 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Memetic Search for Vehicle Routing with Simultaneous Pickup-Delivery and Time Windows
Nov 16, 2020
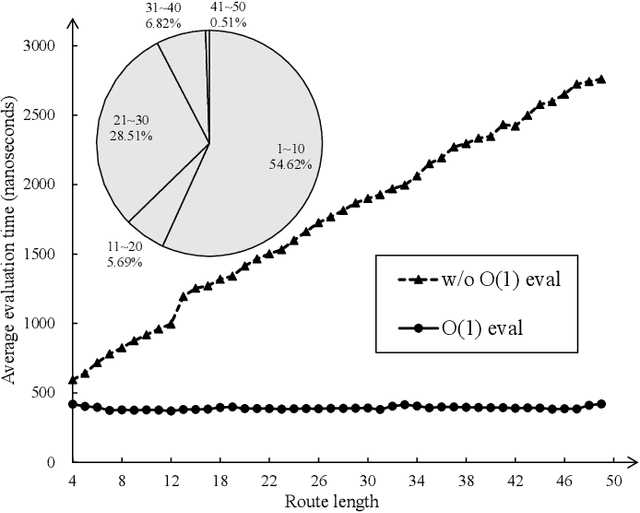
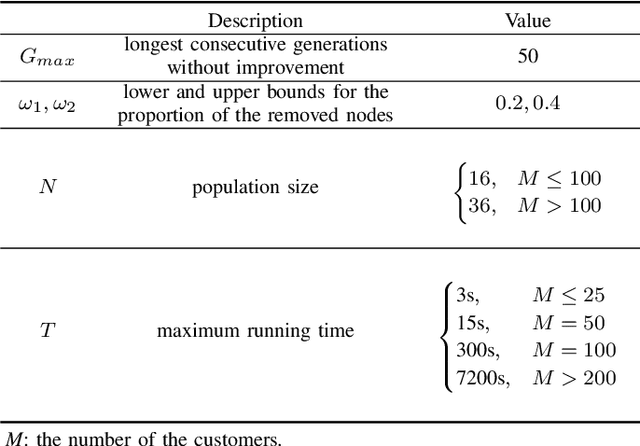
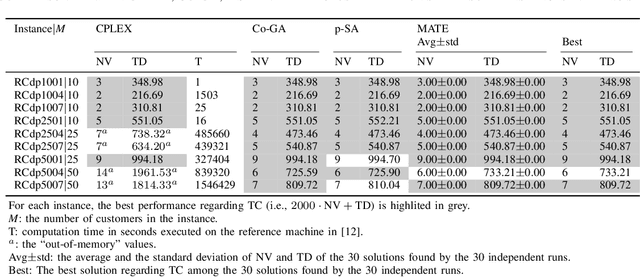
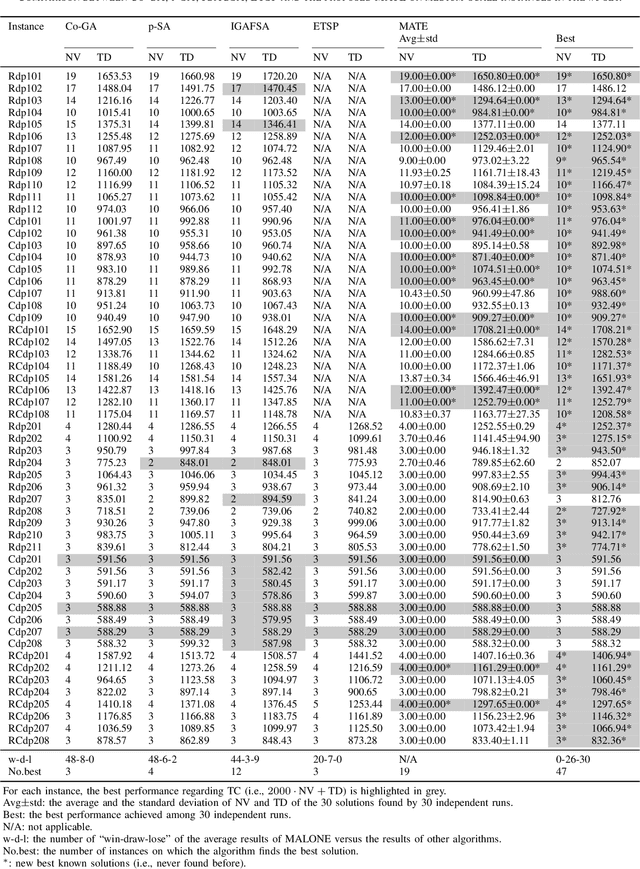
The vehicle routing problem with simultaneous pickup-delivery and time windows (VRPSPDTW) has attracted much attention in the last decade, due to its wide application in modern logistics involving bi-directional flow of goods. In this paper, we propose a memetic algorithm with efficient local search and extended neighborhood, dubbed MATE, for solving this problem. The novelty of MATE lies in three aspects: 1) an initialization procedure which integrates an existing heuristic into the population-based search framework, in an intelligent way; 2) a new crossover involving route inheritance and regret-based node reinsertion; 3) a highly-effective local search procedure which could flexibly search in a large neighborhood by switching between move operators with different step sizes, while keeping low computational complexity. Experimental results on public benchmark show that MATE consistently outperforms all the state-of-the-art algorithms, and notably, finds new best-known solutions on 44 instances (65 instances in total). A new benchmark of large-scale instances, derived from a real-world application of the JD logistics, is also introduced, which could serve as a new and more practical test set for future research.
