 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-Time Adaptive Velocity Optimization for Autonomous Electric Cars at the Limits of Handling
Dec 25, 2020
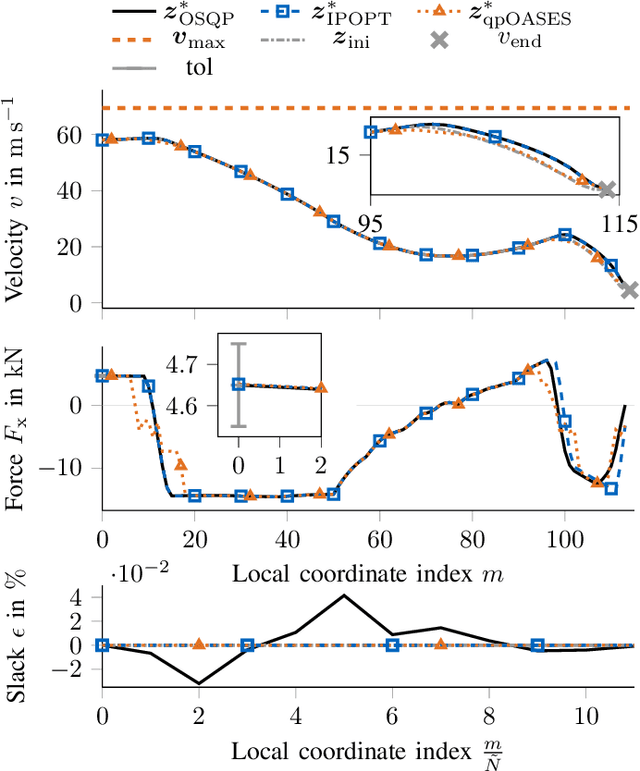
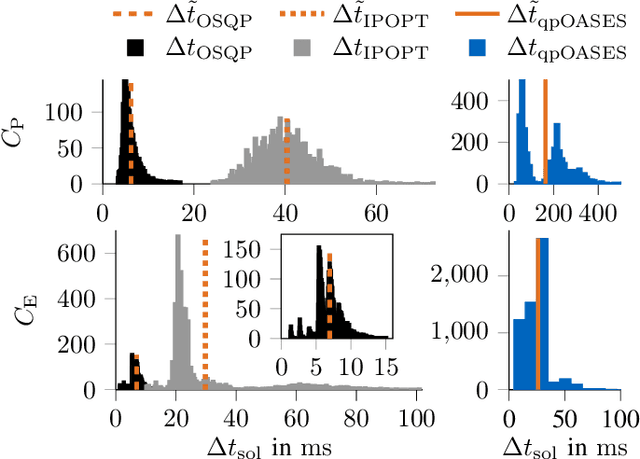

With the evolution of self-driving cars, autonomous racing series like Roborace and the Indy Autonomous Challenge are rapidly attracting growing attention. Researchers participating in these competitions hope to subsequently transfer their developed functionality to passenger vehicles, in order to improve self-driving technology for reasons of safety, and due to environmental and social benefits. The race track has the advantage of being a safe environment where challenging situations for the algorithms are permanently created. To achieve minimum lap times on the race track, it is important to gather and process information about external influences including, e.g., the position of other cars and the friction potential between the road and the tires. Furthermore, the predicted behavior of the ego-car's propulsion system is crucial for leveraging the available energy as efficiently as possible. In this paper, we therefore present an optimization-based velocity planner, mathematically formulated as a multi-parametric Sequential Quadratic Problem (mpSQP). This planner can handle a spatially and temporally varying friction coefficient, and transfer a race Energy Strategy (ES) to the road. It further handles the velocity-profile-generation task for performance and emergency trajectories in real time on the vehicle's Electronic Control Unit (ECU).
