 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Quantum Algorithms for Reinforcement Learning with a Generative Model
Dec 15, 2021
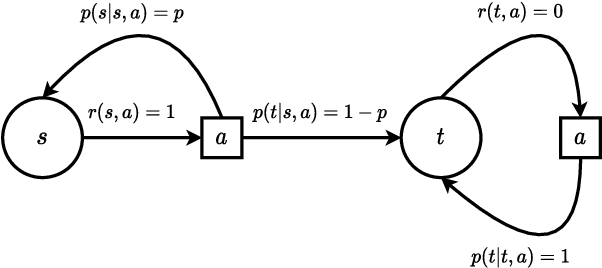
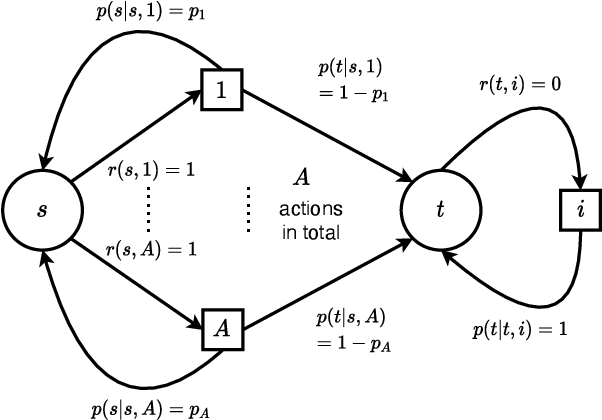
Reinforcement learning studies how an agent should interact with an environment to maximize its cumulative reward. A standard way to study this question abstractly is to ask how many samples an agent needs from the environment to learn an optimal policy for a $\gamma$-discounted Markov decision process (MDP). For such an MDP, we design quantum algorithms that approximate an optimal policy ($\pi^*$), the optimal value function ($v^*$), and the optimal $Q$-function ($q^*$), assuming the algorithms can access samples from the environment in quantum superposition. This assumption is justified whenever there exists a simulator for the environment; for example, if the environment is a video game or some other program. Our quantum algorithms, inspired by value iteration, achieve quadratic speedups over the best-possible classical sample complexities in the approximation accuracy ($\epsilon$) and two main parameters of the MDP: the effective time horizon ($\frac{1}{1-\gamma}$) and the size of the action space ($A$). Moreover, we show that our quantum algorithm for computing $q^*$ is optimal by proving a matching quantum lower bound.
* 26 pages
Iterative RAKI with Complex-Valued Convolution for Improved Image Reconstruction with Limited Scan-Specific Training Samples
Jan 10, 2022
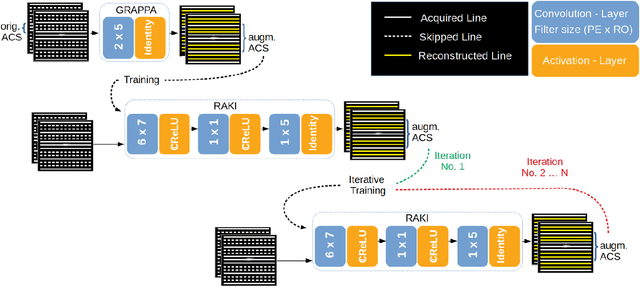
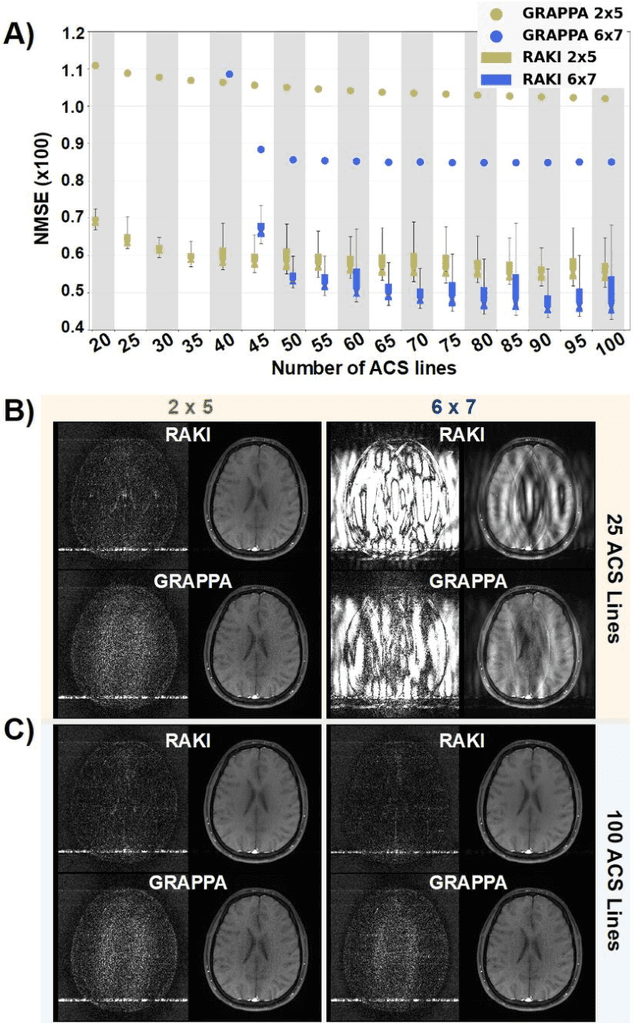
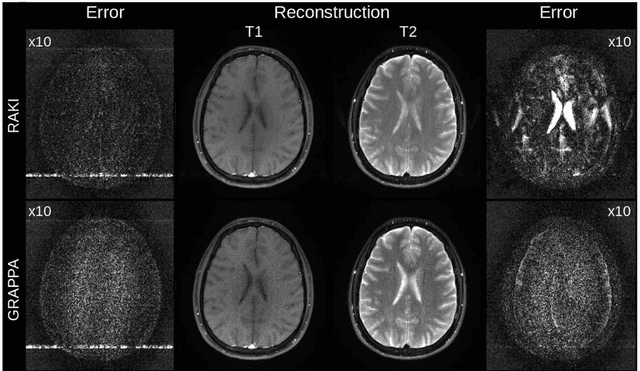
