 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
FLOWER: A comprehensive dataflow compiler for high-level synthesis
Dec 14, 2021
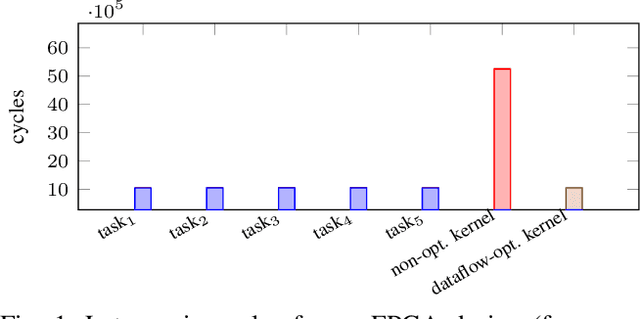
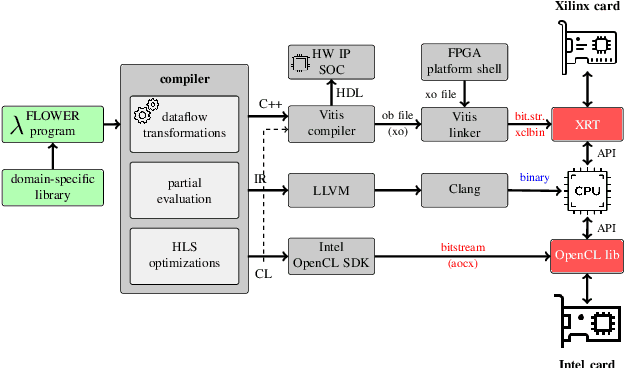
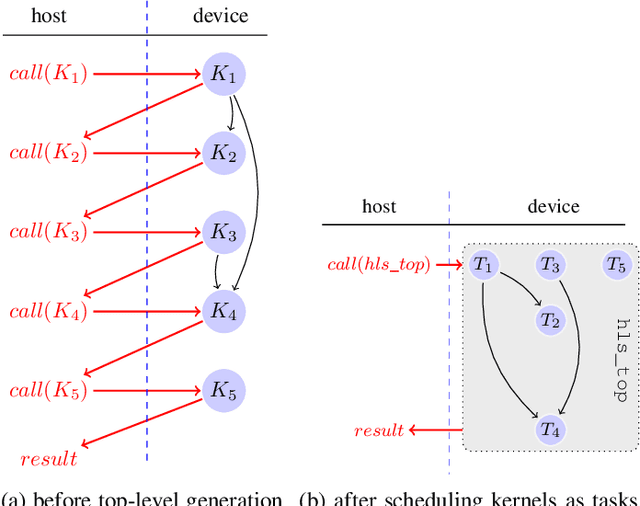
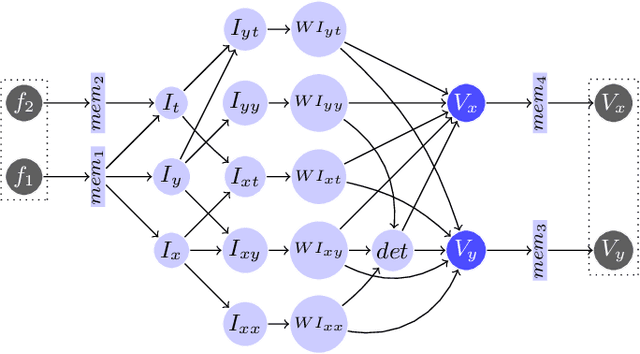
FPGAs have found their way into data centers as accelerator cards, making reconfigurable computing more accessible for high-performance applications. At the same time, new high-level synthesis compilers like Xilinx Vitis and runtime libraries such as XRT attract software programmers into the reconfigurable domain. While software programmers are familiar with task-level and data-parallel programming, FPGAs often require different types of parallelism. For example, data-driven parallelism is mandatory to obtain satisfactory hardware designs for pipelined dataflow architectures. However, software programmers are often not acquainted with dataflow architectures - resulting in poor hardware designs. In this work we present FLOWER, a comprehensive compiler infrastructure that provides automatic canonical transformations for high-level synthesis from a domain-specific library. This allows programmers to focus on algorithm implementations rather than low-level optimizations for dataflow architectures. We show that FLOWER allows to synthesize efficient implementations for high-performance streaming applications targeting System-on-Chip and FPGA accelerator cards, in the context of image processing and computer vision.
