 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-time Human Activity Recognition Using Conditionally Parametrized Convolutions on Mobile and Wearable Devices
Jun 13, 2020
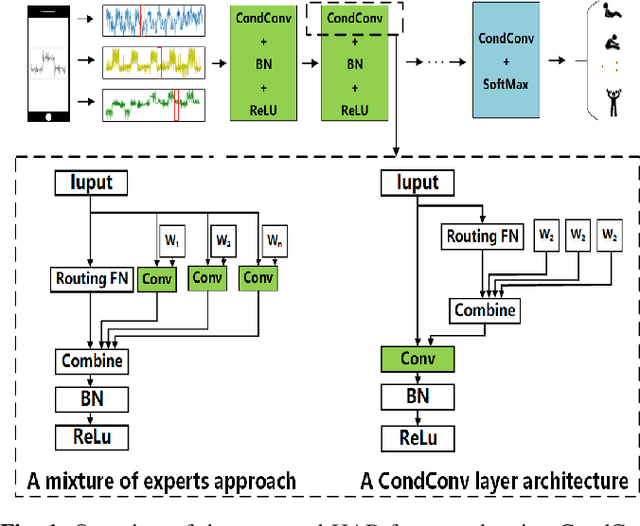
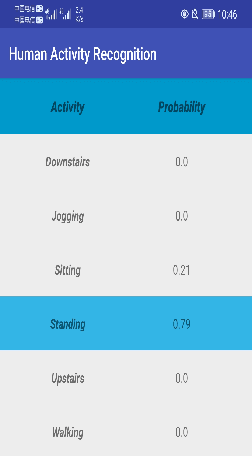
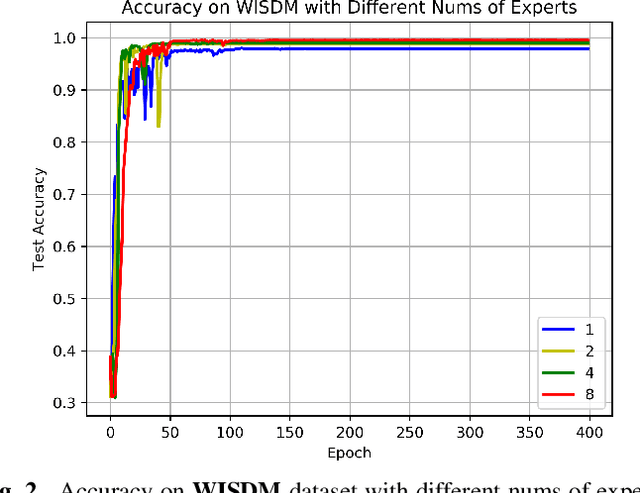
Recently, deep learning has represented an important research trend in human activity recognition (HAR). In particular, deep convolutional neural networks (CNNs) have achieved state-of-the-art performance on various HAR datasets. For deep learning, improvements in performance have to heavily rely on increasing model size or capacity to scale to larger and larger datasets, which inevitably leads to the increase of operations. A high number of operations in deep leaning increases computational cost and is not suitable for real-time HAR using mobile and wearable sensors. Though shallow learning techniques often are lightweight, they could not achieve good performance. Therefore, deep learning methods that can balance the trade-off between accuracy and computation cost is highly needed, which to our knowledge has seldom been researched. In this paper, we for the first time propose a computation efficient CNN using conditionally parametrized convolution for real-time HAR on mobile and wearable devices. We evaluate the proposed method on four public benchmark HAR datasets consisting of WISDM dataset, PAMAP2 dataset, UNIMIB-SHAR dataset, and OPPORTUNITY dataset, achieving state-of-the-art accuracy without compromising computation cost. Various ablation experiments are performed to show how such a network with large capacity is clearly preferable to baseline while requiring a similar amount of operations. The method can be used as a drop-in replacement for the existing deep HAR architectures and easily deployed onto mobile and wearable devices for real-time HAR applications.