MRI scan time reduction is commonly achieved by Parallel Imaging methods, typically based on uniform undersampling of the inverse image space (a.k.a. k-space) and simultaneous signal reception with multiple receiver coils. The GRAPPA method interpolates missing k-space signals by linear combination of adjacent, acquired signals across all coils, and can be described by a convolution in k-space. Recently, a more generalized method called RAKI was introduced. RAKI is a deep-learning method that generalizes GRAPPA with additional convolution layers, on which a non-linear activation function is applied. This enables non-linear estimation of missing signals by convolutional neural networks. In analogy to GRAPPA, the convolution kernels in RAKI are trained using scan-specific training samples obtained from auto-calibration-signals (ACS). RAKI provides superior reconstruction quality compared to GRAPPA, however, often requires much more ACS due to its increased number of unknown parameters. In order to overcome this limitation, this study investigates the influence of training data on the reconstruction quality for standard 2D imaging, with particular focus on its amount and contrast information. Furthermore, an iterative k-space interpolation approach (iRAKI) is evaluated, which includes training data augmentation via an initial GRAPPA reconstruction, and refinement of convolution filters by iterative training. Using only 18, 20 and 25 ACS lines (8%), iRAKI outperforms RAKI by suppressing residual artefacts occurring at accelerations factors R=4 and R=5, and yields strong noise suppression in comparison to GRAPPA, underlined by quantitative quality metrics. Combination with a phase-constraint yields further improvement. Additionally, iRAKI shows better performance than GRAPPA and RAKI in case of pre-scan calibration and strongly varying contrast between training- and undersampled data.