A Multi-Resolution Front-End for End-to-End Speech Anti-Spoofing
Oct 11, 2021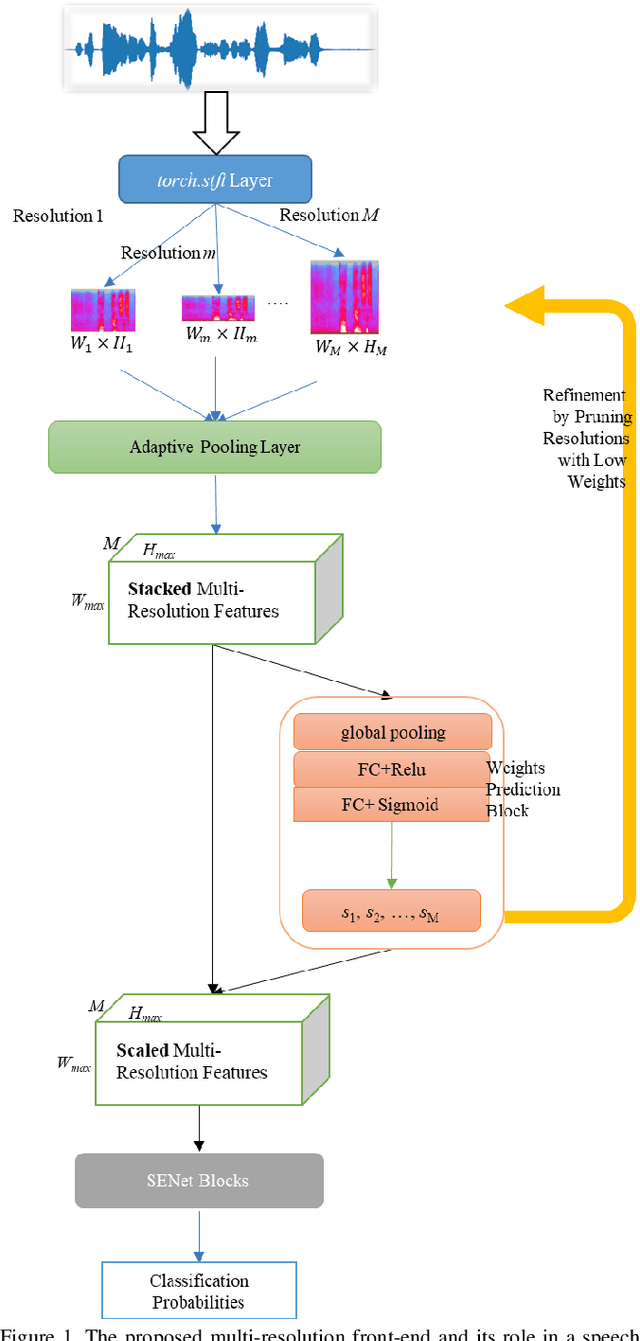
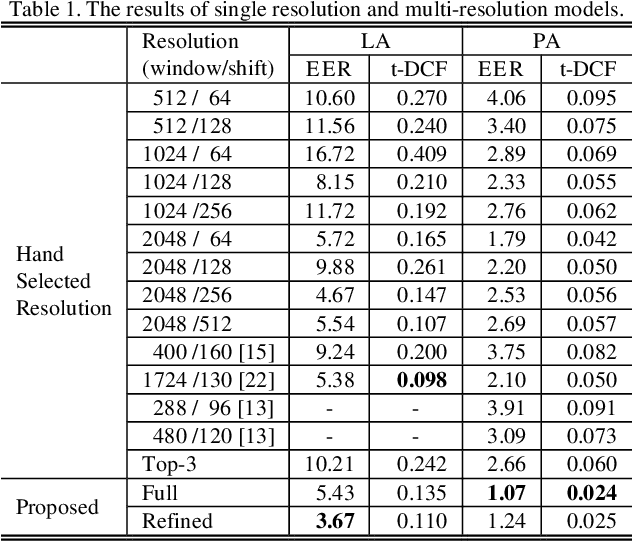
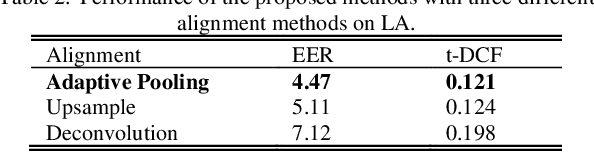
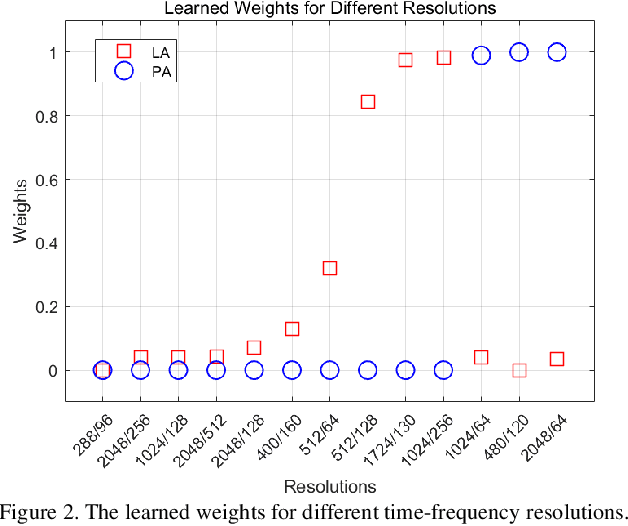
The choice of an optimal time-frequency resolution is usually a difficult but important step in tasks involving speech signal classification, e.g., speech anti-spoofing. The variations of the performance with different choices of timefrequency resolutions can be as large as those with different model architectures, which makes it difficult to judge what the improvement actually comes from when a new network architecture is invented and introduced as the classifier. In this paper, we propose a multi-resolution front-end for feature extraction in an end-to-end classification framework. Optimal weighted combinations of multiple time-frequency resolutions will be learned automatically given the objective of a classification task. Features extracted with different time-frequency resolutions are weighted and concatenated as inputs to the successive networks, where the weights are predicted by a learnable neural network inspired by the weighting block in squeeze-and-excitation networks (SENet). Furthermore, the refinement of the chosen