 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
HAD-Net: Hybrid Attention-based Diffusion Network for Glucose Level Forecast
Nov 14, 2021
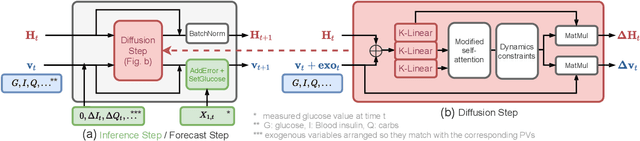
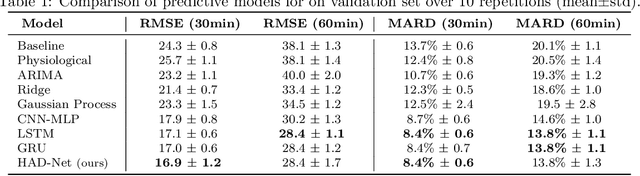
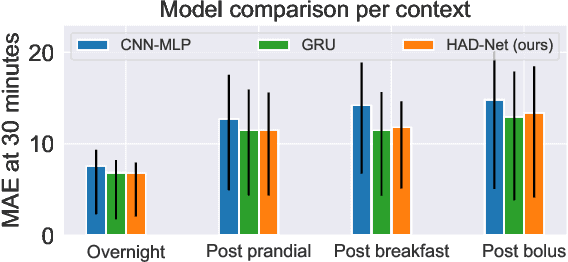
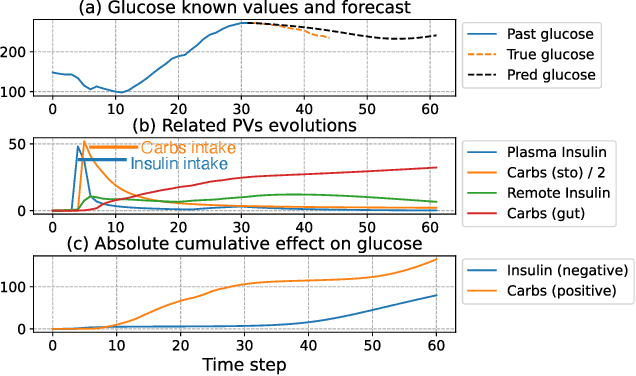
Data-driven models for glucose level forecast often do not provide meaningful insights despite accurate predictions. Yet, context understanding in medicine is crucial, in particular for diabetes management. In this paper, we introduce HAD-Net: a hybrid model that distills knowledge into a deep neural network from physiological models. It models glucose, insulin and carbohydrates diffusion through a biologically inspired deep learning architecture tailored with a recurrent attention network constrained by ODE expert models. We apply HAD-Net for glucose level forecast of patients with type-2 diabetes. It achieves competitive performances while providing plausible measurements of insulin and carbohydrates diffusion over time.
Adaptive Bayesian Sum of Trees Model for Covariate Dependent Spectral Analysis
Sep 29, 2021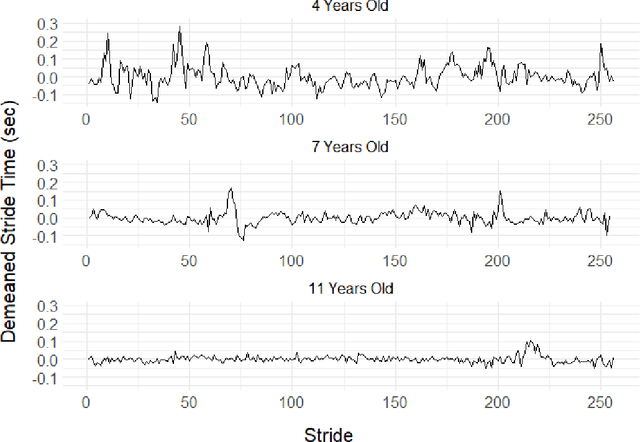
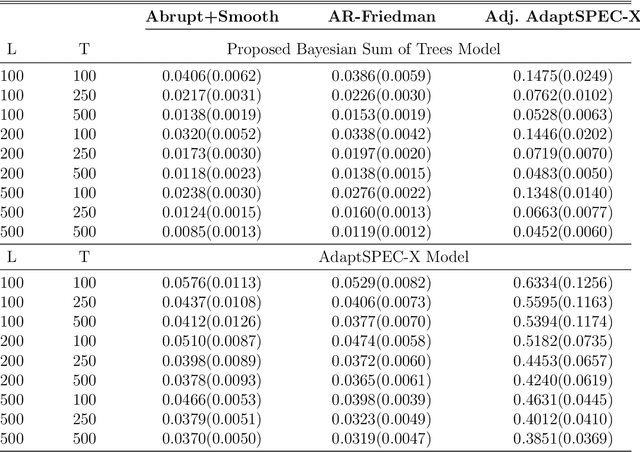
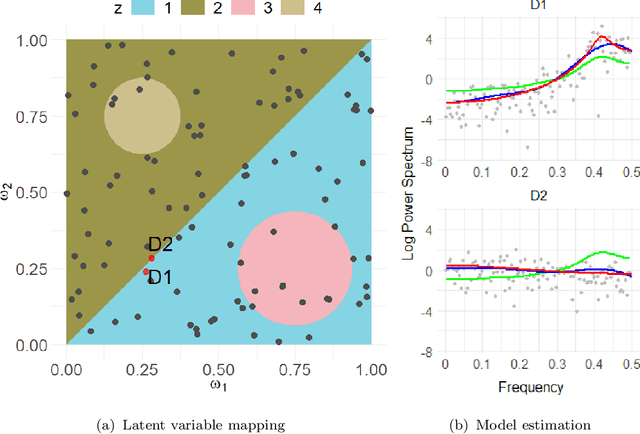
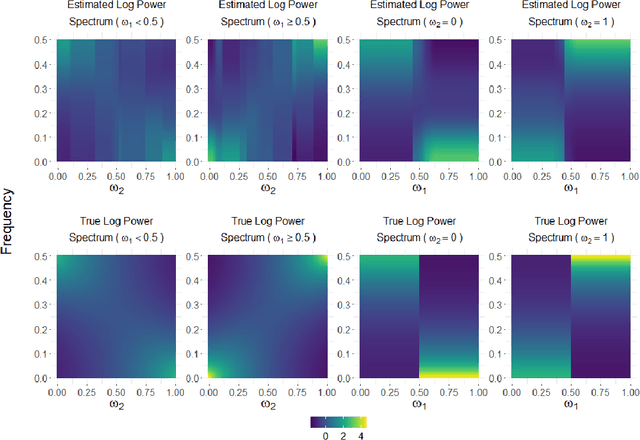
This article introduces a flexible and adaptive nonparametric method for estimating the association between multiple covariates and power spectra of multiple time series. The proposed approach uses a Bayesian sum of trees model to capture complex dependencies and interactions between covariates and the power spectrum, which are often observed in studies of biomedical time series. Local power spectra corresponding to terminal nodes within trees are estimated nonparametrically using Bayesian penalized linear splines. The trees are considered to be random and fit using a Bayesian backfitting Markov chain Monte Carlo (MCMC) algorithm that sequentially considers tree modifications via reversible-jump MCMC techniques. For high-dimensional covariates, a sparsity-inducing Dirichlet hyperprior on tree splitting proportions is considered, which provides sparse estimation of covariate effects and efficient variable selection. By averaging over the posterior distribution of trees, the proposed method can recover both smooth and abrupt changes in the power spectrum across multiple covariates. Empirical performance is evaluated via simulations to demonstrate the proposed method's ability to accurately recover complex relationships and interactions. The proposed methodology is used to study gait maturation in young children by evaluating age-related changes in power spectra of stride interval time series in the presence of other covariates.