Improving ECG Classification Interpretability using Saliency Maps
Jan 10, 2022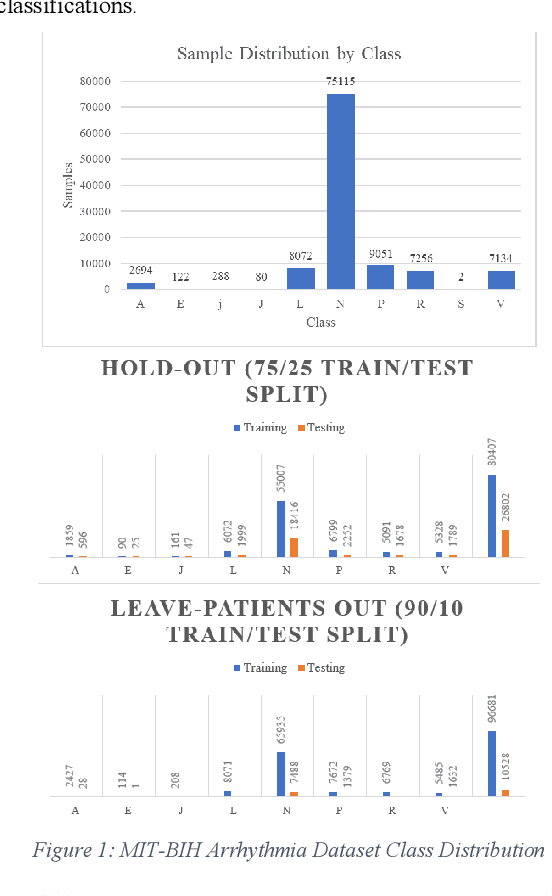
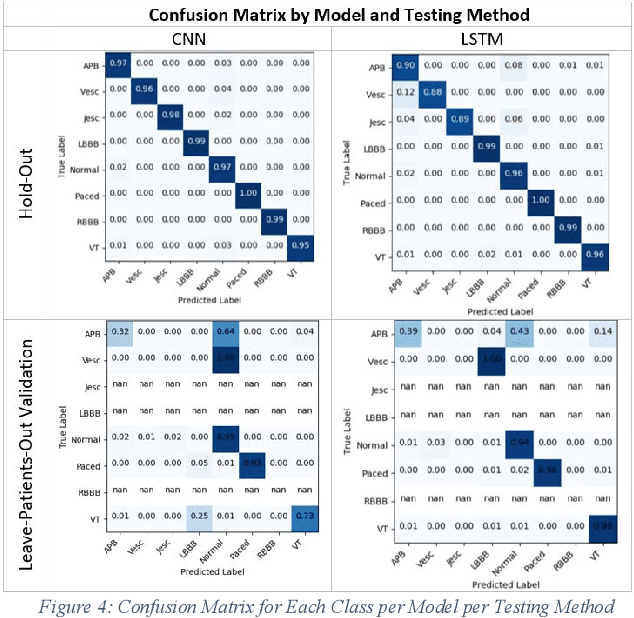
Cardiovascular disease is a large worldwide healthcare issue; symptoms often present suddenly with minimal warning. The electrocardiogram (ECG) is a fast, simple and reliable method of evaluating the health of the heart, by measuring electrical activity recorded through electrodes placed on the skin. ECGs often need to be analyzed by a cardiologist, taking time which could be spent on improving patient care and outcomes. Because of this, automatic ECG classification systems using machine learning have been proposed, which can learn complex interactions between ECG features and use this to detect abnormalities. However, algorithms built for this purpose often fail to generalize well to unseen data, reporting initially impressive results which drop dramatically when applied to new environments. Additionally, machine learning algorithms suffer a "black-box" issue, in which it is difficult to determine how a decision has been made. This is vital for applications in healthcare, as clinicians need to be able to verify the process of evaluation in order to trust the algorithm. This paper proposes a method for visualizing model decisions across each class in the MIT-BIH arrhythmia dataset, using adapted saliency maps averaged across complete classes to determine what patterns are being learned. We do this by building two algorithms based on state-of-the-art models. This paper highlights how these maps can be used to find problems in the model which could be affecting generalizability and model performance. Comparing saliency maps across complete classes gives an overall impression of confounding variables or other biases in the model, unlike what would be highlighted when comparing saliency maps on an ECG-by-ECG basis.
Ten Conceptual Dimensions of Context
Nov 04, 2021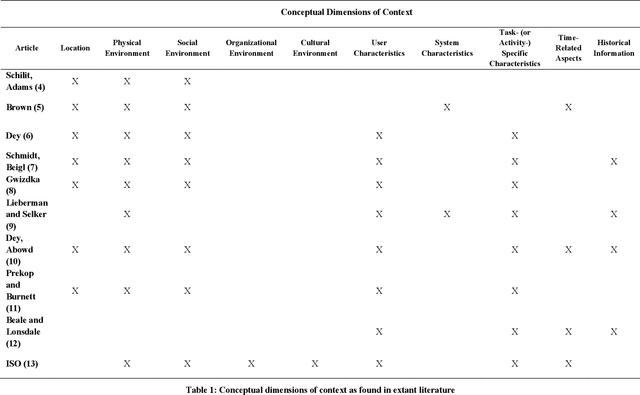
This paper attempts to synthesize various conceptualizations of the term "context" as found in computing literature. Ten conceptual dimensions of context thus emerge -- location; user, task, and system characteristics; physical, social, organizational, and cultural environments; time-related aspects, and historical information. Together, the ten dimensions of context provide a comprehensive view of the notion of context, and allow for a more systematic examination of the influence of context and contextual information on human-system or human-AI interactions.
