 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Developing Products Update-Alert System for e-Commerce Websites Users Using HTML Data and Web Scraping Technique
Sep 02, 2021
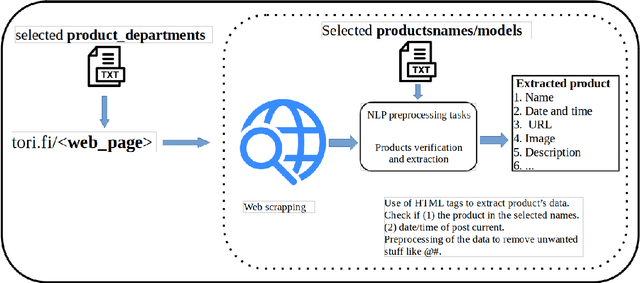

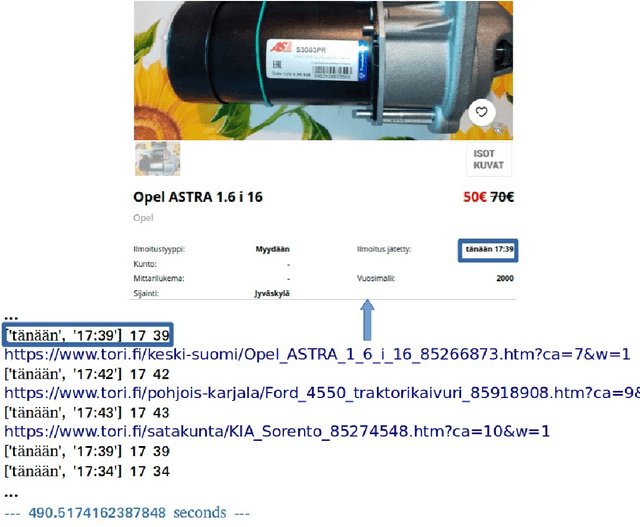
Websites are regarded as domains of limitless information which anyone and everyone can access. The new trend of technology put us to change the way we are doing our business. The Internet now is fastly becoming a new place for business and the advancement in this technology gave rise to the number of e-commerce websites. This made the lifestyle of marketers/vendors, retailers and consumers (collectively regarded as users in this paper) easy, because it provides easy platforms to sale/order items through the internet. This also requires that the users will have to spend a lot of time and effort to search for the best product deals, products updates and offers on e-commerce websites. They have to filter and compare search results by themselves which takes a lot of time and there are chances of ambiguous results. In this paper, we applied web crawling and scraping methods on an e-commerce website to get HTML data for identifying products updates based on the current time. The HTML data is preprocessed to extract details of the products such as name, price, post date and time, etc. to serve as useful information for users.
* 6 pages, 3 figures, 1 table, IJNLC Journal
On the Detection of Markov Decision Processes
Dec 23, 2021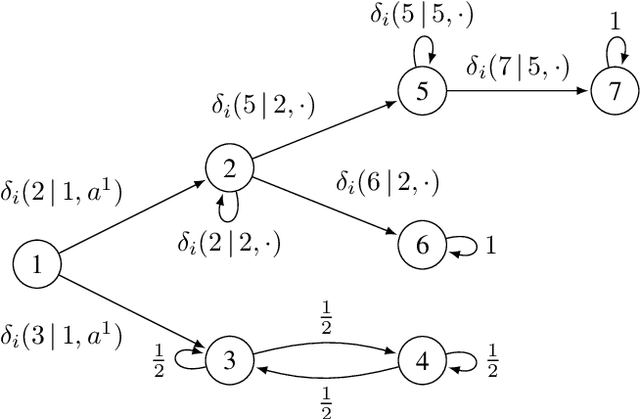
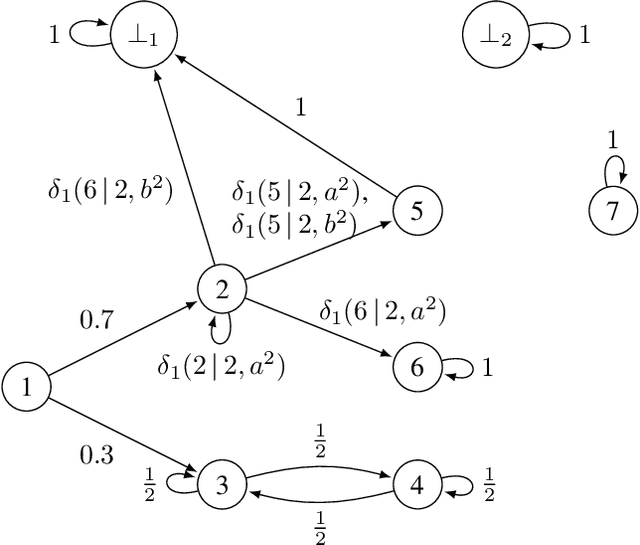
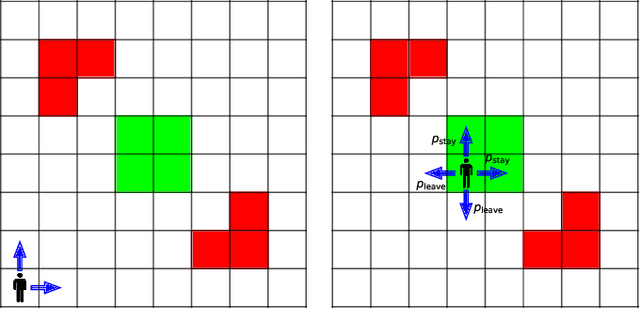
We study the detection problem for a finite set of Markov decision processes (MDPs) where the MDPs have the same state and action spaces but possibly different probabilistic transition functions. Any one of these MDPs could be the model for some underlying controlled stochastic process, but it is unknown a priori which MDP is the ground truth. We investigate