 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Tracking People by Predicting 3D Appearance, Location & Pose
Dec 08, 2021

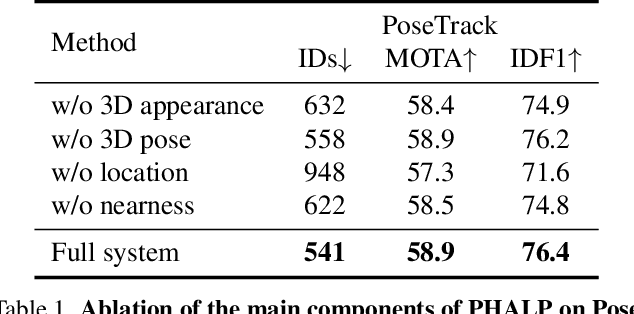
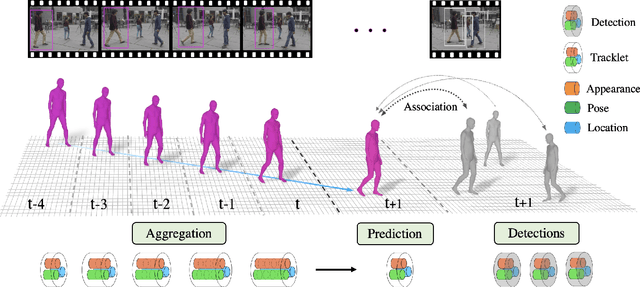

In this paper, we present an approach for tracking people in monocular videos, by predicting their future 3D representations. To achieve this, we first lift people to 3D from a single frame in a robust way. This lifting includes information about the 3D pose of the person, his or her location in the 3D space, and the 3D appearance. As we track a person, we collect 3D observations over time in a tracklet representation. Given the 3D nature of our observations, we build temporal models for each one of the previous attributes. We use these models to predict the future state of the tracklet, including 3D location, 3D appearance, and 3D pose. For a future frame, we compute the similarity between the predicted state of a tracklet and the single frame observations in a probabilistic manner. Association is solved with simple Hungarian matching, and the matches are used to update the respective tracklets. We evaluate our approach on various benchmarks and report state-of-the-art results.
AquaVis: A Perception-Aware Autonomous Navigation Framework for Underwater Vehicles
Oct 04, 2021
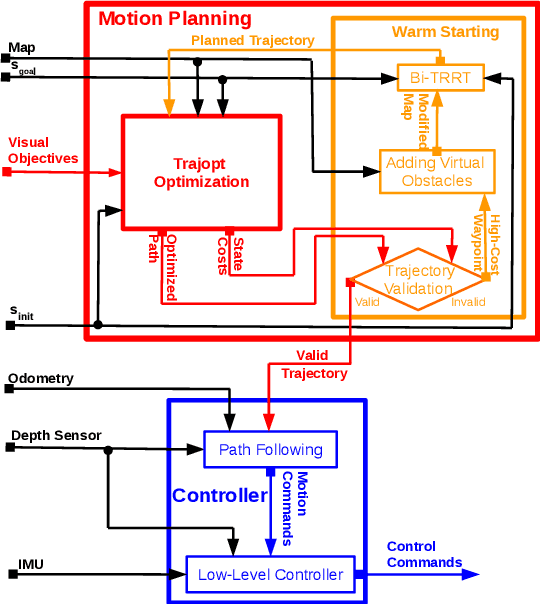
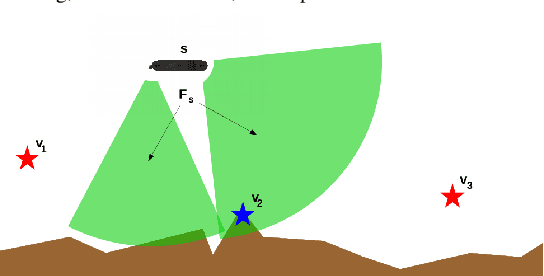
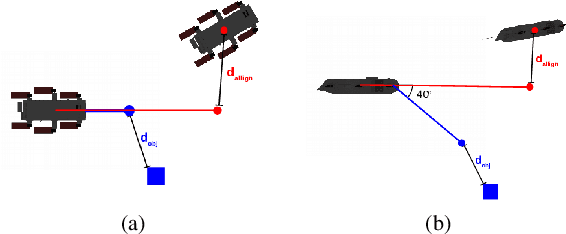
Visual monitoring operations underwater require both observing the objects of interest in close-proximity, and tracking the few feature-rich areas necessary for state estimation.This paper introduces the first navigation framework, called AquaVis, that produces on-line visibility-aware motion plans that enable Autonomous Underwater Vehicles (AUVs) to track multiple visual objectives with an arbitrary camera configuration in real-time. Using the proposed pipeline, AUVs can efficiently move in 