Multiple Style-Transfer in Real-Time
Nov 18, 2019
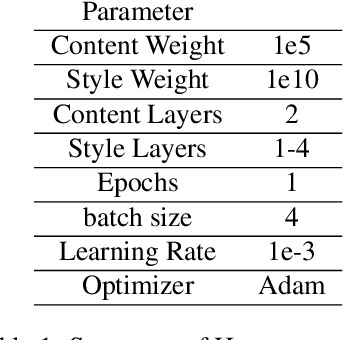

Style transfer aims to combine the content of one image with the artistic style of another. It was discovered that lower levels of convolutional networks captured style information, while higher levels captures content information. The original style transfer formulation used a weighted combination of VGG-16 layer activations to achieve this goal. Later, this was accomplished in real-time using a feed-forward network to learn the optimal combination of style and content features from the respective images. The first aim of our project was to introduce a framework for capturing the style from several images at once. We propose a method that extends the original real-time style transfer formulation by combining the features of several style images. This method successfully captures color information from the separate style images. The other aim of our project was to improve the temporal style continuity from frame to frame. Accordingly, we have experimented with the temporal stability of the output images and discussed the various available techniques that could be employed as alternatives.
Deep forecasting of translational impact in medical research
Oct 17, 2021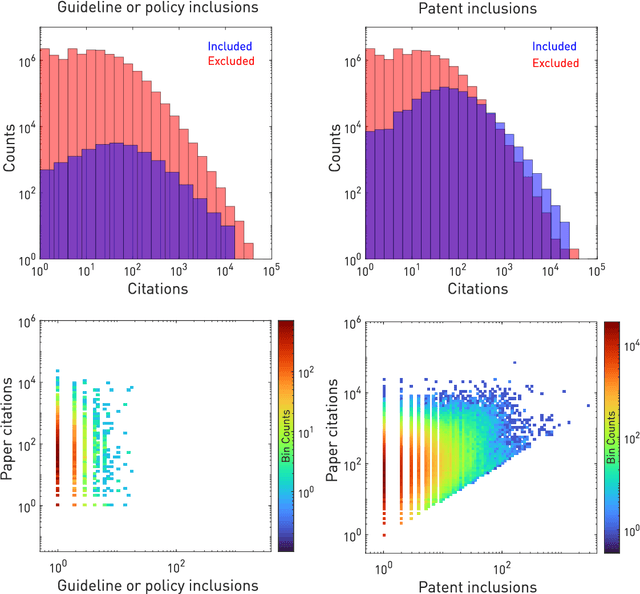
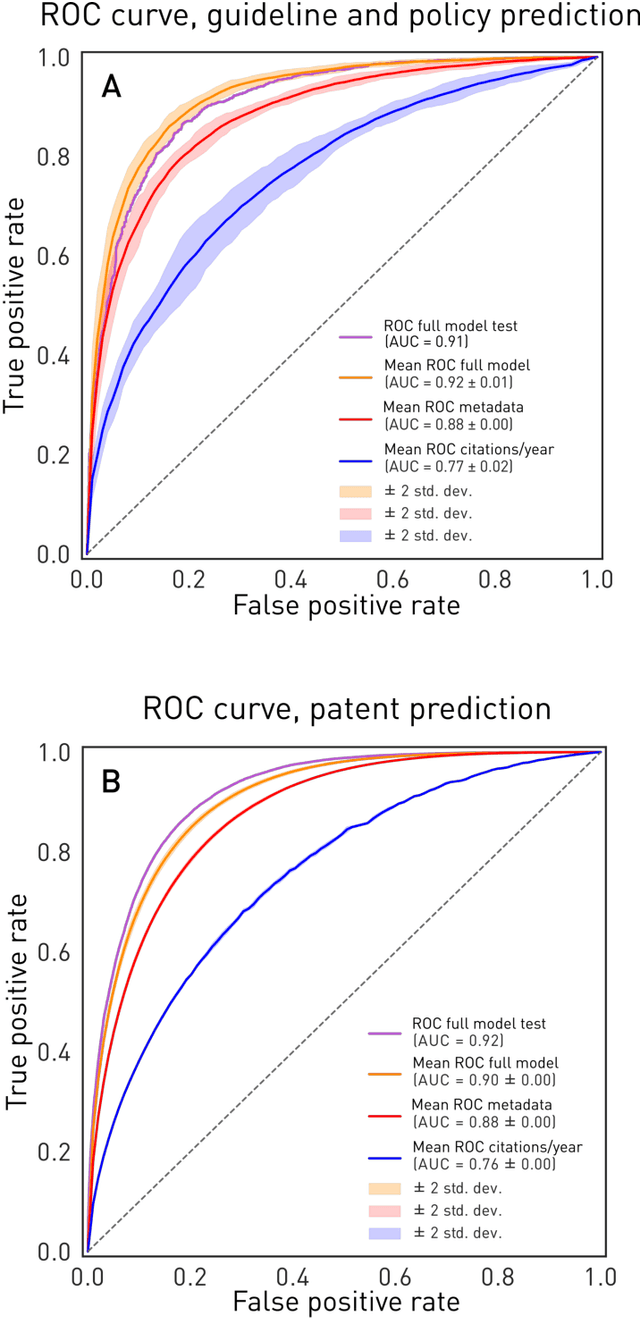
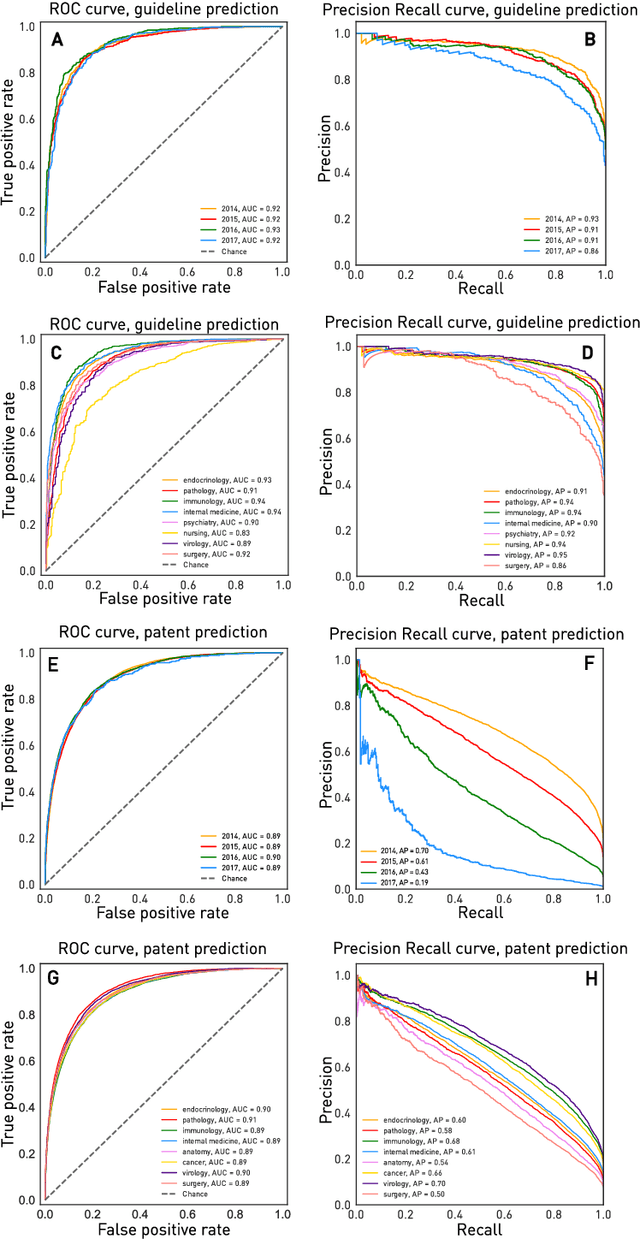
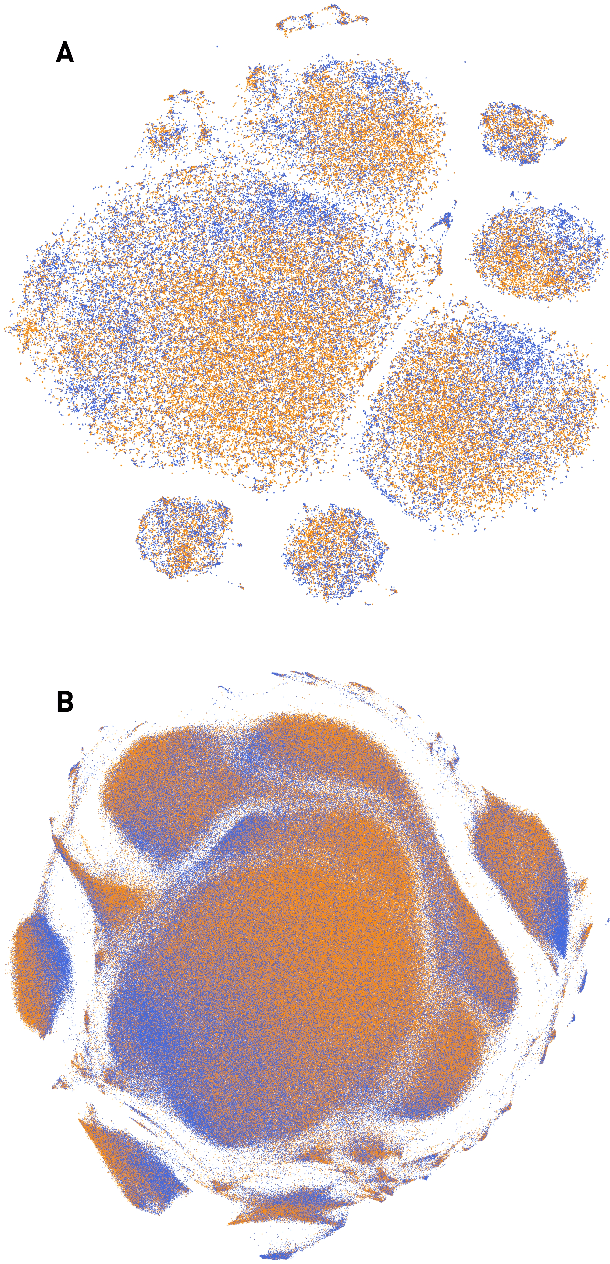
