 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Probabilistic Time of Arrival Localization
Oct 15, 2019
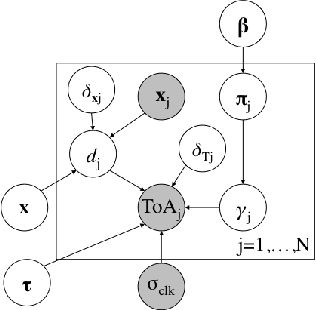

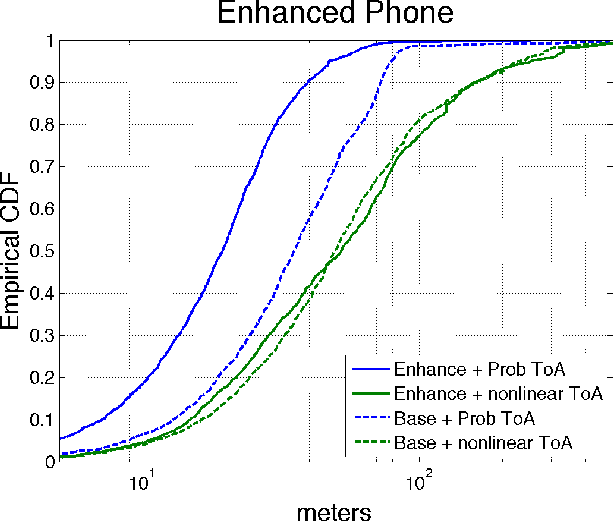
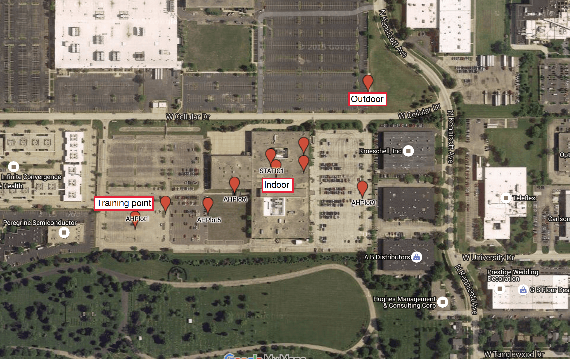
In this paper, we take a new approach for time of arrival geo-localization. We show that the main sources of error in metropolitan areas are due to environmental imperfections that bias our solutions, and that we can rely on a probabilistic model to learn and compensate for them. The resulting localization error is validated using measurements from a live LTE cellular network to be less than 10 meters, representing an order-of-magnitude improvement.
Enhancing Food Intake Tracking in Long-Term Care with Automated Food Imaging and Nutrient Intake Tracking (AFINI-T) Technology
Dec 08, 2021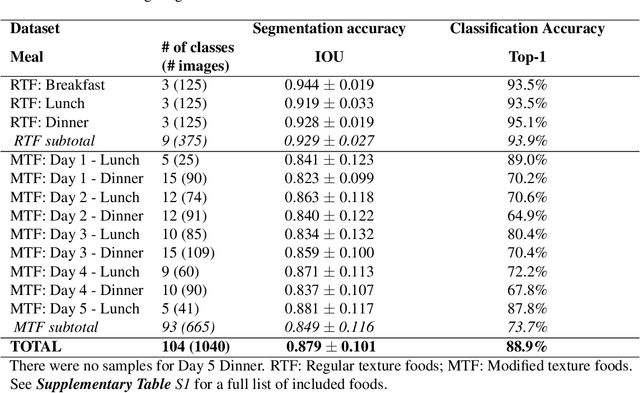
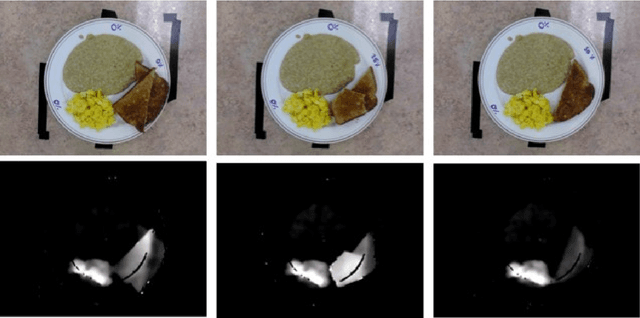
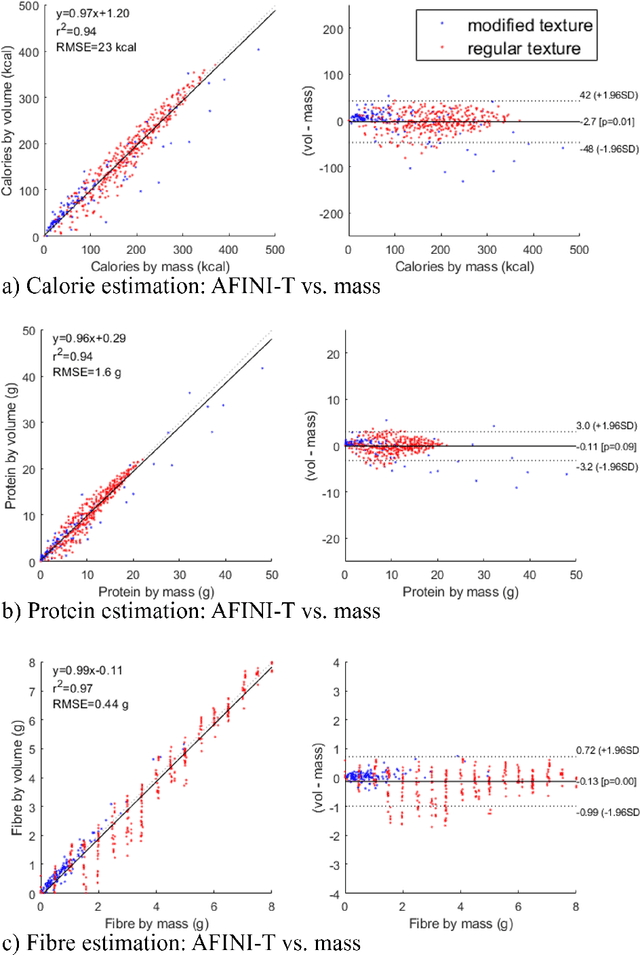

Half of long-term care (LTC) residents are malnourished increasing hospitalization, mortality, morbidity, with lower quality of life. Current tracking methods are subjective and time consuming. This paper presents the automated food imaging and nutrient intake tracking (AFINI-T) technology designed for LTC. We propose a novel convolutional autoencoder for food classification, trained on an augmented UNIMIB2016 dataset and tested on our simulated LTC food intake dataset (12 meal scenarios; up to 15 classes each; top-1 classification accuracy: 88.9%; mean intake error: -0.4 mL$\pm$36.7 mL). Nutrient intake estimation by volume was strongly linearly correlated with nutrient estimates from mass ($r^2$ 0.92 to 0.99) with good agreement between methods ($\sigma$= -2.7 to -0.01; zero within each of the limits of agreement). The AFINI-T approach is a deep-learning powered computational nutrient sensing system that may provide a novel means for more accurately and objectively tracking LTC resident food intake to support and prevent malnutrition tracking strategies.