3D, reach their goals while avoiding obstacles safely, and maximizing the visibility of multiple objectives along the path within a specified proximity. The method is sufficiently fast to be executed in real-time and is suitable for single or multiple camera configurations. Experimental results show the significant improvement on tracking multiple automatically-extracted points of interest, with low computational overhead and fast re-planning times
Self-Supervised Speaker Verification with Simple Siamese Network and Self-Supervised Regularization
Dec 08, 2021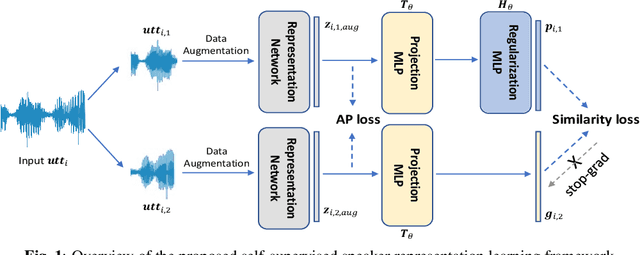
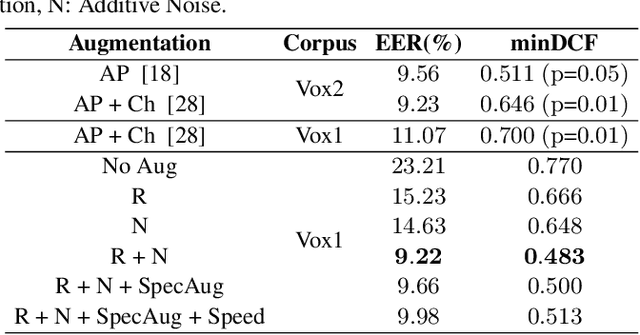
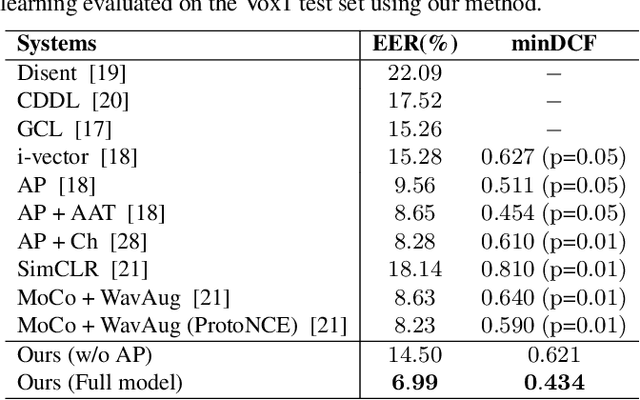
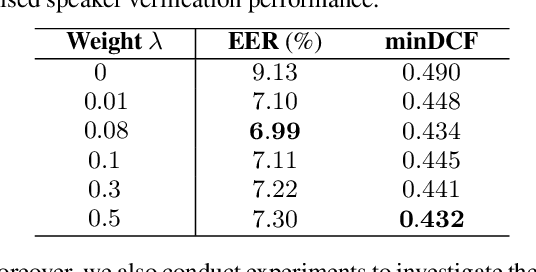
Training speaker-discriminative and robust speaker verification systems without speaker labels is still challenging and worthwhile to explore. In this study, we propose an effective self-supervised learning framework and a novel regularization strategy to facilitate self-supervised speaker representation learning. Different from contrastive learning-based self-supervised learning methods, the proposed self-supervised regularization (SSReg) focuses exclusively on the similarity between the latent representations of positive data pairs. We also explore the effectiveness of alternative online data augmentation strategies on both the time domain and frequency domain. With our strong online data augmentation strategy, the proposed SSReg shows the potential of self-supervised learning without using negative pairs and it can significantly improve the performance of self-supervised speaker representation learning with a simple Siamese network architecture. Comprehensive experiments on the VoxCeleb datasets demonstrate that our proposed self-supervised approach obtains a 23.4% relative improvement by adding the effective self-supervised regularization and outperforms other previous works.
