 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MiniNet: An extremely lightweight convolutional neural network for real-time unsupervised monocular depth estimation
Jun 27, 2020
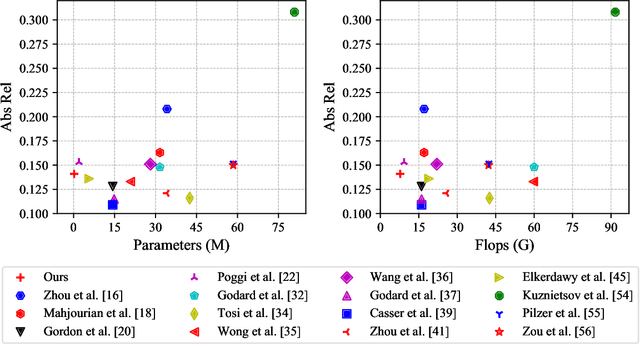
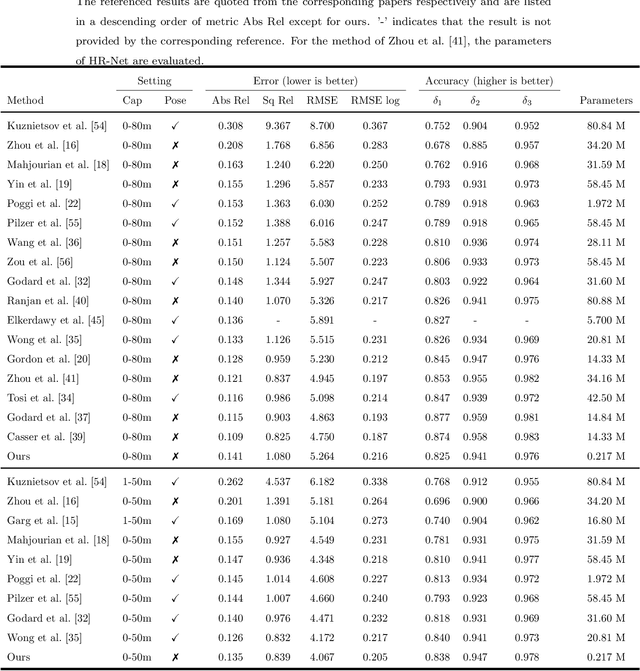
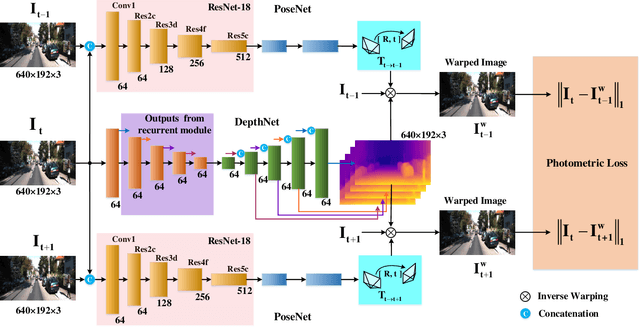
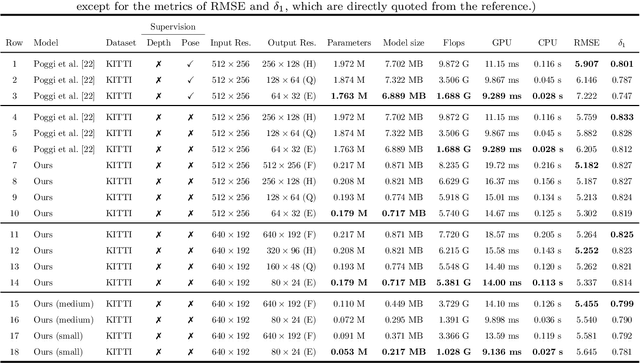
Predicting depth from a single image is an attractive research topic since it provides one more dimension of information to enable machines to better perceive the world. Recently, deep learning has emerged as an effective approach to monocular depth estimation. As obtaining labeled data is costly, there is a recent trend to move from supervised learning to unsupervised learning to obtain monocular depth. However, most unsupervised learning methods capable of achieving high depth prediction accuracy will require a deep network architecture which will be too heavy and complex to run on embedded devices with limited storage and memory spaces. To address this issue, we propose a new powerful network with a recurrent module to achieve the capability of a deep network while at the same time maintaining an extremely lightweight size for real-time high performance unsupervised monocular depth prediction from video sequences. Besides, a novel efficient upsample block is proposed to fuse the features from the associated encoder layer and recover the spatial size of features with the small number of model parameters. We validate the effectiveness of our approach via extensive experiments on the KITTI dataset. Our new model can run at a speed of about 110 frames per second (fps) on a single GPU, 37 fps on a single CPU, and 2 fps on a Raspberry Pi 3. Moreover, it achieves higher depth accuracy with nearly 33 times fewer model parameters than state-of-the-art models. To the best of our knowledge, this work is the first extremely lightweight neural network trained on monocular video sequences for real-time unsupervised monocular depth estimation, which opens up the possibility of implementing deep learning-based real-time unsupervised monocular depth prediction on low-cost embedded devices.