Self-Supervised Domain Adaptation for Visual Navigation with Global Map Consistency
Oct 14, 2021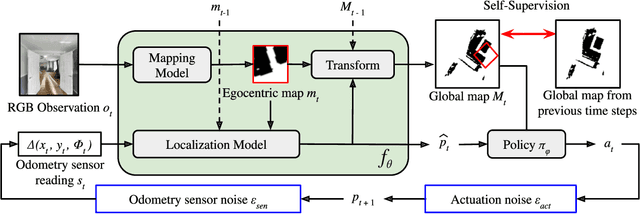
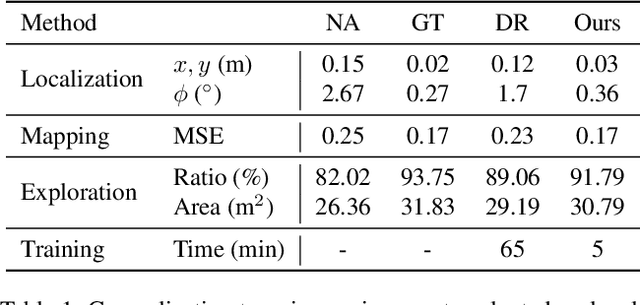
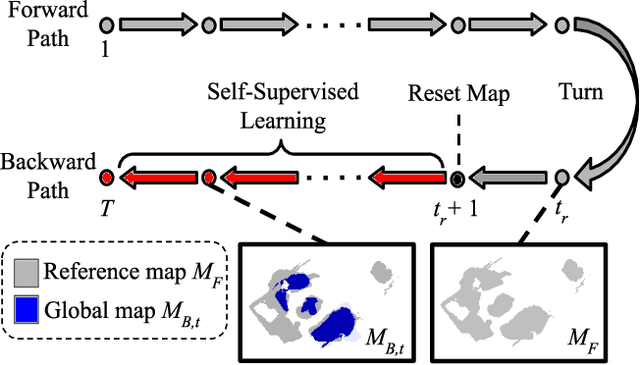
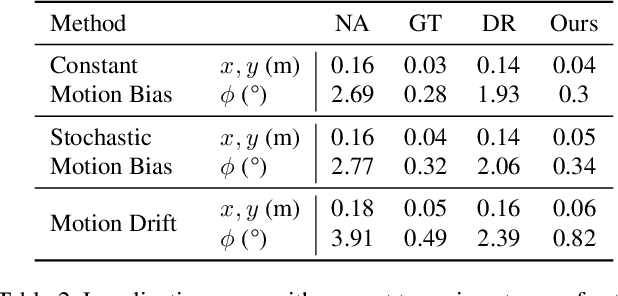
We propose a light-weight, self-supervised adaptation for a visual navigation agent to generalize to unseen environment. Given an embodied agent trained in a noiseless environment, our objective is to transfer the agent to a noisy environment where actuation and odometry sensor noise is present. Our method encourages the agent to maximize the consistency between the global maps generated at different time steps in a round-trip trajectory. The proposed task is completely self-supervised, not requiring any supervision from ground-truth pose data or explicit noise model. In addition, optimization of the task objective is extremely light-weight, as training terminates within a few minutes on a commodity GPU. Our experiments show that the proposed task helps the agent to successfully transfer to new, noisy environments. The transferred agent exhibits improved localization and mapping accuracy, further leading to enhanced performance in downstream visual navigation tasks. Moreover, we demonstrate test-time adaptation with our self-supervised task to show its potential applicability in real-world deployment.
Multi-concept adversarial attacks
Oct 19, 2021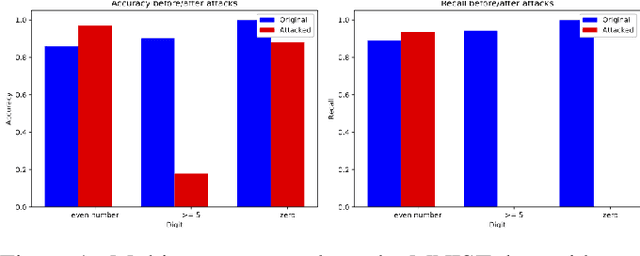
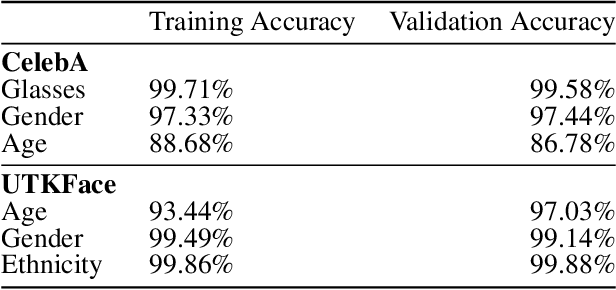

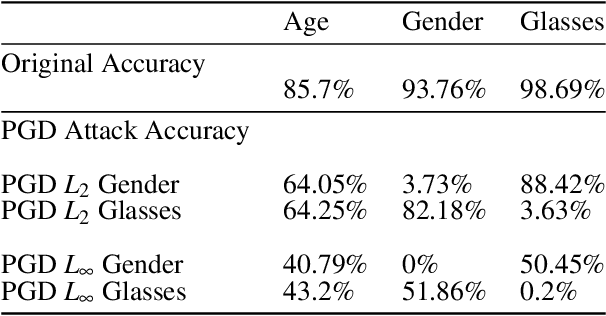
As machine learning (ML) techniques are being increasingly used in many applications, their vulnerability to adversarial attacks becomes well-known. Test time attacks, usually launched by adding adversarial noise to test instances, have been shown effective against the deployed ML models. In practice, one test input may be leveraged by different ML models. Test time attacks targeting a single ML model often neglect their impact on other ML models. In this work, we empirically demonstrate that naively attacking the classifier learning one concept may negatively impact classifiers trained to learn other concepts. For example, for the online image classification scenario, when the Gender classifier is under attack, the (wearing) Glasses classifier is simultaneously attacked with the accuracy dropped from 98.69 to 88.42. This raises an interesting question: is it possible to attack one set of classifiers without impacting the other set that uses the same test instance? Answers to the above research question have interesting implications