Smart obervation method with wide field small aperture telescopes for real time transient detection
Nov 20, 2020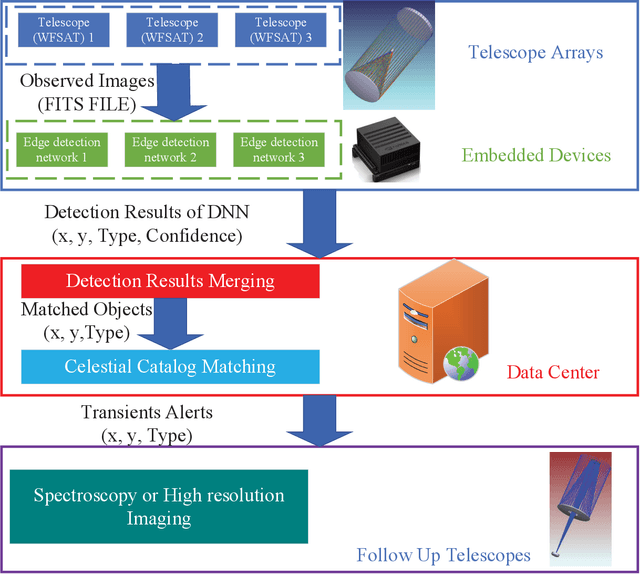
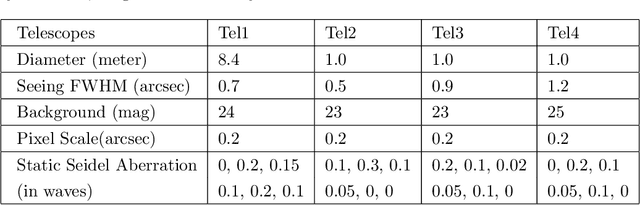


Wide field small aperture telescopes (WFSATs) are commonly used for fast sky survey. Telescope arrays composed by several WFSATs are capable to scan sky several times per night. Huge amount of data would be obtained by them and these data need to be processed immediately. In this paper, we propose ARGUS (Astronomical taRGets detection framework for Unified telescopes) for real-time transit detection. The ARGUS uses a deep learning based astronomical detection algorithm implemented in embedded devices in each WFSATs to detect astronomical targets. The position and probability of a detection being an astronomical targets will be sent to a trained ensemble learning algorithm to output information of celestial sources. After matching these sources with star catalog, ARGUS will directly output type and positions of transient candidates. We use simulated data to test the performance of ARGUS and find that ARGUS can increase the performance of WFSATs in transient detection tasks robustly.
Noninvasive ultrasound for Lithium-ion batteries state estimation
Oct 26, 2021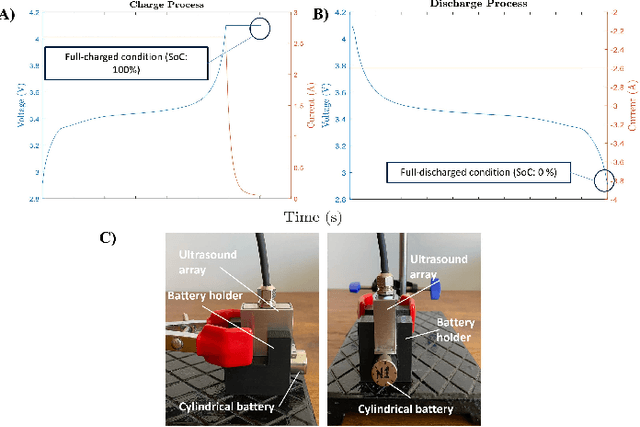
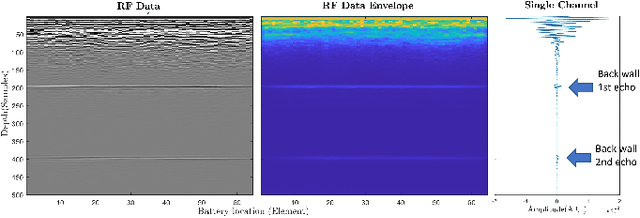
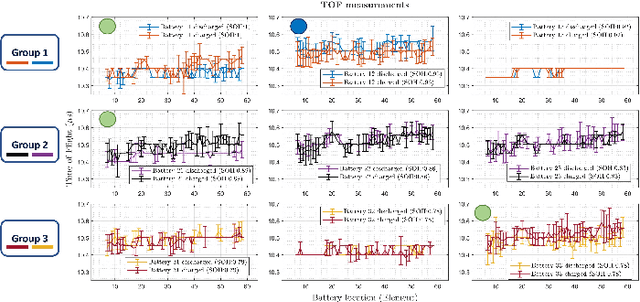
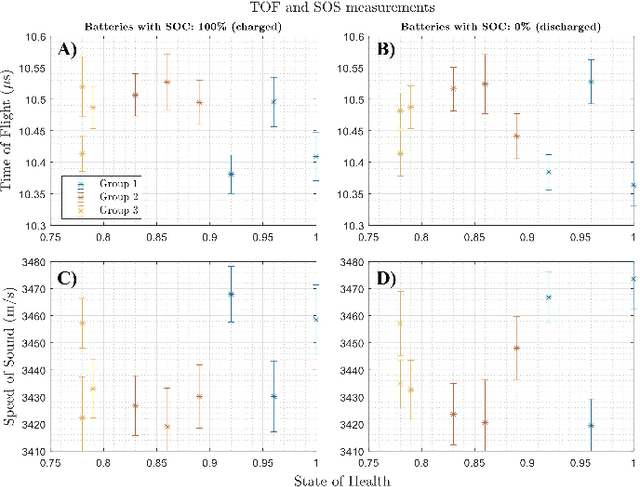
Lithium-ion battery degradation estimation using fast and noninvasive techniques is a crucial issue in the circular economy framework of this technology. Currently, most of the approaches used to establish the battery-state (i.e., State of Charge (SoC), State of Health (SoH)) require time-consuming processes. In the present preliminary study, an ultrasound array was used to assess the influence of the SoC and SoH on the variations in the time of flight (TOF) and the speed of sound (SOS) of the ultrasound wave