 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Geometry-aware 3D Generative Adversarial Networks
Dec 15, 2021

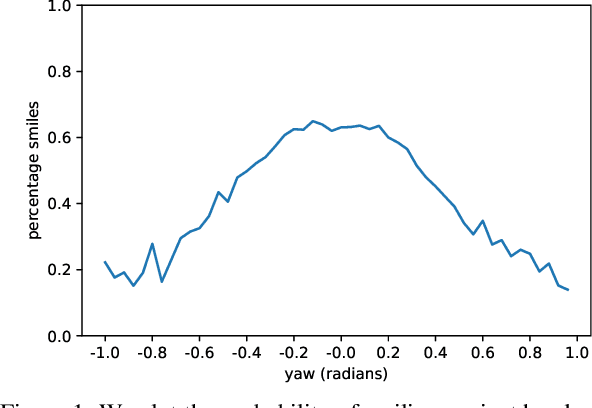
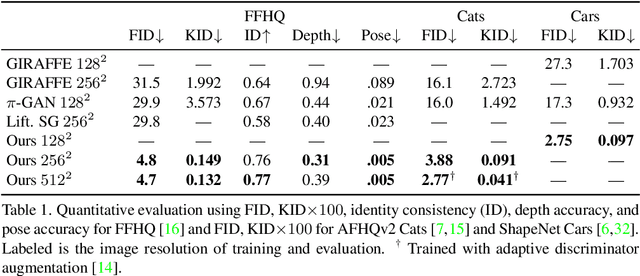
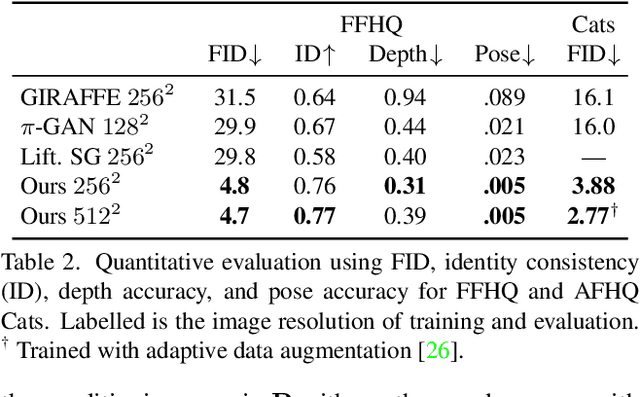
Unsupervised generation of high-quality multi-view-consistent images and 3D shapes using only collections of single-view 2D photographs has been a long-standing challenge. Existing 3D GANs are either compute-intensive or make approximations that are not 3D-consistent; the former limits quality and resolution of the generated images and the latter adversely affects multi-view consistency and shape quality. In this work, we improve the computational efficiency and image quality of 3D GANs without overly relying on these approximations. For this purpose, we introduce an expressive hybrid explicit-implicit network architecture that, together with other design choices, synthesizes not only high-resolution multi-view-consistent images in real time but also produces high-quality 3D geometry. By decoupling feature generation and neural rendering, our framework is able to leverage state-of-the-art 2D CNN generators, such as StyleGAN2, and inherit their efficiency and expressiveness. We demonstrate state-of-the-art 3D-aware synthesis with FFHQ and AFHQ Cats, among other experiments.
