 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Enabling Fast Differentially Private SGD via Just-in-Time Compilation and Vectorization
Oct 18, 2020
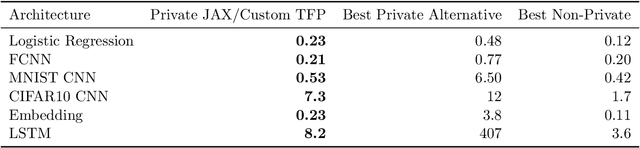
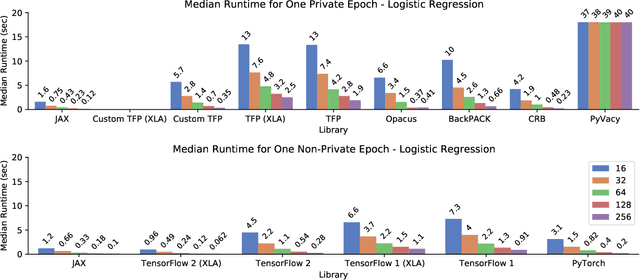
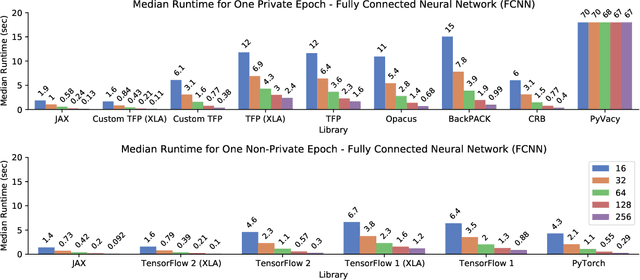
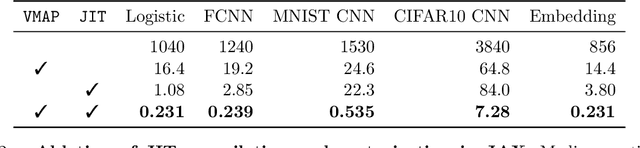
A common pain point in differentially private machine learning is the significant runtime overhead incurred when executing Differentially Private Stochastic Gradient Descent (DPSGD), which may be as large as two orders of magnitude. We thoroughly demonstrate that by exploiting powerful language primitives, including vectorization, just-in-time compilation, and static graph optimization, one can dramatically reduce these overheads, in many cases nearly matching the best non-private running times. These gains are realized in two frameworks: JAX and TensorFlow. JAX provides rich support for these primitives as core features of the language through the XLA compiler. We also rebuild core parts of TensorFlow Privacy, integrating features from TensorFlow 2 as well as XLA compilation, granting significant memory and runtime improvements over the current release version. These approaches allow us to achieve up to 50x speedups in comparison to the best alternatives. Our code is available at https://github.com/TheSalon/fast-dpsgd.
GraphPAS: Parallel Architecture Search for Graph Neural Networks
Dec 07, 2021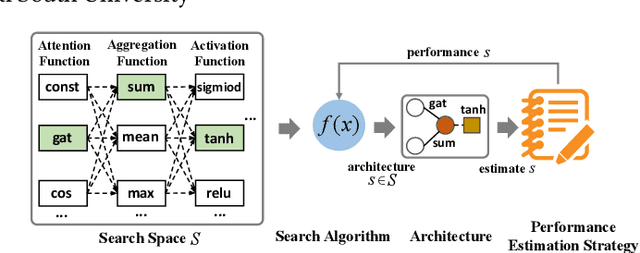

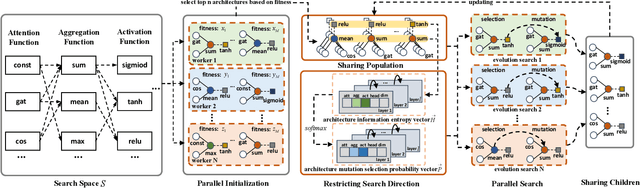
Graph neural architecture search has received a lot of attention as Graph Neural Networks (GNNs) has been successfully applied on the non-Euclidean data recently. However, exploring all possible GNNs architectures in the huge search space is too time-consuming or impossible for big graph data. In this paper, we propose a parallel graph architecture search (GraphPAS) framework for graph neural networks. In GraphPAS, we explore the search space in parallel by designing a sharing-based evolution learning, which can improve the search efficiency without losing the accuracy. Additionally, architecture information entropy is adopted dynamically for mutation selection probability, which can reduce space exploration. The experimental result shows that GraphPAS outperforms state-of-art models with efficiency and accuracy simultaneously.