On Slowly-varying Non-stationary Bandits
Oct 25, 2021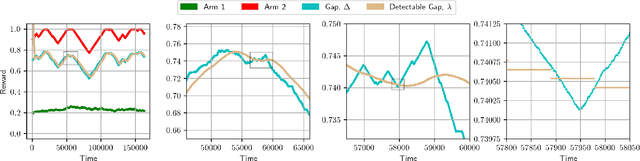
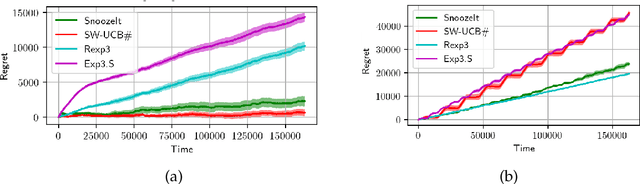
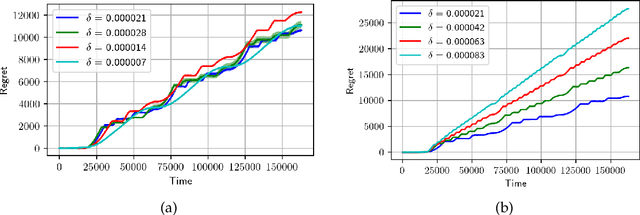
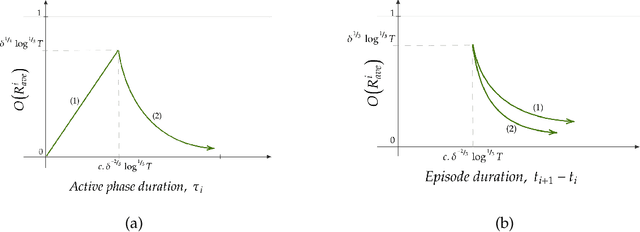
We consider minimisation of dynamic regret in non-stationary bandits with a slowly varying property. Namely, we assume that arms' rewards are stochastic and independent over time, but that the absolute difference between the expected rewards of any arm at any two consecutive time-steps is at most a drift limit $\delta > 0$. For this setting that has not received enough attention in the past, we give a new algorithm which extends naturally the well-known Successive Elimination algorithm to the non-stationary bandit setting. We establish the first instance-dependent regret upper bound for slowly varying non-stationary bandits. The analysis in turn relies on a novel characterization of the instance as a detectable gap profile that depends on the expected arm reward differences. We also provide the first minimax regret lower bound for this problem, enabling us to show that our algorithm is essentially minimax optimal. Also, this lower bound we obtain matches that of the more general total variation-budgeted bandits problem, establishing that the seemingly easier former problem is at least as hard as the more general latter problem in the minimax sense. We complement our theoretical results with experimental illustrations.