Multi-Scale RCNN Model for Financial Time-series Classification
Nov 21, 2019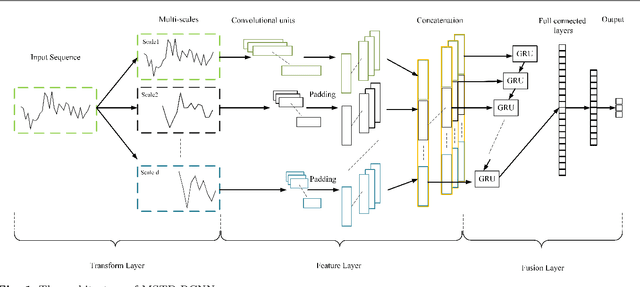

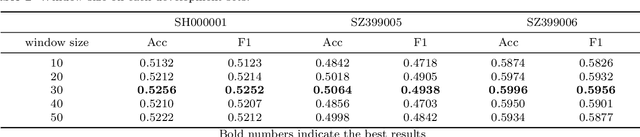
Financial time-series classification (FTC) is extremely valuable for investment management. In past decades, it draws a lot of attention from a wide extent of research areas, especially Artificial Intelligence (AI). Existing researches majorly focused on exploring the effects of the Multi-Scale (MS) property or the Temporal Dependency (TD) within financial time-series. Unfortunately, most previous researches fail to combine these two properties effectively and often fall short of accuracy and profitability. To effectively combine and utilize both properties of financial time-series, we propose a Multi-Scale Temporal Dependent Recurrent Convolutional Neural Network (MSTD-RCNN) for FTC. In the proposed method, the MS features are simultaneously extracted by convolutional units to precisely describe the state of the financial market. Moreover, the TD and complementary across different scales are captured through a Recurrent Neural Network. The proposed method is evaluated on three financial time-series datasets which source from the Chinese stock market. Extensive experimental results indicate that our model achieves the state-of-the-art performance in trend classification and simulated trading, compared with classical and advanced baseline models.
An AI-based Solution for Enhancing Delivery of Digital Learning for Future Teachers
Nov 09, 2021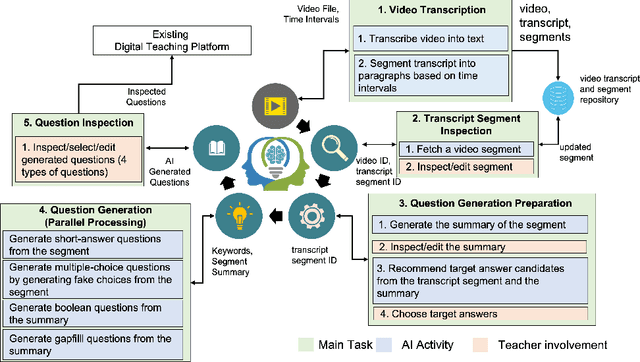

There has been a recent and rapid shift to digital learning hastened by the pandemic but also influenced by ubiquitous availability of digital tools and platforms now, making digital learning ever more accessible. An integral and one of the most difficult part of scaling digital learning and teaching is to be able to assess learner's knowledge and competency. An educator can record a lecture or create digital content that can be delivered to thousands of learners but assessing learners is extremely time consuming. In the paper, we propose an Artificial Intelligence (AI)-based solution namely VidVersityQG for generating questions automatically from pre-recorded video lectures. The solution can automatically generate different types of assessment questions (including short answer, multiple choice, true/false and fill in the blank questions) based on contextual and semantic information inferred from the videos. The proposed solution takes a human-centred approach, wherein teachers are provided the ability to modify/edit any AI generated questions. This approach encourages trust and engagement of teachers in the use and implementation of AI in education. The AI-based solution was evaluated for its accuracy in generating questions by 7 experienced teaching professionals and 117 education videos from multiple domains provided to us by our industry partner VidVersity. VidVersityQG solution showed promising results in generating high-quality questions automatically from video thereby significantly reducing the time and effort for educators in manual question generation.
