 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Compressed Sensing Channel Estimation for OTFS Modulation in Non-Integer Delay-Doppler Domain
Nov 24, 2021
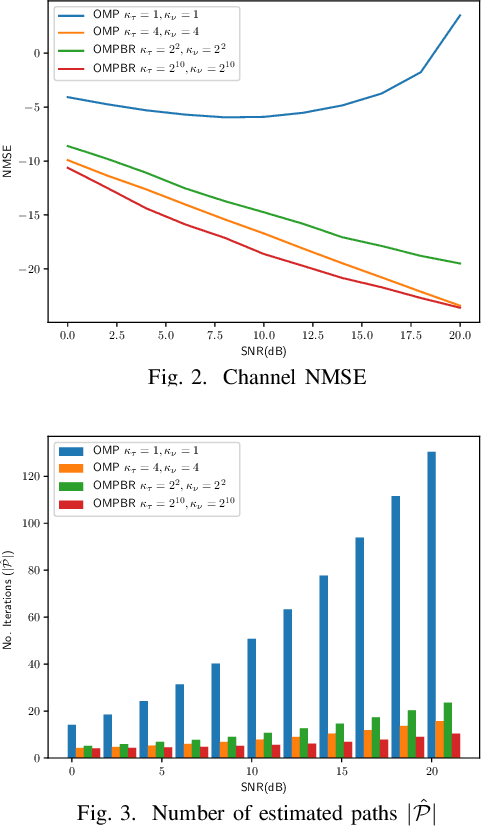

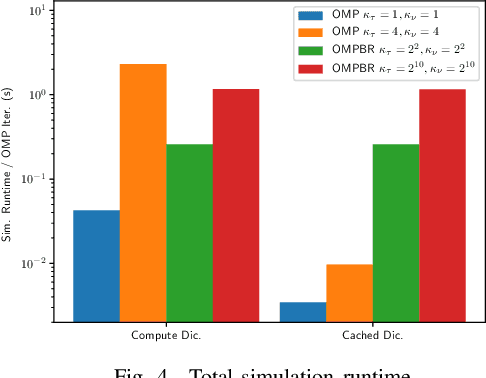
This paper introduces a Compressed Sensing (CS) estimation scheme for Orthogonal Time Frequency Space (OTFS) channels with sparse multipath. The OTFS waveform represents signals in a two dimensional Delay-Doppler (DD) orthonormal basis. The proposed model does not require the assumption that the delays are integer multiples of the sampling period. The analysis shows that non-integer delay and Doppler shifts in the channel cannot be accurately modelled by integer approximations. An Orthogonal Matching Pursuit with Binary-division Refinement (OMPBR) estimation algorithm is proposed. The proposed estimator finds the best channel approximation over a continuous DD dictionary without integer approximations. This results in a significant reduction of the estimation normalized mean squared error with reasonable computational complexity.
Towards Evaluating the Robustness of Neural Networks Learned by Transduction
Oct 27, 2021
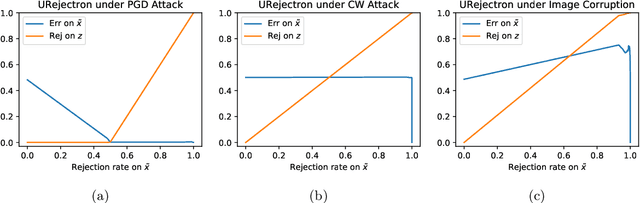
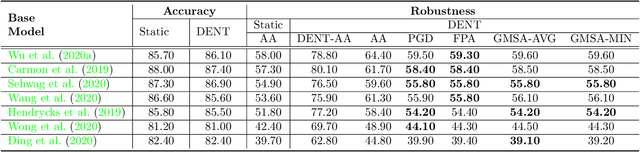

There has been emerging interest in using transductive learning for adversarial robustness (Goldwasser et al., NeurIPS 2020; Wu et al., ICML 2020; Wang et al., ArXiv 2021). Compared to traditional defenses, these defense mechanisms "dynamically learn" the model based on test-time input; and theoretically, attacking these defenses reduces to solving a bilevel optimization problem, which poses difficulty in crafting adaptive attacks. In this paper, we examine these defense mechanisms from a principled threat analysis perspective. We formulate and analyze threat models for transductive-learning based defenses, and point out important subtleties. We propose the principle of attacking model space for solving bilevel attack objectives, and present Greedy Model Space Attack (GMSA), an attack framework that can serve as a new baseline for evaluating transductive-learning based defenses. Through systematic evaluation, we show that GMSA, even with weak instantiations, can break previous transductive-learning based defenses, which were resilient to previous attacks, such as AutoAttack (Croce and Hein, ICML 2020). On the positive side, we report a somewhat surprising empirical result of "transductive adversarial training": Adversarially retraining the model using fresh randomness at the test time gives a significant increase in robustness against attacks we consider.
