing algorithms often assume ideal conditions that are not representative of real-world limitations, such as noisy input, latency requirements, and edge resource constraints. To address the limitations of existing approaches, this paper presents Real-World Graph Convolution Networks (RW-GCNs), an architecture-level solution for meeting the domain constraints of Real World Skeleton-based Action Recognition. Inspired by the presence of feedback connections in the human visual cortex, RW-GCNs leverage attentive feedback augmentation on existing near state-of-the-art (SotA) Spatial-Temporal Graph Convolution Networks (ST-GCNs). The ST-GCNs' design choices are derived from information theory-centric principles to address both the spatial and temporal noise typically encountered in end-to-end real-time and on-the-edge smart video systems. Our results demonstrate RW-GCNs' ability to serve these applications by achieving a new SotA accuracy on the NTU-RGB-D-120 dataset at 94.1%, and achieving 32X less latency than baseline ST-GCN applications while still achieving 90.4% accuracy on the Northwestern UCLA dataset in the presence of spatial keypoint noise. RW-GCNs further show system scalability by running on the 10X cost effective NVIDIA Jetson Nano (as opposed to NVIDIA Xavier NX), while still maintaining a respectful range of throughput (15.6 to 5.5 Actions per Second) on the resource constrained device. The code is available here: https://github.com/TeCSAR-UNCC/RW-GCN.
Relevant Region Sampling Strategy with Adaptive Heuristic Estimation for Asymptotically Optimal Motion Planning
Oct 31, 2021
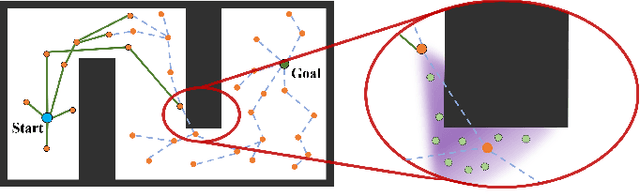
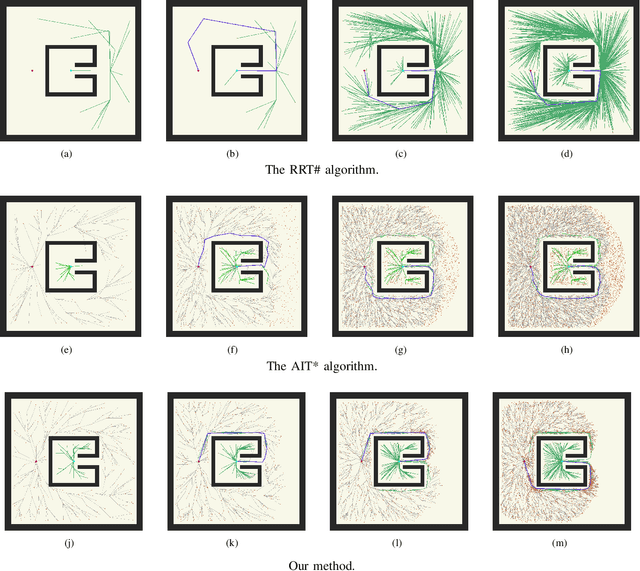
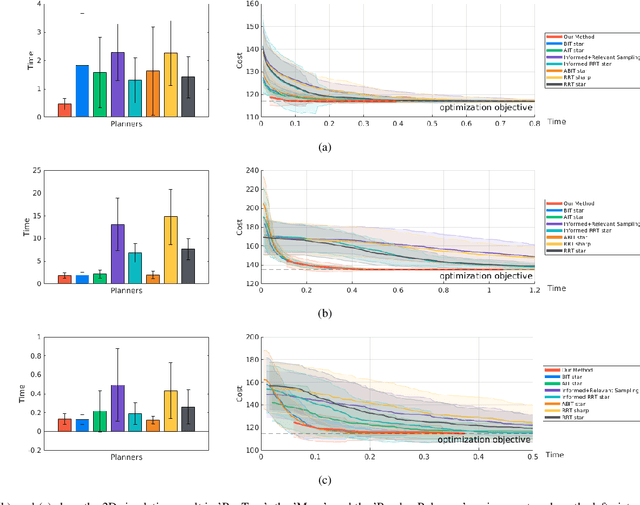
The sampling-based motion planning algorithms can solve the motion planning problem in high-dimensional state space efficiently. This article presents a novel approach to sample in the promising region and reduce planning time remarkably. The RRT# defines the Relevant Region according to the cost-to-come provided by the optimal forward-searching tree; however, it takes the cumulative cost of a direct connection between the current state and the goal state as the cost-to-go. We propose a batch sampling method that samples in the refined Relevant Region, which is defined according to the optimal cost-to-come and the adaptive cost-to-go. In our method, the cost-to-come and the cost-to-go of a specific vertex are estimated by the valid optimal forward-searching tree and the lazy reverse-searching tree, respectively. New samples are generated with a direct sampling method, which can take advantage of the heuristic estimation result. We carry on several simulations in both SE(2) and SE(3) state spaces to validate the effectiveness of our method. Simulation results demonstrate that the proposed algorithm can find a better initial solution and consumes less planning time than related work.