Real-time Surface Deformation Recovery from Stereo Videos
Jul 16, 2020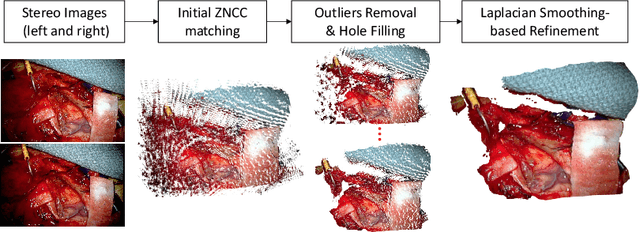

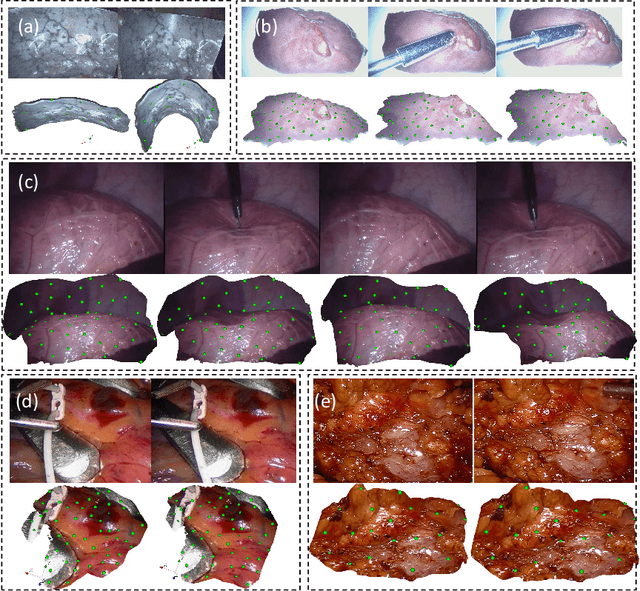
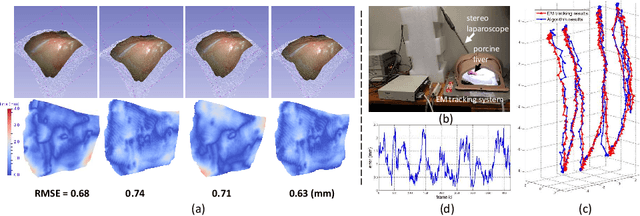
Tissue deformation during the surgery may significantly decrease the accuracy of surgical navigation systems. In this paper, we propose an approach to estimate the deformation of tissue surface from stereo videos in real-time, which is capable of handling occlusion, smooth surface and fast deformation. We first use a stereo matching method to extract depth information from stereo video frames and generate the tissue template, and then estimate the deformation of the obtained template by minimizing ICP, ORB feature matching and as-rigid-as-possible (ARAP) costs. The main novelties are twofold: (1) Due to non-rigid deformation, feature matching outliers are difficult to be removed by traditional RANSAC methods; therefore we propose a novel 1-point RANSAC and reweighting method to preselect matching inliers, which handles smooth surfaces and fast deformations. (2) We propose a novel ARAP cost function based on dense connections between the control points to achieve better smoothing performance with limited number of iterations. Algorithms are designed and implemented for GPU parallel computing. Experiments on ex- and in vivo data showed that this approach works at an update rate of 15Hz with an accuracy of less than 2.5 mm on a NVIDIA Titan X GPU.
Multi-scale Interaction for Real-time LiDAR Data Segmentation on an Embedded Platform
Aug 20, 2020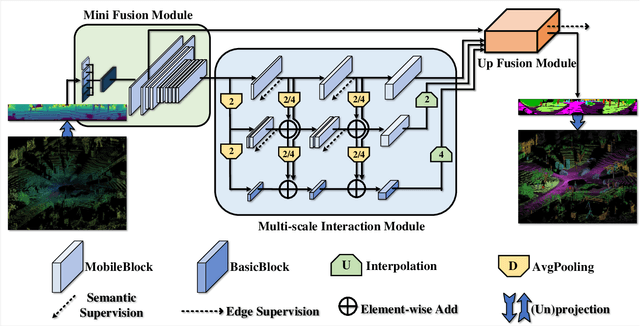
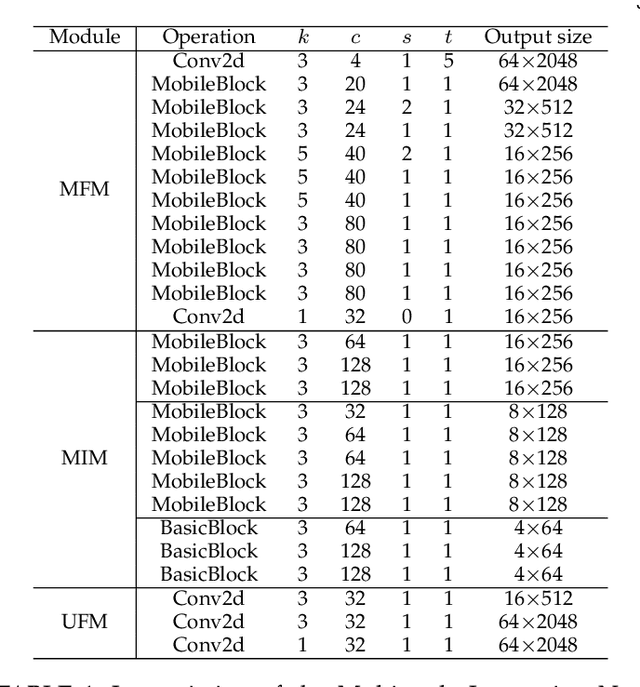
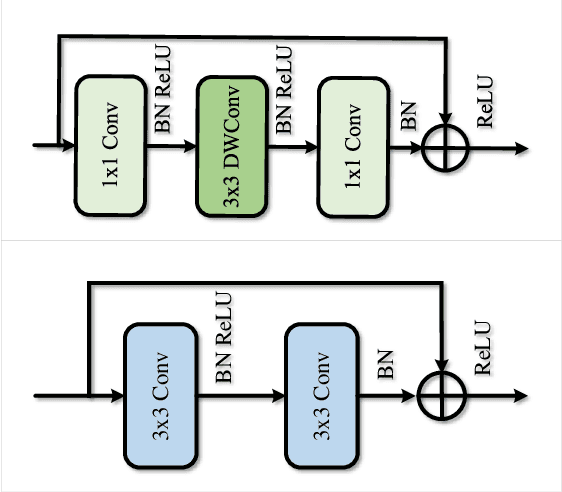

Real-time semantic segmentation of LiDAR data is crucial for autonomously driving vehicles, which are usually equipped with an embedded platform and have limited computational resources. Approaches that operate directly on the point cloud use complex spatial aggregation operations, which are very expensive and difficult to optimize for embedded platforms. They are therefore not suitable for real-time