timefrequency resolutions is investigated by pruning the ones with relatively low importance, which reduces the complexity and size of the model. The proposed method is evaluated on the tasks of speech anti-spoofing in ASVSpoof 2019 and its superiority has been justified by comparing with similar baselines.
Automatic Tuning of Federated Learning Hyper-Parameters from System Perspective
Oct 06, 2021

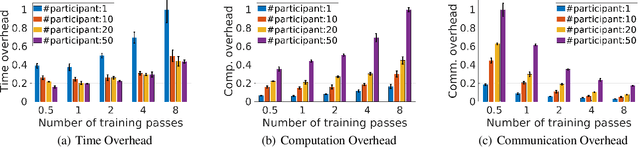
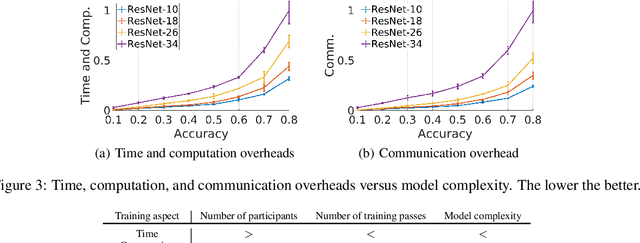
Federated learning (FL) is a distributed model training paradigm that preserves clients' data privacy. FL hyper-parameters significantly affect the training overheads in terms of time, computation, and communication. However, the current practice of manually selecting FL hyper-parameters puts a high burden on FL practitioners since various applications prefer different training preferences. In this paper, we propose FedTuning, an automatic FL hyper-parameter tuning algorithm tailored to applications' diverse system requirements of FL training. FedTuning is lightweight and flexible, achieving an average of 41% improvement for different training preferences on time, computation, and communication compared to fixed FL hyper-parameters. FedTuning is available at https://github.com/dtczhl/FedTuning.