whether it is possible to asymptotically detect the ground truth MDP model perfectly based on a single observed history (state-action sequence). Since the generation of histories depends on the policy adopted to control the MDPs, we discuss the existence and synthesis of policies that allow for perfect detection. We start with the case of two MDPs and establish a necessary and sufficient condition for the existence of policies that lead to perfect detection. Based on this condition, we then develop an algorithm that efficiently (in time polynomial in the size of the MDPs) determines the existence of policies and synthesizes one when they exist. We further extend the results to the more general case where there are more than two MDPs in the candidate set, and we develop a policy synthesis algorithm based on the breadth-first search and recursion. We demonstrate the effectiveness of our algorithms through numerical examples.
Propagation Graph Estimation by Pairwise Alignment of Time Series Observation Sequences
May 11, 2020
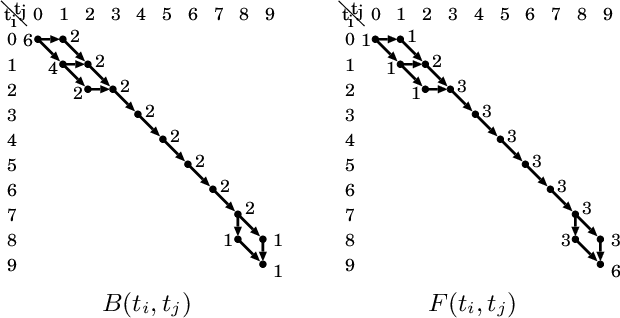
Various things propagate through the medium of individuals. Some biological cells fire right after the firing of their neighbor cells, and such firing propagates from cells to cells. In this paper, we study the problem of estimating the firing propagation order of cells from the $\{0,1 \}$-state sequences of all the cells, where '1' at the $i$-th position means the firing state of the cell at time step $i$. We propose a method to estimate the propagation direction between cells by the sum of one cell's time delay of the matched positions from the other cell averaged over the minimum cost alignments and show how to calculate it efficiently. The propagation order estimated by our proposed method is demonstrated to be correct for our synthetic datasets, and also to be consistent with visually recognizable firing order for the dataset of soil-dwelling amoeba's chemical signal emitting state sequences.