Attention-based Dual-stream Vision Transformer for Radar Gait Recognition
Nov 24, 2021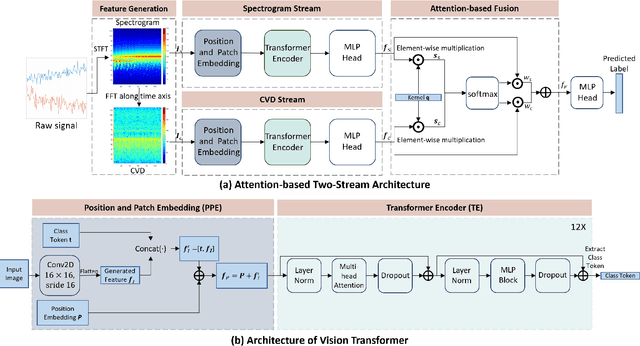

Radar gait recognition is robust to light variations and less infringement on privacy. Previous studies often utilize either spectrograms or cadence velocity diagrams. While the former shows the time-frequency patterns, the latter encodes the repetitive frequency patterns. In this work, a dual-stream neural network with attention-based fusion is proposed to fully aggregate the discriminant information from these two representations. The both streams are designed based on the Vision Transformer, which well captures the gait characteristics embedded in these representations. The proposed method is validated on a large benchmark dataset for radar gait recognition, which shows that it significantly outperforms state-of-the-art solutions.
Multiple Style-Transfer in Real-Time
Nov 18, 2019
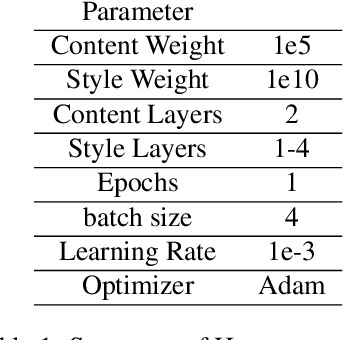

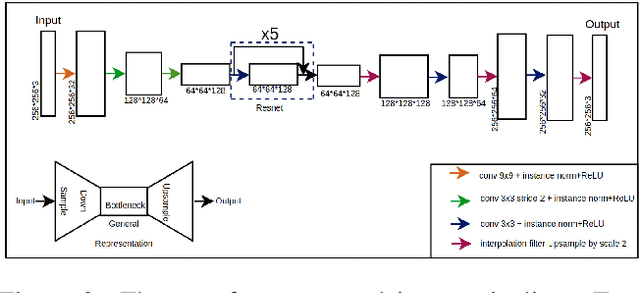
Style transfer aims to combine the content of one image with the artistic style of another. It was discovered that lower levels of convolutional networks captured style information, while higher levels captures content information. The original style transfer formulation used a weighted combination of VGG-16 layer activations to achieve this goal. Later, this was accomplished in real-time using a feed-forward network to learn the optimal combination of style and content features from the respective images. The first aim of our project was to introduce a framework for capturing the style from several images at once. We propose a method that extends the original real-time style transfer formulation by combining the features of several style images. This method successfully captures color information from the separate style images. The other aim of our project was to improve the temporal style continuity from frame to frame. Accordingly, we have experimented with the temporal stability of the output images and discussed the various available techniques that could be employed as alternatives.