Cyberattack Detection in Large-Scale Smart Grids using Chebyshev Graph Convolutional Networks
Dec 25, 2021
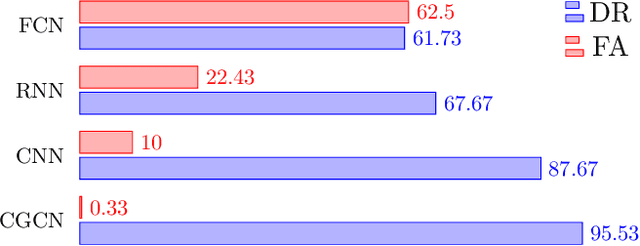
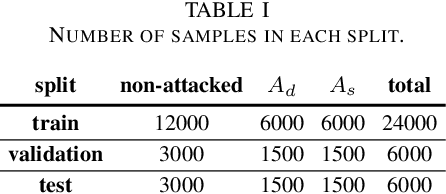
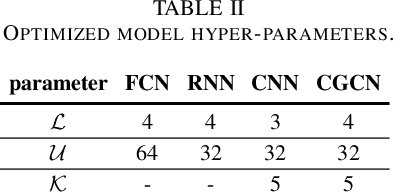
As a highly complex and integrated cyber-physical system, modern power grids are exposed to cyberattacks. False data injection attacks (FDIAs), specifically, represent a major class of cyber threats to smart grids by targeting the measurement data's integrity. Although various solutions have been proposed to detect those cyberattacks, the vast majority of the works have ignored the inherent graph structure of the power grid measurements and validated their detectors only for small test systems with less than a few hundred buses. To better exploit the spatial correlations of smart grid measurements, this paper proposes a deep learning model for cyberattack detection in large-scale AC power grids using Chebyshev Graph Convolutional Networks (CGCN). By reducing the complexity of spectral graph filters and making them localized, CGCN provides a fast and efficient convolution operation to model the graph structural smart grid data. We numerically verify that the proposed CGCN based detector surpasses the state-of-the-art model by 7.86 in detection rate and 9.67 in false alarm rate for a large-scale power grid with 2848 buses. It is notable that the proposed approach detects cyberattacks under 4 milliseconds for a 2848-bus system, which makes it a good candidate for real-time detection of cyberattacks in large systems.
Reduced, Reused and Recycled: The Life of a Dataset in Machine Learning Research
Dec 03, 2021
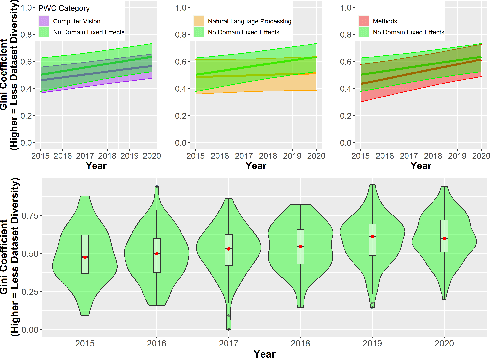
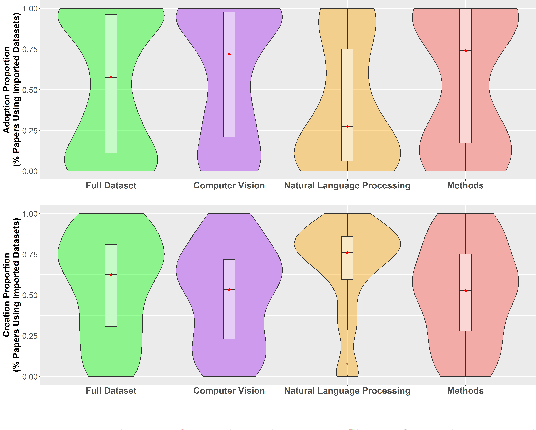
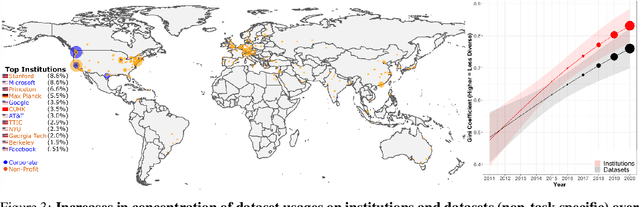
Benchmark datasets play a central role in the organization of machine learning research. They coordinate researchers around shared research problems and serve as a measure of progress towards shared goals. Despite the foundational role of benchmarking practices in this field, relatively little attention has been paid to the dynamics of benchmark dataset use and reuse, within or across machine learning subcommunities. In this paper, we dig into these dynamics. We study how dataset usage patterns differ across machine learning subcommunities and across time from 2015-2020. We find increasing concentration on fewer and fewer datasets within task communities, significant adoption of datasets from other tasks, and concentration across the field on datasets that have been introduced by researchers situated within a small number of elite institutions. Our results have implications for scientific evaluation, AI ethics, and equity/access within the field.