Evaluation of Thermal Imaging on Embedded GPU Platforms for Application in Vehicular Assistance Systems
Jan 05, 2022


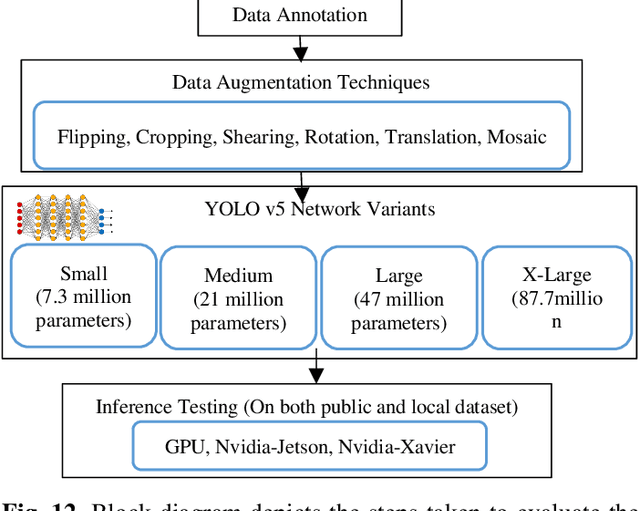
This study is focused on evaluating the real-time performance of thermal object detection for smart and safe vehicular systems by deploying the trained networks on GPU & single-board EDGE-GPU computing platforms for onboard automotive sensor suite testing. A novel large-scale thermal dataset comprising of > 35,000 distinct frames is acquired, processed, and open-sourced in challenging weather and environmental scenarios. The dataset is a recorded from lost-cost yet effective uncooled LWIR thermal camera, mounted stand-alone and on an electric vehicle to minimize mechanical vibrations. State-of-the-art YOLO-V5 networks variants are trained using four different public datasets as well newly acquired local dataset for optimal generalization of DNN by employing SGD optimizer. The effectiveness of trained networks is validated on extensive test data using various quantitative metrics which include precision, recall curve, mean average precision, and frames per second. The smaller network variant of YOLO is further optimized using TensorRT inference accelerator to explicitly boost the frames per second rate. Optimized network engine increases the frames per second rate by 3.5 times when testing on low power edge devices thus achieving 11 fps on Nvidia Jetson Nano and 60 fps on Nvidia Xavier NX development boards.