Uncertainty quantification of a 3D In-Stent Restenosis model with surrogate modelling
Nov 11, 2021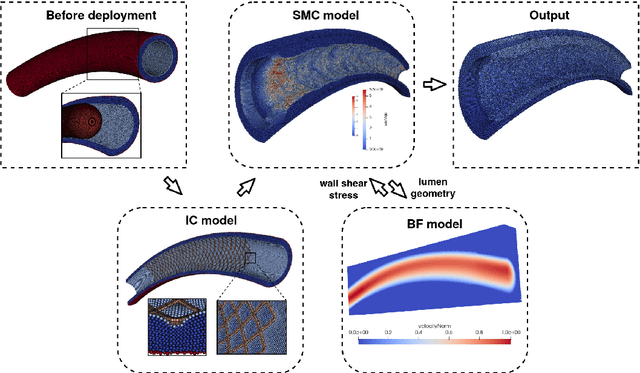
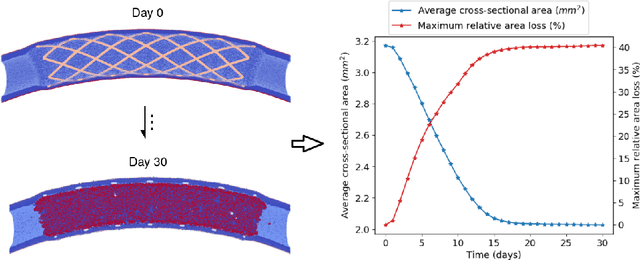
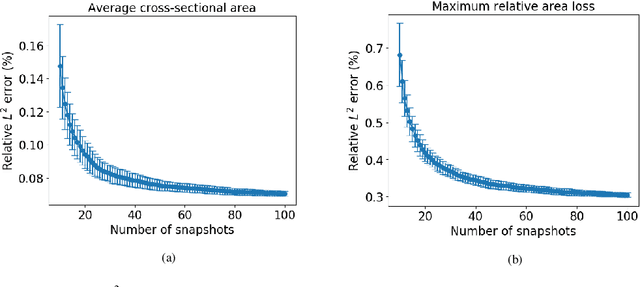
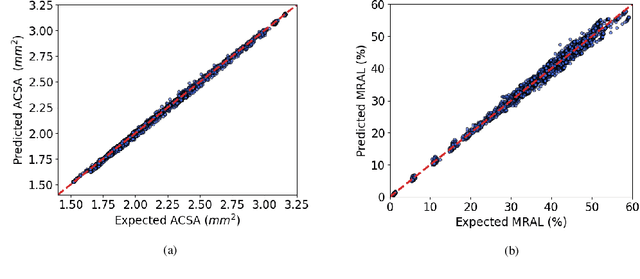
In-Stent Restenosis is a recurrence of coronary artery narrowing due to vascular injury caused by balloon dilation and stent placement. It may lead to the relapse of angina symptoms or to an acute coronary syndrome. An uncertainty quantification of a model for In-Stent Restenosis with four uncertain parameters (endothelium regeneration time, the threshold strain for smooth muscle cells bond breaking, blood flow velocity and the percentage of fenestration in the internal elastic lamina) is presented. Two quantities of interest were studied, namely the average cross-sectional area and the maximum relative area loss in a vessel. Due to the computational intensity of the model and the number of evaluations required in the uncertainty quantification, a surrogate model, based on Gaussian process regression with proper orthogonal decomposition, was developed which subsequently replaced the original In-Stent Restenosis model in the uncertainty quantification. A detailed analysis of the uncertainty propagation and sensitivity analysis is presented. Around 11% and 16% of uncertainty are observed on the average cross-sectional area and maximum relative area loss respectively, and the uncertainty estimates show that a higher fenestration mainly determines uncertainty in the neointimal growth at the initial stage of the process. On the other hand, the uncertainty in blood flow velocity and endothelium regeneration time mainly determine the uncertainty in the quantities of interest at the later, clinically relevant stages of the restenosis process. The uncertainty in the threshold strain is relatively small compared to the other uncertain parameters.
