 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Probabilistic Time of Arrival Localization
Oct 15, 2019
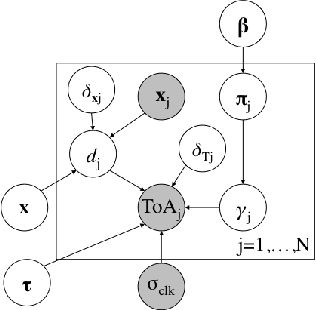

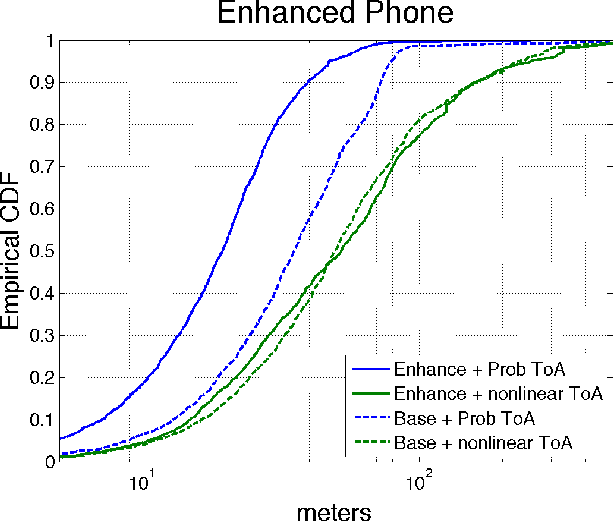
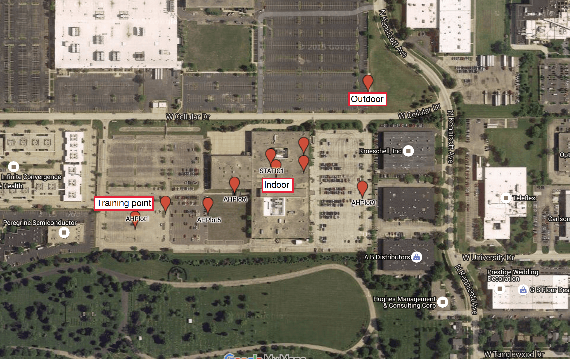
In this paper, we take a new approach for time of arrival geo-localization. We show that the main sources of error in metropolitan areas are due to environmental imperfections that bias our solutions, and that we can rely on a probabilistic model to learn and compensate for them. The resulting localization error is validated using measurements from a live LTE cellular network to be less than 10 meters, representing an order-of-magnitude improvement.
The Mirror Langevin Algorithm Converges with Vanishing Bias
Sep 24, 2021The technique of modifying the geometry of a problem from Euclidean to Hessian metric has proved to be quite effective in optimization, and has been the subject of study for sampling. The Mirror Langevin Diffusion (MLD) is a sampling analogue of mirror flow in continuous time, and it has nice convergence properties under log-Sobolev or Poincare inequalities relative to the Hessian metric, as shown by Chewi et al. (2020). In discrete time, a simple discretization of MLD is the Mirror Langevin Algorithm (MLA) studied by Zhang et al. (2020), who showed a biased convergence bound with a non-vanishing bias term (does not go to zero as step size goes to zero). This raised the question of whether we need a better analysis or a better discretization to achieve a vanishing bias. Here we study the basic Mirror Langevin Algorithm and show it indeed has a vanishing bias. We apply mean-square analysis based on Li et al. (2019) and Li et al. (2021) to show the mixing time bound for MLA under the modified self-concordance condition introduced by Zhang et al. (2020).