Stage Conscious Attention Network (SCAN) : A Demonstration-Conditioned Policy for Few-Shot Imitation
Dec 04, 2021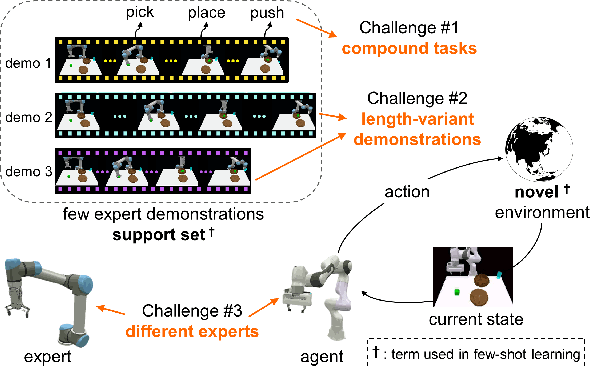
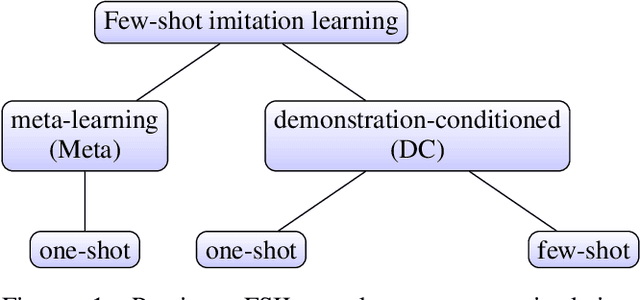

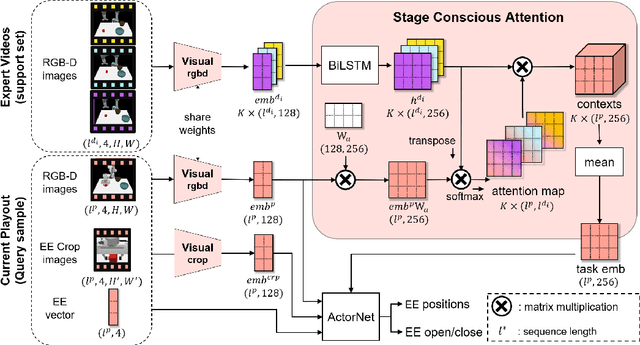
In few-shot imitation learning (FSIL), using behavioral cloning (BC) to solve unseen tasks with few expert demonstrations becomes a popular research direction. The following capabilities are essential in robotics applications: (1) Behaving in compound tasks that contain multiple stages. (2) Retrieving knowledge from few length-variant and misalignment demonstrations. (3) Learning from a different expert. No previous work can achieve these abilities at the same time. In this work, we conduct FSIL problem under the union of above settings and introduce a novel stage conscious attention network (SCAN) to retrieve knowledge from few demonstrations simultaneously. SCAN uses an attention module to identify each stage in length-variant demonstrations. Moreover, it is designed under demonstration-conditioned policy that learns the relationship between experts and agents. Experiment results show that SCAN can learn from different experts without fine-tuning and outperform baselines in complicated compound tasks with explainable visualization.