applications with embedded systems. As an alternative, projection-based methods are more efficient and can run on embedded platforms. However, the current state-of-the-art projection-based methods do not achieve the same accuracy as point-based methods and use millions of parameters. In this paper, we therefore propose a projection-based method, called Multi-scale Interaction Network (MINet), which is very efficient and accurate. The network uses multiple paths with different scales and balances the computational resources between the scales. Additional dense interactions between the scales avoid redundant computations and make the network highly efficient. The proposed network outperforms point-based, image-based, and projection-based methods in terms of accuracy, number of parameters, and runtime. Moreover, the network processes more than 24 scans per second on an embedded platform, which is higher than the framerates of LiDAR sensors. The network is therefore suitable for autonomous vehicles.
Cross-Domain Generalization and Knowledge Transfer in Transformers Trained on Legal Data
Dec 15, 2021

We analyze the ability of pre-trained language models to transfer knowledge among datasets annotated with different type systems and to generalize beyond the domain and dataset they were trained on. We create a meta task, over multiple datasets focused on the prediction of rhetorical roles. Prediction of the rhetorical role a sentence plays in a case decision is an important and often studied task in AI & Law. Typically, it requires the annotation of a large number of sentences to train a model, which can be time-consuming and expensive. Further, the application of the models is restrained to the same dataset it was trained on. We fine-tune language models and evaluate their performance across datasets, to investigate the models' ability to generalize across domains. Our results suggest that the approach could be helpful in overcoming the cold-start problem in active or interactvie learning, and shows the ability of the models to generalize across datasets and domains.