Synthetic Event Time Series Health Data Generation
Nov 14, 2019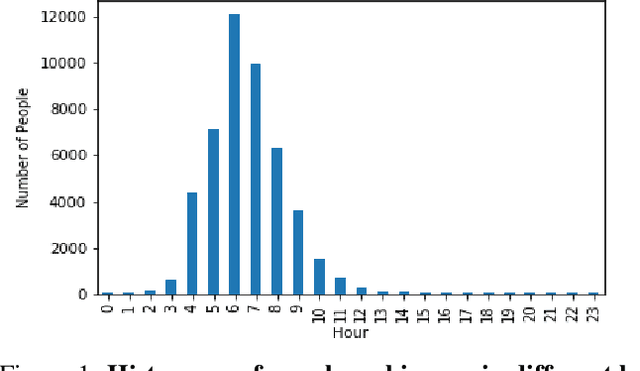
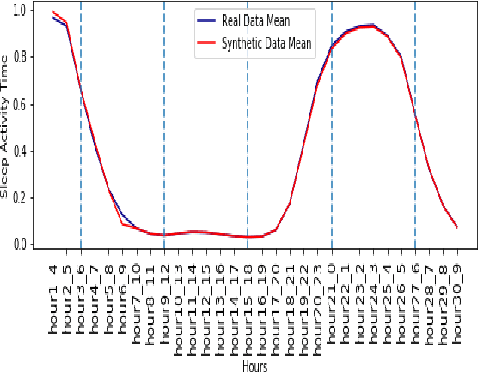
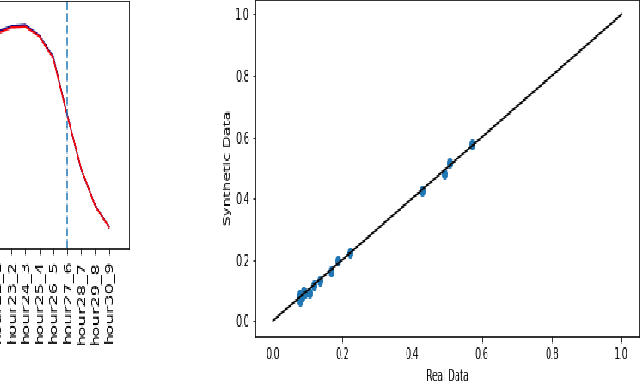
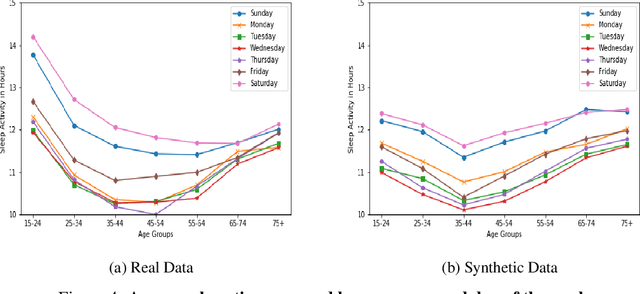
Synthetic medical data which preserves privacy while maintaining utility can be used as an alternative to real medical data, which has privacy costs and resource constraints associated with it. At present, most models focus on generating cross-sectional health data which is not necessarily representative of real data. In reality, medical data is longitudinal in nature, with a single patient having multiple health events, non-uniformly distributed throughout their lifetime. These events are influenced by patient covariates such as comorbidities, age group, gender etc. as well as external temporal effects (e.g. flu season). While there exist seminal methods to model time series data, it becomes increasingly challenging to extend these methods to medical event time series data. Due to the complexity of the real data, in which each patient visit is an event, we transform the data by using summary statistics to characterize the events for a fixed set of time intervals, to facilitate analysis and interpretability. We then train a generative adversarial network to generate synthetic data. We demonstrate this approach by generating human sleep patterns, from a publicly available dataset. We empirically evaluate the generated data and show close univariate resemblance between synthetic and real data. However, we also demonstrate how stratification by covariates is required to gain a deeper understanding of synthetic data quality.