MegLoc: A Robust and Accurate Visual Localization Pipeline
Nov 25, 2021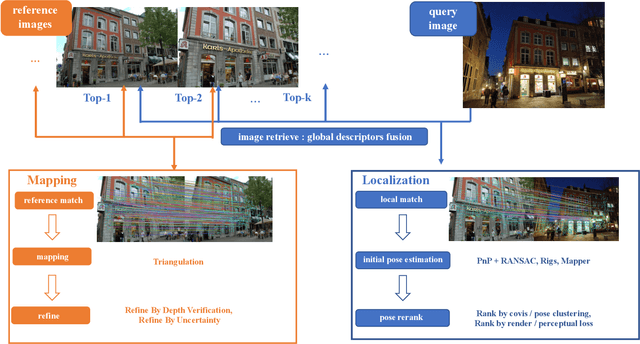
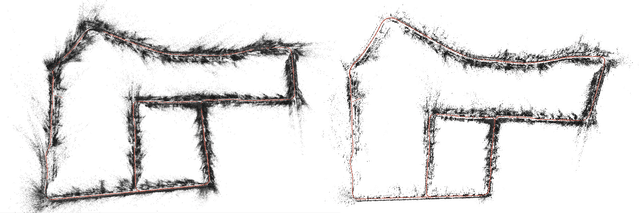
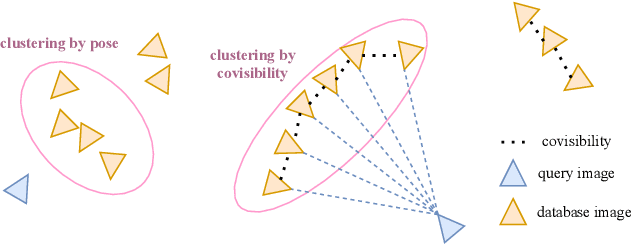

In this paper, we present a visual localization pipeline, namely MegLoc, for robust and accurate 6-DoF pose estimation under varying scenarios, including indoor and outdoor scenes, different time across a day, different seasons across a year, and even across years. MegLoc achieves state-of-the-art results on a range of challenging datasets, including winning the Outdoor and Indoor Visual Localization Challenge of ICCV 2021 Workshop on Long-term Visual Localization under Changing Conditions, as well as the Re-localization Challenge for Autonomous Driving of ICCV 2021 Workshop on Map-based Localization for Autonomous Driving.
Driver Drowsiness Detection Using Ensemble Convolutional Neural Networks on YawDD
Dec 20, 2021
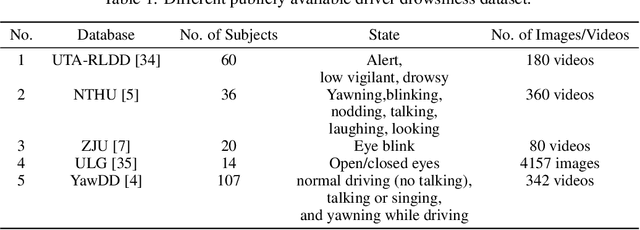
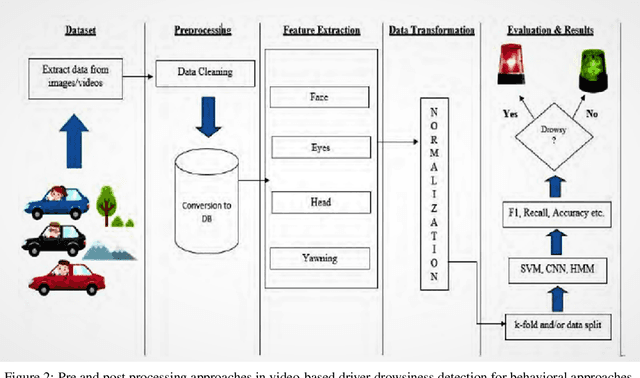
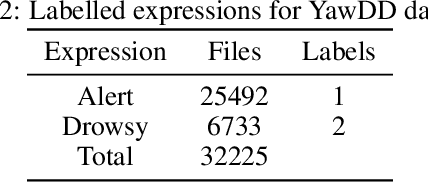
Driver drowsiness detection using videos/images is one of the most essential areas in today's time for driver safety. The development of deep learning techniques, notably Convolutional Neural Networks (CNN), applied in computer vision applications such as drowsiness detection, has shown promising results due to the tremendous increase in technology in the recent few decades. Eyes that are closed or blinking excessively, yawning, nodding, and occlusion are all key aspects of drowsiness. In this work, we have applied four different Convolutional Neural Network (CNN) techniques on the YawDD dataset to detect and examine the extent of drowsiness depending on the yawning frequency with specific pose and occlusion variation. Preliminary computational results show that our proposed Ensemble Convolutional Neural Network (ECNN) outperformed the traditional CNN-based approach by achieving an F1 score of 0.935, whereas the other three CNN, such as CNN1, CNN2, and CNN3 approaches gained 0.92, 0.90, and 0.912 F1 scores, respectively.