Unsupervised Shot Boundary Detection for Temporal Segmentation of Long Capsule Endoscopy Videos
Oct 18, 2021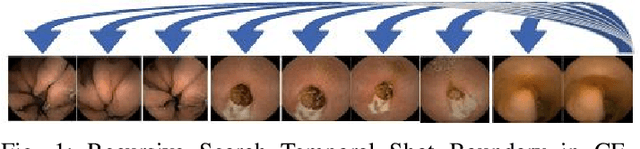
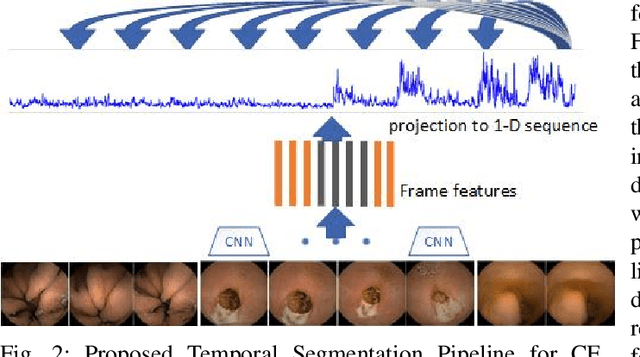
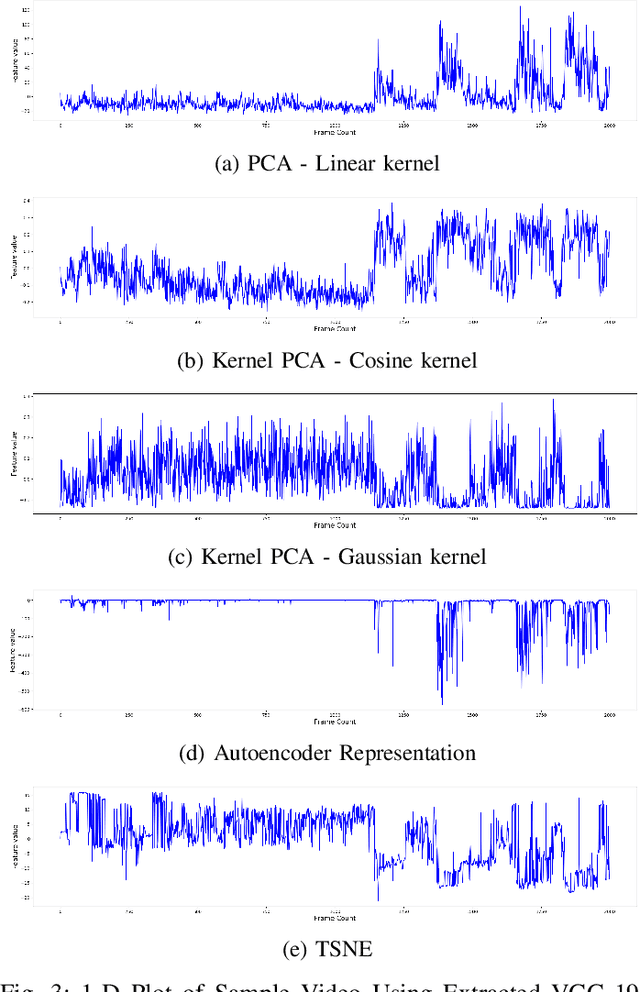
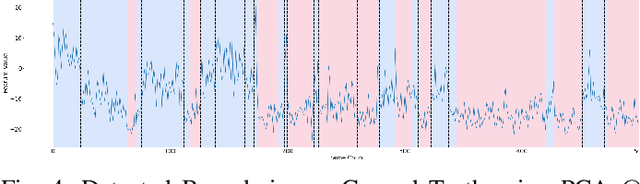
Physicians use Capsule Endoscopy (CE) as a non-invasive and non-surgical procedure to examine the entire gastrointestinal (GI) tract for diseases and abnormalities. A single CE examination could last between 8 to 11 hours generating up to 80,000 frames which is compiled as a video. Physicians have to review and analyze the entire video to identify abnormalities or diseases before making diagnosis. This review task can be very tedious, time consuming and prone to error. While only as little as a single frame may capture useful content that is relevant to the physicians' final diagnosis, frames covering the small bowel region alone could be as much as 50,000. To minimize physicians' review time and effort, this paper proposes a novel unsupervised and computationally efficient temporal segmentation method to automatically partition long CE videos into a homogeneous and identifiable video segments. However, the search for temporal boundaries in a long video using high dimensional frame-feature matrix is computationally prohibitive and impracticable for real clinical application. Therefore, leveraging both spatial and temporal information in the video, we first extracted high level frame features using a pretrained CNN model and then projected the high-dimensional frame-feature matrix to lower 1-dimensional embedding. Using this 1-dimensional sequence embedding, we applied the Pruned Exact Linear Time (PELT) algorithm to searched for temporal boundaries that indicates the transition points from normal to abnormal frames and vice-versa. We experimented with multiple real patients' CE videos and our model achieved an AUC of 66\% on multiple test videos against expert provided labels.