The value of biomedical research--a $1.7 trillion annual investment--is ultimately determined by its downstream, real-world impact. Current objective predictors of impact rest on proxy, reductive metrics of dissemination, such as paper citation rates, whose relation to real-world translation remains unquantified. Here we sought to determine the comparative predictability of future real-world translation--as indexed by inclusion in patents, guidelines or policy documents--from complex models of the abstract-level content of biomedical publications versus citations and publication meta-data alone. We develop a suite of representational and discriminative mathematical models of multi-scale publication data, quantifying predictive performance out-of-sample, ahead-of-time, across major biomedical domains, using the entire corpus of biomedical research captured by Microsoft Academic Graph from 1990 to 2019, encompassing 43.3 million papers across all domains. We show that citations are only moderately predictive of translational impact as judged by inclusion in patents, guidelines, or policy documents. By contrast, high-dimensional models of publication titles, abstracts and metadata exhibit high fidelity (AUROC > 0.9), generalise across time and thematic domain, and transfer to the task of recognising papers of Nobel Laureates. The translational impact of a paper indexed by inclusion in patents, guidelines, or policy documents can be predicted--out-of-sample and ahead-of-time--with substantially higher fidelity from complex models of its abstract-level content than from models of publication meta-data or citation metrics. We argue that content-based models of impact are superior in performance to conventional, citation-based measures, and sustain a stronger evidence-based claim to the objective measurement of translational potential.
Recent Advances in Automated Question Answering In Biomedical Domain