Contrastively Disentangled Sequential Variational Autoencoder
Oct 22, 2021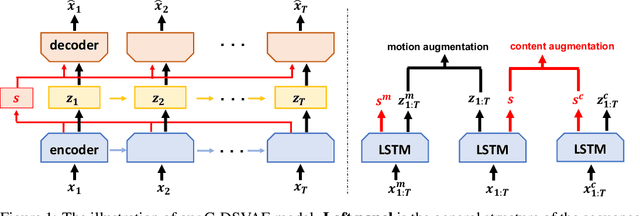

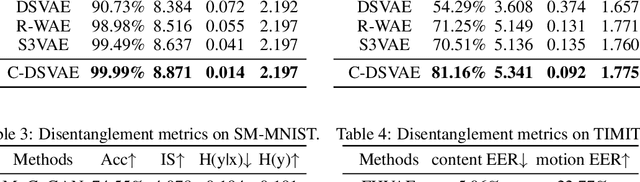
Self-supervised disentangled representation learning is a critical task in sequence modeling. The learnt representations contribute to better model interpretability as well as the data generation, and improve the sample efficiency for downstream tasks. We propose a novel sequence representation learning method, named Contrastively Disentangled Sequential Variational Autoencoder (C-DSVAE), to extract and separate the static (time-invariant) and dynamic (time-variant) factors in the latent space. Different from previous sequential variational autoencoder methods, we use a novel evidence lower bound which maximizes the mutual information between the input and the latent factors, while penalizes the mutual information between the static and dynamic factors. We leverage contrastive estimations of the mutual information terms in training, together with simple yet effective augmentation techniques, to introduce additional inductive biases. Our experiments show that C-DSVAE significantly outperforms the previous state-of-the-art methods on multiple metrics.
Reactive Message Passing for Scalable Bayesian Inference
Dec 25, 2021
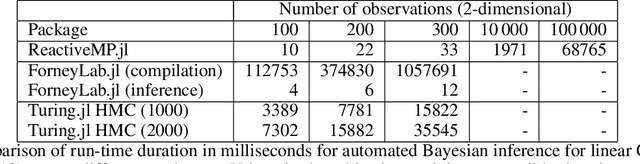
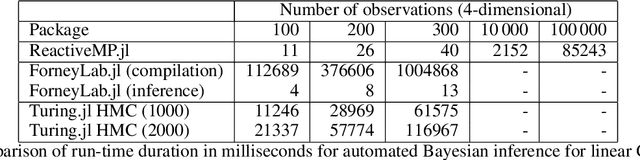
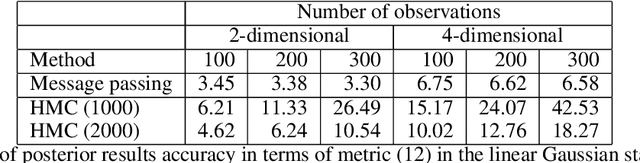
We introduce Reactive Message Passing (RMP) as a framework for executing schedule-free, robust and scalable message passing-based inference in a factor graph representation of a probabilistic model. RMP is based on the reactive programming style that only describes how nodes in a factor graph react to changes in connected nodes. The absence of a fixed message passing schedule improves robustness, scalability and execution time of the inference procedure. We also present ReactiveMP.jl, which is a Julia package for realizing RMP through minimization of a constrained Bethe free energy. By user-defined specification of local form and factorization constraints on the variational posterior distribution, ReactiveMP.jl executes hybrid message passing algorithms including belief propagation, variational message passing, expectation propagation, and expectation maximisation update rules. Experimental results demonstrate the improved performance of ReactiveMP-based RMP in comparison to other Julia packages for Bayesian inference across a range of probabilistic models. In particular, we show that the RMP framework is able to run Bayesian inference for large-scale probabilistic state space models with hundreds of thousands of random variables on a standard laptop computer.