EEG functional connectivity and deep learning for automatic diagnosis of brain disorders: Alzheimer's disease and schizophrenia
Oct 07, 2021
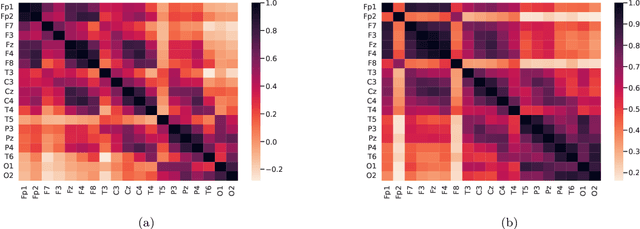
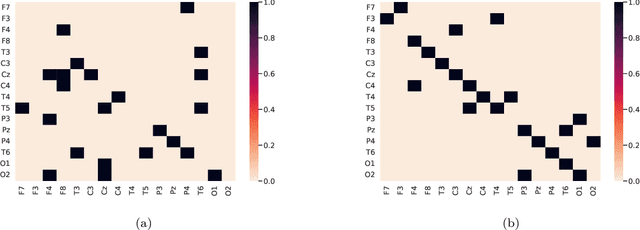
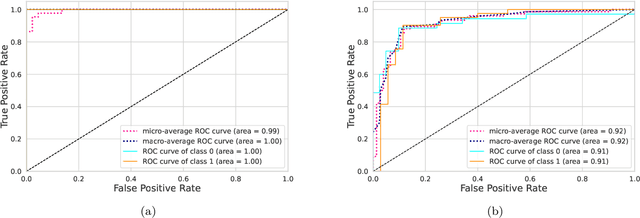
Mental disorders are among the leading causes of disability worldwide. The first step in treating these conditions is to obtain an accurate diagnosis, but the absence of established clinical tests makes this task challenging. Machine learning algorithms can provide a possible solution to this problem, as we describe in this work. We present a method for the automatic diagnosis of mental disorders based on the matrix of connections obtained from EEG time series and deep learning. We show that our approach can classify patients with Alzheimer's disease and schizophrenia with a high level of accuracy. The comparison with the traditional cases, that use raw EEG time series, shows that our method provides the highest precision. Therefore, the application of deep neural networks on data from brain connections is a very promising method to the diagnosis of neurological disorders.
Representation Learning for Dynamic Hyperedges
Dec 19, 2021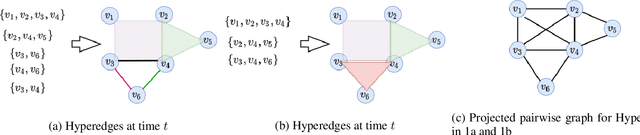
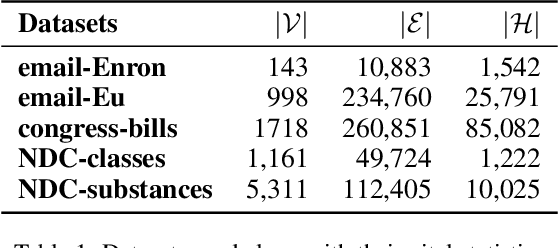
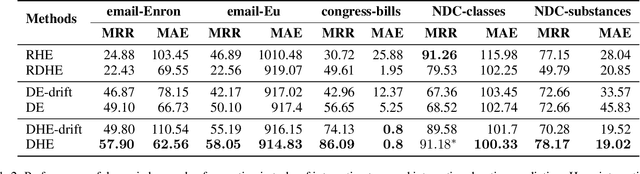
Recently there has been a massive interest in extracting information from interaction data. Traditionally this is done by modeling it as pair-wise interaction at a particular time in a dynamic network. However, real-world interactions are seldom pair-wise; they can involve more than two nodes. In literature, these types of group interactions are modeled by hyperedges/hyperlinks. The existing works for hyperedge modeling focused only on static networks, and they cannot model the temporal evolution of nodes as they interact with other nodes. Also, they cannot answer temporal queries like which type of interaction will occur next and when the interaction will occur. To address these limitations, in this paper, we develop a temporal point process model for hyperlink prediction. Our proposed model uses dynamic representation techniques for nodes to model the evolution and uses this representation in a neural point process framework to make inferences. We evaluate our models on five real-world interaction data and show that our dynamic model has significant performance gain over the static model. Further, we also demonstrate the advantages of our technique over the pair-wise interaction modeling technique.