Automated Urban Planning for Reimagining City Configuration via Adversarial Learning: Quantification, Generation, and Evaluation
Dec 26, 2021
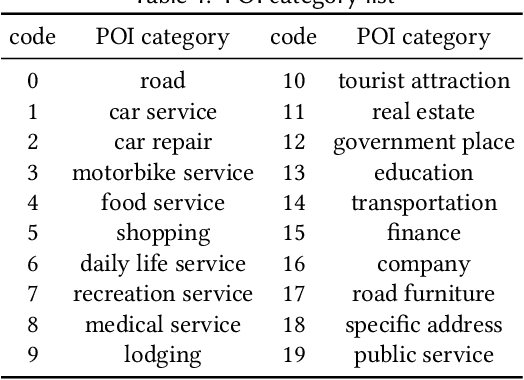
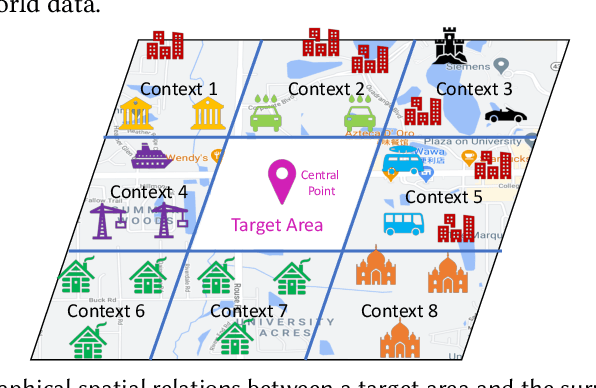
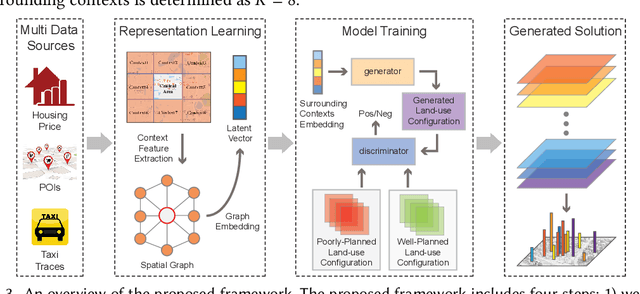
Urban planning refers to the efforts of designing land-use configurations given a region. However, to obtain effective urban plans, urban experts have to spend much time and effort analyzing sophisticated planning constraints based on domain knowledge and personal experiences. To alleviate the heavy burden of them and produce consistent urban plans, we want to ask that can AI accelerate the urban planning process, so that human planners only adjust generated configurations for specific needs? The recent advance of deep generative models provides a possible answer, which inspires us to automate urban planning from an adversarial learning perspective. However, three major challenges arise: 1) how to define a quantitative land-use configuration? 2) how to automate configuration planning? 3) how to evaluate the quality of a generated configuration? In this paper, we systematically address the three challenges. Specifically, 1) We define a land-use configuration as a longitude-latitude-channel tensor. 2) We formulate the automated urban planning problem into a task of deep generative learning. The objective is to generate a configuration tensor given the surrounding contexts of a target region. 3) We provide quantitative evaluation metrics and conduct extensive experiments to demonstrate the effectiveness of our framework.
FakeTransformer: Exposing Face Forgery From Spatial-Temporal Representation Modeled By Facial Pixel Variations
Nov 15, 2021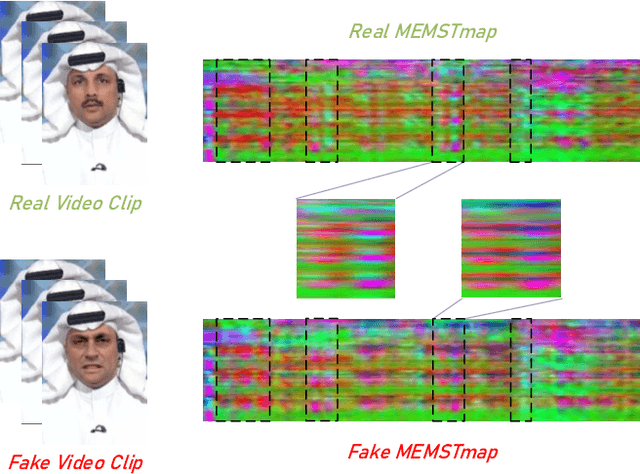
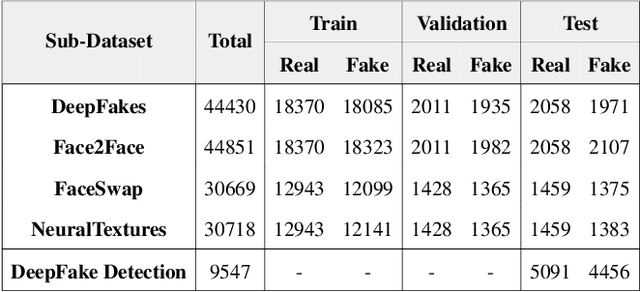
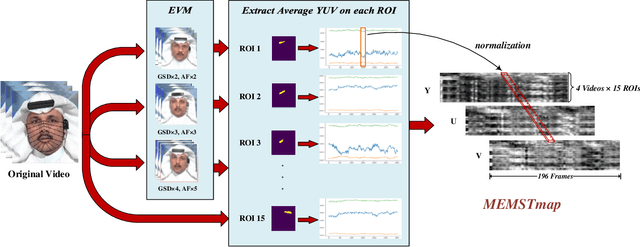
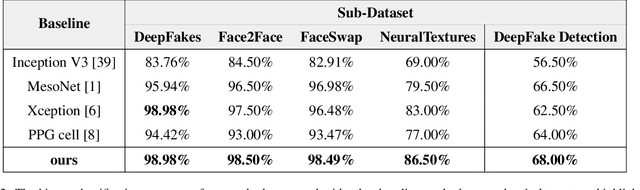
With the rapid development of generation model, AI-based face manipulation technology, which called DeepFakes, has become more and more realistic. This means of face forgery can attack any target, which poses a new threat to personal privacy and property security. Moreover, the misuse of synthetic video shows potential dangers in many areas, such as identity harassment, pornography and news rumors. Inspired by the fact that the