Test-Time Adaptable Neural Networks for Robust Medical Image Segmentation
Apr 10, 2020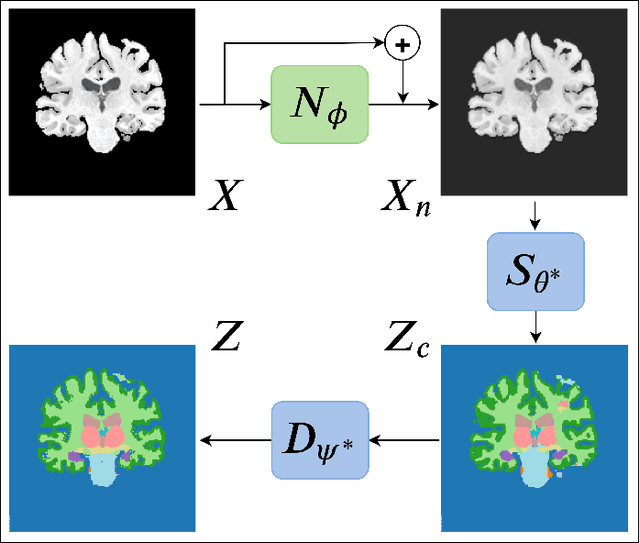
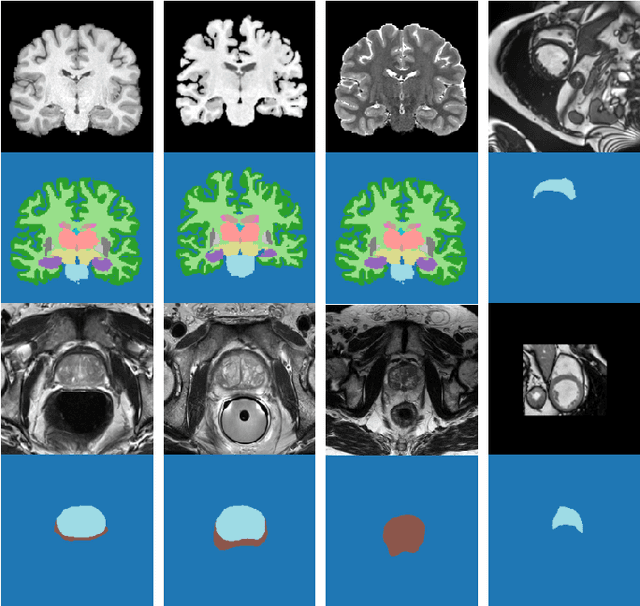
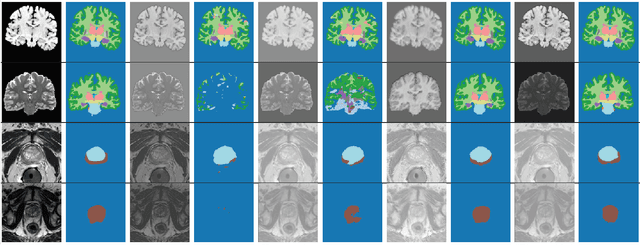
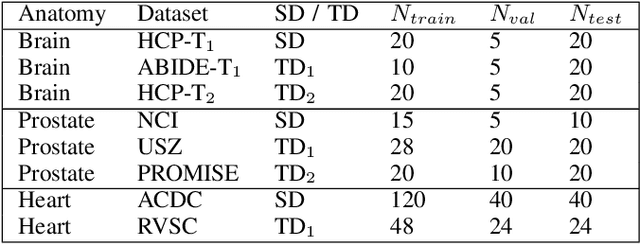
Convolutional Neural Networks (CNNs) work very well for supervised learning problems when the training dataset is representative of the variations expected to be encountered at test time. In medical image segmentation, this premise is violated when there is a mismatch between training and test images in terms of their acquisition details, such as the scanner model or the protocol. Remarkable performance degradation of CNNs in this scenario is well documented in the literature. To address this problem, we design the segmentation CNN as a concatenation of two sub-networks: a relatively shallow image normalization CNN, followed by a deep CNN that segments the normalized image. We train both these sub-networks using a training dataset, consisting of annotated images from a particular scanner and protocol setting. Now, at test time, we adapt the image normalization sub-network for each test image, guided by an implicit prior on the predicted segmentation labels. We employ an independently trained denoising autoencoder (DAE) in order to model such an implicit prior on plausible anatomical segmentation labels. We validate the proposed idea on multi-center Magnetic Resonance imaging datasets of three anatomies: brain, heart and prostate. The proposed test-time adaptation consistently provides performance improvement, demonstrating the promise and generality of the approach. Being agnostic to the architecture of the deep CNN, the second sub-network, the proposed design can be utilized with any segmentation network to increase robustness to variations in imaging scanners and protocols.