Contrastive Spatio-Temporal Pretext Learning for Self-supervised Video Representation
Dec 19, 2021
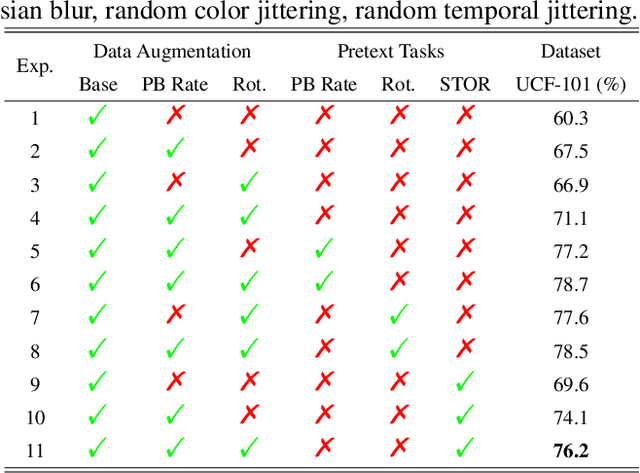
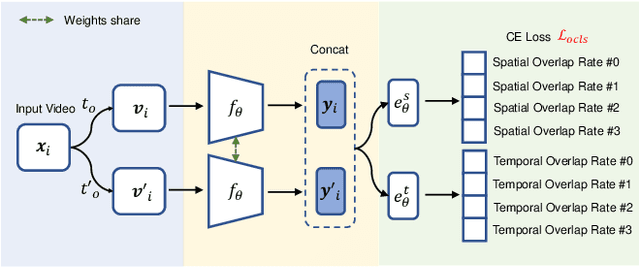
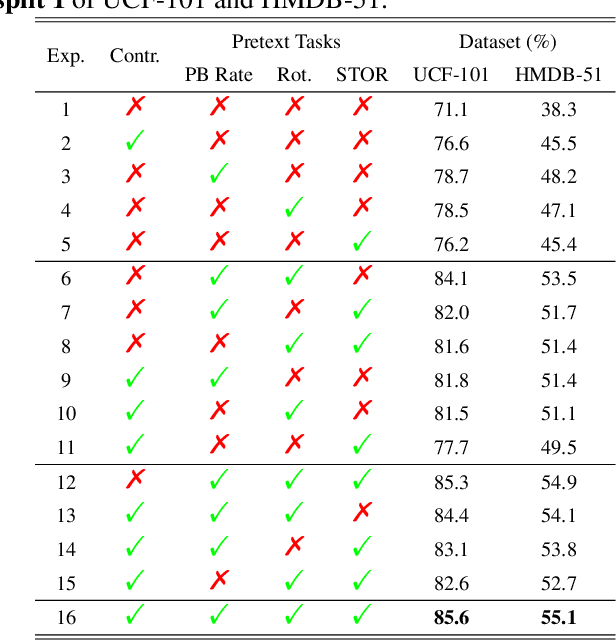
Spatio-temporal representation learning is critical for video self-supervised representation. Recent approaches mainly use contrastive learning and pretext tasks. However, these approaches learn representation by discriminating sampled instances via feature similarity in the latent space while ignoring the intermediate state of the learned representations, which limits the overall performance. In this work, taking into account the degree of similarity of sampled instances as the intermediate state, we propose a novel pretext task - spatio-temporal overlap rate (STOR) prediction. It stems from the observation that humans are capable of discriminating the overlap rates of videos in space and time. This task encourages the model to discriminate the STOR of two generated samples to learn the representations. Moreover, we employ a joint optimization combining pretext tasks with contrastive learning to further enhance the spatio-temporal representation learning. We also study the mutual influence of each component in the proposed scheme. Extensive experiments demonstrate that our proposed STOR task can favor both contrastive learning and pretext tasks. The joint optimization scheme can significantly improve the spatio-temporal representation in video understanding. The code is available at https://github.com/Katou2/CSTP.