A Theoretical Overview of Neural Contraction Metrics for Learning-based Control with Guaranteed Stability
Oct 02, 2021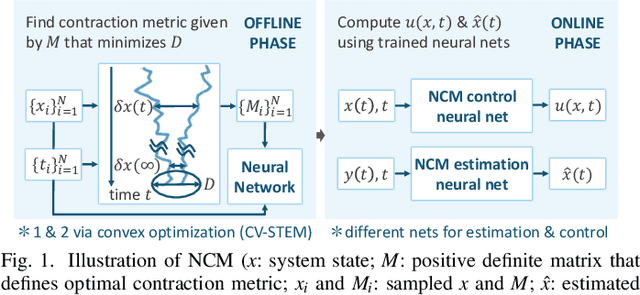
This paper presents a theoretical overview of a Neural Contraction Metric (NCM): a neural network model of an optimal contraction metric and corresponding differential Lyapunov function, the existence of which is a necessary and sufficient condition for incremental exponential stability of non-autonomous nonlinear system trajectories. Its innovation lies in providing formal robustness guarantees for learning-based control frameworks, utilizing contraction theory as an analytical tool to study the nonlinear stability of learned systems via convex optimization. In particular, we rigorously show in this paper that, by regarding modeling errors of the learning schemes as external disturbances, the NCM control is capable of obtaining an explicit bound on the distance between a time-varying target trajectory and perturbed solution trajectories, which exponentially decreases with time even under the presence of deterministic and stochastic perturbation. These useful features permit simultaneous synthesis of a contraction metric and associated control law by a neural network, thereby enabling real-time computable and probably robust learning-based control for general control-affine nonlinear systems.
Human-Level Control without Server-Grade Hardware
Nov 01, 2021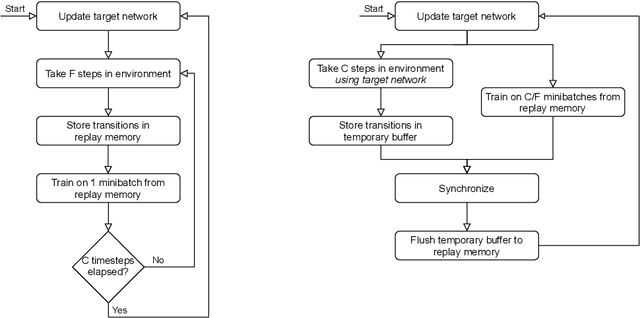

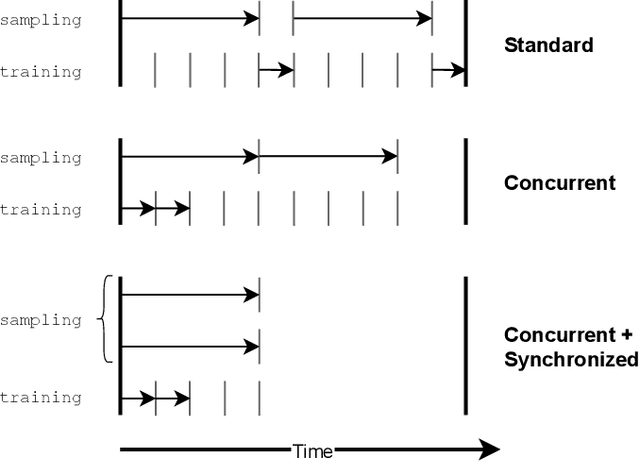

Deep Q-Network (DQN) marked a major milestone for reinforcement learning, demonstrating for the first time that human-level control policies could be learned directly from raw visual inputs via reward maximization. Even years after its introduction, DQN remains highly relevant to the research community since many of its innovations have been adopted by successor methods. Nevertheless, despite significant hardware advances in the interim, DQN's original Atari 2600 experiments remain costly to replicate in full. This poses an immense barrier to researchers who cannot afford state-of-the-art hardware or lack access to large-scale cloud computing resources. To facilitate improved access to deep reinforcement learning research, we introduce a DQN implementation that leverages a novel concurrent and synchronized execution framework designed to maximally utilize a heterogeneous CPU-GPU desktop system. With just one NVIDIA GeForce GTX 1080 GPU, our implementation reduces the training time of a 200-million-frame Atari experiment from 25 hours to just 9 hours. The ideas introduced in our paper should be generalizable to a large number of off-policy deep reinforcement learning methods.