Black-Box Testing of Deep Neural Networks through Test Case Diversity
Jan 18, 2022

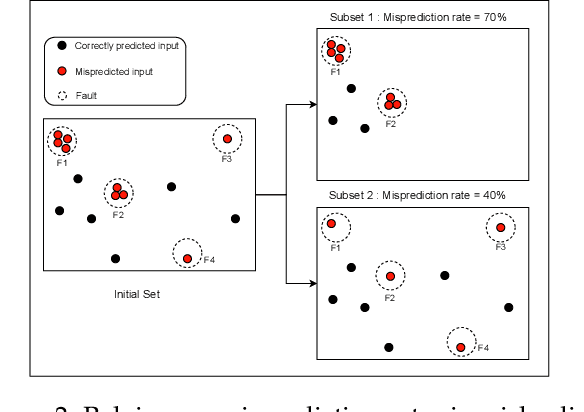

Deep Neural Networks (DNNs) have been extensively used in many areas including image processing, medical diagnostics, and autonomous driving. However, DNNs can exhibit erroneous behaviours that may lead to critical errors, especially when used in safety-critical systems. Inspired by testing techniques for traditional software systems, researchers have proposed neuron coverage criteria, as an analogy to source code coverage, to guide the testing of DNN models. Despite very active research on DNN coverage, several recent studies have questioned the usefulness of such criteria in guiding DNN testing. Further, from a practical standpoint, these criteria are white-box as they require access to the internals or training data of DNN models, which is in many contexts not feasible or convenient. In this paper, we investigate black-box input diversity metrics as an alternative to white-box coverage criteria. To this end, we first select and adapt three diversity metrics and study, in a controlled manner, their capacity to measure actual diversity in input sets. We then analyse their statistical association with fault detection using two datasets and three DNN models. We further compare diversity with state-of-the-art white-box coverage criteria. Our experiments show that relying on the diversity of image features embedded in test input sets is a more reliable indicator than coverage criteria to effectively guide the testing of DNNs. Indeed, we found that one of our selected black-box diversity metrics far outperforms existing coverage criteria in terms of fault-revealing capability and computational time. Results also confirm the suspicions that state-of-the-art coverage metrics are not adequate to guide the construction of test input sets to detect as many faults as possible with natural inputs.
A Divide-and-Merge Point Cloud Clustering Algorithm for LiDAR Panoptic Segmentation
Sep 16, 2021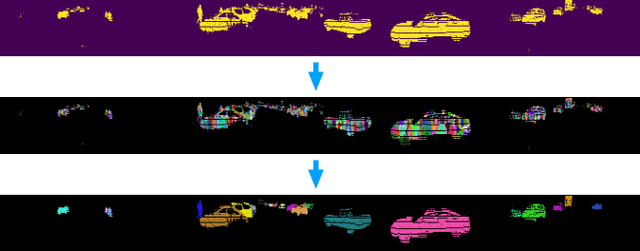
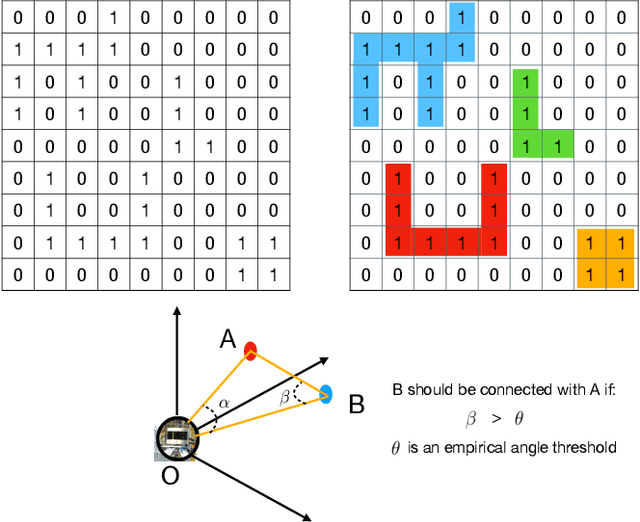
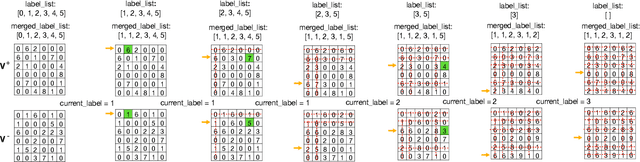

Clustering objects from the LiDAR point cloud is an important research problem with many applications such as autonomous driving. To meet the real-time requirement, existing research proposed to apply the connected-component-labeling (CCL) technique on LiDAR spherical range image with a heuristic condition to check if two neighbor points are connected. However, LiDAR range image is different from a binary image which has a deterministic condition to tell if two pixels belong to the same component. The heuristic condition used on the LiDAR range image only works empirically, which suggests the LiDAR clustering algorithm should be robust to potential failures of the empirical heuristic condition. To overcome this challenge, this paper proposes a divide-and-merge LiDAR clustering algorithm. This algorithm firstly conducts clustering in each evenly divided local region, then merges the local clustered small components by voting on edge point pairs. Assuming there are $N$ LiDAR points of objects in total with $m$ divided local regions, the time complexity of the proposed algorithm is $O(N)+O(m^2)$. A smaller $m$ means the voting will involve more neighbor points, but the time complexity will become larger. So the $m$ controls the trade-off between the time complexity and the clustering accuracy. A proper $m$ helps the proposed algorithm work in real-time as well as maintain good performance. We evaluate the divide-and-merge clustering algorithm on the SemanticKITTI panoptic segmentation benchmark by cascading it with a state-of-the-art semantic segmentation model. The final performance evaluated through the leaderboard achieves the best among all published methods. The proposed algorithm is implemented with C++ and wrapped as a python function. It can be easily used with the modern deep learning framework in python.