Improved Regret Analysis for Variance-Adaptive Linear Bandits and Horizon-Free Linear Mixture MDPs
Nov 05, 2021In online learning problems, exploiting low variance plays an important role in obtaining tight performance guarantees yet is challenging because variances are often not known a priori. Recently, a considerable progress has been made by Zhang et al. (2021) where they obtain a variance-adaptive regret bound for linear bandits without knowledge of the variances and a horizon-free regret bound for linear mixture Markov decision processes (MDPs). In this paper, we present novel analyses that improve their regret bounds significantly. For linear bandits, we achieve $\tilde O(d^{1.5}\sqrt{\sum_{k}^K \sigma_k^2} + d^2)$ where $d$ is the dimension of the features, $K$ is the time horizon, and $\sigma_k^2$ is the noise variance at time step $k$, and $\tilde O$ ignores polylogarithmic dependence, which is a factor of $d^3$ improvement. For linear mixture MDPs, we achieve a horizon-free regret bound of $\tilde O(d^{1.5}\sqrt{K} + d^3)$ where $d$ is the number of base models and $K$ is the number of episodes. This is a factor of $d^3$ improvement in the leading term and $d^6$ in the lower order term. Our analysis critically relies on a novel elliptical potential `count' lemma. This lemma allows a peeling-based regret analysis, which can be of independent interest.
Deep Learning Head Model for Real-time Estimation of Entire Brain Deformation in Concussion
Oct 16, 2020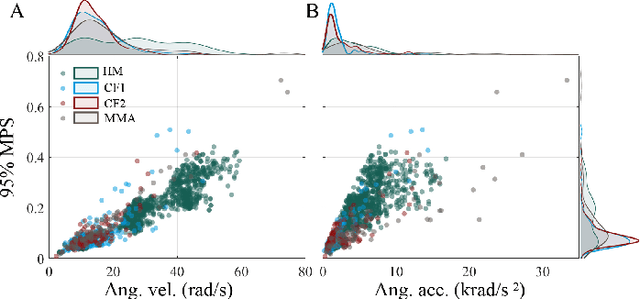

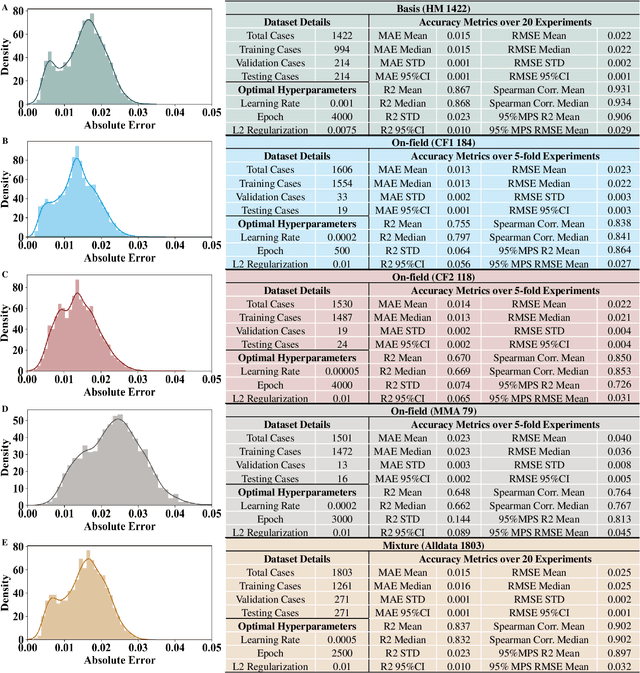
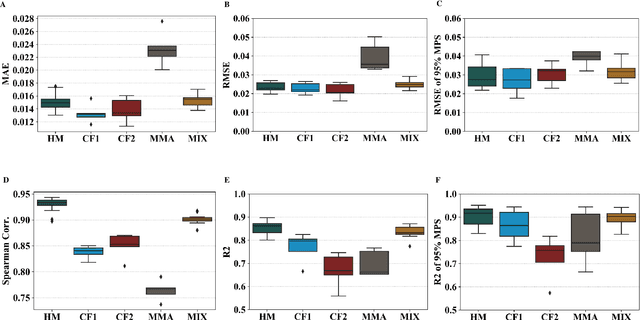
Objective: Many recent studies have suggested that brain deformation resulting from a head impact is linked to the corresponding clinical outcome, such as mild traumatic brain injury (mTBI). Even though several finite element (FE) head models have been developed and validated to calculate brain deformation based on impact kinematics, the clinical application of these FE head models is limited due to the time-consuming nature of FE simulations. This work aims to accelerate the process of brain deformation calculation and thus improve the potential for clinical applications. Methods: We propose a deep learning head model with a five-layer deep neural network and feature engineering, and trained and tested the model on 1803 total head impacts from a combination of head model simulations and on-field college football and mixed martial arts impacts. Results: The proposed deep learning head model can calculate the maximum principal strain for every element in the entire brain in less than 0.001s (with an average root mean squared error of 0.025, and with a standard deviation of 0.002 over twenty repeats with random data partition and model initialization). The contributions of various features to the predictive power of the model were investigated, and it was noted that the features based on angular acceleration were found to be more predictive than the features based on angular velocity. Conclusion: Trained using the dataset of 1803 head impacts, this model can be applied to various sports in the calculation of brain strain with accuracy, and its applicability can even further be extended by incorporating data from other types of head impacts. Significance: In addition to the potential clinical application in real-time brain deformation monitoring, this model will help researchers estimate the brain strain from a large number of head impacts more efficiently than using FE models.