A portfolio approach to massively parallel Bayesian optimization
Oct 18, 2021
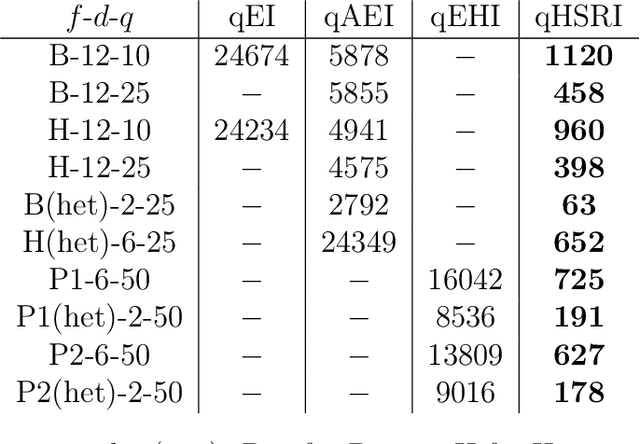
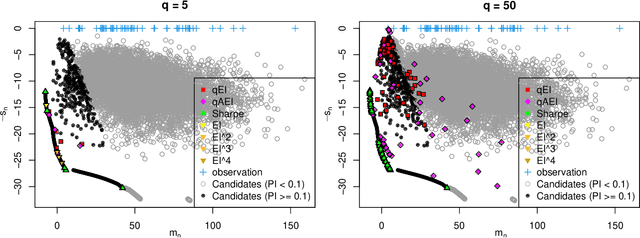
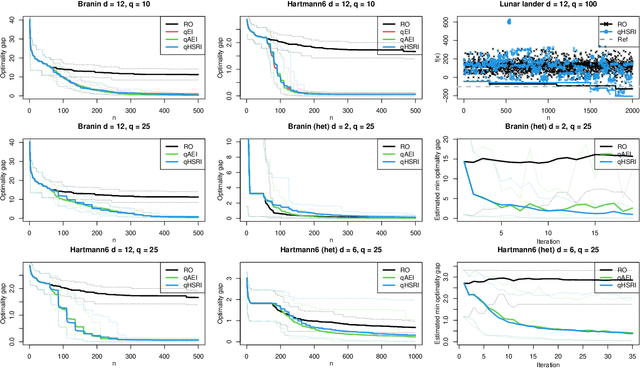
One way to reduce the time of conducting optimization studies is to evaluate designs in parallel rather than just one-at-a-time. For expensive-to-evaluate black-boxes, batch versions of Bayesian optimization have been proposed. They work by building a surrogate model of the black-box that can be used to select the designs to evaluate efficiently via an infill criterion. Still, with higher levels of parallelization becoming available, the strategies that work for a few tens of parallel evaluations become limiting, in particular due to the complexity of selecting more evaluations. It is even more crucial when the black-box is noisy, necessitating more evaluations as well as repeating experiments. Here we propose a scalable strategy that can keep up with massive batching natively, focused on the exploration/exploitation trade-off and a portfolio allocation. We compare the approach with related methods on deterministic and noisy functions, for mono and multiobjective optimization tasks. These experiments show similar or better performance than existing methods, while being orders of magnitude faster.
StARformer: Transformer with State-Action-Reward Representations
Oct 12, 2021
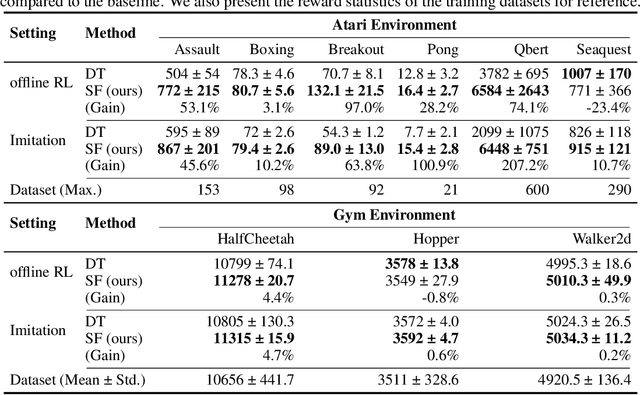
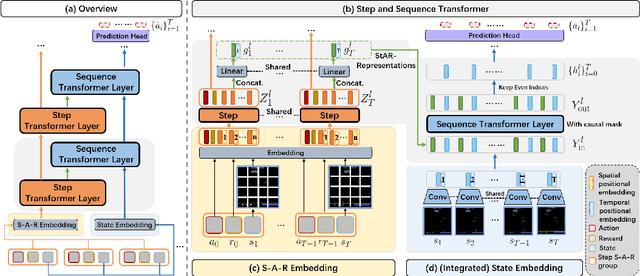
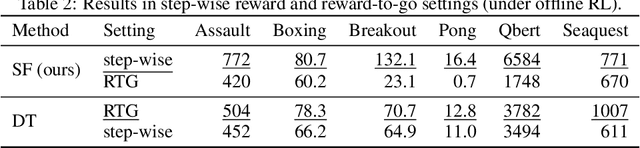
Reinforcement Learning (RL) can be considered as a sequence modeling task, i.e., given a sequence of past state-action-reward experiences, a model autoregressively predicts a sequence of future actions. Recently, Transformers have been successfully adopted to model this problem. In this work, we propose State-Action-Reward