AdaViT: Adaptive Tokens for Efficient Vision Transformer
Dec 14, 2021
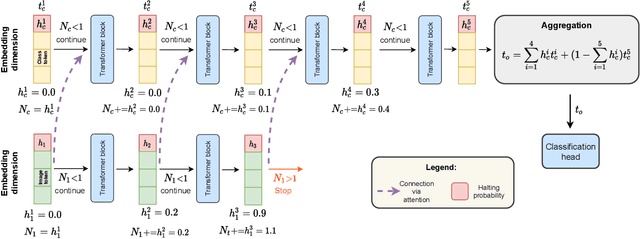
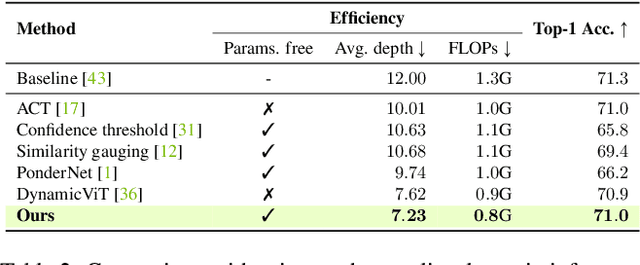

We introduce AdaViT, a method that adaptively adjusts the inference cost of vision transformer (ViT) for images of different complexity. AdaViT achieves this by automatically reducing the number of tokens in vision transformers that are processed in the network as inference proceeds. We reformulate Adaptive Computation Time (ACT) for this task, extending halting to discard redundant spatial tokens. The appealing architectural properties of vision transformers enables our adaptive token reduction mechanism to speed up inference without modifying the network architecture or inference hardware. We demonstrate that AdaViT requires no extra parameters or sub-network for halting, as we base the learning of adaptive halting on the original network parameters. We further introduce distributional prior regularization that stabilizes training compared to prior ACT approaches. On the image classification task (ImageNet1K), we show that our proposed AdaViT yields high efficacy in filtering informative spatial features and cutting down on the overall compute. The proposed method improves the throughput of DeiT-Tiny by 62% and DeiT-Small by 38% with only 0.3% accuracy drop, outperforming prior art by a large margin.