spatial coherence and temporal consistency of physiological signal are destroyed in the generated content, we attempt to find inconsistent patterns that can distinguish between real videos and synthetic videos from the variations of facial pixels, which are highly related to physiological information. Our approach first applies Eulerian Video Magnification (EVM) at multiple Gaussian scales to the original video to enlarge the physiological variations caused by the change of facial blood volume, and then transform the original video and magnified videos into a Multi-Scale Eulerian Magnified Spatial-Temporal map (MEMSTmap), which can represent time-varying physiological enhancement sequences on different octaves. Then, these maps are reshaped into frame patches in column units and sent to the vision Transformer to learn the spatio-time descriptors of frame levels. Finally, we sort out the feature embedding and output the probability of judging whether the video is real or fake. We validate our method on the FaceForensics++ and DeepFake Detection datasets. The results show that our model achieves excellent performance in forgery detection, and also show outstanding generalization capability in cross-data domain.
Lightweight Speech Enhancement in Unseen Noisy and Reverberant Conditions using KISS-GEV Beamforming
Oct 10, 2021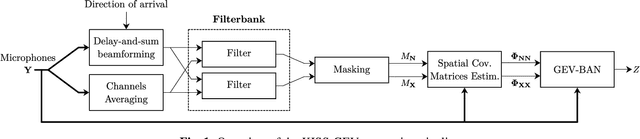
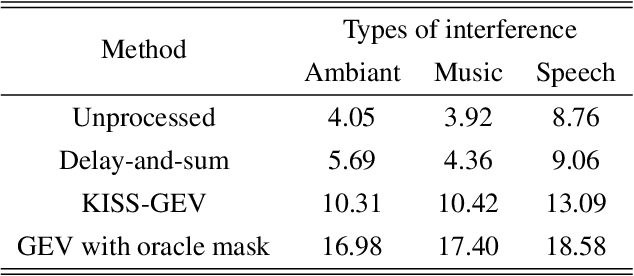
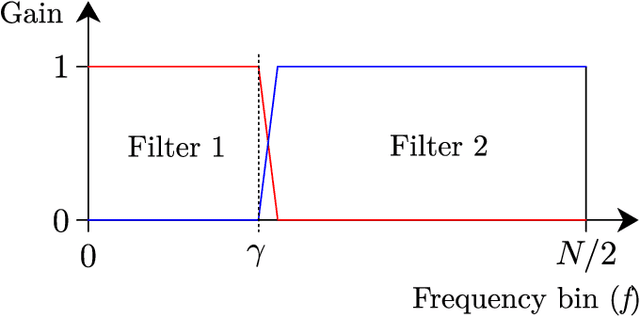
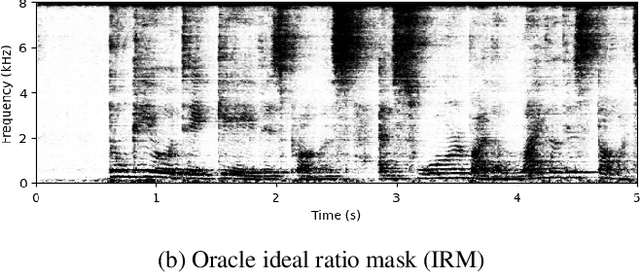
This paper introduces a new method referred to as KISS-GEV (for Keep It Super Simple Generalized eigenvalue) beamforming. While GEV beamforming usually relies on deep neural network for estimating target and noise time-frequency masks, this method uses a signal processing approach based on the direction of arrival (DoA) of the target. This considerably reduces the amount of computations involved at test time, and works for speech enhancement in unseen conditions as there is no need to train a neural network with noisy speech. The proposed method can also be used to separate speech from a mixture, provided the speech sources come from different directions. Results also show that the proposed method uses the same minimal DoA assumption as Delay-and-Sum beamforming, yet outperforms this traditional approach.