Transformer (StARformer), which explicitly models local causal relations to help improve action prediction in long sequences. StARformer first extracts local representations (i.e., StAR-representations) from each group of state-action-reward tokens within a very short time span. A sequence of such local representations combined with state representations, is then used to make action predictions over a long time span. Our experiments show that StARformer outperforms the state-of-the-art Transformer-based method on Atari (image) and Gym (state vector) benchmarks, in both offline-RL and imitation learning settings. StARformer is also more compliant with longer sequences of inputs compared to the baseline. Our code is available at https://github.com/elicassion/StARformer.
A integrating critic-waspas group decision making method under interval-valued q-rung orthogonal fuzzy enviroment
Jan 04, 2022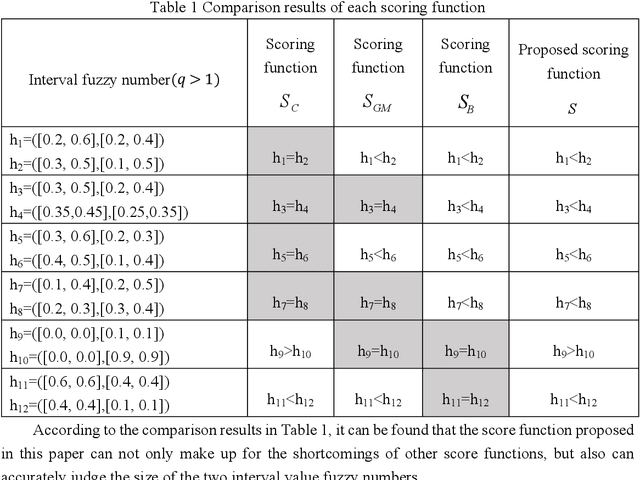
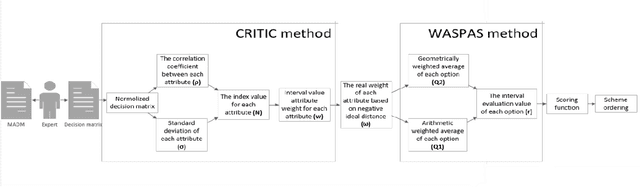
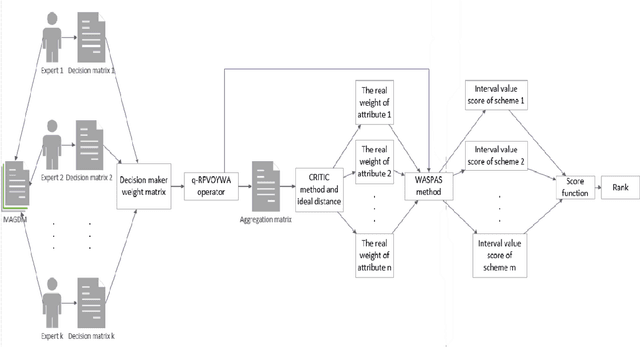
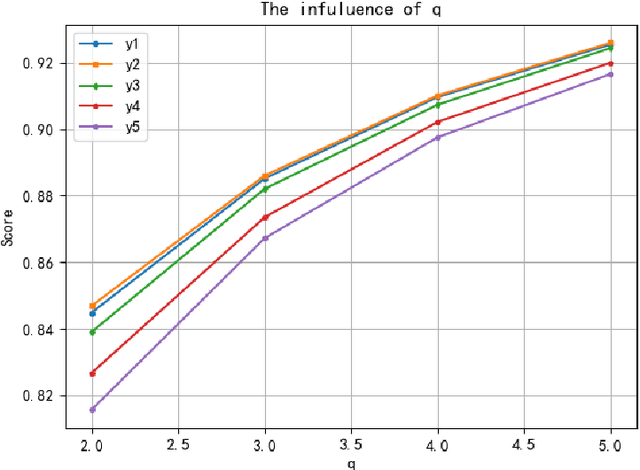
This paper provides a new tool for multi-attribute multi-objective group decision-making with unknown weights and attributes' weights. An interval-valued generalized orthogonal fuzzy group decision-making method is proposed based on the Yager operator and CRITIC-WASPAS method with unknown weights. The method integrates Yager operator, CRITIC, WASPAS, and interval value generalized orthogonal fuzzy group. Its merits lie in allowing decision-makers greater freedom, avoiding bias due to decision-makers' weight, and yielding accurate evaluation. The research includes: expanding the interval value generalized distance measurement method for comparison and application of similarity measurement and decision-making methods; developing a new scoring