Efficient Belief Space Planning in High-Dimensional State Spaces using PIVOT: Predictive Incremental Variable Ordering Tactic
Dec 29, 2021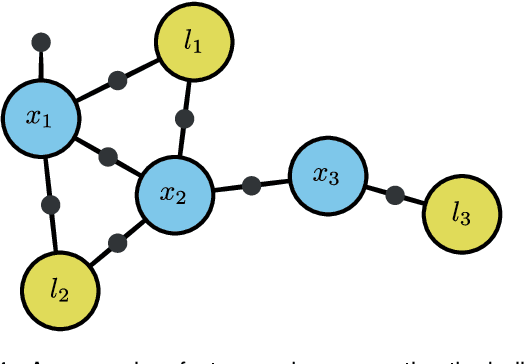
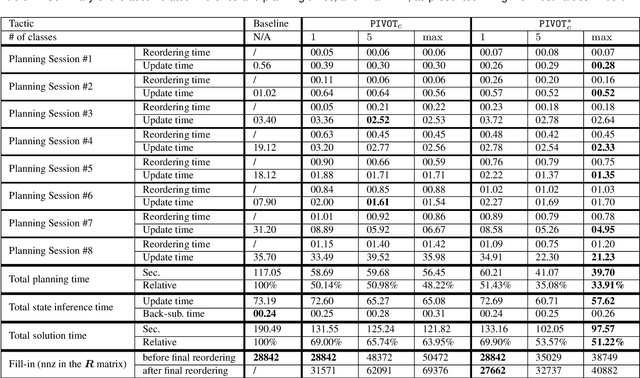
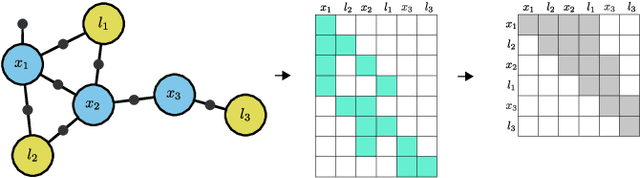
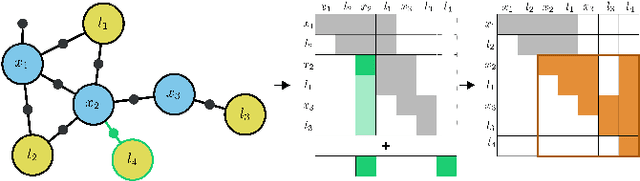
In this work, we examine the problem of online decision making under uncertainty, which we formulate as planning in the belief space. Maintaining beliefs (i.e., distributions) over high-dimensional states (e.g., entire trajectories) was not only shown to significantly improve accuracy, but also allows planning with information-theoretic objectives, as required for the tasks of active SLAM and information gathering. Nonetheless, planning under this "smoothing" paradigm holds a high computational complexity, which makes it challenging for online solution. Thus, we suggest the following idea: before planning, perform a standalone state variable reordering procedure on the initial belief, and "push forwards" all the predicted loop closing variables. Since the initial variable order determines which subset of them would be affected by incoming updates, such reordering allows us to minimize the total number of affected variables, and reduce the computational complexity of candidate evaluation during planning. We call this approach PIVOT: Predictive Incremental Variable Ordering Tactic. Applying this tactic can also improve the state inference efficiency; if we maintain the PIVOT order after the planning session, then we should similarly reduce the cost of loop closures, when they actually occur. To