Nov 10, 2021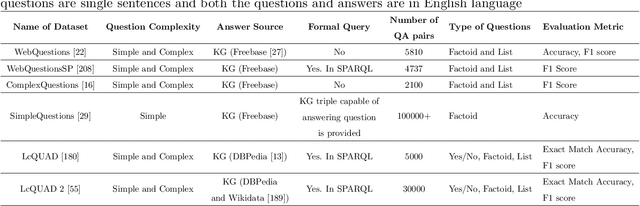
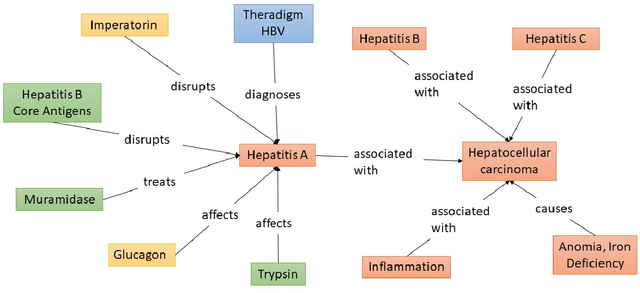
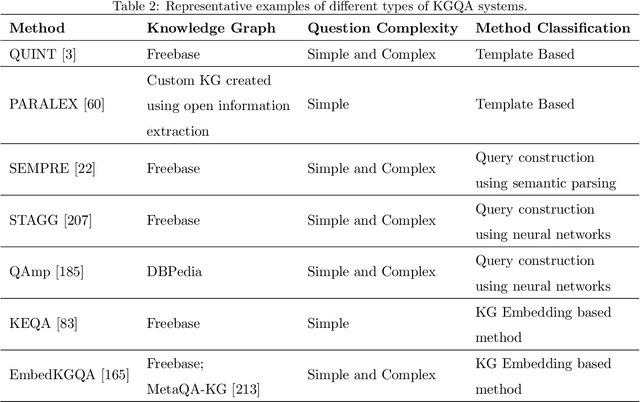
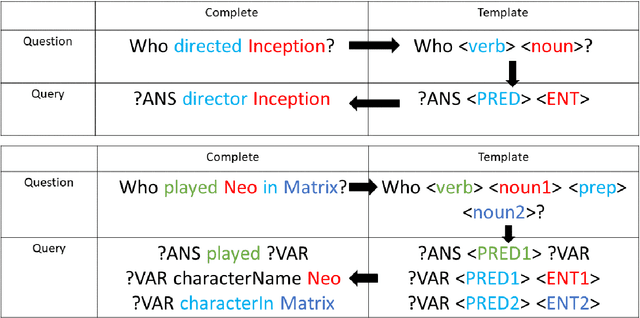
The objective of automated Question Answering (QA) systems is to provide answers to user queries in a time efficient manner. The answers are usually found in either databases (or knowledge bases) or a collection of documents commonly referred to as the corpus. In the past few decades there has been a proliferation of acquisition of knowledge and consequently there has been an exponential growth in new scientific articles in the field of biomedicine. Therefore, it has become difficult to keep track of all the information in the domain, even for domain experts. With the improvements in commercial search engines, users can type in their queries and get a small set of documents most relevant for answering their query, as well as relevant snippets from the documents in some cases. However, it may be still tedious and time consuming to manually look for the required information or answers. This has necessitated the development of efficient QA systems which aim to find exact and precise answers to user provided natural language questions in the domain of biomedicine. In this paper, we introduce the basic methodologies used for developing general domain QA systems, followed by a thorough investigation of different aspects of biomedical QA systems, including benchmark datasets and several proposed approaches, both using structured databases and collection of texts. We also explore the limitations of current systems and explore potential avenues for further advancement.