CoboGuider: Haptic Potential Fields for Safe Human-Robot Interaction
Oct 25, 2021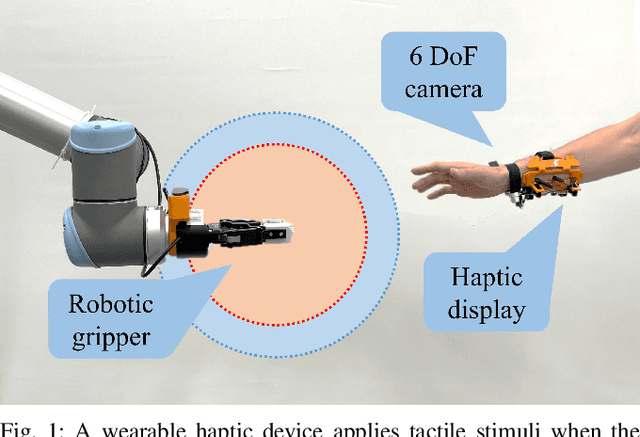
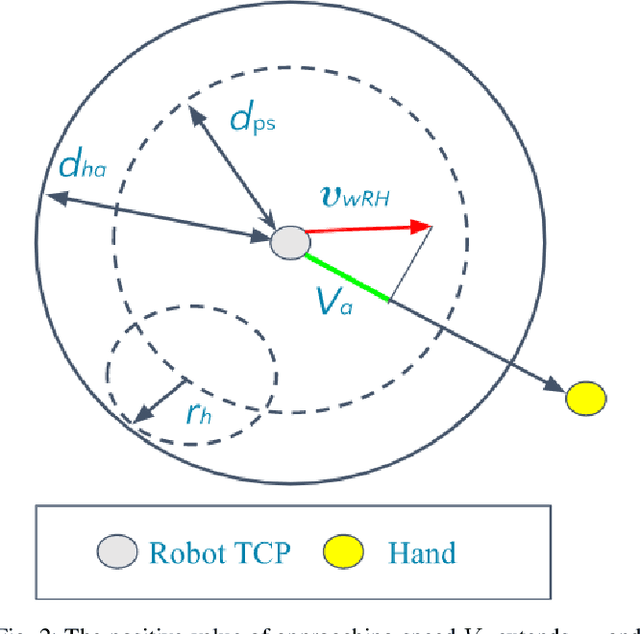

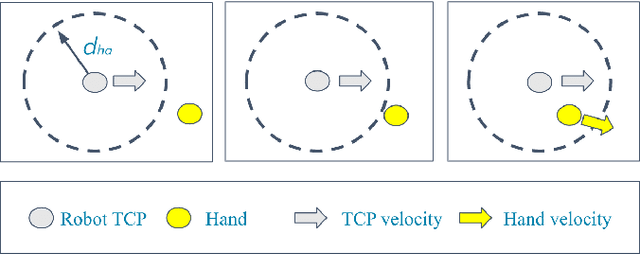
Modern industry still relies on manual manufacturing operations and safe human-robot interaction is of great interest nowadays. Speed and Separation Monitoring (SSM) allows close and efficient collaborative scenarios by maintaining a protective separation distance during robot operation. The paper focuses on a novel approach to strengthen the SSM safety requirements by introducing haptic feedback to a robotic cell worker. Tactile stimuli provide early warning of dangerous movements and proximity to the robot, based on the human reaction time and instantaneous velocities of robot and operator. A preliminary experiment was performed to identify the reaction time of participants when they are exposed to tactile stimuli in a collaborative environment with controlled conditions. In a second experiment, we evaluated our approach into a study case where human worker and cobot performed collaborative planetary gear assembly. Results show that the applied approach increased the average minimum distance between the robot's end-effector and hand by 44% compared to the operator relying only on the visual feedback. Moreover, the participants without the haptic support have failed several times to maintain the protective separation distance.