function for comparing the size of interval value generalized orthogonal fuzzy numbers,and further existing researches. The proposed interval-valued Yager weighted average operator (IVq-ROFYWA) and Yager weighted geometric average operator (IVq-ROFYWG) are used for information aggregation. The CRITIC-WASPAS combines the advantages of CRITIC and WASPAS, which not only work in the single decision but also serve as the basis of the group decision. The in-depth study of the decision-maker's weight matrix overcomes the shortcomings of taking the decision as a whole, and weighs the decision-maker's information aggregation. Finally, the group decision algorithm is used for hypertension risk management. The results are consistent with decision-makers' opinions. Practice and case analysis have proved the effectiveness of the method proposed in this paper. At the same time, it is compared with other operators and decision-making methods, which proves the method effective and feasible.
Non-separable Spatio-temporal Graph Kernels via SPDEs
Nov 16, 2021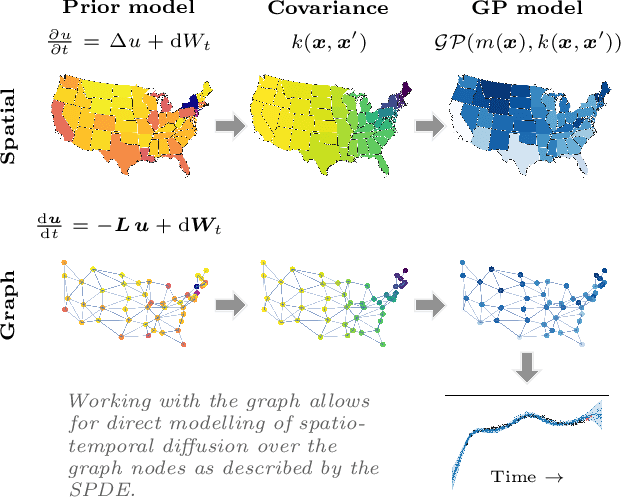


Gaussian processes (GPs) provide a principled and direct approach for inference and learning on graphs. However, the lack of justified graph kernels for spatio-temporal modelling has held back their use in graph problems. We leverage an explicit link between stochastic partial differential equations (SPDEs) and GPs on graphs, and derive non-separable spatio-temporal graph kernels that capture interaction across space and time. We formulate the graph kernels for the stochastic heat equation and wave equation. We show that by providing novel tools for spatio-temporal GP modelling on graphs, we outperform pre-existing graph kernels in real-world applications that feature diffusion, oscillation, and other complicated interactions.