inside the batteries. Nine aged 18650 Lithium-ion batteries were imaged at 100% and 0% SoC using a Vantage-256 system (Verasonics, Inc.) equipped with a 64-element ultrasound array and a center frequency of 5 MHz (Imasonic SAS). It was found that second-life batteries have a complex ultrasound response due to the presence of many degradation pathways and, thus, making it harder to analyze the ultrasound measurements. Although further analysis must be done to elucidate a clear correlation between changes in the ultrasound wave properties and the battery state estimation, this approach seems very promising for future nondestructive evaluation of second-life batteries.
Time-Series Anomaly Detection Service at Microsoft
Jun 10, 2019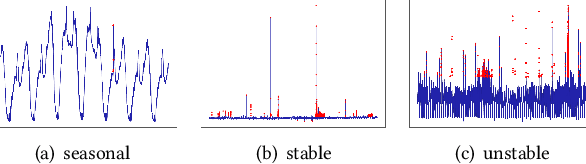
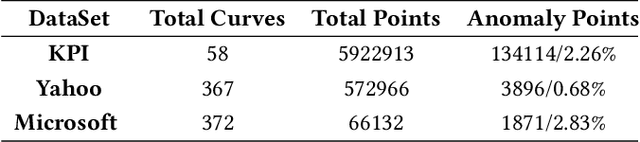
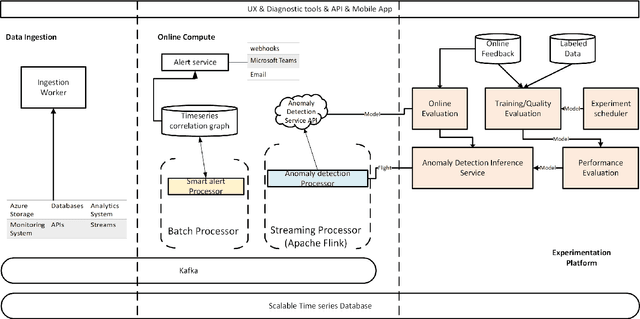

Large companies need to monitor various metrics (for example, Page Views and Revenue) of their applications and services in real time. At Microsoft, we develop a time-series anomaly detection service which helps customers to monitor the time-series continuously and alert for potential incidents on time. In this paper, we introduce the pipeline and algorithm of our anomaly detection service, which is designed to be accurate, efficient and general. The pipeline consists of three major modules, including data ingestion, experimentation platform and online compute. To tackle the problem of time-series anomaly detection, we propose a novel algorithm based on Spectral Residual (SR) and Convolutional Neural Network (CNN). Our work is the first attempt to borrow the SR model from visual saliency detection domain to time-series anomaly detection. Moreover, we innovatively combine SR and CNN together to improve the performance of SR model. Our approach achieves superior experimental results compared with state-of-the-art baselines on both public datasets and Microsoft production data.