Safe Online Bid Optimization with Return-On-Investment and Budget Constraints subject to Uncertainty
Jan 18, 2022In online marketing, the advertisers' goal is usually a tradeoff between achieving high volumes and high profitability. The companies' business units customarily address this tradeoff by maximizing the volumes while guaranteeing a lower bound to the Return On Investment (ROI). This paper investigates combinatorial bandit algorithms for the bid optimization of advertising campaigns subject to uncertain budget and ROI constraints. We study the nature of both the optimization and learning problems. In particular, when focusing on the optimization problem without uncertainty, we show that it is inapproximable within any factor unless P=NP, and we provide a pseudo-polynomial-time algorithm that achieves an optimal solution. When considering uncertainty, we prove that no online learning algorithm can violate the (ROI or budget) constraints during the learning process a sublinear number of times while guaranteeing a sublinear pseudo-regret. Thus, we provide an algorithm, namely GCB, guaranteeing sublinear regret at the cost of a potentially linear number of constraints violations. We also design its safe version, namely GCB_{safe}, guaranteeing w.h.p. a constant upper bound on the number of constraints violations at the cost of a linear pseudo-regret. More interestingly, we provide an algorithm, namely GCB_{safe}(\psi,\phi), guaranteeing both sublinear pseudo-regret and safety w.h.p. at the cost of accepting tolerances \psi and \phi in the satisfaction of the ROI and budget constraints, respectively. This algorithm actually mitigates the risks due to the constraints violations without precluding the convergence to the optimal solution. Finally, we experimentally compare our algorithms in terms of pseudo-regret/constraint-violation tradeoff in settings generated from real-world data, showing the importance of adopting safety constraints in practice and the effectiveness of our algorithms.