Theoretical Guarantees of Fictitious Discount Algorithms for Episodic Reinforcement Learning and Global Convergence of Policy Gradient Methods
Sep 13, 2021When designing algorithms for finite-time-horizon episodic reinforcement learning problems, a common approach is to introduce a fictitious discount factor and use stationary policies for approximations. Empirically, it has been shown that the fictitious discount factor helps reduce variance, and stationary policies serve to save the per-iteration computational cost. Theoretically, however, there is no existing work on convergence analysis for algorithms with this fictitious discount recipe. This paper takes the first step towards analyzing these algorithms. It focuses on two vanilla policy gradient (VPG) variants: the first being a widely used variant with discounted advantage estimations (DAE), the second with an additional fictitious discount factor in the score functions of the policy gradient estimators. Non-asymptotic convergence guarantees are established for both algorithms, and the additional discount factor is shown to reduce the bias introduced in DAE and thus improve the algorithm convergence asymptotically. A key ingredient of our analysis is to connect three settings of Markov decision processes (MDPs): the finite-time-horizon, the average reward and the discounted settings. To our best knowledge, this is the first theoretical guarantee on fictitious discount algorithms for the episodic reinforcement learning of finite-time-horizon MDPs, which also leads to the (first) global convergence of policy gradient methods for finite-time-horizon episodic reinforcement learning.