Complexity assessments for decidable fragments of Set Theory. III: A quadratic reduction of constraints over nested sets to Boolean formulae
Dec 09, 2021
As a contribution to quantitative set-theoretic inferencing, a translation is proposed of conjunctions of literals of the forms $x=y\setminus z$, $x \neq y\setminus z$, and $z =\{x\}$, where $x,y,z$ stand for variables ranging over the von Neumann universe of sets, into unquantified Boolean formulae of a rather simple conjunctive normal form. The formulae in the target language involve variables ranging over a Boolean ring of sets, along with a difference operator and relators designating equality, non-disjointness and inclusion. Moreover, the result of each translation is a conjunction of literals of the forms $x=y\setminus z$, $x\neq y\setminus z$ and of implications whose antecedents are isolated literals and whose consequents are either inclusions (strict or non-strict) between variables, or equalities between variables. Besides reflecting a simple and natural semantics, which ensures satisfiability-preservation, the proposed translation has quadratic algorithmic time-complexity, and bridges two languages both of which are known to have an NP-complete satisfiability problem.
Improving the Segmentation of Pediatric Low-Grade Gliomas through Multitask Learning
Nov 29, 2021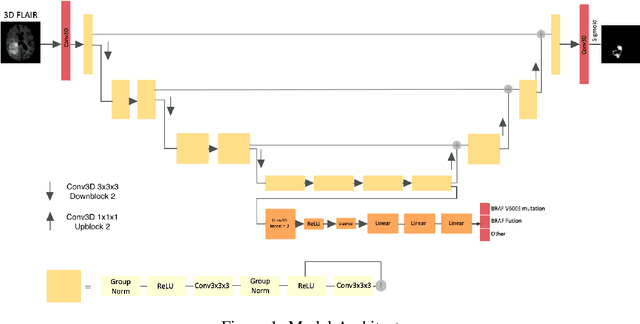
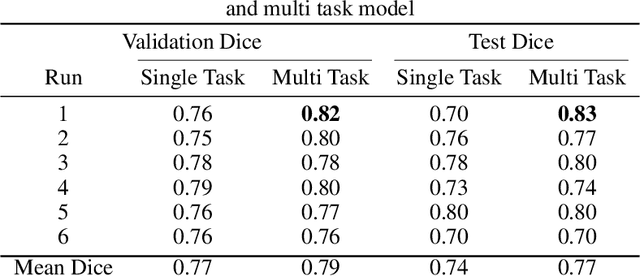
Brain tumor segmentation is a critical task for tumor volumetric analyses and AI algorithms. However, it is a time-consuming process and requires neuroradiology expertise. While there has been extensive research focused on optimizing brain tumor segmentation in the adult population, studies on AI guided pediatric tumor segmentation are scarce. Furthermore, MRI signal characteristics of pediatric and adult brain tumors differ, necessitating the development of segmentation algorithms specifically designed for pediatric brain tumors. We developed a segmentation model trained on magnetic resonance imaging (MRI) of pediatric patients with low-grade gliomas (pLGGs) from The Hospital for Sick Children (Toronto, Ontario, Canada). The proposed model utilizes deep Multitask Learning (dMTL) by adding tumor's genetic alteration classifier as an auxiliary task to the main network, ultimately improving the accuracy of the segmentation results.
Are E2E ASR models ready for an industrial usage?