Automated Human Mind Reading Using EEG Signals for Seizure Detection
Nov 05, 2021Epilepsy is one of the most occurring neurological disease globally emerged back in 4000 BC. It is affecting around 50 million people of all ages these days. The trait of this disease is recurrent seizures. In the past few decades, the treatments available for seizure control have improved a lot with the advancements in the field of medical science and technology. Electroencephalogram (EEG) is a widely used technique for monitoring the brain activity and widely popular for seizure region detection. It is performed before surgery and also to predict seizure at the time operation which is useful in neuro stimulation device. But in most of cases visual examination is done by neurologist in order to detect and classify patterns of the disease but this requires a lot of pre-domain knowledge and experience. This all in turns put a pressure on neurosurgeons and leads to time wastage and also reduce their accuracy and efficiency. There is a need of some automated systems in arena of information technology like use of neural networks in deep learning which can assist neurologists. In the present paper, a model is proposed to give an accuracy of 98.33% which can be used for development of automated systems. The developed system will significantly help neurologists in their performance.
* 11 Pages, 12 Figures, 5 Tables
Static-Dynamic Co-Teaching for Class-Incremental 3D Object Detection
Dec 14, 2021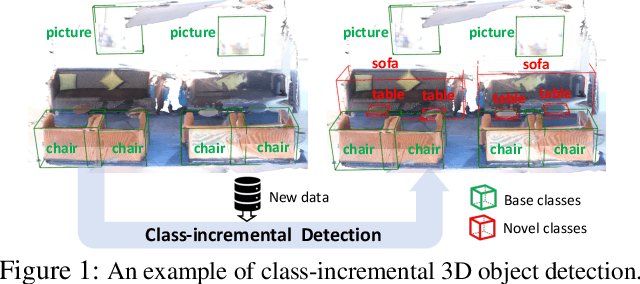
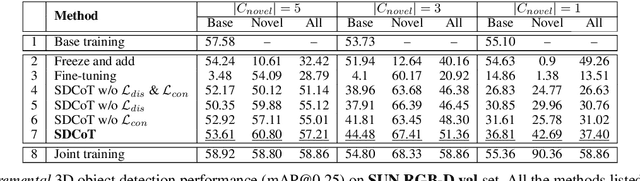
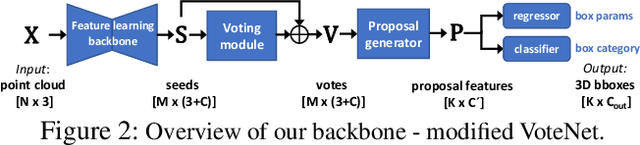
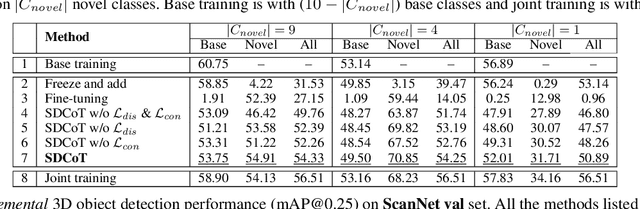
Deep learning-based approaches have shown remarkable performance in the 3D object detection task. However, they suffer from a catastrophic performance drop on the originally trained classes when incrementally learning new classes without revisiting the old data. This "catastrophic forgetting" phenomenon impedes the deployment of 3D object detection approaches in real-world scenarios, where continuous learning systems are needed. In this paper, we study the unexplored yet important class-incremental 3D object detection problem and present the first solution - SDCoT, a novel static-dynamic co-teaching method. Our SDCoT alleviates the catastrophic forgetting of old classes via a static teacher, which provides pseudo annotations for old classes in the new samples and regularizes the current model by extracting previous knowledge with a distillation loss. At the same time, SDCoT consistently learns the underlying knowledge from new data via a dynamic teacher. We conduct extensive experiments on two benchmark datasets and demonstrate the superior performance of our SDCoT over baseline approaches in several incremental learning scenarios.