A recurrent neural network approach for remaining useful life prediction utilizing a novel trend features construction method
Dec 10, 2021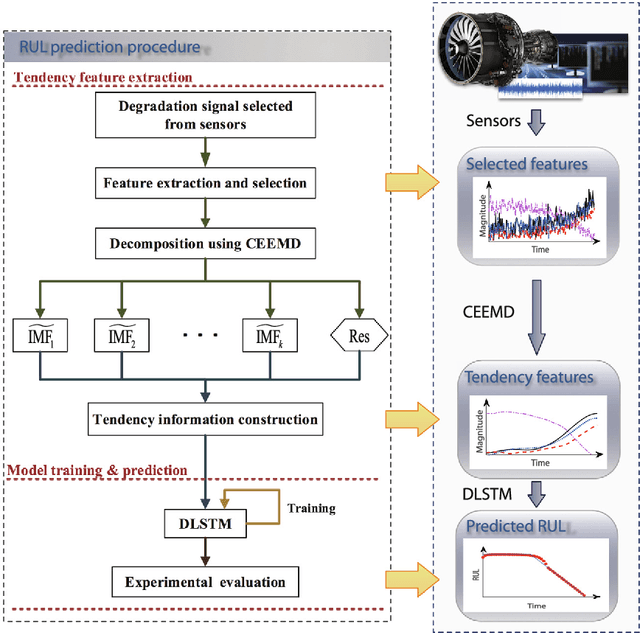
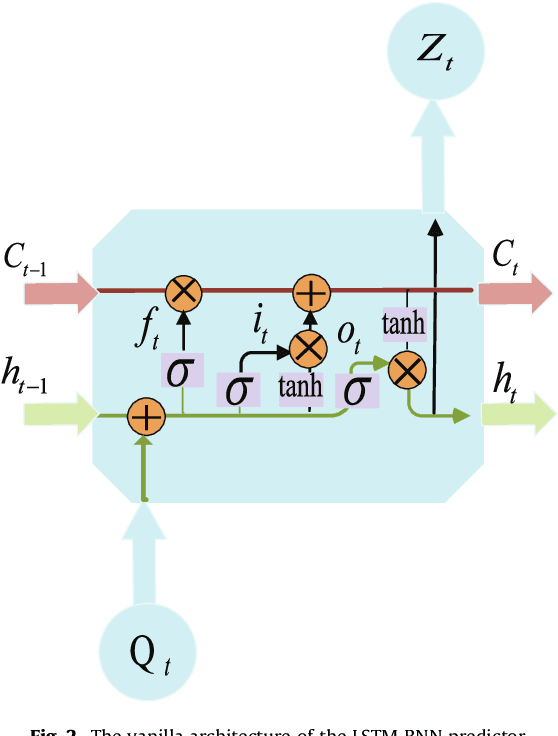

Data-driven methods for remaining useful life (RUL) prediction normally learn features from a fixed window size of a priori of degradation, which may lead to less accurate prediction results on different datasets because of the variance of local features. This paper proposes a method for RUL prediction which depends on a trend feature representing the overall time sequence of degradation. Complete ensemble empirical mode decomposition, followed by a reconstruction procedure, is created to build the trend features. The probability distribution of sensors' measurement learned by conditional neural processes is used to evaluate the trend features. With the best trend feature, a data-driven model using long short-term memory is developed to predict the RUL. To prove the effectiveness of the proposed method, experiments on a benchmark C-MAPSS dataset are carried out and compared with other state-of-the-art methods. Comparison results show that the proposed method achieves the smallest root mean square values in prediction of all RUL.
Deep survival analysis with longitudinal X-rays for COVID-19
Aug 22, 2021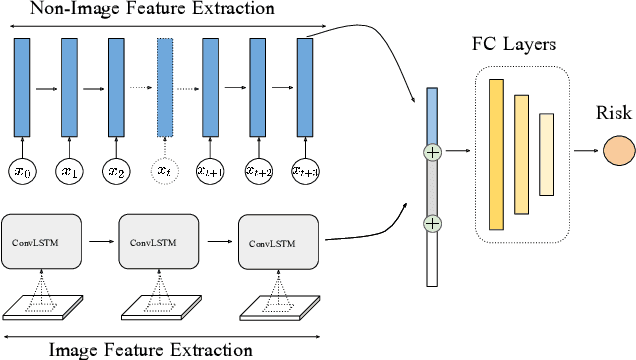
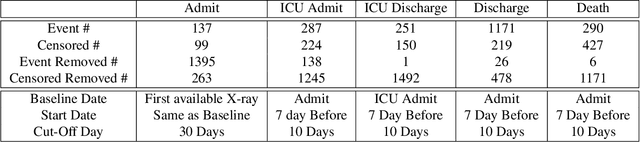
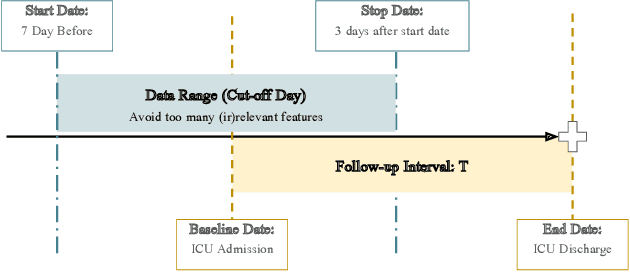
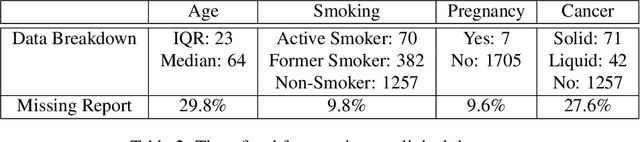
Time-to-event analysis is an important statistical tool for allocating clinical resources such as ICU beds. However, classical techniques like the Cox model cannot directly incorporate images due to their high dimensionality. We propose a deep learning approach that naturally incorporates multiple, time-dependent imaging studies as well as non-imaging data into time-to-event analysis. Our techniques are benchmarked on a clinical dataset of 1,894 COVID-19 patients, and show that image sequences significantly improve predictions. For example, classical time-to-event methods produce a concordance error of around 30-40% for predicting hospital admission, while our error is 25% without images and 20% with multiple X-rays included. Ablation studies suggest that our models are not learning spurious features such as scanner artifacts. While our focus and evaluation is on COVID-19, the methods we develop are broadly applicable.