Theoretical Guarantees of Fictitious Discount Algorithms for Episodic Reinforcement Learning and Global Convergence of Policy Gradient Methods
Sep 13, 2021When designing algorithms for finite-time-horizon episodic reinforcement learning problems, a common approach is to introduce a fictitious discount factor and use stationary policies for approximations. Empirically, it has been shown that the fictitious discount factor helps reduce variance, and stationary policies serve to save the per-iteration computational cost. Theoretically, however, there is no existing work on convergence analysis for algorithms with this fictitious discount recipe. This paper takes the first step towards analyzing these algorithms. It focuses on two vanilla policy gradient (VPG) variants: the first being a widely used variant with discounted advantage estimations (DAE), the second with an additional fictitious discount factor in the score functions of the policy gradient estimators. Non-asymptotic convergence guarantees are established for both algorithms, and the additional discount factor is shown to reduce the bias introduced in DAE and thus improve the algorithm convergence asymptotically. A key ingredient of our analysis is to connect three settings of Markov decision processes (MDPs): the finite-time-horizon, the average reward and the discounted settings. To our best knowledge, this is the first theoretical guarantee on fictitious discount algorithms for the episodic reinforcement learning of finite-time-horizon MDPs, which also leads to the (first) global convergence of policy gradient methods for finite-time-horizon episodic reinforcement learning.
Generating synthetic mobility data for a realistic population with RNNs to improve utility and privacy
Jan 04, 2022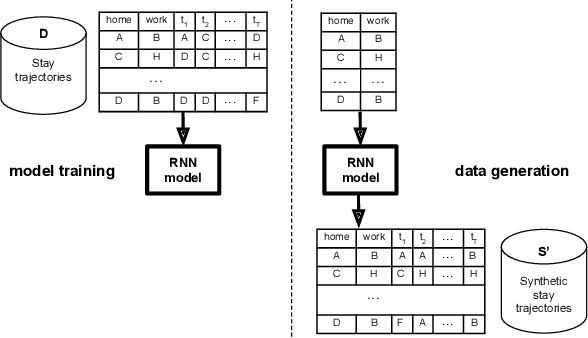
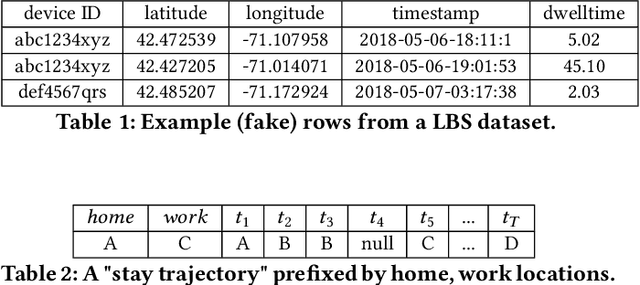
Location data collected from mobile devices represent mobility behaviors at individual and societal levels. These data have important applications ranging from transportation planning to epidemic modeling. However, issues must be overcome to best serve these use cases: The data often represent a limited sample of the population and use of the data jeopardizes privacy. To address these issues, we present and evaluate a system for generating synthetic mobility data using a deep recurrent neural network (RNN) which is trained on real location data. The system takes a population distribution as input and generates mobility traces for a corresponding synthetic population. Related generative approaches have not solved the challenges of capturing both the patterns and variability in individuals' mobility behaviors over longer time periods, while also balancing the generation of realistic data with privacy. Our system leverages RNNs' ability to generate complex and novel sequences while retaining patterns from training data. Also, the model introduces randomness used to calibrate the variation between the synthetic and real data at the individual level. This is to both capture variability in human mobility, and protect user privacy. Location based services (LBS) data from more than 22,700 mobile devices were used in an experimental evaluation across utility and privacy metrics. We show the generated mobility data retain the characteristics of the real data, while varying from the real data at the individual level, and where this amount of variation matches the variation within the real data.