demonstrate its effectiveness, we applied PIVOT in a realistic active SLAM simulation, where we managed to significantly reduce the computation time of both the planning and inference sessions. The approach is applicable to general distributions, and induces no loss in accuracy.
The Curse of Zero Task Diversity: On the Failure of Transfer Learning to Outperform MAML and their Empirical Equivalence
Dec 24, 2021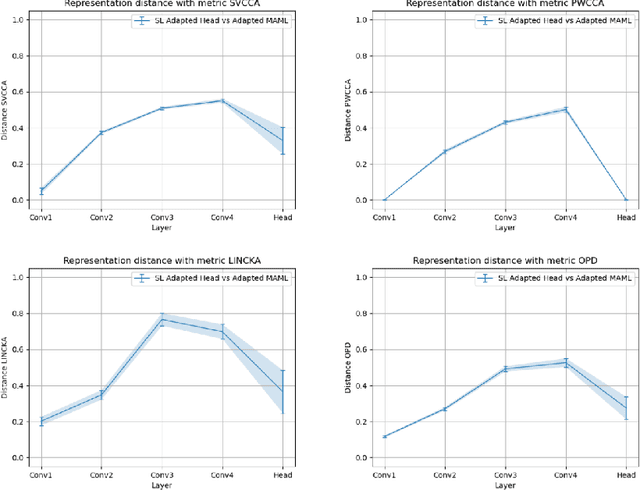
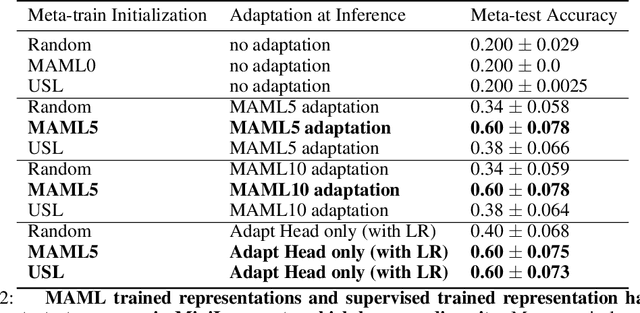
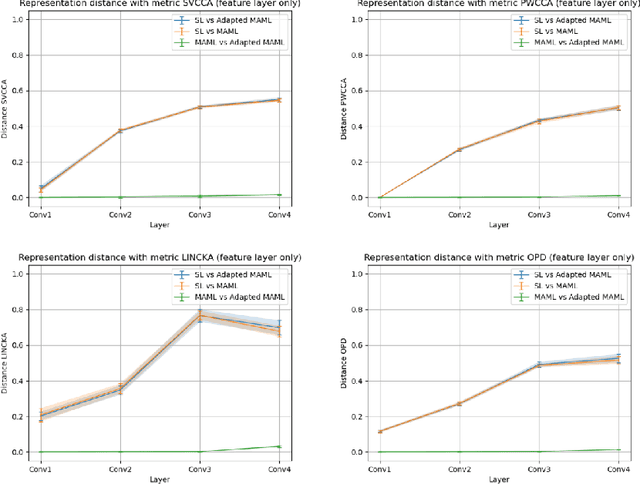
It has been recently observed that a transfer learning solution might be all we needed to solve many few-shot learning benchmarks. This raises important questions about when and how meta-learning algorithms should be deployed. In this paper, we make a first step in clarifying these questions by first formulating a computable metric for a few-shot learning benchmark that we hypothesize is predictive of whether meta-learning solutions will succeed or not. We name this metric the diversity coefficient of a few-shot learning benchmark. Using the diversity coefficient, we show that the MiniImagenet benchmark has zero diversity - according to twenty-four different ways to compute the diversity. We proceed to show that when making a fair comparison between MAML learned solutions to transfer learning, both have identical meta-test accuracy. This suggests that transfer learning fails to outperform MAML - contrary to what previous work suggests. Together, these two facts provide the first test of whether diversity correlates with meta-learning success and therefore show that a diversity