Dec 09, 2021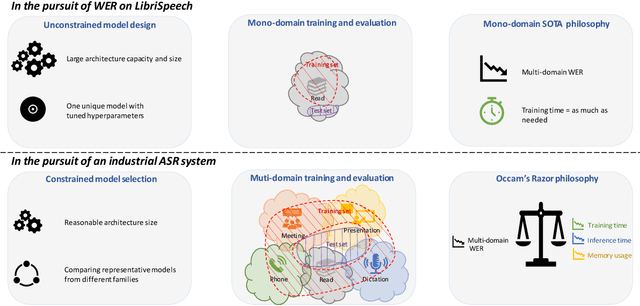
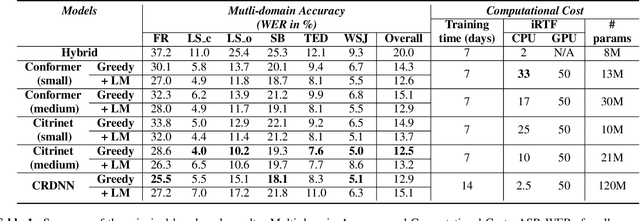
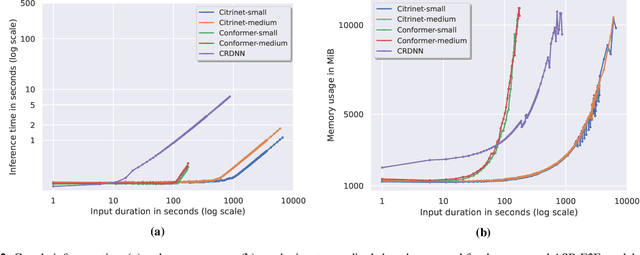
The Automated Speech Recognition (ASR) community experiences a major turning point with the rise of the fully-neural (End-to-End, E2E) approaches. At the same time, the conventional hybrid model remains the standard choice for the practical usage of ASR. According to previous studies, the adoption of E2E ASR in real-world applications was hindered by two main limitations: their ability to generalize on unseen domains and their high operational cost. In this paper, we investigate both above-mentioned drawbacks by performing a comprehensive multi-domain benchmark of several contemporary E2E models and a hybrid baseline. Our experiments demonstrate that E2E models are viable alternatives for the hybrid approach, and even outperform the baseline both in accuracy and in operational efficiency. As a result, our study shows that the generalization and complexity issues are no longer the major obstacle for industrial integration, and draws the community's attention to other potential limitations of the E2E approaches in some specific use-cases.
Distribution Shift in Airline Customer Behavior during COVID-19
Nov 29, 2021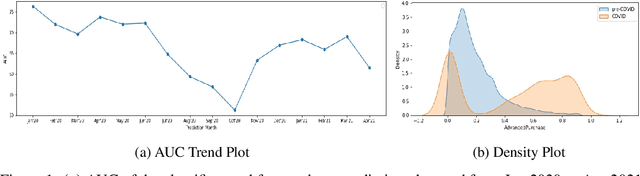

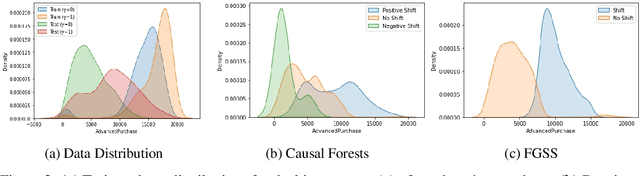
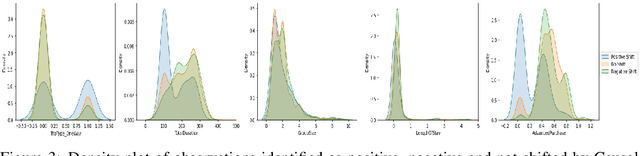
Traditional AI approaches in customized (personalized) contextual pricing applications assume that the data distribution at the time of online pricing is similar to that observed during training. However, this assumption may be violated in practice because of the dynamic nature of customer buying patterns, particularly due to unanticipated system shocks such as COVID-19. We study the changes in customer behavior for a major airline during the COVID-19 pandemic by framing it as a covariate shift and concept drift detection problem. We identify which customers changed their travel and purchase behavior and the attributes affecting that change using (i) Fast Generalized Subset Scanning and (ii) Causal Forests. In our experiments with simulated and real-world data, we present how these two techniques can be used through qualitative analysis.
Improved Regret Analysis for Variance-Adaptive Linear Bandits and Horizon-Free Linear Mixture MDPs
Nov 05, 2021In online learning problems, exploiting low variance plays an important role in obtaining tight performance guarantees yet is challenging because variances are often not known a priori. Recently, a considerable progress has been made by Zhang et al. (2021) where they obtain a variance-adaptive regret bound for linear bandits without knowledge of the variances and a horizon-free regret bound for linear mixture Markov decision processes (MDPs). In this paper, we present novel analyses that improve their regret bounds significantly. For linear bandits, we achieve $\tilde O(d^{1.5}\sqrt{\sum_{k}^K \sigma_k^2} + d^2)$ where $d$ is the dimension of the features, $K$ is the time horizon, and $\sigma_k^2$ is the noise variance at time step $k$, and $\tilde O$ ignores polylogarithmic dependence, which is a factor of $d^3$ improvement. For linear mixture MDPs, we achieve a horizon-free regret bound of $\tilde O(d^{1.5}\sqrt{K} + d^3)$ where $d$ is the number of base models and $K$ is the number of episodes. This is a factor of $d^3$ improvement in the leading term and $d^6$ in the lower order term. Our analysis critically relies on a novel elliptical potential `count' lemma. This lemma allows a peeling-based regret analysis, which can be of independent interest.