DeepABM: Scalable, efficient and differentiable agent-based simulations via graph neural networks
Oct 09, 2021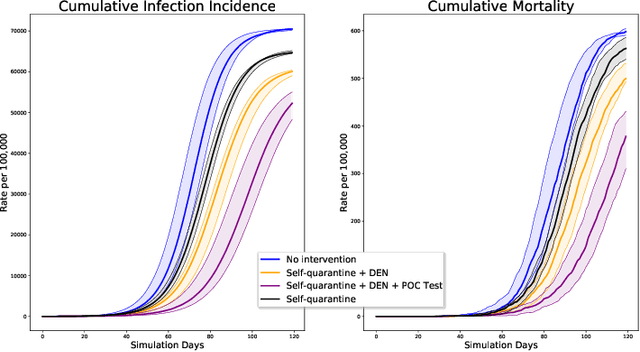

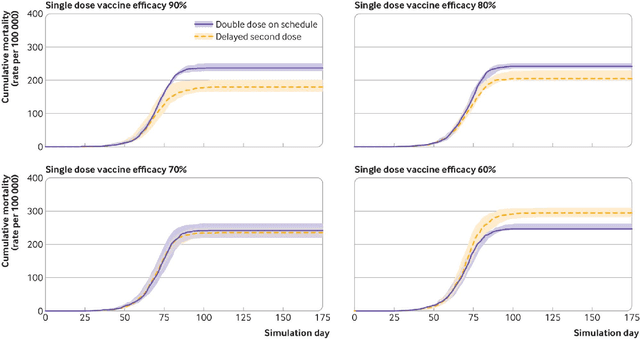
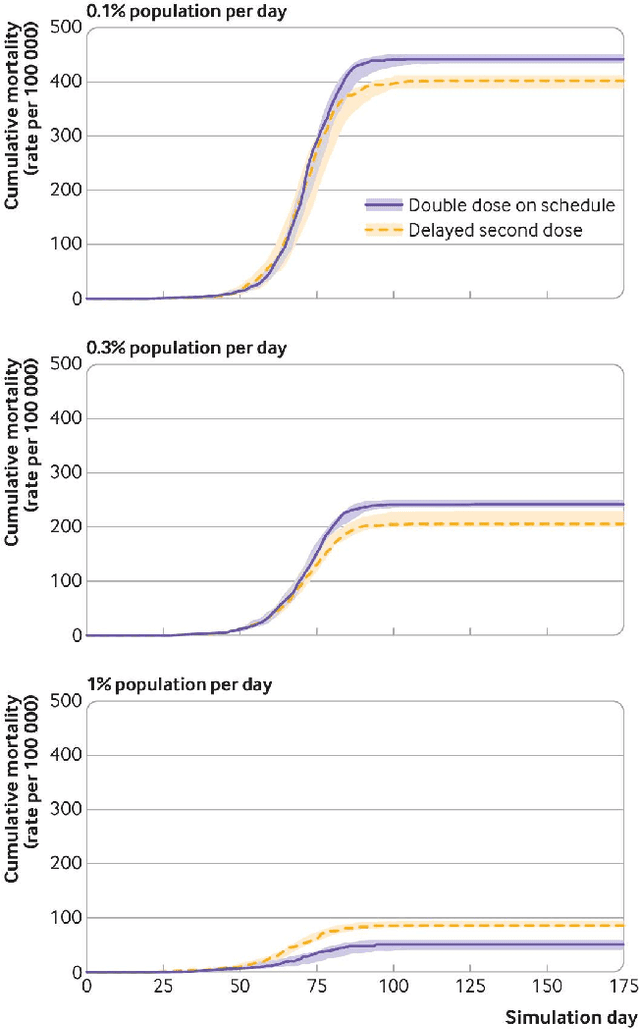
We introduce DeepABM, a framework for agent-based modeling that leverages geometric message passing of graph neural networks for simulating action and interactions over large agent populations. Using DeepABM allows scaling simulations to large agent populations in real-time and running them efficiently on GPU architectures. To demonstrate the effectiveness of DeepABM, we build DeepABM-COVID simulator to provide support for various non-pharmaceutical interventions (quarantine, exposure notification, vaccination, testing) for the COVID-19 pandemic, and can scale to populations of representative size in real-time on a GPU. Specifically, DeepABM-COVID can model 200 million interactions (over 100,000 agents across 180 time-steps) in 90 seconds, and is made available online to help researchers with modeling and analysis of various interventions. We explain various components of the framework and discuss results from one research study to evaluate the impact of delaying the second dose of the COVID-19 vaccine in collaboration with clinical and public health experts. While we simulate COVID-19 spread, the ideas introduced in the paper are generic and can be easily extend to other forms of agent-based simulations. Furthermore, while beyond scope of this document, DeepABM enables inverse agent-based simulations which can be used to learn physical parameters in the (micro) simulations using gradient-based optimization with large-scale real-world (macro) data. We are optimistic that the current work can have interesting implications for bringing ABM and AI communities closer.