for protecting privacy against ML model misuse. Attacking ML models that pose unnecessary risks of privacy invasion can be an important tool for protecting individuals from harmful privacy exploitation. In this paper, we address the above research question by developing novel attack techniques that can simultaneously attack one set of ML models while preserving the accuracy of the other. In the case of linear classifiers, we provide a theoretical framework for finding an optimal solution to generate such adversarial examples. Using this theoretical framework, we develop a multi-concept attack strategy in the context of deep learning. Our results demonstrate that our techniques can successfully attack the target classes while protecting the protected classes in many different settings, which is not possible with the existing test-time attack-single strategies.
An AI-based Solution for Enhancing Delivery of Digital Learning for Future Teachers
Nov 09, 2021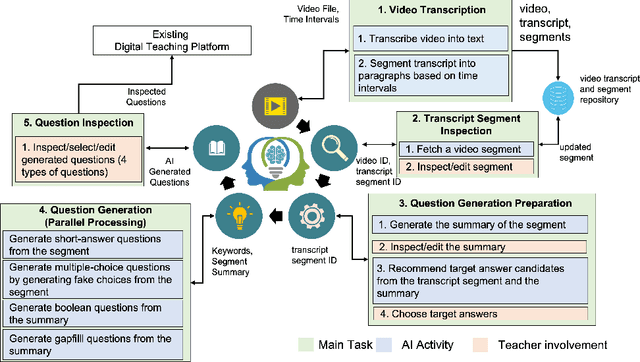

There has been a recent and rapid shift to digital learning hastened by the pandemic but also influenced by ubiquitous availability of digital tools and platforms now, making digital learning ever more accessible. An integral and one of the most difficult part of scaling digital learning and teaching is to be able to assess learner's knowledge and competency. An educator can record a lecture or create digital content that can be delivered to thousands of learners but assessing learners is extremely time consuming. In the paper, we propose an Artificial Intelligence (AI)-based solution namely VidVersityQG for generating questions automatically from pre-recorded video lectures. The solution can automatically generate different types of assessment questions (including short answer, multiple choice, true/false and fill in the blank questions) based on contextual and semantic information inferred from the videos. The proposed solution takes a human-centred approach, wherein teachers are provided the ability to modify/edit any AI generated questions. This approach encourages trust and engagement of teachers in the use and implementation of AI in education. The AI-based solution was evaluated for its accuracy in generating questions by 7 experienced teaching professionals and 117 education videos from multiple domains provided to us by our industry partner VidVersity. VidVersityQG solution showed promising results in generating high-quality questions automatically from video thereby significantly reducing the time and effort for educators in manual question generation.