A Python Framework for Fast Modelling and Simulation of Cellular Nonlinear Networks and other Finite-difference Time-domain Systems
Feb 20, 2021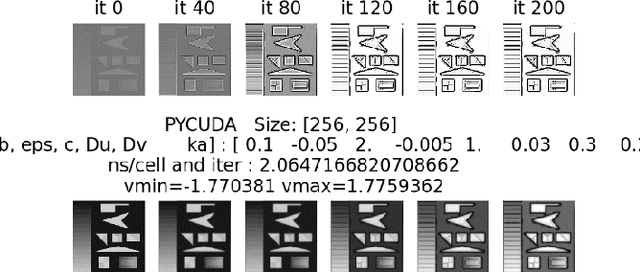

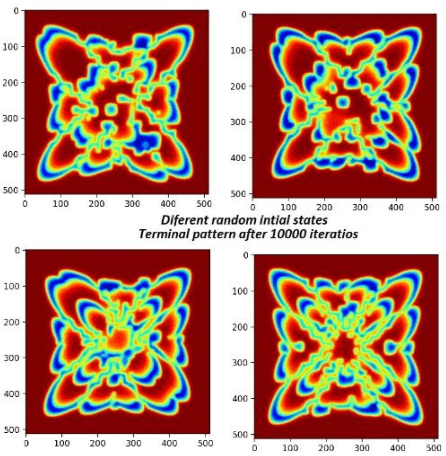
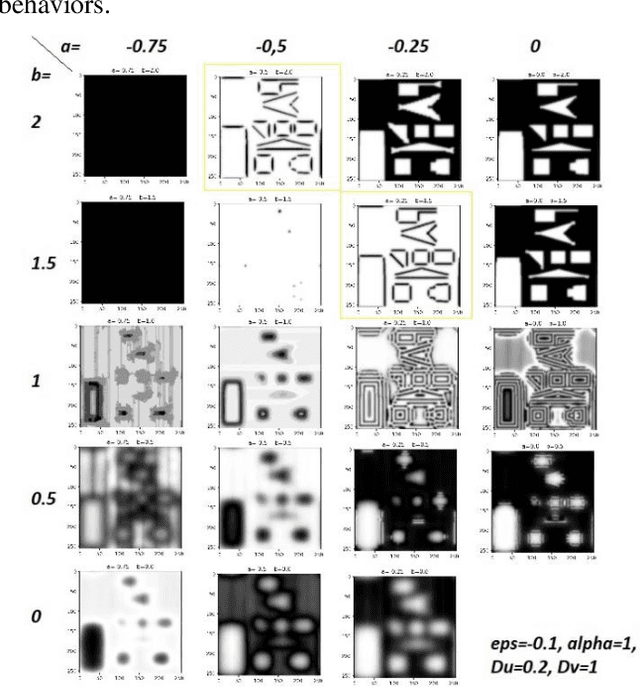
This paper introduces and evaluates a freely available cellular nonlinear network simulator optimized for the effective use of GPUs, to achieve fast modelling and simulations. Its relevance is demonstrated for several applications in nonlinear complex dynamical systems, such as slow-growth phenomena as well as for various image processing applications such as edge detection. The simulator is designed as a Jupyter notebook written in Python and functionally tested and optimized to run on the freely available cloud platform Google Collaboratory. Although the simulator, in its actual form, is designed to model the FitzHugh Nagumo Reaction-Diffusion cellular nonlinear network, it can be easily adapted for any other type of finite-difference time-domain model. Four implementation versions are considered, namely using the PyCUDA, NUMBA respectively CUPY libraries (all three supporting GPU computations) as well as a NUMPY-based implementation to be used when GPU is not available. The specificities and performances for each of the four implementations are analyzed concluding that the PyCUDA implementation ensures a very good performance being capable to run up to 14000 Mega cells per seconds (each cell referring to the basic nonlinear dynamic system composing the cellular nonlinear network).