Feature Selection on a Flare Forecasting Testbed: A Comparative Study of 24 Methods
Sep 30, 2021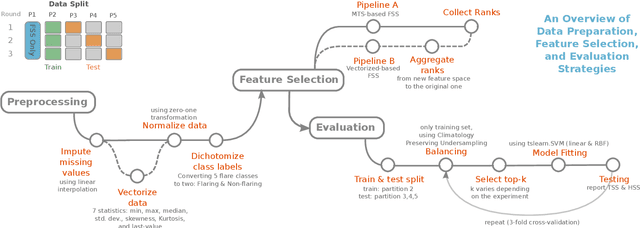
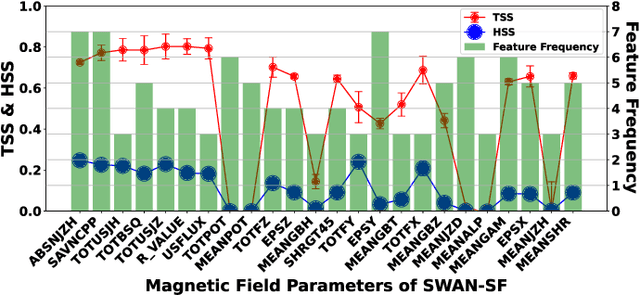
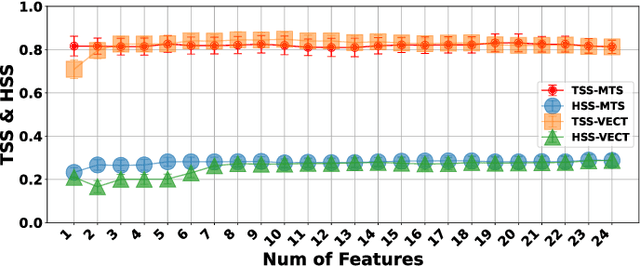
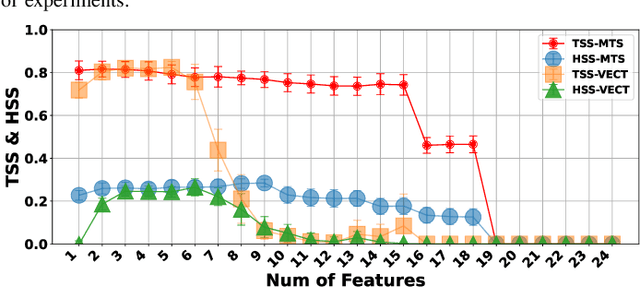
The Space-Weather ANalytics for Solar Flares (SWAN-SF) is a multivariate time series benchmark dataset recently created to serve the heliophysics community as a testbed for solar flare forecasting models. SWAN-SF contains 54 unique features, with 24 quantitative features computed from the photospheric magnetic field maps of active regions, describing their precedent flare activity. In this study, for the first time, we systematically attacked the problem of quantifying the relevance of these features to the ambitious task of flare forecasting. We implemented an end-to-end pipeline for preprocessing, feature selection, and evaluation phases. We incorporated 24 Feature Subset Selection (FSS) algorithms, including multivariate and univariate, supervised and unsupervised, wrappers and filters. We methodologically compared the results of different FSS algorithms, both on the multivariate time series and vectorized formats, and tested their correlation and reliability, to the extent possible, by using the selected features for flare forecasting on unseen data, in univariate and multivariate fashions. We concluded our investigation with a report of the best FSS methods in terms of their top-k features, and the analysis of the findings. We wish the reproducibility of our study and the availability of the data allow the future attempts be comparable with our findings and themselves.