Efficient Online Bayesian Inference for Neural Bandits
Dec 01, 2021
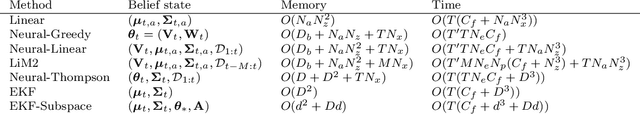
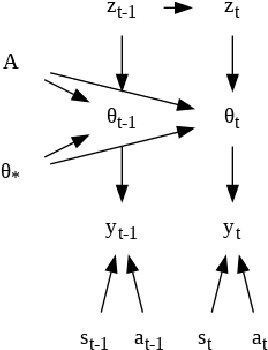
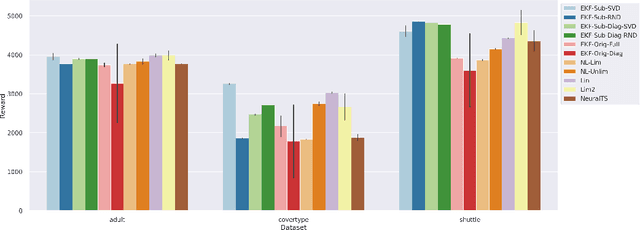
In this paper we present a new algorithm for online (sequential) inference in Bayesian neural networks, and show its suitability for tackling contextual bandit problems. The key idea is to combine the extended Kalman filter (which locally linearizes the likelihood function at each time step) with a (learned or random) low-dimensional affine subspace for the parameters; the use of a subspace enables us to scale our algorithm to models with $\sim 1M$ parameters. While most other neural bandit methods need to store the entire past dataset in order to avoid the problem of "catastrophic forgetting", our approach uses constant memory. This is possible because we represent uncertainty about all the parameters in the model, not just the final linear layer. We show good results on the "Deep Bayesian Bandit Showdown" benchmark, as well as MNIST and a recommender system.
Multi-Object Grasping -- Generating Efficient Robotic Picking and Transferring Policy
Dec 18, 2021
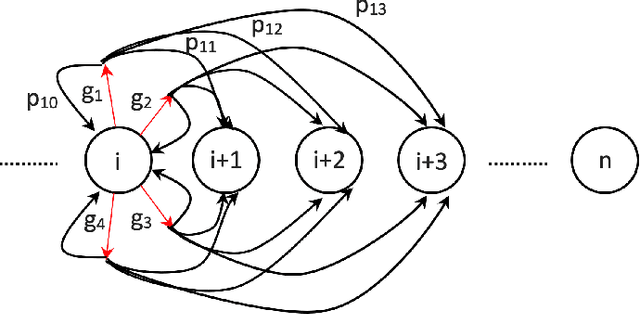

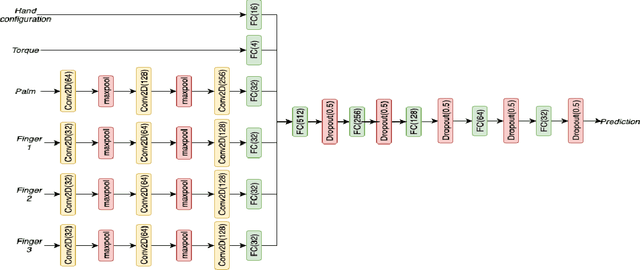
Transferring multiple objects between bins is a common task for many applications. In robotics, a standard approach is to pick up one object and transfer it at a time. However, grasping and picking up multiple objects and transferring them together at once is more efficient. This paper presents a set of novel strategies for efficiently grasping multiple objects in a bin to transfer them to another. The strategies enable a robotic hand to identify an optimal ready hand configuration (pre-grasp) and calculate a flexion synergy based on the desired quantity of objects to be grasped. This paper also presents an approach that uses the Markov decision process (MDP) to model the pick-transfer routines when the required quantity is larger than the capability of a single grasp. Using the MDP model, the proposed approach can generate an optimal pick-transfer routine that minimizes the number of transfers, representing efficiency. The proposed approach has been evaluated in both a simulation environment and on a real robotic system. The results show the approach reduces the number of transfers by 59% and the number of lifts by 58% compared to an optimal single object pick-transfer solution.