Learning Large Neighborhood Search Policy for Integer Programming
Nov 01, 2021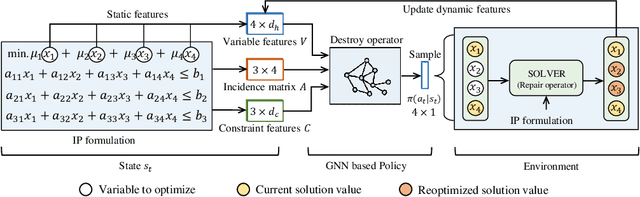

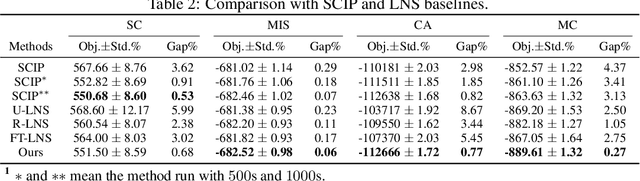
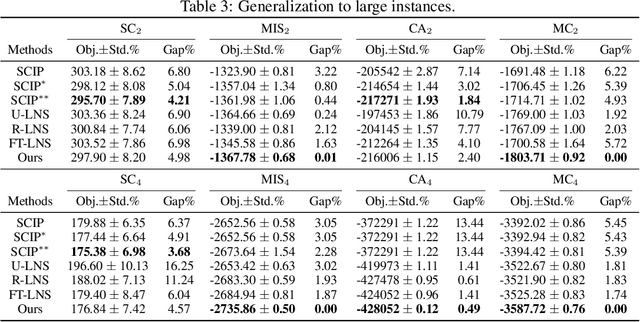
We propose a deep reinforcement learning (RL) method to learn large neighborhood search (LNS) policy for integer programming (IP). The RL policy is trained as the destroy operator to select a subset of variables at each step, which is reoptimized by an IP solver as the repair operator. However, the combinatorial number of variable subsets prevents direct application of typical RL algorithms. To tackle this challenge, we represent all subsets by factorizing them into binary decisions on each variable. We then design a neural network to learn policies for each variable in parallel, trained by a customized actor-critic algorithm. We evaluate the proposed method on four representative IP problems. Results show that it can find better solutions than SCIP in much less time, and significantly outperform other LNS baselines with the same runtime. Moreover, these advantages notably persist when the policies generalize to larger problems. Further experiments with Gurobi also reveal that our method can outperform this state-of-the-art commercial solver within the same time limit.
Body Models in Humans and Robots
Jan 20, 2022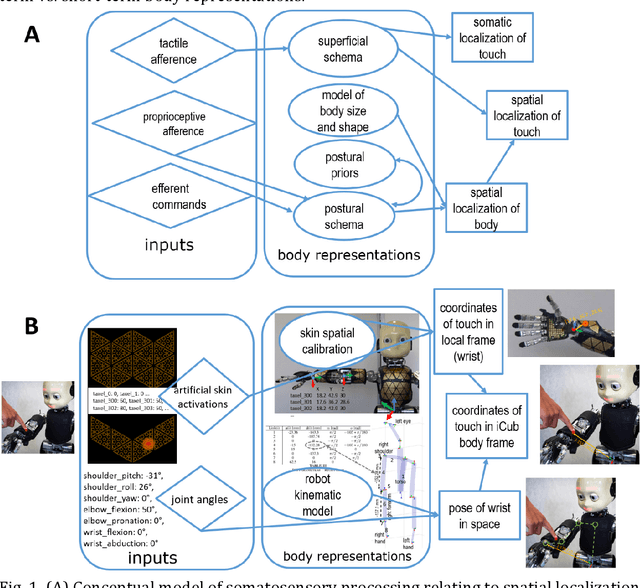
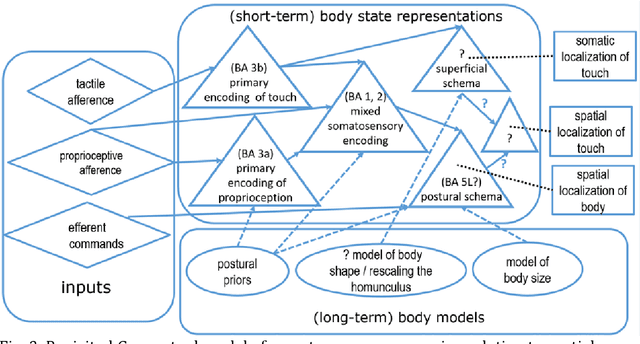
Neurocognitive models of higher-level somatosensory processing have emphasised the role of stored body representations in interpreting real-time sensory signals coming from the body (Longo, Azanon and Haggard, 2010; Tame, Azanon and Longo, 2019). The need for such stored representations arises from the fact that immediate sensory signals coming from the body do not specify metric details about body size and shape. Several aspects of somatoperception, therefore, require that immediate sensory signals be combined with stored body representations. This basic problem is equally true for humanoid robots and, intriguingly, neurocognitive models developed to explain human perception are strikingly similar to those developed independently for localizing touch on humanoid robots, such as the iCub, equipped with artificial electronic skin on the majority of its body surface (Roncone et al., 2014; Hoffmann, 2021). In this chapter, we will review the key features of these models, discuss their similarities and differences to each other, and to other models in the literature. Using robots as embodied computational models is an example of synthetic methodology or 'understanding by building' (e.g., Hoffmann and Pfeifer, 