Contrastive Neural Processes for Self-Supervised Learning
Oct 31, 2021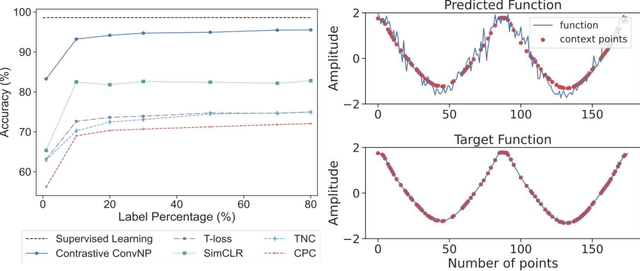
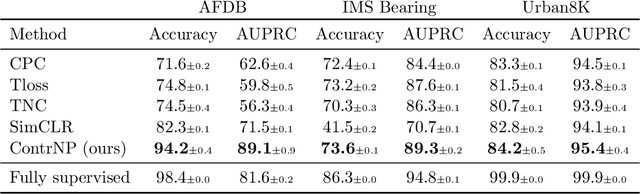
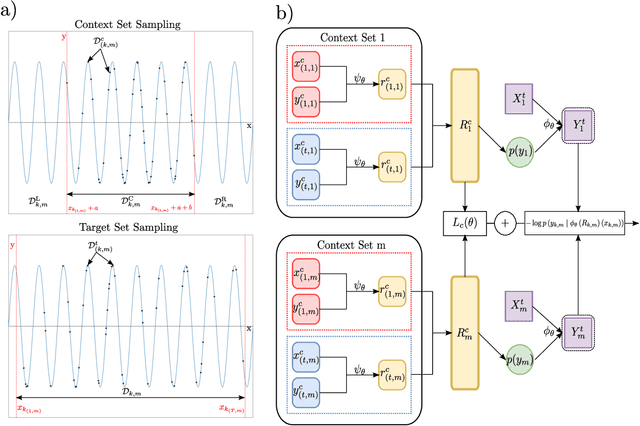
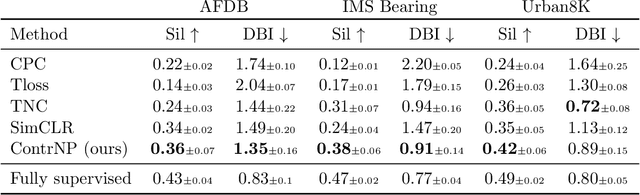
Recent contrastive methods show significant improvement in self-supervised learning in several domains. In particular, contrastive methods are most effective where data augmentation can be easily constructed e.g. in computer vision. However, they are less successful in domains without established data transformations such as time series data. In this paper, we propose a novel self-supervised learning framework that combines contrastive learning with neural processes. It relies on recent advances in neural processes to perform time series forecasting. This allows to generate augmented versions of data by employing a set of various sampling functions and, hence, avoid manually designed augmentations. We extend conventional neural processes and propose a new contrastive loss to learn times series representations in a self-supervised setup. Therefore, unlike previous self-supervised methods, our augmentation pipeline is task-agnostic, enabling our method to perform well across various applications. In particular, a ResNet with a linear classifier trained using our approach is able to outperform state-of-the-art techniques across industrial, medical and audio datasets improving accuracy over 10% in ECG periodic data. We further demonstrate that our self-supervised representations are more efficient in the latent space, improving multiple clustering indexes and that fine-tuning our method on 10% of labels achieves results competitive to fully-supervised learning.