Who supervises the supervisor? Model monitoring in production using deep feature embeddings with applications to workpiece inspection
Jan 17, 2022The automation of condition monitoring and workpiece inspection plays an essential role in maintaining high quality as well as high throughput of the manufacturing process. To this end, the recent rise of developments in machine learning has lead to vast improvements in the area of autonomous process supervision. However, the more complex and powerful these models become, the less transparent and explainable they generally are as well. One of the main challenges is the monitoring of live deployments of these machine learning systems and raising alerts when encountering events that might impact model performance. In particular, supervised classifiers are typically build under the assumption of stationarity in the underlying data distribution. For example, a visual inspection system trained on a set of material surface defects generally does not adapt or even recognize gradual changes in the data distribution - an issue known as "data drift" - such as the emergence of new types of surface defects. This, in turn, may lead to detrimental mispredictions, e.g. samples from new defect classes being classified as non-defective. To this end, it is desirable to provide real-time tracking of a classifier's performance to inform about the putative onset of additional error classes and the necessity for manual intervention with respect to classifier re-training. Here, we propose an unsupervised framework that acts on top of a supervised classification system, thereby harnessing its internal deep feature representations as a proxy to track changes in the data distribution during deployment and, hence, to anticipate classifier performance degradation.
Joint Detection of Motion Boundaries and Occlusions
Nov 01, 2021



We propose MONet, a convolutional neural network that jointly detects motion boundaries (MBs) and occlusion regions (Occs) in video both forward and backward in time. Detection is difficult because optical flow is discontinuous along MBs and undefined in Occs, while many flow estimators assume smoothness and a flow defined everywhere. To reason in the two time directions simultaneously, we direct-warp the estimated maps between the two frames. Since appearance mismatches between frames often signal vicinity to MBs or Occs, we construct a cost block that for each feature in one frame records the lowest discrepancy with matching features in a search range. This cost block is two-dimensional, and much less expensive than the four-dimensional cost volumes used in flow analysis. Cost-block features are computed by an encoder, and MB and Occ estimates are computed by a decoder. We found that arranging decoder layers fine-to-coarse, rather than coarse-to-fine, improves performance. MONet outperforms the prior state of the art for both tasks on the Sintel and FlyingChairsOcc benchmarks without any fine-tuning on them.
Real-Time Adaptive Velocity Optimization for Autonomous Electric Cars at the Limits of Handling
Dec 25, 2020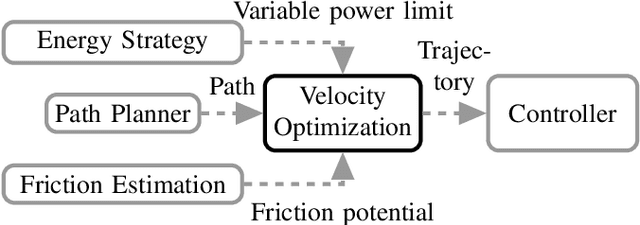
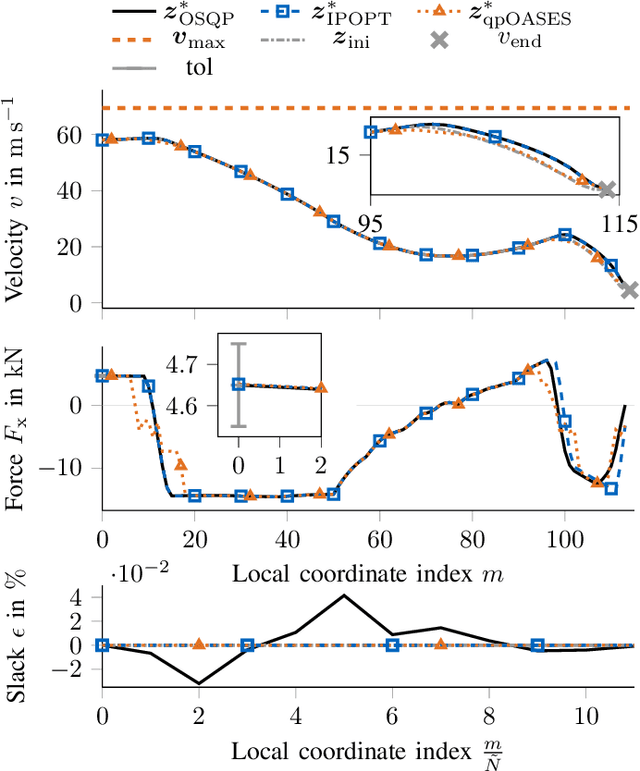