2018), computational embodied neuroscience (Caligiore et al., 2010) or 'synthetic psychology of the self' (Prescott and Camilleri, 2019). Such models have the advantage that they need to be worked out into every detail, making any theory explicit and complete. There is also an additional way of (pre)validating such a theory other than comparing to the biological or psychological phenomenon studied by simply verifying that a particular implementation really performs the task: can the robot localize where it is being touched (see https://youtu.be/pfse424t5mQ)?
* 14 pages, 2 figures
An Application of Pseudo-Log-Likelihoods to Natural Language Scoring
Jan 23, 2022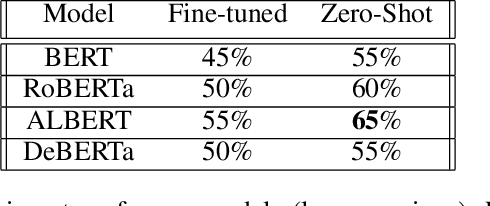


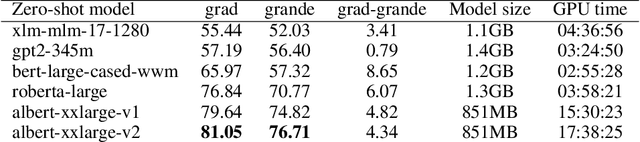
Language models built using semi-supervised machine learning on large corpora of natural language have very quickly enveloped the fields of natural language generation and understanding. In this paper we apply a zero-shot approach independently developed by a number of researchers now gaining recognition as a significant alternative to fine-tuning for evaluation on common sense tasks. A language model with relatively few parameters and training steps compared to a more recent language model (T5) can outperform it on a recent large data set (TimeDial), while displaying robustness in its performance across a similar class of language tasks. Surprisingly, this result is achieved by using a hyperparameter-free zero-shot method with the smaller model, compared to fine-tuning to the larger model. We argue that robustness of the smaller model ought to be understood in terms of compositionality, in a sense that we draw from recent literature on a class of similar models. We identify a practical cost for our method and model: high GPU-time for natural language evaluation. The zero-shot measurement technique that produces remarkable stability, both for ALBERT and other BERT variants, is an application of pseudo-log-likelihoods to masked language models for the relative measurement of probability for substitution alternatives in forced choice language tasks such as the Winograd Schema Challenge, Winogrande, and others. One contribution of this paper is to bring together a number of similar, but independent strands of research. We produce some absolute state-of-the-art results for common sense reasoning in binary choice tasks, performing better than any published result in the literature, including fine-tuned efforts. We show a remarkable consistency of the model's performance under adversarial settings, which we argue is best explained by the model's compositionality of representations.