Improving the Segmentation of Pediatric Low-Grade Gliomas through Multitask Learning
Nov 29, 2021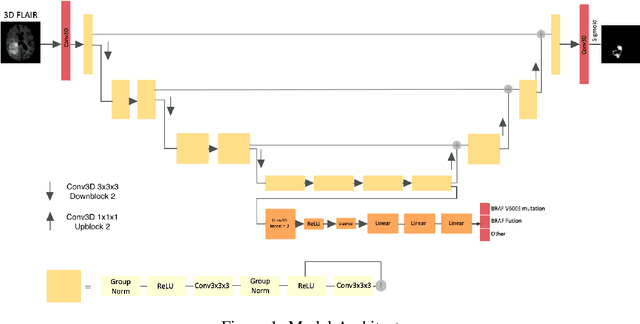
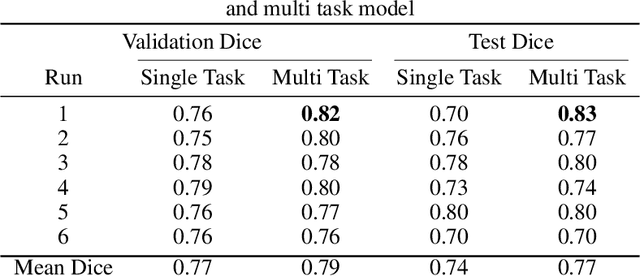
Brain tumor segmentation is a critical task for tumor volumetric analyses and AI algorithms. However, it is a time-consuming process and requires neuroradiology expertise. While there has been extensive research focused on optimizing brain tumor segmentation in the adult population, studies on AI guided pediatric tumor segmentation are scarce. Furthermore, MRI signal characteristics of pediatric and adult brain tumors differ, necessitating the development of segmentation algorithms specifically designed for pediatric brain tumors. We developed a segmentation model trained on magnetic resonance imaging (MRI) of pediatric patients with low-grade gliomas (pLGGs) from The Hospital for Sick Children (Toronto, Ontario, Canada). The proposed model utilizes deep Multitask Learning (dMTL) by adding tumor's genetic alteration classifier as an auxiliary task to the main network, ultimately improving the accuracy of the segmentation results.