CARPe Posterum: A Convolutional Approach for Real-time Pedestrian Path Prediction
May 26, 2020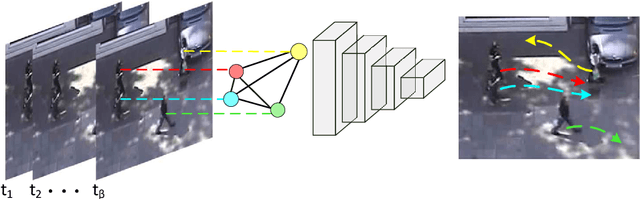
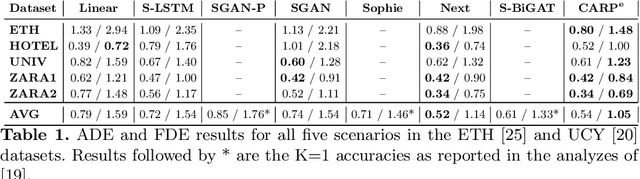
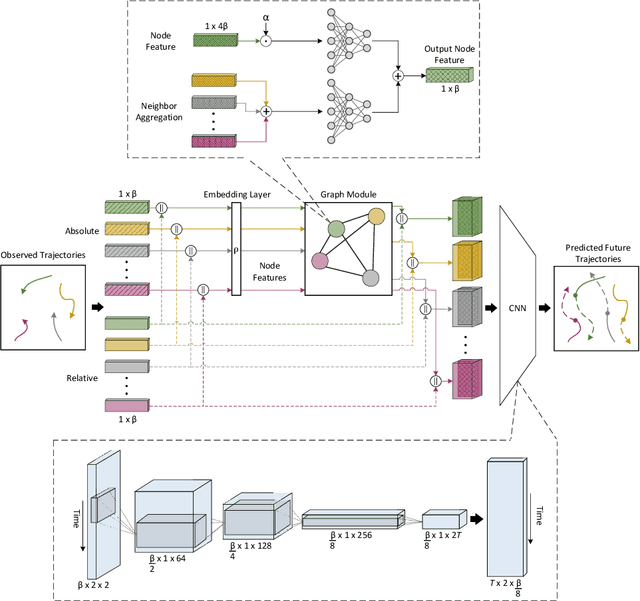

Pedestrian path prediction is an essential topic in computer vision and video understanding. Having insight into the movement of pedestrians is crucial for ensuring safe operation in a variety of applications including autonomous vehicles, social robots, and environmental monitoring. Current works in this area utilize complex generative or recurrent methods to capture many possible futures. However, despite the inherent real-time nature of predicting future paths, little work has been done to explore accurate and computationally efficient approaches for this task. To this end, we propose a convolutional approach for real-time pedestrian path prediction, CARPe. It utilizes a variation of Graph Isomorphism Networks in combination with an agile convolutional neural network design to form a fast and accurate path prediction approach. Notable results in both inference speed and prediction accuracy are achieved, improving FPS by at least 8x in comparison to current state-of-the-art methods while delivering competitive accuracy on well-known path prediction datasets.
Transformer Networks for Data Augmentation of Human Physical Activity Recognition
Sep 04, 2021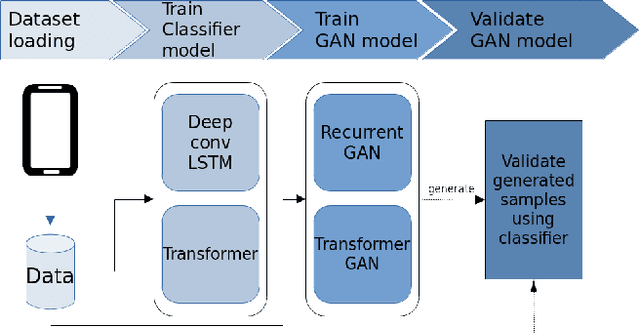
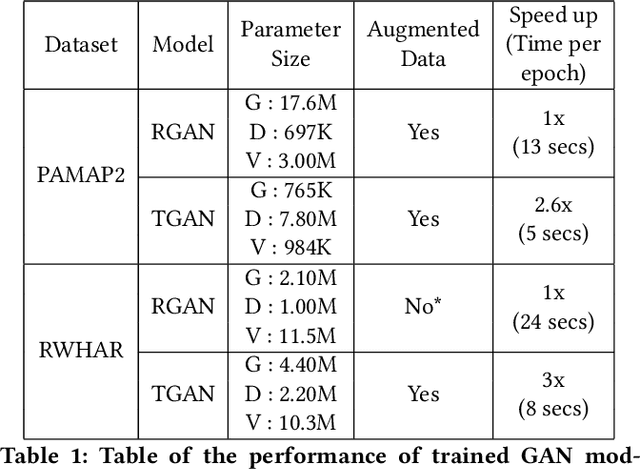
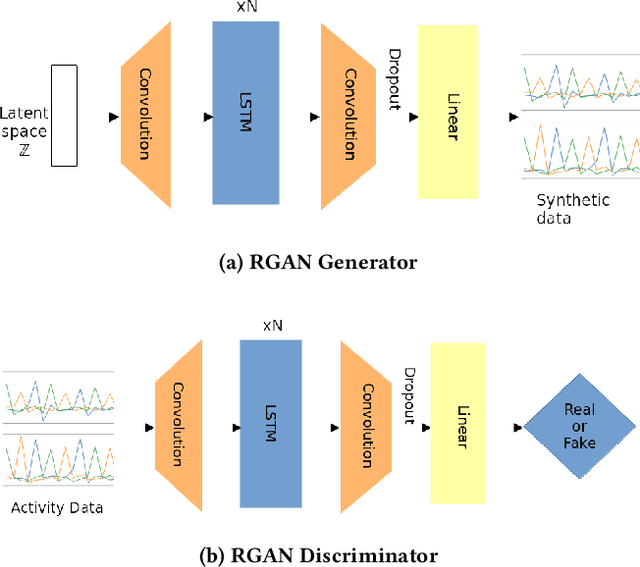
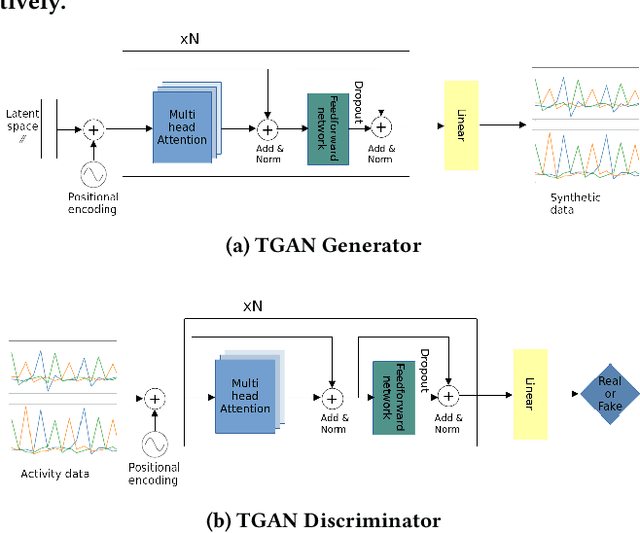
Data augmentation is a widely used technique in classification to increase data used in training. It improves generalization and reduces amount of annotated human activity data needed for training which reduces labour and time needed with the dataset. Sensor time-series data, unlike images, cannot be augmented by computationally simple transformation