coefficient of zero correlates with a high similarity between transfer learning and MAML learned solutions - especially at meta-test time. We therefore conjecture meta-learned solutions have the same meta-test performance as transfer learning when the diversity coefficient is zero.
Enhancing Food Intake Tracking in Long-Term Care with Automated Food Imaging and Nutrient Intake Tracking (AFINI-T) Technology
Dec 08, 2021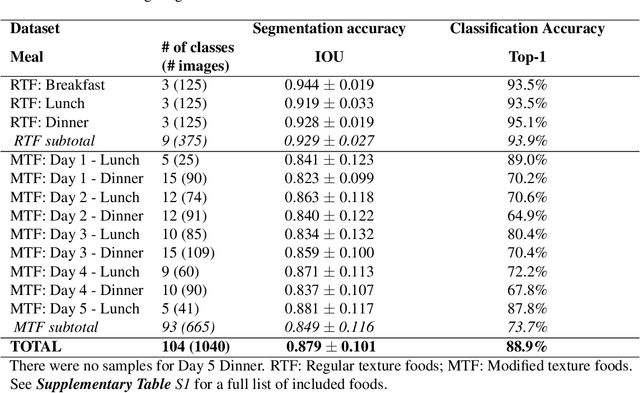
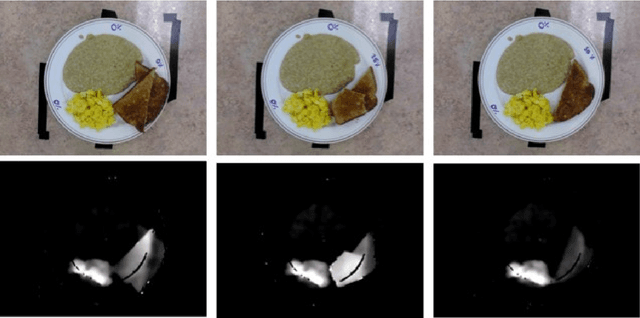
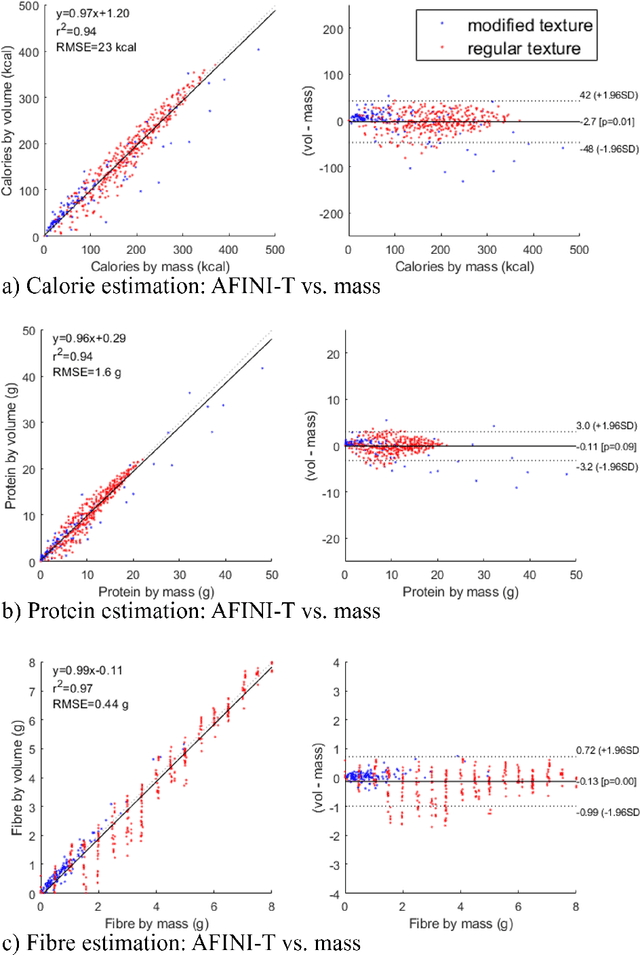

Half of long-term care (LTC) residents are malnourished increasing hospitalization, mortality, morbidity, with lower quality of life. Current tracking methods are subjective and time consuming. This paper presents the automated food imaging and nutrient intake tracking (AFINI-T) technology designed for LTC. We propose a novel convolutional autoencoder for food classification, trained on an augmented UNIMIB2016 dataset and tested on our simulated LTC food intake dataset (12 meal scenarios; up to 15 classes each; top-1 classification accuracy: 88.9%; mean intake error: -0.4 mL$\pm$36.7 mL). Nutrient intake estimation by volume was strongly linearly correlated with nutrient estimates from mass ($r^2$ 0.92 to 0.99) with good agreement between methods ($\sigma$= -2.7 to -0.01; zero within each of the limits of agreement). The AFINI-T approach is a deep-learning powered computational nutrient sensing system that may provide a novel means for more accurately and objectively tracking LTC resident food intake to support and prevent malnutrition tracking strategies.