ELight: Enabling Efficient Photonic In-Memory Neurocomputing with Life Enhancement
Dec 15, 2021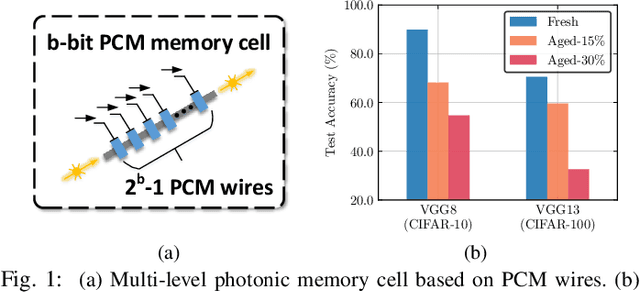
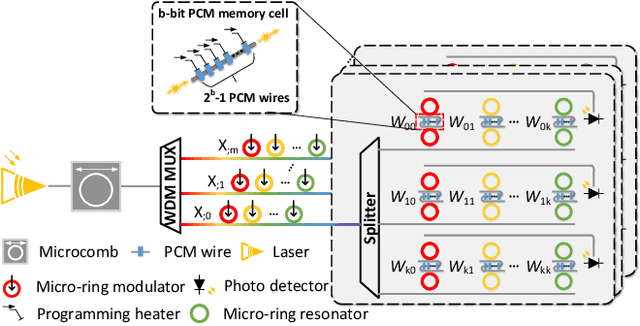
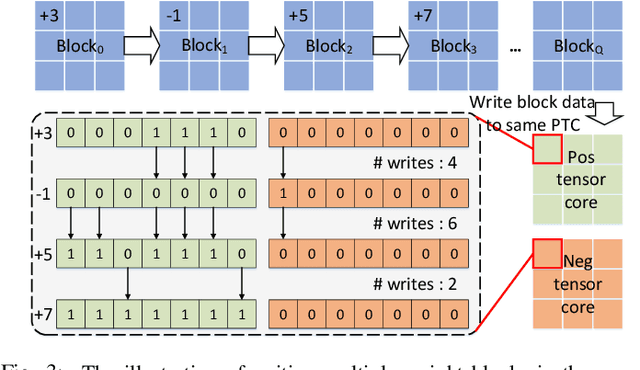
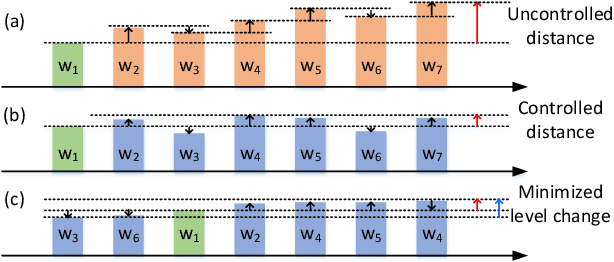
With the recent advances in optical phase change material (PCM), photonic in-memory neurocomputing has demonstrated its superiority in optical neural network (ONN) designs with near-zero static power consumption, time-of-light latency, and compact footprint. However, photonic tensor cores require massive hardware reuse to implement large matrix multiplication due to the limited single-core scale. The resultant large number of PCM writes leads to serious dynamic power and overwhelms the fragile PCM with limited write endurance. In this work, we propose a synergistic optimization framework, ELight, to minimize the overall write efforts for efficient and reliable optical in-memory neurocomputing. We first propose write-aware training to encourage the similarity among weight blocks, and combine it with a post-training optimization method to reduce programming efforts by eliminating redundant writes. Experiments show that ELight can achieve over 20X reduction in the total number of writes and dynamic power with comparable accuracy. With our ELight, photonic in-memory neurocomputing will step forward towards viable applications in machine learning with preserved accuracy, order-of-magnitude longer lifetime, and lower programming energy.