Exploiting Bi-directional Global Transition Patterns and Personal Preferences for Missing POI Category Identification
Dec 31, 2021

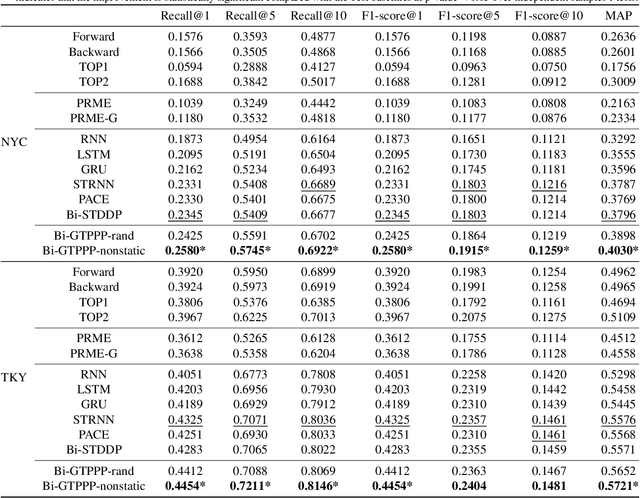
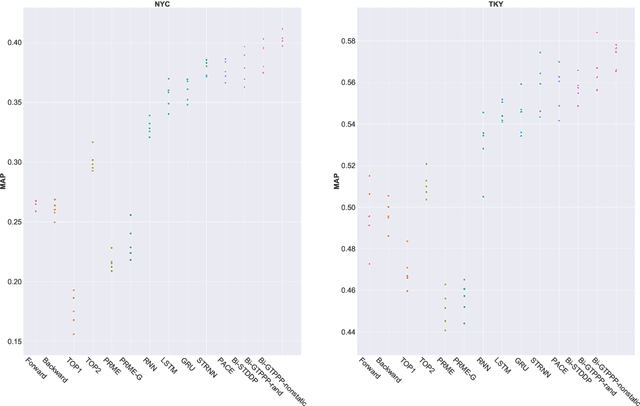
Recent years have witnessed the increasing popularity of Location-based Social Network (LBSN) services, which provides unparalleled opportunities to build personalized Point-of-Interest (POI) recommender systems. Existing POI recommendation and location prediction tasks utilize past information for future recommendation or prediction from a single direction perspective, while the missing POI category identification task needs to utilize the check-in information both before and after the missing category. Therefore, a long-standing challenge is how to effectively identify the missing POI categories at any time in the real-world check-in data of mobile users. To this end, in this paper, we propose a novel neural network approach to identify the missing POI categories by integrating both bi-directional global non-personal transition patterns and personal preferences of users. Specifically, we delicately design an attention matching cell to model how well the check-in category information matches their non-personal transition patterns and personal preferences. Finally, we evaluate our model on two real-world datasets, which clearly validate its effectiveness compared with the state-of-the-art baselines. Furthermore, our model can be naturally extended to address next POI category recommendation and prediction tasks with competitive performance.
S$^2$FPR: Crowd Counting via Self-Supervised Coarse to Fine Feature Pyramid Ranking
Jan 13, 2022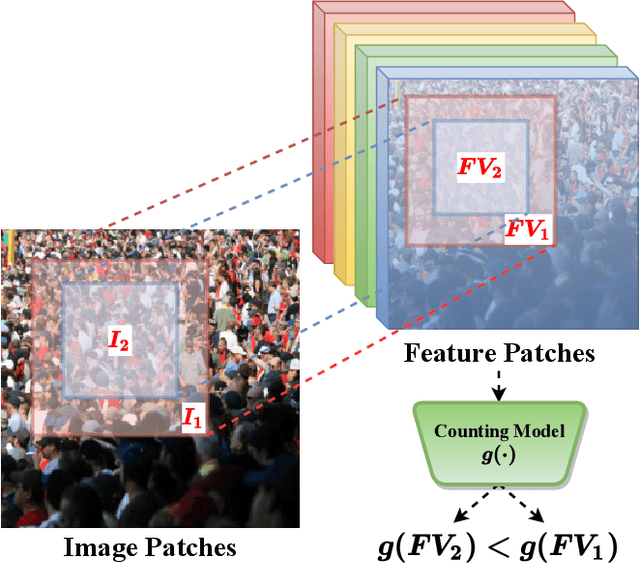
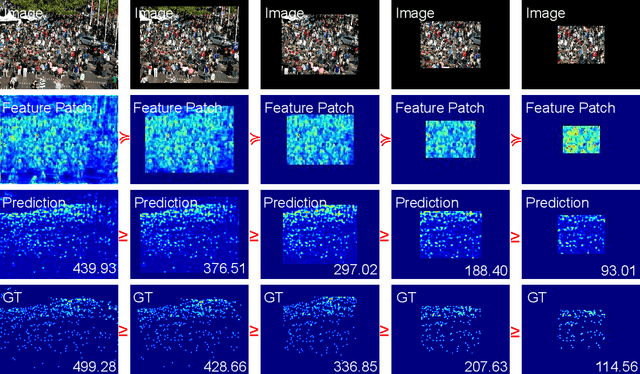
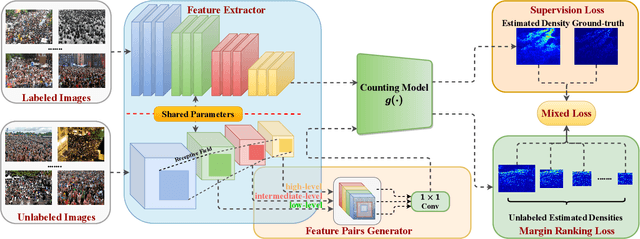

Most conventional crowd counting methods utilize a fully-supervised learning framework to learn a mapping between scene images and crowd density maps. Under the circumstances of such fully-supervised training settings, a large quantity of expensive and time-consuming pixel-level annotations are required to generate density maps as the