AquaVis: A Perception-Aware Autonomous Navigation Framework for Underwater Vehicles
Oct 04, 2021
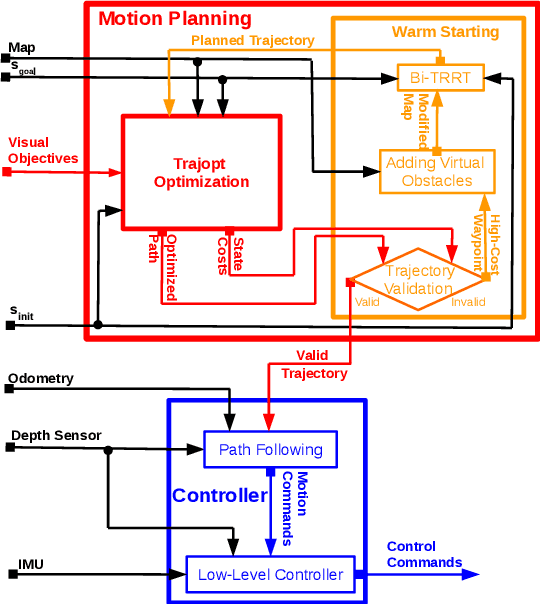
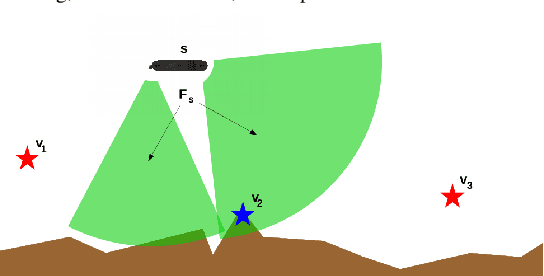
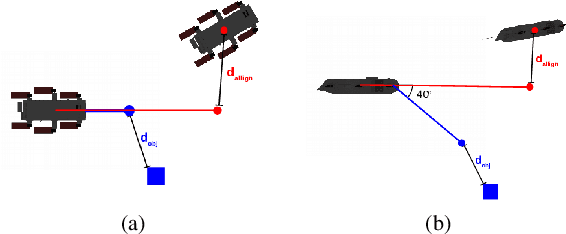
Visual monitoring operations underwater require both observing the objects of interest in close-proximity, and tracking the few feature-rich areas necessary for state estimation.This paper introduces the first navigation framework, called AquaVis, that produces on-line visibility-aware motion plans that enable Autonomous Underwater Vehicles (AUVs) to track multiple visual objectives with an arbitrary camera configuration in real-time. Using the proposed pipeline, AUVs can efficiently move in 3D, reach their goals while avoiding obstacles safely, and maximizing the visibility of multiple objectives along the path within a specified proximity. The method is sufficiently fast to be executed in real-time and is suitable for single or multiple camera configurations. Experimental results show the significant improvement on tracking multiple automatically-extracted points of interest, with low computational overhead and fast re-planning times
Cloud-Based Dynamic Programming for an Electric City Bus Energy Management Considering Real-Time Passenger Load Prediction
Oct 28, 2020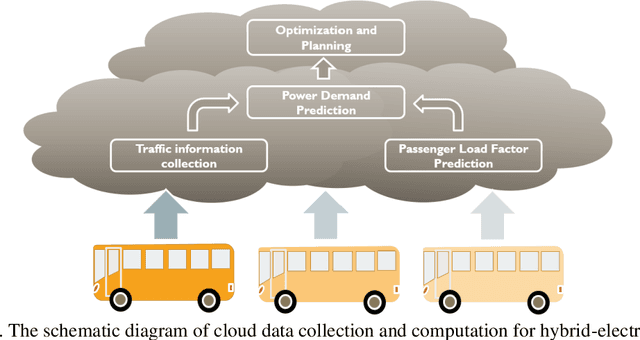
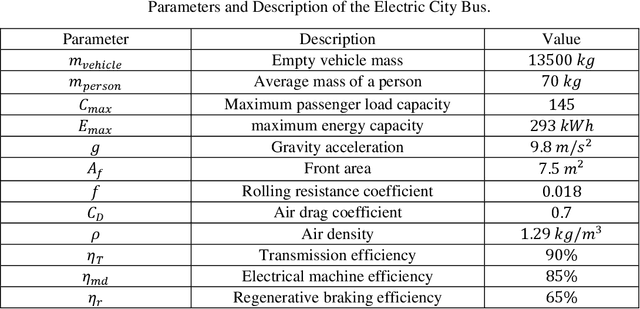
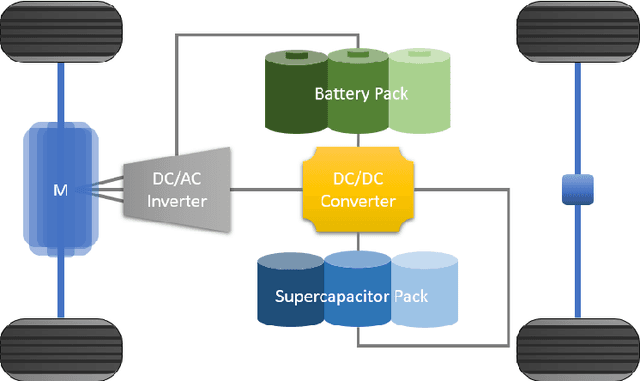

Electric city bus gains popularity in recent years for its low greenhouse gas emission, low noise level, etc. Different from a passenger car, the weight of a city bus varies significantly with different amounts of onboard passengers, which is not well studied in existing literature. This study proposes a passenger load prediction model using day-of-week, time-of-day, weather, temperatures, wind levels, and holiday information as inputs. The average model, Regression Tree, Gradient Boost Decision Tree, and Neural Networks