algorithms. State of the art models like Recurrent Generative Adversarial Networks (RGAN) are used to generate realistic synthetic data. In this paper, transformer based generative adversarial networks which have global attention on data, are compared on PAMAP2 and Real World Human Activity Recognition data sets with RGAN. The newer approach provides improvements in time and savings in computational resources needed for data augmentation than previous approach.
SGTR: End-to-end Scene Graph Generation with Transformer
Dec 30, 2021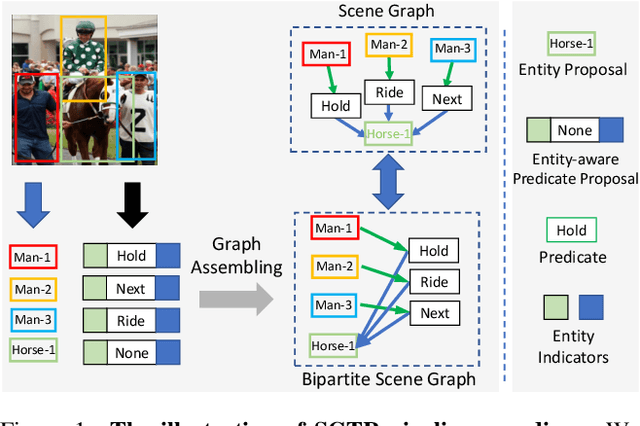

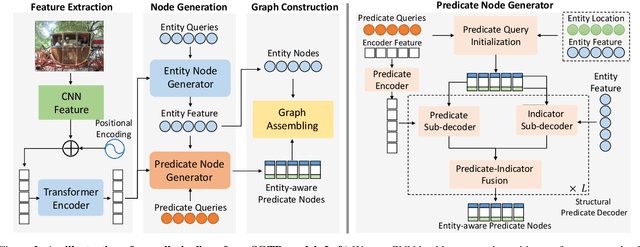

Scene Graph Generation (SGG) remains a challenging visual understanding task due to its complex compositional property. Most previous works adopt a bottom-up two-stage or a point-based one-stage approach, which often suffers from overhead time complexity or sub-optimal design assumption. In this work, we propose a novel SGG method to address the aforementioned issues, which formulates the task as a bipartite graph construction problem. To solve the problem, we develop a transformer-based end-to-end framework that first generates the entity and predicate proposal set, followed by inferring directed edges to form the relation triplets. In particular, we develop a new entity-aware predicate representation based on a structural predicate generator to leverage the compositional property of relationships. Moreover, we design a graph assembling module to infer the connectivity of the bipartite scene graph based on our entity-aware structure, enabling us to generate the scene graph in an end-to-end manner. Extensive experimental results show that our design is able to achieve the state-of-the-art or comparable performance on two challenging benchmarks, surpassing most of the existing approaches and enjoying higher efficiency in inference. We hope our model can serve as a strong baseline for the Transformer-based scene graph generation.