supervision. One way to reduce costly labeling is to exploit self-structural information and inner-relations among unlabeled images. Unlike the previous methods utilizing these relations and structural information from the original image level, we explore such self-relations from the latent feature spaces because it can extract more abundant relations and structural information. Specifically, we propose S$^2$FPR which can extract structural information and learn partial orders of coarse-to-fine pyramid features in the latent space for better crowd counting with massive unlabeled images. In addition, we collect a new unlabeled crowd counting dataset (FUDAN-UCC) with 4,000 images in total for training. One by-product is that our proposed S$^2$FPR method can leverage numerous partial orders in the latent space among unlabeled images to strengthen the model representation capability and reduce the estimation errors for the crowd counting task. Extensive experiments on four benchmark datasets, i.e. the UCF-QNRF, the ShanghaiTech PartA and PartB, and the UCF-CC-50, show the effectiveness of our method compared with previous semi-supervised methods. The source code and dataset are available at https://github.com/bridgeqiqi/S2FPR.
An Analytical Update Rule for General Policy Optimization
Dec 03, 2021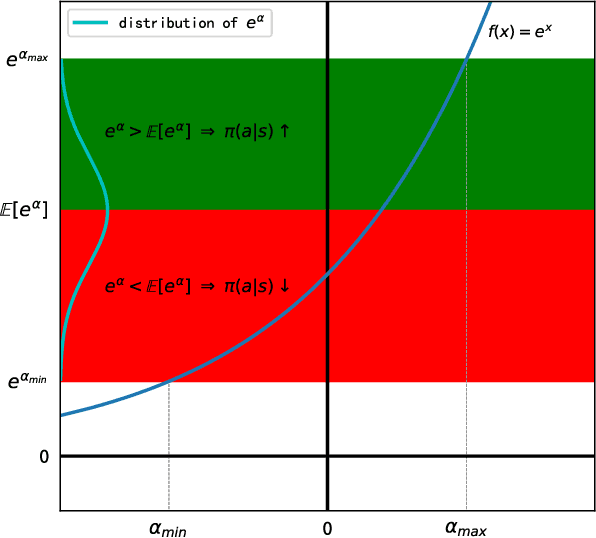
We present an analytical policy update rule that is independent of parameterized function approximators. The update rule is suitable for general stochastic policies with monotonic improvement guarantee. The update rule is derived from a closed-form trust-region solution using calculus of variation, following a new theoretical result that tightens existing bounds for policy search using trust-region methods. An explanation building a connection between the policy update rule and value-function methods is provided. Based on a recursive form of the update rule, an off-policy algorithm is derived naturally, and the monotonic improvement guarantee remains. Furthermore, the update rule extends immediately to multi-agent systems when updates are performed by one agent at a time.