Learning Hidden Patterns from Patient Multivariate Time Series Data Using Convolutional Neural Networks: A Case Study of Healthcare Cost Prediction
Sep 14, 2020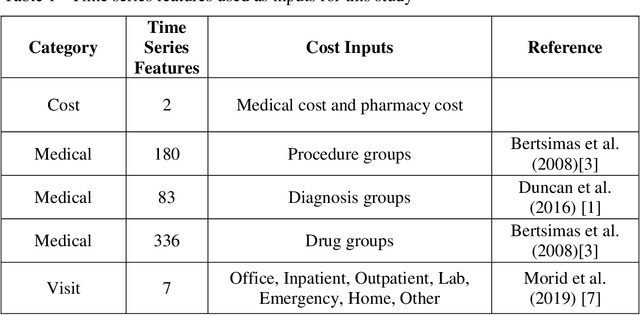
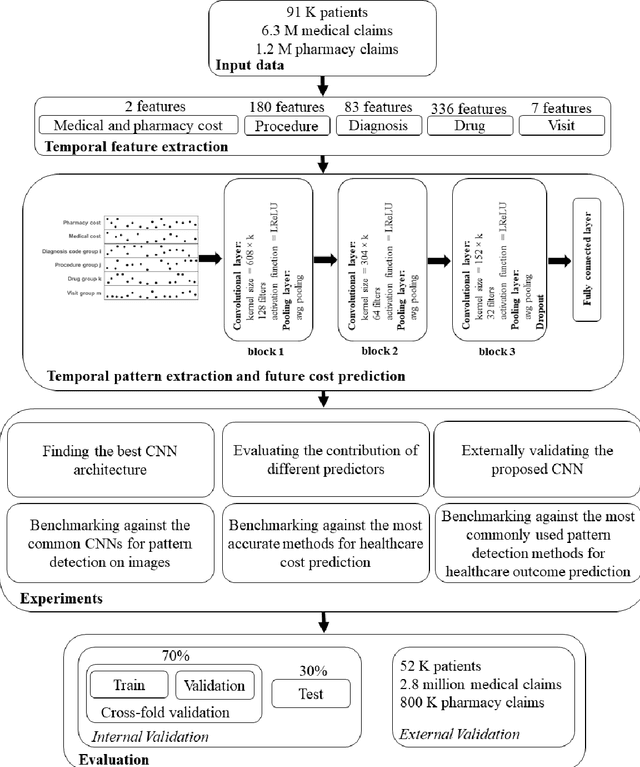
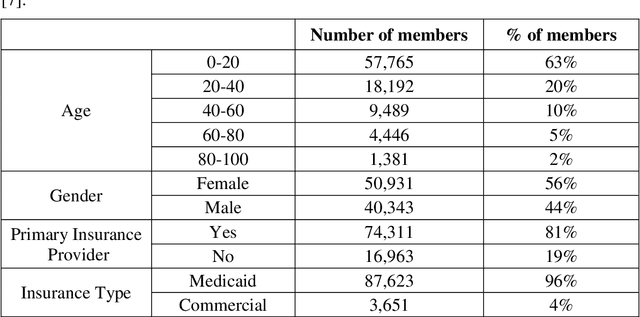
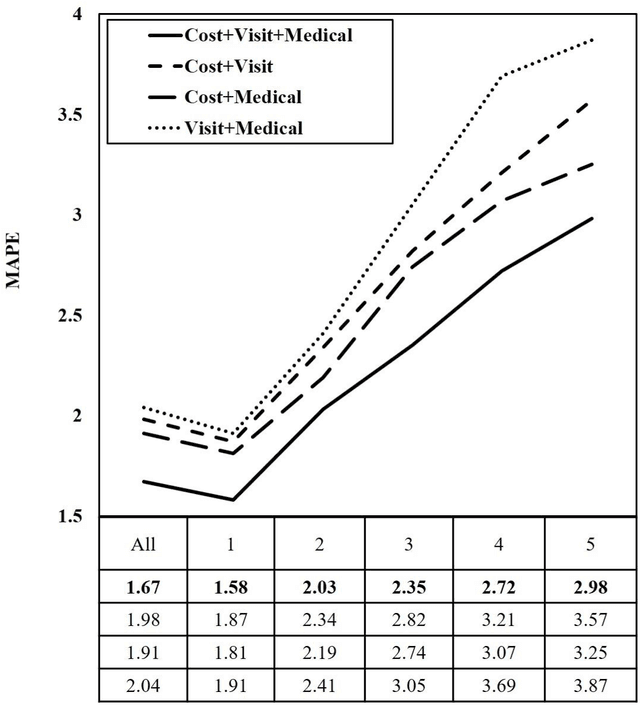
Objective: To develop an effective and scalable individual-level patient cost prediction method by automatically learning hidden temporal patterns from multivariate time series data in patient insurance claims using a convolutional neural network (CNN) architecture. Methods: We used three years of medical and pharmacy claims data from 2013 to 2016 from a healthcare insurer, where data from the first two years were used to build the model to predict costs in the third year. The data consisted of the multivariate time series of cost, visit and medical features that were shaped as images of patients' health status (i.e., matrices with time windows on one dimension and the medical, visit and cost features on the other dimension). Patients' multivariate time series images were given to a CNN method with a proposed architecture. After hyper-parameter tuning, the proposed architecture consisted of three building blocks of convolution and pooling layers with an LReLU activation function and a customized kernel size at each layer for healthcare data. The proposed CNN learned temporal patterns became inputs to a fully connected layer. Conclusions: Feature learning through the proposed CNN configuration significantly improved individual-level healthcare cost prediction. The proposed CNN was able to outperform temporal pattern detection methods that look for a pre-defined set of pattern shapes, since it is capable of extracting a variable number of patterns with various shapes. Temporal patterns learned from medical, visit and cost data made significant contributions to the prediction performance. Hyper-parameter tuning showed that considering three-month data patterns has the highest prediction accuracy. Our results showed that patients' images extracted from multivariate time series data are different from regular images, and hence require unique designs of CNN architectures.