Maximum Bayes Smatch Ensemble Distillation for AMR Parsing
Dec 14, 2021
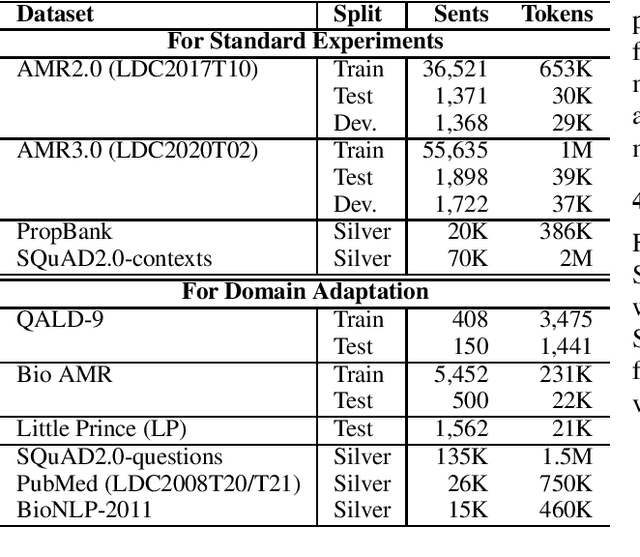
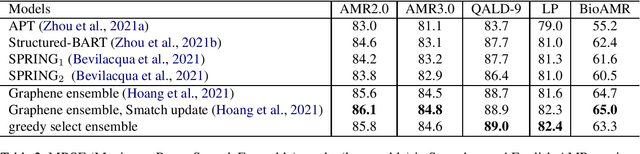
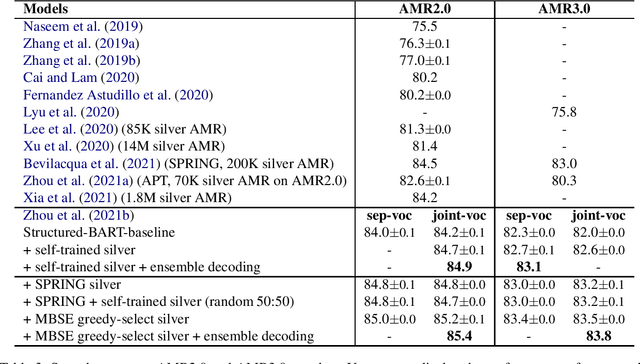
AMR parsing has experienced an unprecendented increase in performance in the last three years, due to a mixture of effects including architecture improvements and transfer learning. Self-learning techniques have also played a role in pushing performance forward. However, for most recent high performant parsers, the effect of self-learning and silver data generation seems to be fading. In this paper we show that it is possible to overcome this diminishing returns of silver data by combining Smatch-based ensembling techniques with ensemble distillation. In an extensive experimental setup, we push single model English parser performance above 85 Smatch for the first time and return to substantial gains. We also attain a new state-of-the-art for cross-lingual AMR parsing for Chinese, German, Italian and Spanish. Finally we explore the impact of the proposed distillation technique on domain adaptation, and show that it can produce gains rivaling those of human annotated data for QALD-9 and achieve a new state-of-the-art for BioAMR.