Reachable Sets for Safe, Real-Time Manipulator Trajectory Design
Feb 05, 2020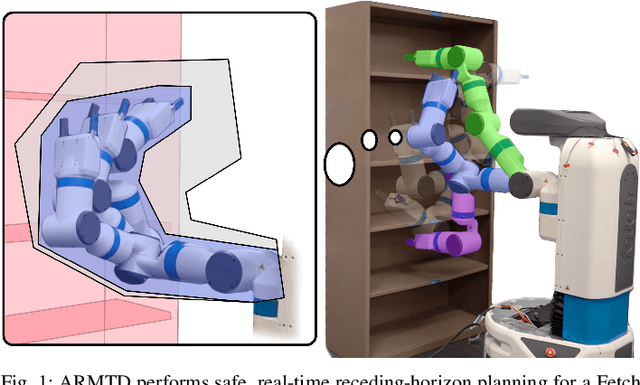
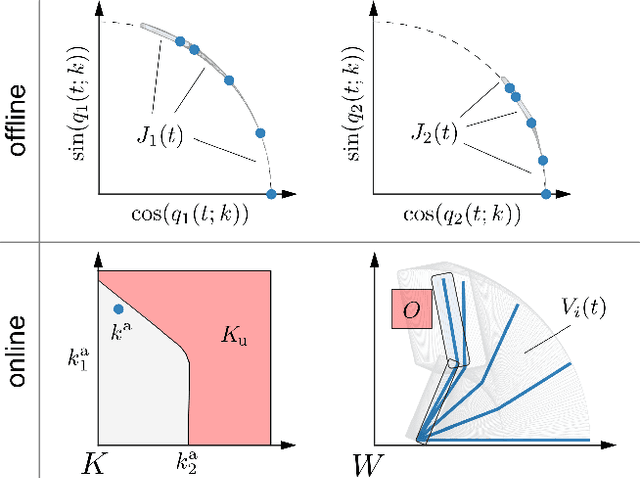
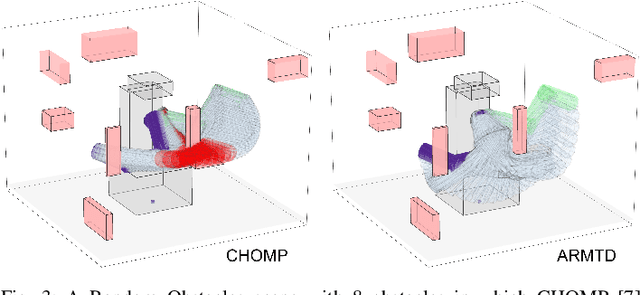
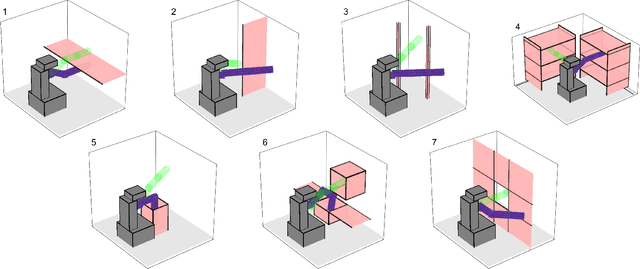
For robotic arms to operate in arbitrary environments, especially near people, it is critical to certify the safety of their motion planning algorithms. However, there is often a trade-off between safety and real-time performance; one can either carefully design safe plans, or rapidly generate potentially-unsafe plans. This work presents a receding-horizon, real-time trajectory planner with safety guarantees, called ARMTD (Autonomous Reachability-based Manipulator Trajectory Design). The method first computes (offline) a reachable set of parameterized trajectories for each joint of an arm. Each trajectory includes a fail-safe maneuver (braking to a stop). At runtime, in each receding-horizon planning iteration, ARMTD constructs a reachable set of the entire arm in workspace and intersects it with obstacles to generate sub-differentiable and provably-conservative collision-avoidance constraints on the trajectory parameters. ARMTD then performs trajectory optimization for an arbitrary cost function on the parameters, subject to these constraints. On a 6 degree-of-freedom arm, ARMTD outperforms CHOMP in simulation and completes a variety of real-time planning tasks on hardware, all without collisions.