models are compared in the passenger load prediction. The Gradient Boost Decision Tree model is selected due to its best accuracy and high stability. Given the predicted passenger load, dynamic programming algorithm determines the optimal power demand for supercapacitor and battery by optimizing the battery aging and energy usage in the cloud. Then rule extraction is conducted on dynamic programming results, and the rule is real-time loaded to onboard controllers of vehicles. The proposed cloud-based dynamic programming and rule extraction framework with the passenger load prediction shows 4% and 11% fewer bus operating costs in off-peak and peak hours, respectively. The operating cost by the proposed framework is less than 1% shy of the dynamic programming with the true passenger load information.
EEG functional connectivity and deep learning for automatic diagnosis of brain disorders: Alzheimer's disease and schizophrenia
Oct 07, 2021
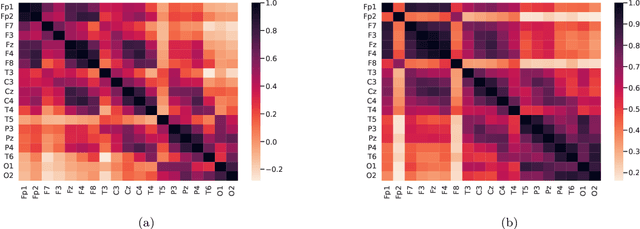
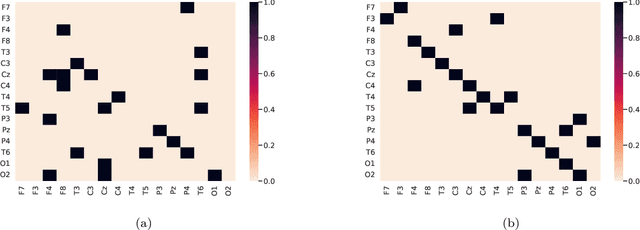
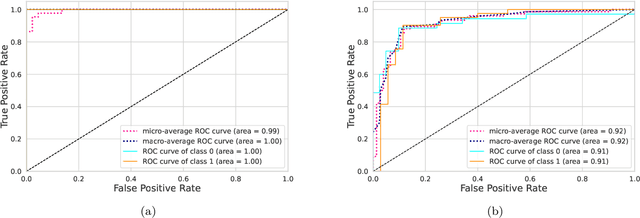
Mental disorders are among the leading causes of disability worldwide. The first step in treating these conditions is to obtain an accurate diagnosis, but the absence of established clinical tests makes this task challenging. Machine learning algorithms can provide a possible solution to this problem, as we describe in this work. We present a method for the automatic diagnosis of mental disorders based on the matrix of connections obtained from EEG time series and deep learning. We show that our approach can classify patients with Alzheimer's disease and schizophrenia with a high level of accuracy. The comparison with the traditional cases, that use raw EEG time series, shows that our method provides the highest precision. Therefore, the application of deep neural networks on data from brain connections is a very promising method to the diagnosis of neurological disorders.