Smooth head tracking for virtual reality applications
Oct 27, 2021
In this work, we propose a new head-tracking solution for human-machine real-time interaction with virtual 3D environments. This solution leverages RGBD data to compute virtual camera pose according to the movements of the user's head. The process starts with the extraction of a set of facial features from the images delivered by the sensor. Such features are matched against their respective counterparts in a reference image for the computation of the current head pose. Afterwards, a prediction approach is used to guess the most likely next head move (final pose). Pythagorean Hodograph interpolation is then adapted to determine the path and local frames taken between the two poses. The result is a smooth head trajectory that serves as an input to set the camera in virtual scenes according to the user's gaze. The resulting motion model has the advantage of being: continuous in time, it adapts to any frame rate of rendering; it is ergonomic, as it frees the user from wearing tracking markers; it is smooth and free from rendering jerks; and it is also torsion and curvature minimizing as it produces a path with minimum bending energy.
* 8 pages, 1 figure
Controllable and Interpretable Singing Voice Decomposition via Assem-VC
Oct 25, 2021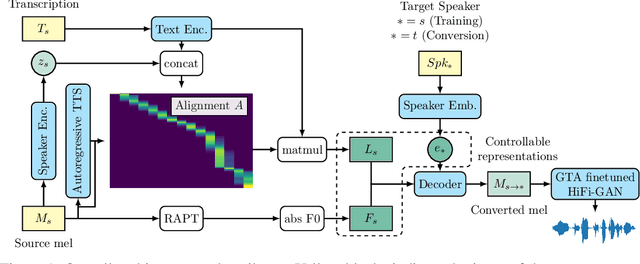

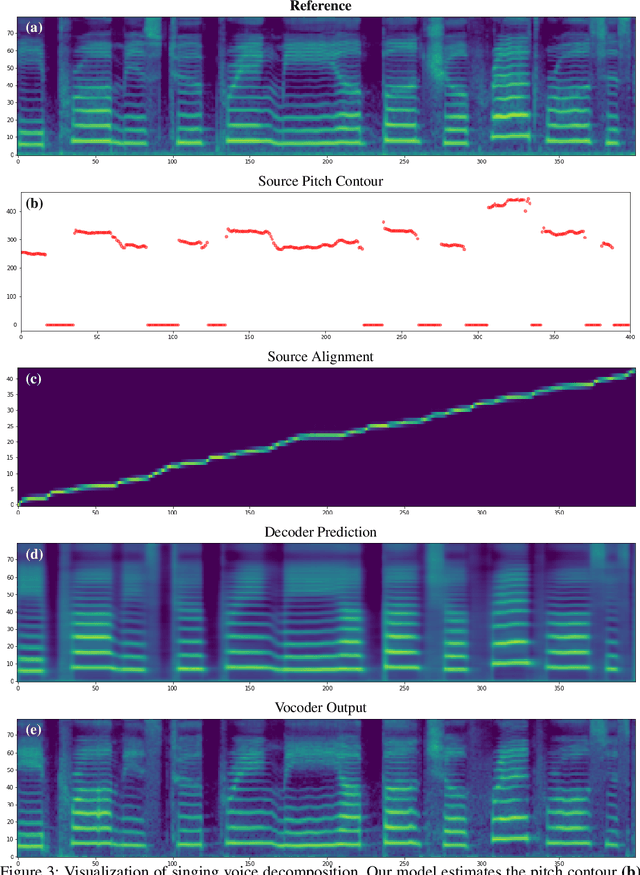
We propose a singing decomposition system that encodes time-aligned linguistic content, pitch, and source speaker identity via Assem-VC. With decomposed speaker-independent information and the target speaker's embedding, we could synthesize the singing voice of the target speaker. In conclusion, we made a perfectly synced duet with the user's singing voice and the target singer's converted singing voice.