Inferring Individual Level Causal Models from Graph-based Relational Time Series
Jan 16, 2020
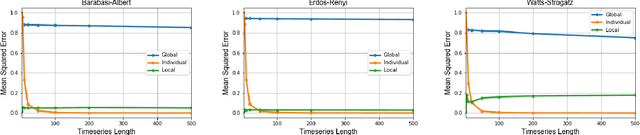
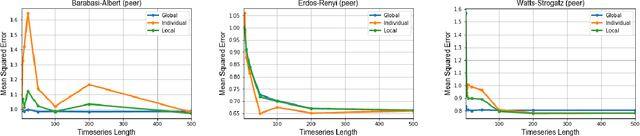
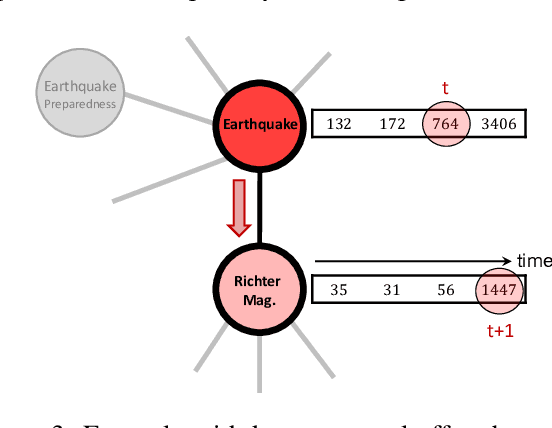
In this work, we formalize the problem of causal inference over graph-based relational time-series data where each node in the graph has one or more time-series associated to it. We propose causal inference models for this problem that leverage both the graph topology and time-series to accurately estimate local causal effects of nodes. Furthermore, the relational time-series causal inference models are able to estimate local effects for individual nodes by exploiting local node-centric temporal dependencies and topological/structural dependencies. We show that simpler causal models that do not consider the graph topology are recovered as special cases of the proposed relational time-series causal inference model. We describe the conditions under which the resulting estimate can be used to estimate a causal effect, and describe how the Durbin-Wu-Hausman test of specification can be used to test for the consistency of the proposed estimator from data. Empirically, we demonstrate the effectiveness of the causal inference models on both synthetic data with known ground-truth and a large-scale observational relational time-series data set collected from Wikipedia.
Visual Microfossil Identification via Deep Metric Learning
Jan 04, 2022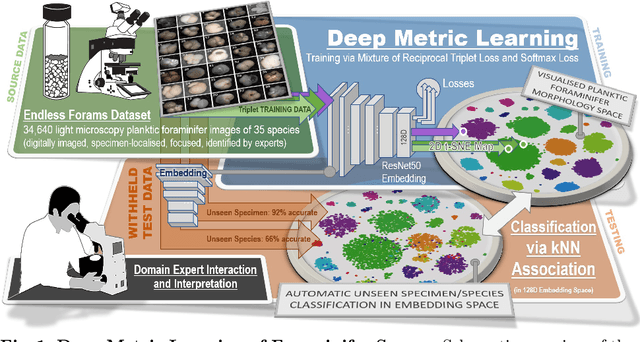
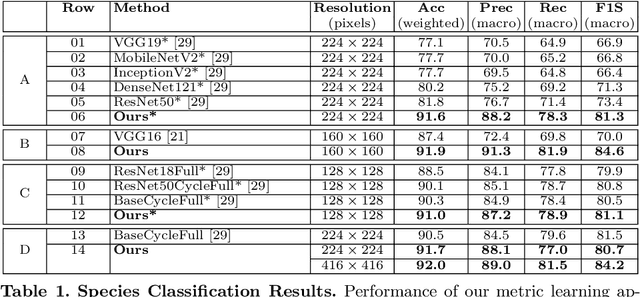
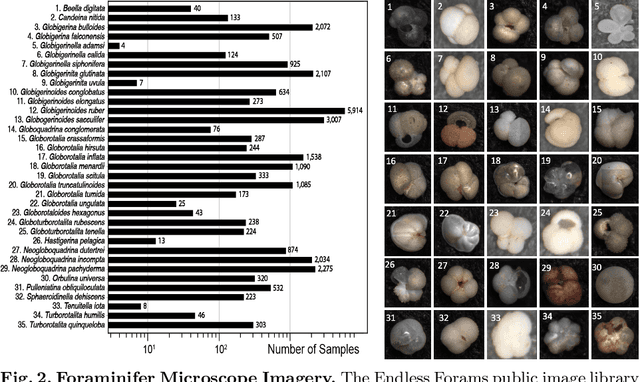
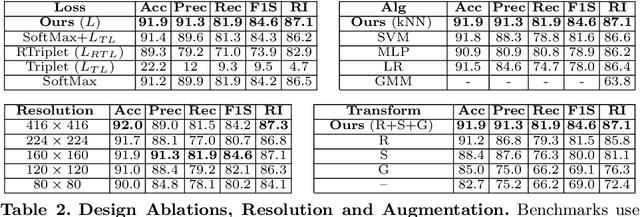