Cloud-Based Dynamic Programming for an Electric City Bus Energy Management Considering Real-Time Passenger Load Prediction
Oct 28, 2020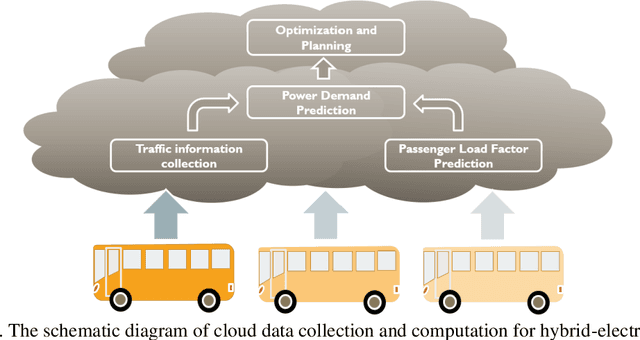
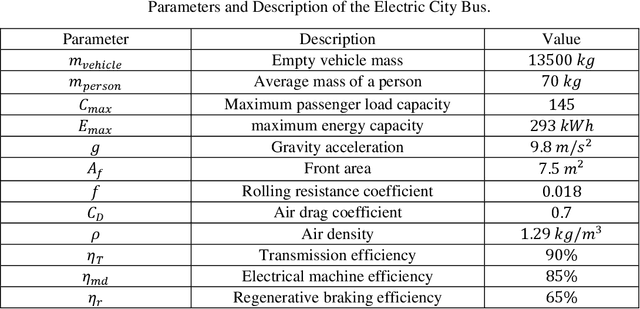
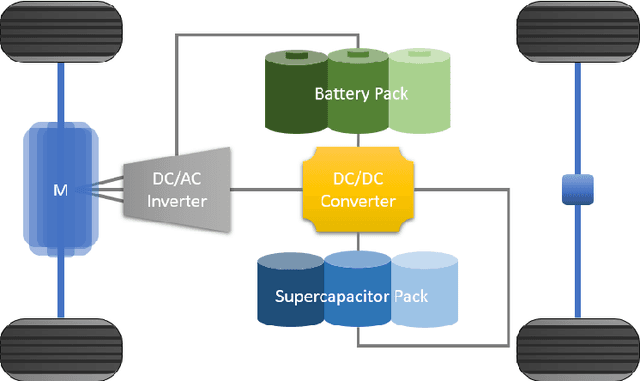

Electric city bus gains popularity in recent years for its low greenhouse gas emission, low noise level, etc. Different from a passenger car, the weight of a city bus varies significantly with different amounts of onboard passengers, which is not well studied in existing literature. This study proposes a passenger load prediction model using day-of-week, time-of-day, weather, temperatures, wind levels, and holiday information as inputs. The average model, Regression Tree, Gradient Boost Decision Tree, and Neural Networks models are compared in the passenger load prediction. The Gradient Boost Decision Tree model is selected due to its best accuracy and high stability. Given the predicted passenger load, dynamic programming algorithm determines the optimal power demand for supercapacitor and battery by optimizing the battery aging and energy usage in the cloud. Then rule extraction is conducted on dynamic programming results, and the rule is real-time loaded to onboard controllers of vehicles. The proposed cloud-based dynamic programming and rule extraction framework with the passenger load prediction shows 4% and 11% fewer bus operating costs in off-peak and peak hours, respectively. The operating cost by the proposed framework is less than 1% shy of the dynamic programming with the true passenger load information.
Seasonally-Adjusted Auto-Regression of Vector Time Series
Nov 04, 2019
We present a simple algorithm to forecast vector time series, that is robust against missing data, in both training and inference. It models seasonal annual, weekly, and daily baselines, and a Gaussian process for the seasonally-adjusted residuals. We develop a custom truncated eigendecomposition to fit a low-rank plus block-diagonal Gaussian kernel. Inference is performed with the Schur complement, using Tikhonov regularization to prevent overfit, and the Woodbury formula to invert sub-matrices of the kernel efficiently. Inference requires an amount of memory and computation linear in the dimension of the time series, and so the model can scale to very large datasets. We also propose a simple "greedy" grid search for automatic hyper-parameter tuning. The paper is accompanied by tsar (i.e., time series auto-regressor), a Python library that implements the algorithm.