Right on Time: Multi-Temporal Convolutions for Human Action Recognition in Videos
Nov 08, 2020The variations in the temporal performance of human actions observed in videos present challenges for their extraction using fixed-sized convolution kernels in CNNs. We present an approach that is more flexible in terms of processing the input at multiple timescales. We introduce Multi-Temporal networks that model spatio-temporal patterns of different temporal durations at each layer. To this end, they employ novel 3D convolution (MTConv) blocks that consist of a short stream for local space-time features and a long stream for features spanning across longer times. By aligning features of each stream with respect to the global motion patterns using recurrent cells, we can discover temporally coherent spatio-temporal features with varying durations. We further introduce sub-streams within each of the block pathways to reduce the computation requirements. The proposed MTNet architectures outperform state-of-the-art 3D-CNNs on five action recognition benchmark datasets. Notably, we achieve at 87.22% top-1 accuracy on HACS, and 58.39% top-1 at Kinectics-700. We further demonstrate the favorable computational requirements. Using sub-streams, we can further achieve a drastic reduction in parameters (~60%) and GLOPs (~74%). Experiments using transfer learning finally verify the generalization capabilities of the multi-temporal features
On Slowly-varying Non-stationary Bandits
Oct 25, 2021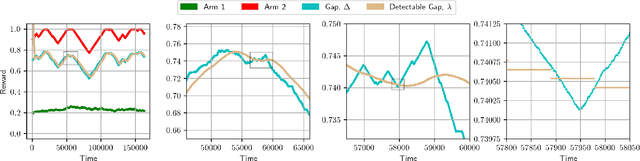
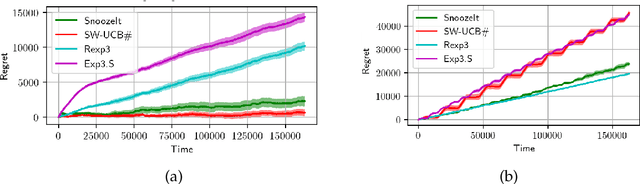
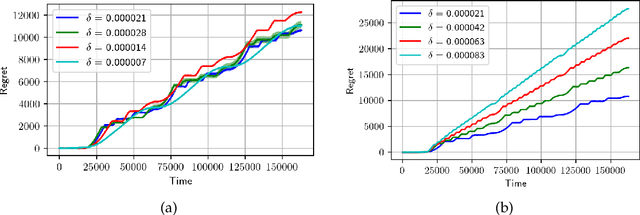
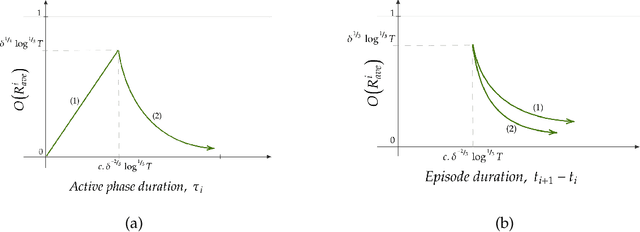
We consider minimisation of dynamic regret in non-stationary bandits with a slowly varying property. Namely, we assume that arms' rewards are stochastic and independent over time, but that the absolute difference between the expected rewards of any arm at any two consecutive time-steps is at most a drift limit $\delta > 0$. For this setting that has not received enough attention in the past, we give a new algorithm which extends naturally the well-known Successive Elimination algorithm to the non-stationary bandit setting. We establish the first instance-dependent regret upper bound for slowly varying non-stationary bandits. The analysis in turn relies on a novel characterization of the instance as a detectable gap profile that depends on the expected arm reward differences. We also provide the first minimax regret lower bound for this problem, enabling us to show that our algorithm is essentially minimax optimal. Also, this lower bound we obtain matches that of the more general total variation-budgeted bandits problem, establishing that the seemingly easier former problem is at least as hard as the more general latter problem in the minimax sense. We complement our theoretical results with experimental illustrations.