Feature Generation and Hypothesis Verification for Reliable Face Anti-Spoofing
Dec 30, 2021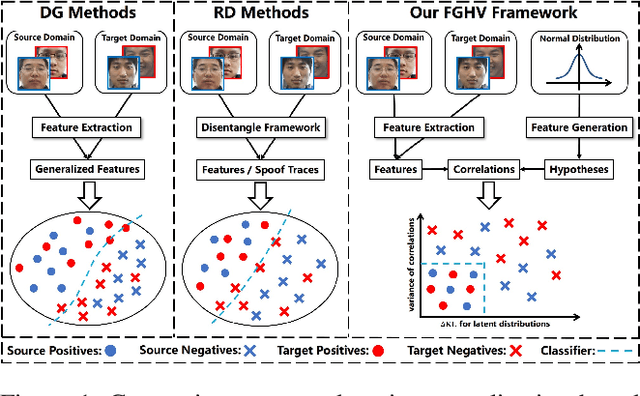
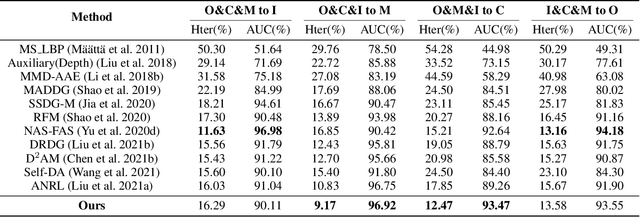
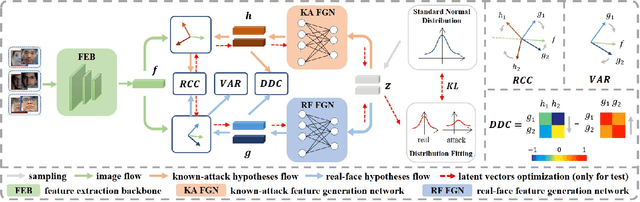
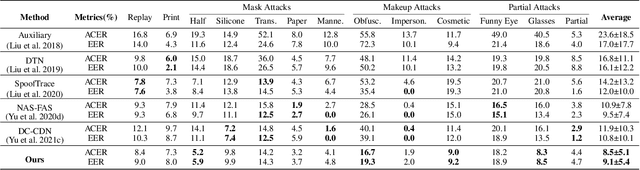
Although existing face anti-spoofing (FAS) methods achieve high accuracy in intra-domain experiments, their effects drop severely in cross-domain scenarios because of poor generalization. Recently, multifarious techniques have been explored, such as domain generalization and representation disentanglement. However, the improvement is still limited by two issues: 1) It is difficult to perfectly map all faces to a shared feature space. If faces from unknown domains are not mapped to the known region in the shared feature space, accidentally inaccurate predictions will be obtained. 2) It is hard to completely consider various spoof traces for disentanglement. In this paper, we propose a Feature Generation and Hypothesis Verification framework to alleviate the two issues. Above all, feature generation networks which generate hypotheses of real faces and known attacks are introduced for the first time in the FAS task. Subsequently, two hypothesis verification modules are applied to judge whether the input face comes from the real-face space and the real-face distribution respectively. Furthermore, some analyses of the relationship between our framework and Bayesian uncertainty estimation are given, which provides theoretical support for reliable defense in unknown domains. Experimental results show our framework achieves promising results and outperforms the state-of-the-art approaches on extensive public datasets.
Urine Microscopic Image Dataset
Nov 19, 2021Urinalysis is a standard diagnostic test to detect urinary system related problems. The automation of urinalysis will reduce the overall diagnostic time. Recent studies used urine microscopic datasets for designing deep learning based algorithms to classify and detect urine cells. But these datasets are not publicly available for further research. To alleviate the need for urine datsets, we prepare our urine sediment microscopic image (UMID) dataset comprising of around 3700 cell annotations and 3 categories of cells namely RBC, pus and epithelial cells. We discuss the several challenges involved in preparing the dataset and the annotations. We make the dataset publicly available.