Towards Lightweight Controllable Audio Synthesis with Conditional Implicit Neural Representations
Dec 02, 2021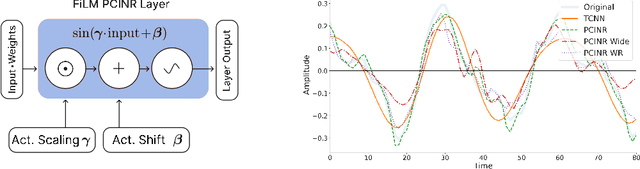
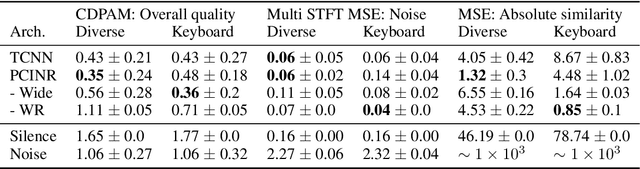
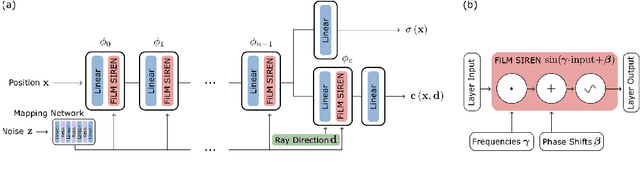
The high temporal resolution of audio and our perceptual sensitivity to small irregularities in waveforms make synthesizing at high sampling rates a complex and computationally intensive task, prohibiting real-time, controllable synthesis within many approaches. In this work we aim to shed light on the potential of Conditional Implicit Neural Representations (CINRs) as lightweight backbones in generative frameworks for audio synthesis. Our experiments show that small Periodic Conditional INRs (PCINRs) learn faster and generally produce quantitatively better audio reconstructions than Transposed Convolutional Neural Networks with equal parameter counts. However, their performance is very sensitive to activation scaling hyperparameters. When learning to represent more uniform sets, PCINRs tend to introduce artificial high-frequency components in reconstructions. We validate this noise can be minimized by applying standard weight regularization during training or decreasing the compositional depth of PCINRs, and suggest directions for future research.
Does Terrorism Trigger Online Hate Speech? On the Association of Events and Time Series
Apr 30, 2020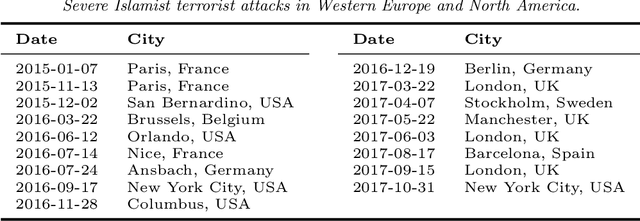
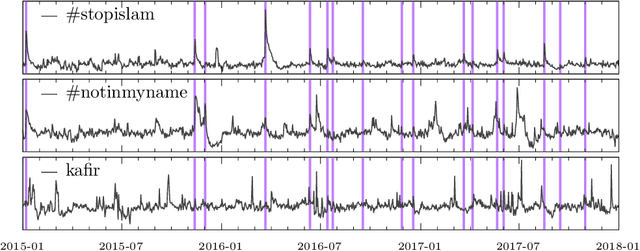
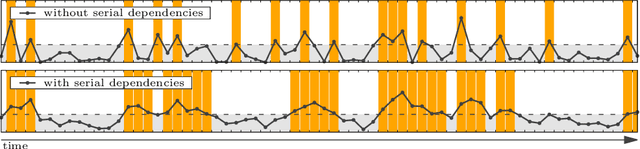
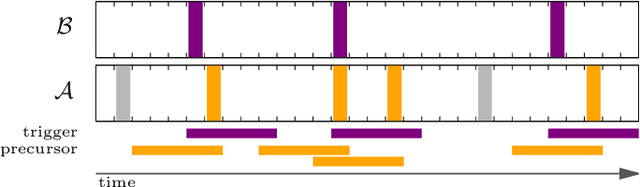
Hate speech is ubiquitous on the Web. Recently, the offline causes that contribute to online hate speech have received increasing attention. A recurring question is whether the occurrence of extreme events offline systematically triggers bursts of hate speech online, indicated by peaks in the volume of hateful social media posts. Formally, this question translates into measuring the association between a sparse event series and a time series. We propose a novel statistical methodology to measure, test and visualize the systematic association between rare events and peaks in a time series. In contrast to previous methods for causal inference or independence tests on time series, our approach focuses only on the timing of events and peaks, and no other distributional characteristics. We follow the framework of event coincidence analysis (ECA) that was originally developed to correlate point processes. We formulate a discrete-time variant of ECA and derive all required distributions to enable analyses of peaks in time series, with a special focus on serial dependencies and peaks over multiple thresholds. The analysis gives rise to a novel visualization of the association via quantile-trigger rate plots. We demonstrate the utility of our approach by analyzing whether Islamist terrorist attacks in Western Europe and North America systematically trigger bursts of hate speech and counter-hate speech on Twitter.