Adaptive Energy Management for Self-Sustainable Wearables in Mobile Health
Jan 16, 2022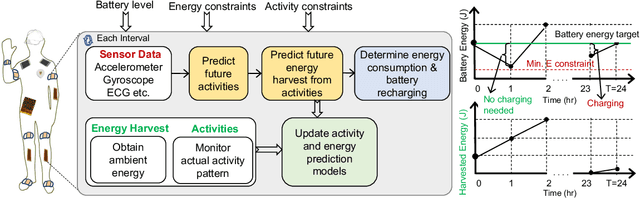
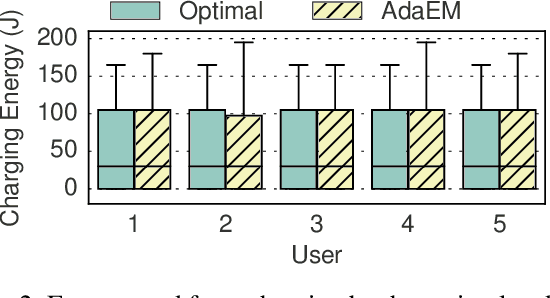
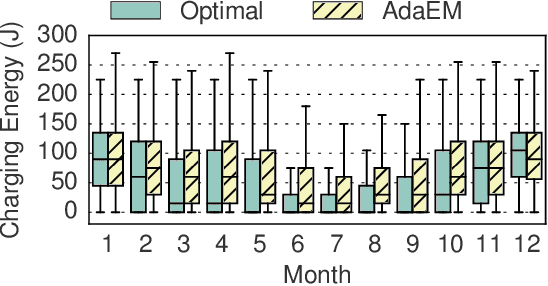
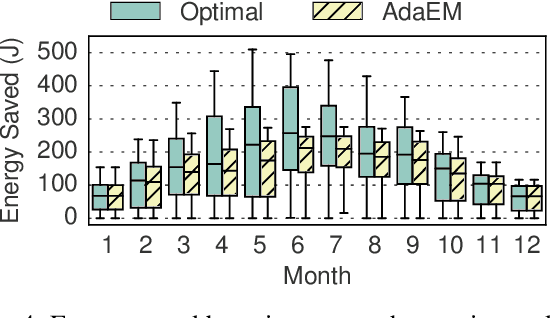
Wearable devices that integrate multiple sensors, processors, and communication technologies have the potential to transform mobile health for remote monitoring of health parameters. However, the small form factor of the wearable devices limits the battery size and operating lifetime. As a result, the devices require frequent recharging, which has limited their widespread adoption. Energy harvesting has emerged as an effective method towards sustainable operation of wearable devices. Unfortunately, energy harvesting alone is not sufficient to fulfill the energy requirements of wearable devices. This paper studies the novel problem of adaptive energy management towards the goal of self-sustainable wearables by using harvested energy to supplement the battery energy and to reduce manual recharging by users. To solve this problem, we propose a principled algorithm referred as AdaEM. There are two key ideas behind AdaEM. First, it uses machine learning (ML) methods to learn predictive models of user activity and energy usage patterns. These models allow us to estimate the potential of energy harvesting in a day as a function of the user activities. Second, it reasons about the uncertainty in predictions and estimations from the ML models to optimize the energy management decisions using a dynamic robust optimization (DyRO) formulation. We propose a light-weight solution for DyRO to meet the practical needs of deployment. We validate the AdaEM approach on a wearable device prototype consisting of solar and motion energy harvesting using real-world data of user activities. Experiments show that AdaEM achieves solutions that are within 5% of the optimal with less than 0.005% execution time and energy overhead.