Guaranteed Contraction Control in the Presence of Imperfectly Learned Dynamics
Dec 15, 2021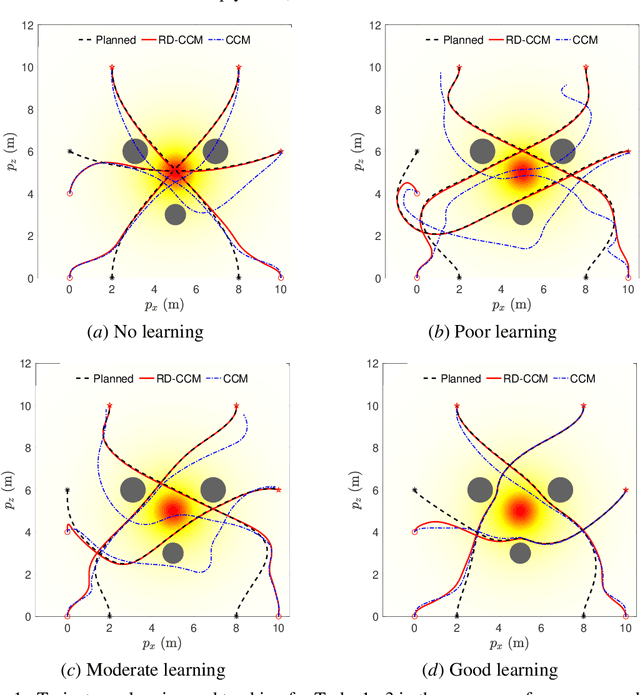
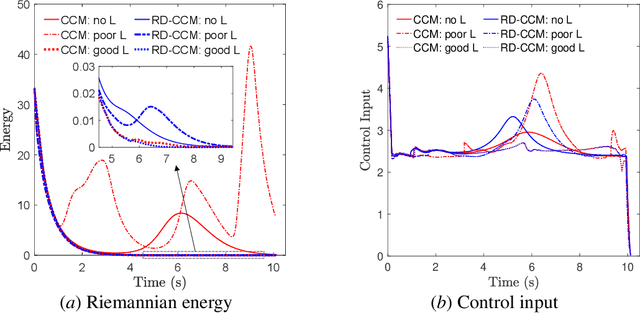
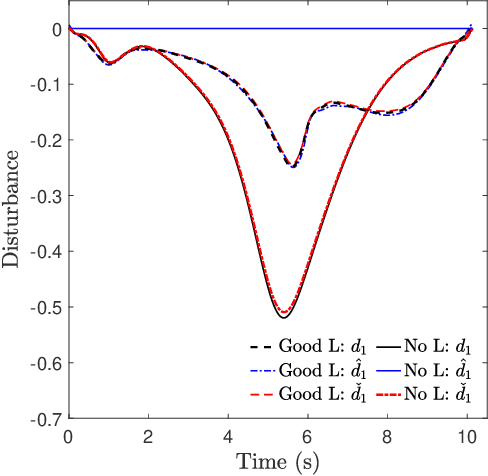
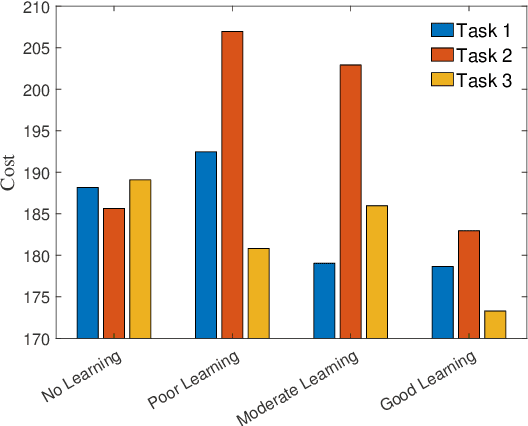
This paper presents an approach for trajectory-centric learning control based on contraction metrics and disturbance estimation for nonlinear systems subject to matched uncertainties. The approach allows for the use of a broad class of model learning tools including deep neural networks to learn uncertain dynamics while still providing guarantees of transient tracking performance throughout the learning phase, including the special case of no learning. Within the proposed approach, a disturbance estimation law is proposed to estimate the pointwise value of the uncertainty, with pre-computable estimation error bounds (EEBs). The learned dynamics, the estimated disturbances, and the EEBs are then incorporated in a robust Riemannian energy condition to compute the control law that guarantees exponential convergence of actual trajectories to desired ones throughout the learning phase, even when the learned model is poor. On the other hand, with improved accuracy, the learned model can be incorporated in a high-level planner to plan better trajectories with improved performance, e.g., lower energy consumption and shorter travel time. The proposed framework is validated on a planar quadrotor navigation example.