Reduced, Reused and Recycled: The Life of a Dataset in Machine Learning Research
Dec 03, 2021
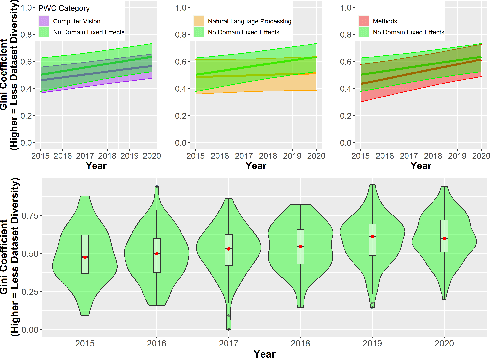
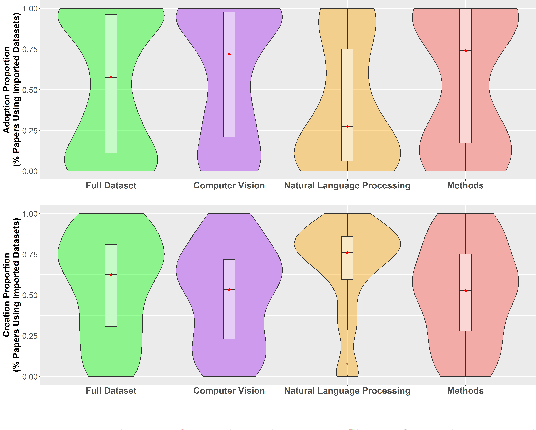
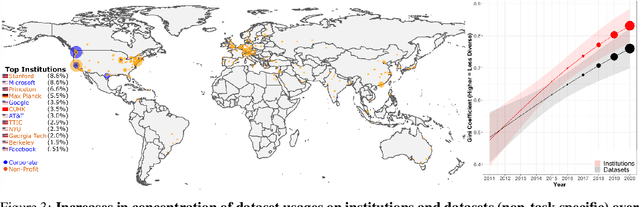
Benchmark datasets play a central role in the organization of machine learning research. They coordinate researchers around shared research problems and serve as a measure of progress towards shared goals. Despite the foundational role of benchmarking practices in this field, relatively little attention has been paid to the dynamics of benchmark dataset use and reuse, within or across machine learning subcommunities. In this paper, we dig into these dynamics. We study how dataset usage patterns differ across machine learning subcommunities and across time from 2015-2020. We find increasing concentration on fewer and fewer datasets within task communities, significant adoption of datasets from other tasks, and concentration across the field on datasets that have been introduced by researchers situated within a small number of elite institutions. Our results have implications for scientific evaluation, AI ethics, and equity/access within the field.
Distribution Shift in Airline Customer Behavior during COVID-19
Nov 29, 2021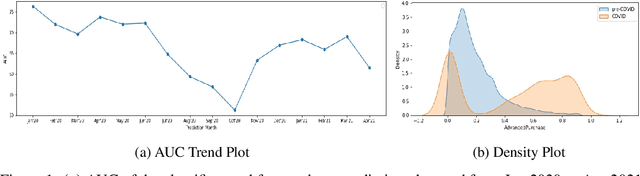

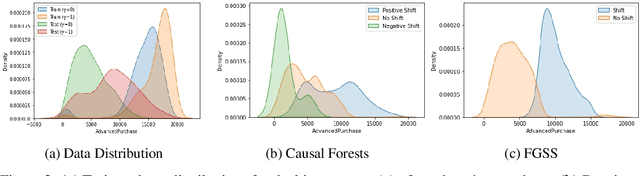
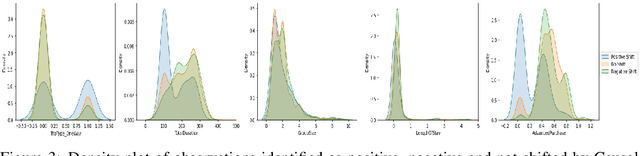
Traditional AI approaches in customized (personalized) contextual pricing applications assume that the data distribution at the time of online pricing is similar to that observed during training. However, this assumption may be violated in practice because of the dynamic nature of customer buying patterns, particularly due to unanticipated system shocks such as COVID-19. We study the changes in customer behavior for a major airline during the COVID-19 pandemic by framing it as a covariate shift and concept drift detection problem. We identify which customers changed their travel and purchase behavior and the attributes affecting that change using (i) Fast Generalized Subset Scanning and (ii) Causal Forests. In our experiments with simulated and real-world data, we present how these two techniques can be used through qualitative analysis.