Iterative Contrast-Classify For Semi-supervised Temporal Action Segmentation
Dec 08, 2021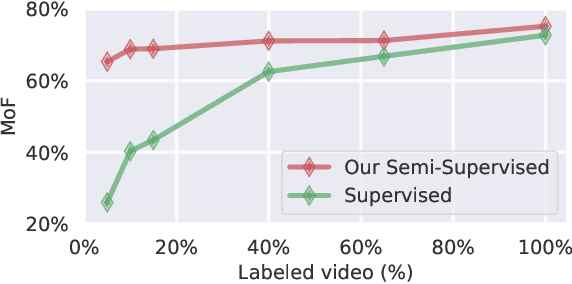
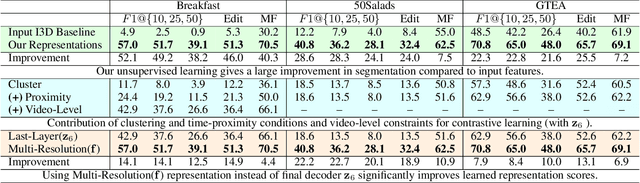
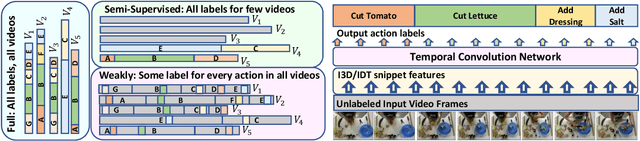
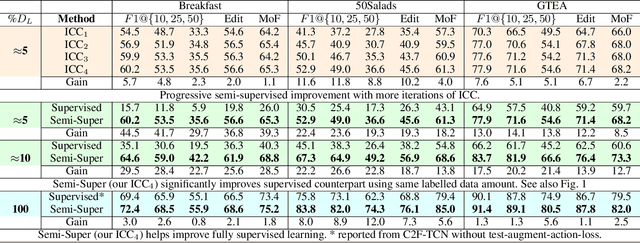
Temporal action segmentation classifies the action of each frame in (long) video sequences. Due to the high cost of frame-wise labeling, we propose the first semi-supervised method for temporal action segmentation. Our method hinges on unsupervised representation learning, which, for temporal action segmentation, poses unique challenges. Actions in untrimmed videos vary in length and have unknown labels and start/end times. Ordering of actions across videos may also vary. We propose a novel way to learn frame-wise representations from temporal convolutional networks (TCNs) by clustering input features with added time-proximity condition and multi-resolution similarity. By merging representation learning with conventional supervised learning, we develop an "Iterative-Contrast-Classify (ICC)" semi-supervised learning scheme. With more labelled data, ICC progressively improves in performance; ICC semi-supervised learning, with 40% labelled videos, performs similar to fully-supervised counterparts. Our ICC improves MoF by {+1.8, +5.6, +2.5}% on Breakfast, 50Salads and GTEA respectively for 100% labelled videos.