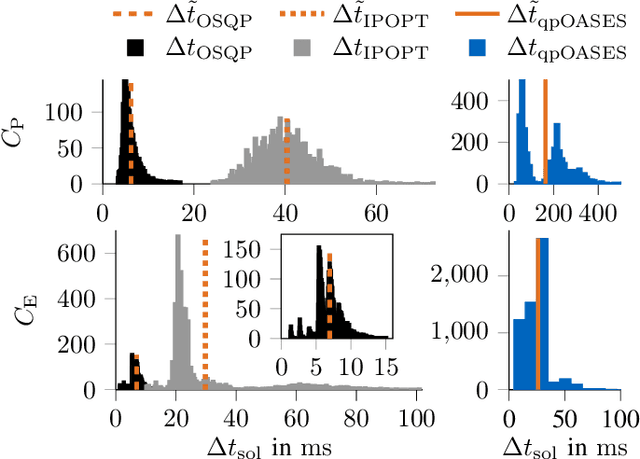

With the evolution of self-driving cars, autonomous racing series like Roborace and the Indy Autonomous Challenge are rapidly attracting growing attention. Researchers participating in these competitions hope to subsequently transfer their developed functionality to passenger vehicles, in order to improve self-driving technology for reasons of safety, and due to environmental and social benefits. The race track has the advantage of being a safe environment where challenging situations for the algorithms are permanently created. To achieve minimum lap times on the race track, it is important to gather and process information about external influences including, e.g., the position of other cars and the friction potential between the road and the tires. Furthermore, the predicted behavior of the ego-car's propulsion system is crucial for leveraging the available energy as efficiently as possible. In this paper, we therefore present an optimization-based velocity planner, mathematically formulated as a multi-parametric Sequential Quadratic Problem (mpSQP). This planner can handle a spatially and temporally varying friction coefficient, and transfer a race Energy Strategy (ES) to the road. It further handles the velocity-profile-generation task for performance and emergency trajectories in real time on the vehicle's Electronic Control Unit (ECU).
Proactive Query Expansion for Streaming Data Using External Source
Jan 17, 2022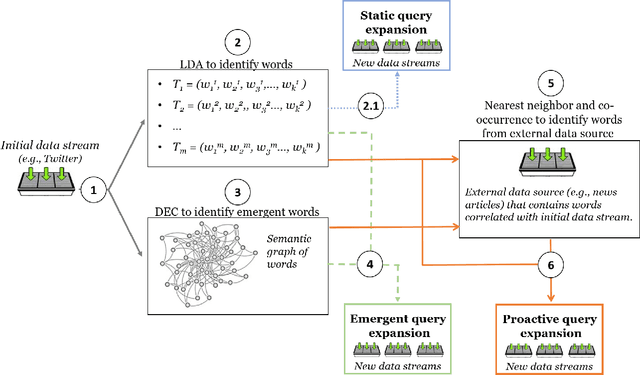
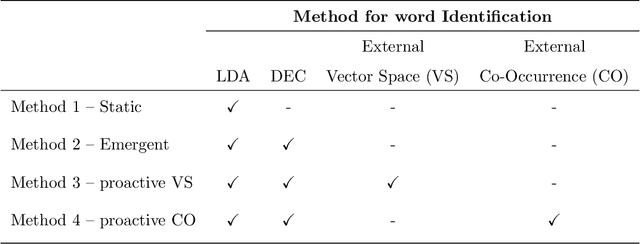

Query expansion is the process of reformulating the original query by adding relevant words. Choosing which terms to add in order to improve the performance of the query expansion methods or to enhance the quality of the retrieved results is an important aspect of any information retrieval system. Adding words that can positively impact the quality of the search query or are informative enough play an important role in returning or gathering relevant documents that cover a certain topic can result in improving the efficiency of the information retrieval system. Typically, query expansion techniques are used to add or substitute words to a given search query to collect relevant data. In this paper, we design and implement a pipeline of automated query expansion. We outline several tools using different methods to expand the query. Our methods depend on targeting emergent events in streaming data over time and finding the hidden topics from targeted documents using probabilistic topic models. We employ Dynamic Eigenvector Centrality to trigger the emergent events, and the Latent Dirichlet Allocation to discover the topics. Also, we use an external data source as a secondary stream to supplement the primary stream with relevant words and expand the query using the words from both primary and secondary streams. An experimental study is performed on Twitter data (primary stream) related to the events that happened during protests in Baltimore in 2015. The quality of the retrieved results was measured using a quality indicator of the streaming data: tweets count, hashtag count, and hashtag clustering.