DeepGuard: A Framework for Safeguarding Autonomous Driving Systems from Inconsistent Behavior
Nov 18, 2021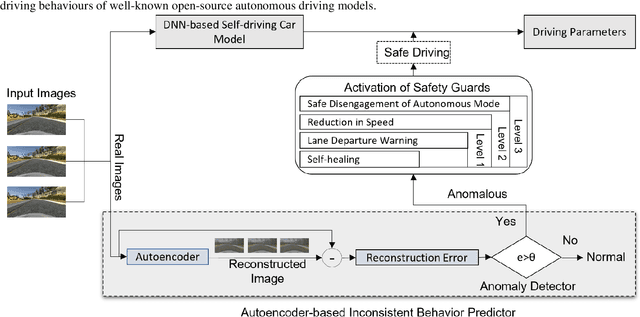
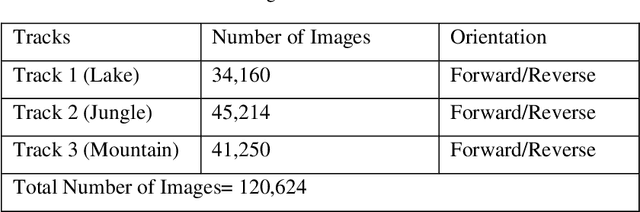

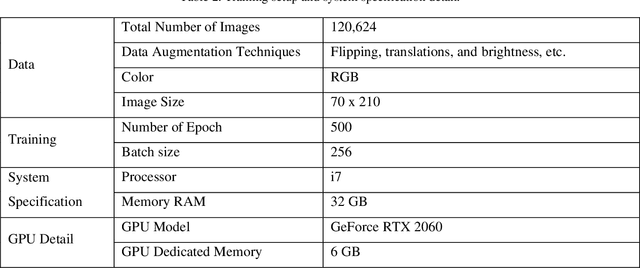
The deep neural networks (DNNs)based autonomous driving systems (ADSs) are expected to reduce road accidents and improve safety in the transportation domain as it removes the factor of human error from driving tasks. The DNN based ADS sometimes may exhibit erroneous or unexpected behaviors due to unexpected driving conditions which may cause accidents. It is not possible to generalize the DNN model performance for all driving conditions. Therefore, the driving conditions that were not considered during the training of the ADS may lead to unpredictable consequences for the safety of autonomous vehicles. This study proposes an autoencoder and time series analysis based anomaly detection system to prevent the safety critical inconsistent behavior of autonomous vehicles at runtime. Our approach called DeepGuard consists of two components. The first component, the inconsistent behavior predictor, is based on an autoencoder and time series analysis to reconstruct the driving scenarios. Based on reconstruction error and threshold it determines the normal and unexpected driving scenarios and predicts potential inconsistent behavior. The second component provides on the fly safety guards, that is, it automatically activates healing strategies to prevent inconsistencies in the behavior. We evaluated the performance of DeepGuard in predicting the injected anomalous driving scenarios using already available open sourced DNN based ADSs in the Udacity simulator. Our simulation results show that the best variant of DeepGuard can predict up to 93 percent on the CHAUFFEUR ADS, 83 percent on DAVE2 ADS, and 80 percent of inconsistent behavior on the EPOCH ADS model, outperforming SELFORACLE and DeepRoad. Overall, DeepGuard can prevent up to 89 percent of all predicted inconsistent behaviors of ADS by executing predefined safety guards.
Complexity assessments for decidable fragments of Set Theory. III: A quadratic reduction of constraints over nested sets to Boolean formulae
Dec 09, 2021
As a contribution to quantitative set-theoretic inferencing, a translation is proposed of conjunctions of literals of the forms $x=y\setminus z$, $x \neq y\setminus z$, and $z =\{x\}$, where $x,y,z$ stand for variables ranging over the von Neumann universe of sets, into unquantified Boolean formulae of a rather simple conjunctive normal form. The formulae in the target language involve variables ranging over a Boolean ring of sets, along with a difference operator and relators designating equality, non-disjointness and inclusion. Moreover, the result of each translation is a conjunction of literals of the forms $x=y\setminus z$, $x\neq y\setminus z$ and of implications whose antecedents are isolated literals and whose consequents are either inclusions (strict or non-strict) between variables, or equalities between variables. Besides reflecting a simple and natural semantics, which ensures satisfiability-preservation, the proposed translation has quadratic algorithmic time-complexity, and bridges two languages both of which are known to have an NP-complete satisfiability problem.