FLOWER: A comprehensive dataflow compiler for high-level synthesis
Dec 14, 2021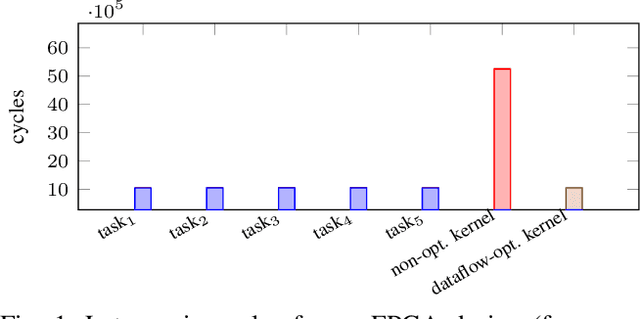
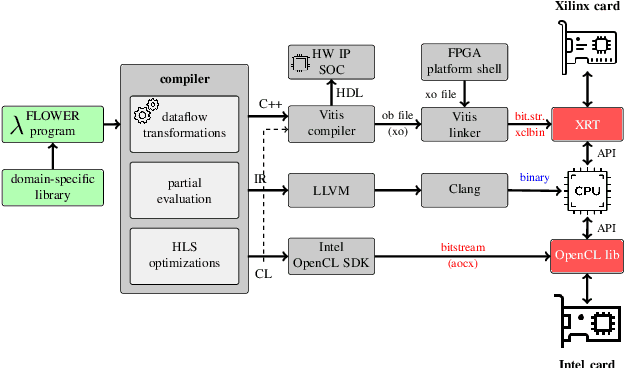
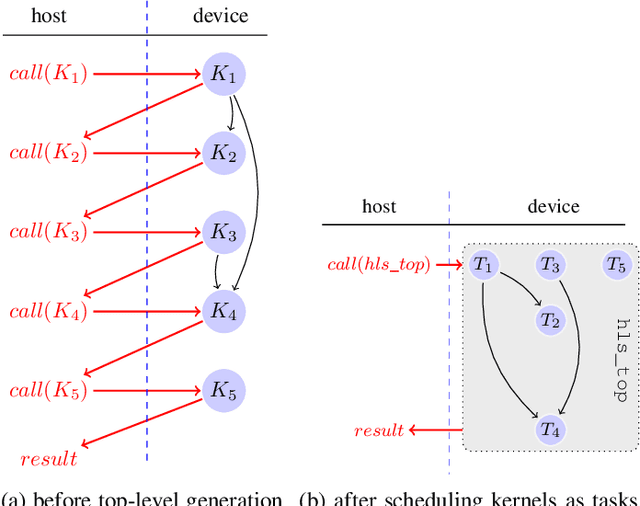
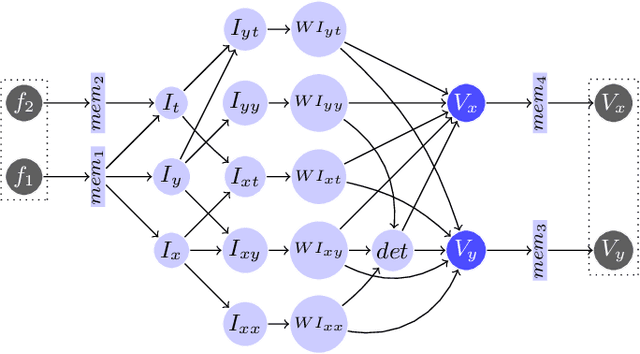
FPGAs have found their way into data centers as accelerator cards, making reconfigurable computing more accessible for high-performance applications. At the same time, new high-level synthesis compilers like Xilinx Vitis and runtime libraries such as XRT attract software programmers into the reconfigurable domain. While software programmers are familiar with task-level and data-parallel programming, FPGAs often require different types of parallelism. For example, data-driven parallelism is mandatory to obtain satisfactory hardware designs for pipelined dataflow architectures. However, software programmers are often not acquainted with dataflow architectures - resulting in poor hardware designs. In this work we present FLOWER, a comprehensive compiler infrastructure that provides automatic canonical transformations for high-level synthesis from a domain-specific library. This allows programmers to focus on algorithm implementations rather than low-level optimizations for dataflow architectures. We show that FLOWER allows to synthesize efficient implementations for high-performance streaming applications targeting System-on-Chip and FPGA accelerator cards, in the context of image processing and computer vision.