Fast Learning of MNL Model from General Partial Rankings with Application to Network Formation Modeling
Dec 31, 2021
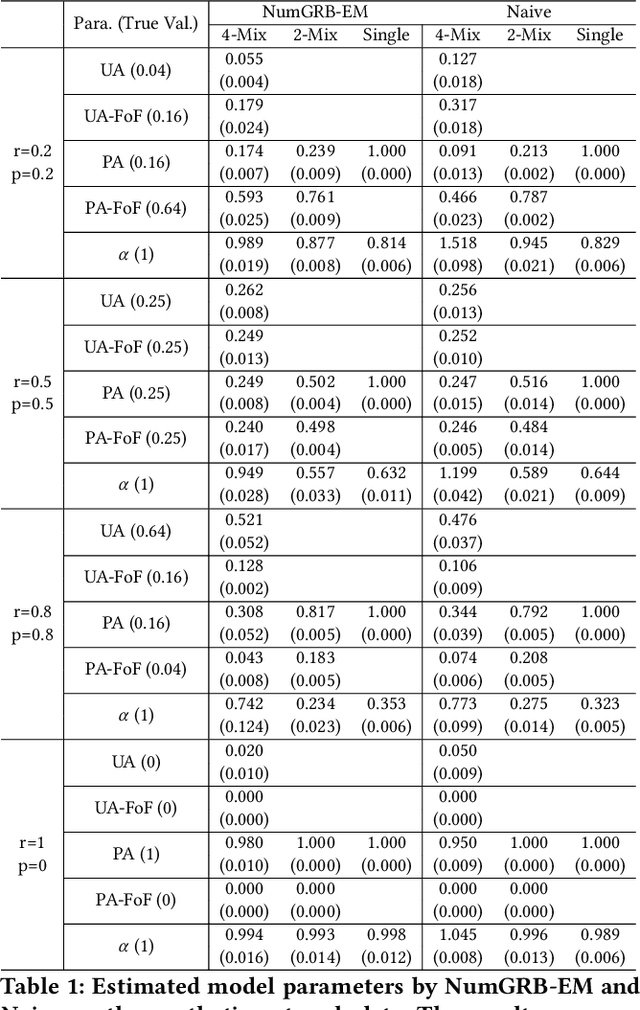
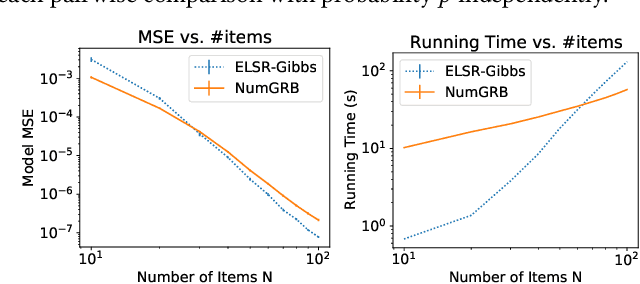
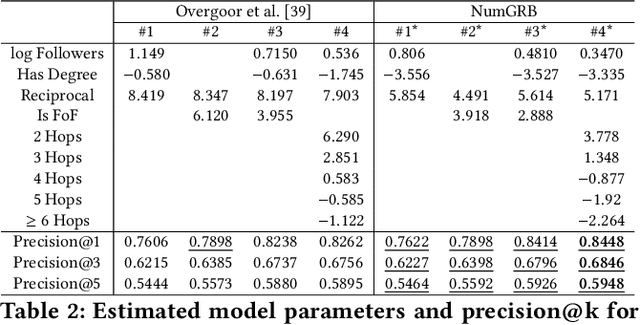
Multinomial Logit (MNL) is one of the most popular discrete choice models and has been widely used to model ranking data. However, there is a long-standing technical challenge of learning MNL from many real-world ranking data: exact calculation of the MNL likelihood of \emph{partial rankings} is generally intractable. In this work, we develop a scalable method for approximating the MNL likelihood of general partial rankings in polynomial time complexity. We also extend the proposed method to learn mixture of MNL. We demonstrate that the proposed methods are particularly helpful for applications to choice-based network formation modeling, where the formation of new edges in a network is viewed as individuals making choices of their friends over a candidate set. The problem of learning mixture of MNL models from partial rankings naturally arises in such applications. And the proposed methods can be used to learn MNL models from network data without the strong assumption that temporal orders of all the edge formation are available. We conduct experiments on both synthetic and real-world network data to demonstrate that the proposed methods achieve more accurate parameter estimation and better fitness of data compared to conventional methods.