We apply deep metric learning for the first time to the prob-lem of classifying planktic foraminifer shells on microscopic images. This species recognition task is an important information source and scientific pillar for reconstructing past climates. All foraminifer CNN recognition pipelines in the literature produce black-box classifiers that lack visualisation options for human experts and cannot be applied to open set problems. Here, we benchmark metric learning against these pipelines, produce the first scientific visualisation of the phenotypic planktic foraminifer morphology space, and demonstrate that metric learning can be used to cluster species unseen during training. We show that metric learning out-performs all published CNN-based state-of-the-art benchmarks in this domain. We evaluate our approach on the 34,640 expert-annotated images of the Endless Forams public library of 35 modern planktic foraminifera species. Our results on this data show leading 92% accuracy (at 0.84 F1-score) in reproducing expert labels on withheld test data, and 66.5% accuracy (at 0.70 F1-score) when clustering species never encountered in training. We conclude that metric learning is highly effective for this domain and serves as an important tool towards expert-in-the-loop automation of microfossil identification. Key code, network weights, and data splits are published with this paper for full reproducibility.
Quadrupedal Robotic Guide Dog with Vocal Human-Robot Interaction
Nov 25, 2021
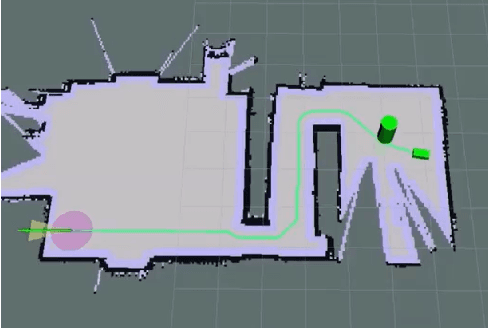
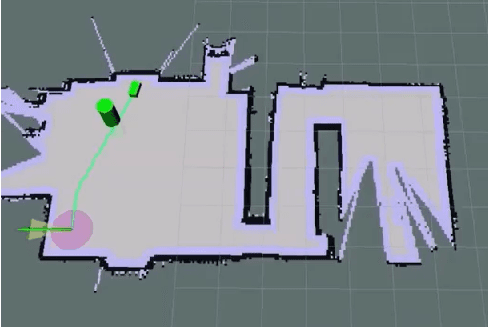
Guide dogs play a critical role in the lives of many, however training them is a time- and labor-intensive process. We are developing a method to allow an autonomous robot to physically guide humans using direct human-robot communication. The proposed algorithm will be deployed on a Unitree A1 quadrupedal robot and will autonomously navigate the person to their destination while communicating with the person using a speech interface compatible with the robot. This speech interface utilizes cloud based services such as Amazon Polly and Google Cloud to serve as the text-to-speech and speech-to-text engines.