Data-Driven Deep Learning Based Hybrid Beamforming for Aerial Massive MIMO-OFDM Systems with Implicit CSI
Jan 18, 2022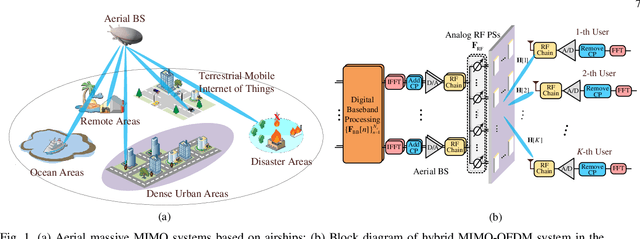
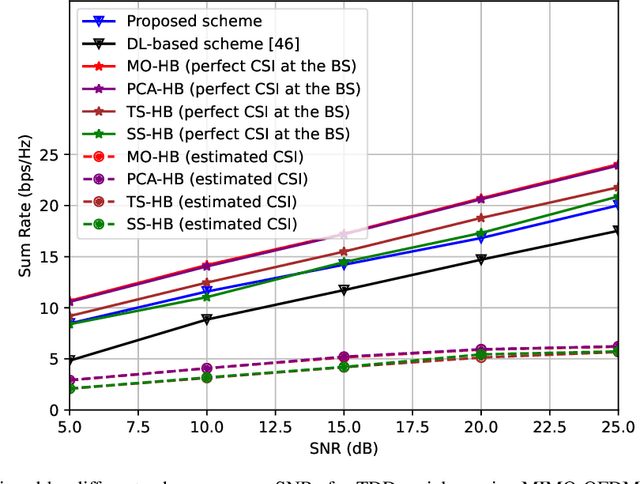
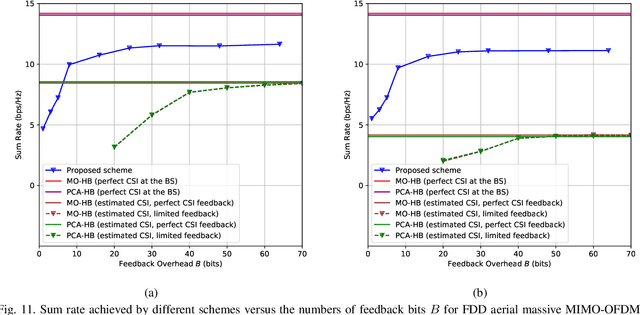
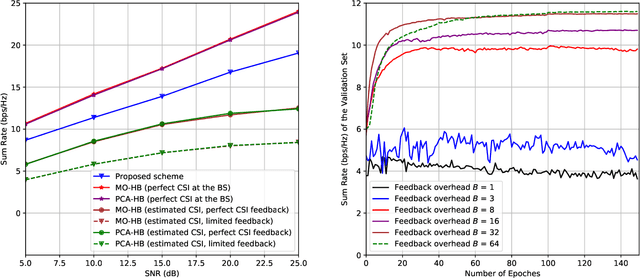
In an aerial hybrid massive multiple-input multiple-output (MIMO) and orthogonal frequency division multiplexing (OFDM) system, how to design a spectral-efficient broadband multi-user hybrid beamforming with a limited pilot and feedback overhead is challenging. To this end, by modeling the key transmission modules as an end-to-end (E2E) neural network, this paper proposes a data-driven deep learning (DL)-based unified hybrid beamforming framework for both the time division duplex (TDD) and frequency division duplex (FDD) systems with implicit channel state information (CSI). For TDD systems, the proposed DL-based approach jointly models the uplink pilot combining and downlink hybrid beamforming modules as an E2E neural network. While for FDD systems, we jointly model the downlink pilot transmission, uplink CSI feedback, and downlink hybrid beamforming modules as an E2E neural network. Different from conventional approaches separately processing different modules, the proposed solution simultaneously optimizes all modules with the sum rate as the optimization object. Therefore, by perceiving the inherent property of air-to-ground massive MIMO-OFDM channel samples, the DL-based E2E neural network can establish the mapping function from the channel to the beamformer, so that the explicit channel reconstruction can be avoided with reduced pilot and feedback overhead. Besides, practical low-resolution phase shifters (PSs) introduce the quantization constraint, leading to the intractable gradient backpropagation when training the neural network. To mitigate the performance loss caused by the phase quantization error, we adopt the transfer learning strategy to further fine-tune the E2E neural network based on a pre-trained network that assumes the ideal infinite-resolution PSs. Numerical results show that our DL-based schemes have considerable advantages over state-of-the-art schemes.