Accelerated and instance-optimal policy evaluation with linear function approximation
Dec 24, 2021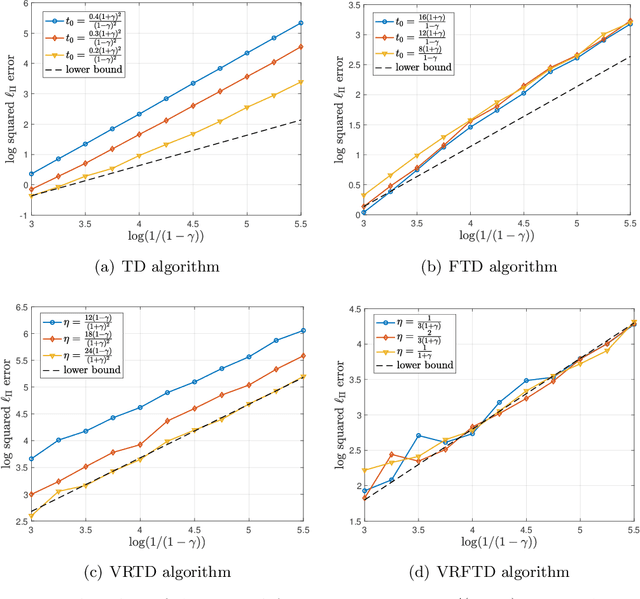
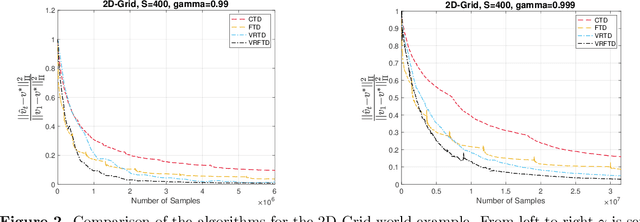
We study the problem of policy evaluation with linear function approximation and present efficient and practical algorithms that come with strong optimality guarantees. We begin by proving lower bounds that establish baselines on both the deterministic error and stochastic error in this problem. In particular, we prove an oracle complexity lower bound on the deterministic error in an instance-dependent norm associated with the stationary distribution of the transition kernel, and use the local asymptotic minimax machinery to prove an instance-dependent lower bound on the stochastic error in the i.i.d. observation model. Existing algorithms fail to match at least one of these lower bounds: To illustrate, we analyze a variance-reduced variant of temporal difference learning, showing in particular that it fails to achieve the oracle complexity lower bound. To remedy this issue, we develop an accelerated, variance-reduced fast temporal difference algorithm (VRFTD) that simultaneously matches both lower bounds and attains a strong notion of instance-optimality. Finally, we extend the VRFTD algorithm to the setting with Markovian observations, and provide instance-dependent convergence results that match those in the i.i.d. setting up to a multiplicative factor that is proportional to the mixing time of the chain. Our theoretical guarantees of optimality are corroborated by numerical experiments.
Safe Driving via Expert Guided Policy Optimization
Oct 30, 2021
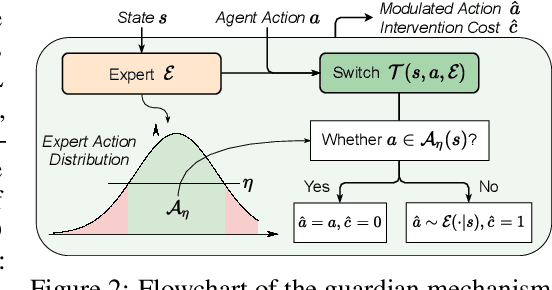
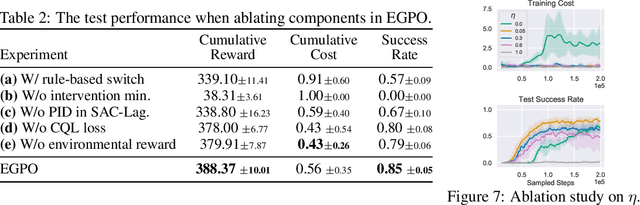

When learning common skills like driving, beginners usually have domain experts standing by to ensure the safety of the learning process. We formulate such learning scheme under the Expert-in-the-loop Reinforcement Learning where a guardian is introduced to safeguard the exploration of the learning agent. While allowing the sufficient exploration in the uncertain environment, the guardian intervenes under dangerous situations and demonstrates the correct actions to avoid potential accidents. Thus ERL enables both exploration and expert's partial demonstration as two training sources. Following such a setting, we develop a novel Expert Guided Policy Optimization (EGPO) method which integrates the guardian in the loop of reinforcement learning. The guardian is composed of an expert policy to generate demonstration and a switch function to decide when to intervene. Particularly, a constrained optimization technique is used to tackle the trivial solution that the agent deliberately behaves dangerously to deceive the expert into taking over. Offline RL technique is further used to learn from the partial demonstration generated by the expert. Safe driving experiments show that our method achieves superior training and test-time safety, outperforms baselines with a substantial margin in sample efficiency, and preserves the generalizabiliy to unseen environments in test-time. Demo video and source code are available at: https://decisionforce.github.io/EGPO/