Adverse Media Mining for KYC and ESG Compliance
Oct 22, 2021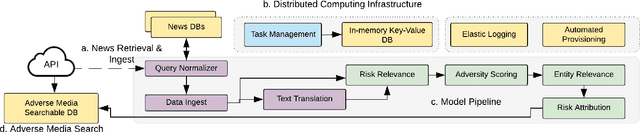
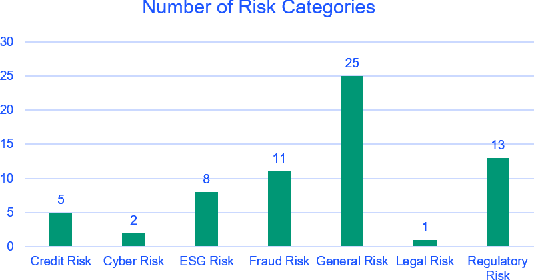
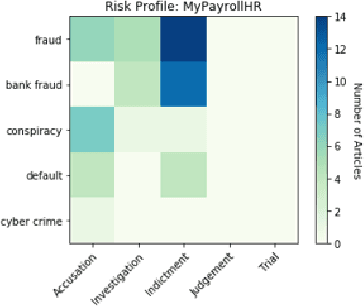
In recent years, institutions operating in the global market economy face growing risks stemming from non-financial risk factors such as cyber, third-party, and reputational outweighing traditional risks of credit and liquidity. Adverse media or negative news screening is crucial for the identification of such non-financial risks. Typical tools for screening are not real-time, involve manual searches, require labor-intensive monitoring of information sources. Moreover, they are costly processes to maintain up-to-date with complex regulatory requirements and the institution's evolving risk appetite. In this extended abstract, we present an automated system to conduct both real-time and batch search of adverse media for users' queries (person or organization entities) using news and other open-source, unstructured sources of information. Our scalable, machine-learning driven approach to high-precision, adverse news filtering is based on four perspectives - relevance to risk domains, search query (entity) relevance, adverse sentiment analysis, and risk encoding. With the help of model evaluations and case studies, we summarize the performance of our deployed application.
Policy Search for Model Predictive Control with Application to Agile Drone Flight
Dec 16, 2021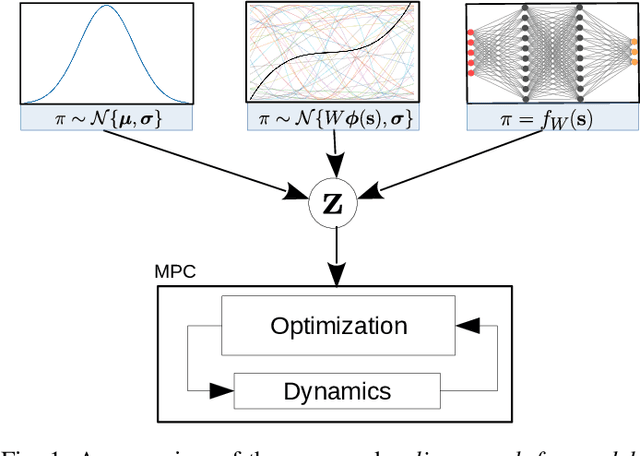
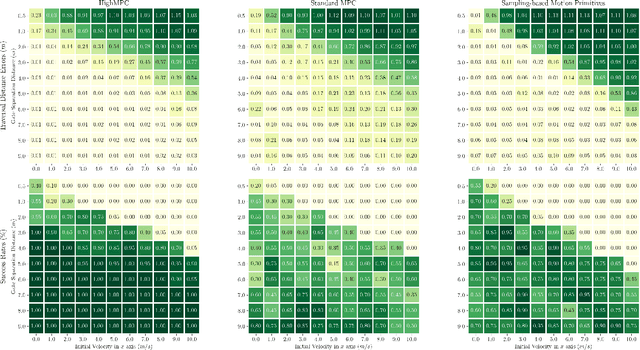


Policy Search and Model Predictive Control~(MPC) are two different paradigms for robot control: policy search has the strength of automatically learning complex policies using experienced data, while MPC can offer optimal control performance using models and trajectory optimization. An open research question is how to leverage and combine the advantages of both approaches. In this work, we provide an answer by using policy search for automatically choosing high-level decision variables for MPC, which leads to a novel policy-search-for-model-predictive-control framework. Specifically, we formulate the MPC as a parameterized controller, where the hard-to-optimize decision variables are represented as high-level policies. Such a formulation allows optimizing policies in a self-supervised fashion. We validate this framework by focusing on a challenging problem in agile drone flight: flying a quadrotor through fast-moving gates. Experiments show that our controller achieves robust and real-time control performance in both simulation and the real world. The proposed framework offers a new perspective for merging learning and control.