Contextual Bandits for Advertising Campaigns: A Diffusion-Model Independent Approach (Extended Version)
Jan 13, 2022
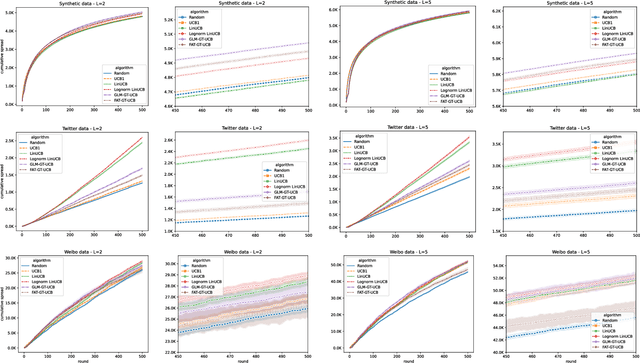
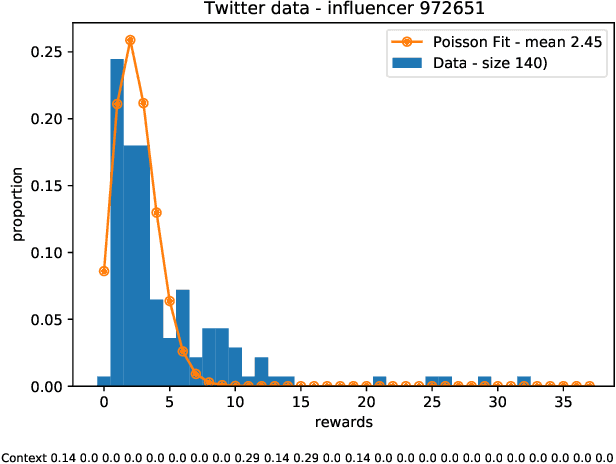
Motivated by scenarios of information diffusion and advertising in social media, we study an influence maximization problem in which little is assumed to be known about the diffusion network or about the model that determines how information may propagate. In such a highly uncertain environment, one can focus on multi-round diffusion campaigns, with the objective to maximize the number of distinct users that are influenced or activated, starting from a known base of few influential nodes. During a campaign, spread seeds are selected sequentially at consecutive rounds, and feedback is collected in the form of the activated nodes at each round. A round's impact (reward) is then quantified as the number of newly activated nodes. Overall, one must maximize the campaign's total spread, as the sum of rounds' rewards. In this setting, an explore-exploit approach could be used to learn the key underlying diffusion parameters, while running the campaign. We describe and compare two methods of contextual multi-armed bandits, with upper-confidence bounds on the remaining potential of influencers, one using a generalized linear model and the Good-Turing estimator for remaining potential (GLM-GT-UCB), and another one that directly adapts the LinUCB algorithm to our setting (LogNorm-LinUCB). We show that they outperform baseline methods using state-of-the-art ideas, on synthetic and real-world data, while at the same time exhibiting different and complementary behavior, depending on the scenarios in which they are deployed.